
Since the emergence of ChatGPT at the end of 2022, artificial intelligence has once again become the focus of the world, and AI based on large language models (LLM) has become a "hot chicken" in the field of artificial intelligence. In the year since then, we have witnessed the rapid progress of AI in the fields of Wensheng text and Wensheng pictures, but the development in the field of Wensheng video has been relatively slow. At the beginning of 2024, OpenAI once again released a blockbuster - Vincent's video model Sora. The last piece of the content creation puzzle was completed by AI.
A year ago, a video of Smith eating noodles went viral on social media. In the picture, the actor had a hideous face, deformed facial features, and was eating spaghetti in a twisted posture. This terrible picture reminds us that the technology of AI-generated video was just in its infancy at the time.

Just a year later, an AI video of "fashionable women walking on the streets of Tokyo" generated by Sora once again set social media ablaze. In the following March, Sora joined forces with artists from all over the world to officially launch a series of surreal art short films that subverted tradition. The following short film "Air Head" was created by the famous director Walter and Sora. The picture is exquisite and lifelike, and the content is wild and imaginative. It can be said that Sora "crushed" mainstream AI video models such as Gen-2, Pika, and Stable Video Diffusion when it debuted.

The evolution of AI is far faster than expected. We can easily foresee that the existing industrial structure, including short videos, games, film and television, advertising, etc., will be reshaped in the near future. Sora's arrival seems to bring us one step closer to a model for world building.
Why does Sora have such powerful magic? What magical technologies does it use? After reviewing the official technical report and many related documents, the author will explain the technical principles behind Sora and the key to its success in this article.
1 What core problem does Sora want to solve?
To sum up in one sentence, the challenge Sora faces is how to transform multiple types of visual data into a unified representation method so that unified training can be performed.
Why do we need unified training? Before answering this question, let's first take a look at Sora's previous mainstream AI video generation ideas.
1.1 AI video generation method in the pre-Sora era
- Expand based on single frame image content
Extensions based on single-frame images use the content of the current frame to predict the next frame. Each frame is a continuation of the previous frame, thus forming a continuous video stream (the essence of video is an image displayed continuously frame by frame).
In this process, text descriptions are generally used to generate images, and then videos are generated based on the images. However, there is a problem with this idea: using text to generate images itself is random. This randomness is amplified twice when using images to generate videos, and the controllability and stability of the final video are very low.
- Train directly on the entire video
Since the video effect based on single frame derivation is not good, then the idea is changed to training the entire video.
Here, a video clip of a few seconds is usually selected and the model is told what the video shows. After a lot of training, the AI can learn to generate video clips that are similar in style to the training data. The flaw of this idea is that the content learned by AI is fragmented, it is difficult to generate long videos, and the continuity of the videos is poor.
Some people may ask, why not use longer videos for training? The main reason is that videos are very large compared to text and pictures, and the graphics card has limited video memory and cannot support longer video training. Under various restrictions, the amount of knowledge of AI is extremely limited. When inputting content that it “does not know”, the generated results are often unsatisfactory.
Therefore, if you want to break through the bottleneck of AI video, you must solve these core problems.
1.2 Challenges in video model training
Video data comes in various forms, from horizontal screen to vertical screen, from 240p to 4K, different aspect ratios, different resolutions, and different video attributes. The complexity and diversity of data brings great difficulties to AI training, which in turn leads to poor model performance. This is why these video data must be represented in a unified manner first.
The core task of Sora is to find a way to convert multiple types of visual data into a unified representation method so that all video data can be effectively trained under a unified framework.
1.3 Sora: Milestones towards AGI
Our mission is to ensure that artificial general intelligence benefits all of humanity. —— OpenAI
OpenAI's goal has always been clear-to achieve artificial general intelligence (AGI), so what significance does the birth of Sora have in achieving OpenAI's goal?
To implement AGI, the large model must understand the world. Throughout the development of OpenAI, the initial GPT model allowed AI to understand text (one dimension, only length), and the subsequently launched DALL·E model allowed AI to understand images (two dimensions, length and width), and now The Sora model allows AI to understand video (three-dimensional, length, width and time).
