Estructura de la tabla de la base de datos:
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
select id,name where name='shenjian'
select id,name,sex where name='shenjian'
Se consulta un atributo más, ¿por qué el proceso de recuperación es completamente diferente?
¿Qué es una consulta de devolución de formulario?
¿Qué es la cobertura del índice?
¿Cómo lograr la cobertura del índice?
¿En qué escenarios se puede usar la cobertura de índice para optimizar SQL?
Estos, esto es lo que quiero compartir hoy.
Nota: El experimento de este artículo se basa en MySQL5.6-InnoDB.
1. ¿Qué es una consulta de formulario de devolución?
Esto comienza con la implementación del índice de InnoDB.InnoDB tiene dos tipos de índices:
- índice agrupado
- índice ordinario (índice secundario)
¿Cuál es la diferencia entre un índice agrupado de InnoDB y un índice normal?
Los nodos hoja del índice agrupado de InnoDB almacenan registros de filas. Por lo tanto, InnoDB debe tener un solo índice agrupado:
(1) Si la tabla define una PK, entonces la PK es un índice agrupado;
(2) Si la tabla no define PK, la primera columna única no NULL es un índice agrupado;
(3) De lo contrario, InnoDB creará una identificación de fila oculta como un índice agrupado;
Nota: Por lo tanto, la consulta PK es muy rápida y el registro de fila se encuentra directamente.
Los nodos hoja de un índice común de InnoDB almacenan el valor de la clave principal.
Voz en off: tenga en cuenta que, en lugar de almacenar punteros de encabezado de registro de fila, los nodos de hoja de índice de MyISAM almacenan punteros de registro.
Por ejemplo, tengamos una tabla:
t(id PK, nombre CLAVE, sexo, bandera);
Nota: id es un índice agrupado y nombre es un índice común.
Hay cuatro registros en la tabla:
1, shenjian, metro, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, si
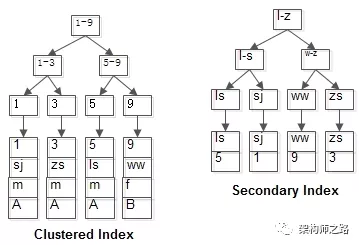
Los dos índices de árbol B+ son los que se muestran arriba:
(1) id es PK, índice agrupado y registros de fila de almacenamiento de nodos hoja;
(2) el nombre es CLAVE, índice común, el nodo hoja almacena el valor PK, es decir, id;
Dado que el registro de fila no se puede ubicar directamente desde el índice ordinario, ¿cuál es el proceso de consulta del índice ordinario?
Por lo general, debe escanear el árbol de índices dos veces.
P.ej:
select * from t where name='lisi';
¿Como funciona?
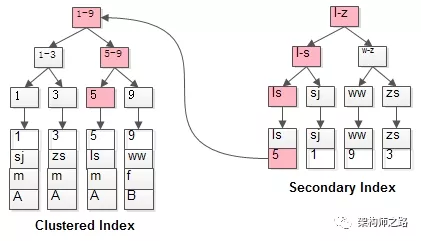
Por ejemplo , la ruta rosa necesita escanear el árbol de índices dos veces:
(1) Primero ubique el valor de la clave primaria id=5 a través del índice ordinario;
(2) Ubique el registro de la fila a través del índice agrupado;
Esta es la llamada consulta de vuelta a la tabla , que localiza primero el valor de la clave principal y luego localiza el registro de la fila. Su rendimiento es menor que escanear el árbol de índice una vez.
En segundo lugar, ¿qué es el índice de cobertura (Índice de cobertura)?
Bueno, no encontré este concepto en el sitio web oficial de MySQL.
Voz en off: ¿Eres riguroso en tus estudios?
Para tomar prestada la declaración del sitio web oficial de SQL-Server.

En el sitio web oficial de MySQL, aparece una declaración similar en el capítulo de optimización del plan de consulta de explicación, es decir, cuando el campo Extra del resultado de salida de explicación es Usar índice , se puede activar la cobertura del índice.

Ya sea el sitio web oficial de SQL-Server o el sitio web oficial de MySQL, se expresa que todos los datos de columna requeridos por SQL se pueden obtener solo en un árbol de índice, sin volver a la tabla, y la velocidad es más rápida.
