
Nota del editor: cuando el autor intentaba enseñarle a su madre a usar LLM para completar tareas laborales, se dio cuenta de que la optimización de las palabras clave no era tan simple como se imaginaba. La optimización automática de las palabras clave es valiosa para los redactores de palabras clave sin experiencia que no tienen suficiente experiencia para ajustar y mejorar las palabras clave proporcionadas al modelo , lo que ha desencadenado una mayor exploración de herramientas automatizadas de optimización de palabras clave.
El autor de este artículo analiza la naturaleza de la ingeniería de palabras rápidas desde dos perspectivas: puede considerarse como parte de la optimización de hiperparámetros o como un proceso de exploración, prueba y error y corrección que requiere intentos y ajustes constantes. .
El autor cree que para tareas con entrada y salida de modelo relativamente claras, como resolver problemas matemáticos, clasificación de emociones y generar declaraciones SQL, etc. El autor cree que la ingeniería de palabras rápida en este caso es más como optimizar un "parámetro", al igual que ajustar los hiperparámetros en el aprendizaje automático. Podemos utilizar métodos automatizados para probar constantemente diferentes palabras clave y ver cuál funciona mejor. Para tareas relativamente subjetivas y vagas, como escribir correos electrónicos, poemas, resúmenes de artículos, etc. Debido a que no existe un estándar en blanco y negro para juzgar si la salida es "correcta", la optimización de las palabras clave no se puede realizar de manera simple y mecánica.
El enlace del artículo original: https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
Enlace al perfil de LinkedIn: https://linkedin.com/in/ianhojy
Enlace de perfil medio para suscripciones: https://ianhojy.medium.com/
Autor |
Compilado |
Durante los últimos meses, he intentado crear varias aplicaciones basadas en LLM. Para ser honesto, dedico una buena parte de mi tiempo a mejorar Prompt para obtener el resultado que deseo de LLM.
Hubo muchas ocasiones en las que me quedé atrapado en el vacío y la confusión, preguntándome si no era más que un ingeniero rápido y glorificado. Dado el estado actual de la interacción humana con los LLM (grandes modelos de lenguaje), todavía tiendo a concluir "todavía no" y soy capaz de superar mi síndrome del impostor la mayoría de las noches. (Nota del traductor: Es un fenómeno psicológico que se refiere a individuos que son escépticos acerca de sus propios logros y capacidades. Muchas veces se sienten mentirosos, creen que no son dignos de tener o alcanzar los logros que han alcanzado, y son preocupado por quedar expuesto.) Actualmente no discutiremos este tema en profundidad por ahora.
Pero todavía me pregunto a menudo si algún día el proceso de escritura de Prompt podrá automatizarse básicamente. La forma de responder a esta pregunta depende de si se puede descubrir la verdadera naturaleza de la ingeniería rápida.
Aunque existen innumerables manuales de ingeniería rápida en Internet, todavía no puedo decidir si la ingeniería rápida es un arte o una ciencia.
Por un lado, se siente como un arte cuando tengo que aprender y pulir repetidamente las indicaciones que escribo en función de lo que observo en el resultado del modelo . Con el tiempo, descubrí que los pequeños detalles importan (como usar "debe" en lugar de "debería" o agregar pautas, recomendaciones o especificaciones) al final de la palabra clave en lugar de en el medio. Dependiendo de la tarea, hay tantas maneras en que uno puede expresar una serie de instrucciones y pautas que a veces se siente como un constante ensayo y error y cometer errores.
Por otro lado, uno podría pensar que las palabras clave son sólo hiperparámetros. En última instancia, LLM (modelo de lenguaje grande) en realidad solo trata las palabras clave que escribimos como incrustaciones, al igual que todos los hiperparámetros. Si tenemos un conjunto de datos preparado y aprobado para entrenar y probar modelos de aprendizaje automático, podemos hacer ajustes a las palabras clave y evaluar objetivamente su desempeño. Recientemente vi una publicación de Moritz Laurer, ingeniero de aprendizaje automático en HuggingFace[1]:
Cada vez que prueba un mensaje diferente en sus datos, se vuelve menos seguro de si el LLM realmente se generaliza a datos no vistos... Usar una división de validación separada para ajustar el hiperparámetro principal de los LLM (el mensaje) es tan importante como train-val-test dividir para realizar ajustes. La única diferencia es que ya no tienes un conjunto de datos de entrenamiento y de alguna manera se siente diferente porque no hay entrenamiento ni actualizaciones de parámetros. Es fácil engañarse a sí mismo haciéndose creer que un LLM se desempeña bien en su tarea, cuando en realidad ha sobreajustado el mensaje a sus datos. Todo buen artículo de “tiro cero” debe aclarar que utilizaron una división de validación para encontrar su mensaje antes de la prueba final.
