


Hay dos novedades recientes:
Sam Altman reveló los detalles de GPT-5 y declaró públicamente que la mejora de GPT-5 será enorme y que cualquier empresa que lo subestime será aplastada. También tuiteó sugiriendo que los productos de OpenAI de este año cambiarán la historia de la humanidad.
En cuanto a las noticias sobre el primer ingeniero de software de IA, el desempeño del ingeniero de software de IA ya es bastante sobresaliente. Tiene capacidades de planificación general, DevOp y escaneo completo de proyectos. No está lejos de ser un verdadero programador.
Aunque todo era de esperarse, todavía parecía que llegó un poco más rápido.
Personalmente, creo que el progreso actual de la tecnología de IA tiene al menos dos impactos:
A nivel de competencia nacional, con la bendición de la IA, la gran ventaja que antes tenía China sobre Estados Unidos (el número de graduados universitarios destacados) ya no existe. Quién ganará después dependerá de quién cometa menos errores.
A nivel de trabajos personales, se espera que los métodos de producción cambien en 2 a 5 años. Si no mantenemos el ritmo, podemos sufrir una reducción de dimensionalidad. Como codificador, es imperativo aprender los principios subyacentes de la IA o participar en prácticas de aplicaciones relacionadas con la IA.

-
Explica los principios básicos de las redes neuronales y el aprendizaje profundo a través de una red muy sencilla. -
Luego te daré algo de experiencia a través de una operación de red neuronal real. -
Finalmente, una pregunta común conduce a la compleja red neuronal que se presentará en el siguiente artículo.

Consejos clave en este capítulo:
Las redes neuronales resuelven problemas fuera del conjunto de entrenamiento "aprendiendo" y almacenando las reglas generales del conjunto de entrenamiento.
El almacenamiento está bien. La red neuronal se divide en varias capas, cada capa tiene varias neuronas y cada neurona tiene N + 1 parámetros (donde N es igual al número de entradas conectadas a la neurona). En estos parámetros se almacenan las reglas generales "aprendidas" (de todas las neuronas).
El proceso también es seguro. Debido a que el proceso de "aprendizaje" comienza desde cualquier punto en el espacio de parámetros de alta dimensión (parámetros X de todas las neuronas) (los valores iniciales de los parámetros se dan aleatoriamente) y regresa gradualmente al punto con la pérdida más baja, Es un proceso de ajuste de parámetros paso a paso. Entonces, si se determina la fórmula para ajustar los parámetros, entonces se determina el proceso de "aprendizaje". Sí, se determina la fórmula para ajustar los parámetros: cuando se compila el modelo, la fórmula de ajuste para cada parámetro de cada neurona en cada capa se puede determinar tempranamente en función de la transitividad de las derivadas parciales.
▐Qué pueden hacer las redes neuronales
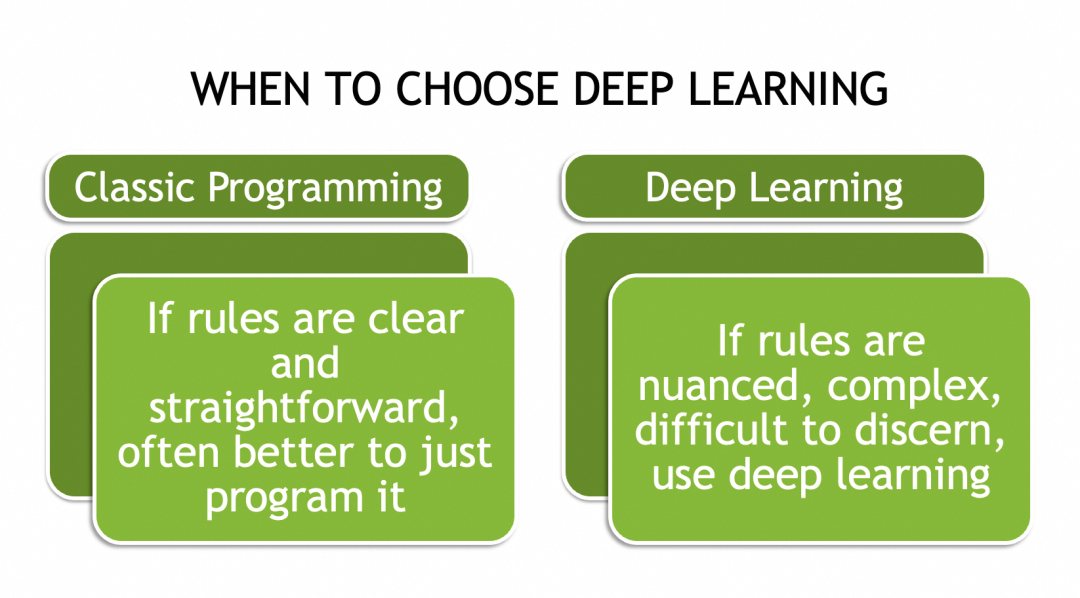
▐Por qué las redes neuronales pueden resolver problemas complejos
Los problemas complejos a menudo no son exhaustivos (como diferentes imágenes de gatos), por lo que no existe un conjunto de reglas que se puedan aplicar a todos sus casos. La única manera es abstraer sus leyes, características o patrones generales.
Por ejemplo, la incrustación de texto se puede utilizar para el procesamiento del lenguaje natural porque no registra (ni puede) todas las combinaciones de texto, sino que registra el patrón de un solo texto o token a través de un vector. Este vector es la representación del texto. abstracción. Si los vectores de dos palabras son parcialmente similares, esta similitud puede corresponder a sus características comunes en un contexto específico. No nos importa qué valor de vector representa qué característica. Estos son más bien metadatos de lenguaje y texto.
Supongamos que después del entrenamiento, la representación vectorial del rey es [0,3, 0,5,..., 0,9], la reina es [0,8, 0,5,..., 0,2] y el príncipe es [0,3, 0,7,..., 0,5 ], en un contexto determinado, como por ejemplo xx gobierna el reino, xx puede estar lleno de rey o reina, luego pueden estar determinados por el segundo elemento del vector, el común 0,5. En otro contexto, como por ejemplo xx es un. Hombre, xx puede completarse con rey o príncipe, lo que puede estar determinado por el primer elemento.
