
Bienvenido al informe de actualización de funciones del producto Kangaroo Cloud 09. En este informe, nos adherimos al concepto de igual énfasis en la innovación y la optimización, y llevamos a cabo un pulido en profundidad y una actualización integral del producto. La mejora de cada detalle es nuestra búsqueda incansable de una excelente calidad. Esperamos que estas nuevas funciones puedan ayudar a las operaciones y el desarrollo de su negocio, facilitando el camino hacia la transformación digital.
El siguiente es el contenido del Informe de actualización de funciones del producto Kangaroo Cloud, número 09. Para obtener más información, continúe leyendo.
Plataforma de desarrollo fuera de línea
Nuevas actualizaciones de funciones
1.Plantilla de tareas
Antecedentes: los clientes esperan mantener plantillas de código comunes diarias fuera de línea y hacer referencia a ellas directamente durante el desarrollo de datos.
La diferencia entre plantillas y componentes:
1. Se admite la edición después de hacer referencia al código de la plantilla, pero no se admite la edición después de hacer referencia al componente.
2. Los cambios de plantilla no afectarán las tareas a las que se hace referencia, pero los cambios de componentes sí afectarán las tareas a las que se hace referencia.
Descripción de la nueva función: admite plantillas de código de proyecto y plantillas de código de inquilino para cada tipo de tarea, y admite plantillas de código de referencia al crear tareas .
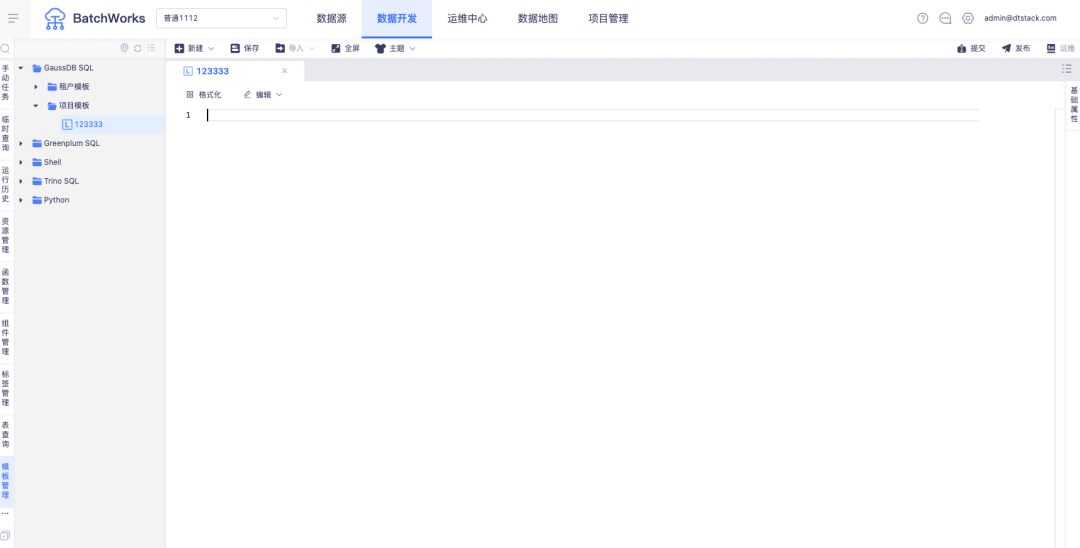
2.shell en el agente/python en el agente agrega un nuevo control de dimensión del proyecto
fondo:
Shell on Agent es un tipo de tarea especial para plataformas fuera de línea.
La tarea de Shell no se ejecuta directamente en la máquina implementada en el clúster, sino que el Shell se ejecuta en un nodo de servidor implementado de forma independiente. Debido a que una tarea fuera de línea requiere dos núcleos, si hay muchas tareas de Shell en el escenario del cliente, es fácil llenar los recursos del clúster . Por lo tanto, ejecutar tareas como Shell y Python en nodos implementados de forma independiente puede reducir eficazmente la presión sobre el clúster.
Actualmente existe un problema, siempre que el cliente configure el nodo y el usuario del servidor en EM y la consola, todos los proyectos del clúster pueden utilizar el nodo y el usuario del servidor configurados. Esto plantea un problema de seguridad. Por ejemplo, para usuarios con permisos altos, como root, los clientes prestan más atención a los problemas de seguridad y no quieren que todos los proyectos puedan usar esta cuenta. Por lo tanto, es necesario diseñar una solución que pueda controlar la configuración de los nodos del servidor. y usuarios del servidor para resolver este problema.
Descripción de nuevas características:
1. La consola controla los permisos de usuario del nodo y del servidor a través de la autorización del proyecto.
2. Las tareas en proyectos fuera de línea admiten la selección de usuarios y nodos de servidor autorizados.
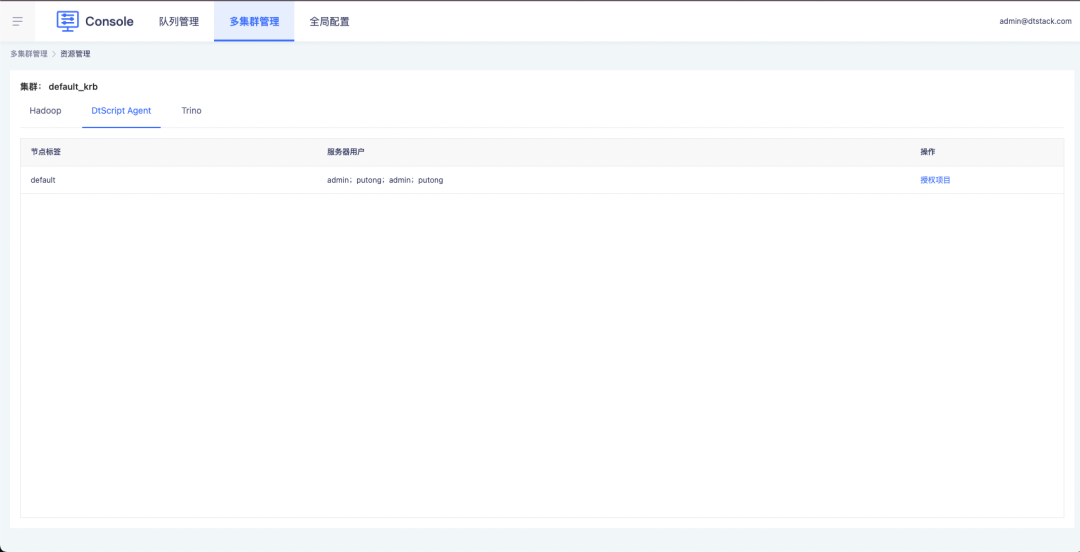
Optimización de funciones
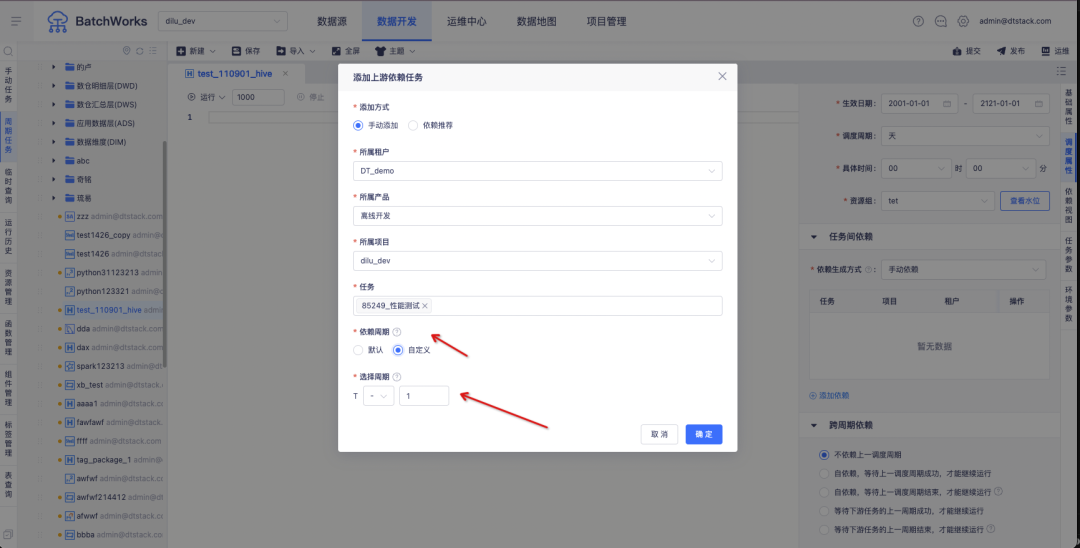
1. Optimización de la configuración de programación, que puede controlar cualquier instancia periódica que dependa de tareas ascendentes.
fondo:
Actualmente, la programación de tareas de Zhongtian solo puede depender de la instancia ascendente del ciclo actual. Los clientes pueden tener los siguientes escenarios:
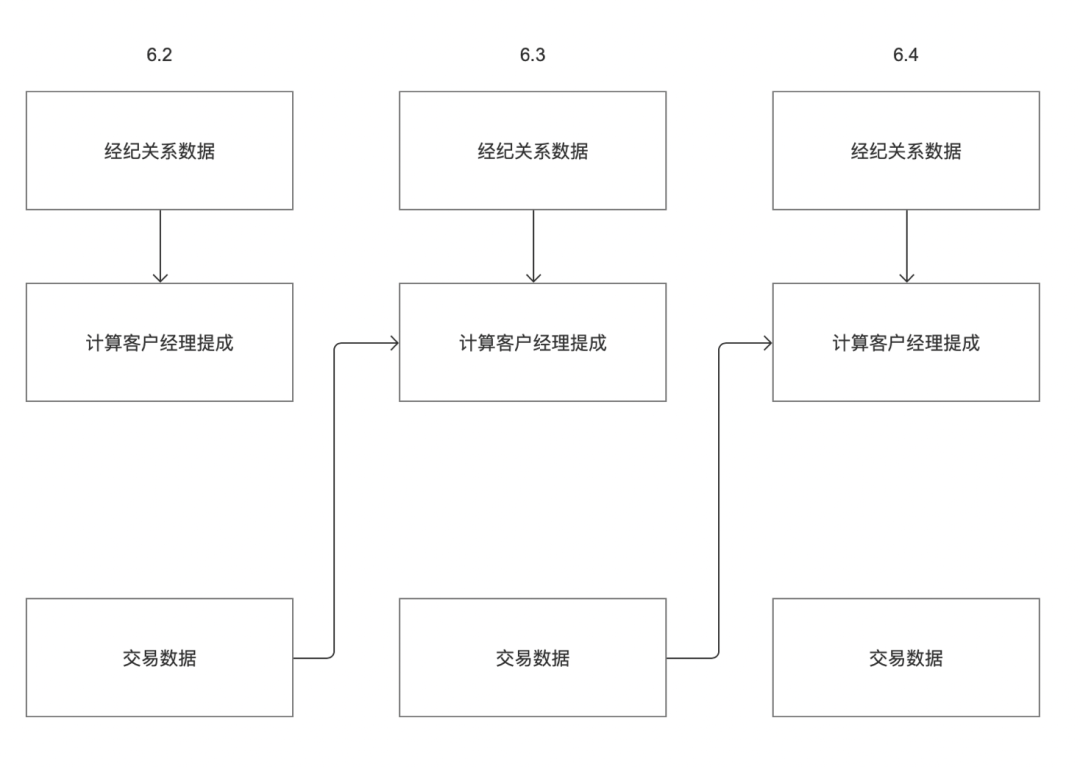
Por ejemplo, un cliente tiene dos sistemas comerciales, "datos de la relación de corretaje" y "datos de la transacción". La comisión del cliente el 3 de junio debe calcularse en función de los "datos de la relación de corretaje" y los "datos de la transacción", respectivamente. Como se muestra en la figura anterior, la hora de salida de los datos del sistema empresarial de "datos de relaciones de corretaje" del 2 de junio es el 3 de junio y la hora de salida de los datos del sistema empresarial de "datos de transacciones" del 2 de junio es la tarde del 2 de junio;
De acuerdo con la lógica actual de dependencia ascendente y descendente fuera de línea, la tarea "Calcular la comisión del administrador de cuentas" solo puede obtener tareas el 3 de junio, pero no puede obtener tareas el 2 de junio. Por lo tanto, debe modificarse para admitir la configuración de dependencia de la instancia de tarea, que Se puede personalizar el ciclo.
