
En la conferencia de primavera de 2024, recién pasada, Kangaroo Cloud presentó una nueva versión de la versión V6.2 del producto de pila de datos . Entre ellos, EasyMR, como capacidad clave en la pila de datos V6.2, representa la comprensión profunda y la innovación continua de Kangaroo Cloud del ecosistema de big data.
EasyMR (en lo sucesivo denominado colectivamente EMR) es un motor informático elástico creado por Kangaroo Cloud basado en componentes de código abierto como Hadoop, Hive, Spark, Flink y HBase. Proporciona grandes beneficios seguros, confiables, elásticamente escalables y de bajo costo. servicios de informática y almacenamiento de datos . Entre ellos, la plataforma de gestión de mantenimiento y operación de big data a nivel empresarial EasyManager, desarrollada de forma independiente , admite las funciones integrales de creación, gestión, implementación, operación y mantenimiento y monitoreo de los clústeres de Hadoop, proporcionando una solución de centro de datos eficiente.
Frente a las crecientes necesidades de procesamiento y análisis de datos de las empresas, la versión EMR6.2 proporcionará a los usuarios mejores servicios de operación y mantenimiento de big data y optimización del rendimiento informático. La siguiente es una introducción detallada a la optimización de las cuatro funciones principales de la versión EMR6.2 para ayudar a los usuarios a comprender completamente este producto innovador.
UI completamente renovada y mejorada: experiencia interactiva simple y cómoda
Kangaroo Cloud comprende la importancia de la experiencia del usuario, por lo que en la versión EMR6.2, hemos actualizado y actualizado completamente la interfaz de usuario. El nuevo diseño de la interfaz sigue un estilo simple pero elegante, con el objetivo de brindar a los usuarios una experiencia interactiva intuitiva y cómoda. Ya sea un usuario novato o experimentado, puede comenzar rápidamente y administrar fácilmente complejos grupos de big data.
