1. What is meta-learning?
The performance of a learned model depends on its training dataset, algorithm, and parameters of the algorithm. Many experiments are required to find the best performing algorithm and the parameters of the algorithm. Meta-learning methods help find these and optimize the number of experiments. This allows for better predictions in less time.
Meta-learning can be used for different machine learning models (e.g. few-shot learning, reinforcement learning, natural language processing, etc.). Meta-learning algorithms make predictions by taking the output of the machine learning algorithm and metadata as input. Meta-learning algorithms can learn to use the best predictions of machine learning algorithms to make better predictions.
In computer science, meta-learning research and methods started in the 1980s and became popular after the work of Jürgen Schmidhuber and Yoshua Bengio on the subject.
Meta-learning, also known as "learning by learning," is a subset of machine learning in computer science. It is used to improve the results and performance of a learning algorithm by changing some aspects of the learning algorithm based on experimental results. Meta-learning helps researchers understand which algorithms produce the best/better predictions from a dataset.
Meta-learning algorithms use the metadata of the learning algorithm as input. They then make predictions and provide as output information about the performance of these learning algorithms. For non-technical users, metadata is data about data. For example, the metadata of an image in a learning model can be its size, resolution, style, creation date, and owner.
Systematic experimental design in meta-learning is the most important challenge.
2. Why Meta-Learning Matters
Machine learning algorithms have some challenges such as
Requires large datasets for training
High operating costs due to many trials/experiments during the training phase
Experiments/trials take a long time to find the best model that performs best on a certain dataset.
Meta-learning can help machine learning algorithms meet these challenges by optimizing learning algorithms and finding better-performing ones.
3. What are the interests of meta-learning?
Interest in meta-learning has been growing over the past five years, especially accelerating after 2017. As the use of deep learning and advanced machine learning algorithms increases, the difficulty of training these learning algorithms increases the interest in meta-learning learning.

4. How does meta-learning work?
In general, meta-learning algorithms are trained using the output of the machine learning algorithm (i.e. the model's predictions) and metadata. After training, its skills are tested and used to make final predictions.
Meta-learning covers things like
- Observe how different machine learning models perform on learning tasks
- learn from metadata
- Perform a faster learning process for new tasks
For example, we might want to train a model to label different breeds of dogs .
- We first need an annotated dataset
- Various ML models are built on the training set. They can focus only on certain parts of the dataset
- A meta-training process is used to improve the performance of these models
- Finally, a meta-trained model can be used to build a new model from several examples based on its experience in previous training processes
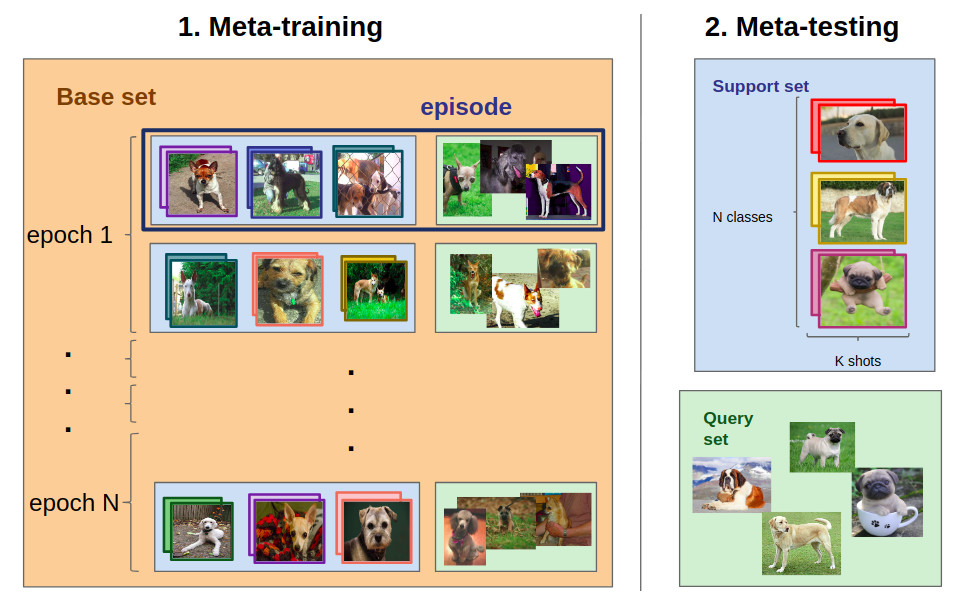
5. What are the methods and applications of meta-learning?
Meta-learning is used in various fields in the field of machine learning. There are different approaches in meta-learning such as model-based, metric-based, and optimization-based approaches. We briefly explain some common methods and approaches in the field of meta-learning below.
metric learning
Metric learning means learning a metric space for prediction. The model gives good results in few-shot classification task.
Model-Agnostic Meta-Learning (MAML)
By training a neural network with a small number of examples, the model adapts to new tasks more quickly. MAML is a general optimization and task-agnostic algorithm for training the parameters of a model for fast learning with few gradient updates.
Recurrent Neural Network (RNN)
Recurrent Neural Networks are a category/type of Artificial Neural Networks that are applied to different machine learning problems, such as problems with sequential data or time series data. RNN models are commonly used for language translation, speech recognition, and handwriting recognition tasks. In meta-learning, RNNs are used as an alternative to creating recurrent models that sequentially collect data from a dataset and process it as new input.
stacking/stacking generalization
Stacking is a subfield of ensemble learning for meta-learning models. Additionally, supervised and unsupervised learning models also benefit from stacking. Stacking includes the following steps:
Train Learning Algorithms Using Available Data
Create combiner algorithms (such as meta-learning models or logistic regression models) to combine all the predictions of these learning algorithms, which are called ensemble members.
The combinator algorithm is used to make the final prediction.
6. What are the benefits of meta-learning?
Meta-learning algorithms are used to improve machine learning solutions.
The benefits of meta-learning are
Higher model prediction accuracy:
Optimizing learning algorithms: For example, optimizing hyperparameters to find the best results. Therefore, this optimization task, which is usually done by humans, is done by meta-learning algorithms.
Helps learning algorithms better adapt to changing conditions
Find clues to designing better learning algorithms
Faster and cheaper training process
Support learning from fewer examples
Increase the speed of the learning process by reducing necessary experiments
Building more general models: Learning to solve many tasks instead of just one: Meta-learning does not focus on training one model on one specific dataset.