Instrucciones de optimización de la experiencia:
Admite la personalización del ciclo de programación de tareas ascendentes dependientes .
T representa el tiempo planificado de la tarea actual (tarea posterior), "+ -" representa la dirección de desplazamiento, "+" representa el tiempo de desplazamiento hacia el futuro, "-" representa el tiempo de desplazamiento hacia el pasado y "-" es seleccionado por defecto.
El desplazamiento es un cuadro de entrada numérico con un valor máximo de 10 y un valor mínimo de 1, que representa el número de ciclos de tareas ascendentes del desplazamiento.
Plataforma de desarrollo en tiempo real
Nuevas actualizaciones de funciones
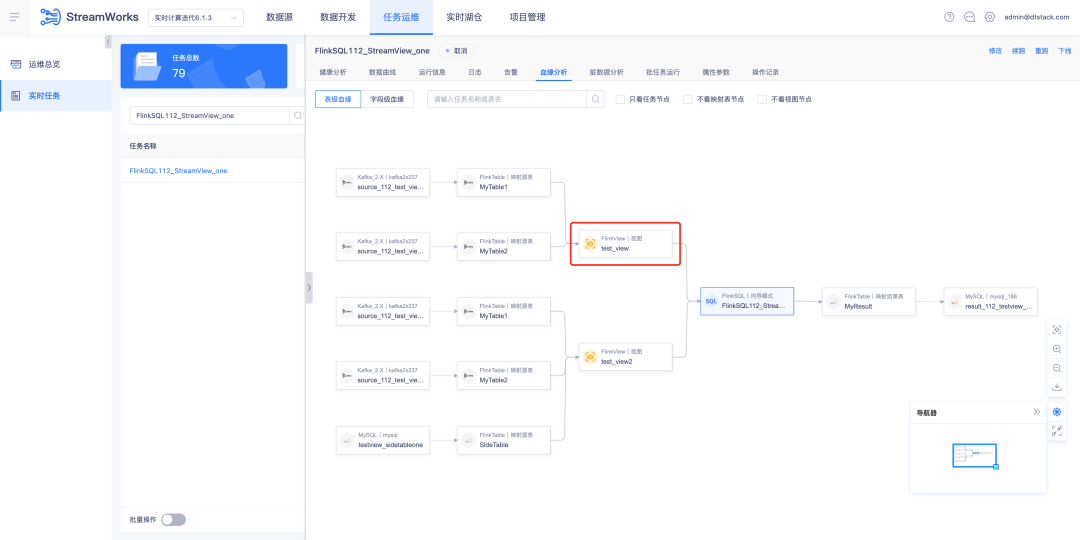
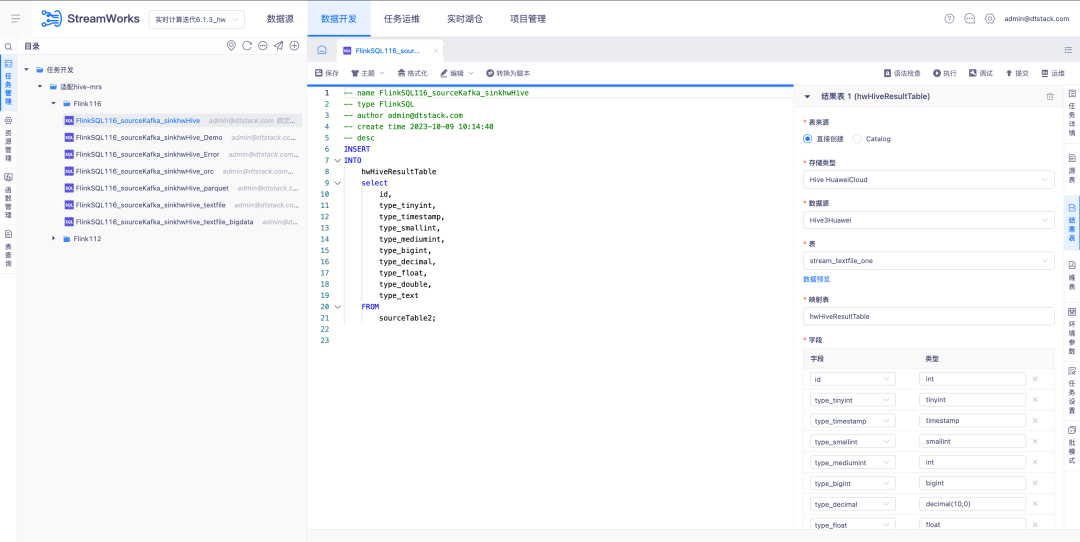
1. Ver análisis de linaje
Antecedentes: actualmente, SQLParser no admite el análisis de linaje de vistas de FlinkSQL. Sin embargo, en escenarios de desarrollo generales, si la tarea involucra más de tres tablas, muchas reuniones optan por crear vistas en el IDE para facilitar la lectura de la lógica SQL.
Función:
1. SQLParser admite la tabla de vista FlinkSQL para mostrar el análisis de relaciones sanguíneas
2. Operación y mantenimiento de tareas: tareas en tiempo real: detalles de la tarea FlinkSQL: función de visualización de análisis de línea sanguínea
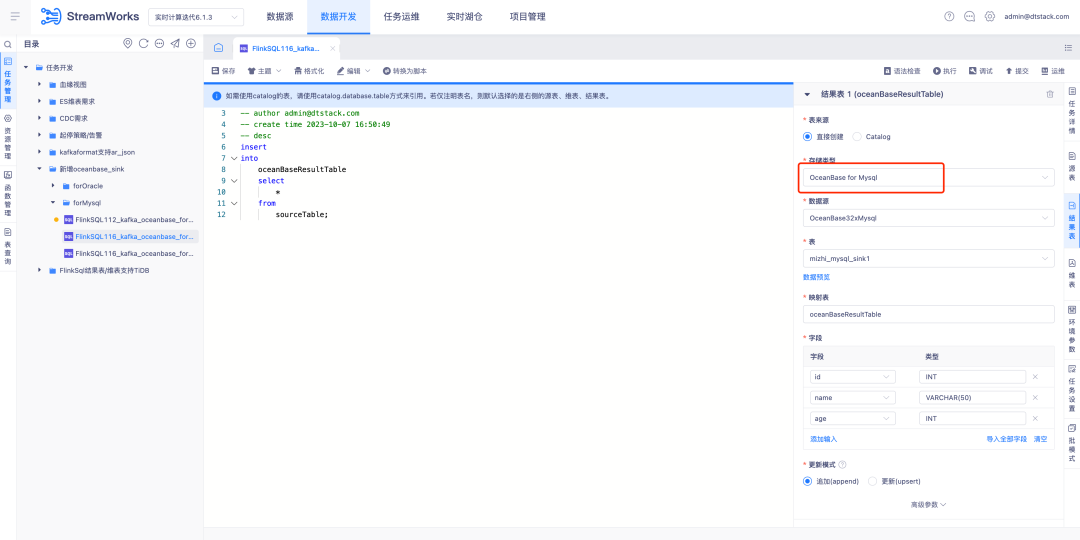
2.FlinkSQL admite Oceanbase Sink
FlinkSQL versión 1.16 admite tablas de resultados de OceanBase y es compatible con los modos MySQL y Oracle de OceanBase versión 4.2.0, lo que brinda a los usuarios capacidades de procesamiento de datos más flexibles y eficientes.
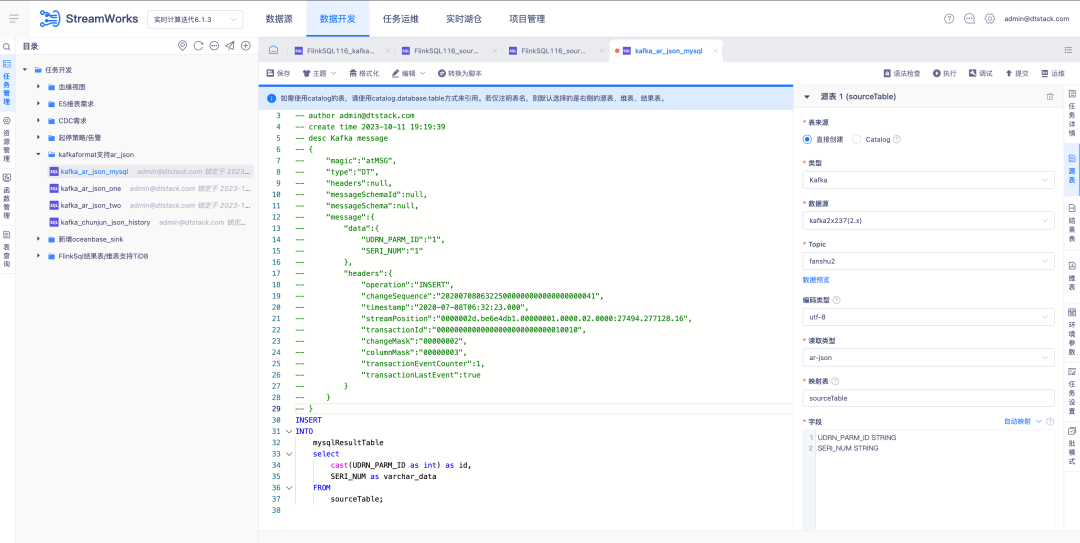
3. El tipo de lectura Kafka de la tabla fuente es compatible con AR Json
Antecedentes: OGG y Attunity Replicate son dos productos comerciales ampliamente utilizados en el extranjero. Para satisfacer mejor las necesidades de los clientes, debemos asegurarnos de que el formato JSON de Kafka sea compatible con el tipo de lectura AR Json.
Descripción de la nueva característica: tabla fuente de la versión FlinkSQL1.16 El tipo de lectura Kafka admite el tipo AR Json y admite funciones relacionadas con el mapeo automático para analizar Json.