A medida que probamos más y más palabras de aviso diferentes (Prompts) en estos conjuntos de datos, estaremos cada vez más inseguros de si LLM realmente puede generalizar a datos invisibles... Aislar una parte del conjunto de datos Establecer como conjunto de validación para ajustar los hiperparámetros principales (Pregunta) de LLM y utilice el método de división train-val-test (Nota del traductor: divida el conjunto de datos disponible en tres partes: conjunto de entrenamiento, conjunto de validación y conjunto de prueba). El ajuste fino es igualmente importante. La única diferencia es que este proceso no implica entrenar el modelo (sin entrenamiento) ni actualizar los parámetros del modelo (sin actualizaciones de parámetros), sino solo evaluar el rendimiento de diferentes palabras de aviso en el conjunto de validación. Es fácil engañarse creyendo que el LLM funciona bien en la tarea objetivo, cuando en realidad las palabras clave ajustadas pueden funcionar muy bien en este conjunto de datos actual, pero pueden no funcionar bien en un conjunto de datos más amplio o invisible. Todo buen artículo de "tiro cero" debe indicar claramente que utiliza un conjunto de validación para ayudar a encontrar las mejores indicaciones antes de la prueba final.
Después de pensarlo un poco, creo que la respuesta está en algún punto intermedio. Si la ingeniería rápida es una ciencia o un arte depende de lo que queramos que haga LLM. Hemos visto a LLM hacer muchas cosas sorprendentes durante el año pasado, pero tiendo a clasificar las intenciones de las personas al usar modelos grandes en dos categorías amplias: resolver problemas y completar tareas creativas (crear).
En el lado de la resolución de problemas , tenemos LLM que resuelven problemas matemáticos, clasifican sentimientos, generan declaraciones SQL, traducen textos, etc. En términos generales, creo que todas estas tareas se pueden agrupar porque pueden tener pares de entrada-salida relativamente claros (Nota del traductor: la asociación entre los datos de entrada y los datos de salida del modelo correspondiente) (por lo tanto, he visto muchos casos en los que se usa sólo una pequeña cantidad de indicaciones pueden realizar muy bien la tarea objetivo). Para este tipo de tareas con datos de entrenamiento bien definidos (Nota del traductor: la relación entre entrada y salida en el conjunto de datos de entrenamiento es clara y clara), la ingeniería rápida me parece más una ciencia. Por lo tanto, la primera mitad de este artículo analizará Prompt como hiperparámetro , explorando específicamente el progreso de la investigación de la ingeniería de avisos automatizada (Nota del traductor: uso de métodos o tecnologías automatizados para diseñar, optimizar y ajustar palabras de aviso).
En términos de tareas creativas , las tareas requeridas de LLM son más subjetivas y ambiguas. Escribe correos electrónicos, informes, poemas, resúmenes. Es aquí donde encontramos más ambigüedad: ¿es impersonal el contenido de la escritura de ChatGPT? (Basado en los miles de artículos que he escrito al respecto, mi opinión actual es sí) Y, dado que a menudo carecemos de un criterio más objetivo sobre cómo queremos que respondan los LLM, la naturaleza y las demandas de las tareas creativas a menudo no son apropiadas. pensar en las palabras clave como parámetros que se pueden ajustar y optimizar como hiperparámetros.
Llegados a este punto, algunos podrían decir que para tareas creativas sólo necesitamos usar el sentido común. Para ser honesto, yo también solía pensar lo mismo, hasta que intenté enseñarle a mi madre cómo usar ChatGPT para ayudarla a generar correos electrónicos de trabajo. En estos casos, dado que la ingeniería de Prompt todavía se trata principalmente de mejorar a través de la experimentación y el ajuste continuos en lugar de una finalización única, ¿cómo puede usar sus propias ideas para mejorar Prompt y aún conservar la universalidad de Prompt (como se mencionó en la cita anterior? ), no siempre es obvio.
De todos modos, busqué una herramienta que pudiera mejorar automáticamente las indicaciones basadas en los comentarios de los usuarios sobre ejemplos generados por modelos grandes, pero no encontré nada. Por lo tanto, construí un prototipo de dicha herramienta para explorar si existía una solución viable. Más adelante en este artículo, compartiré con ustedes una herramienta con la que experimenté y que mejora automáticamente las palabras clave en función de los comentarios de los usuarios en tiempo real.