Como se mencionará a continuación, las redes neuronales también tienen un mecanismo para calcular y almacenar estos patrones abstractos, por lo que las redes neuronales son muy adecuadas para resolver problemas complejos que involucran conceptos abstractos.
▐Cómo implementar una red neuronal
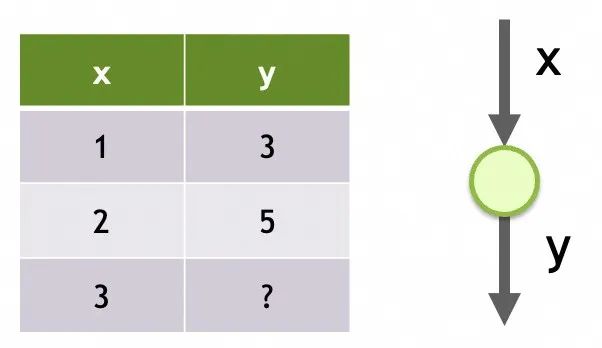
Red 1
Estructura de almacenamiento de la red neuronal
Su estructura es una única entrada, una sola capa y una sola neurona en esta capa.
Sus parámetros son los datos entrenados en cada neurona. Aquí solo hay una neurona y tiene dos parámetros, my b.
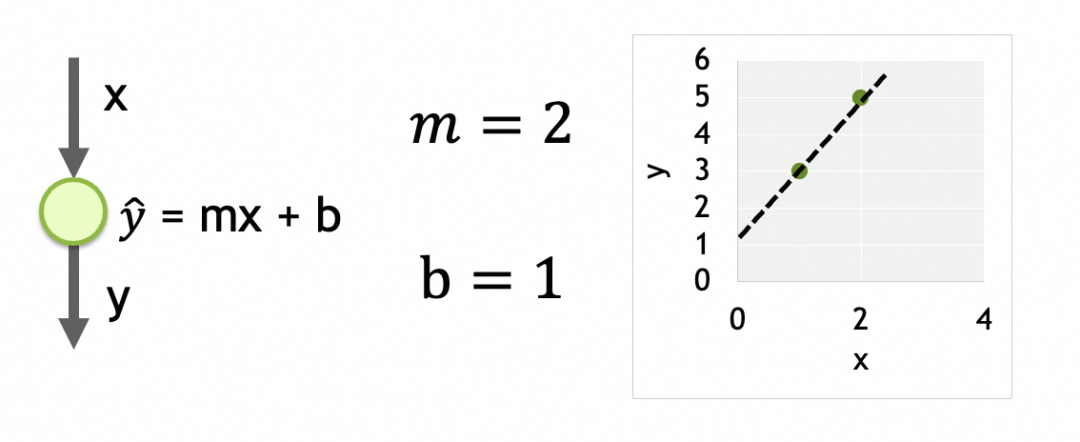
Una red en la que cada capa está densamente conectada, cada nodo está conectado a todos los nodos de la capa superior y todos los nodos de la capa superior son entradas a cada nodo de la capa inferior. La salida de cada nodo es la suma ponderada de sus entradas, el resultado después del procesamiento por la función de activación: output = activation_function(W * X + b), donde