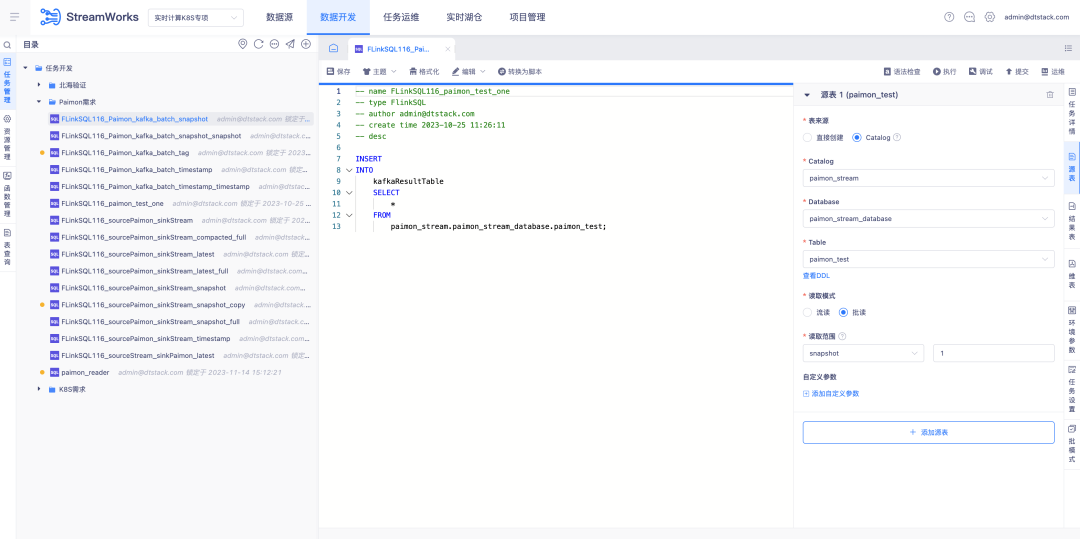
4. Soporte de Paimon en el almacén del lago en tiempo real
Antecedentes: con el desarrollo de Paimon, esta vez es necesario iterar un nuevo modelo de desarrollo FlinkSQL. Utilizando este modelo, el módulo de gestión del almacén del lago se puede unir a lo largo de toda la cadena.
Descripción de nuevas características:
1. La administración del almacén de Lake agrega la capacidad de agregar, eliminar, modificar y consultar tablas de Paimon.
2. Agregue la función de configuración visual de la tabla Paimon a la plataforma de desarrollo de datos.
3. La plataforma de desarrollo de datos utiliza el IDE para completar las funciones de lectura y escritura de la tabla Paimon.
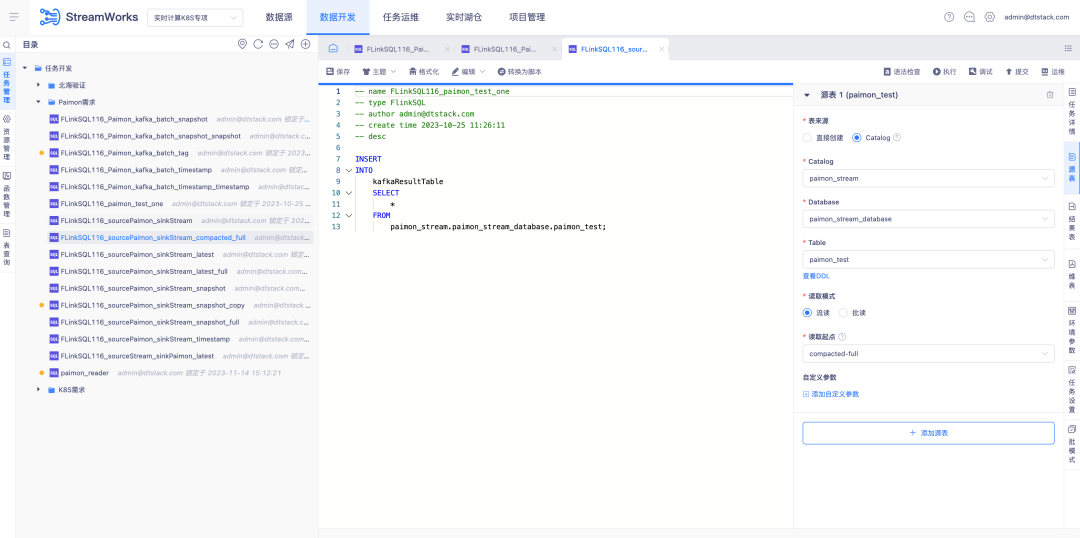
5.FlinkCDC integrado de FlinkSQL
Antecedentes: FlinkCDC es un componente de recopilación en tiempo real de código abierto con una velocidad de iteración muy rápida. El marco Flink subyacente en el que se basa también es el mismo que el marco ChunJun que utilizamos. Por lo tanto, consideramos convertirlo en un componente predeterminado para la implementación de plataformas en tiempo real y empaquetarlo en nuestro sistema.
Descripción de nuevas características:
1. Paquete de implementación predeterminado en tiempo real, trae la configuración de recopilación en tiempo real de FlinkCDC
2. Modo de script de plataforma, debe verificar las capacidades de recopilación integradas de FlinkCDC y los conectores compatibles
3. El modo de asistente de plataforma configurará la colección de conectores admitida por FlinkCDC de acuerdo con la situación del proyecto.
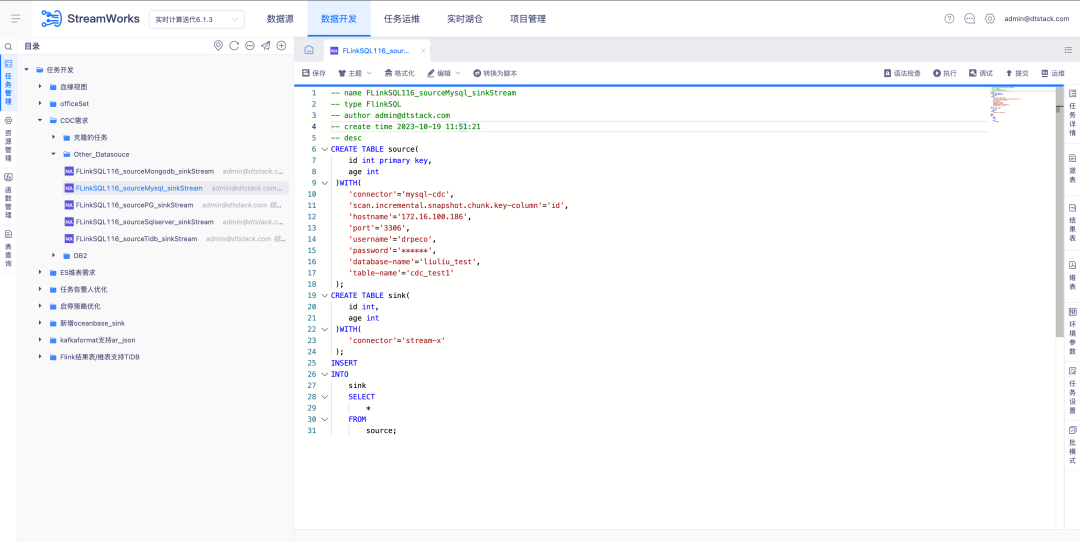
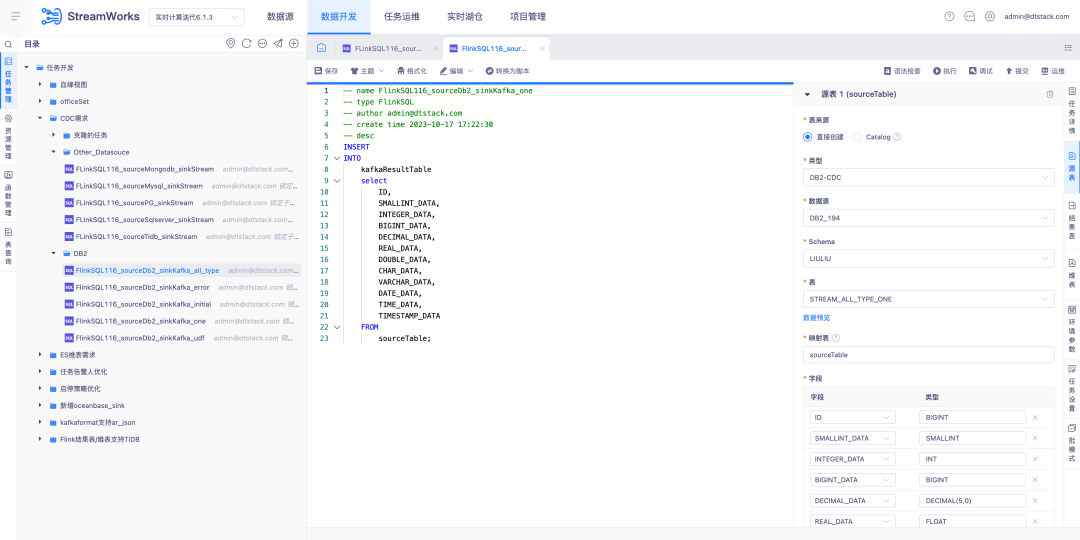
6.FlinkSQL admite la fuente de datos FlinkCDC DB2
Antecedentes: los clientes deben admitir la recopilación de DB2 en tiempo real. Teniendo en cuenta que el desarrollo del conector CDC es difícil, FinkCDC simplemente lo admite, por lo que la capa inferior toma prestadas las capacidades de FlinkCDC.
Descripción de la nueva función: la plataforma en tiempo real admite el modo de asistente para configurar la tabla de origen como origen de datos DB2-CDC .
Optimización de funciones
1.Optimización de la lógica de continuación.
Antecedentes: cuando una tarea en tiempo real se reanuda a través de CheckPoint y continúa ejecutándose, es necesario seleccionar manualmente un punto de tiempo. Sin embargo, de hecho, la mayoría de los escenarios de continuación seleccionan el último CheckPoint.
Descripción de la optimización de la experiencia: al optimizar para restaurar y continuar ejecutando CheckPoint , se seleccionará automáticamente el CheckPoint más cercano dentro de la fecha.
