
Todos son bienvenidos a destacarnos en GitHub:
Sistema distribuido de aprendizaje causal de enlace completo OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Gran gráfico de conocimiento basado en modelos OpenSPG: https://github.com/OpenSPG/openspg
Sistema de aprendizaje de gráficos a gran escala OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
En menos de cinco años, la tecnología de modelos grandes y Transformers ha cambiado casi por completo el campo del procesamiento del lenguaje natural y ha comenzado a revolucionar campos como la visión por computadora y la biología computacional. El Dr. Sebastian Raschka se centra en artículos de investigación académica y ha preparado una lista de lecturas introductorias para investigadores y profesionales del aprendizaje automático. Después de leerla en orden, realmente podrá comenzar en el campo actual de la tecnología de modelos grandes.
Por supuesto, el Dr. Sebastian Raschka también mencionó que existen muchos otros recursos útiles, como por ejemplo:
- Jay Alammar的《Transformador ilustrado》;
- Más publicaciones de blog técnicas de Lilian Weng;
- Todos los catálogos y genealogía de Transformers organizados por Xavier Amatriain;
- Una implementación de código mínimo de un modelo de lenguaje generativo escrito con fines educativos por Andrej Karpathy;
- y una serie de conferencias y un capítulo de libro del autor de este artículo.
Comprender la arquitectura y las tareas principales.
Si eres nuevo en Transformers/modelos grandes, lo más sensato es empezar desde cero.
1. Traducción automática neuronal mediante aprendizaje conjunto para alinear y traducir (2014)
Autor: Bahdanau, Cho Wa Bengio
Enlace del artículo: https://arxiv.org/abs/1409.0473