X es el vector de entrada [x1, x2, ..., xn], W es el vector de pesos de cada entrada [w1, w2, ..., wn], b es la constante de polarización y función_activación es la función de activación. . Cuando la función de activación es lineal output = W * X + b, Cuando un nodo tiene n entradas, el nodo tiene [w1, w2, ..., wn, b]un total de n+1 parámetros. Existe una relación en cadena entre las diferentes capas de la red y los resultados se pasan hacia abajo hasta la última capa de salida. Cualquier parámetro de cualquier neurona en cualquier capa afectará el resultado final. Entonces, estos parámetros son las unidades de almacenamiento de la red neuronal, que se utilizan para almacenar patrones abstractos.
Para dar otro ejemplo, la [Red 2] en la figura siguiente es una red con dos entradas, dos capas, 2 elementos en la primera capa, 1 elemento en la segunda capa y la función de activación de cada capa es lineal. El número total de parámetros en la primera capa de la red = (número de entradas + 1) el número de nodos = (2 + 1) 2 = 6, el número total de parámetros en la segunda capa = (2 + 1) * 1 = 3, el número total de parámetros de red = 6 + 3 = 9, el patrón abstracto se almacena en estos parámetros. (w111,w112,b11,w121,w122,b12,w21,w22,b2 en la imagen de abajo)
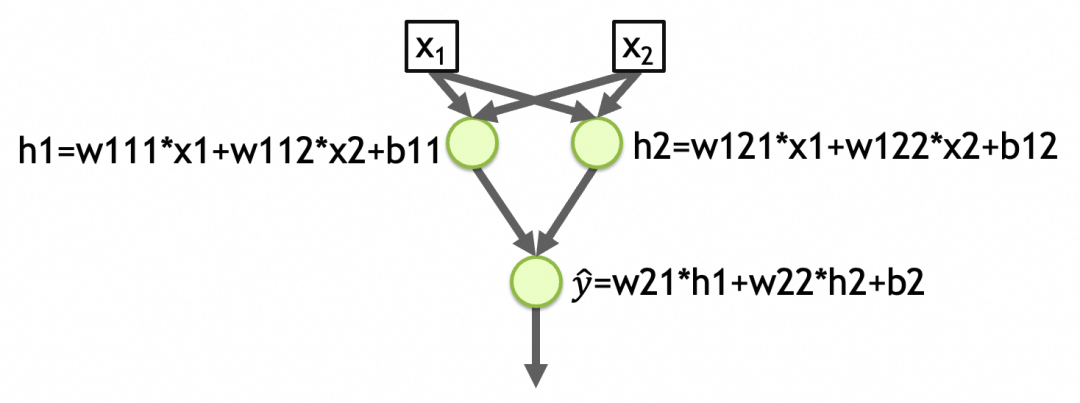
función de activación
y_hat=w21*h1+w22*h2+b2=w21*(w111*x1+w112*x2+b11)+w22*(w121*x1+w122*x2+b12)+b2
最终可以化简为
y_hat=w1'*x1+w2'*x2+b'
。而一个线性函数(直线、平面、…)是没法拟合/抽象现实问题的复杂度的。
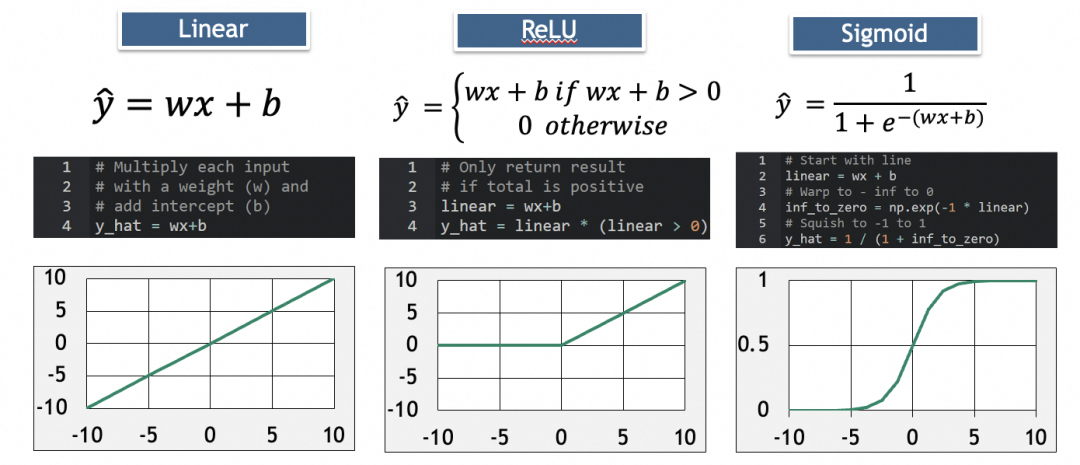
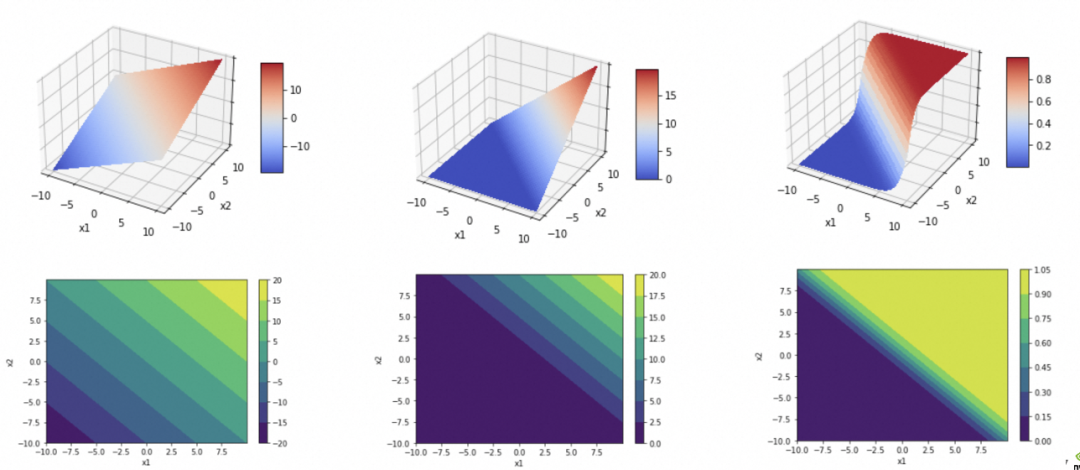
其中,ReLU用于消除负值,Sigmoid用于增加弧度。
深度学习过程
y_hat
。因为多层网络的计算是从上往下,所以称为前向传播:
第4步、通过反向传播算法计算各参数的梯度(gradient)。
各参数的梯度,即单个参数的变化会多大程度影响损失结果的变化。计算各参数的梯度,再将参数往损失结果变小的方向调整,即可在高维参数空间中找到损失最小值点。
为了计算梯度,我们需要先了解损失曲面。
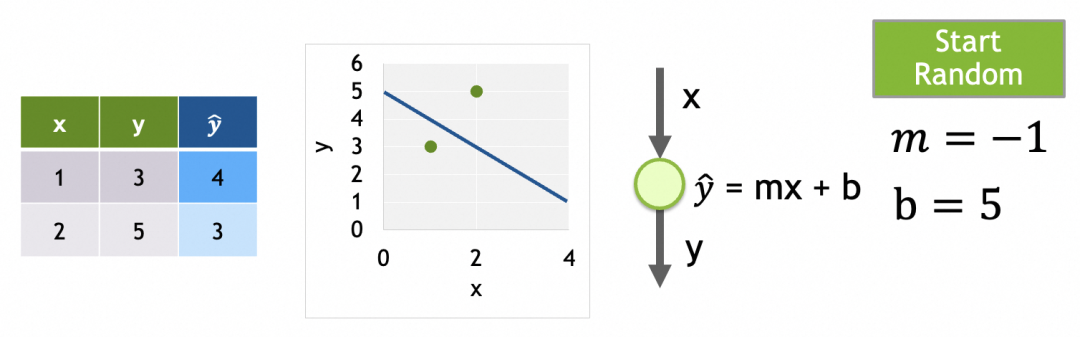
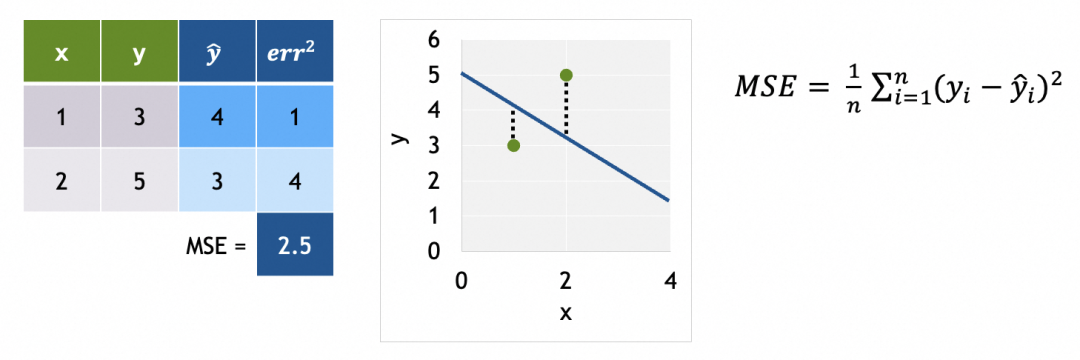
例子中只有m和b两个参数,如果将m和b作为x和y轴,损失函数结果作为z轴,可以得出损失曲面。(如果存在更多参数,形成高维参数空间,道理类似)
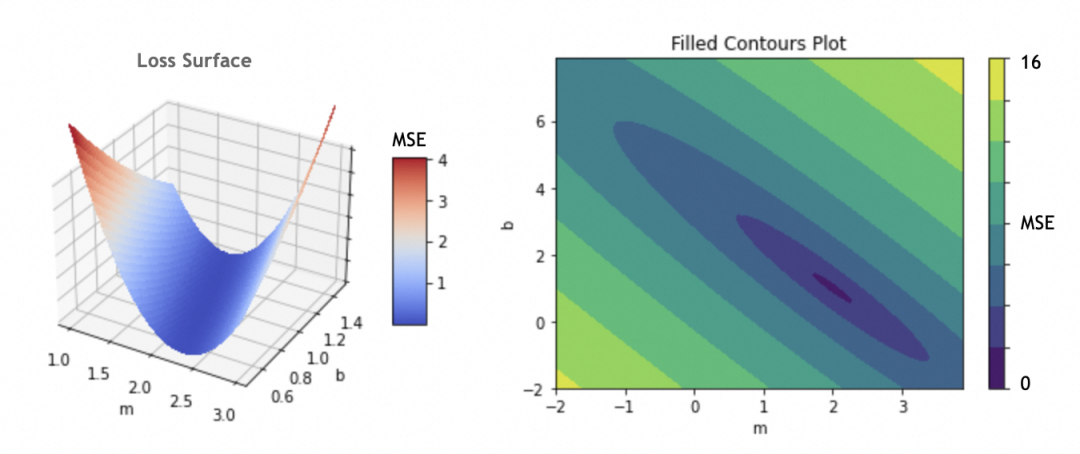
我们的目标是找出损失函数结果最小的m和b,这里即m=2,b=1。具体做法是将参数的当前值m=-1,b=5分次进行一定偏移,往m=2,b=1靠拢。
