Los microservicios son inmortales: explicación detallada de la implementación de variables compartidas en el proyecto del motor de políticas
Others
2024-04-17 01:07:03
views: null
fondo
1. Proposición de variables compartidas
Hace algún tiempo, un estudio de caso del equipo de Amazon Prime Video causó revuelo en la comunidad de desarrolladores. Básicamente, como plataforma de transmisión, Prime Video ofrece miles de transmisiones en vivo a los clientes todos los días. Para garantizar que los clientes recibieran el contenido sin problemas, Prime Video necesitaba crear una herramienta de monitoreo para identificar problemas de calidad en cada transmisión que veían los clientes, lo que imponía requisitos de escalabilidad extremadamente altos.
En este sentido, el equipo de Prime Video priorizó la arquitectura de microservicios. Debido a que los microservicios pueden descomponer una sola aplicación en múltiples módulos, esto no solo resuelve el problema del desarrollo e implementación independiente de herramientas, sino que también proporciona mayor disponibilidad, confiabilidad y diversidad técnica para las aplicaciones. En última instancia, el servicio de Prime Video consta de tres partes: el convertidor de medios envía las transmisiones de audio y video al búfer de audio y video del detector; el detector de defectos ejecuta el algoritmo y envía notificaciones en tiempo real cuando se encuentran defectos y el tercer componente proporciona control. la orquestación de los procesos de servicio.
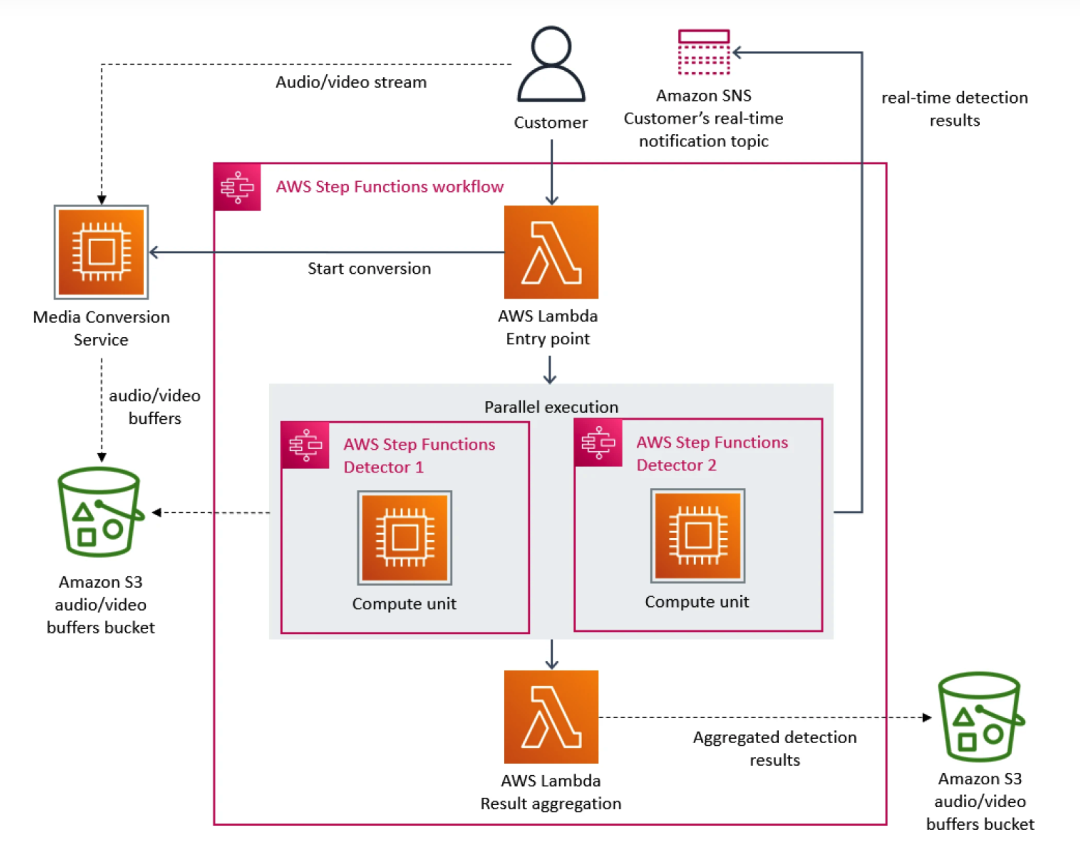 A medida que se añaden más flujos al servicio, comienza a aparecer el problema del coste excesivo. Dado que AWS Step cobra a los usuarios en función de las transiciones de estado de las funciones, cuando es necesario procesar una gran cantidad de transmisiones, la sobrecarga de ejecutar la infraestructura a escala se vuelve muy costosa. El costo total de todos los componentes básicos es demasiado alto, lo que impide Prime Video. equipo acepte la solución inicial a gran escala. Al final, el equipo de Prime Video reestructuró la infraestructura y migró de microservicios a una arquitectura monolítica. Según sus datos, los costos de infraestructura se redujeron en un 90%.
Este incidente también nos hizo más conscientes de que la arquitectura distribuida también tiene deficiencias en comparación con la arquitectura de servicio único. Por ejemplo, el equipo de Prime Video encontró un problema: la arquitectura distribuida no puede compartir variables como la arquitectura monolítica, lo que hace que el servicio subyacente maneje más solicitudes iguales, lo que genera costos vertiginosos. Este dilema también existe en la arquitectura internacional de iQiyi, especialmente en la relación de llamadas del motor estratégico.
A medida que se añaden más flujos al servicio, comienza a aparecer el problema del coste excesivo. Dado que AWS Step cobra a los usuarios en función de las transiciones de estado de las funciones, cuando es necesario procesar una gran cantidad de transmisiones, la sobrecarga de ejecutar la infraestructura a escala se vuelve muy costosa. El costo total de todos los componentes básicos es demasiado alto, lo que impide Prime Video. equipo acepte la solución inicial a gran escala. Al final, el equipo de Prime Video reestructuró la infraestructura y migró de microservicios a una arquitectura monolítica. Según sus datos, los costos de infraestructura se redujeron en un 90%.
