【读论文】Real-time infrared and visible image fusion network using adaptive pixel weighting strategy
Paper: https://www.sciencedirect.com/science/article/pii/S1566253523001793
If there is any infringement, please contact the blogger
For more detailed interpretations of papers on infrared and visible light image fusion, you are welcome to come to the infrared and visible light image fusion column . For questions in this field, you are also welcome to contact me via private message or public account.
introduce
I haven’t read a paper for a long time. I just had free time today and found another paper on information fusion. Let’s take a look at it together.

A paper that improves real-time performance. This paper is different from the papers we have seen before. As for the differences, let’s take a look.
Network structure
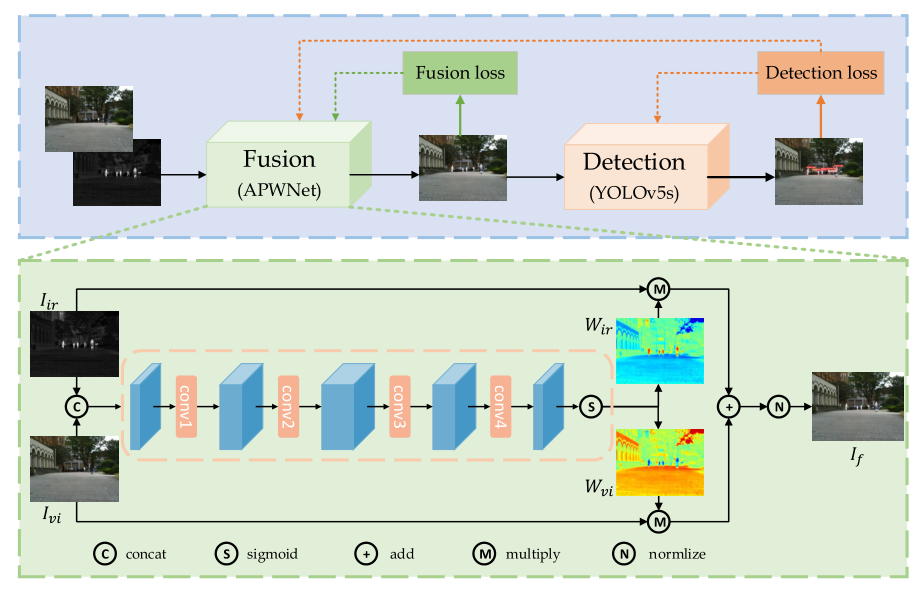
Let’s take a look at this network architecture diagram first
What do you think? My first reaction is that I got excited today. Why is this network architecture diagram so simple? Why are there no attention blocks, enhancement blocks, etc.? There are only these few convolutional layers. I have to admire this. The author of this paper can design such a simple network structure, and it is also useful.

So what is its structure like?
On the surface, it looks like several convolutional layers stacked together. In fact, it is just several convolutional layers stacked together.
What is lightweight? This is lightweight!

So what do the previous convolutions do?
Let me talk about it first. The author hopes to improve the real-time performance of the entire network. Those methods of extracting deep features and then restoring the image are obviously inappropriate. And it is mentioned in the article that although the method based on deep features improves the effect of the image, it is not suitable for For downstream tasks, there is no difference compared with pixel-based methods.
Therefore, the purpose of setting up these convolutional layers is to generate a weight. Use the generated weight to add the infrared and visible light images, and then fuse the images after processing.
The process of generating weights is as follows. P here is the multiple convolutional layers we mentioned earlier, plus a sigmoid. The purpose is to make the weight of the output result be between 0 and 1. C is the process of splicing operations using weights to fuse images

. As follows

, and then normalize

At this point, image fusion is completed.
You may have a question when you see this, so how can we make these convolutional layers generate the weights we want?
Let’s look at the loss function for this problem. Don’t worry, let’s take a look at the loss function now.
loss function




What does it feel like to see this loss function? It’s so refreshing, right?
I haven’t seen such a simple loss for a long time, and they are all familiar to us, the maximum gradient and maximum strength losses.
The only difference is the detection loss here, which is consistent with YoloV5.
What we have been saying is that the goal of this paper is to make the fused image more suitable for downstream tasks. The detection loss here is just like this. It improves the detection accuracy of the fused image, and combined with the maximum gradient and maximum intensity loss, makes the fused image not only suitable for downstream tasks. detection, and can retain intensity information and detail information.
Then it is very clear. The only thing that can be trained in the network architecture is the previous convolution layer. The output of the convolution layer is the weight. So does it mean that we want to achieve the above goal by generating the corresponding weight through the convolution layer? , so these loss functions can enable the convolutional layer to have the ability to generate adaptive weights during the training process.
Summarize
The whole paper is very easy to read. The biggest inspiration for me is that the original pursuit of the size of the network and the variety of feature extraction methods can be changed. After all, we still hope that the fused image can be used for Downstream tasks, not just generation will do.
Interpretation of other fusion image papers
==》Infrared and visible light image fusion column, come and click on me》==
【Read the paper】DIVFusion: Darkness-free infrared and visible image fusion
【读论文】RFN-Nest: An end-to-end residual fusion network for infrared and visible images
【读论文】Self-supervised feature adaption for infrared and visible image fusion
【读论文】FusionGAN: A generative adversarial network for infrared and visible image fusion
【读论文】DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
【读论文】DenseFuse: A Fusion Approach to Infrared and Visible Images
reference
[1] Real-time infrared and visible image fusion network using adaptive pixel
weighting strategy