【LSS】Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
1 abstract
The main goal of existing autonomous vehicles is to extract semantic information from multiple sensors, fuse this semantic information into a feature map in the BEV coordinate system, and then perform motion planning. The author of this article proposed a method that converts any number of camera data into features under BEV; lift: first map the Image information into a frustum, splat: then rasterize multiple frustums and train The results show that this model can not only achieve a good expression of picture information, but also achieve a good fusion of multiple pictures into a single expression, and is robust to calibration errors. Shoot: When the trajectory of the target movement is Mapping to our BEV perspective, we can find that the representations inferred by our model enable interpretable motion planning.

2 Introduction
In autonomous driving, multiple sensors are used as input. Each sensor has its own coordinate system, which ultimately needs to be unified into the own vehicle coordinate system for motion planning:
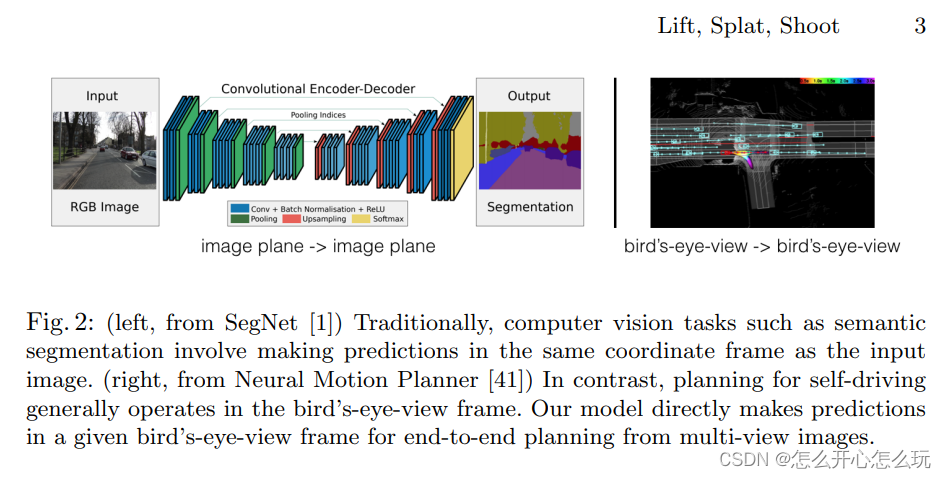
For multiple sensors Images generated by multiple cameras can be detected through a single Image, and then converted and translated in the large self-vehicle coordinate system to achieve panoramic detection of multiple self-vehicles, and single Image detection has translation invariance, transposition invariance, self-vehicle Isometrics under the autonomous vehicle framework have three valuable properties, but they require post-processing of the data, and this post-processing cannot be achieved in a data-driven manner.
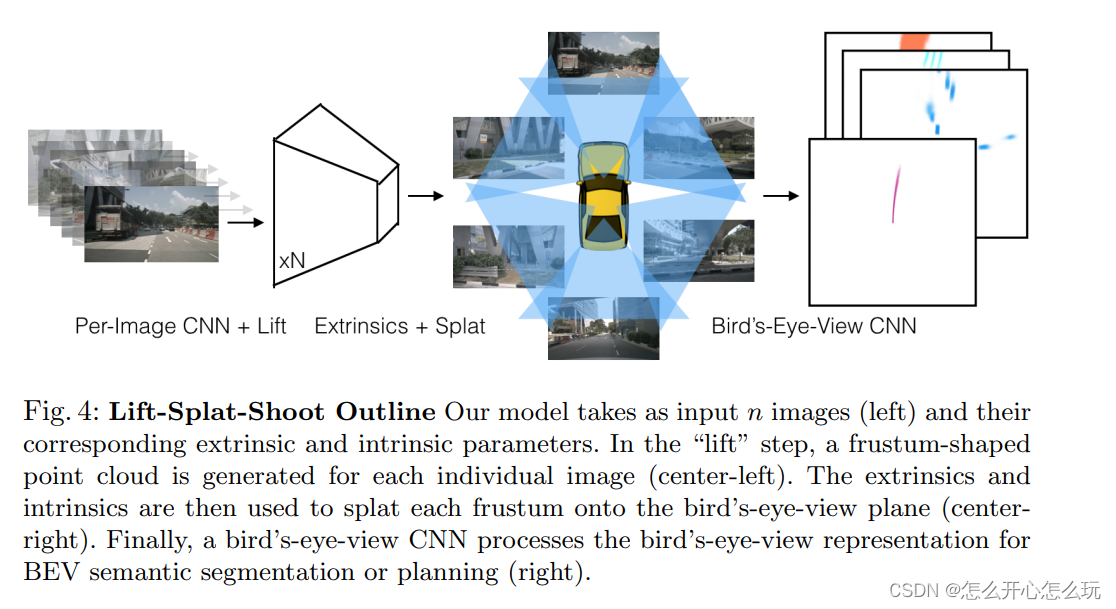
The author proposed the "lift-splat" method to ensure the above three symmetry points, but can achieve end-to-end training model. "Lift" is to map Images to 3D space by generating a cross-section; "splat" is to map all cross-sections to the same plane to facilitate downstream motion planning; "shooting" is to map the predicted trajectory to With reference to the plane, an interpretable motion plan can be obtained.