Este incidente también nos hizo más conscientes de que la arquitectura distribuida también tiene deficiencias en comparación con la arquitectura de servicio único. Por ejemplo, el equipo de Prime Video encontró un problema: la arquitectura distribuida no puede compartir variables como la arquitectura monolítica, lo que hace que el servicio subyacente maneje más solicitudes iguales, lo que genera costos vertiginosos. Este dilema también existe en la arquitectura internacional de iQiyi, especialmente en la relación de llamadas del motor estratégico.
2. Relación de llamadas al motor de estrategia en el extranjero de iQiyi
2.1 Introducción a la relación de llamada del motor de políticas
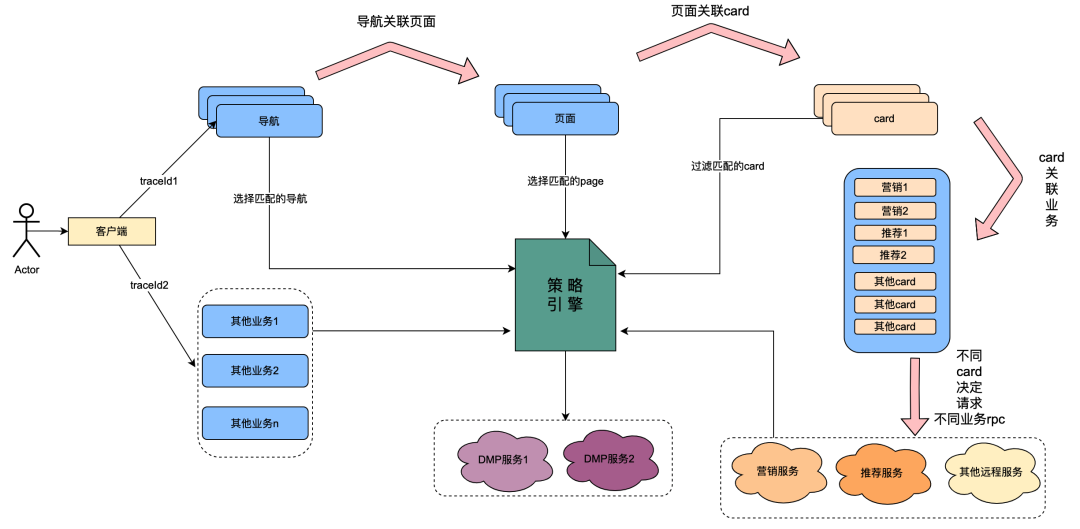
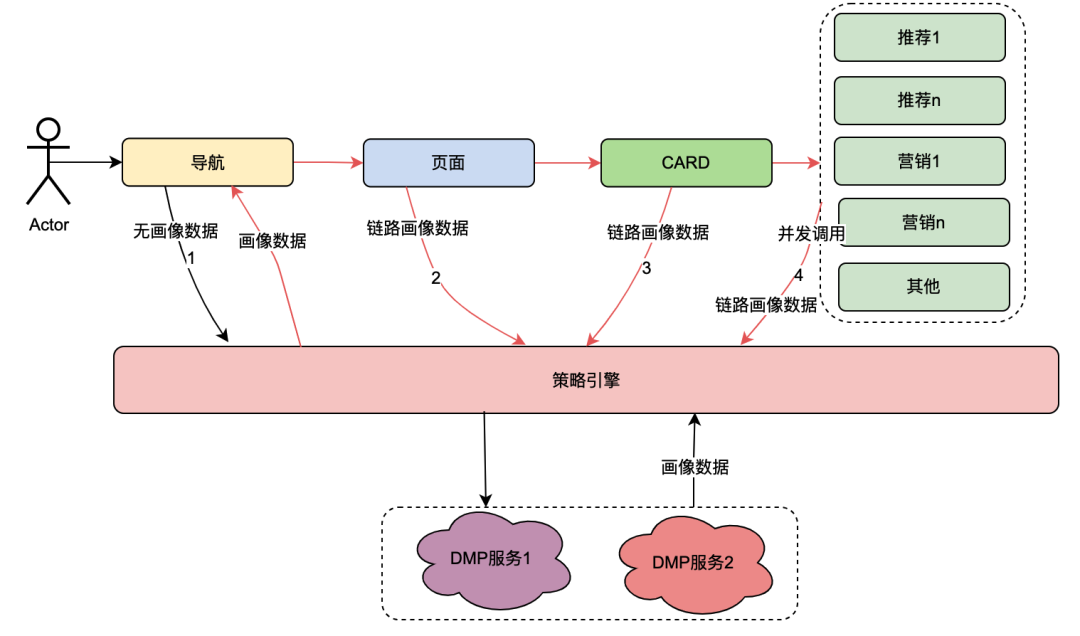
Entre ellos, la tarjeta es el módulo de subdivisión de cada columna de la página. Por lo general, las columnas como series de televisión y películas son una tarjeta. Las fuentes de datos en cada tarjeta son diferentes, como datos de marketing obtenidos de marketing, contenido obtenido de recomendaciones, contenido de programas obtenido de Chip, etc. Existe una relación de asociación, por ejemplo, la página está asociada en la navegación, la tarjeta está asociada en la página y los datos comerciales específicos en la tarjeta están asociados en la tarjeta.
El motor de políticas es un servicio de coincidencia para identificar grupos de personas. Por ejemplo, actualmente está configurada una política de grupo que contiene miembros dorados japoneses, hombres, días de vencimiento de la membresía de menos de 7 días y preferencia por el anime japonés. El servicio del motor de políticas puede identificar si un usuario pertenece a las políticas de grupo anteriores.
Tras la transformación tecnológica del " todo vale ", se ha conseguido la posibilidad de personalizar las dimensiones del perfil de usuario de navegación, páginas, tarjetas y datos dentro de las tarjetas. La implementación general es la siguiente: cuando el cliente inicia una solicitud, primero solicita la API de navegación. En el contexto de configuración de datos de navegación, los estudiantes de operaciones configuraron diferentes datos de navegación y cada dato de navegación se asoció con una política. La API de navegación obtiene internamente todos los datos de navegación y luego utiliza la política asociada a la navegación y el uid de usuario y la identificación del dispositivo como parámetros de entrada para solicitar el motor de políticas. El motor de políticas coincidirá y devolverá la política coincidente. se devuelve la navegación con la política que cumple con los requisitos, logrando así la capacidad de que diferentes retratos de usuarios vean diferentes datos de navegación. Las páginas, tarjetas y datos dentro de las tarjetas se implementan aproximadamente de la misma manera.
