// 在 product 表中,查询 id = 1 的记录
select * from product where id = 1;What is the MySQL execution process like?
For the process of MySQL query statements, you can see the various functional modules in the internal architecture of MySQL:

As you can see, the MySQL architecture is divided into two layers: Server layer and storage engine layer.
- The Server layer is responsible for establishing connections, analyzing and executing SQL . Most of MySQL's core functional modules are implemented here, including connectors, query caches, parsers, preprocessors, optimizers, executors, etc. In addition, all built-in functions (such as time, date, mathematical and encryption functions, etc.) and all cross-storage engine functions (such as stored procedures, triggers, views, etc.) are implemented in the Server layer.
- The storage engine layer is responsible for data storage and retrieval . It supports multiple storage engines such as InnoDB, MyISAM, and Memory. Different storage engines share a Server layer. The most commonly used storage engine now is InnoDB. Starting from MySQL version 5.5, InnoDB has become the default storage engine of MySQL.
Step One: Connectors
If you want to use MySQL in the Linux operating system, the first step is to connect to the MySQL service before executing the SQL statement. Generally, we use the following command to connect:
# -h 指定 MySQL 服务得 IP 地址,如果是连接本地的 MySQL服务,可以不用这个参数;
# -u 指定用户名,管理员角色名为 root;
# -p 指定密码,如果命令行中不填写密码(为了密码安全,建议不要在命令行写密码),就需要在交互对话里面输入密码
mysql -h$ip -u$user -pThe connection process requires a TCP three-way handshake first, because MySQL is transmitted based on the TCP protocol. If the MySQL service is not started, you will receive the following error:

If the MySQL service is running normally, after completing the establishment of the TCP connection, the connector will start to verify the user name and password. If the user name or password is incorrect, an "Access denied for user" error will be received, and then the client program will end running.

If there is no problem with the user's password, the connector will obtain the user's permissions and save them. Any subsequent operations performed by the user in this connection will be logically judged based on the permissions read at the beginning of the connection.
Therefore, if a user has already established a connection, even if the administrator modifies the user's permissions midway, it will not affect the permissions of the existing connection. After the modification is completed, only new connections will use the new permission settings.
How to check how many clients are connected to the MySQL service?
You can execute the show processlist command to view

For example, as shown in the above figure, there are two users named root who have connected to the MySQL service. The status of the Command column of the user with id 6 is Sleep, which means that the user has not executed any operations after connecting to the MySQL service. command, that is to say, this is an idle connection, and the idle time is 736 seconds (Time column).
Will idle connections be always occupied?
Of course not, MySQL defines the maximum idle time of an idle connection, which is controlled by the wait_timeout parameter. The default is 8 hours. If the idle connection exceeds this time , the connector will automatically disconnect .
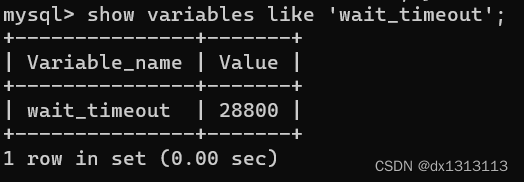
We can also manually disconnect idle connections by using the kill connection + id command.
mysql> kill connection +6;
Query OK, 0 rows affected (0.00 sec)After an idle connection is actively disconnected by the server, the client will not know it immediately. When the client initiates the next request, it will receive such an error: "ERROR 2013 (HY000): Lost connection to MySQL server during query”
Is there a limit to the number of MySQL connections?
The maximum number of connections supported by the MySQL service is controlled by the max_connections parameter. If this value is exceeded, the system will reject subsequent connection requests and report an error message "Too many connections"
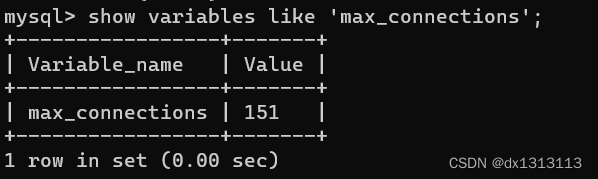
MySQL connections are the same as HTTP. Long connections also have the concept of segmented connections. The differences are as follows:
// 短连接
连接 mysql 服务(TCP 三次握手)
执行sql
断开 mysql 服务(TCP 四次挥手)
// 长连接
连接 mysql 服务(TCP 三次握手)
执行sql
执行sql
执行sql
....