Además, también hemos optimizado la velocidad de respuesta y la fluidez de operación de la interfaz para garantizar que los usuarios puedan disfrutar de una experiencia operativa más fluida durante la operación y el mantenimiento del clúster .
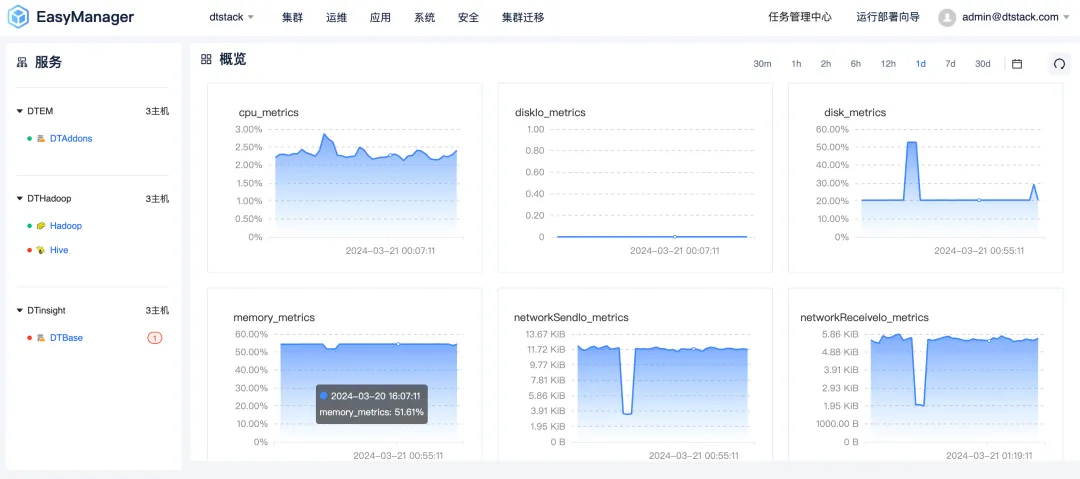
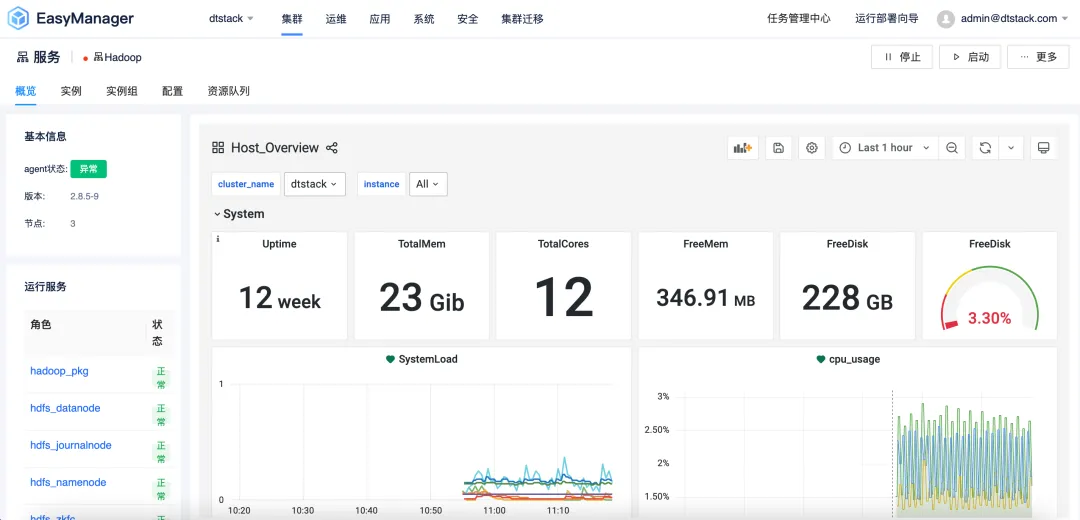
Configuración diferenciada: satisfacer diversas necesidades
La versión EMR6.2 introduce la función de configuración diferenciada de grupos de instancias , lo que permite a los usuarios personalizar la configuración del clúster según sus necesidades específicas. Los usuarios pueden crear grupos de instancias independientes a partir de diferentes nodos en el clúster de EMR y establecer parámetros de configuración específicos en el grupo de instancias para lograr un mejor rendimiento, utilización de recursos y programación de tareas.
Ya sea que se trate de una nueva empresa sensible a los costos o de una gran empresa con mayores requisitos de rendimiento, EMR6.2 puede proporcionar opciones de configuración flexibles para satisfacer las necesidades de diferentes usuarios.
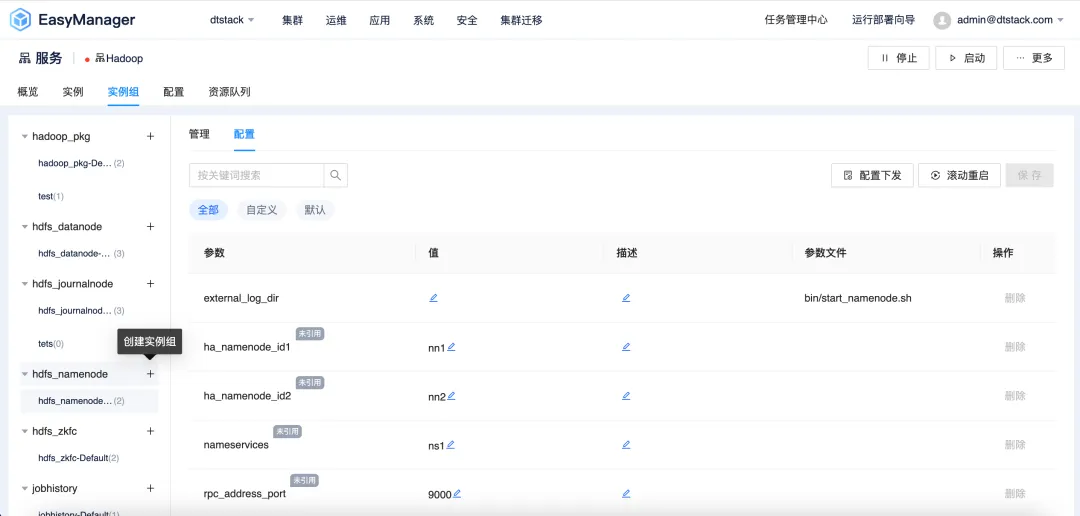
Las ventajas específicas de implementar estrategias de configuración diferenciadas para grupos de instancias incluyen, entre otras, las siguientes:
● Asignación de recursos
La configuración diferenciada puede implementar de manera efectiva una asignación refinada de recursos de acuerdo con las necesidades únicas de diversas tareas, cubriendo múltiples niveles, como recursos informáticos, de almacenamiento y de red. Evite el desperdicio de recursos y mejore su utilización para garantizar que todas las tareas del clúster estén respaldadas por los recursos adecuados.