Del contenido anterior, se puede resumir que el enlace de llamada del motor de políticas tiene las siguientes características:
(1) Una operación de un usuario que abre una página llamará a varios servicios del motor de políticas en serie.
(2) El rendimiento de la interfaz del motor de políticas afecta directamente la experiencia del usuario: asocia solicitudes para muchos servicios comerciales de páginas.
(3) Los datos del motor de estrategias requieren una fuerte naturaleza en tiempo real: después de que un usuario compra una membresía, debe asociarse inmediatamente con estrategias relacionadas con los miembros.
2.2 Dilemas encontrados
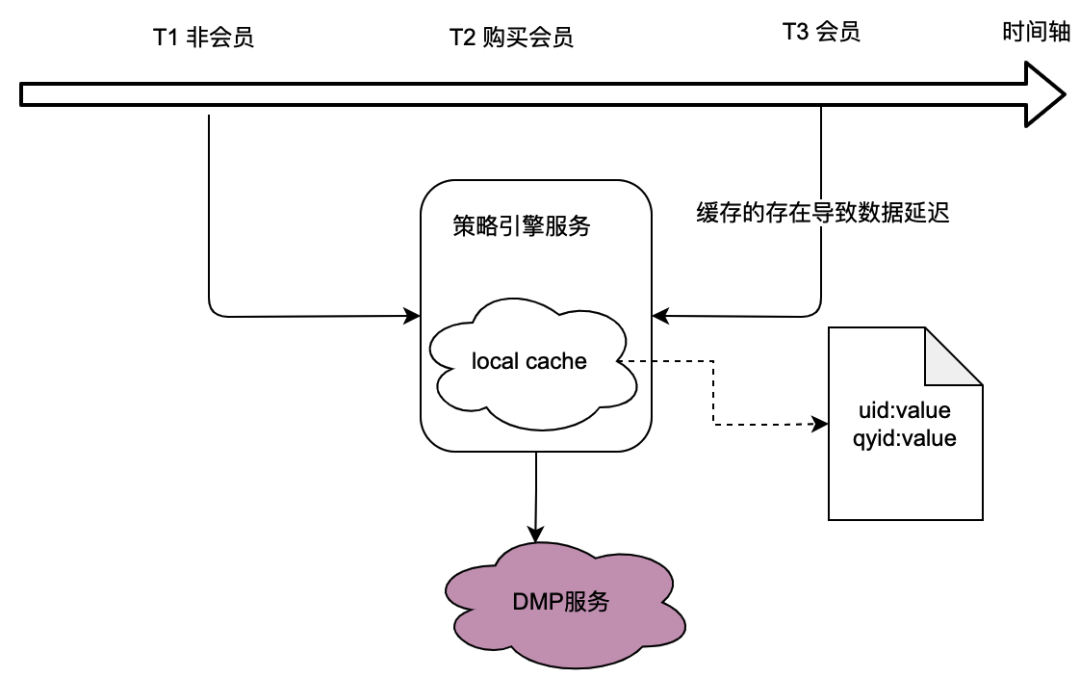
Como se puede ver en la relación de llamadas en la sección anterior, el motor de políticas, como servicio subyacente, realiza el tráfico de muchas partes comerciales, y el motor de políticas necesita obtener datos de retratos de usuarios para determinar si la política colectiva coincide, lo que en a su vez depende en gran medida del servicio DMP (Plataformas de gestión de datos). Para reducir el tráfico al servicio DMP, consideramos una solución de almacenamiento en caché local.
Sin embargo, el problema con esto es obvio, es decir, no puede cumplir con los requisitos de datos en tiempo real . Cuando un usuario compra una membresía y los datos de retrato devueltos por el servicio DMP cambian, el usuario no puede ver los datos más recientes relacionados con la política debido al retraso en el almacenamiento en caché local, lo que obviamente es intolerable.
También consideramos soluciones de almacenamiento en caché distribuido. Si se utiliza el ID de usuario como clave, el problema es el mismo que el del caché local, que no puede cumplir con los requisitos de tiempo real.
Por lo tanto, cómo optimizar el tráfico a los servicios DMP y al mismo tiempo cumplir con los requisitos de datos en tiempo real es un desafío para la optimización de todo el proyecto del motor de políticas.
El amanecer de las variables compartidas
1. Información general
El quid del dilema es que los servicios distribuidos no pueden compartir variables. El comportamiento de apertura de la página de un usuario va acompañado de múltiples solicitudes de backend, y los datos de perfil de usuario asociados con estas múltiples solicitudes de backend son en realidad uno, es decir, los datos de perfil obtenidos del servicio DMP deben ser los mismos. A continuación, realizamos un análisis abstracto del enlace de llamada del motor de políticas para ver qué características tiene.
2. Análisis de enlaces de llamadas del motor de políticas
La relación de llamada del motor de políticas se introdujo en el capítulo 1.2.1 Introducción a la relación de llamada del motor de políticas. Esta vez clasificamos principalmente de forma abstracta sus enlaces de llamada.