Through comprehensive understanding of text, images, and videos, AI can gradually understand the world. Sora is OpenAI's outpost to AGI. It is more than just a video generation model, as the title of its technical report [1] says: "A video generation model as a world simulator."
The vision of Tuoshupai coincides with the goal of OpenAI. The extensionists believe that using a small number of symbols and computational models to model human society and individual intelligence laid the foundation for early AI, but more dividends depend on larger amounts of data and higher computing power. When we cannot build a groundbreaking new model, we can look for more data sets and use greater computing power to improve the accuracy of the model, exchange data computing power for model power, and drive innovation in data computing systems. In the large-model data computing system released by Tuoshupai, AI mathematical models, data and calculations will be seamlessly connected and mutually reinforcing like never before, becoming a new productive force that promotes high-quality development of society [2].
2 Sora principle interpretation
Sora isn't the first Vincent video model to be released, so why is it causing such a stir? What's the secret behind it? If you describe Sora's training process in one sentence: the original video is compressed into latent space through a visual encoder and decomposed into spacetime patches, which are combined with text Conditional constraints are used to perform diffusion training and generation through the transformer. The generated spatiotemporal image blocks are finally mapped back to the pixel space through the corresponding visual decoder.
2.1 Video compression network
Sora first converts raw video data into low-dimensional latent space features. The video data we watch every day is too large, and it must first be converted into low-dimensional vectors that AI can process. Here, OpenAI draws on a classic paper: Latent Diffusion Models[3].
The core point of this paper is to refine the original image into a latent space feature, which can not only retain the key feature information of the original image, but also greatly compress the amount of data and information.
OpenAI is likely to have upgraded the variational autoencoder (VAE) for images in this paper to support the processing of video data. In this way, Sora can convert a large amount of original video data into low-dimensional latent space features, that is, extract the core key information in the video, which can represent the key content of the video.
2.2 Spacetime Patches
To conduct large-scale AI video training, the basic unit of training data must first be defined. In the large language model (LLM), the basic unit of training is Token[4]. OpenAI draws inspiration from the success of ChatGPT: the Token mechanism elegantly unifies different forms of text—code, mathematical symbols, and various natural languages. Can Sora find its “Token”?
Thanks to previous research results, Sora finally found the answer - Patch.