●Optimización de la programación de tareas
Para diferentes tipos de tareas o trabajos, se pueden establecer diferentes parámetros de configuración según sus características para optimizar la programación de tareas y la eficiencia de ejecución.
● Tolerancia a fallos y estabilidad
Mediante una configuración diferenciada, se puede mejorar la tolerancia a fallos y la estabilidad del clúster. Dependiendo de la importancia y la carga del nodo o grupo de instancias, se pueden configurar diferentes mecanismos de tolerancia a fallas y estrategias de manejo de fallas para garantizar que el clúster pueda mantener un funcionamiento estable ante situaciones anormales.
● Gestión de costos
La configuración diferenciada también puede ayudar a administrar los costos. Según las necesidades comerciales y las restricciones presupuestarias, se pueden configurar de manera razonable diferentes grupos de instancias en el clúster para evitar el desperdicio de recursos, reducir los costos de operación y mantenimiento y encontrar un equilibrio entre rendimiento y costo.
Migración de clústeres: transición fluida sin interrupción del negocio
A medida que se desarrolla el negocio de una empresa, la creciente cantidad de datos a menudo genera problemas como una capacidad insuficiente del centro de datos o cambios en el centro de datos. Las empresas necesitan migrar datos de un centro de datos a otro. Al mismo tiempo, en el contexto del reemplazo de la localización, cada vez más empresas están migrando plataformas no innovadoras como CDH, HDP y CDP a plataformas de big data localizadas. Por lo tanto, EMR ha lanzado una función de migración de clústeres de big data para ayudar a las empresas a completar la migración del centro de datos de manera eficiente.
La función de migración de clústeres permite a los usuarios migrar sin problemas sus clústeres de big data entre diferentes centros de datos o servicios en la nube sin preocuparse por la pérdida de datos o la interrupción del negocio. A través de esta característica, las empresas pueden ajustar de manera más flexible su infraestructura de TI para adaptarse a las necesidades cambiantes del mercado.