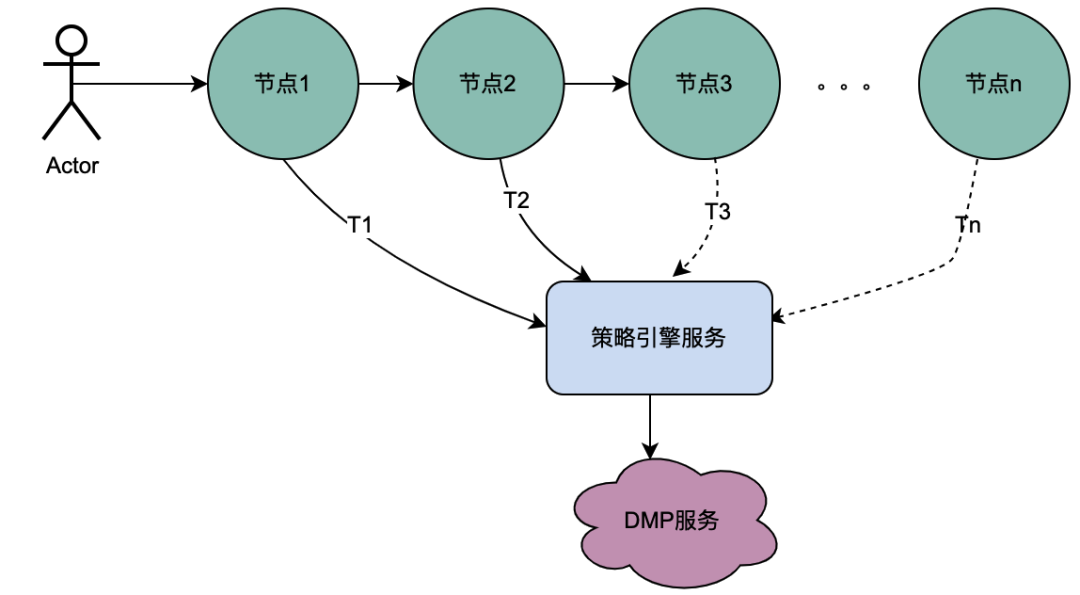
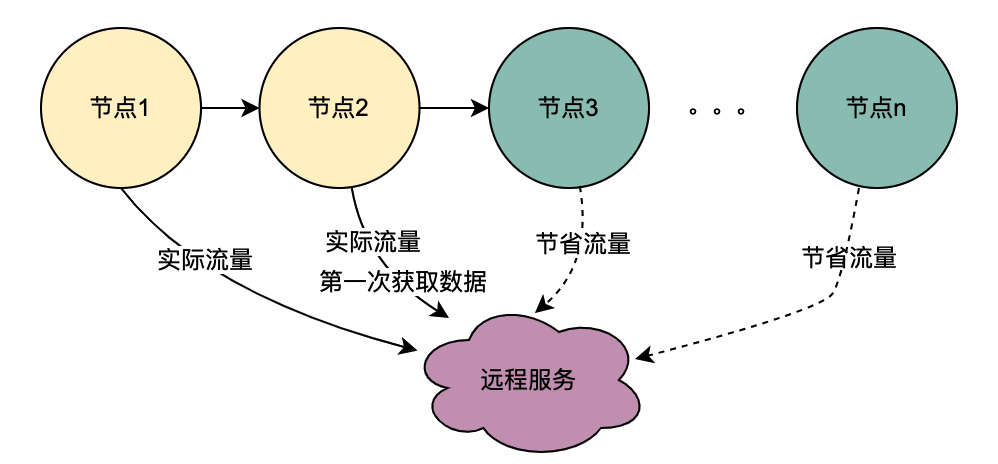
2.1 Escenario de llamada en serie
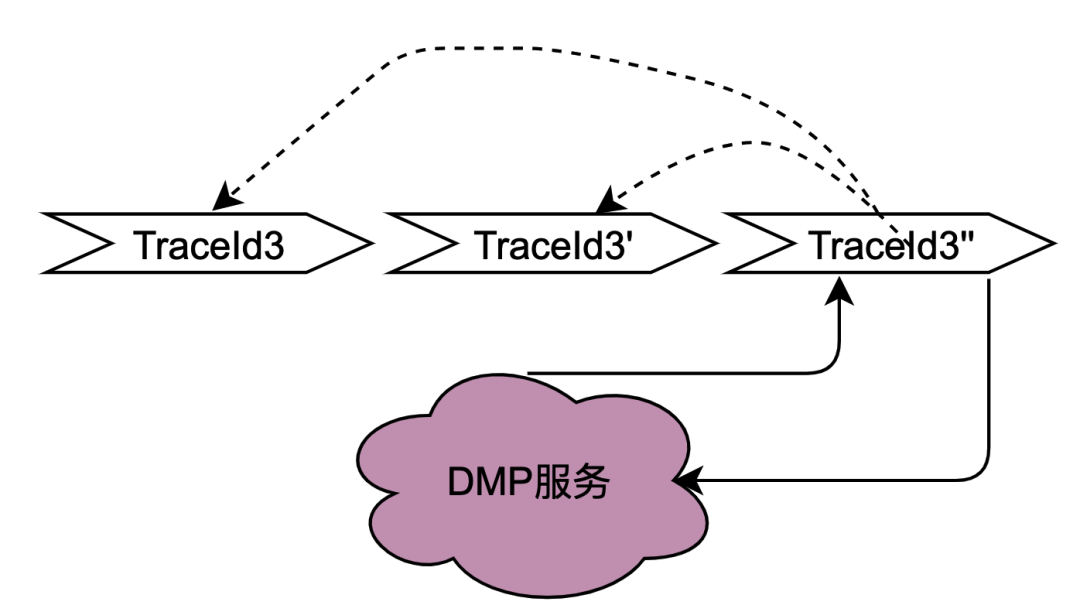
Como puede ver en la figura anterior, un usuario inicia una solicitud y pasa por varios servicios de nodo. Los servicios de nodo están en una relación en serie y cada nodo depende del servicio del motor de políticas. El servicio del motor de políticas necesita obtener el retrato del usuario. data, y obviamente, las solicitudes de T1 a Tn son todas del mismo usuario, y los datos obtenidos por el servicio DMP deben ser los mismos. Entonces, si se utiliza la idea de variables compartidas, las solicitudes al DMP. El servicio de T1 a Tn se puede optimizar a 1 pedido. Aquí denominamos variables compartidas distribuidas a los datos de retrato obtenidos del servicio DMP .
