
01
fondo
02
Introducción a la plataforma de registros de Venus
Venus es una plataforma de servicios de registros desarrollada por iQiyi. Proporciona recopilación, procesamiento, almacenamiento, análisis y otras funciones de registros. Se utiliza principalmente para la resolución de problemas de registros, análisis de big data, monitoreo y alarmas dentro de la empresa. 1. mostrado.
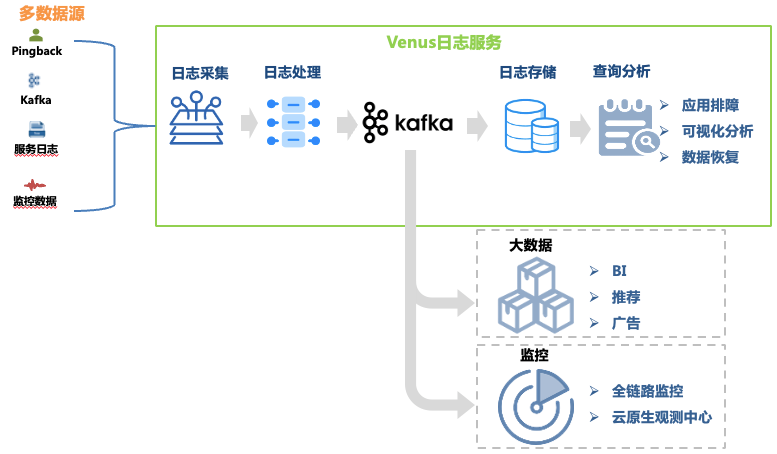 Figura 1 Enlace de Venus
Figura 1 Enlace de Venus
Este artículo se centra en la evolución arquitectónica del enlace de solución de problemas de registros. Sus enlaces de datos incluyen:
Recopilación de registros : al implementar agentes de recopilación en máquinas y hosts de contenedores, se recopilan registros de front-end, back-end, monitoreo y otras fuentes de cada línea de negocio, y la empresa también puede autoentregar registros que cumplan con los requisitos de formato. . Se han implementado más de 30.000 agentes, que admiten 10 fuentes de datos como Kafka, MySQL, K8 y puertas de enlace.
Procesamiento de registros : después de la recopilación de registros, se somete a un procesamiento estandarizado, como la extracción regular y la extracción del analizador integrado, y se escribe de manera uniforme en Kafka en formato JSON y luego el programa de volcado lo escribe en el sistema de almacenamiento.
Almacenamiento de registros : Venus almacena casi 10,000 flujos de registros comerciales, con un pico de escritura de más de 10 millones de QPS y nuevos registros diarios que superan los 500 TB. A medida que cambia la escala de almacenamiento, la selección de sistemas de almacenamiento ha pasado por muchos cambios desde ElasticSearch hasta el lago de datos.
Análisis de consultas : Venus proporciona análisis de consultas visuales, consultas contextuales, disco de registro, reconocimiento de patrones, descarga de registros y otras funciones.
Para cumplir con el almacenamiento y el análisis rápido de datos de registro masivos, la plataforma de registro Venus ha experimentado tres actualizaciones de arquitectura importantes, evolucionando gradualmente de la arquitectura ELK clásica a un sistema de desarrollo propio basado en lagos de datos. Este artículo presentará los problemas encontrados. durante la transformación de la arquitectura y soluciones de Venus.
03
Venus 1.0: basado en la arquitectura ELK
Venus 1.0 comenzó en 2015 y se creó en base al entonces popular ElasticSearch+Kibana, como se muestra en la Figura 2. ElasticSearch es responsable de las funciones de almacenamiento y análisis de registros, y Kibana proporciona capacidades de análisis y consultas visuales. Solo necesita consumir Kafka y escribir registros en ElasticSearch para proporcionar servicios de registro.