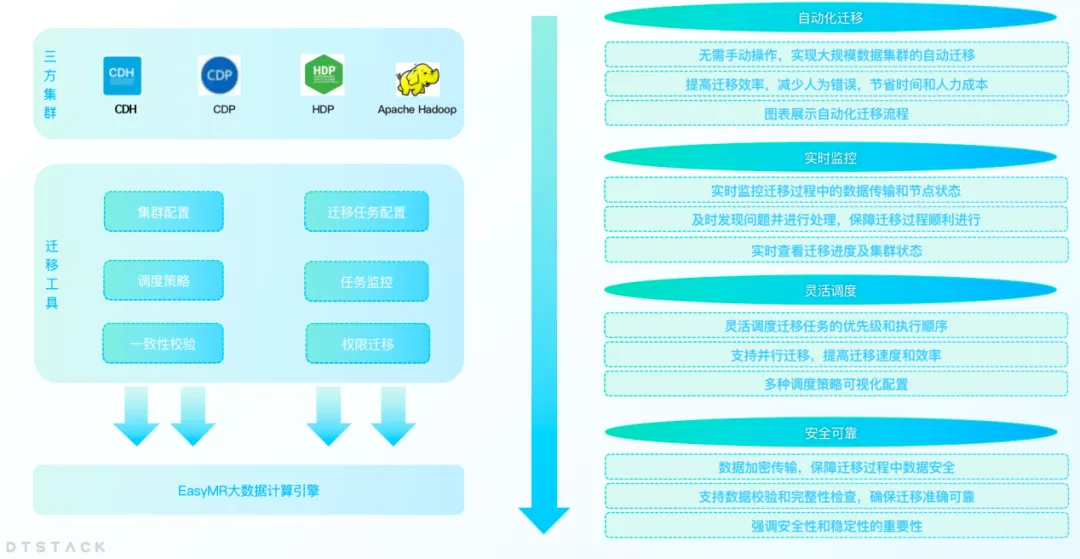
Actualización del motor revelada: salto de rendimiento, nueva experiencia
Lo más emocionante es que la versión EMR6.2 ha logrado un gran avance en el rendimiento del motor informático . No solo optimizamos los motores informáticos Spark y Flink existentes, sino que también introdujimos nuevos algoritmos y tecnologías para mejorar la velocidad de procesamiento de datos y la eficiencia informática. Esto significa que los usuarios pueden completar tareas de análisis de datos más complejas en menos tiempo, acelerando así el proceso de toma de decisiones y mejorando la competitividad corporativa.
● Spark3 admite la optimización del índice Z-oreder
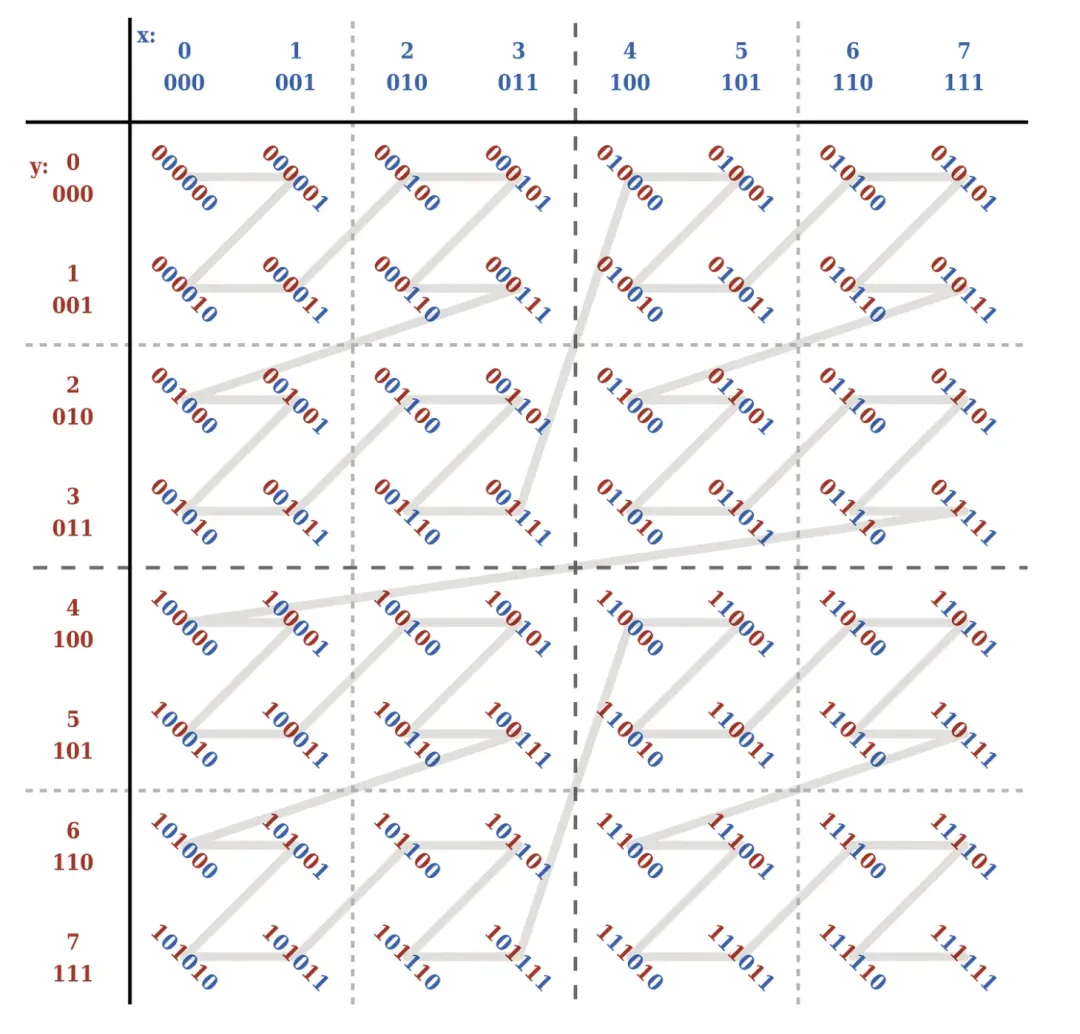
Z-Order es una tecnología que puede comprimir datos multidimensionales en una dimensión. Para un dato, podemos considerar que sus múltiples campos están ordenados como múltiples dimensiones de los datos. Z-Order puede asignar ciertas reglas a datos multidimensionales . datos unidimensionales.
Específicamente, el valor z se construye mediante ciertas reglas . El valor z puede entenderse como los datos unidimensionales mencionados anteriormente. En este momento, podemos ordenarlos en función de los datos unidimensionales. Como se muestra abajo:
En Spark SQL, Kangaroo Cloud ha agregado la sintaxis OPTIMIZE XX ZORDER BY para admitir el índice de orden Z, logrando la optimización del índice de orden Z de la tabla INSERT INTO, la tabla INSERT OVERWRITE, la tabla CREATE TABLE AS SELECT, DISTINCT y otros SQL.
