This article records the pest identification paper "High performing ensemble of convolutional neural networks for insect pest image detection" that I just read.
Article summary
This article is mainly about the innovation of optimization methods, which is actually innovative. As mentioned in the abstract of this article, the main contribution of the article is to propose two variants based on the Adam optimizer: EXP and EXPLR. Then the author used five popular CNN models: ResNet50, GoogleNet, ShuffleNet, MobileNetv2 and DenseNet201 to conduct experiments, and finally adopted a simple integration strategy to obtain better experimental results. The main advantage of the two optimization algorithms proposed in the article is that the model converges faster and can achieve relatively better performance. The better part of the article is that not only experiments were carried out on the pest data set, but also on the medical image data set to verify that the proposed optimizer is effective. This is actually a bonus item of this article, which further verifies the effectiveness of the proposed method.
The two optimizers proposed in the article
Before proposing a new optimizer, the article mainly analyzes Adam and related variant optimizers, and finally proposes a new optimizer. This logic is actually very good.
1 EXP
This is mainly based on DGrad, setting the fixed parameter in the original method to a variable parameter K, and then combining the formulas to finally get the EXP optimizer. An example of the learning rate change of the EXP optimizer is given in the article. The bad point is to use , the horizontal and vertical coordinates of the figure in the article are not given, this is actually an example figure that the author does not know how to draw. But it can be roughly seen from the figure that the larger K is, the steeper the learning rate change will be. However, in the follow-up experiments in the article, the author seems to directly set K=10 without performing an optimization operation on it, which is actually somewhat imperfect.

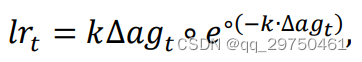
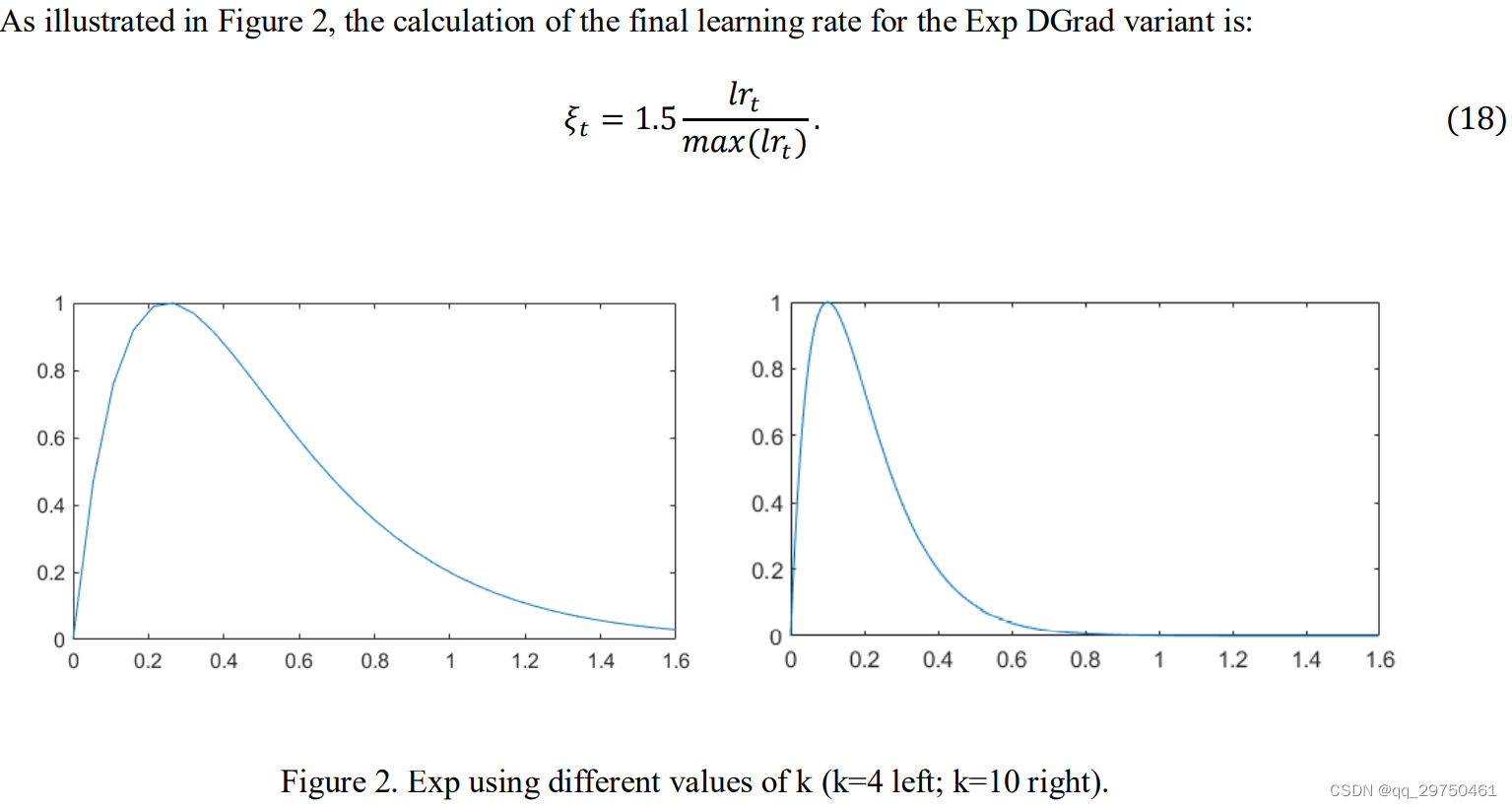
2 EXPLR
Compared with the above EXP, this optimizer multiplies a Sigmoid function, which is equivalent to further smoothing the learning rate.

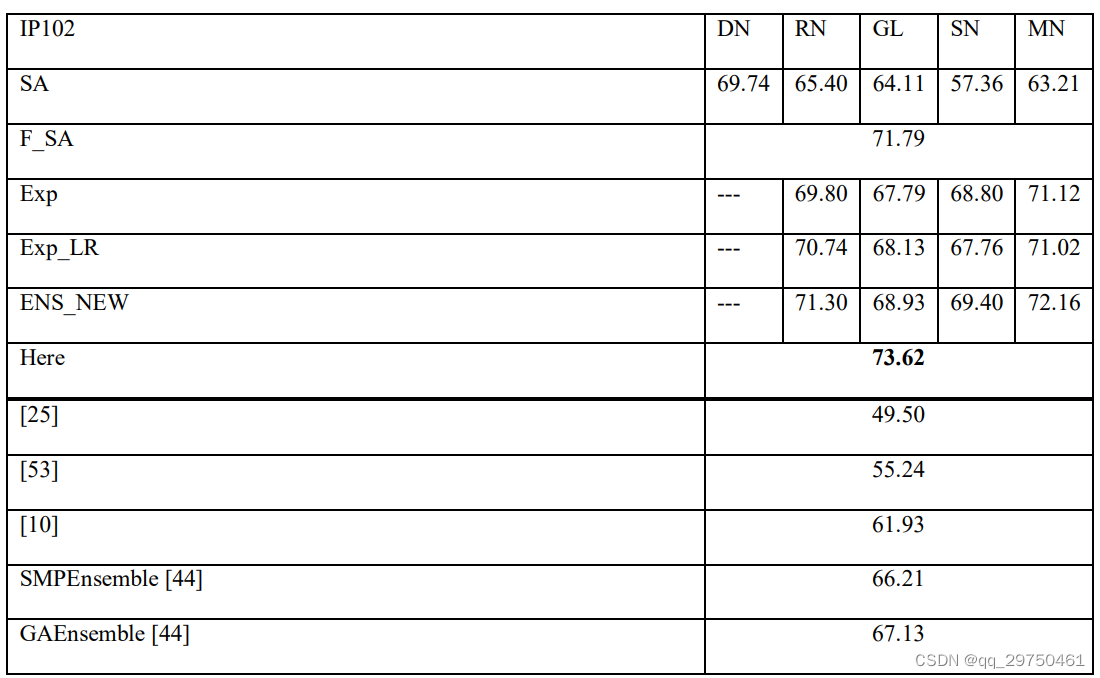
Article experiment configuration and results
Each model in this paper only performs 20 rounds of iterations to get the results in the table, which further shows that the proposed optimizer is effective.