Article directory

Thoughts triggered by the interview question "Is Redis single-threaded?"
Author: Li Le
Source: IT Reading Ranking
Many people have encountered such an interview question: Is Redis single-threaded or multi-threaded? This question is both simple and complex. It is said to be simple because most people know that Redis is single-threaded, and it is said to be complex because the answer is actually inaccurate.
Isn't Redis single-threaded? We start a Redis instance and verify it. The Redis installation and deployment method is as follows:
// 下载
wget https://download.redis.io/redis-stable.tar.gz
tar -xzvf redis-stable.tar.gz
// 编译安装
cd redis-stable
make
// 验证是否安装成功
./src/redis-server -v
Redis server v=7.2.4
Next, start the Redis instance and use the command ps to view all threads, as shown below:
// 启动Redis实例
./src/redis-server ./redis.conf
// 查看实例进程ID
ps aux | grep redis
root 385806 0.0 0.0 245472 11200 pts/2 Sl+ 17:32 0:00 ./src/redis-server 127.0.0.1:6379
// 查看所有线程
ps -L -p 385806
PID LWP TTY TIME CMD
385806 385806 pts/2 00:00:00 redis-server
385806 385809 pts/2 00:00:00 bio_close_file
385806 385810 pts/2 00:00:00 bio_aof
385806 385811 pts/2 00:00:00 bio_lazy_free
385806 385812 pts/2 00:00:00 jemalloc_bg_thd
385806 385813 pts/2 00:00:00 jemalloc_bg_thd
There are actually 6 threads! Isn’t it said that Redis is single-threaded? Why are there so many threads?