- Vision Transformer(ViT)
What is a patch? Patch can be understood colloquially as an image block. When the resolution of the image to be processed is too large, direct training is not practical. Therefore, a method is proposed in the paper Vision Transformer [5]: split the original image into image blocks (Patch) of the same size, and then serialize these image blocks and add their position information ( Position Embedding), so that complex images can be converted into the most familiar sequences in the Transformer architecture, using the self-attention mechanism to capture the relationship between each image block, and ultimately understand the content of the entire image.
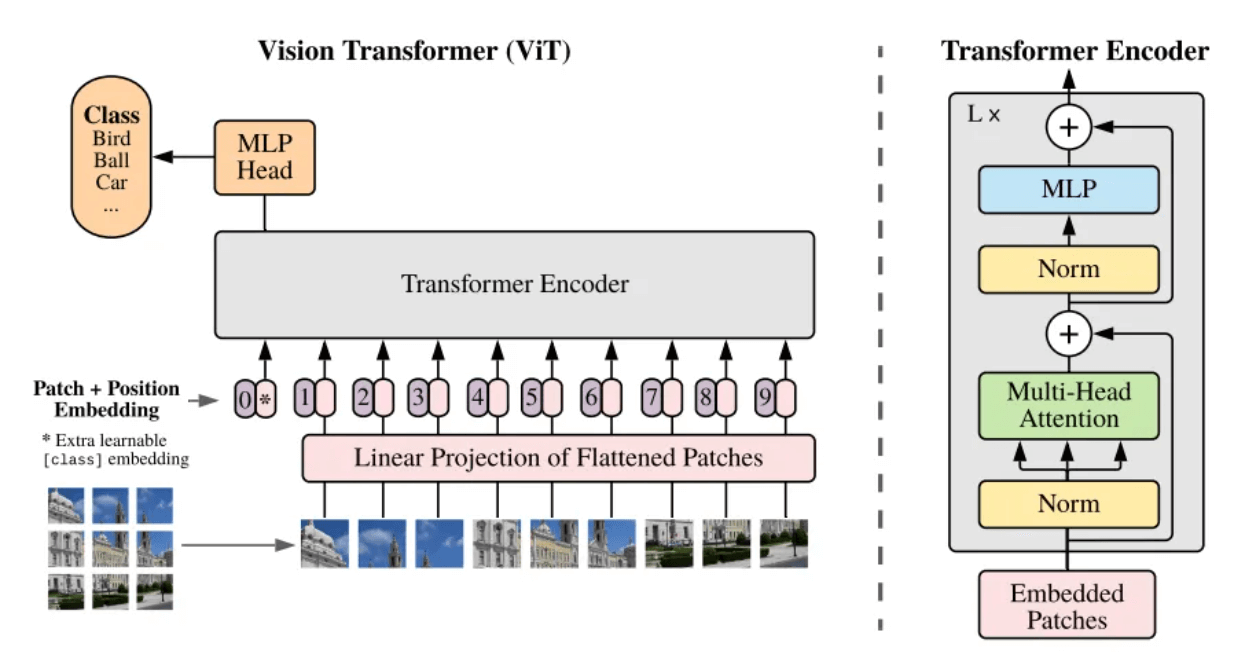
Framework structure of ViT model[5]
Video can be seen as a sequence of images distributed along the time axis, so Sora adds the dimension of time, upgrading static image blocks into spacetime image patches (Spacetime Patches). Each spatio-temporal image block contains both temporal information and spatial information in the video. That is, a spatio-temporal image block not only represents a small spatial area in the video, but also represents the changes in this spatial area over a period of time.
By introducing the concept of patch, the spatial correlation can be calculated for spatio-temporal image blocks at different positions in a single frame; the temporal correlation can be calculated for spatio-temporal image blocks at the same position in consecutive frames. Each image block no longer exists in isolation, but is closely connected with surrounding elements. In this way, Sora is able to understand and generate video content with rich spatial details and temporal dynamics.

Decompose sequence frames into spatiotemporal image blocks
- Native Resolution(NaViT)
However, the ViT model has a very big disadvantage - the original image must be square and each image block has the same fixed size. Daily videos are only wide or tall, and there are no square videos.
Therefore, OpenAI found another solution: the "Patch n' Pack" technology [6] in NaViT , which can process input content of any resolution and aspect ratio.
This technology splits content with different aspect ratios and resolutions into image blocks. These image blocks can be resized according to different needs. Image blocks from different images can be flexibly packaged in the same sequence for unified training. In addition, this technology can also discard identical image blocks based on the similarity of the images, significantly reducing the cost of training and achieving faster training.
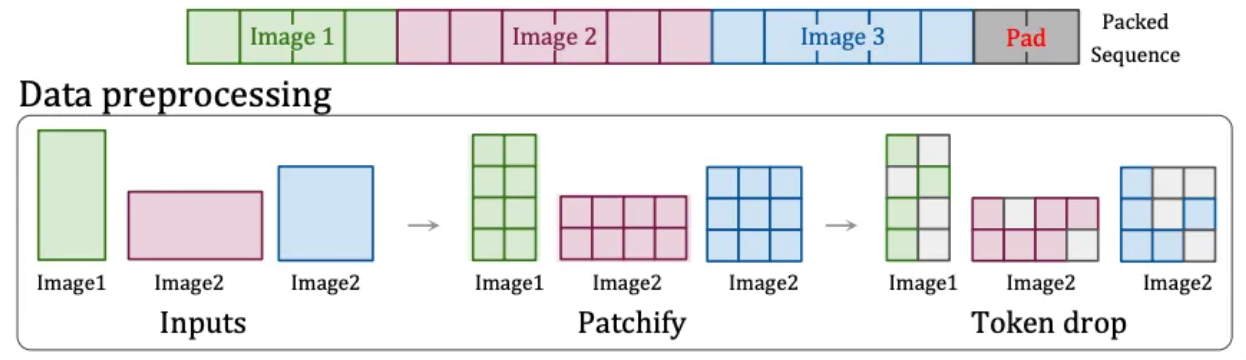
Patch n'Pack Technology[6]
This is why Sora can support generating videos of different resolutions and aspect ratios. Moreover, training with the native aspect ratio can improve the composition and framing of the output video, because cropping will inevitably lose information, and the model will easily misunderstand the main content of the original image, resulting in a picture with only part of the main body.