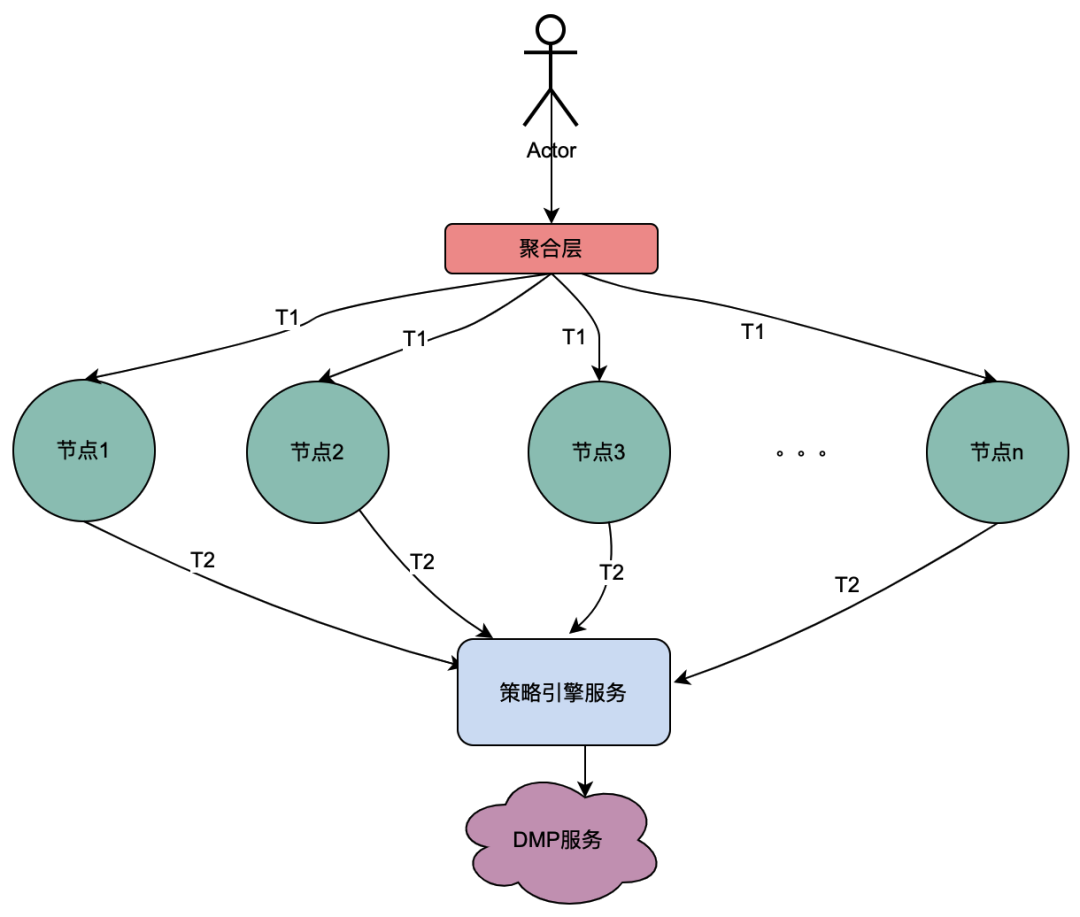
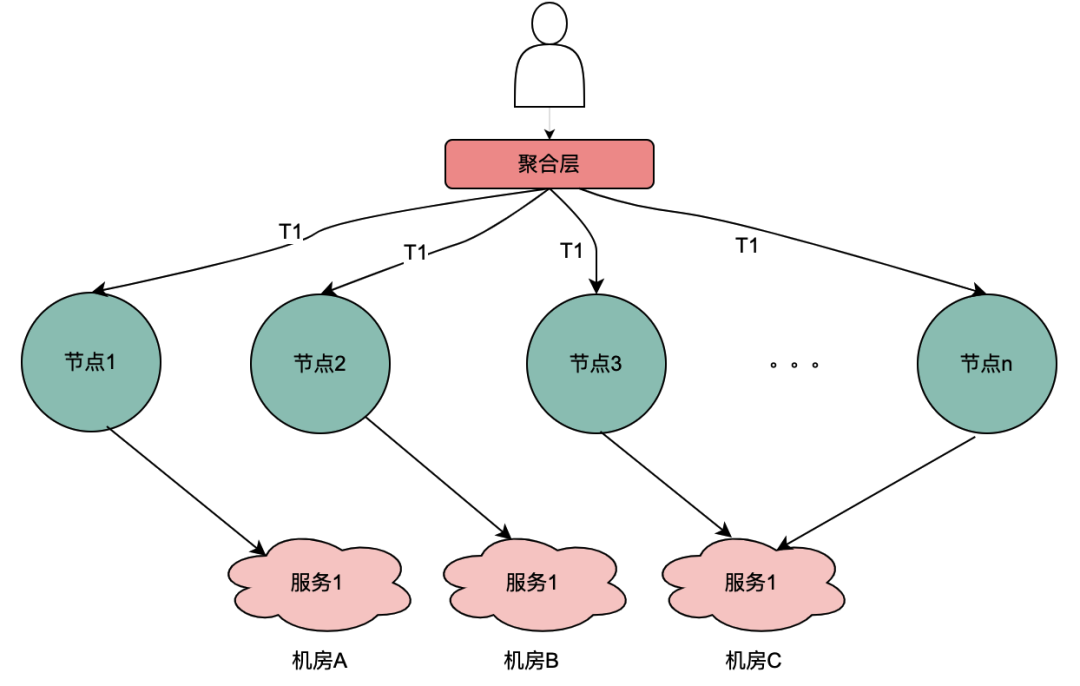
2.2 Escenario de llamadas paralelas
A diferencia de la cadena de llamadas en serie anterior, las llamadas en serie T1 a Tn están en secuencia de tiempo y la llamada T1 debe ser anterior a la llamada T2. No existe una secuencia de tiempo para llamadas paralelas, es decir, el mismo usuario puede iniciar una solicitud y la empresa de la capa de agregación puede iniciar una solicitud al servicio dependiente al mismo tiempo, y el servicio dependiente depende del motor de políticas. una solicitud iniciada por el mismo usuario se ejecutará al mismo tiempo. Realice múltiples solicitudes al motor de políticas. Luego, si se colocan varias solicitudes en una cola, la primera solicitud en realidad solicita el servicio DMP y las solicitudes restantes esperan en la cola los datos de la primera solicitud, se pueden optimizar n solicitudes en 1 solicitud. Aquí llamamos variables locales compartidas a los datos de retrato obtenidos del servicio DMP .
Introducción a las variables compartidas distribuidas.
1. Descripción general de principios
Cuando el usuario abre la página, el cliente solicitará navegación y luego obtendrá la página de funciones, la tarjeta específica y los datos de la tarjeta de funciones en secuencia. Cada enlace implica el servicio del motor de políticas. En circunstancias normales, una solicitud de cliente desencadenará múltiples llamadas al motor de políticas, lo que provocará múltiples llamadas al servicio DMP. Pero obviamente, esta es una solicitud del mismo usuario, y los datos del retrato del usuario obtenidos por estas solicitudes al servicio DMP deben ser los mismos.
Según el análisis anterior, una descripción simple del principio de las variables compartidas distribuidas es que cuando [Navegación] obtiene los datos del retrato por primera vez, coloca su contenido en el enlace de solicitud y lo transmite de manera similar al TraceId del completo. enlace. De esta manera, cuando el flujo descendente, como [Página], solicita nuevamente el motor de políticas, puede obtener directamente los datos del enlace en el contexto del enlace TraceContext sin solicitar el servicio DMP. Para CARD, lo mismo ocurre con el negocio de páginas.