You may not understand the meaning of these six threads, but this example at least shows that Redis is not single-threaded.
01 Multithreading in Redis
Next, we introduce the functions of the above 6 threads one by one:
1)redis-server:
The main thread is used to receive and process client requests.
2)jemalloc_bg_thd
jemalloc is a new generation of memory allocator, which is used by the bottom layer of Redis to manage memory.
3)bio_xxx:
Those starting with the bio prefix are all asynchronous threads, used to perform some time-consuming tasks asynchronously. Among them, thread bio_close_file is used to asynchronously delete files, thread bio_aof is used to asynchronously flush AOF files to disk, and thread bio_lazy_free is used to asynchronously delete data (lazy deletion).
It should be noted that the main thread distributes tasks to asynchronous threads through the queue, and this operation requires locking. The relationship between the main thread and the asynchronous thread is as shown in the figure below:
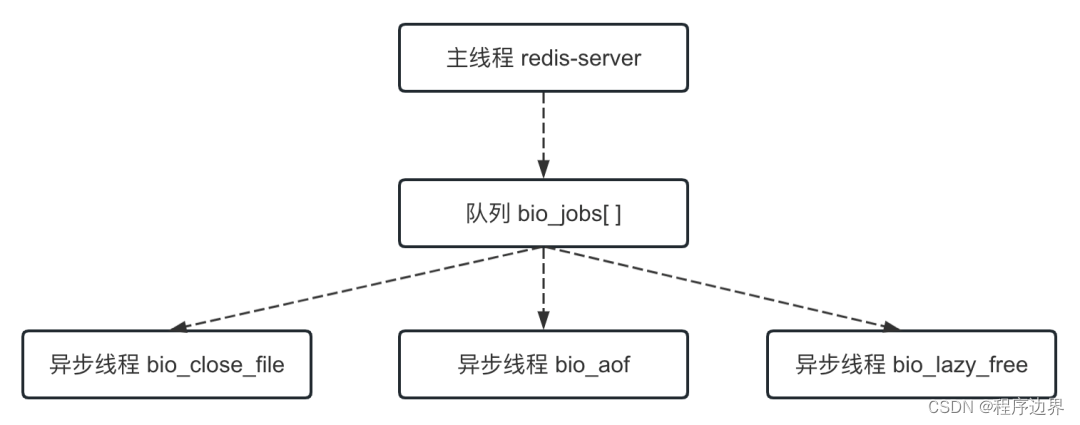
Main thread and asynchronous thread Main thread and asynchronous threadMain thread and asynchronous thread
Here we take lazy deletion as an example to explain why asynchronous thread should be used. Redis is an in-memory database that supports multiple data types, including strings, lists, hash tables, sets, etc. Think about it, what is the process of deleting (DEL) list type data? The first step is to delete the key-value pair from the