断开 mysql 服务(TCP 四次挥手)It can be seen that the advantage of using long connections is that it can reduce the process of establishing and disconnecting connections , so it is generally recommended to use long connections .
However, using long connections may occupy more memory , because MySQL temporarily uses memory to manage connection objects during query execution, and these connection object resources will only be released when the connection is disconnected. If there are many long connections accumulated, the MySQL service will occupy too much memory and may be forcibly killed by the system. This may cause the MySQL service to restart abnormally.
How to solve the problem of long connections occupying memory?
Two solutions:
The first is to regularly disconnect long connections . Since the memory resources occupied by the connection will be released after disconnecting, we can disconnect long connections regularly.
Second, the client actively resets the connection . MySQL version 5.7 implements the interface of the mysql_reset_connection() function. This interface function is not a command. After the client performs a large operation, the mysql_reset_connection function is called in the code to reset the connection and achieve the effect of releasing memory. This process does not require reconnection and permission verification, but will restore the connection to the state when it was just created.
At this point, the work of the connector is completed. Let’s briefly summarize :
- Perform TCP three-way handshake with client to establish connection
- Verify the username and password of the client. If the username or password is incorrect, an error will be reported.
- If the username and password are correct, the user's permissions will be read, and subsequent permission logic judgments will be based on the permissions read at this time.
Step 2: Query cache
After the connector's work is completed, the client can send the SQL statement to the MySQL service. After the MySQL service receives the SQL statement, it will parse out the first field of the SQL statement to see what type of statement it is.
If SQL is a query statement (select statement), MySQL will first search the cache data in the Query Cache to see if this command has been executed before. This query cache is stored in the memory in the form of key_value, key It is a SQL query statement, and value is the result of the SQL statement query.
If the query statement hits the query cache, the value will be returned directly to the client. If the query statement does not hit the query cache, the execution will continue. After the execution is completed, the query results will be placed in the query cache. middle.
Look at it this way, the query cache is quite useful, but in fact the query cache is useless .
For tables that are updated frequently, the query cache hit rate is very low, because as long as there is an update operation on a table, the query cache of this table will be cleared. If a data with a large query result has just been cached and has not been used yet, and there is an update operation on the table at this time, the query cache will be cleared.
Therefore, MySQL version 8.0 directly deletes the query cache , which means that starting from MySQL 8.0, executing a SQL query statement will no longer reach the query cache stage.
For versions prior to MySQL 8.0, if we want to turn off the query cache, we can set the parameter query_cache_type to DEMAND.
Step 3: Parse SQL
Before officially executing the SQL query statement, MySQL will first parse the SQL statement, and this work is completed by the [parser].
parser
The parser does two things:
The first thing: lexical analysis . MySQL will identify the keywords based on the input string and construct a SQL syntax tree, which facilitates subsequent modules to obtain SQL types, table names, field names, where conditions, etc.
The second thing: grammatical analysis . Based on the results of lexical analysis, the syntax parser will determine whether the input SQL statement satisfies MySQL syntax based on grammatical rules.
If the SQL syntax we input is incorrect, an error will be reported at this stage of the parser. For example, in the following query statement, if from is written as form, the MySQL parser will report an error.

But note that the table does not exist or the field does not exist, it is not done in the parser. The parser is only responsible for building the syntax tree and checking the syntax, but it will not look up the table or whether the field exists .