Vale la pena mencionar que TraceContext solo se puede transmitir mediante solicitud. De esta manera, cuando se almacenan datos de enlace, los datos verticales solo se pueden colocar en el contexto del enlace TraceContext después de que [Navegación] obtenga los datos del motor de políticas.
如果导航没有关联策略数据,无需请求策略引擎,但是后面的页面、CARD等又关联了策略引擎,那该怎么处理呢?我们参考了TraceId的处理方式,在每个调用策略引擎服务的节点(不同业务如页面、CARD等)进行判断是否有链路数据,如果没有,则获取策略引擎数据后放置进去,如果有则忽略。这样就保证最前置的节点拿到画像数据后,进行向后传递,减少后续节点对于DMP服务的流量。很明显,这些逻辑有一些业务侵入性,所以我们将调用策略引擎的方式优化为SDK调用,在SDK内部做了一些统一的逻辑处理,让业务调用方无感知。
2、全链路追踪 — 基于SkyWalking
skywalking 是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器化技术(docker、K8s、Mesos)架构而设计,它是一款优秀的 APM(Application Performance Management)工具。skywalking 是观察性分析平台和应用性能管理系统。提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。对于为什么选择skywalking,除去skywalking本身的优势以外,业务上的理由是爱奇艺海外项目目前已经接入SkyWalking,开发成本最低,维护更加便利。所以,使用skywalking传递分布式共享变量只需要引入一个Maven依赖,调用其特有的方法,就可以将数据进行链路传递。
分布式共享变量的方案会增加网络传递数据的大小,增加网络开销;当链路数据足够大的时候甚至会影响服务响应性能。因此控制链路数据大小、链路数据的控制和评估链路数据对网络性能造成影响是尤为重要的。下面将详细介绍。
3、链路传输优化 — 压缩解压缩
3.1 压缩基本原理
目前用处最为广泛的压缩算法包括Gzip等大多是基于DEFLATE,而DEFLATE 是同时使用了 LZ77 算法与哈夫曼编码(Huffman Coding)的一种无损数据压缩算法。其中 LZ77 算法是先通过前向缓冲区预读取数据,然后再向滑动窗口移入(滑动窗口有一定的长度), 不断寻找能与字典中短语匹配的最长短语,然后通过标记符标记,依次来缩短字符串的长度。哈夫曼编码主要是用较短的编码代替较常用的字母,用较长的编码代替较少用的字母,从而减少了文本的总长度,其较少的编码通常使用构造二叉树来实现。
3.2 压缩选型
由于BI获取的用户画像TAG固定且个数较少,因此这里选择DMP数据作为实验对比数据。以下是不同场景下压缩大小对比数据

方案3得到的数据最小,因此选择方案3作为分布式共享变量的压缩方案。
4、数据大小导致的网络消耗分析和极端情况控制
4.1 背景概述
这种方案也存在一些弊端,即需要把用户画像数据通过网络传递,显然这增加了网络开销。理论上,网络数据量与传输速度成正比,但是在工程实践中,带宽肯定是有上限的,因此,对于DMP画像数据存入大小进行压测试验,以确定分布式共享变量对于网络性能的影响。