database dictionary, and the second step is to traverse and delete all elements in the list (freeing memory). Think about what if the number of elements in the list is very large? This step will be very time consuming. This deletion method is called synchronous deletion, and the process is as shown in the figure below:
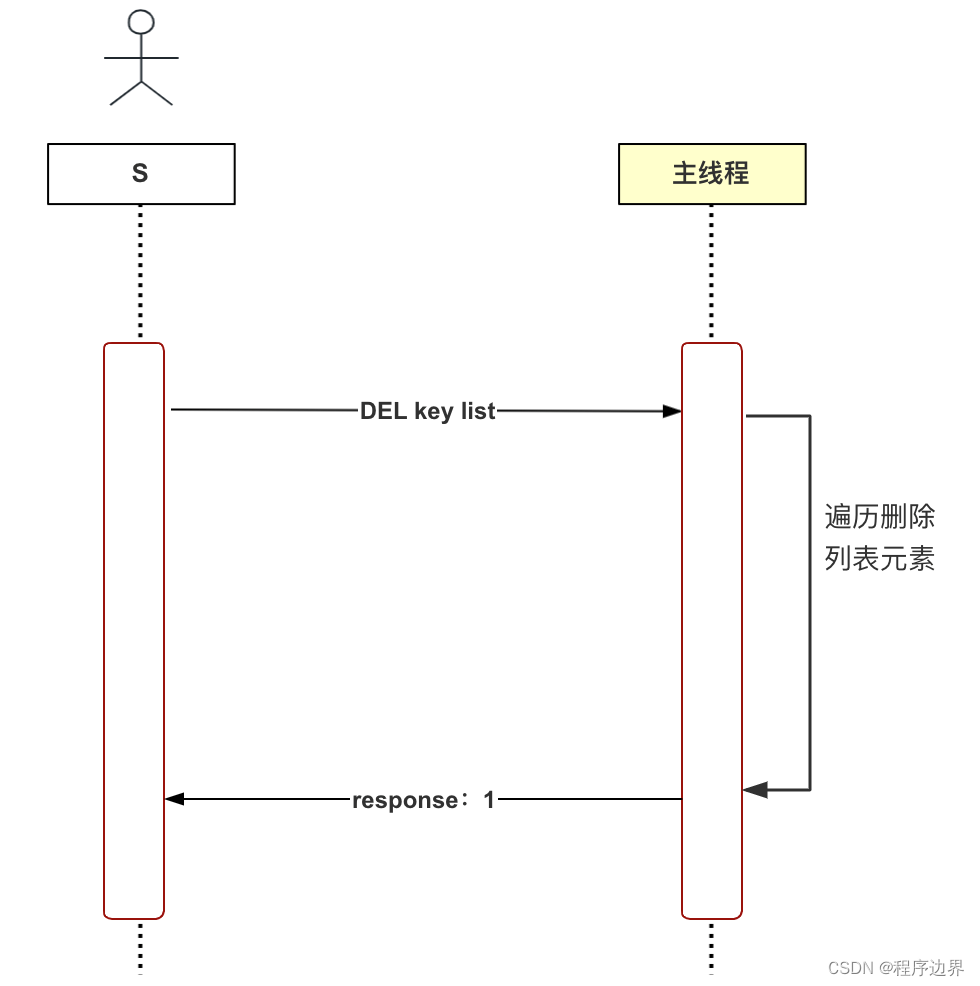
Synchronous deletion flow chart Synchronous deletion flow chartSynchronous deletion flow chart
In response to the above problems, Redis proposed lazy deletion (asynchronous deletion). When the main thread receives the deletion command (UNLINK), it first deletes the key-value pair from the database dictionary, and then distributes the deletion task to the asynchronous thread. bio_lazy_free, the second step of time-consuming logic is executed by the asynchronous thread. The process at this time is shown below:
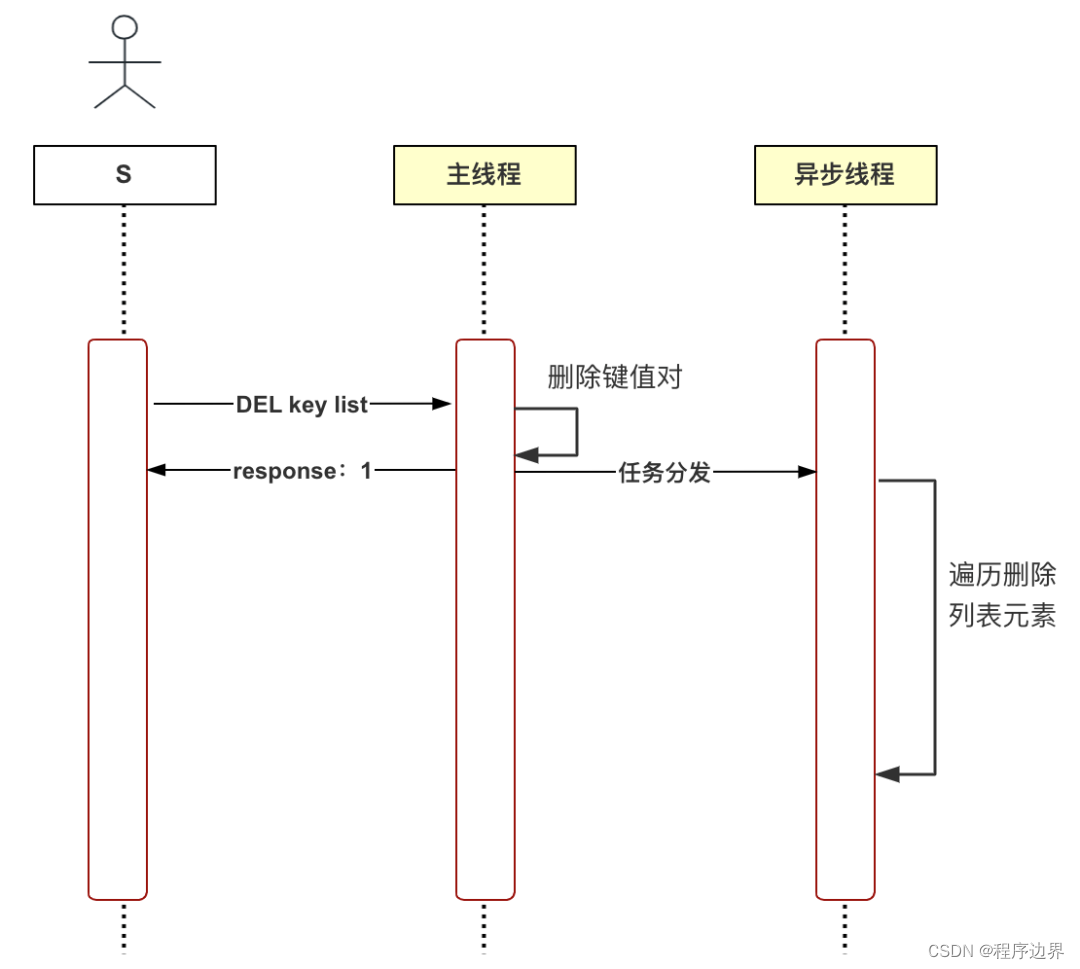
Lazy deletion flow chart Lazy deletion flow chartLazy deletion flow chart
02 I/O multi-threading
Is Redis multi-threaded? So why do we always say that Redis is single-threaded? This is because reading client command requests, executing commands, and returning results to the client are all completed in the main thread. Otherwise, if multiple threads operate the in-memory database at the same time, how to solve the concurrency problem? If a lock is locked before each operation, what is the difference between it and a single thread?