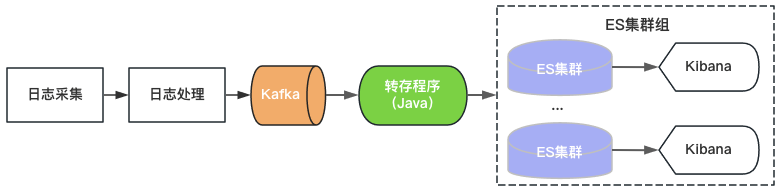 Figura 2 Arquitectura Venus 1.0
Figura 2 Arquitectura Venus 1.0
Dado que existen límites superiores en el rendimiento, la capacidad de almacenamiento y la cantidad de fragmentos de índice de un único clúster de ElasticSearch, Venus continúa agregando nuevos clústeres de ElasticSearch para hacer frente a la creciente demanda de registros. Para controlar los costos, la carga de cada ElasticSearch es alta y el índice está configurado con 0 copias. A menudo se encuentran problemas como escritura de tráfico repentina, consultas de datos grandes o fallas de la máquina que provocan la indisponibilidad del clúster. Al mismo tiempo, debido a la gran cantidad de índices en el clúster, la gran cantidad de datos y el largo tiempo de recuperación, los registros no están disponibles durante mucho tiempo y la experiencia de uso de Venus empeora cada vez más.
04
Venus 2.0: basado en ElasticSearch + Hive
Clasificación de clústeres: los clústeres de ElasticSearch se dividen en dos categorías: alta calidad y baja calidad. Las empresas clave utilizan clústeres de alta calidad, la carga del clúster se controla a un nivel bajo y el índice está habilitado con una configuración de 1 copia para tolerar fallas de un solo nodo. Las empresas no clave usan un clúster de baja calidad, la carga; se controla en un nivel alto y el índice todavía usa una configuración de 0 copias.
Clasificación de almacenamiento: ElasticSearch y Hive de doble escritura para registros de almacenamiento prolongado. ElasticSearch guarda los registros de los últimos 7 días y Hive guarda los registros durante un período de tiempo más largo, lo que reduce la presión de almacenamiento de ElasticSearch y también reduce el riesgo de que ElasticSearch quede bloqueado por grandes consultas de datos. Sin embargo, dado que Hive no puede realizar consultas interactivas, los registros en Hive deben consultarse a través de una plataforma informática fuera de línea, lo que genera una experiencia de consulta deficiente.
Portal de consultas unificado: proporciona un portal de análisis y consultas visuales unificados similar a Kibana, que protege el clúster ElasticSearch subyacente. Cuando un clúster falla, los registros recién escritos se programan en otros clústeres sin afectar la consulta y el análisis de los nuevos registros. Programe de forma transparente el tráfico entre clústeres cuando la carga del clúster esté desequilibrada.
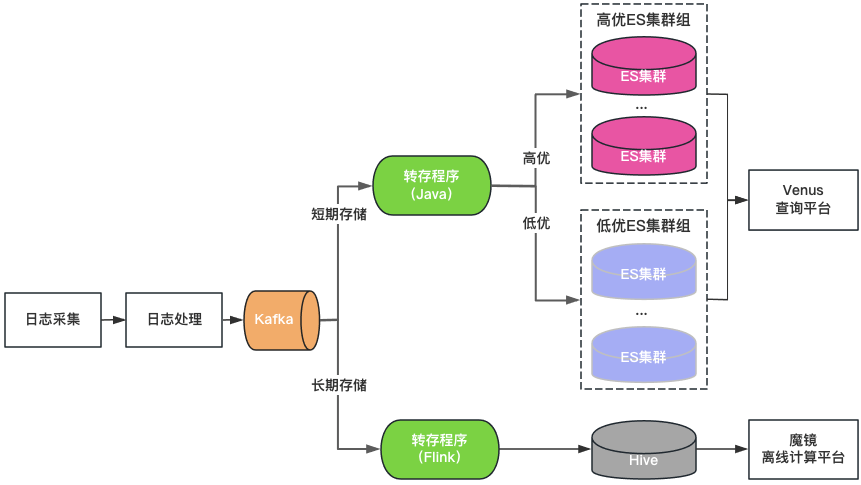
Figura 3 Arquitectura de Venus 2.0
Venus 2.0 es una solución de compromiso para proteger empresas clave y reducir el riesgo y el impacto de las fallas. Todavía tiene los problemas de alto costo y mala estabilidad:
ElasticSearch tiene un tiempo de almacenamiento corto: debido a la gran cantidad de registros, ElasticSearch solo puede almacenar 7 días, lo que no puede satisfacer las necesidades comerciales diarias.
Hay muchas entradas y fragmentación de datos: más de 20 clústeres de ElasticSearch + 1 clúster de Hive, hay muchas entradas de consultas, lo cual es muy inconveniente para las consultas y la administración.