The role played by Spacetime Patches is the same as the role of Token in the large language model. It is the basic unit of video. When we compress and decompose a video into a series of spatiotemporal patches, we actually convert the continuous visual information into A series of discrete units that can be processed by the model, which are the basis for model learning and generation.
2.3 Video text description
Through the above explanation, we have understood the process of Sora converting original videos into final trainable spatio-temporal vectors. But there is one problem that needs to be solved before actual training: telling the model what this video is about.
To train a Wensheng video model, it is necessary to establish a correspondence between text and video . During training, a large number of videos with corresponding text descriptions are required. However, the quality of manually annotated descriptions is low and irregular, which affects the training results. Therefore, OpenAI borrowed the re-captioning technology [7] from its own DALL·E 3 and applied it to the video field.
Specifically, OpenAI first trained a highly descriptive subtitle generation model, and used this model to generate detailed description information for all videos in the training set according to specifications. This part of the text description information was combined with the previously mentioned spatiotemporal image patches during final training. After matching and training, Sora can understand and correspond to the text description and video image blocks.
In addition, OpenAI will also use GPT to convert the user's brief prompts into more detailed description sentences similar to those during training, which allows Sora to accurately follow the user's prompts and generate high-quality videos.
2.4 Video training and generation
It is clearly mentioned in the official technical report [1] that Sora is a diffusion transformer, that is, Sora is a Diffusion model with Transformer as the backbone network.
- Broadcast Transformer(DiT)
The concept of Diffusion comes from the diffusion process in physics. For example, when a drop of ink is dropped into water, it will slowly spread over time. This diffusion is the process from low entropy to high entropy. You will see that the ink will gradually disperse from one drop to Various parts of water.
Inspired by this diffusion process, the Diffusion Model was born. It is a classic "drawing" model on which Stable Diffusion and Midjourney are based. Its basic principle is to gradually add noise to the original image, allowing it to gradually become a complete noise state, and then reverse this process, that is, denoising (Denoise) to restore the image. By letting the model learn a large number of reversal experiences, the model eventually learns to generate specific image content from the noise image.
According to the report, Sora's method is likely to replace the U-Net architecture in the original Diffusion model with the Transformer architecture that he is most familiar with. Because according to experience in other deep learning tasks, compared with U-Net, the parameters of the Transformer architecture are highly scalable. As the number of parameters increases, the performance improvement of the Transformer architecture will be more obvious.
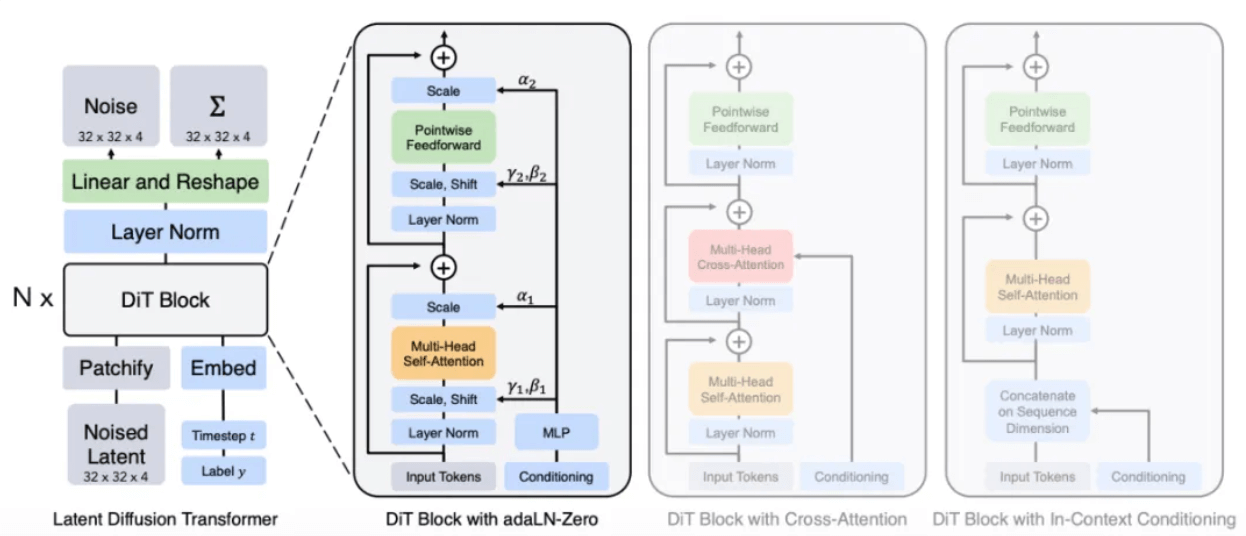
DiT model architecture[8]
Through a process similar to the diffusion model, noise Patches (and conditional information such as text prompts) are given during training, and noise is added and denoised repeatedly, and finally the model learns to predict the original Patches.