01 Parte 1: LLM como solucionadores: trate la ingeniería rápida como parte de la optimización de hiperparámetros
Mucha gente en la industria está familiarizada con la famosa terminología "Zero-Shot-COT" en el artículo "Los modelos de lenguaje grandes son razonadores de tiro cero" [2] (Nota del traductor: el modelo no ha aprendido datos de entrenamiento explícitos para una tarea específica A continuación, resuelva nuevos problemas combinando los conocimientos existentes). Zhou et al (2022) decidieron explorar más a fondo en el artículo "Los modelos de lenguaje grandes son ingenieros de indicaciones a nivel humano" [3] ¿Cuál es su versión mejorada? —— "Resolvamos esto paso a paso para asegurarnos de que tenemos la respuesta correcta". La siguiente es una descripción general del método del ingeniero de avisos automáticos que propusieron:
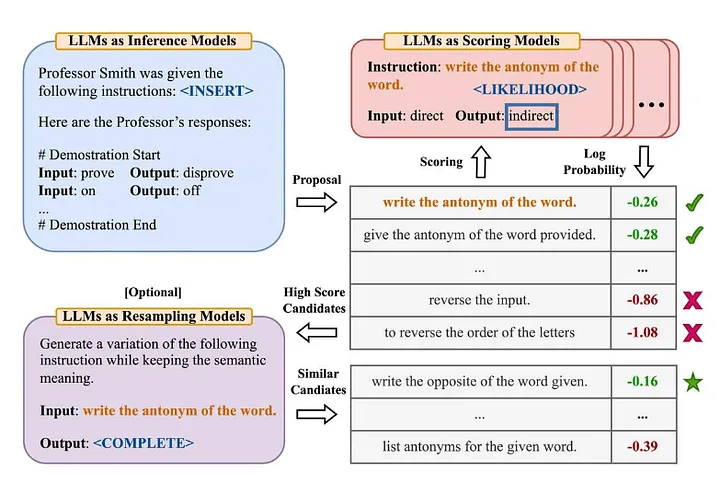
Fuente: Los modelos de lenguajes grandes son ingenieros rápidos a nivel humano[3]
Para resumir este artículo:
- Utilice LLM para generar indicaciones de orientación para candidatos basadas en pares de entrada y salida determinados (Nota del traductor: la asociación entre los datos de entrada y los datos de salida del modelo correspondiente).
- Utilice LLM para calificar cada sugerencia de instrucción, ya sea en función de qué tan bien la respuesta generada usando la instrucción coincide con la respuesta esperada, o en función de la respuesta del modelo obtenida con la instrucción para evaluar la probabilidad logarítmica.
- Las nuevas palabras de orientación para candidatos se generan de forma iterativa en función de palabras de orientación para candidatos con puntuación alta (instrucciones).
Se descubrieron algunas conclusiones interesantes:
- Además de demostrar el rendimiento superior de (los ingenieros de ayuda humana) y los algoritmos propuestos anteriormente, los autores señalan: "De manera contraria a la intuición, agregar ejemplos en contexto perjudica el rendimiento del modelo... porque todas las palabras de instrucción seleccionadas se ajustan demasiado al escenario de aprendizaje de disparo cero y, por lo tanto, funcionan mal". en el caso de muestras pequeñas (pocas tomas) .
- El efecto del algoritmo iterativo de búsqueda Monte Carlo (Búsqueda Monte Carlo) se debilitará gradualmente en la mayoría de los casos, pero cuando el espacio de la propuesta original (Nota del traductor: puede referirse al algoritmo de búsqueda Monte Carlo, utilizado inicialmente para generar candidatos. Funciona bien cuando el El alcance o la solución inicial del problema no es lo suficientemente adecuado o eficaz.
Luego, en 2023, algunos investigadores de Google DeepMind lanzaron un método llamado "Optimización mediante indicaciones (OPRO)". De manera similar al ejemplo anterior, el metamensaje contiene una serie de pares de entrada/salida (Nota del traductor: la entrada y las expectativas que describen una tarea específica o una combinación de salida de problema). La diferencia clave aquí es que el meta-indicador también contiene muestras de palabras de indicaciones previamente entrenadas y sus respuestas o soluciones correctas y con qué precisión el modelo respondió a estas palabras de indicaciones, además de detallar las diferencias entre las diferentes partes de las palabras de orientación del meta-indicador. para las relaciones.