Alto costo: aunque ElasticSearch solo almacena registros durante 7 días, aún consume más de 500 máquinas.
Lectura y escritura integradas: el servidor ElasticSearch se encarga de leer y escribir al mismo tiempo, afectándose entre sí.
Muchas fallas: las fallas de ElasticSearch representan el 80% del total de fallas de Venus. Después de las fallas, la lectura y la escritura se bloquean, los registros se pierden fácilmente y el procesamiento es difícil.
05
Venus 3.0: Nueva arquitectura basada en lago de datos
Pensando en introducir un lago de datos
Después de un análisis en profundidad del escenario logarítmico de Venus, resumimos sus características de la siguiente manera:
Gran cantidad de datos : casi 10 000 flujos de registros comerciales con una capacidad máxima de escritura de 10 millones de QPS y almacenamiento de datos a nivel de PB.
Escriba más y verifique menos : las empresas generalmente solo consultan registros cuando es necesario solucionar problemas. La mayoría de los registros no tienen requisitos de consulta dentro de un día y el QPS de consulta general también es extremadamente bajo.
Consulta interactiva : los registros se utilizan principalmente para solucionar problemas en escenarios urgentes que requieren múltiples consultas consecutivas y requieren una experiencia de consulta interactiva de segundo nivel.
Con respecto a los problemas encontrados al usar ElasticSearch para almacenar y analizar registros, creemos que no coincide del todo con el escenario del registro de Venus por las siguientes razones:
Un solo clúster tiene QPS de escritura y escala de almacenamiento limitados, por lo que varios clústeres deben compartir el tráfico. Es necesario considerar cuestiones complejas de estrategias de programación, como el tamaño del clúster, el tráfico de escritura, el espacio de almacenamiento y la cantidad de índices, lo que aumenta la dificultad de la gestión. Dado que el tráfico de registros comerciales varía ampliamente y es impredecible, para resolver el impacto del tráfico repentino en la estabilidad del clúster, a menudo es necesario reservar más recursos inactivos, lo que resulta en un enorme desperdicio de recursos del clúster.