Of course, this process has also changed in the Redis 6.0 version. Redis officials pointed out that Redis is a memory-based key-value database. The process of executing commands is very fast. It reads the client command request and returns the results to the client ( That is, network I/O) usually becomes the performance bottleneck of Redis.
Therefore, in the Redis 6.0 version, the author added the capability of multi-threaded I/O, that is, multiple I/O threads can be opened, client command requests can be read in parallel, and results can be returned to the client in parallel. I/O multi-threading capability at least doubles the performance of Redis.
In order to enable multi-threaded I/O capability, you need to modify the configuration file redis.conf first:
io-threads-do-reads yes
io-threads 4
The meanings of these two configurations are as follows:
-
io-threads-do-reads: Whether to enable multi-threaded I/O capability, the default is "no";
-
io-threads: The number of I/O threads, the default is 1, that is, only the main thread is used to perform network I/O, and the maximum number of threads is 128; this configuration should be set according to the number of CPU cores. The author recommends setting 2~3 for a 4-core CPU I/O threads, 8-core CPU sets 6 I/O threads.
After turning on the multi-threaded I/O capability, restart the Redis instance and view all threads. The results are as follows:
ps -L -p 104648
PID LWP TTY TIME CMD
104648 104648 pts/1 00:00:00 redis-server
104648 104654 pts/1 00:00:00 io_thd_1
104648 104655 pts/1 00:00:00 io_thd_2
104648 104656 pts/1 00:00:00 io_thd_3
……
Since we set io-threads equal to 4, 4 threads will be created to perform I/O operations (including the main thread). The above results are in line with expectations.
Of course, only the I/O phase uses multi-threading, and processing command requests is still a single-thread. After all, there are concurrency issues in multi-threaded operations of memory data.
Finally, after I/O multi-threading is enabled, the command execution flow is as shown below:
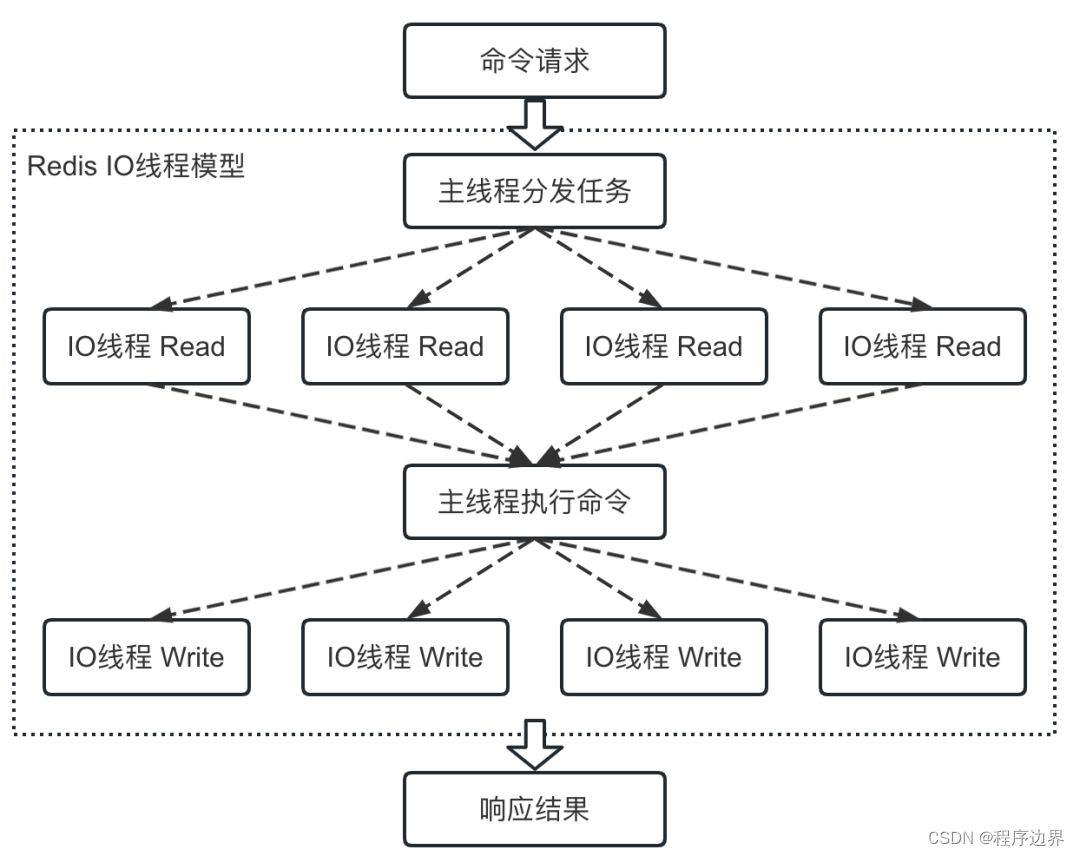
I/O multi-thread flow chart I/O multi-thread flow chartI / O multithreading flow chart
03 Multi-process in Redis
Does Redis have multiple processes? Yes. In some scenarios, Redis will also create multiple sub-processes to perform some tasks. Taking persistence as an example, Redis supports two types of persistence:
-
AOF (Append Only File): It can be regarded as a log file of commands. Redis will append each write command to the AOF file.
-
RDB (Redis Database): stores data in Redis memory in the form of snapshots. The command SAVE is used to manually trigger RDB persistence. Think about it if the amount of data in Redis is very large, the persistence operation must take a long time, and Redis processes command requests in a single thread, so when the execution time of the SAVE command is too long, it will inevitably affect the execution of other commands.