Si tiene unos minutos libres, le recomiendo comenzar con este documento. Este artículo presenta un mecanismo de atención a las redes neuronales recurrentes (RNN) para mejorar las capacidades de modelado de secuencias largas. Esto permite a los RNN traducir oraciones más largas con mayor precisión, que fue la motivación detrás del desarrollo de la arquitectura Transformer original.
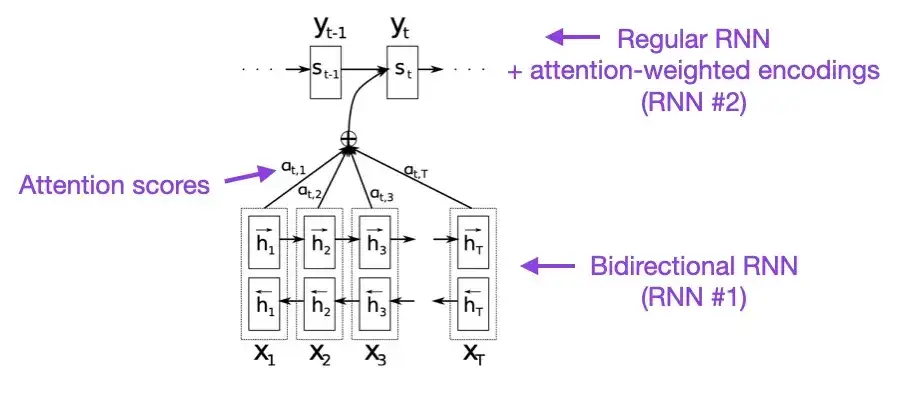
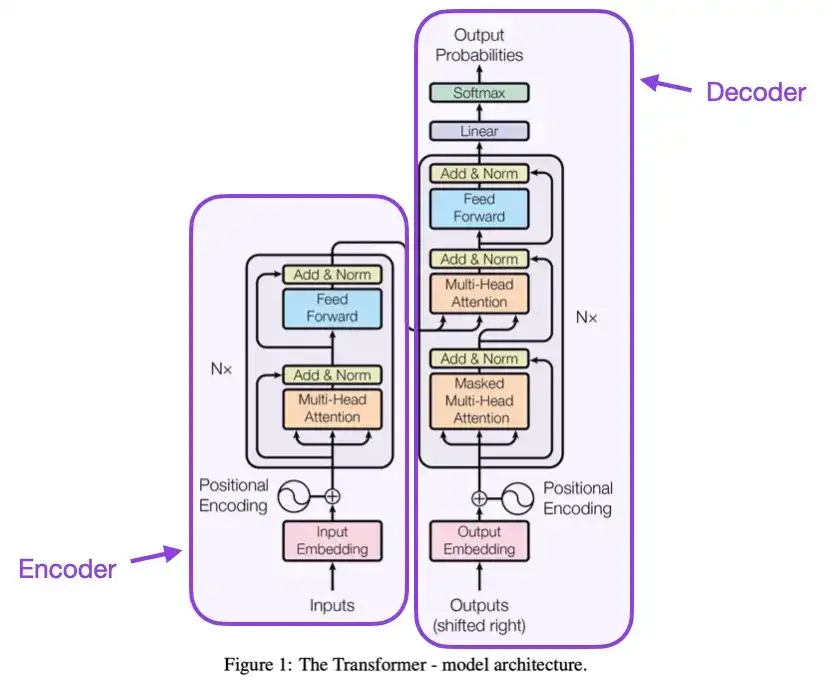
2. Todo lo que necesitas es atención (2017)
Créditos: Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser y Polosukhin
Enlace del artículo: https://arxiv.org/abs/1706.03762
Este artículo presenta la arquitectura Transformer original, que consta de dos partes: un codificador y un decodificador. Estas dos partes se convertirán posteriormente en módulos independientes para su explicación. Además, este artículo también presentó conceptos como el mecanismo de atención de productos escalables, los bloques de atención de múltiples cabezales y la codificación de entrada posicional, que siguen siendo la base de los modelos Transformer modernos.
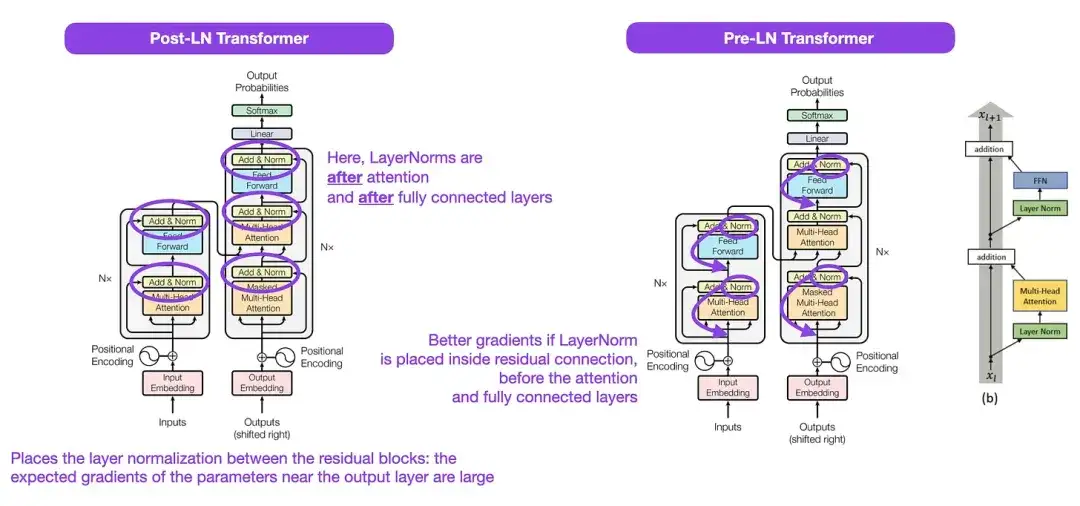
3. Sobre la normalización de capas en la arquitectura Transformer __ (2020)
Autores: Yang, He, K Zheng, S Zheng, Xing, Zhang, Lan, Wang, Liu
Enlace del artículo: https://arxiv.org/abs/2002.04745
Aunque la estructura Transformer original que se muestra en la figura anterior es un muy buen resumen de la arquitectura codificador-decodificador original, la posición de LayerNorm en la figura ha sido controvertida. Por ejemplo, el diagrama de estructura de Transformer en "La atención es todo lo que necesita" coloca LayerNorm entre los bloques residuales, lo cual es inconsistente con la implementación del código oficial (actualizado) que acompaña al documento original de Transformer. La variante que se muestra en la imagen de "La atención es todo lo que necesita" se llama Transformador Post-LN, y la implementación del código actualizado utiliza la variante Pre-LN de forma predeterminada.
En el artículo "Normalización de capas en la arquitectura del transformador", se señala que Pre-LN funciona mejor y puede resolver el problema del gradiente. Como se muestra a continuación, muchas arquitecturas adoptan este enfoque en la práctica, pero puede provocar un colapso de la representación. Por lo tanto, mientras continúa la discusión sobre si usar Post-LN o Pre-LN, un nuevo artículo "ResiDual: Transformer with Dual Residual Connections" ( https://arxiv.org/abs/2304.14802 ) propone utilizar ambas ventajas; su eficacia en la práctica aún está por verse.
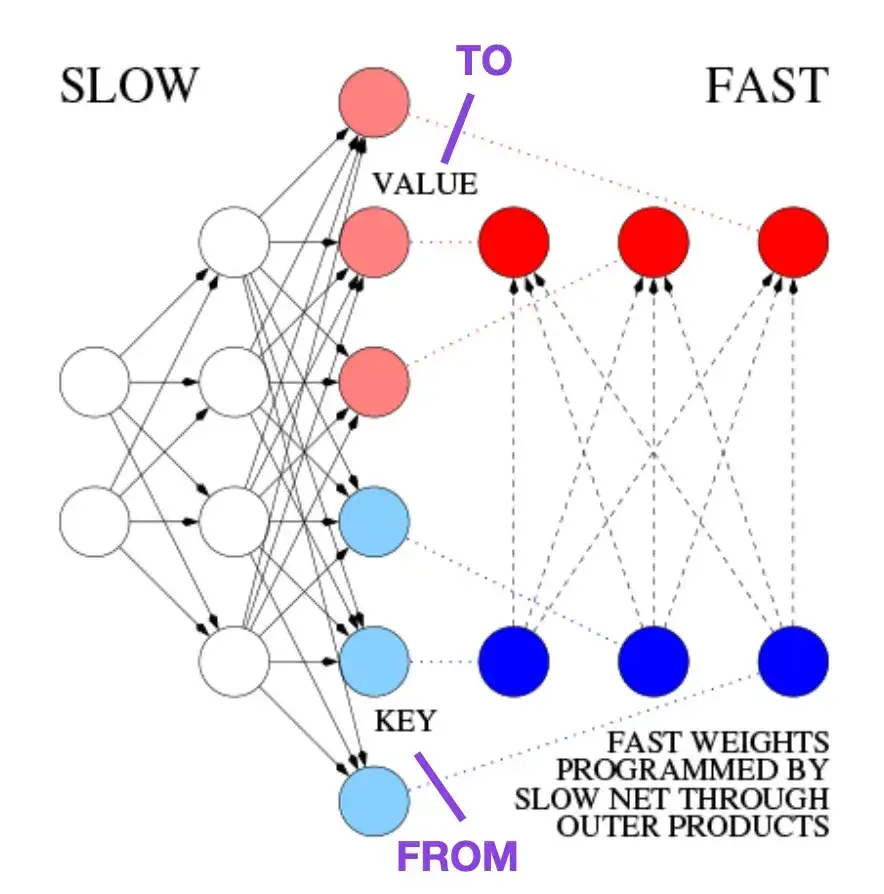
4. Aprender a controlar los recuerdos de peso rápido: una alternativa a las redes neuronales dinámicas recurrentes __ (1991)
Autor: Schmidhuber
Enlace del artículo:
Este artículo se recomienda para lectores interesados en anécdotas históricas y tecnologías tempranas similares a la arquitectura Transformer moderna. Por ejemplo, en 1991, aproximadamente 25 años antes del artículo original de Transformer, Attention Is All You Need , Juergen Schmidhuber propuso un programador de peso rápido (FWP) como alternativa a las redes neuronales recurrentes. El método FWP implica una red neuronal de avance que aprende lentamente a través del descenso de gradiente para programar los rápidos cambios de peso de otra red neuronal. La analogía con un transformador moderno se explica en la siguiente publicación del blog:
En la terminología actual de Transformer, FROM y TO se denominan claves y valores respectivamente. La ENTRADA utilizada por las redes rápidas se llama consulta. Básicamente, la consulta se procesa a través de una matriz de peso rápida, que es la suma de los productos externos de claves y valores (ignorando la normalización y la proyección). Dado que todas las operaciones de ambas redes son diferenciables, obtenemos un control activo diferenciable de extremo a extremo de cambios rápidos de peso mediante la adición de productos externos o productos tensoriales de segundo orden. Por lo tanto, la red lenta se puede aprender mediante el descenso de gradiente, modificando rápidamente la red rápida durante el procesamiento de secuencia. Esto es matemáticamente equivalente (excepto por la normalización) a lo que se conoció como Transformador Lineal de Autoatención (o Transformador Lineal).
Como se menciona en el extracto de la publicación del blog anterior, este enfoque ahora se conoce como "Transformador lineal" o "Transformador con autoatención linealizada". Posteriormente, la equivalencia entre la autoatención linealizada y los programadores de peso rápidos de la década de 1990 se demostró claramente en el artículo de 2021 "Los transformadores lineales son programadores de peso secretos rápidos".
5. Ajuste del modelo de lenguaje universal para la clasificación de textos (2018)
Autor; Howard, Ruder
Dirección del artículo: https://arxiv.org/abs/1801.06146
Este es un artículo muy interesante desde una perspectiva histórica. Fue escrito un año después del lanzamiento de "Attention Is All You Need", pero no involucró a Transformer, sino que se centró en redes neuronales recurrentes. Sin embargo, todavía merece atención, ya que propone efectivamente modelos de lenguaje previamente entrenados y transferencia de aprendizaje para tareas posteriores. Aunque el aprendizaje por transferencia está bien establecido en el campo de la visión por computadora, aún no se ha vuelto popular en el procesamiento del lenguaje natural (PNL). ULMFit es uno de los primeros artículos que demuestra modelos de lenguaje previamente entrenados y los ajusta a tareas específicas, lo que genera resultados de última generación en muchas tareas de PNL.
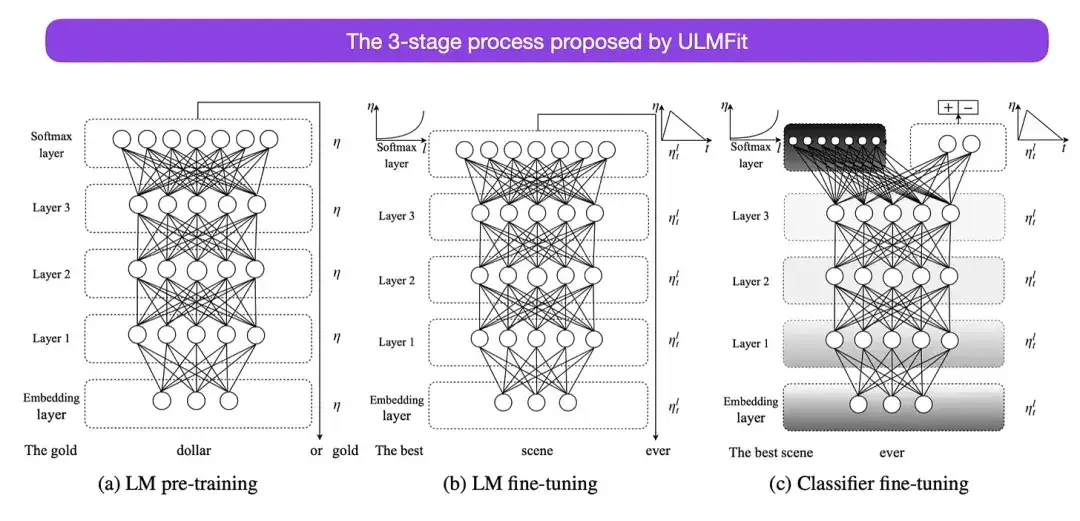
El proceso de tres etapas para ajustar los modelos de lenguaje propuesto por ULMFit es el siguiente:
- Entrene un modelo de lenguaje en un corpus de texto grande;
- Ajuste este modelo de lenguaje previamente entrenado con datos específicos de la tarea para adaptarlo al estilo y vocabulario del texto específico;
- Evite olvidos catastróficos descongelando capas gradualmente mientras ajusta el clasificador en datos específicos de la tarea.
Este método (primero entrenar un modelo de lenguaje en un corpus grande y luego ajustarlo a tareas posteriores) es el método central de los modelos basados en Transformer y los modelos básicos (como BERT, GPT-2/3/4, RoBERTa, etc.). Sin embargo, la parte clave en ULMFit, el descongelamiento gradual, generalmente no se realiza de manera rutinaria cuando realmente se opera la arquitectura del convertidor y, por lo general, todas las capas se ajustan a la vez.
6. BERT: Capacitación previa de transformadores bidireccionales profundos para la comprensión del lenguaje **** (2018)
Traducción: Devlin, Chang, Lee, Toutanova
Enlace del artículo: https://arxiv.org/abs/1810.04805
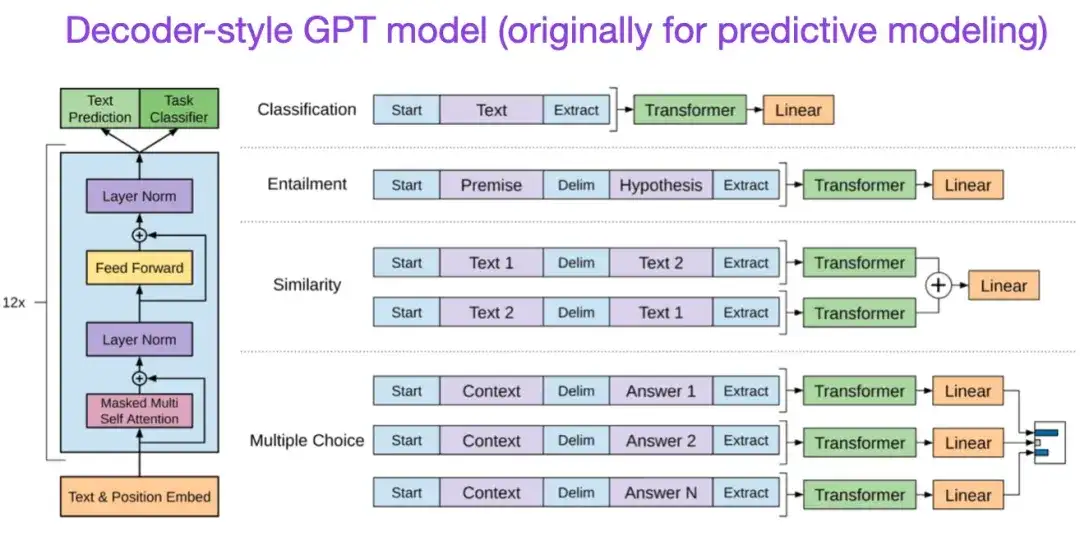
Según la arquitectura Transformer original, la investigación sobre modelos de lenguaje a gran escala comenzó a divergir en dos direcciones: Transformers basados en codificadores para tareas de modelado predictivo (como la clasificación de texto) y tareas de modelado generativo (como traducción, resumen y decodificador). estilo Transformer para otras formas de creación de texto).
El artículo BERT antes mencionado introdujo los conceptos originales de modelado de lenguaje enmascarado y predicción de la siguiente oración, y sigue siendo la arquitectura de estilo codificador más influyente. Si está interesado en esta rama de la investigación, le recomiendo que continúe aprendiendo sobre RoBERTa, que simplifica el objetivo previo al entrenamiento al eliminar la tarea de predicción de la siguiente oración.
** 7. Mejora de la comprensión del lenguaje mediante formación previa generativa (2018) ** Autor: Radford y Narasimhan Dirección del artículo:
El artículo original de GPT introdujo la popular arquitectura de estilo decodificador y el entrenamiento previo mediante la predicción de la siguiente palabra. Mientras que BERT puede verse como un transformador bidireccional debido a su objetivo de preentrenamiento del modelo de lenguaje enmascarado, GPT es un modelo autorregresivo unidireccional. Aunque las incorporaciones de GPT también se pueden utilizar para la clasificación, los métodos GPT son el núcleo de los modelos de lenguajes grandes (LLM) más influyentes de la actualidad, como ChatGPT.
Si está interesado en esta dirección de investigación, le recomiendo que continúe aprendiendo más sobre los artículos relacionados con GPT-2 y GPT-3. Estos dos artículos demuestran que los LLM pueden lograr un aprendizaje de pocas posibilidades y cero posibilidades, y destacan las capacidades emergentes de los LLM. GPT-3 sigue siendo el modelo básico y de referencia más utilizado para el entrenamiento de LLM actual. La tecnología InstructGPT que dio origen a ChatGPT se presentará en una entrada separada más adelante.
Artículos relacionados con GPT2: https://www.semanticscholar.org/paper/Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/9405cc0d6169988371b2755e573cc28650d14dfe
Artículos relacionados con GPT3: https://arxiv.org/abs/2005.14165
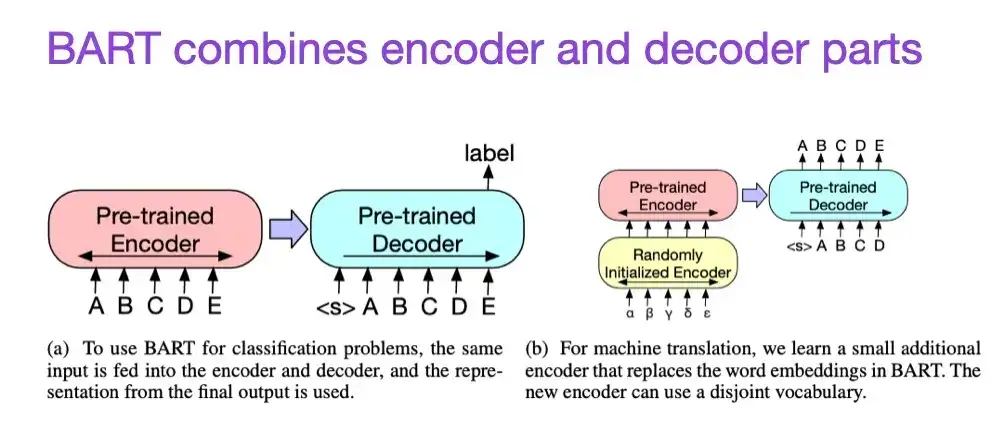
8. BART: Entrenamiento previo de eliminación de ruido de secuencia a secuencia para la generación, traducción y comprensión del lenguaje natural (2019)
Ejemplos: Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov, Zettlemoyer
Enlace del artículo: https://arxiv.org/abs/1910.13461 .
Como se mencionó anteriormente, los modelos de lenguaje grande (LLM) de estilo codificador tipo BERT generalmente son más adecuados para tareas de modelado predictivo, mientras que los LLM de estilo decodificador tipo GPT son mejores para generar texto. Para combinar lo mejor de ambos mundos, el documento BART mencionado anteriormente combina las partes del codificador y el decodificador (que es similar a la estructura original de Transformer presentada en el segundo documento).