Step 4: Execute SQL
After passing through the parser, it is time to enter the process of executing the SQL query statement. The process of each SELECT query statement can be mainly divided into the following three stages:
- prepare stage, that is, preprocessing stage
- optimize phase, that is, optimization phase
- execute stage, that is, execution stage
preprocessor
The job of the preprocessor:
- Check whether the table or field in the SQL query statement exists
- Expand the * symbol in SELECT * to all columns on the table
For the following query statement, the test table does not exist. At this time, MySQL will report an error during the prepare phase of executing the SQL query statement.
mysql> select * from test;
ERROR 1146 (42S02): Table 'mysql.test' doesn't existoptimizer
After the preprocessing stage, an execution plan needs to be formulated for the SQL query statement. This work is completed by the [optimizer].
The optimizer is mainly responsible for determining the execution plan of the SQL query statement . For example, when there are multiple indexes in the table, the optimizer will decide which index to use based on the query cost.
To know which index the optimizer selected, we can add an explain command at the beginning of the query statement, which will output the execution plan of this SQL statement, and then the key in the execution plan indicates which index was used during the execution. For example, if the key in the figure below is PRIMARY , the primary key index is used.

If the key in the execution plan of the query statement is null, it means that no index is used, then a full table scan (type = ALL) will be performed. This query scan method is the least efficient, as shown below:

This product table has only one index, which is the primary key. Now set name as a normal index (secondary index) in the table.
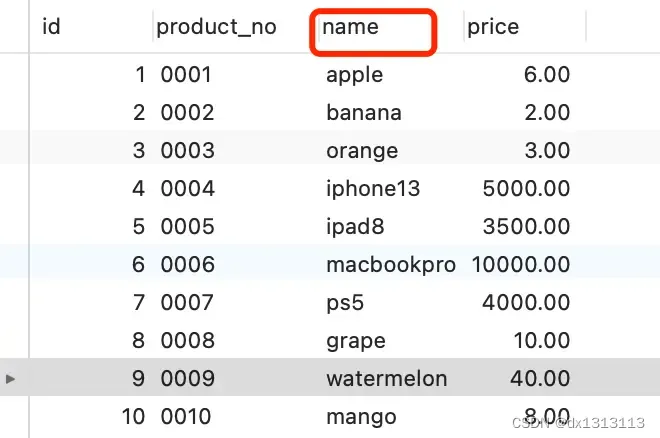
At this time, the product table has a primary key index (id) and a common index (name). Suppose this query statement is executed:
select id from product where id > 1 and name like 'i%';The result of this query statement can use either the primary key index or the ordinary index, but the execution efficiency will be different. At this time, the optimizer is needed to decide which index to use.
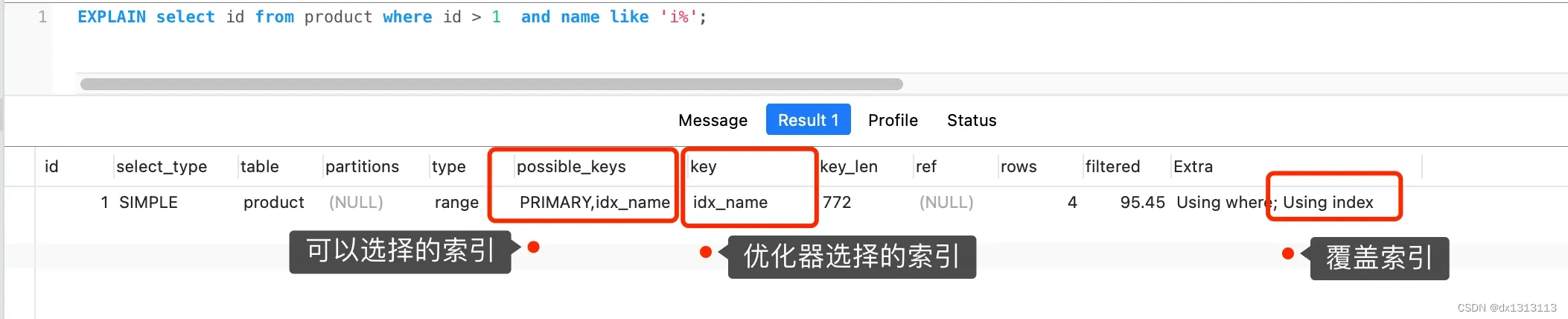
Obviously this query statement is a covering index , and the result can be found directly in the secondary index (because the data of the leaf nodes of the B+ tree in the secondary index stores the primary key value), so there is no need to search in the primary key index. Because the cost of querying the B+ tree of the primary key index is high, the optimizer will select a common index with a low query cost based on the consideration of query cost .