Como explican los autores, cada paso de optimización de palabras clave en el trabajo de investigación genera nuevas palabras clave, con el objetivo de hacer referencia a trayectorias de aprendizaje anteriores para que el modelo pueda comprender mejor la tarea actual y producir resultados más precisos.
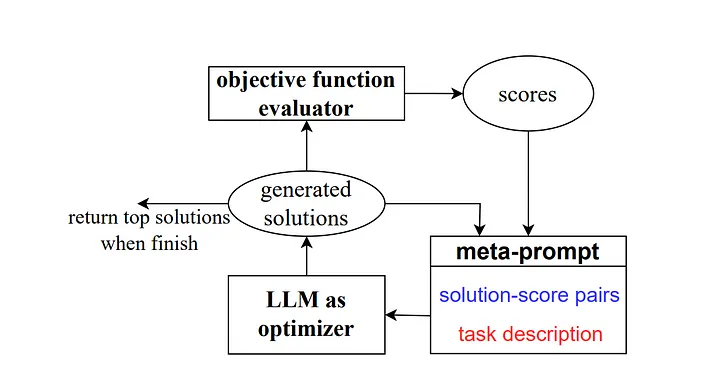
Fuente: Modelos de lenguajes grandes como optimizadores[4]
Para el escenario Zero-Shot-COT, propusieron el método de optimización de palabras rápidas "Respire profundamente y trabaje en este problema paso a paso" y lograron buenos resultados.
Tengo algunas ideas sobre esto:
- "Los estilos de indicaciones de instrucción generadas por diferentes tipos de modelos de lenguaje varían mucho. Algunos modelos, como PaLM 2-L-IT y text-bison, generan indicaciones de instrucción muy concisas y claras, mientras que otros, como GPT, las instrucciones son largas y bastante detallado. "Esto merece nuestra atención. Actualmente, muchos métodos de ingeniería rápida en el mercado se escriben utilizando el modelo de lenguaje OpenAI como objeto de referencia. Sin embargo, a medida que se utilizan cada vez más modelos de diferentes fuentes, debemos prestar atención a que estas pautas de ingeniería comunes pueden no funcionar. está bien. En la Sección 5.2.3 del artículo se ofrece un ejemplo que demuestra la alta sensibilidad del rendimiento del modelo a pequeños cambios en las instrucciones. Necesitamos prestar más atención a esto.
Por ejemplo, cuando se utilizó PaLM 2-L para evaluar el modelo en el equipo de prueba GSM8K, la precisión de "Pensemos paso a paso" alcanzó el 71,8% y la precisión de "Resolvamos el problema juntos" fue del 60,5%. mientras que los dos primeros La combinación semántica de palabras de instrucción, "Trabajemos juntos para resolver este problema paso a paso", tiene una precisión de sólo el 49,4%.
Este comportamiento aumenta tanto la variación entre las instrucciones de un solo paso como las fluctuaciones que ocurren durante el proceso de optimización, lo que nos lleva a generar múltiples instrucciones de un solo paso en cada paso para mejorar la estabilidad del proceso de optimización.
Otro punto importante se menciona en la conclusión del artículo: "Una limitación de nuestra aplicación actual de algoritmos a problemas del mundo real es que los grandes modelos de lenguaje utilizados para optimizar las palabras clave no explotan eficazmente los casos erróneos en el conjunto de entrenamiento para inferir prometedor En el experimento, intentamos agregar casos de error que ocurrieron cuando el modelo fue entrenado o probado en el meta-indicador, en lugar de muestrear aleatoriamente del conjunto de entrenamiento en cada paso de optimización, pero los resultados fueron similares, lo que mostró que solo El La cantidad de información en estos casos de error no es suficiente para que el optimizador LLM (un modelo de lenguaje grande utilizado para optimizar las palabras clave) comprenda las razones de las predicciones incorrectas "De hecho, vale la pena enfatizar esto, porque aunque estos métodos proporcionan evidencia sólida de la falla. Proceso de optimización de palabras clave Similar al proceso de optimización de hiperparámetros en ML/AI tradicional, pero tendemos a preferir usar ejemplos positivos, ya sea qué tipo de entrada de contenido queremos proporcionar a LLM o cómo guiamos a LLM. mejorar las palabras clave. Sin embargo, en el ML/AI tradicional, esta preferencia no suele ser tan obvia y nos centramos más en cómo utilizar la información sobre el error para optimizar el modelo, en lugar de prestar demasiada atención a la dirección o el tipo del error en sí ( es decir, nos centramos en los errores -5 y +5, que en su mayoría se tratan por igual).