4.2 压测方案
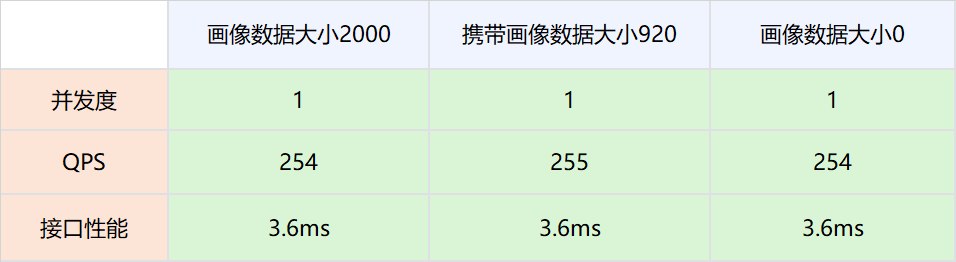
1.测试网络,画像数据不被策略引擎使用,策略引擎依然请求DMP服务。
实验组是请求策略引擎服务的时候带入压缩后的画像数据,对照组是请求策略引擎服务的时候不带入压缩后的画像数据。调整并发值,比较在不同QPS场景下两者的接口性能。
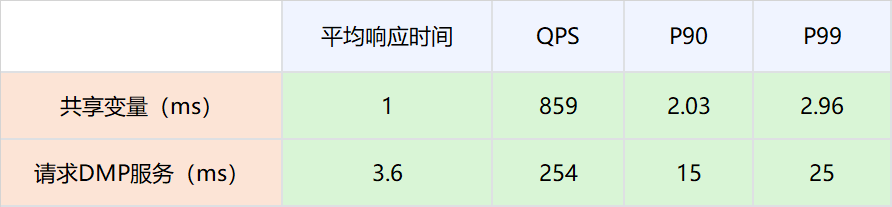
2.分布式共享变量的画像数据被策略引擎使用,策略引擎在有分布式共享变量画像数据的时候,不再请求DMP服务。
4.3结论
-
网络链路上存放数据大小在2000以下,对网络性能的影响可以忽略不计。
-
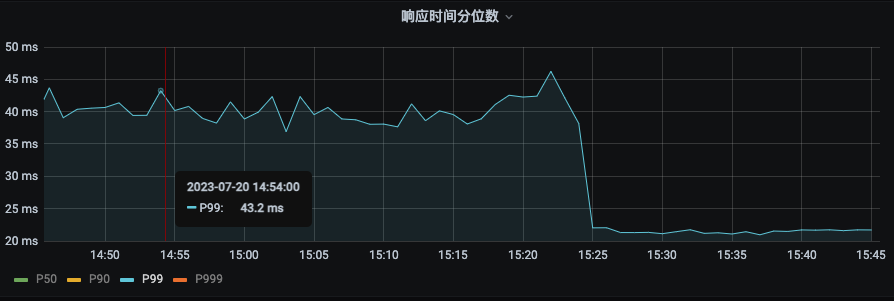
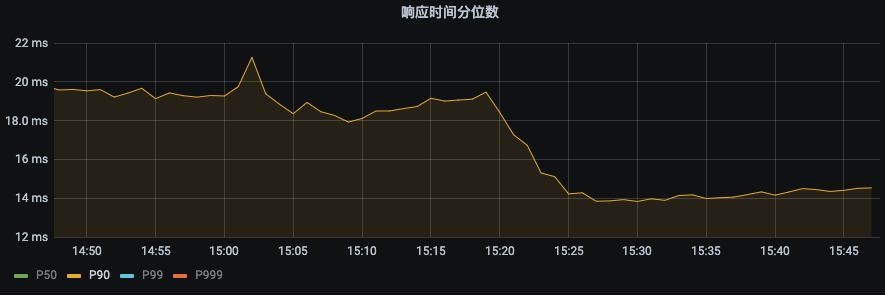
因为分布式共享变量的存在而减少对DMP服务的请求,接口性能可以有比较大的提升。具体数值为P99从25ms提升到2.96ms。
4.4 极端情况控制
因为DMP数据与用户行为相关,比如一个用户在海外站点所有站点都有购买会员的行为,那么其DMP画像数据就会很大。为了防止这种极端情况所以在判断压缩后的用户画像数据足够大的时候,将自动舍弃,而不是放入网络当中,防止大数据对整个网路数据的性能损耗。
5、线上运行情况
5.1 性能优化
|
|
|
|
|
|
|
P99 由之前的43ms下降到22ms。下降幅度 48.8%
|
P90由之前19ms下降到14ms,下降幅度26.3%
|
5.2 对DMP服务的流量优化
|
|
|
|
|
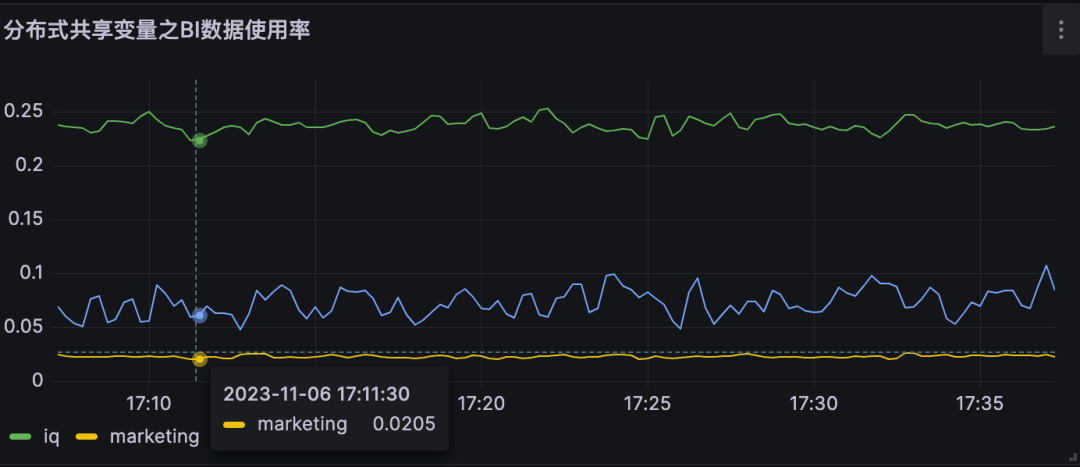
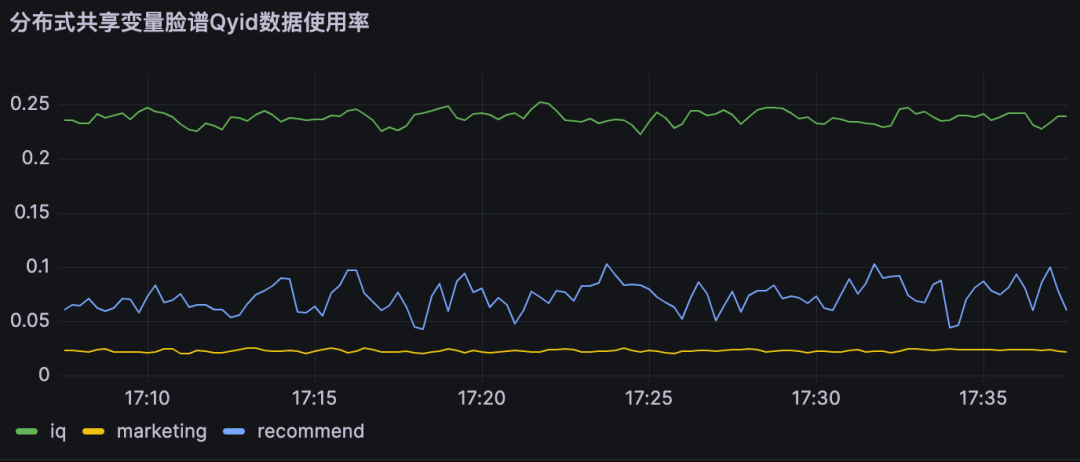
分布式共享变量使用率即为对不同DMP服务优化流量。
A业务节约大约25%的流量,B业务节约约10% 的流量,
|
|
|
|
|
6、结论
分布式共享变量在满足数据实时性要求的前提下,减少了对DMP服务的流量,同时提高了策略引擎服务的接口性能,具体优化指标见上节。
本地共享变量介绍
1、原理概述
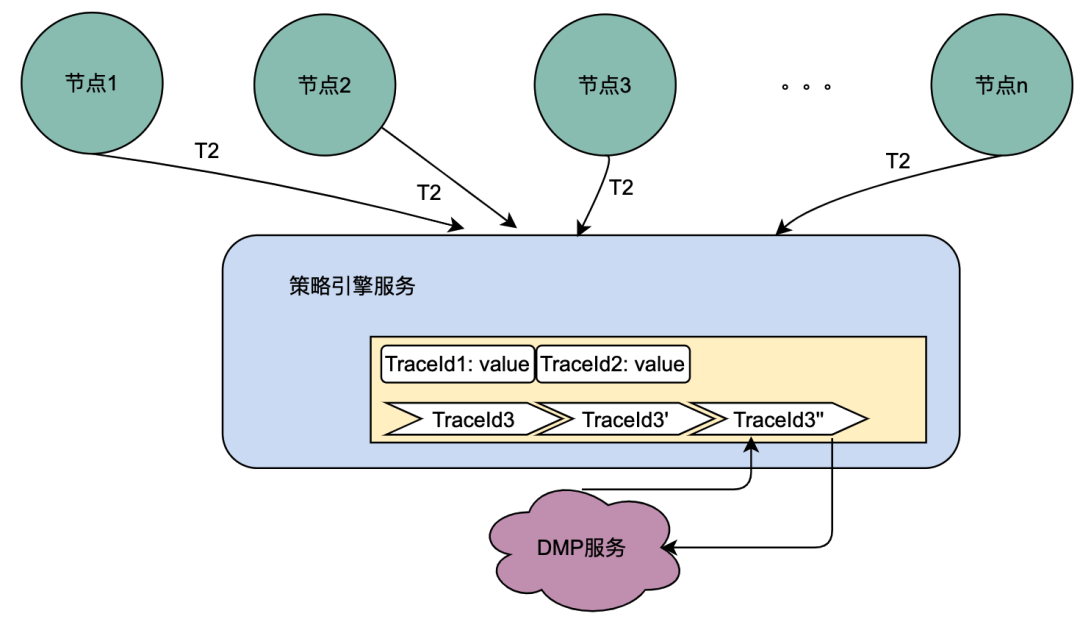
在2.2.2 并行调用场景章节对本地共享变量解决的调用场景进行了阐述,主要解决的是同一个用户并发请求策略引擎带来的多次请求DMP服务问题。如何区分是同一个用户的同一次请求呢?答案是TraceId。在一个请求下,TraceId一定是相同的,如果TraceId相同,那么策略引擎则可以认为是同一个用户的一次请求。
如上图,如果同时多个TraceId3的请求到达策略引擎,将这些请求放入队列,只要其中一个去获取用户画像数据(此处为TraceId3''),其余的请求TraceId3和TraceId3'在队列中等待TraceId3''的结果拿来用即可。
这种思路可以很好的优化并发请求的数据,符合策略引擎调用特性。实现起来有点类似AQS,开发落地有一些难点,比如Trace3''什么时候去请求DMP服务,当拿到数据后,后面仍然有其他trace3进来该如何处理,等待多少时间?这么一思考,这个组件的实现将会耗费我们很多的开发时长,那么有没有现成的中间件可以用呢?答案是本地缓存框架。