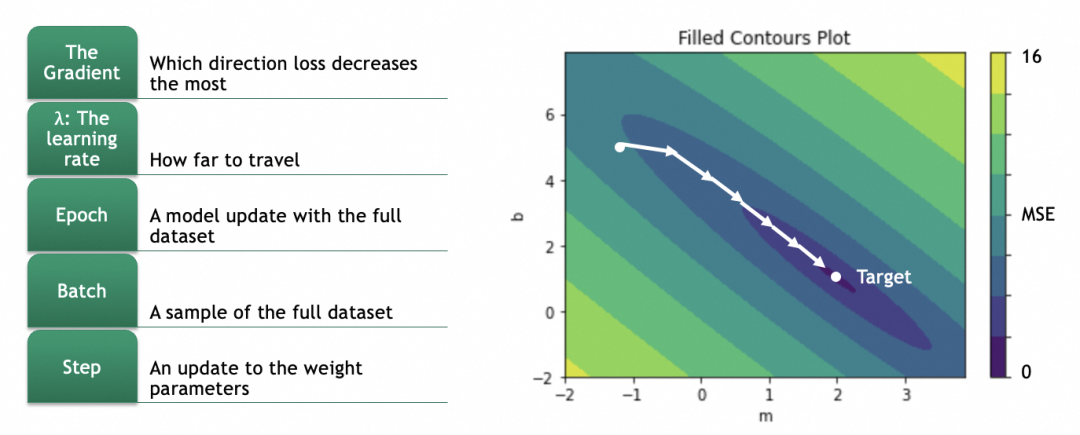
偏移具体怎么算呢?这就涉及到计算梯度,数学上就是计算偏导数。
对于一个曲面,当前在高处,要往低处移动,可以分别计算x、y两个方向(即m和b两个参数),在当前位置的梯度,即偏导数(partial derivative),即几何上的切线斜率,即单个参数的变化会多大程度影响损失结果的变化(注意梯度是向上的,用的话要取反)。
幸运的是,对于任何损失函数,都有对应公式算出对于某个参数的偏导数。例如,激活函数是y_hat = m * x + b,损失函数是L = (1/N) * Σ(y - y_hat)^2,则对于m的偏导数是∂L/∂w = (1/N) * Σ -2x(y - y_hat) = (1/N) * Σ -2x(y - (m * x + b))。这里仅仅是说明能解,因为模型会提供这个能力,所以我们一般不人为关注。
不仅如此,神经网络还有传导性,拿[网络2]举例,如果我们希望算出第一层参数w111的梯度,则可以按∂L/∂w111 = ∂L/∂y_hat * ∂y_hat/∂h1 * ∂h1/∂w111一层一层反向传播算回去,得到w111梯度具体的公式。
第5步、按梯度更新各参数:
因为偏导数是向上的,往低处走、梯度下降要取反。
拿m举例,m的新值m = m - learning_rate * ∂L/∂m。
注意learning_rate的选择,过大会导致越过最低点,过小会导致单次变化太小,训练时间太长。不过一般模型会提供自动渐进式的算法,我们无需人为关注。
第6步、网络的训练过程是迭代的,在每个训练周期(epoch)中,网络将通过梯度下降的方式逐步调整其参数。整个过程会重复多个epoch,直到模型的表现不再显著提高或满足特定的停止条件。
每个训练周期,即会用训练集进行训练,也会用验证集进行验证。通过对比训练集和验证集的结果,能发现是否存在过拟合现象。
关于全局最优解和局部最优解:
如果损失曲面比较复杂,比如有多个低洼,从某个点渐进式移动不一定能找到最低的那个,这种情况会拿到局部最优解而不是全局最优解。