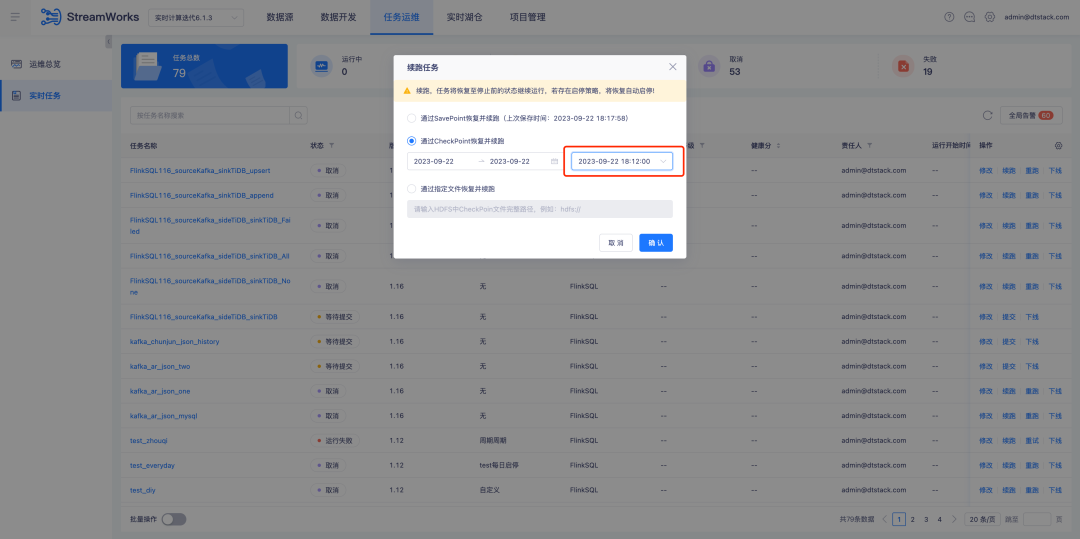
2. Estrategia start-stop/optimización externa
Antecedentes: durante el uso en profundidad por parte de los clientes, descubrimos que aspectos como la estrategia de inicio y parada, el envío y la repetición se pueden optimizar para lograr un flujo de trabajo más eficiente y una mejor experiencia de usuario.
Actualmente, la configuración de la marca de tiempo externa en nuestras tablas de fuentes de desarrollo de datos está arreglada. Sin embargo, en escenarios de computación de tareas en tiempo real, algunos clientes solo se centran en el cálculo de datos del día, por lo que configuran una política de inicio y parada para volver a ejecutar la tarea todos los días. Quieren poder volver a ejecutar la tarea a partir de la medianoche todos los días, en lugar de utilizar una marca de tiempo fija. Aunque en teoría Latest puede cumplir con este requisito, el consumo de tiempo de inicio de la tarea en tiempo real puede hacer que el tiempo de ejecución real se desvíe de cero, lo que provocará errores de datos.
Instrucciones de optimización de la experiencia:
1. Optimice la configuración de la política start-stop , ahora admita la política start-stop entre días y mejore la interacción actual de la página de la política start-stop para proporcionar una experiencia operativa más eficiente y conveniente
2. Desarrollo de datos: tabla de origen, admite configuración parametrizada de ubicaciones externas
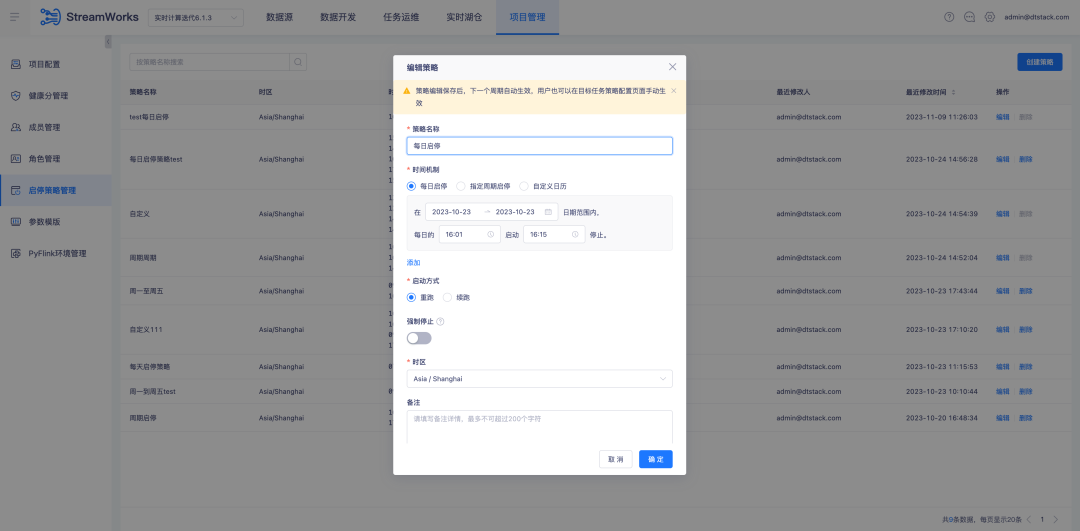
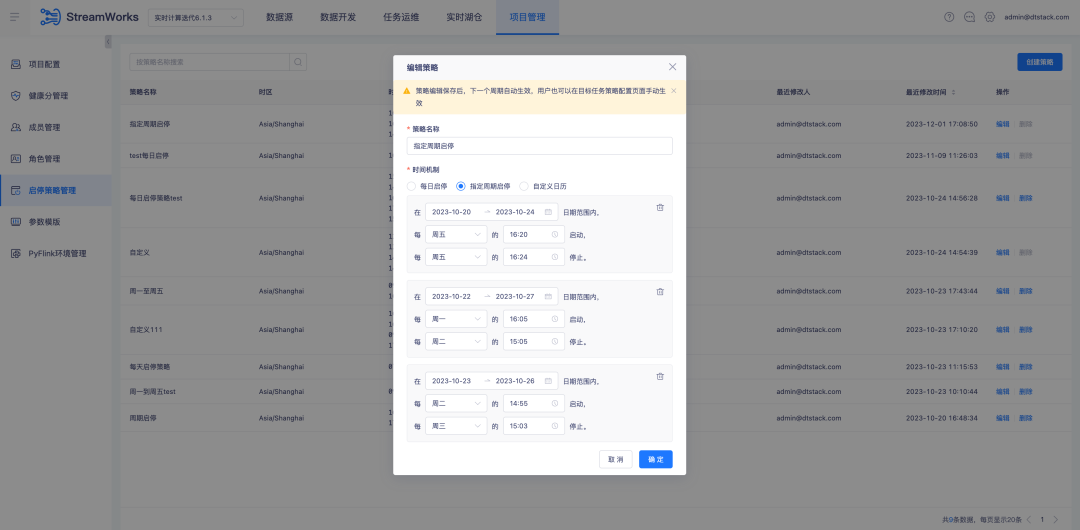
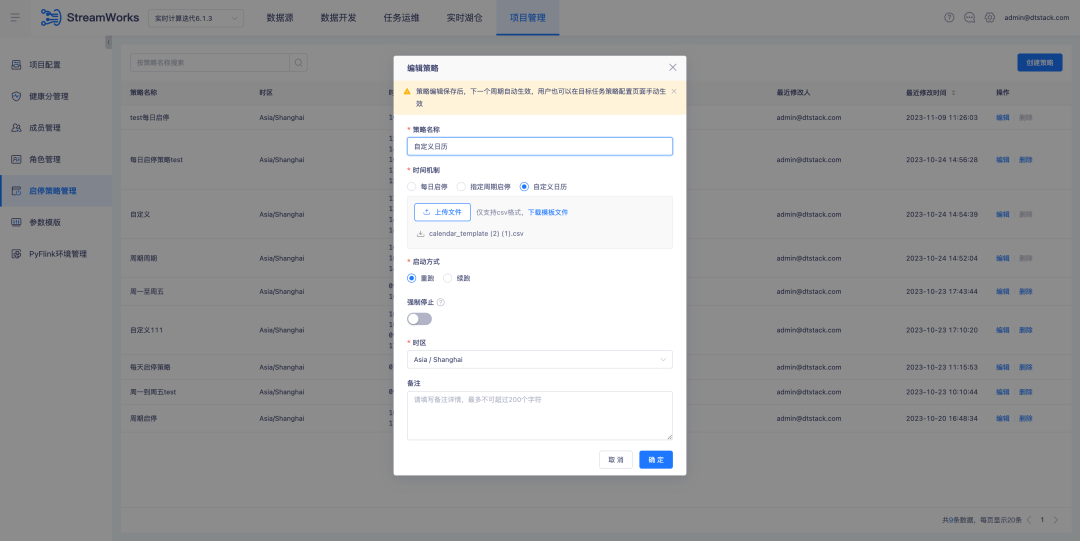
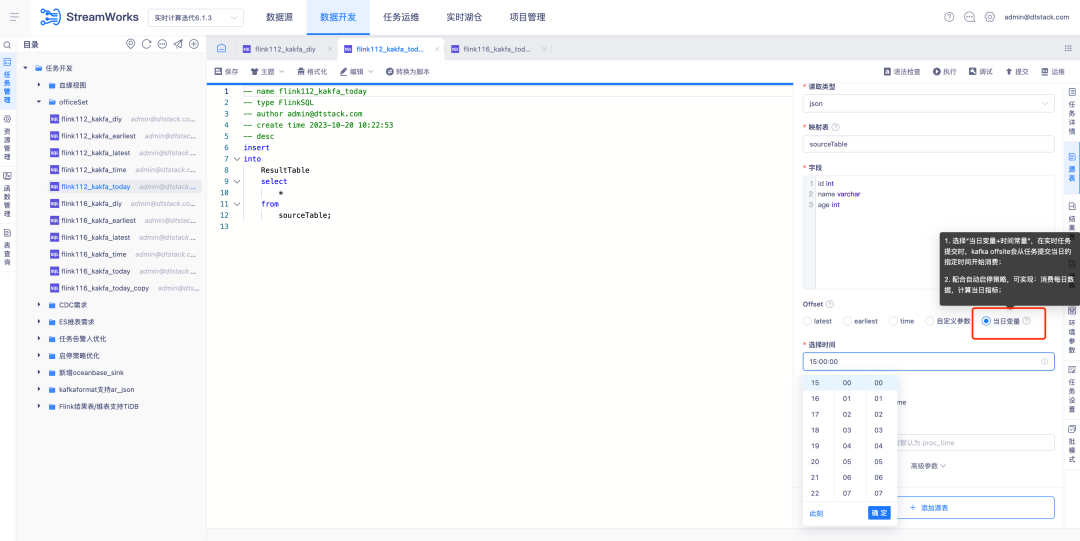
3.Optimización del complemento FlinkSQL1.16 versión ES7.x
Antecedentes: el complemento ES de FlinkSQL versión 1.10 admite la configuración del tiempo de espera de la tabla de dimensiones y el límite de datos de tiempo de espera. Esta función no está disponible temporalmente en la versión actual de FlinkSQL 1.16 y se está optimizando activamente.
Instrucciones de optimización de la experiencia:
La tabla de dimensiones del complemento ES7.x de FlinkSQL1.16 configura table.exec.async-lookup.timeout o utiliza la sintaxis de sugerencias para establecer el tiempo de espera. Cuando la tarea se ejecuta en el modo LRU de la tabla de dimensiones, el tiempo de espera de la consulta asincrónica toma . efecto.