无论是本地缓存Caffeine 还是Guava Cache,有相同key的多个请求,只有一个key会请求下游服务,而其他请求会等待拿现成的结果。另外存放的时间可以通过配置缓存的失效时间来确定,至于失效时间的计算方法,将在下面章节会介绍。
2、网关层Hash路由方式的支持
目前,主流的服务一般都是多机房多机器部署,这样有水平扩展能力可以应对业务增长带来的流量增加的问题。但同一个用户的同一个请求,很可能到不同的服务实例,这样上一次获取到的本地缓存数据在下一次请求当中就无法获取。
如上图,同一个用户的同一次请求,被聚合层并发请求到不同业务节点1到节点n。由于策略引擎服务是多实例部署,那么不同节点的请求可能到不同实例,那么本地共享变量的命中率就会大大降低,对DMP服务的流量节约数据就会小很多。因此,需要一个方案使得用户的多次请求能到同一个机房的同一个实例。
最终落地的方案是网关支持按照业务自定义字段Hash路由。策略引擎使用qyid进行hash路由,即同一个设备的所有请求到策略引擎服务,那么路由到的机器实例一定是同一个。这样可以很好的提升本地共享变量的命中率。这里提一下,相比轮询请求,字段Hash方式存在如流量偏移的问题,需要配合服务实例流量的监控和报警,避免某些实例流量过多而导致不可用。由于和本次主题无关,实例流量的监控和报警在这里就不做介绍。
3、本地共享变量个数和有效时间设计
和本地缓存不同,本地共享变量的最大个数和过期时间与命中率不成正比,这和具体业务指标相关。
假设策略引擎服务QPS10000,服务实例有50台,那么每台实例的QPS是200,即一台服务实例每秒的请求是200个。只需要保证,同一个TraceId的一批请求,在个数区间内不被淘汰,在时间区间内不被过期即可。我们通过网关日志查找历史上同一个traceId的请求时间戳,几乎都在100ms内。
那么过期时间设置为1s,最大个数设置为200个就可以保证绝大多数同一个TraceId的批次请求,只有一个请求下游服务,其余从缓存获取数据。我们为此也进行了实验,设置不同的过期时间和缓存最大个数,结论和以上分析完全一致。
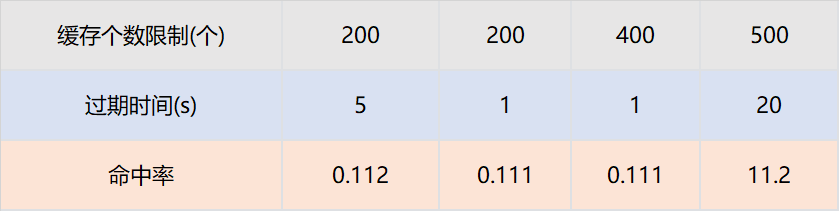
本地共享变量命中率与接口QPS和相同TraceId并发时间相关。
4、结论
-
对于DMP服务1,优化流量15.8%。对于DMP服务2,优化流量 16.7%。对于DMP服务3,优化流量16.2%。
-
与分布式共享变量一样,本地共享变量同样可以满足数据实时性要求,即不会存在1.2.2 遇到的困境 所遇到的缓存导致的数据实时性不够的问题。
总结和展望
本次优化是比较典型的技术创新项目。是先从社区看到一篇技术博客,然后想到爱奇艺海外遇到相同痛点问题的的项目,从而提出优化因为微服务导致的策略引擎对于DMP服务流量压力的目标。
在落地过程中,遇到使用本地缓存进行优化而无法克服数据实效性问题的挑战。最终沉下心分析策略引擎的调用链路,将调用链路一分为二:串行调用和并行调用,最终提出了共享变量的解决方案。因为串行调用和并行调用的特点迥异,依次针对两者进行分期优化,其中第一期通过分布式共享变量优化了串行调用DMP服务的流量,在第二期通过本地共享变量优化了并行调用DMP服务的流量。
参考文章:

也许你还想看
低代码、中台化:爱奇艺号微服务工作流实践
揭秘内存暴涨:解决大模型分布式训练OOM纪实
分布式系统日志打印优化方案的探索与实践
本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Origin my.oschina.net/u/4484233/blog/10924140