Spark3 admite la optimización del orden Z, lo que mejora en gran medida la eficiencia del procesamiento y las consultas de datos, reduce la sobrecarga de IO y acelera la ejecución del trabajo. Especialmente en escenarios donde es necesario procesar conjuntos de datos a gran escala y operaciones de consulta complejas, la optimización del orden Z puede desempeñar un papel importante. Para resolver el problema de la tasa de compresión de archivos, después de utilizar la optimización de orden Z, la tasa de compresión de archivos aumentó en casi un 20% en comparación con la optimización manual y casi 10 veces en comparación con la tarea original. En comparación con el Spark3 de código abierto. tarea, el rendimiento también es casi del 30% y ha mejorado enormemente el rendimiento y la eficiencia de las operaciones fuera de línea.
● Actualización activa de tareas por trabajo de Flink
En las operaciones de producción reales, a menudo ocurren cambios de parámetros de tareas en tiempo real o ajustes de operadores y funciones. Por lo general, la tarea actual solo se puede cancelar primero y luego se selecciona CheckPoint para restaurar o volver a ejecutar. Todo el proceso demora entre 3 y 5 minutos. Espere, lo cual es muy difícil. Una gran pérdida de tiempo de desarrollo de tareas.
Para resolver el problema de interrupción del servicio causado por las actualizaciones de tareas en el modo tradicional por trabajo, mejorar la estabilidad de las tareas y la disponibilidad del sistema, y cumplir con los requisitos de continuidad del negocio y alta disponibilidad en el entorno de producción. El equipo de Kangaroo Cloud Engine ha realizado mejoras relevantes en la exploración y el código fuente, y ha optimizado el reinicio en caliente de las tareas en la devolución de llamada asincrónica de la cancelación de tareas por trabajo :
① Primero determine si hay un nuevo caché de JobGraph actualmente. Si hay un caché, ingrese la lógica de reinicio en caliente.