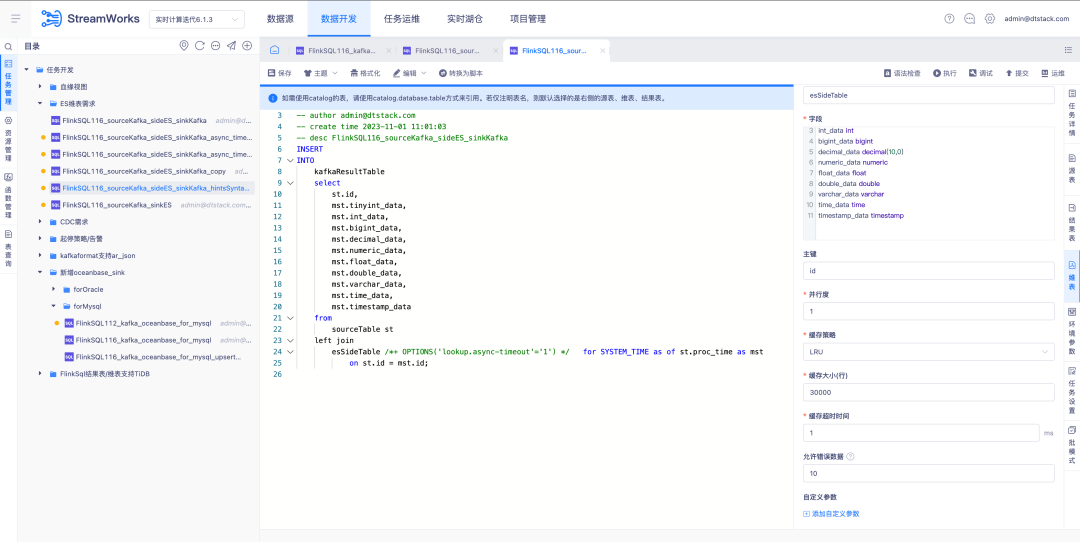
4.Optimización de la configuración de alarmas
Antecedentes: en las reglas de alarma de tareas, la configuración de recepción de alarmas debe seleccionarse manualmente. No es posible hacer coincidir y enviar información de alarma automáticamente según la persona responsable de la tarea. Al mismo tiempo, en la configuración de alarma global, también es posible. imposible enviar automáticamente la información de alarma correspondiente según la persona responsable de la tarea.
Instrucciones de optimización de la experiencia:
1. Ajuste del destinatario de la configuración de la regla de alarma de tarea única . La persona responsable de la tarea se selecciona de forma predeterminada. Se pueden seleccionar otros destinatarios a través del cuadro de selección.
2. La configuración de la regla de alarma global en realidad se enviará a la persona responsable de cada tarea cuando se marque la persona responsable de la tarea. Cuando se seleccionan otros destinatarios, la tarea seleccionada se enviará al destinatario seleccionado cuando la tarea seleccionada sea anormal.
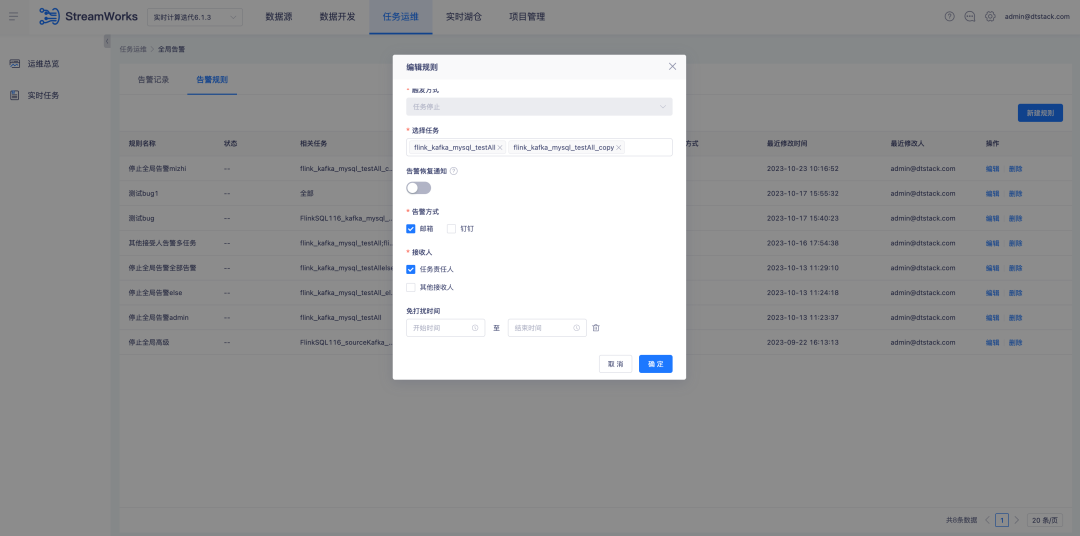
5.La plataforma del complemento Tidb versión FlinkSQL1.12 y 1.16 es compatible
Antecedentes: las versiones 1.12 y 1.16 de FlinkSQL han completado la adaptación a Tidb. Sin embargo, la capa de plataforma solo se ha adaptado en la versión 1.10, por lo que las versiones 1.12 y 1.16 no son compatibles.
Instrucciones de optimización de la experiencia:
La plataforma en tiempo real es compatible con el complemento Tidb versión 1.12 y 1.16 y debe admitir tablas de dimensiones y tablas de resultados.
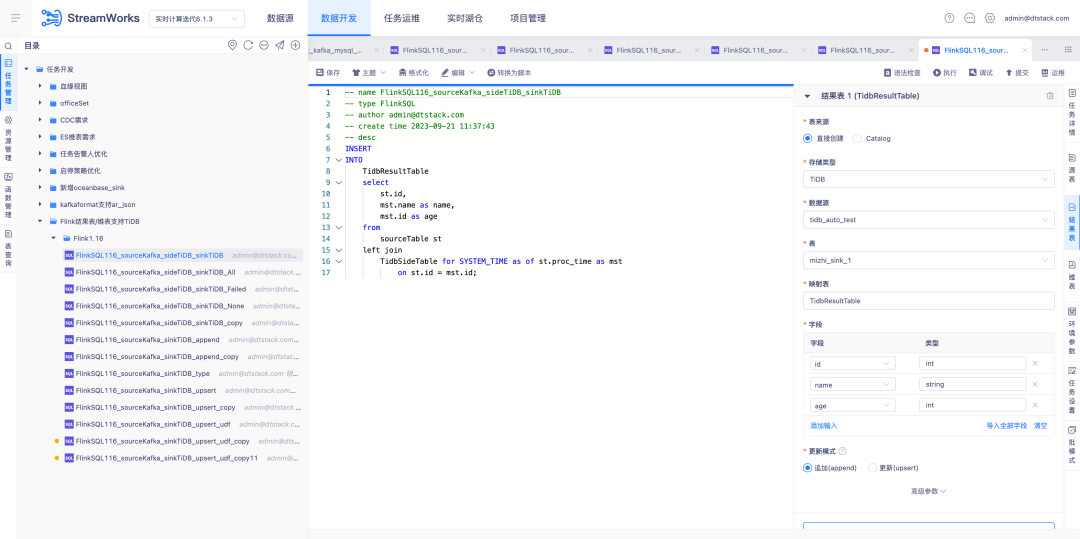
6.FlinkSQL1.12 y 1.16 versión Hive adaptación a huaweiCloud
Antecedentes: la copia de seguridad en tiempo real de los datos de Kafka se ingresa en MRS Hive. Cuando hay un problema con los datos de cálculo en tiempo real, se pueden analizar los mensajes de copia de seguridad en Hive.
Instrucciones de optimización de la experiencia:
Las versiones 1.12 y 1.16 de FlinkSQL están adaptadas a Hive huaweiCloud. El centro de origen de datos, el motor y la plataforma se desarrollan simultáneamente para admitir la tabla de resultados de Hive huaweiCloud . Debe prestar atención al escenario de habilitación de Kerberos.
plataforma de servicios de datos
Nuevas actualizaciones de funciones
1. Admite API de creación de versión HBase TBDS
Se agregó la API de creación de versiones HBase TBDS, que incluye: API de generación en modo asistente , importación y exportación, y publicación en proyectos de destino.

Optimización de funciones
1.La fuente de datos de Oracle admite DML
Mejorar las fuentes de datos soportadas por DML .
2. El análisis de comentarios en modo SQL personalizado ya no sobrescribe la descripción
Antecedentes: para la lógica histórica, después de volver a analizar el esquema SQL personalizado para la base de datos, los comentarios que vienen con la base de datos sobrescribirán las instrucciones modificadas.
Instrucciones de optimización de la experiencia: modifique la lógica histórica para las instrucciones modificadas, los comentarios en la base de datos ya no se sobrescribirán después del nuevo análisis.
3. Una vez habilitados los permisos a nivel de fila, no es necesario completarlos de forma predeterminada.
Antecedentes: para los permisos históricos a nivel de fila, los permisos a nivel de fila se habilitarán desde los campos de la tabla. Después de habilitarlos, los campos serán obligatorios de forma predeterminada y no se admitirá la cancelación por parte del usuario.
Descripción de la optimización de la experiencia: esta iteración ajusta la lógica histórica. Los permisos a nivel de fila se habilitarán desde el nivel de API. Después de habilitarse, cuando la API use la tabla, estará restringida por permisos a nivel de fila.
4. Versión del marco y actualización de componentes.
Se actualiza la versión del marco Spring Cloud (Boot) y el componente Nacos se actualiza para reducir la probabilidad de vulnerabilidades y mejorar la estabilidad de la API en sí.
Plataforma de información de datos del cliente
Nuevas actualizaciones de funciones
1. Admite funciones UDF personalizadas
Antecedentes: el número de teléfono móvil, el número de identificación y otros datos involucrados en los datos procesados por el cliente son datos cifrados. Desde una perspectiva de auditoría, este tipo de datos no se pueden mostrar en texto sin formato, pero habrá escenarios en los que el contenido de texto sin formato sí lo será. mostrado en el negocio de nivel superior. Por ejemplo: marketing por SMS basado en números de teléfono móvil.
Los clientes deben retrasar el proceso de descifrado lo más posible, colocarlo en la plataforma de etiquetas para completarlo y agregar etiquetas personalizadas a través de la personalización de la función UDF para completar el procesamiento.
Descripción de nuevas funciones: se ha agregado un nuevo módulo de administración de funciones al centro de etiquetas , bajo el cual se pueden crear, ver y eliminar funciones UDF (solo las versiones Trino385 y superiores admiten la creación de funciones)
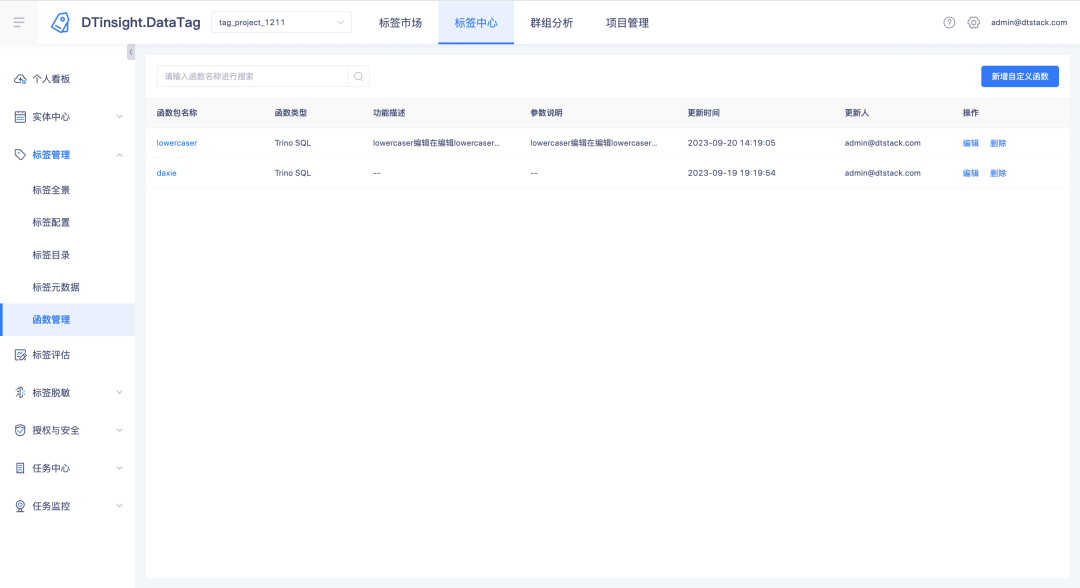
Para las funciones cargadas, puede hacer clic en el nombre de la función para ver los detalles de la función.