Restore the noise patch to the original image patch
- Video generation process
Finally, we summarize the entire process of Sora generating videos from text.
When the user inputs a text description, Sora will first call the model to expand it into a standard video description sentence, and then generate an initial spatio-temporal image block from the noise based on the description. Then Sora will continue to generate the video based on the existing spatio-temporal image block and text conditions. The next spatio-temporal image block is speculated to be generated (similar to GPT predicting the next Token based on the existing Token), and finally the generated potential representation is mapped back to the pixel space through the corresponding decoder to form a video.
3 The potential of data computing
Looking at Sora's technical report, we can find that in fact Sora has not achieved a major breakthrough in technology, but has well integrated previous research work. After all, no technology will suddenly appear from a corner. Come. The more critical reason for Sora’s success is the accumulation of computing power and data.
Sora 在训练过程中表现出明显的规模效应,下图展现了对于固定的输入和种子,随着计算量的增加,生成的样本质量显著提升。

Comparison of effects under basic computing power, 4 times computing power and 32 times computing power
In addition, by learning from large amounts of data, Sora also demonstrated some unexpected abilities.
➢ 3D consistency: Sora is able to generate videos with dynamic camera movements. As the camera moves and rotates, characters and scene elements always maintain consistent movement patterns in the three-dimensional space.
➢Long -term consistency and object persistence: In long shots, people, animals and objects maintain a consistent appearance even after they are occluded or leave the frame.
➢World interactivity: Sora can simulate behaviors that affect the state of the world in a simple way. For example, in the video describing painting, each stroke leaves a mark on the canvas.
➢Simulate the digital world: Sora can also simulate game videos, such as "Minecraft".
These properties do not require an explicit inductive bias to 3D objects, etc., they are purely a phenomenon of scale effects.
4 Tuoshupai large model data computing system
The success of Sora once again proves the effectiveness of the "bigger power makes miracles" strategy - the continuous expansion of model scale will directly promote the improvement of performance, which is highly dependent on a large number of high-quality data sets and ultra-large-scale computing power. Data and computing are indispensable. No.
At the beginning of its establishment, Tuoshupai positioned its mission as "data computing, only for new discoveries", and our goal is to create an "infinite model game". Its large model data computing system uses cloud-native technology to reconstruct data storage and computing, with one storage and multi-engine data computing, making AI models larger and faster, and comprehensively upgrading the big data system to the era of large models.
In the large-model data computing system, everything in the world and its movements can be digitized into data. The data can be used to train the initial model. The trained model forms calculation rules and is then added to the data computing system. This process continues to iterate and infinitely explore AI intelligence. In the future, Tuoshupai will continue to explore in the field of data, strengthen core technology research capabilities, work with industry partners to explore best practices in the data element industry, and promote digital intelligent decision-making.
Note: The official technical report from OpenAI only shows the general modeling method and does not involve any implementation details. If there are any errors in this article, please correct me and communicate with me.
references:
- [1] Video Generation Models as World Simulators
- [2] Large model data computing system - theory
- [3] High-Resolution Image Synthesis with Latent Diffusion Models
- [4] Attention Is All You Need
- [5] An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale
- [6] Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
- [7] Improving Image Generation with Better Captions
- [8] Scalable Diffusion Models with Transformers