La indexación de texto completo durante la escritura consume una gran cantidad de CPU, lo que genera expansión de datos y un aumento significativo de los costos de computación y almacenamiento. En muchos escenarios, almacenar registros de análisis requiere más recursos que los recursos del servicio en segundo plano. Para escenarios como registros donde hay muchas escrituras y pocas consultas, precalcular el índice de texto completo es más lujoso.
Los datos de almacenamiento y los cálculos están en la misma máquina. Las consultas de grandes volúmenes de datos o el análisis agregado pueden afectar fácilmente la escritura, provocando retrasos en la escritura o incluso fallas del clúster.
为了解决上述问题,我们调研了ClickHouse、Iceberg数据湖等替代方案。其中,Iceberg是爱奇艺内部选择的数据湖技术,是一种存储在HDFS或对象存储之上的表结构,支持分钟级的写入可见性及海量数据的存储。Iceberg对接Trino查询引擎,可以支持秒级的交互式查询,满足日志的查询分析需求。
针对海量日志场景,我们对ElasticSearch、ElasticSearch+Hive、ClickHouse、Iceberg+Trino等方案做了对比评估:
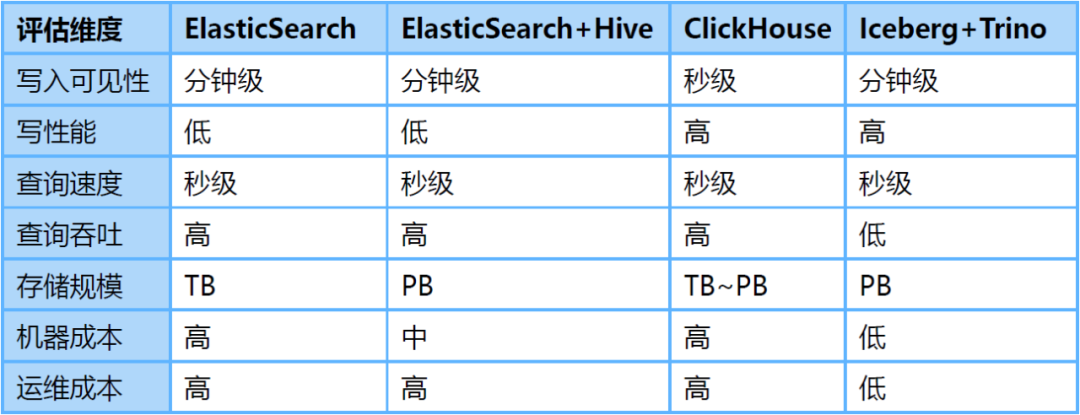
-
存储空间大:Iceberg底层数据存储在大数据统一的存储底座HDFS上,意味着可以使用大数据的超大存储空间,不需要再通过多个集群分担存储,降低了存储的维护代价。 -
存储成本低:日志写入到Iceberg不做全文索引等预处理,同时开启压缩。HDFS开启三副本相比于ElasticSearch的三副本存储空间降低近90%,相比ElasticSearch的单副本存储空间仍然降低30%。同时,日志存储可以与大数据业务共用HDFS空间,进一步降低存储成本。 -
计算成本低:对于日志这种写多查少的场景,相比于ElasticSearch存储前做全文索引等预处理,按查询触发计算更能有效利用算力。 -
存算隔离:Iceberg存储数据,Trino分析数据的存算分离架构天然的解决了查询分析对写入的影响。
基于数据湖架构的建设
通过上述评估,我们基于Iceberg和Trino构建了Venus 3.0。采集到Kafka中的日志由转存程序写入Iceberg数据湖。Venus查询平台通过Trino引擎查询分析数据湖中的日志。架构如图4所示。
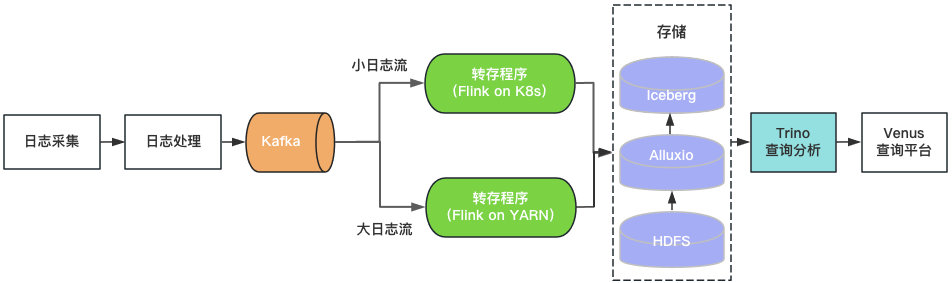 图4 Venus 3.0架构
图4 Venus 3.0架构
-
日志存储
-
查询分析
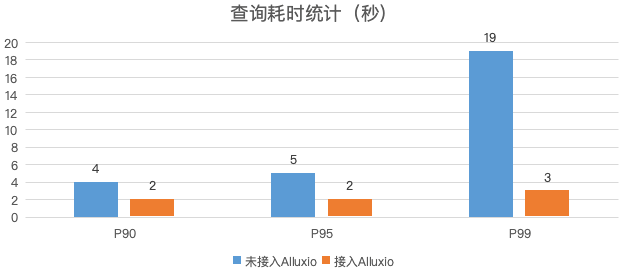
图5 日志查询性能对比
-
转存程序
-
落地效果
-
存储空间 :日志的物理存储空间降低30%,考虑到ElasticSearch集群的磁盘存储空间利用率较低,实际存储空间降低50%以上。 -
计算资源 :Trino使用的CPU核数相比于ElasticSearch减少80%,转存程序资源消耗降低70%。 -
稳定性提升:迁移到数据湖后,故障数降低了85%,大幅节省运维人力。
06
总结与规划
-
Iceberg+Trino的数据湖架构支持的查询并发较低,我们将尝试使用Bloomfilter、Zorder等轻量级索引提升查询性能,提高查询并发,满足更多的实时分析的需求。 -
目前Venus存储了近万个业务日志流,日新增日志超过500TB。计划引入基于数据热度的日志生命周期管理机制,及时下线不再使用的日志,进一步节省资源。 -
如图1所示,Venus同时也承载了大数据分析链路的Pingback用户数据的采集与处理,该链路与日志数据链路比较类似,参考日志入湖经验,我们对Pingback数据的处理环节进行基于数据湖的流批一体化改造。目前已完成一期开发与上线,应用于直播监控、QOS、DWD湖仓等场景,后续将继续推广至更多的湖仓场景。详细技术细节将在后续的数据湖系列文章中介绍。

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。