3. ¿Cómo lograr la cobertura del índice?
El método común es construir el campo que se consultará en el índice conjunto.
Todavía el ejemplo de antes:
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
La primera instrucción SQL:
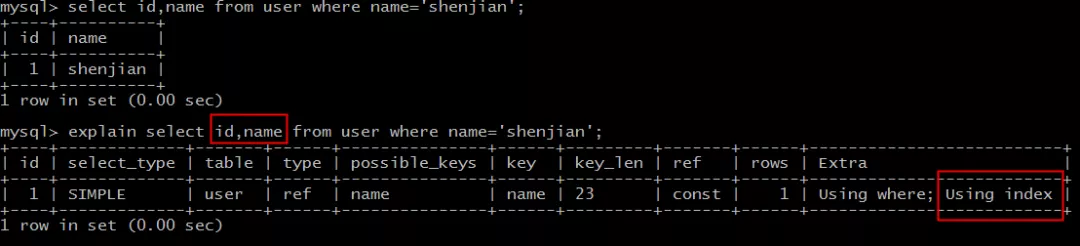
select id,name from user where name='shenjian';
Puede alcanzar el índice de nombre, el nodo de hoja de índice almacena la identificación de clave principal, y la identificación y el nombre se pueden obtener a través del árbol de índice de nombre, sin volver a la tabla, en línea con la cobertura del índice y alta eficiencia.
Voz en off, Extra: Uso de index .
Segunda sentencia SQL:
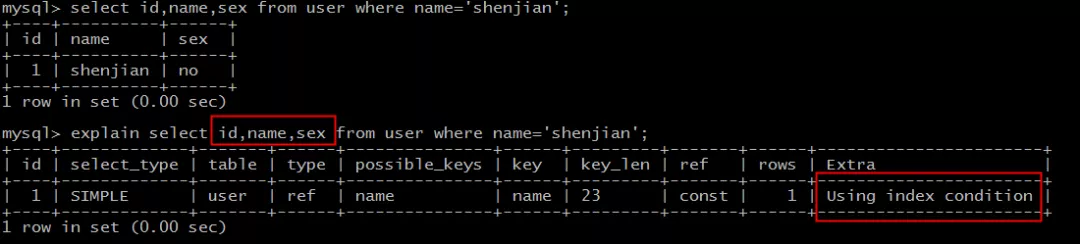
select id,name,sex from user where name='shenjian';
Se puede acceder al índice de nombre y el nodo de hoja del índice almacena la identificación de la clave principal, pero el campo de sexo solo se puede obtener consultando la tabla, que no cumple con la cobertura del índice.
Voz en off, extra: uso de la condición de índice .
Si el índice de una sola columna (nombre) se actualiza a un índice conjunto (nombre, sexo), será diferente.
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name, sex)
)engine=innodb;
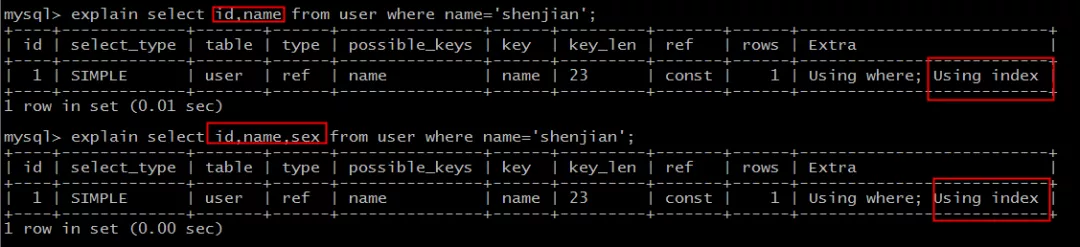
puede ser visto:
select id,name ... where name='shenjian';
select id,name,sex ... where name='shenjian';
Todos pueden alcanzar la cobertura del índice sin volver a la mesa.
Voz en off, Extra: Uso de index .
4. ¿Qué escenarios pueden usar la cobertura de índice para optimizar SQL?