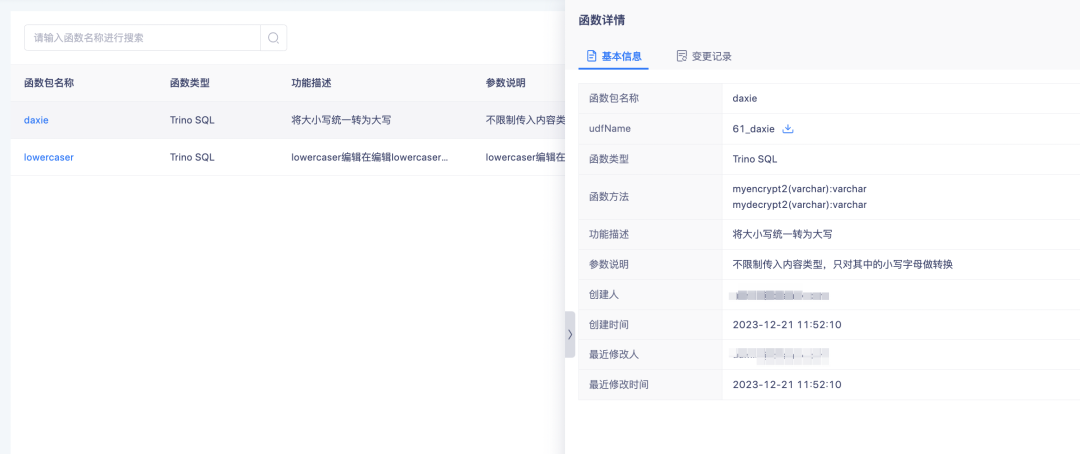
La función cargada se utiliza principalmente para procesar etiquetas SQL derivadas.
2. Admite el procesamiento de etiquetas de valores múltiples
Antecedentes: las reglas de procesamiento actuales para etiquetas derivadas y etiquetas combinadas son que cuando una instancia alcanza por primera vez una determinada condición de regla, el valor de etiqueta correspondiente se marcará en la instancia y otros valores de etiqueta ya no coincidirán. , los resultados de la etiqueta de valor único se almacenarán en la base de datos.
Sin embargo, en aplicaciones prácticas, las condiciones no son necesariamente excluyentes entre sí. Por ejemplo, al usuario se le asigna una etiqueta de preferencia de producto basada en la cantidad de veces que ha comprado un tipo específico de producto. A un usuario le pueden gustar tanto muebles como ropa. En este caso, es necesario admitir múltiples valores.
Descripción de nuevas características:
Las etiquetas de reglas derivadas, las etiquetas SQL derivadas, las etiquetas combinadas y el procesamiento de etiquetas personalizadas admiten la configuración como etiquetas de valores múltiples y el sistema las calcula en función del tipo de valor de etiqueta establecido.
• Etiquetas de un solo valor: coinciden en orden según la configuración de la regla. Dejan de coincidir cuando se alcanza un determinado valor de etiqueta. Hay como máximo un valor de etiqueta en el resultado de los datos.
• Etiquetas de valores múltiples: coincida en secuencia según el orden de configuración de la regla. Cada regla coincidirá una vez. Habrá como máximo n valores de etiqueta configurados en el resultado de los datos.
Según los resultados del cálculo, los detalles de la etiqueta contarán la cantidad de instancias para cada etiqueta individual, es decir, la suma de la cantidad de instancias cubiertas por cada valor de etiqueta de una etiqueta de valor único es la cantidad de instancias cubiertas por la etiqueta. y el número de instancias cubiertas por cada valor de etiqueta de una etiqueta de varios valores. La suma de los números es mayor o igual que la cantidad de instancias de cobertura de etiqueta.
3. Centro de negocios de acoplamiento de funciones personalizado
Antecedentes: anteriormente, los roles eran roles integrados en el sistema y los roles no se podían agregar, modificar o eliminar. Los permisos de los roles no se podían personalizar. Las funciones eran demasiado fijas y no se podían ajustar de manera flexible de acuerdo con los escenarios comerciales reales. clientes en la versión 6.0, el centro de negocios ha agregado la función de función de personalización, la etiqueta del producto está conectada a esta función del centro de negocios para lograr los siguientes efectos:
1. Apoyar nuevos roles
2. Admite permisos de roles personalizados
Nueva descripción de la función: configure los roles y los permisos de sus indicadores en el centro de negocios, y la plataforma de etiquetado introducirá automáticamente los resultados de la configuración de permisos para su consulta.
1. Agregue nuevos roles y configure puntos de permiso de roles en el centro de negocios:
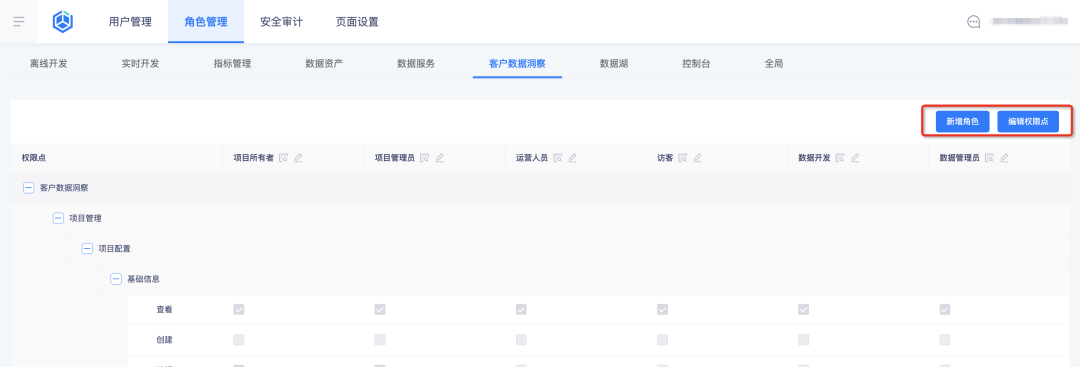
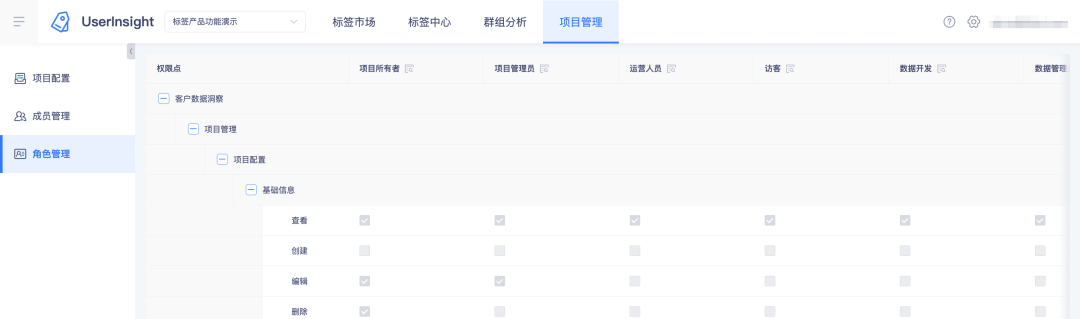
2. Ver roles y sus puntos de permiso en la plataforma de etiquetas:
4. El formato de visualización de datos admite personalización
Antecedentes: para las etiquetas numéricas, actualmente no se admite la configuración de la precisión de visualización, lo que da como resultado una visualización de página irregular. Algunas muestran números enteros como 1 y otras muestran decimales como 1.234. La experiencia de lectura general no es alta para mejorar al usuario. experiencia, es necesario agregar configuraciones de reglas de visualización de datos.
Descripción de nuevas características:
1. Al crear/editar entidades, editar etiquetas atómicas y crear/editar etiquetas SQL derivadas, se admite establecer reglas de visualización para etiquetas numéricas.
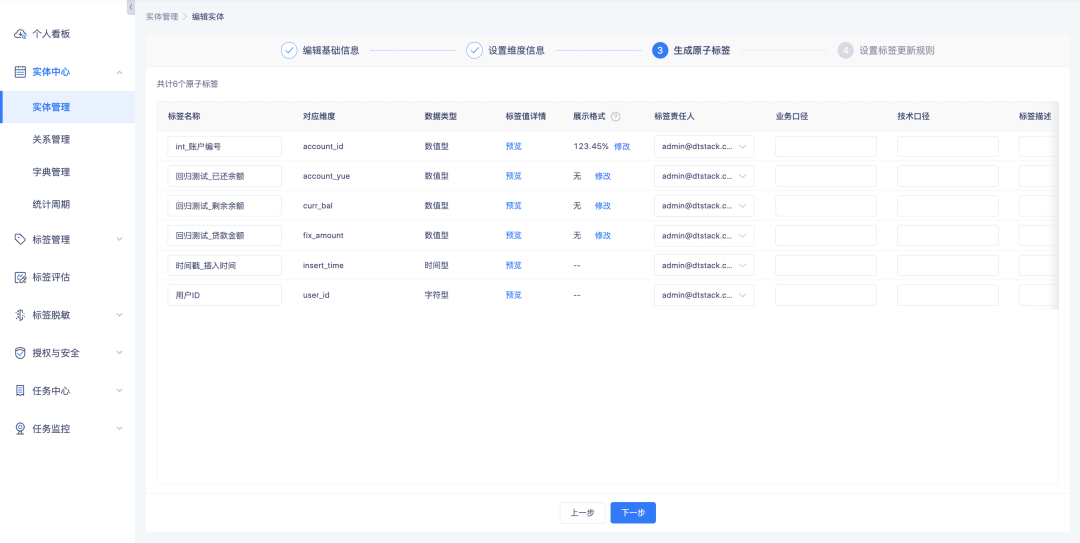
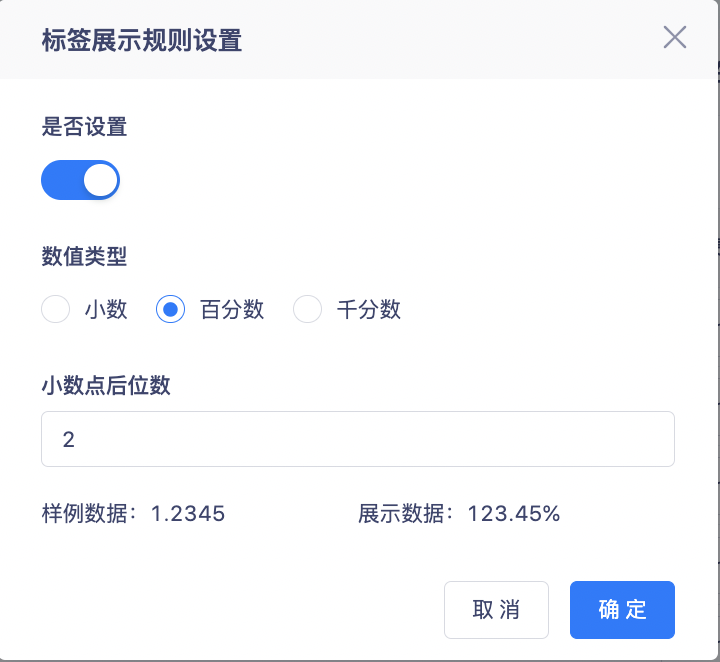
2. Admite la visualización como decimales, porcentajes y milésimas, y admite la configuración del número de dígitos después del punto decimal.