Si está interesado en APE (Ingeniería de aviso automatizada), puede ir a https://github.com/keirp/automatic_prompt_engineer para descargarlo y usarlo.
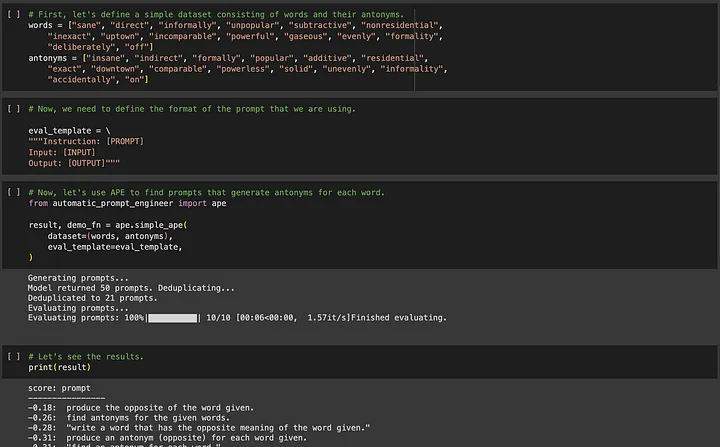
Fuente: Captura de pantalla del cuaderno de ejemplo para APE[5]
Un requisito clave en ambos métodos, APE y OPRO, es que debe haber datos de entrenamiento para ayudar a optimizar, y el conjunto de datos debe ser lo suficientemente grande como para garantizar la universalidad de las palabras clave optimizadas.
Ahora quiero hablar sobre otro tipo de tarea de LLM para la que es posible que no tengamos datos disponibles.
02 Parte 2: LLM como creadores: piense en Prompt Engineering como un proceso de prueba y error constante de mejoras incrementales
Supongamos que ahora se nos ocurrieran algunas historias cortas.
Simplemente no tenemos ejemplos de textos novedosos para entrenar el modelo, y llevaría demasiado tiempo escribir algunos ejemplos de textos novedosos calificados. Además, no me queda claro si tiene sentido que un modelo grande genere una respuesta "supuestamente correcta", ya que puede haber muchos tipos de resultados de modelo que sean aceptables. Por lo tanto, para este tipo de tarea, es casi poco práctico utilizar métodos como APE para automatizar la ingeniería de palabras rápidas.
Sin embargo, algunos lectores pueden preguntarse, ¿por qué necesitamos automatizar el proceso de escritura de palabras clave? Puedes comenzar con cualquier palabra sencilla, como "dame 3 ideas para historias cortas sobre {{issue}} " {{country}}, completar {{problema}} con "desigualdad", reemplazar {{país}} con "Singapur" y observar el modelo. Responder Consulte los resultados, descubra los problemas, ajuste las palabras clave y luego observe si el ajuste es efectivo y repita este proceso.
Pero en este caso, ¿quién se beneficiará más de la ingeniería de palabras clave? Son precisamente aquellos principiantes que no tienen experiencia en escribir palabras clave no tienen suficiente experiencia para ajustar y mejorar las palabras clave proporcionadas al modelo . Experimenté esto de primera mano cuando le enseñé a mi madre a usar ChatGPT para completar tareas laborales.
Puede que mi madre no sea muy buena canalizando su insatisfacción con el resultado de ChatGPT en nuevas mejoras para las palabras dinámicas, pero me he dado cuenta de que no importa cuán buenas sean nuestras habilidades de ingeniería de palabras dinámicas, en lo que somos realmente buenos es en articular los problemas que ver (es decir, la capacidad de quejarse). Por lo tanto, intenté crear una herramienta para ayudar a los usuarios a expresar sus quejas y permitir que LLM mejorara las palabras clave para nosotros. Para mí, esto parece una forma más natural de interactuar y parece hacerlo más fácil para aquellos de nosotros que intentamos utilizar LLM para tareas creativas.
Se debe aclarar de antemano que esto es solo una prueba de concepto, por lo que si los lectores tienen buenas ideas, ¡no duden en compartirlas con el autor!
Primero, escriba la palabra solicitada con {{}} variables. La herramienta detectará estos marcadores de posición para que los completemos más tarde, nuevamente usando el ejemplo anterior, pidiendo al modelo grande que genere algunas historias creativas sobre la desigualdad en Singapur.
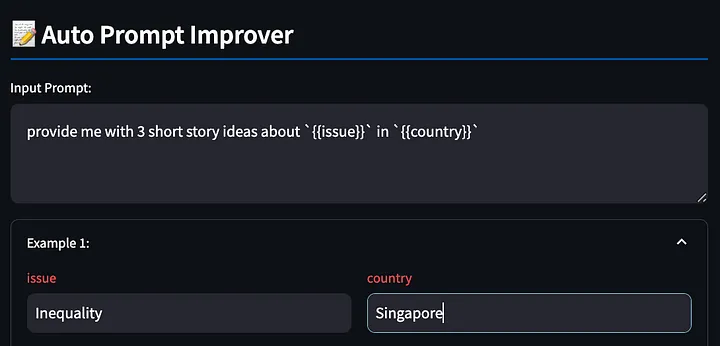
A continuación, la herramienta genera un modelo de respuesta basado en las palabras clave completadas.

Luego envíenos nuestros comentarios (quejas sobre el resultado del modelo):
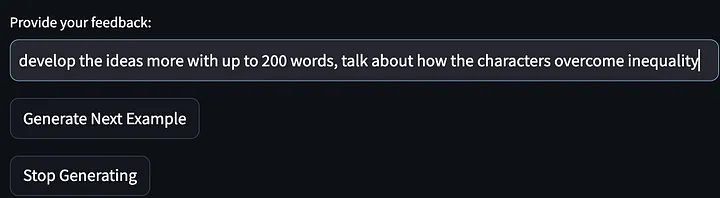
Luego se pidió al modelo que dejara de generar más ejemplos de ideas de historias y palabras clave de salida que mejoraron desde la primera iteración. Tenga en cuenta que las indicaciones que figuran a continuación se han perfeccionado y generalizado para requerir "describir las estrategias... para superar o afrontar estos desafíos". Y mi comentario sobre el resultado del primer modelo fue "hablar sobre cómo el protagonista de la historia resuelve la desigualdad".

Luego le pedimos al modelo grande que volviera a concebir la historia corta, utilizando las palabras clave modificadas.
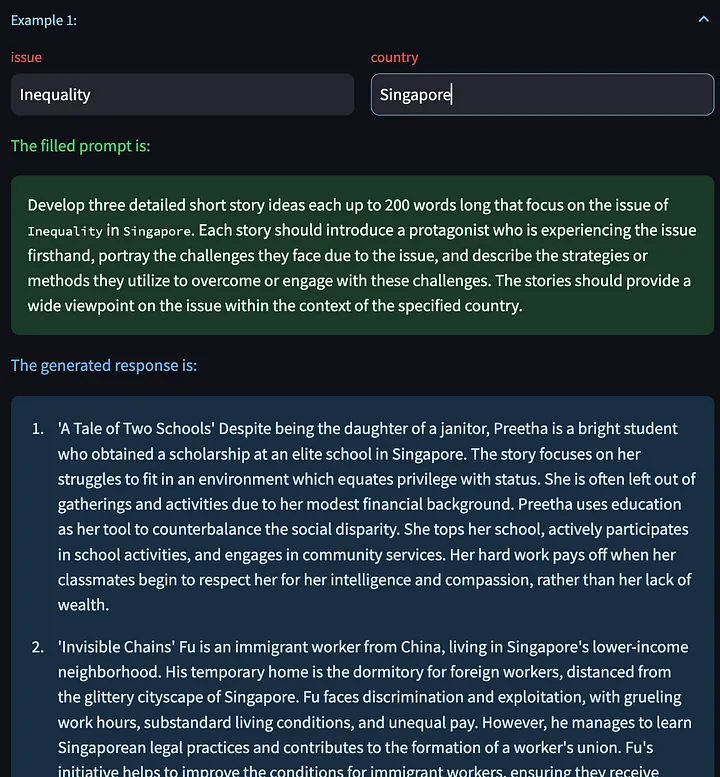
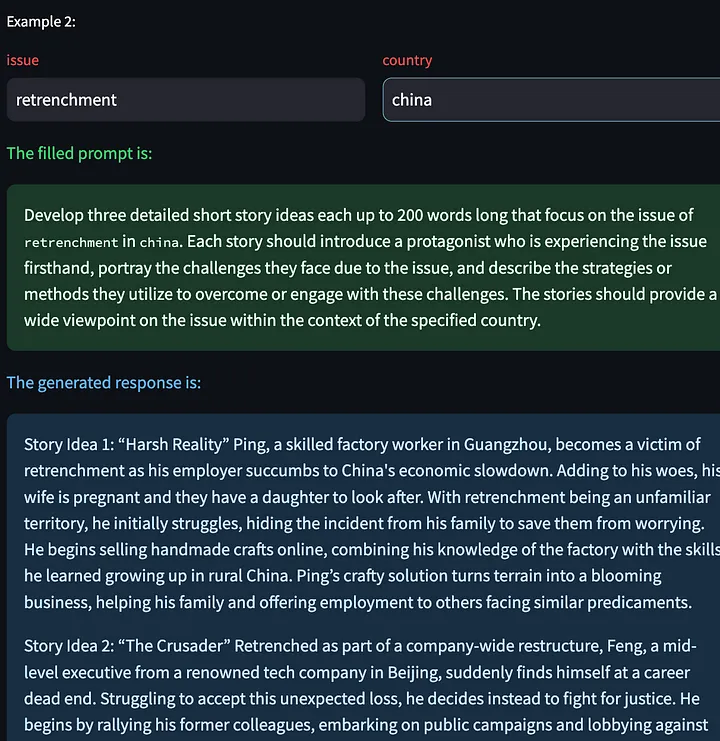
También tenemos la opción de hacer clic en "Generar siguiente ejemplo", lo que nos permite generar un nuevo modelo de respuesta basado en otras variables de entrada. Aquí hay algunas historias creativas generadas sobre el problema de los despidos en China:
Luego proporcione comentarios sobre el resultado del modelo anterior:
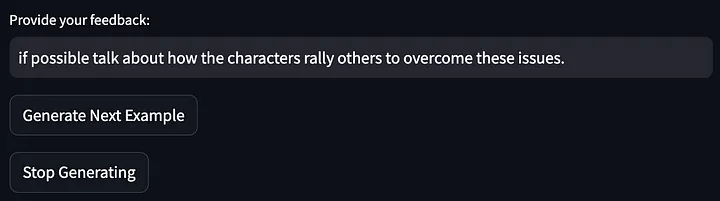
Luego, las palabras clave se optimizaron aún más:

Los resultados de la optimización esta vez se ven bastante bien. Después de todo, al principio era solo una simple palabra de aviso. Después de menos de dos minutos de comentarios (aunque algo casuales), se obtuvo la palabra de aviso optimizada después de tres iteraciones. Ahora, podemos continuar optimizando las palabras clave simplemente sentándonos y expresando insatisfacción con el resultado del LLM.
La implementación interna de esta función es comenzar desde meta-mensaje y optimizar y generar continuamente nuevas palabras de mensaje basadas en los comentarios dinámicos del usuario. No es nada especial y definitivamente hay margen de mejora, pero es un buen comienzo.
prompt_improvement_prompt = """
# Context #
You are given an original prompt.
The original prompt was used to generate some example responses. For each response, feedback was provided on how to improve the desired response.
Your task is to review all the feedback and then return an improved prompt that addresses the feedback, making it better at generating responses when prompted against the GPT language model.