In the execution plan in the figure below, we can see that the ordinary index (name) is used during the execution, and Exta is Using index, which indicates that covering index optimization is used.
Actuator
After going through the optimizer, the execution plan is determined, and then MySQL actually starts executing the statement. This work is completed by the [executor]. During the execution process, the executor will interact with the storage engine, and the interaction is in record units.
Next, perform the process in three ways
- Primary key index query
- Full table scan
- index pushdown
Primary key index query
select * from product where id = 1;The query condition of this query statement uses the primary key index, and it is an equivalent query. At the same time, the primary key id is unique, and there will be no records with the same id. Therefore, the optimizer decided to use the access type const for query, that is, use the primary key index. To query a record, the execution process of the executor and storage engine is as follows:
- When executing the first query, the function pointed to by the read_first_record function pointer will be called. Because the access type selected by the optimizer is const, this function pointer is pointed to the interface for the InnoDB engine index query, and the condition id = 1 is handed over to the storage engine to allow storage The engine locates the first record that meets the conditions
- The storage engine locates the first record with id = 1 through the B+ tree structure of the primary key index . If the record does not exist, it will report a record not found error to the executor, and then the query ends. If the record exists, the record will be returned to the executor;
- After the executor reads the record from the storage engine, it then determines whether the record meets the query conditions. If it does, it will be sent to the client. If it does not, it will skip the record.
- The executor query process is a while loop , so it will be checked again, but this time because it is not the first query, the function pointed to by the read_record function pointer will be called. Because the access type selected by the optimizer is const, this function The pointer is pointed to a function that always returns - 1 , so when the function is called, the executor exits the loop , which ends the query.
Full table scan
select * from product where name = 'iphone';The query condition of this query statement does not use an index, so the optimizer decides to use the access type ALL to query, that is, a full table scan. Then the execution process of the executor and storage engine is as follows:
- For the first query of the executor, the function pointed to by the read_first_record function pointer will be called. Because the access type selected by the optimizer is all, this function pointer is pointed to the interface of the InnoDB engine full scan, allowing the storage engine to read the first record in the table. record ;
- The executor will determine whether the name of the record read is iPhone. If not, it will be skipped; if it is, the record will be sent to the client (yes, the Server layer will send it every time it reads a record from the storage engine. For the client , the reason why the client directly displays all records when displaying is because the client waits for the query statement to be completed before displaying all records ).
- The executor query process is a while loop , so it will be checked again and the function pointed by the read_record function pointer will be called. Because the access type selected by the optimizer is all, the read_record function pointer still points to the InnoDB engine full scan interface, so Then the storage engine layer is asked to continue reading the next record of the previous record . After the storage engine takes out the next record, it returns it to the executor (Server layer). The executor continues to judge the conditions. If the query conditions are not met, it will be skipped. The record is otherwise sent to the client;
- The above process is repeated until the storage engine has read all the records in the table, and then returns the read information to the executor (Server layer)
- The executor receives the query completion information reported by the storage engine, exits the loop, and stops the query.
At this point, the execution of this statement is completed.
index pushdown
(Query optimization strategy introduced in MySQL 5.6) Index pushdown can reduce the table return operations of secondary indexes during queries and improve query efficiency, because it hands over the tasks that the Server layer is responsible for to the storage engine layer.