3. Los datos de etiquetas que se muestran en las páginas relacionadas con el grupo se muestran de acuerdo con las reglas de visualización establecidas.
5. La carga de archivos de etiquetas/grupos permite ver el progreso de la carga.
Antecedentes: la función de importación de archivos actualmente se carga sin mensajes de progreso. Cuando el archivo es demasiado grande, el tiempo de espera es largo, lo que hará que los usuarios malinterpreten que la página está bloqueada. Es necesario agregar mensajes de progreso para aclarar el progreso actual. usuarios.
Descripción de nuevas características:
1. Se agregaron indicaciones de progreso durante las tareas de etiquetas, carga de archivos grupales y consultas sin conexión.
2. La carga de archivos grupales se ha ajustado para admitir la carga de archivos de hasta 500 M de tamaño.
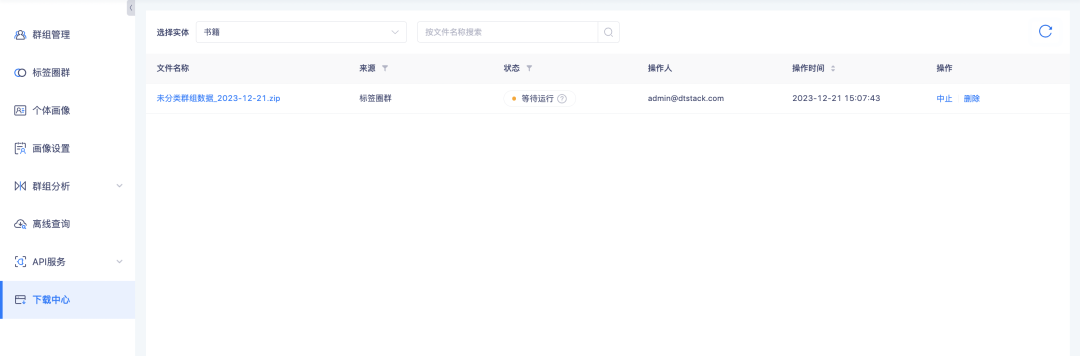
6. El centro de descarga permite consultar el progreso de la descarga.
Antecedentes: durante el proceso de descarga de datos, debido a la gran cantidad de datos, se necesita mucho tiempo para prepararlos antes de que se puedan descargar. Los usuarios no lo esperan cuando los usan y deben actualizarlos con frecuencia para determinar si se realiza la descarga. puede ser llevado a cabo. Es necesario agregar indicaciones de progreso de la descarga para guiar a los usuarios a determinar cuánto tiempo deben esperar.
Nueva descripción de la función: el estado de la tarea del centro de descargas agrega el estado de espera para ejecutarse y de cancelación. Entre ellos, la descarga de etiqueta círculo grupo-lista de grupo, detalles del grupo-lista de grupo, carga de lista de instancias de grupo local, consulta fuera de línea-detalles de grupo-lista de instancias, intersección de grupo y lista de instancias de diferencia depende de los datos de la lista de grupo. el volumen de descarga es grande, se ejecutará en modo de descarga en serie. Las tareas relacionadas con la lista de grupos se pondrán en cola para su ejecución en secuencia. Las otras descargas con volúmenes de datos pequeños se ejecutarán directamente. . Mientras se ejecutan las tareas, puede cancelar las tareas que ya no sean necesarias.
Optimización de funciones
1. La exportación de datos se ajusta para descargar archivos a través del centro de descargas.
Antecedentes: las descargas de archivos en algunas páginas se descargan directamente, lo que hace que el botón esté siempre en estado de ejecución y el usuario no pueda percibir el progreso de la descarga.
Descripción de la optimización de la experiencia: después de hacer clic en el botón relacionado con la exportación de datos, el archivo se descargará de forma asincrónica. Una vez completada la descarga, puede ingresar al módulo "Centro de descargas" para descargar los detalles de los datos. Los botones de la página involucrados son los siguientes: Etiqueta . Grupo circular : exportación de datos, detalles del grupo, lista de grupo, exportación de datos, carga de grupo local, lista de instancias, exportación de datos, consulta sin conexión, carga de grupo local/intersección de grupo y detalles de diferencia, exportación de datos, intersección de grupo y exportación de datos de diferencia.
Si la cantidad de datos es demasiado grande, el sistema los exportará en archivos separados según el límite superior de la cantidad de registros establecidos por el usuario.
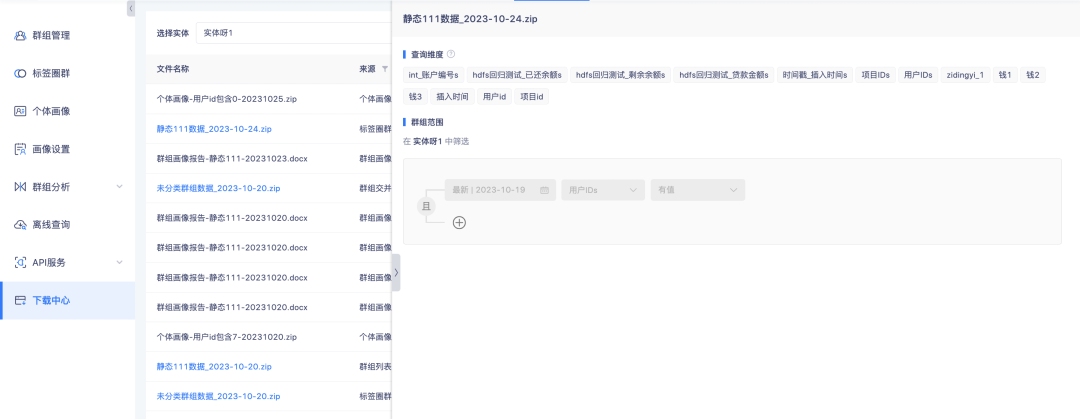
2. Enumerar datos de grupos de círculos de etiquetas y detalles de grupos en el centro de descarga admite la visualización de detalles de configuración.
Antecedentes: actualmente, hay muchas fuentes de archivos en el centro de descarga y es inconveniente distinguir el contenido basándose únicamente en los nombres de los archivos. Es necesario aumentar las fuentes de datos de los archivos para mejorar la disponibilidad de los datos.
Descripción de la optimización de la experiencia: enumere los datos de los grupos de círculos de etiquetas y los detalles del grupo admitan clics. Haga clic en la barra lateral para abrir los detalles de configuración.
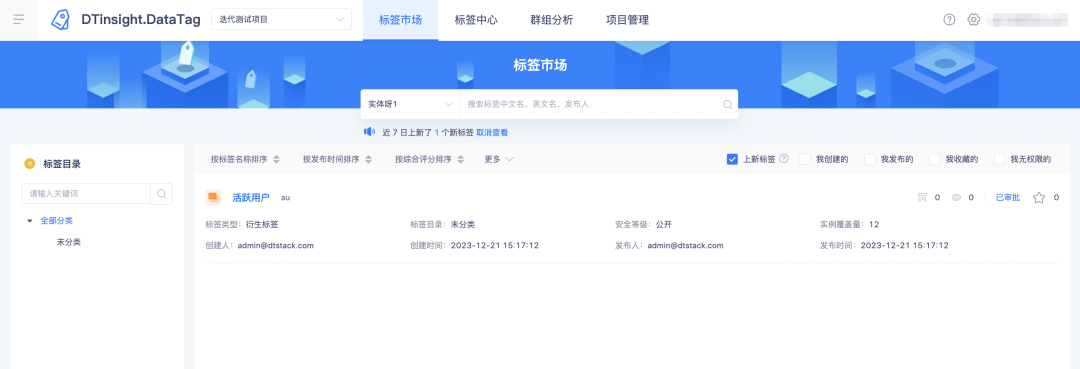
3. Optimización de nuevas funciones de etiquetas en el mercado de etiquetas.
Antecedentes: actualmente, la plataforma no explica la definición de nuevas etiquetas y es necesario agregarlas.
Descripción de optimización de la experiencia: las nuevas etiquetas en la plataforma se definen como las últimas 24 horas, pero en el uso real, las personas generalmente no les prestan atención los fines de semana. Cuando vuelvan a prestar atención el lunes, habrá situaciones en las que las etiquetas actualizadas. No se pueden notificar de viernes a domingo por la mañana. Ajuste la definición a los últimos 7 días.
4. Optimización de la adaptación de permisos de cambio entre subproductos
Cuando un producto etiquetado cambia entre subproductos, faltará el contenido de la pestaña en la página. Esto se debe a problemas de permisos. Esta optimización garantiza que la función esté disponible al cambiar de página entre productos.
5. Admite ajuste y personalización del ancho de la columna
La lista de grupos, la lista de detalles del grupo, la lista de usuarios del grupo de círculos de etiquetas, la lista de intersecciones de grupos y de instancias de diferencias y el ancho de columna de la lista de etiquetas admiten personalización.
Después de personalizar el ancho de la columna, tendrá efecto para usos posteriores según el navegador actual y el usuario que ha iniciado sesión actualmente. Cuando el usuario inicia sesión con un nuevo navegador, borra el caché del navegador actual o vuelve a iniciar sesión. Se mostrarán los ajustes predeterminados.
Plataforma de gestión de indicadores
Nuevas actualizaciones de funciones
1. Centro de negocios de acoplamiento de roles personalizado
Antecedentes: anteriormente, los roles eran roles integrados en el sistema y los roles no se podían agregar, modificar o eliminar. Los permisos de los roles no se podían personalizar. Las funciones eran demasiado fijas y no se podían ajustar de manera flexible de acuerdo con el escenario comercial real del cliente. .