Escenario 1: Optimización de consulta de recuento de tabla completa
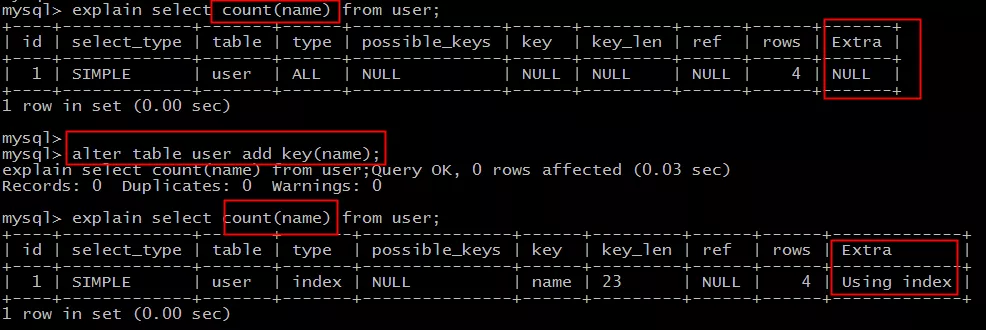
La tabla original es:
usuario (PK id, nombre, sexo);
directo:
select count(name) from user;
No se puede utilizar la cobertura de índice.
Añadir índice:
alter table user add key(name);
Puede utilizar la cobertura de índice para mejorar la eficiencia.
Escenario 2: Optimización de la tabla de retorno de consulta de columna
select id,name,sex ... where name='shenjian';
Este ejemplo no se repetirá aquí. El índice de una sola columna (nombre) se actualiza a un índice conjunto (nombre, sexo) para evitar volver a la tabla.
Escenario 3: consulta de paginación
select id,name,sex ... order by name limit 500,100;
Actualizar un índice de una sola columna (nombre) a un índice conjunto (nombre, sexo) también puede evitar volver a la tabla.
Índice común de índice agrupado de InnoDB , tabla de retorno , cobertura de índice
¿Qué es un índice de cobertura?
## Prólogo
Para comprender un índice de cobertura, primero debe comprender la diferencia entre un índice de clave principal y un índice secundario , y cómo funciona el motor al realizar consultas.
Por supuesto, todo lo anterior se basa en el motor innoDB.
La diferencia entre el índice de clave principal y el índice secundario
Creo que todos también han aprendido sobre este conocimiento, por lo que no lo extenderé aquí, sino que lo resumiré directamente.
índice de clave principal
Los nodos hoja guardan datos
índice secundario
El nodo hoja guarda el valor de la clave principal
¿Cómo funciona la consulta de un dato?
Hablemos primero del proceso de consulta:
Dado que el índice secundario solo almacena el valor de la clave principal, si usa el índice secundario para buscar datos, primero debe obtener el valor de la clave principal del índice secundario y luego usar el valor de la clave principal para consultar en el índice de clave principal hasta que se encuentren y devuelvan los datos en el nodo hoja. ---- Esto también se llama la tabla de retorno
Entonces, ¿cómo evitar las consultas de regreso a la mesa ?
Si los datos que necesitamos ya existen en el índice secundario, entonces el motor no irá a la clave principal para buscar datos. ---- Este es el llamado " índice de cobertura "
A continuación lo demostraremos.
consulta de formulario de devolución
Si existe tal tabla:
CREATE TABLE `test` (
`id` int(11) NOT NULL,
`age` int(11) NOT NULL,
`name` varchar(255) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`age`,`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Agregamos un índice a la edad y luego insertamos algunos datos a voluntad.
insert into test(`id`,`age`,`name`) VALUES(1,10,"小明"),(2,11,"小红"),(3,12,"小伟");
consultar un dato
select * from test where age = 10
Mira la hora

Analiza la oración:
desc select * from test where age = 10
Ver el plan de ejecución:
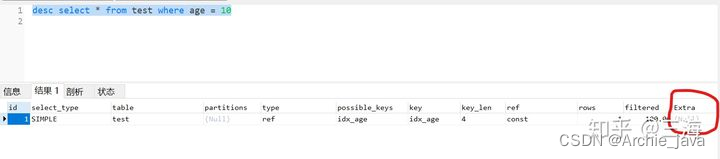
Puede ver que la columna adicional está vacía y la clave usa el índice idx_age. El tiempo de consulta aproximado es de aproximadamente 0.024 segundos.
¿Es tan rápida una consulta?