② Obtenga la información de CheckPoint de la tarea cancelada y complétela en el nuevo JobGraph
③Actualice JobGrap a JobMaster y borre la información de caché de JobGraph
④Borrar los recursos administrados por SloyPool en JobMaster
⑤JobMaster vuelve a crear ScheduleNg y lo programa para ejecutarse. Esto iniciará una nueva ejecución de programación de JobGraph.
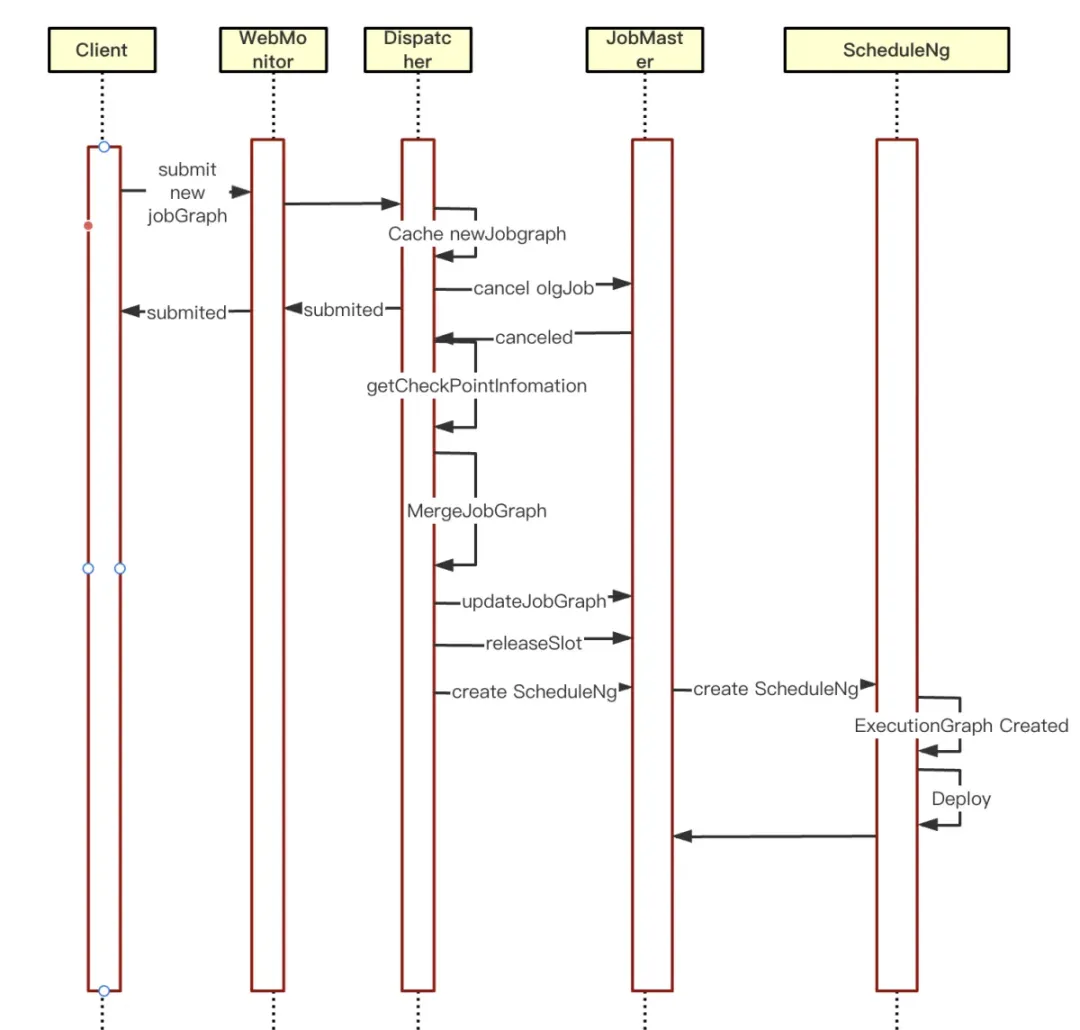
La optimización de las actualizaciones en caliente de tareas por trabajo de Flink mejora significativamente la eficiencia del desarrollo, reduce el tiempo de inactividad y mejora la flexibilidad y confiabilidad de las aplicaciones. Para aplicaciones en tiempo real que requieren iteración rápida y ajuste dinámico, brinda la experiencia de eficiencia definitiva.