The SAVE command may block other requests. For this reason, Redis has introduced the command BGSAVE, which will create a sub-process to perform persistence operations, so that it will not affect the main process from executing other requests.
We can manually execute the command BGSAVE to verify. First, use GDB to track the Redis process, add breakpoints, and let the child process block in the persistence logic. As follows:
// 查询Redis进程ID
ps aux | grep redis
root 448144 0.1 0.0 270060 11520 pts/1 tl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
// GDB跟踪进程
gdb -p 448144
// 跟踪创建的子进程(默认GDB只跟踪主进程,需手动设置)
(gdb) set follow-fork-mode child
// 函数rdbSaveDb用于持久化数据快照
(gdb) b rdbSaveDb
Breakpoint 1 at 0x541a10: file rdb.c, line 1300.
(gdb) c
After setting the breakpoint, use the Redis client to send the command BGSAVE. The results are as follows:
// 请求立即返回
127.0.0.1:6379> bgsave
Background saving started
// GDB输出以下信息
[New process 452541]
Breakpoint 1, rdbSaveDb (...) at rdb.c:1300
As you can see, GDB is currently tracking the child process, and the process ID is 452541. You can also view all processes through the Linux command ps. The results are as follows:
ps aux | grep redis
root 448144 0.0 0.0 270060 11520 pts/1 Sl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
root 452541 0.0 0.0 270064 11412 pts/1 t+ 17:19 0:00 redis-rdb-bgsave 127.0.0.1:6379
You can see that the name of the child process is redis-rdb-bgsave, which means that this process persists snapshots of all data in RDB files.
Finally, consider two questions.
- Question 1: Why use sub-process instead of sub-thread?
Because RDB stores data snapshots persistently, if sub-threads are used, the main thread and sub-threads will share memory data. The main thread will also modify the memory data while persisting, which may lead to data inconsistency. The memory data of the main process and the child process are completely isolated, and this problem does not exist.
- Question 2: Assume that 10GB of data is stored in Redis memory. After creating a child process to perform persistence operations, does the child process also need 10GB of memory at this time? Copying 10GB of memory data will be time-consuming, right? In addition, if the system only has 15GB of memory, can the BGSAVE command still be executed?
There is a concept here called copy on write. After using the fork system call to create a child process, the memory data of the main process and the child process are temporarily shared, but when the main process needs to modify the memory data, the system will automatically Make a copy of this memory block to achieve isolation of memory data.
The execution flow of the command BGSAVE is shown in the figure below:
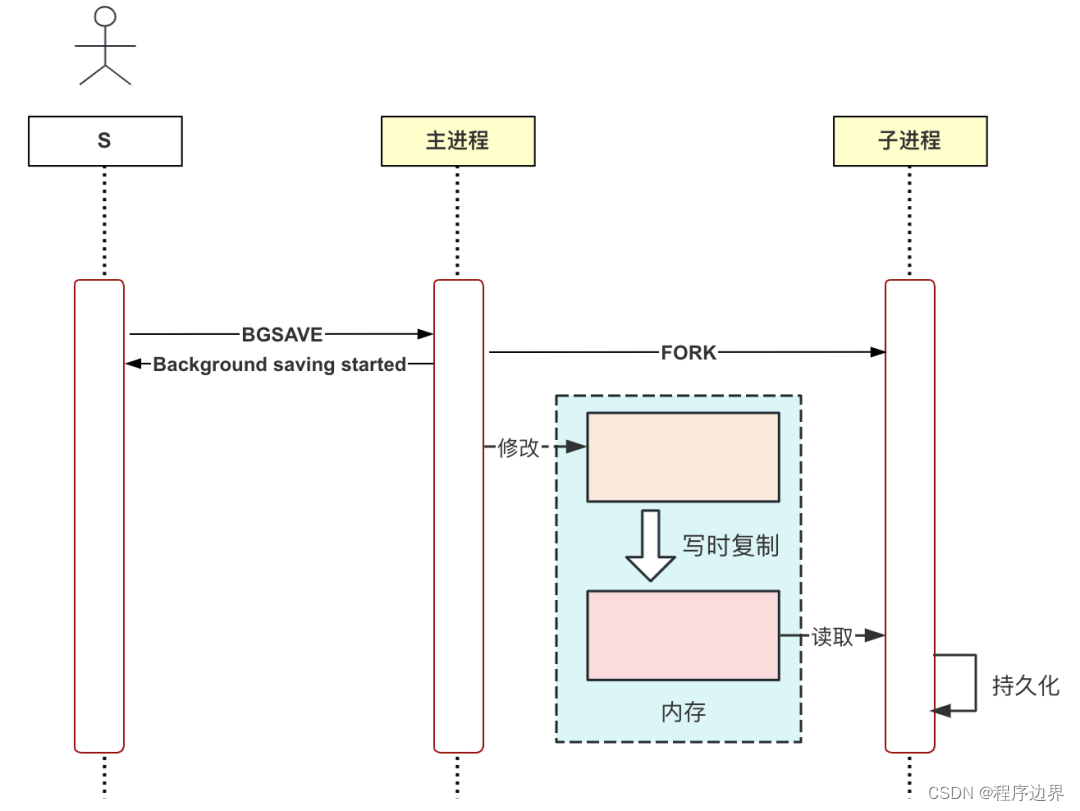
BGSAVE execution process BGSAVE execution processBGS A V E execution process
04 Conclusion
The process model/threading model of Redis is still relatively complex. Here we only briefly introduce multi-threading and multi-processing in some scenarios. Multi-threading and multi-processing in other scenarios have yet to be studied by the readers themselves.
作者介绍
李乐:好未来Golang开发专家、西安电子科技大学硕士,曾就职于滴滴,乐于钻研技术与源码,合著有《高效使用Redis:一书学透数据存储与高可用集群》《Redis5设计与源码分析》《Nginx底层设计与源码分析》。
▼Extended reading

"Using Redis Efficiently: Learn Data Storage and High-Availability Clusters in One Book" "Using Redis Efficiently: Learn Data Storage and High-Availability Clusters in One Book""Using Redis Efficiently : Learn Data Storage and High- Availability Clusters in One Book "
Recommended words: Go deep into the Redis data structure and underlying implementation, and overcome the problems of Redis data storage and cluster management.