3 Method
The author proposes to fuse multiple image data from the BEV perspective and saves the above three advantages. The author uses the camera's intrinsic parameter matrix and extrinsic parameter matrix to map the reference coordinates (x, y, z) to the pixel coordinates (h, w, d).
3.1 Lift: Latent Depth Distribution
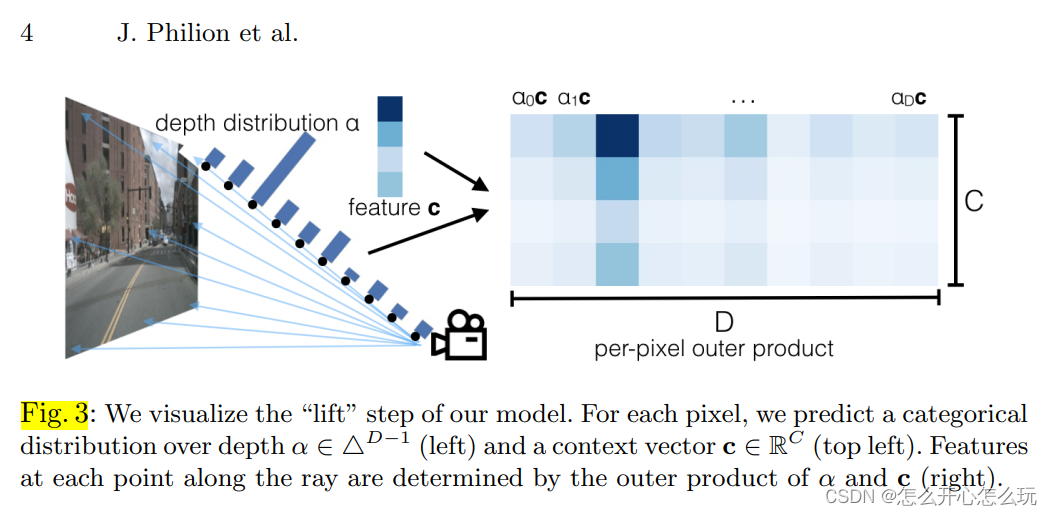
The author first generates a cross-section based on the image, and discretizes the cross-section into |D| points in the depth direction,
For each voxel (h, w) in the image The corresponding feature c can be found on (c is the context feature that has been extracted). Since each voxel (h, w) has |D| points corresponding to it, a |D| - 1-dimensional Vector α, used to represent the feature vector of position d in the same voxel (h, w):

3.2 Splat: Pillar Pooling
First, use internal and external parameters to convert the 3D points obtained by "lift" into the BEV plane, and then use pointpilliar to convert the converted points into featuremaps under bev using sum pooling to implement discrete convolution on discrete matrices.
4 Implementation
4.2 Prism Pooling Cumulative Sum Techniques
This technique is based on the fact that the shape of the point cloud generated by the image is fixed, so each point can be pre-assigned an interval (i.e. BEV grid) index to indicate which interval it belongs to. After sorting by index, do the following:
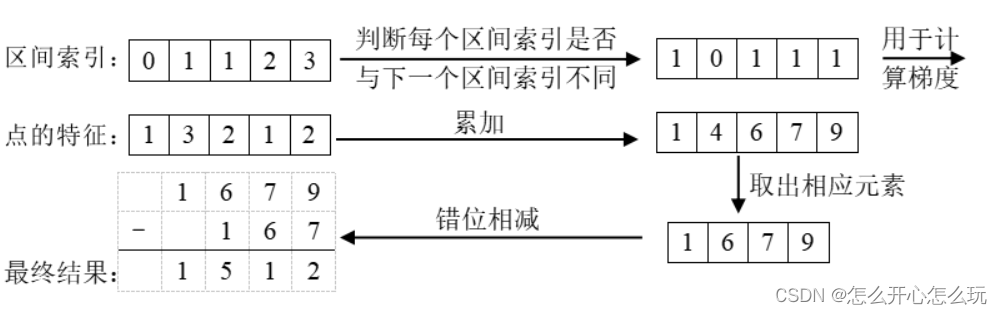
You can speed up training by calculating the analytic gradient of the algorithm instead of using automatic gradient calculation. This method is called "edge pooling".
5 Experiments and results