关于训练batch:如果训练集非常大,每个训练周期不一定会拿全部训练集进行训练,而是会随机选一批数据进行。常见的方式有Stochastic Gradient Descent(SGD),一次选一个样例,这样的好处不仅计算量大大减少,还容易从局部最优解跳出,缺点是不太稳定。另一种方式是Mini-Batch Gradient Descent,这种一次选10-几百个样例。具有SGD的优点且比SGD稳定,比较常用。

MNIST数据集是深度学习领域的一个经典数据集,它包含了大量的手写数字图像,对于验证深度学习算法的有效性具有标志性意义。
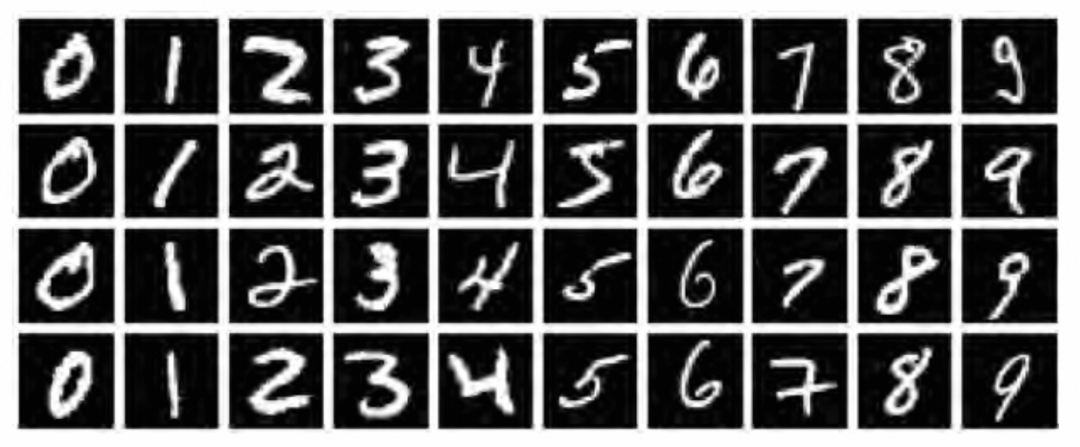
有了前面章节的理论,接下来,我们将通过一个实际案例来展示如何使用神经网络来解决图像分类问题。
下面的操作会用到jupyter平台和tensorflow2深度学习框架,但本文重点解释原理,平台和框架的使用就不多置笔墨了。
加载和观察数据集
在使用图像进行深度学习时,我们既需要图像本身(通常表示为 "X"),也需要这些图像的正确标签(通常表示为 "Y")。此外,我们需要一组X和Y来训练模型,然后还需要一组单独的X和Y来验证训练后模型的表现。因此,MNIST数据集需要分成4份:
x_train:用于训练神经网络的图像y_train:x_train图像的正确标签,用于评估模型在训练过程中的预测结果x_valid:模型训练完成后用于验证模型表现的图像y_valid:x_valid图像的正确标签,用于评估模型训练后的预测结果

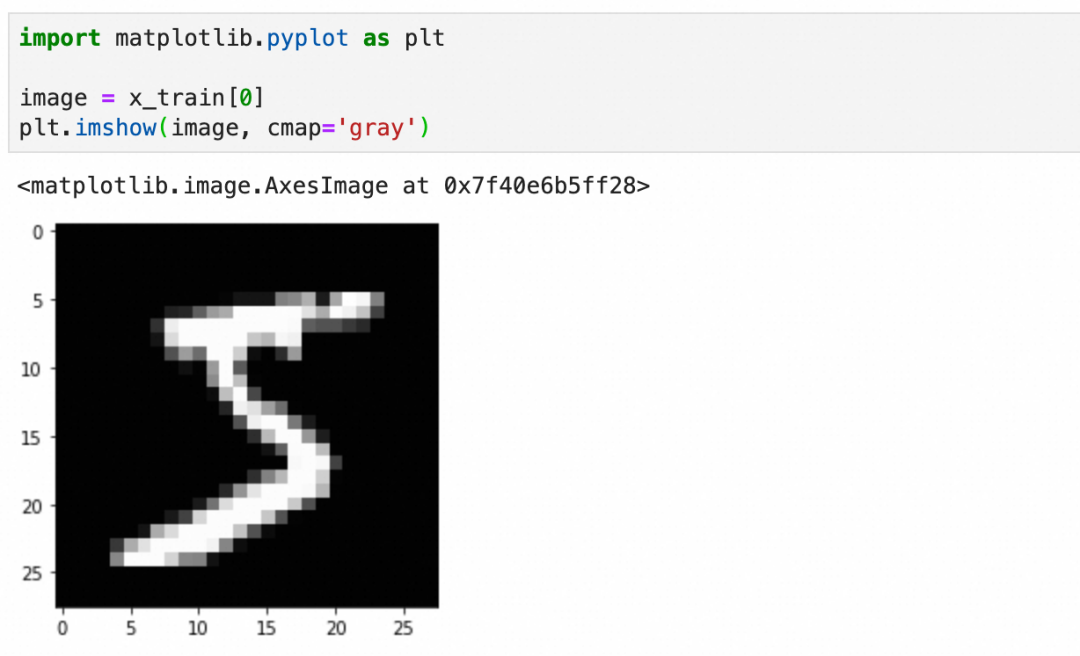
x_train
和验证图像集
x_valid
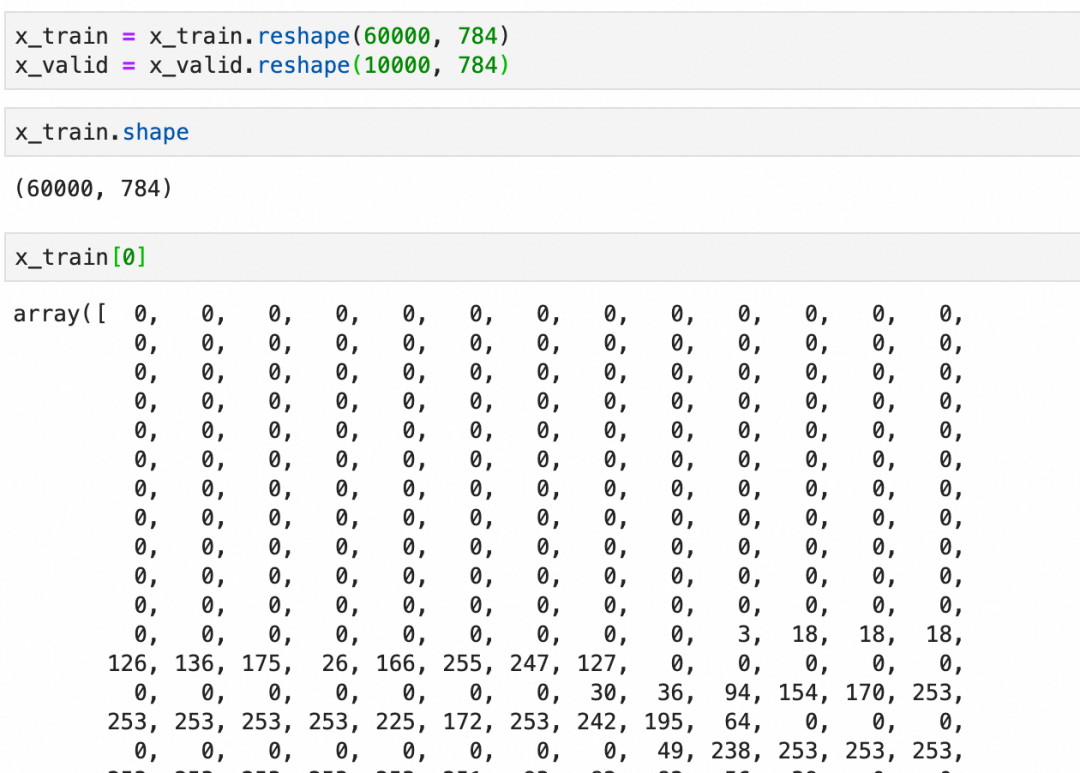
:可以看到是分别是60000张和10000张28x28 pixel的灰阶图像(灰度0-255):

每个图像是一个图像grid的二维数组,下图是二维数组的内容和可视化图像:

标签y_train比较简单,就是图像对应的数字:

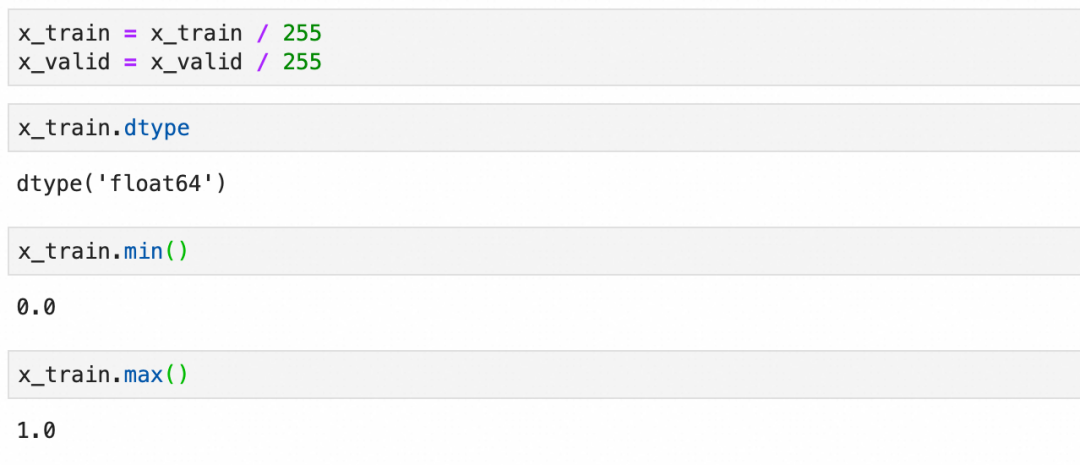
预加工数据集
在将数据输入到神经网络之前,通常需要进行一些预处理。这包括将图像数据展平为一维向量,标准化像素值到0-1之间,并将标签转换为适合分类任务的格式,通常是one-hot编码。
展平:
标准化:
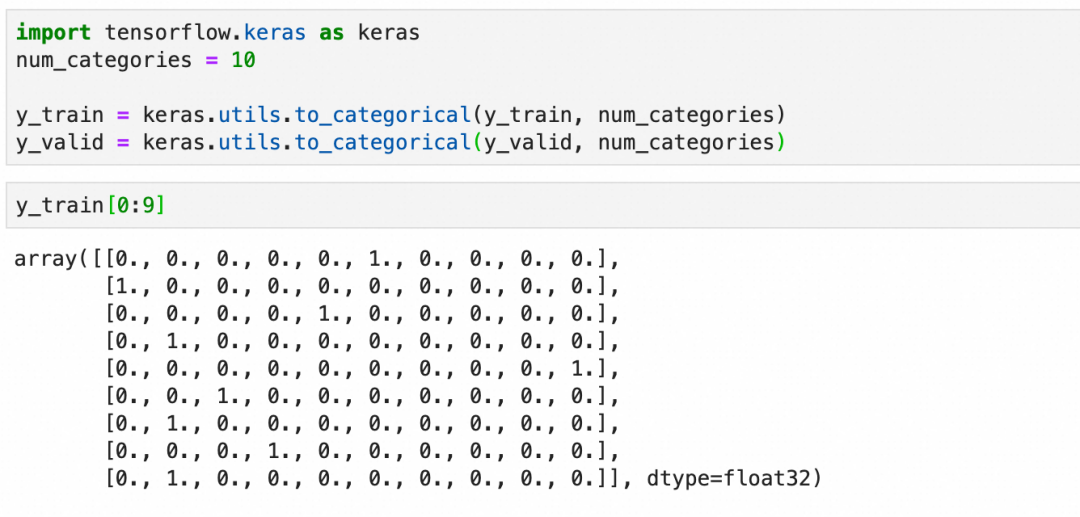
one-hot编码:
虽然这里的标签是0-9的连续整数,但不要把问题看作是一个数值问题(考虑一下这种情况,假设我们不是在识别手写0-9的图片,而是在识别各种动物的图片)。
这里本质上是在处理分类,分类问题的输出在深度学习框架里适合用one-hot编码来表达(一个一维向量,长度为总分类数,所属分类的值为1,其它值为0)。

创建模型
创建一个有效的模型通常需要一定的探索或者经验。对于MNIST数据集,一个常见的起点是构建一个包含以下层的网络:
784个输入(对应于28x28像素的输入图像)。
第一层是输入层,有512个神经元,激活函数是ReLU。
第二层隐藏层,使用512个神经元和ReLU激活函数。
第三层是输出层,10个神经元(对应于10个数字类别),使用Softmax激活函数以输出概率分布。
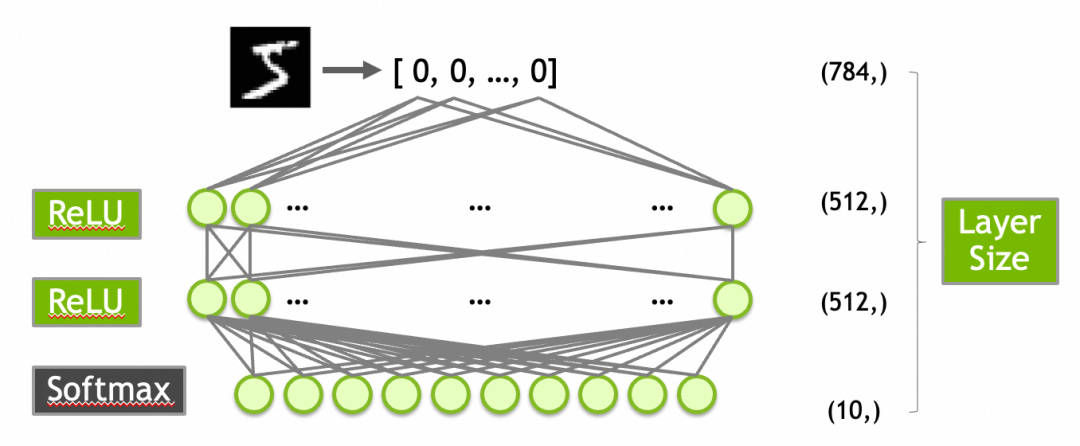
激活函数ReLU上面已经介绍过了,这里的Softmax需要介绍一下:Softmax函数确保输出层的输出值总和为1,从而可以被解释为概率分布。这对于多类分类问题非常有用。例如,输出层的10个输出值为[0.9, 0.0, 0.1, 0.0, ..., 0.0]可以解释为90%概率属于第1类,10%概率属于第3类。
按此创建模型并查看摘要:
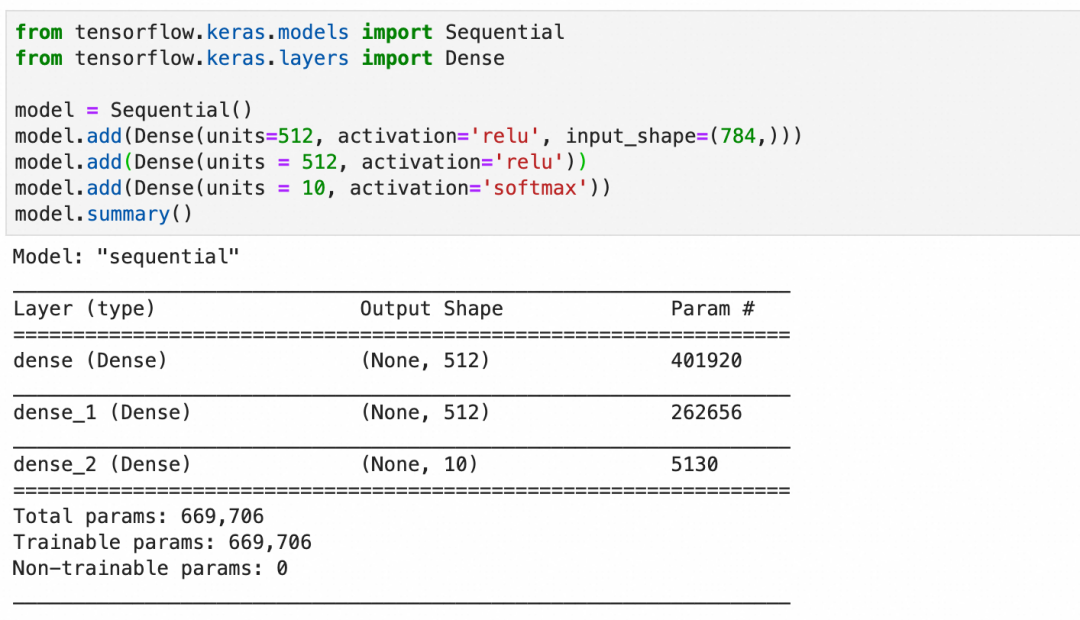
-
编译模型
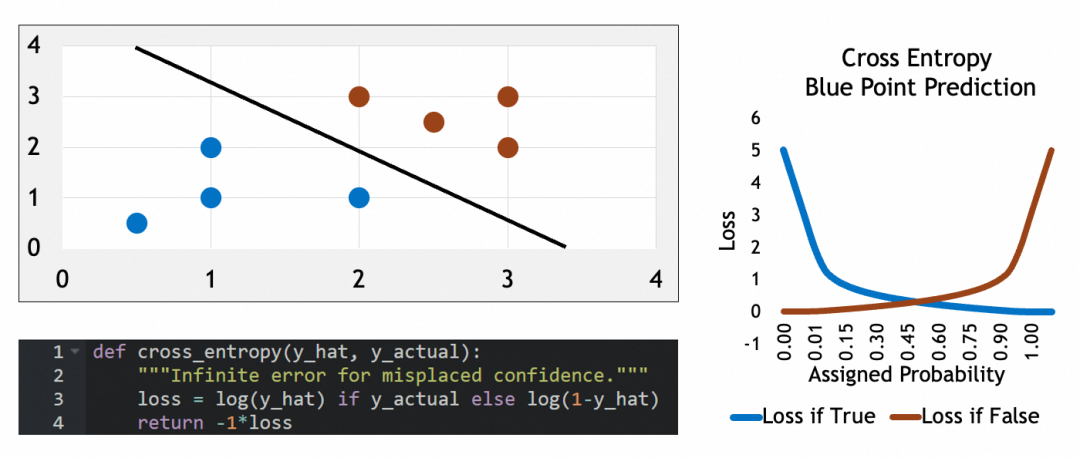
模型在编译时需要指定损失函数和优化器。对于多分类问题,损失函数通常选择交叉熵(Categorical Crossentropy),它的特征可以看参考公式:当实际属于某类(y_actual=1)时,损失等于log(y_hat),否则损失等于log(1-y_hat)。这个损失函数会惩罚错误猜测,使其损失接近∞,可以有效地量化预测概率分布与实际分布之间的差距。优化器则负责调整网络参数以最小化损失函数。

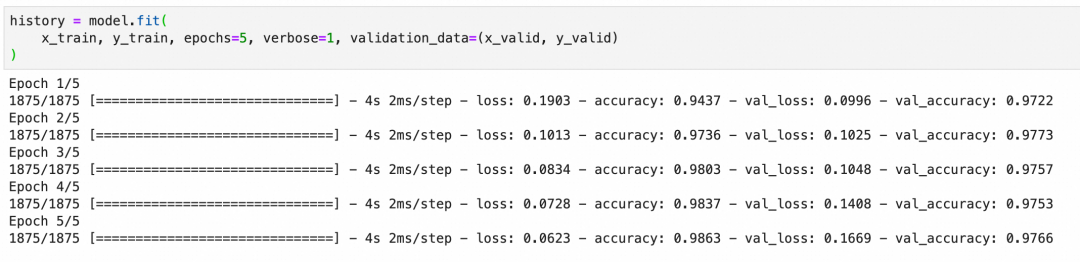
训练并观察准确率
训练模型时,我们会在多个训练周期内迭代更新参数,每个训练周期会经历一次完整的前向传递计算输出、损失函数评估结果和后向传递更新参数的过程。我们观察训练集和验证集上的准确率,以评估模型的表现和泛化能力。