# Guidelines #
- The original prompt will contain placeholders within double curly brackets. These are values for input that you will see in the examples.
- The improved prompt should not exceed 200 words
- Just return the improved prompt and nothing else before and after. Remember to include the same placeholders with double curly brackets.
- When generating the improved prompt, refrain from writing the entire prompt as one paragraph. Instead, you should use a combination of task descriptions, guidelines (in point form), and other sections to the prompt as appropriate.
- The guidelines should be in point form, and should not be a repetition of the task. The guidelines should also be distinct from one another.
- The improved prompt should be written in normal English that is best understood by the language model.
- Based on the feedback provided, you must rephrase the desired behavior of the response into `must`, imperative statements, instead of `should` suggestive statements.
- Improvements made to the prompt should not be overly specific to one single example.
# Details #
The original prompt is:
```
{original_prompt}
```
These are the examples that were provided and the feedback for each:
```
{examples}
```
The improved prompt is:
```
"""
Algunas observaciones al utilizar esta herramienta:
- GPT4 tiende a utilizar una gran cantidad de palabras al generar texto (la característica "políglota"). Por este motivo, pueden producirse dos efectos. En primer lugar, esta propiedad "detallada" puede fomentar el sobreajuste a ejemplos específicos . ** Si LLM recibe demasiadas palabras, las utilizará para corregir comentarios específicos proporcionados por el usuario. En segundo lugar, esta característica "verbal" puede dañar la efectividad de las palabras clave, especialmente en palabras largas, y alguna información guía importante puede quedar oscurecida. Creo que el primer problema se puede resolver escribiendo buenos metaindicadores para alentar al modelo a generalizar en función de los comentarios de los usuarios. Pero el segundo problema es más difícil. En otros casos de uso, las indicaciones instructivas a menudo se ignoran cuando la palabra es demasiado larga. Podemos agregar algunas restricciones en el metamensaje (como limitar el número de palabras en el ejemplo de mensaje proporcionado anteriormente) , pero esto es realmente arbitrario y algunas restricciones o reglas en las palabras del mensaje pueden verse afectadas por el modelo grande subyacente. El impacto de un atributo o comportamiento específico.