Eficiencia de desarrollo mejorada: los desarrolladores pueden probar e iterar código rápidamente sin pasar por el tedioso proceso de parada y reinicio, lo que acelera los ciclos de desarrollo y permite lanzamientos más frecuentes.
· Reducir el tiempo de inactividad: las actualizaciones en caliente pueden minimizar el tiempo de inactividad de las aplicaciones, aumentando así la disponibilidad del servicio, lo cual es especialmente importante para aplicaciones de misión crítica y en tiempo real.
· Ajustar dinámicamente los parámetros: los parámetros de configuración del trabajo, como el paralelismo o los parámetros del operador , se pueden ajustar dinámicamente sin reiniciar el trabajo, lo que permite ajustes flexibles basados en el flujo de datos en tiempo real o las condiciones de carga.
● Desarrollo de otras funciones
Además, en el lado del motor, también hemos desarrollado funciones como el acoplamiento Spark Ranger , la optimización de la vista materializada Spark y el aislamiento de carga de clases en modo Flink Session para mejorar el rendimiento informático del motor y al mismo tiempo mejorar la seguridad y escalabilidad de las tareas del motor.
Resumir
En resumen, el lanzamiento de EMR6.2 marca otro hito importante para Kangaroo Cloud en el campo de los servicios de big data. A través de la optimización de cuatro funciones principales, incluida la actualización y actualización integral de la interfaz de usuario, la configuración diferenciada, la migración de clústeres y la actualización del motor, EMR6.2 proporciona a los usuarios una plataforma de motor informático de big data más potente, flexible y eficiente , que ayuda a las empresas en la gestión de datos y salto cualitativo en el análisis.
Dirección de descarga del "Libro técnico del sistema de indicadores industriales": https://www.dtstack.com/resources/1057?src=szsm
Dirección de descarga del "Informe técnico del producto Dutstack": https://www.dtstack.com/resources/1004?src=szsm
Dirección de descarga del "Libro técnico sobre prácticas de la industria de gobernanza de datos": https://www.dtstack.com/resources/1001?src=szsm
Para aquellos que quieran saber o consultar más sobre productos de big data, soluciones industriales y casos de clientes, visite el sitio web oficial de Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Linus se encargó de evitar que los desarrolladores del kernel reemplazaran las pestañas con espacios. Su padre es uno de los pocos líderes que puede escribir código, su segundo hijo es el director del departamento de tecnología de código abierto y su hijo menor es un núcleo de código abierto. Colaborador Robin Li: El lenguaje natural se convertirá en un nuevo lenguaje de programación universal. El modelo de código abierto se quedará cada vez más atrás de Huawei: tomará 1 año migrar completamente 5,000 aplicaciones móviles de uso común a Hongmeng, que es el lenguaje más propenso. Vulnerabilidades de terceros. Se lanzó el editor de texto enriquecido Quill 2.0 con características, confiabilidad y experiencia de desarrolladores que Ma Huateng y Zhou Hongyi se dieron la mano para "eliminar los rencores". La fuente de Laoxiangji no es el código, las razones detrás de esto son muy conmovedoras. Google anunció una reestructuración a gran escala.