Dije que puedo optimizarlo de nuevo, ¿puedes creerlo? - Lu Xun (no dije eso)
índice de cobertura
Con solo un ligero cambio en los campos de la consulta, podemos ver la diferencia.
seleccione edad, nombre de la prueba donde edad = 10
Mira cuánto tiempo tomó:

¡Puedes ver que el tiempo se reduce!
Qué pasó, analicemos de nuevo el comunicado
desc select age,name from test where age = 10

Puede ver que la columna adicional tiene un idnex de uso , lo que significa que se usa el índice de cobertura y no es necesario volver a consultar la tabla.
Resumir
La práctica es el único criterio para probar los principios. A través de esta práctica, debe haber entendido y experimentado completamente el concepto y el significado del índice de cobertura. Su núcleo es solo pedir datos de índices auxiliares . Entonces, el índice ordinario (campo único) y el índice conjunto, así como el índice único pueden realizar el papel de índice de cobertura.
# ¿Qué es un índice de cobertura?
- Explicación 1: es decir, la columna de datos de la selección solo se puede obtener del índice y no necesita leerse de la tabla de datos. En otras palabras, la columna de consulta debe estar cubierta por el índice utilizado.
- Explicación 2: Los índices son una forma de encontrar filas de manera eficiente. Cuando los datos deseados se pueden leer recuperando el índice, no hay necesidad de leer filas en la tabla de datos. Si un índice contiene (o cubre) datos que satisfacen los campos y las condiciones de la consulta, se denomina índice de cobertura.
- Explicación 3: es una forma de índice compuesto no agrupado, que incluye todas las columnas utilizadas en las cláusulas Select, Join y Where de la consulta (es decir, el campo indexado es exactamente la declaración de consulta que cubre [cláusula select] y las condiciones de la consulta [Cláusula Where], es decir, el índice contiene todos los datos que busca la consulta). No todos los tipos de índices pueden ser índices cubiertos. El índice de cobertura debe almacenar las columnas indexadas, y el índice hash, el índice espacial y el índice de texto completo no almacenan el valor de la columna indexada, por lo que MySQL solo puede usar el índice B-Tree como índice de cobertura al iniciar una consulta cubierta por el índice (también cuando se llama consulta de cobertura de índice), puede ver la información de "Uso del índice" en la columna Extra de EXPLAIN.
Nota: En los siguientes casos, el plan de ejecución optará por no cubrir la consulta.
- Los campos seleccionados por select contienen campos que no están en el índice, es decir, el índice no cubre todas las columnas.
- La condición where no puede contener una operación similar en el índice.
índice agrupado mysql, índice auxiliar, índice de unión, índice de cobertura
Índice agrupado: solo puede haber uno en una tabla, y el orden del índice agrupado es coherente con el orden de almacenamiento físico real de los datos. La velocidad de consulta es muy rápida. El nodo hoja del índice agrupado contiene todos los datos de la fila. El índice de datos puede acelerar la consulta de rango (el orden del índice agrupado es consistente con el orden lógico del almacenamiento de datos). Clave principal != índice agrupado.
Índice auxiliar (índice no agrupado) : puede haber más de uno en una tabla. El nodo de hoja no almacena una fila completa de datos, sino el valor clave. La fila de índice del nodo de hoja también contiene un 'marcador', que apunta al índice agregado Un puntero a un índice agrupado para encontrar una fila completa de datos en el árbol de índice agrupado.
Índice conjunto : Es un índice compuesto por múltiples columnas. Siga la regla del prefijo más a la izquierda. Válido para dónde, ordenar por, agrupar por.
Índice de cobertura : significa que los registros requeridos se pueden obtener del índice auxiliar sin buscar los registros en el índice agrupado. Una ventaja de usar un índice de cobertura es que debido a que el índice auxiliar no incluye toda la información de la fila de un registro, la cantidad de datos es menor que la del índice agrupado, lo que puede reducir muchas operaciones de E/S.
La diferencia entre un índice agrupado y un índice auxiliar : si el nodo hoja almacena una fila completa de datos
Regla del prefijo más a la izquierda : suponiendo que el índice conjunto consta de columnas (a, b, c), el siguiente orden satisface la regla del prefijo más a la izquierda: a, ab, abc; seleccionar, dónde, ordenar por y agrupar por pueden coincidir con el más a la izquierda prefijo. En otros casos, si no se cumple la regla del prefijo más a la izquierda, no se utilizará el índice de unión.