- Las palabras de aviso mejoradas a veces olvidan las optimizaciones anteriores de la palabra de aviso. Una forma de resolver este problema es proporcionar al sistema un historial de mejoras más largo, pero al hacerlo, las palabras de indicación de mejora se vuelven demasiado largas.
- Una ventaja de este enfoque en la primera iteración es que el LLM puede proporcionar orientación para mejoras que no forman parte de los comentarios de los usuarios. Por ejemplo, en la primera palabra de optimización anterior, la herramienta agregó "Proporcionar una perspectiva más amplia sobre el tema discutido...", aunque proporcioné que los comentarios son simplemente una solicitud de estadísticas relevantes de fuentes confiables.
Aún no he implementado esta herramienta porque todavía estoy trabajando en el metamensaje para ver qué funciona mejor y solucionar algunos de los problemas del marco optimizado y luego manejar otros errores o excepciones que puedan surgir en el programa. ¡Pero la herramienta debería estar disponible pronto!
03 En conclusión
Todo el campo de la ingeniería rápida se centra en proporcionar las mejores palabras rápidas para resolver tareas. APE y OPRO son los ejemplos más importantes y destacados en este campo, pero no lo representan todo. Estamos entusiasmados y ansiosos por ver cuánto progreso podemos lograr en este campo en el futuro. Evaluar los efectos de estas técnicas en diferentes modelos puede revelar las tendencias de trabajo o las características de trabajo de estos modelos y también puede ayudarnos a comprender qué técnicas de metaindicaciones son efectivas. Por lo tanto, creo que estas son tareas muy importantes que nos ayudarán a usar LLM. en nuestra vida diaria y práctica productiva.
Sin embargo, estos métodos pueden no ser adecuados para otras personas que deseen utilizar LLM para tareas creativas. Por ahora, existen muchos manuales de aprendizaje que pueden ayudarnos a comenzar, pero nada mejor que prueba y error. Por lo tanto, a corto plazo, creo que lo más valioso es cómo podemos completar de manera eficiente este proceso experimental que está en línea con nuestras fortalezas humanas (dar retroalimentación) y dejar que LLM haga el resto (mejorar las palabras clave).
También trabajaré más en mi POC (Prueba de concepto). Si está interesado en esto, contácteme ( https://www.linkedin.com/in/ianhojy/) .
¡Gracias por leer!
FIN
Referencias
[1] https://www.linkedin.com/in/moritz-laurer/?originalSubdomain=de
[2] https://arxiv.org/pdf/2205.11916.pdf
[3] https://arxiv.org/pdf/2211.01910.pdf
[4] https://arxiv.org/pdf/2309.03409.pdf
[5] https://github.com/keirp/automatic_prompt_engineer
[6] https://arxiv.org/abs/2104.08691
[7] https://medium.com/mantisnlp/automatic-prompt-engineering-part-i-main-concepts-73f94846cacb
[8] https://www.promptingguide.ai/techniques/ape
Este artículo fue compilado por Baihai IDP con la autorización del autor original. Si necesita reimprimir la traducción, comuníquese con nosotros para obtener autorización.
Enlace original:
https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
Decidí renunciar al código abierto Hongmeng Wang Chenglu, el padre del código abierto Hongmeng: El código abierto Hongmeng es el único evento de software industrial de innovación arquitectónica en el campo del software básico en China: se lanza OGG 1.0, Huawei contribuye con todo el código fuente. Google Reader es asesinado por la "montaña de mierda de códigos" Fedora Linux 40 se lanza oficialmente Ex desarrollador de Microsoft: el rendimiento de Windows 11 es "ridículamente malo" Ma Huateng y Zhou Hongyi se dan la mano para "eliminar rencores" Compañías de juegos reconocidas han emitido nuevas regulaciones : los regalos de boda de los empleados no deben exceder los 100.000 yuanes Ubuntu 24.04 LTS lanzado oficialmente Pinduoduo fue sentenciado por competencia desleal Compensación de 5 millones de yuanes