Registro segmentado
Divida archivos grandes en varios archivos más pequeños que sean más fáciles de manejar.
Antecedentes del problema
Un solo archivo de registro puede crecer hasta un tamaño grande y ser leído cuando se inicia el programa, convirtiéndose así en un cuello de botella de rendimiento. Los troncos viejos deben limpiarse con regularidad, pero limpiar un archivo grande es muy laborioso.
solución
Divida un solo registro en varios, y cuando el registro alcance un cierto tamaño, cambiará a un nuevo archivo para continuar escribiendo.
//写入日志
public Long writeEntry(WALEntry entry) {
//判断是否需要另起新文件
maybeRoll();
//写入文件
return openSegment.writeEntry(entry);
}
private void maybeRoll() {
//如果当前文件大小超过最大日志文件大小
if (openSegment.
size() >= config.getMaxLogSize()) {
//强制刷盘
openSegment.flush();
//存入保存好的排序好的老日志文件列表
sortedSavedSegments.add(openSegment);
//获取文件最后一个日志id
long lastId = openSegment.getLastLogEntryId();
//根据日志id,另起一个新文件,打开
openSegment = WALSegment.open(lastId, config.getWalDir());
}
}Si el registro está segmentado, se necesita un mecanismo para localizar rápidamente un archivo con una ubicación de registro (o número de secuencia de registro). Se puede conseguir de dos formas:
- El nombre de cada archivo de división de registro contiene un inicio específico y un desplazamiento de posición de registro (o número de secuencia de registro)
- Cada número de secuencia de registro contiene el nombre del archivo y la compensación de la transacción.
//创建文件名称
public static String createFileName(Long startIndex) {
//特定日志前缀_起始位置_日志后缀
return logPrefix + "_" + startIndex + "_" + logSuffix;
}
//从文件名称中提取日志偏移量
public static Long getBaseOffsetFromFileName(String fileName) {
String[] nameAndSuffix = fileName.split(logSuffix);
String[] prefixAndOffset = nameAndSuffix[0].split("_");
if (prefixAndOffset[0].equals(logPrefix))
return Long.parseLong(prefixAndOffset[1]);
return -1l;
}Una vez que el nombre del archivo contiene esta información, la operación de lectura se divide en dos pasos:
- Dado un desplazamiento (o ID de transacción), obtenga el archivo donde el registro es más grande que este desplazamiento
- Leer todos los registros más grandes que este desplazamiento del archivo
//给定偏移量,读取所有日志
public List<WALEntry> readFrom(Long startIndex) {
List<WALSegment> segments = getAllSegmentsContainingLogGreaterThan(startIndex);
return readWalEntriesFrom(startIndex, segments);
}
//给定偏移量,获取所有包含大于这个偏移量的日志文件
private List<WALSegment> getAllSegmentsContainingLogGreaterThan(Long startIndex) {
List<WALSegment> segments = new ArrayList<>();
//Start from the last segment to the first segment with starting offset less than startIndex
//This will get all the segments which have log entries more than the startIndex
for (int i = sortedSavedSegments.size() - 1; i >= 0; i--) {
WALSegment walSegment = sortedSavedSegments.get(i);
segments.add(walSegment);
if (walSegment.getBaseOffset() <= startIndex) {
break; // break for the first segment with baseoffset less than startIndex
}
}
if (openSegment.getBaseOffset() <= startIndex) {
segments.add(openSegment);
}
return segments;
}Por ejemplo
Básicamente, todo el almacenamiento MQ convencional, como RocketMQ, Kafka y el almacenamiento subyacente BookKeeper de Pulsar, utilizan registros segmentados.
RocketMQ: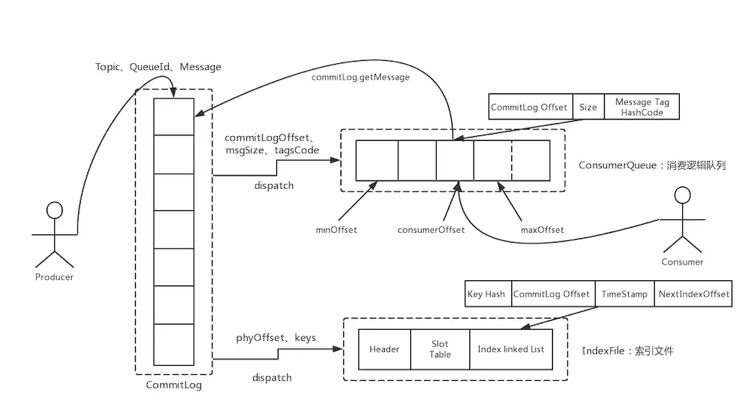
Kafka:
Implementos de almacenamiento de Pulsar BookKeeper: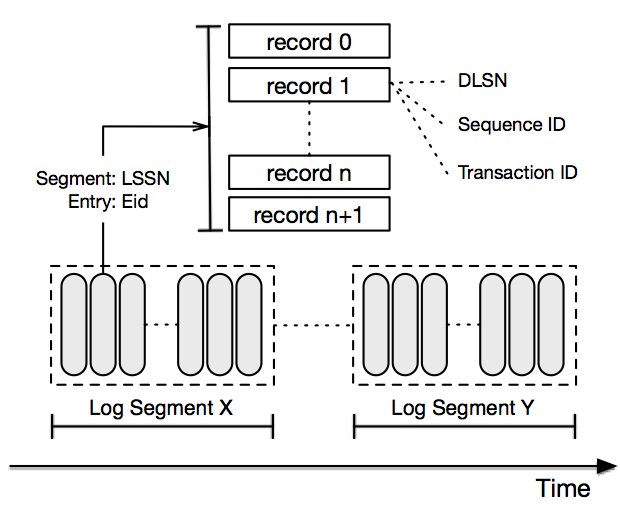
Además, el almacenamiento basado en el protocolo de coherencia Paxos o Raft generalmente utiliza registros segmentados, como Zookeeper y TiDB.
Un deslizamiento todos los días, puede actualizar fácilmente sus habilidades y obtener varias ofertas:
