
Autor: Yue Yang, Chen Dequan, Liu Jingna
Beijing Yushi Technology Co., Ltd. se estableció en junio de 2023. Yushi Technology se posiciona como "la entrada temática en la era de la inversión inteligente en la era del cambio en la que la industria de gestión de activos pasa de estar centrada en las instituciones a estar centrada en los usuarios". , construye un motor de inversión temático, potencia la integración de la inversión inclusiva y crea un "nuevo puente" con inversores e instituciones de gestión de activos como tema y núcleo, y la interacción del lenguaje natural como entrada.

Yushi Technology procesa un promedio de 10,000 piezas de información financiera todos los días. Al recopilar información, descubrir tendencias emergentes y juzgar los puntos de inflexión de las tendencias, ha formado un sistema de inversión temático que incluye más de 10 súper temas, más de 40 temas de inversión y más de 200. subtemas; actualmente 10 Un cliente de referencia en la industria, brindando servicios a través de API de datos e informes semanales y mensuales. En la actualidad, se han publicado un total de unos 500 informes y casi 1.000 artículos de análisis de cuentas públicas. A largo plazo, crearemos un agente de inversión temático para miles de personas mediante la extracción en tiempo real de las intenciones de los usuarios y los cálculos temáticos.
Características de la plataforma y desafíos encontrados
Los productos de Yushi Technology son productos típicos de servicios de información. Después de que la plataforma recopila información de la industria financiera a través de múltiples canales y la almacena localmente, inicia procesos relevantes para su procesamiento de acuerdo con el marco de análisis de inversiones y, finalmente, forma productos de datos financieros para proporcionar servicios externos. Las funciones comerciales de la plataforma y los requisitos para los recursos del sistema tienen las siguientes características:
1. Gran cantidad de datos y diversos requisitos de almacenamiento
a) Los datos centrales de la plataforma son principalmente datos no estructurados. La cantidad total de datos en cada etapa de procesamiento, incluidos los datos de origen, los datos intermedios y los datos de resultados, está en el nivel de TB, aunque esta magnitud es pan comido para el almacenamiento de archivos u objetos. Sin embargo, todavía existe una cierta presión sobre el almacenamiento de análisis/índices.
b) El almacenamiento de datos no estructurados requiere soporte de interfaz de acceso múltiple cuando se enfrentan a diferentes procesos de procesamiento, incluidos archivos, objetos, bases de datos OLAP, sistemas de índice y caché, etc.
c) El procesamiento de información financiera debe cumplir con requisitos de puntualidad, por lo que también existen altos requisitos para el rendimiento de consultas de los sistemas de almacenamiento analítico.
2. El proceso de procesamiento de datos es complejo y cambiante.
a) El proceso de procesamiento de datos es la encarnación de la estrategia de análisis de inversiones en el sistema y es el núcleo de toda la plataforma. La lógica de procesamiento de nodos clave en estos procesos no se puede implementar a través de funciones de plataforma estandarizadas. Debe publicarse en la plataforma a través de código Java/Python y el proceso puede llamarla de manera flexible.
b) Para cumplir con los requisitos de la lógica empresarial, existen frecuentes requisitos de interacción y flujo de datos entre los nodos de procesamiento en el proceso de procesamiento, entre los nodos y las interfaces de almacenamiento de datos, e incluso entre procesos.
c) Las estrategias de inversión deben ajustarse oportunamente en respuesta a los cambios del mercado y las necesidades de los clientes. Los procesos de procesamiento de datos e incluso la lógica de procesamiento central deben ajustarse simultáneamente de acuerdo con las estrategias comerciales.
d) Debido a la complejidad de la lógica del procesamiento de datos, una vez que el desarrollo está en línea, a menudo es necesario rastrear y analizar el procesamiento de datos específicos en el entorno de producción, y es necesario poder ver fácilmente información detallada del tiempo de ejecución.
3. Hay picos y valles obvios en la demanda de recursos de plataformas.
a) Habrá picos fijos durante todo el día de funcionamiento de la plataforma, incluido el período en el que la información ingresa y se procesa de manera intensiva y el período en que el personal comercial realiza consultas intensivas. Al mismo tiempo, también se producen picos de acceso a principios de semana y principios de mes.
b) Los períodos pico requieren índices de expansión del rendimiento de procesamiento más altos, y los diferentes tipos de picos tienen diferentes requisitos para los recursos del sistema. Se requiere una planificación previa de las acciones de expansión para diferentes escenarios.
4. Requisitos de confiabilidad/puntualidad
a) La información seguirá generándose y fluyendo hacia la plataforma las 24 horas del día. Debe procesarse a los pocos minutos de ingresar a la plataforma y ingresar al grupo de datos del servicio externo. Por lo tanto, la plataforma debe poder procesarse de manera estable. y expandirse de forma continua y automática cuando se encuentre con un tráfico pico para evitar la acumulación de datos. Si existen omisiones o errores en el proceso de procesamiento, se deberá poder reintentar automáticamente.
b) Los sistemas externos relacionados con el servicio sirven como portal de acceso para los usuarios finales y tienen ciertos requisitos para la continuidad del servicio.
En vista del diseño de funciones de plataforma anterior, Yushi Technology tiene los siguientes requisitos para la infraestructura de TI, incluido IaaS/PaaS:
1. Diversos tipos de almacenamiento, acceso mutuo fluido entre sistemas, admite múltiples tipos de almacenamiento, acceso mutuo fluido entre varios sistemas de almacenamiento, uso diario, administración y transferencia de datos se pueden configurar a través de la GUI.
2. Proceso de procesamiento de datos simple y flexible
a) Proporcionar una entrada de gestión del flujo de procesamiento unificada y soportar el diseño gráfico del proceso.
b) Admite el uso de lenguajes de desarrollo comunes para implementar una lógica empresarial compleja y puede integrarse sin problemas en los procesos.
c) Entre los nodos de proceso, el proceso y la interfaz de almacenamiento de datos, se puede realizar un control interactivo complejo entre procesos.
d) El proceso de ejecución se puede rastrear y analizar, y datos o procesos específicos se pueden rastrear y analizar fácilmente.
3. Expansión y contracción automática del sistema.
a) La capacidad del sistema del proceso de procesamiento de datos se puede expandir y contraer automáticamente de acuerdo con los picos y valles del tráfico, y su expansión y contracción se puede procesar de acuerdo con ciertos scripts basados en dependencias entre sistemas.
b) Otros sistemas comerciales deben ajustarse automáticamente de acuerdo con los picos y valles del acceso comercial.
4. Mejorar la calidad y eficiencia generales del trabajo de I+D.
a) Reducir el costo directo de los recursos de TI y los costos de gestión al tiempo que se garantiza la confiabilidad del sistema b) Mejorar la eficiencia del proceso general de CI/CD;
Flujo de trabajo en la nube CloudFlow + Function Compute FC ayuda a mejorar el procesamiento de datos complejos
Yushi Technology es una empresa de tecnología de datos nacida bajo la ola de la nube nativa. Al comienzo de su creación, decidió adoptar la tecnología nativa de la nube para mejorar la calidad y eficiencia general del trabajo de TI y optimizar los costos.
Los desafíos encontrados para mejorar la calidad y la eficiencia se centran principalmente en los procesos de procesamiento de datos. Por lo tanto, además de utilizar herramientas habituales de mejora de la eficiencia de CI/CD como Alibaba Cloud y la implementación en contenedores, después de la inspección del equipo, finalmente elegimos el flujo de trabajo en la nube y las funciones Calculate. FC Dos nuevos productos. El objetivo es resolver la necesidad de gestionar procesos de datos complejos a través de Cloud Workflow CloudFlow y utilizar Function Compute FC para resolver el problema. Durante el funcionamiento de Cloud Workflow CloudFlow, algunos nodos procesan una lógica empresarial compleja y, al mismo tiempo, la lógica empresarial compleja. Las capacidades de procesamiento pueden resolver perfectamente la necesidad de escalamiento elástico.
El diagrama de flujo de datos es el siguiente:
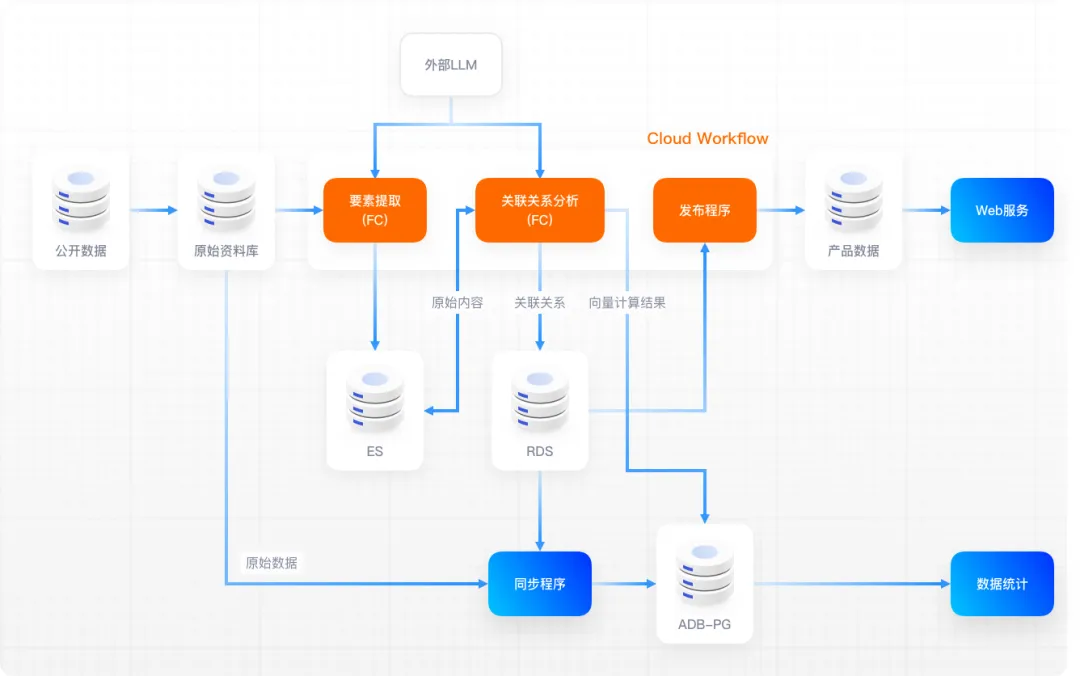
A través de la práctica, se ha descubierto que, para flujos de trabajo comunes, el uso de CloudFlow para desarrollar interfaces web reduce la carga de trabajo de desarrollo a aproximadamente la mitad en comparación con el uso de marcos de aplicaciones Java convencionales. Al mismo tiempo, dado que se omite el enlace de lanzamiento en línea, la eficiencia en línea aumenta. También se ha mejorado la depuración y la eficiencia de uso del seguimiento y la depuración basados en la consola web también se ha mejorado considerablemente después de un período de adaptación.
Durante los seis meses de uso, Yushi Technology ha desarrollado casi 20 flujos de trabajo. Los flujos de trabajo llaman a docenas de funciones y se ejecutan cientos de miles de veces. Aunque solo hay un ingeniero responsable del flujo de trabajo, todavía es posible mantener un promedio de lanzamiento de un nuevo flujo de trabajo cada dos semanas aproximadamente. Para los ingenieros, excepto por la necesidad ocasional de seguimiento y depuración en línea, básicamente no hay necesidad de preocuparse por el estado de ejecución del flujo de trabajo después de que se conecta, logrando realmente "liberarlo y olvidarse de él".
panorama
Como empresa emergente centrada en datos en la era de los grandes modelos, profundizaremos en la posibilidad de combinar plataformas de datos con capacidades de modelos grandes. A través de las capacidades de innovación de infraestructura proporcionadas por Alibaba, brindaremos a nuestros clientes finales capacidades más sólidas y. Más iteraciones. Productos de datos rápidos.
Decidí renunciar al software industrial de código abierto. Eventos importantes: se lanzó OGG 1.0, Huawei contribuyó con todo el código fuente y se lanzó oficialmente Ubuntu 24.04. El equipo de la Fundación Google Python fue despedido por la "montaña de código de mierda" . ". Se lanzó oficialmente Fedora Linux 40. Una conocida compañía de juegos lanzó Nuevas regulaciones: los obsequios de boda de los empleados no deben exceder los 100.000 yuanes. China Unicom lanza la primera versión china Llama3 8B del mundo del modelo de código abierto. Pinduoduo es sentenciado a compensar 5 millones de yuanes por competencia desleal. Método de entrada en la nube nacional: solo Huawei no tiene problemas de seguridad para cargar datos en la nube.