To give a specific example for everyone to understand, here is a user table as follows, with a joint index (age, reward) established for the age and reward fields:
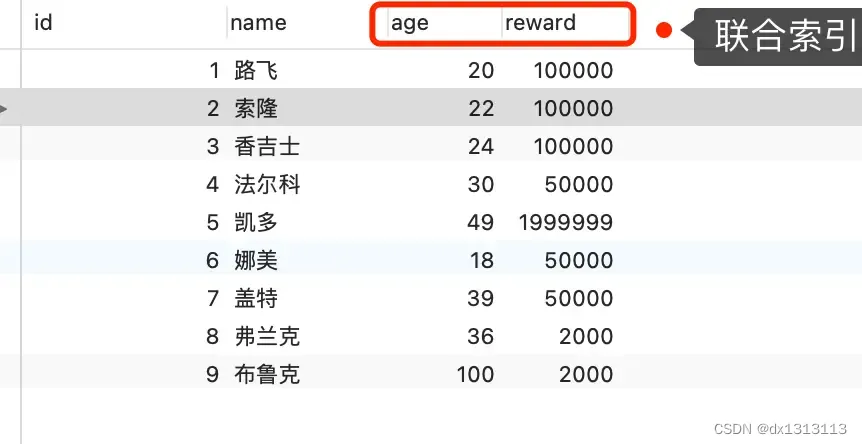
Now we have the following query statement:
select * from t_user where age > 20 and reward = 100000;The joint index will stop matching when it encounters a range query (>, <). That is, the age field can use the joint index, but the reward field cannot use the index .
Then, when index pushdown is not used (versions before MySQL 5.6), the execution flow of the executor and storage engine is as follows:
- The Server layer first calls the storage engine interface to locate the first secondary index record that meets the query conditions, that is, it locates the first record with age > 20;
- After the storage engine quickly locates this record based on the B+ tree of the secondary index, it obtains the primary key value, and then performs a table return operation to return the complete record to the server layer;
- The server layer determines whether the reward of the record is equal to 100000, and if so, it will be sent to the client; otherwise, the record will be skipped;
- Then, continue to request the next record from the storage engine. After the secondary index locates the record, the storage engine obtains the primary key value, and then performs a table return operation to return the complete record to the server layer;
- This repeats until the storage engine has read all the records in the table.
It can be seen that when there is no index pushdown, every time a secondary index record is queried, a table return operation is performed, and then the record is returned to the server, and then the server determines whether the reward of the record is equal to 100000.
After using index pushdown, the task of determining whether the recorded reward is equal to 100000 is handed over to the storage engine layer. The process is as follows:
- The Server layer first calls the storage engine interface to locate the first secondary index record that meets the query conditions, that is, it locates the first record with age > 20;
- After the storage engine locates the secondary index, it does not perform the table return operation, but first determines whether the conditions of the columns (reward columns) contained in the index (whether reward is equal to 100000) are true. If the condition is not met , the secondary index is skipped directly . If it is true , the table return operation is performed and the completed record is returned to the server layer.
- The server layer determines whether other query conditions (there are no other conditions in this query) are true. If they are true, it will be sent to the client; otherwise, the record will be skipped and the next record will be requested from the storage engine.
- This repeats until the storage engine has read all the records in the table.
It can be seen that after using index pushdown , although the reward column cannot be used in the joint index, because it is included in the joint index (age, reward), it is directly after the storage engine filters out the records that satisfy reward = 100000. Go back to the table to get the entire record . Compared with not using index pushdown, a lot of table return operations are saved.

Summarize
What happens during the execution of a SQL query statement?
- Connector: establish connection, manage connection, verify user identity;
- Query cache: If the query statement hits the query cache, it will be returned directly, otherwise it will continue to execute. This module has been removed in MySQL 8.0;
- Parse SQL, perform lexical analysis and syntax analysis on SQL query statements through the parser, and then build a syntax tree to facilitate subsequent modules to read table names, fields, and statement types;
- Execute SQL: There are three stages in executing SQL:
- Preprocessing phase: Checks if the table or field exists; expands the symbols
select *in*to all columns on the table. - Optimization stage: Based on the consideration of query cost, select the execution plan with the smallest query cost;
- Execution phase: Execute SQL query statements according to the execution plan, read records from the storage engine, and return them to the client;
- Preprocessing phase: Checks if the table or field exists; expands the symbols