注意损失曲面、梯度下降等概念和原理,如果不清楚可以回顾一下【深度学习过程】。
下图中的accuracy是训练集的准确率,val_accuracy是验证集的准确率,准确率符合预期。

如果模型在训练集上准确率很高,但在验证集上准确率低,可能出现了过拟合现象(overfitting)。过拟合意味着模型过于复杂或训练过度,以至于学习了训练数据中的噪声而非潜在规律。
训练集,左边损失非常小:
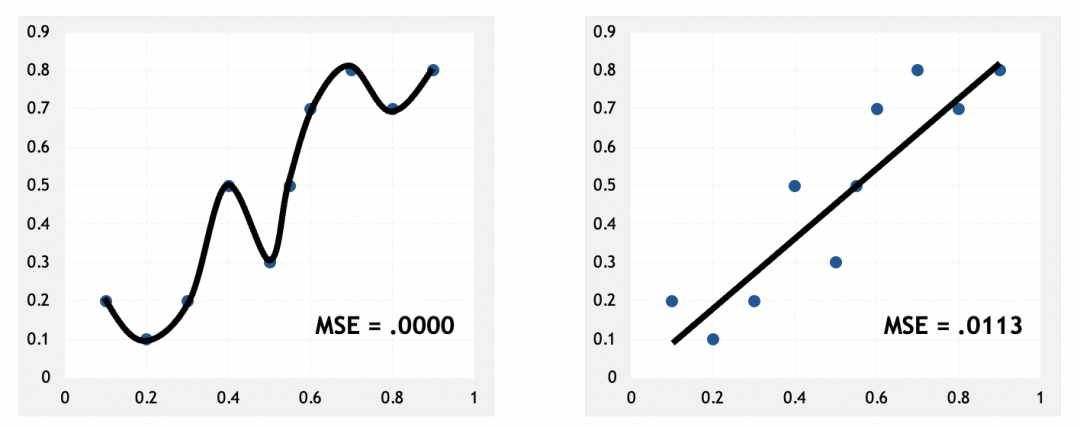
验证集,左边损失反而更大:
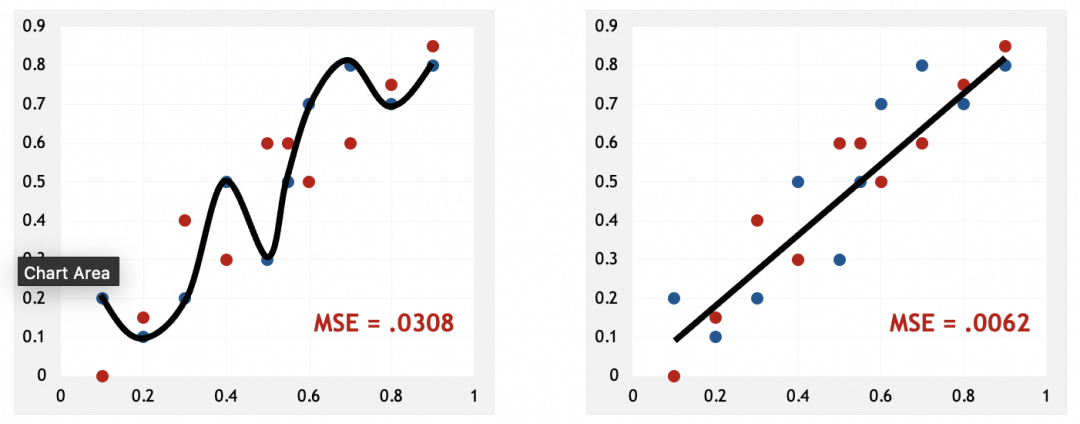
出现过拟合说明什么
左图可以看到,模型几乎硬套了训练集。和人脑类似,硬套部分实例,说明模型只是在记忆这些实例,只有找出它们的规律、特征、模式,才是真正的抽象。这也应证了我前面的说法,神经网络是在通过抽象解决问题。
为什么会出现过拟合
从被训练数据来看,过拟合说明训练集可能特征不明显,不容易抽象。比如被识别的图像模糊、亮度不高。
从模型来看,过拟合通常由于模型过于复杂或训练时间过长造成,走向了死记硬背。
如何解决过拟合
AI技术经过多年的发展,现在已经有比较成熟的方案来解决过拟合了,比如卷积神经网络、递归神经网络,这些我会在后面的文章里进行介绍。
本文大部分素材来自Nvidia在线课程Getting Started with Deep Learning。
(Getting Started with Deep Learning地址:https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-FX-01+V1)

团队介绍
天猫国际是中国领先的进口电商平台, 也是阿里巴巴-淘天集团电商技术体系中链路最完整且最为复杂的技术产品之一,也是淘天集团拥有最完整业务形态(平台+直营、跨境、大贸、免税等多业务模式)的业务。在这里我们参与到阿里电商体系的绝大部分核心系统(导购、商家、商品、交易、营销、履约等),同时借助区块链、大数据、AI算法等前沿技术助力业务高速增长。作为贴近业务前沿的技术团队,我们对于电商行业特性、跨境市场研究、未来交易趋势以及未来技术布局等都有着深度的理解。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。