Descripción de nuevas características:
Configure el rol y sus permisos de indicador en el centro de negocios , y la plataforma de indicadores introducirá automáticamente los resultados de la configuración de permisos para la consulta:
1. Agregue nuevos roles y configure puntos de permiso de roles en el centro de negocios
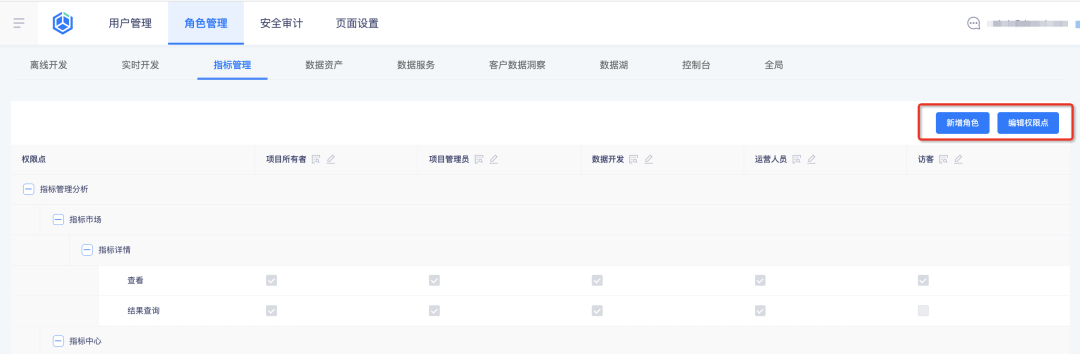
2. Ver roles y sus puntos de permiso en la plataforma de indicadores.
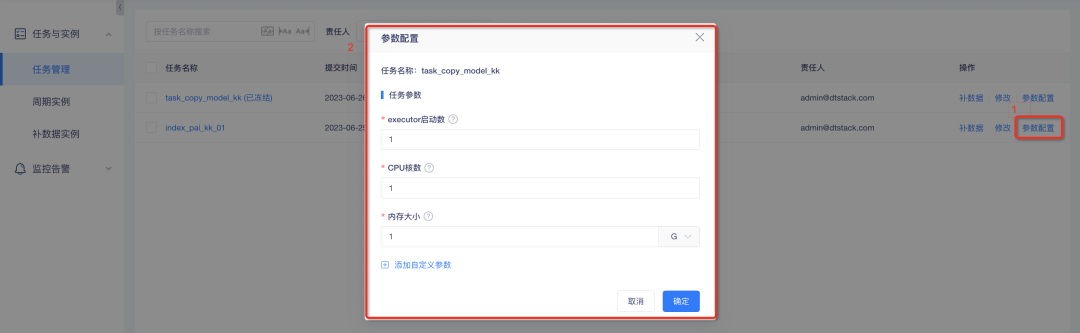
2. Las tareas de sincronización de datos y chispa admiten la configuración de parámetros personalizados
Antecedentes: para las tareas de Spark y las tareas de sincronización de datos, los ajustes de parámetros actualmente solo se pueden realizar a través de la consola. Los resultados del ajuste tendrán efecto globalmente. Sin embargo, las diferencias en la magnitud de los datos entre las tareas del indicador son grandes y la configuración de los mismos parámetros provocará un desperdicio. Por lo tanto, se pueden establecer parámetros a nivel de tarea para Spark y las tareas de sincronización de datos para facilitar el control flexible de las tareas.
Descripción de nuevas características:
1. Configuración de parámetros personalizados de la tarea Spark : entre ellos, se pueden configurar el número de inicios del ejecutor, el número de núcleos de CPU y el tamaño de la memoria;
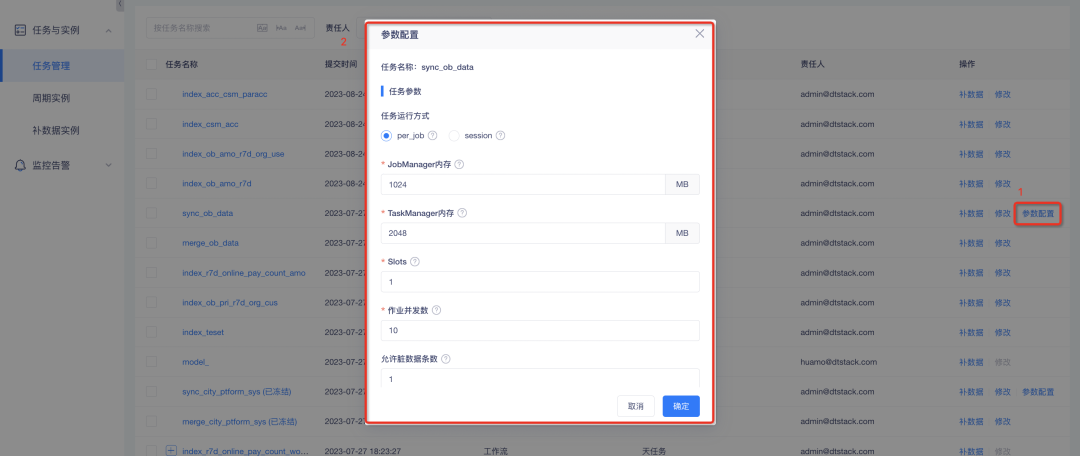
2. Configuración de parámetros personalizados para tareas de sincronización de datos : en el modo por trabajo, se requieren memoria del administrador de trabajos, memoria del administrador de tareas y ranuras; se pueden configurar el número de trabajos simultáneos y WriteBufferSize de HBase;
Optimización de funciones
1. El navegador permite abrir varios proyectos al mismo tiempo.
Antecedentes: en la función de historial, la cookie no almacena los parámetros del proyecto. Como resultado, cuando la pila de datos abre una nueva ventana del proyecto, el contenido de la ventana del historial se actualizará y el usuario regresará a la página de lista del proyecto. selección, lo que afecta el uso del cliente.
Descripción de la optimización de la experiencia: esta optimización permite que el navegador abra varios proyectos al mismo tiempo para consultas, operaciones, etc., para mejorar la eficiencia del uso del producto.
Compatible con navegador 2.edge
Compatible con el navegador egde, las funciones se adaptarán en consecuencia para mejorar la usabilidad del producto en los navegadores convencionales.
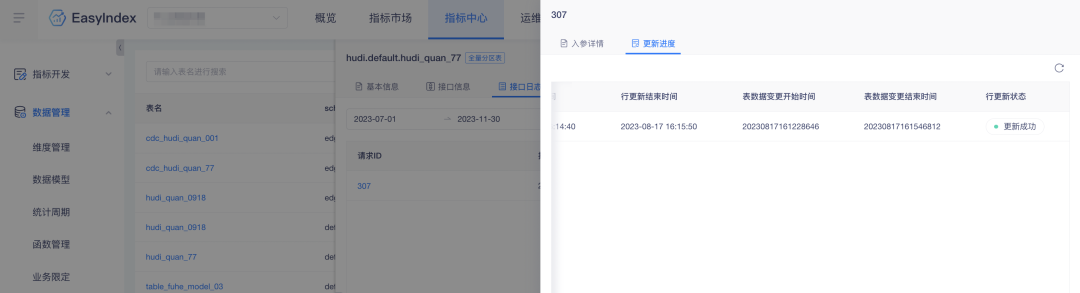
3. Hora de actualización de la tabla complementaria de actualización de filas
Antecedentes: el registro de datos de actualización de filas carece del período de tiempo de cambio de datos de la tabla, lo que hace que la recuperación de datos sea inconveniente. Para mejorar la eficiencia de la recuperación de datos, se agregan datos relevantes a la plataforma.
Descripción de la optimización de la experiencia: la actualización de la fila del indicador agrega la hora de inicio y la hora de finalización del cambio de datos de la tabla.
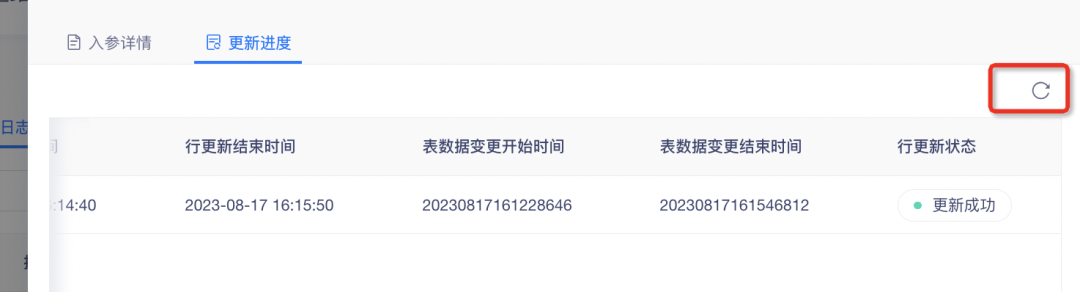
4. Agregue la función de actualización manual al estado de actualización de la fila.
Durante el proceso de actualización de filas, para facilitar el seguimiento oportuno del progreso de la actualización, se agrega un botón de actualización a la página para mejorar la eficiencia de la actualización.
5. Optimización de objetos dimensionales poblados por modelos y funciones de atributos dimensionales.
Al editar el modelo, en el paso de configurar la información de dimensiones, el sistema rellenará la información de dimensiones vinculada a los campos de la tabla de dimensiones principal de forma predeterminada si el usuario ha modificado las dimensiones asociadas en la versión histórica y si no presta atención. Al ajuste durante el proceso de edición, se guardarán datos incorrectos. Para evitar la tasa de error de datos, se ajustará para hacer eco de la información guardada en la versión anterior.
6. La puerta de enlace API admite prefijos personalizados
La información de prefijo del indicador actualmente está escrita en el elemento de configuración de la API. Al mismo tiempo, la API actualmente tiene una función de prefijo personalizada para mejorar la flexibilidad de configuración de la API. En este momento, cuando los elementos de configuración de API del indicador no son consistentes con el prefijo personalizado de API, los datos no se pueden llamar normalmente. Es necesario ajustarlos a los ajustes de configuración de la API de acoplamiento para garantizar que la configuración global sea única.
Dirección de descarga del "Informe técnico del producto Dutstack": https://www.dtstack.com/resources/1004?src=szsm
Dirección de descarga del "Libro técnico sobre prácticas de la industria de gobernanza de datos": https://www.dtstack.com/resources/1001?src=szsm
Para aquellos que quieran saber o consultar más sobre productos de big data, soluciones industriales y casos de clientes, visite el sitio web oficial de Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Linus se encargó de evitar que los desarrolladores del kernel reemplazaran las pestañas con espacios. Su padre es uno de los pocos líderes que puede escribir código, su segundo hijo es el director del departamento de tecnología de código abierto y su hijo menor es un núcleo de código abierto. Colaborador Robin Li: El lenguaje natural se convertirá en un nuevo lenguaje de programación universal. El modelo de código abierto se quedará cada vez más atrás de Huawei: tomará 1 año migrar completamente 5,000 aplicaciones móviles de uso común a Hongmeng, que es el lenguaje más propenso. Vulnerabilidades de terceros. Se lanzó el editor de texto enriquecido Quill 2.0 con características, confiabilidad y experiencia de desarrolladores que Ma Huateng y Zhou Hongyi se dieron la mano para "eliminar los rencores". La fuente de Laoxiangji no es el código, las razones detrás de esto son muy conmovedoras. Google anunció una reestructuración a gran escala.