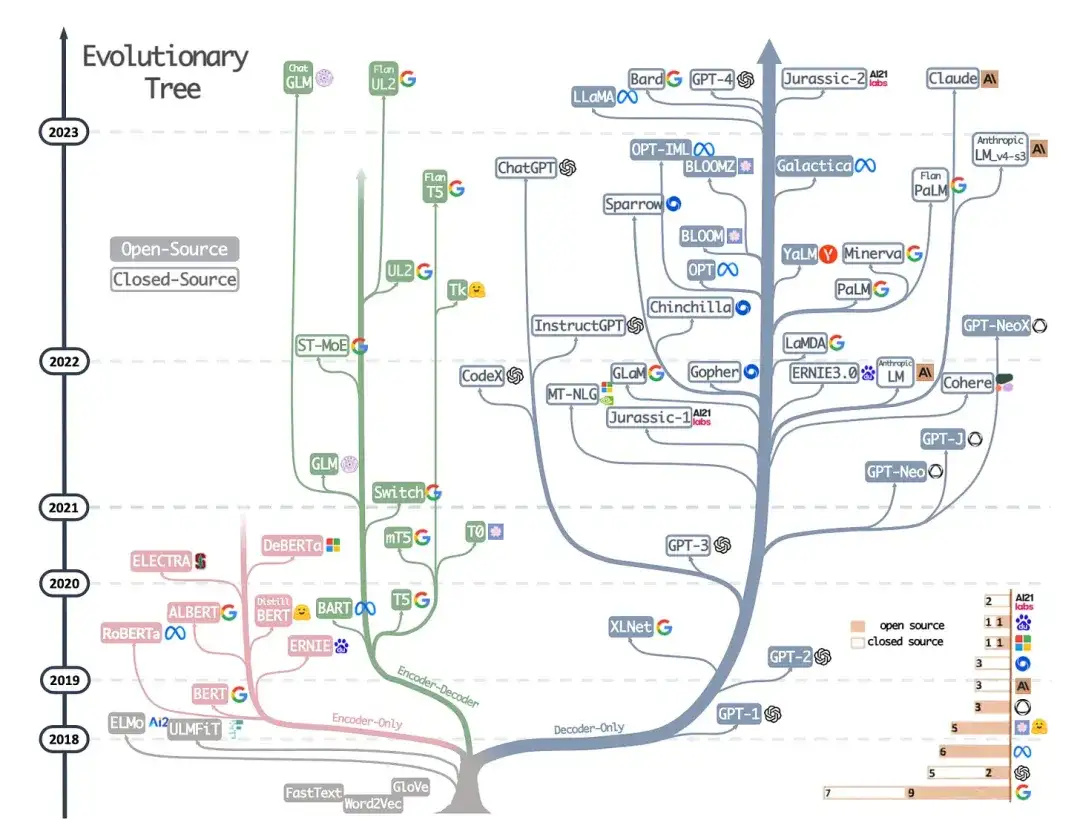
9. Aprovechar el poder de los LLM en la práctica: una encuesta sobre ChatGPT y más allá (2023)
Autor: Yang, Jin, Tang, Han, Feng, Jiang, Yin, Hu,
Enlace del artículo: https://arxiv.org/abs/2304.13712
Este no es un artículo de investigación, pero es probablemente el mejor artículo de descripción general de la arquitectura hasta el momento y muestra vívidamente cómo han evolucionado las diferentes arquitecturas. Sin embargo, además de analizar los modelos de lenguaje enmascarado (codificadores) de estilo BERT y los modelos de lenguaje autorregresivos (decodificadores) de estilo GPT, también proporciona discusión y orientación útiles sobre el entrenamiento previo y el ajuste de datos.
Leyes de escalamiento y mejora de la eficiencia
Si desea obtener más información sobre diversas técnicas para mejorar la eficiencia de los transformadores, le recomiendo leer el artículo de 2020 "Transformadores eficientes: una encuesta" y el artículo de 2023 "Una encuesta sobre capacitación eficiente de transformadores". Además, aquí hay algunos artículos que encontré particularmente interesantes y que vale la pena leer.
- 《Transformadores eficientes: una encuesta》:
https://arxiv.org/abs/2009.06732
- 《Encuesta sobre formación eficiente de transformadores》:
https://arxiv.org/abs/2302.01107
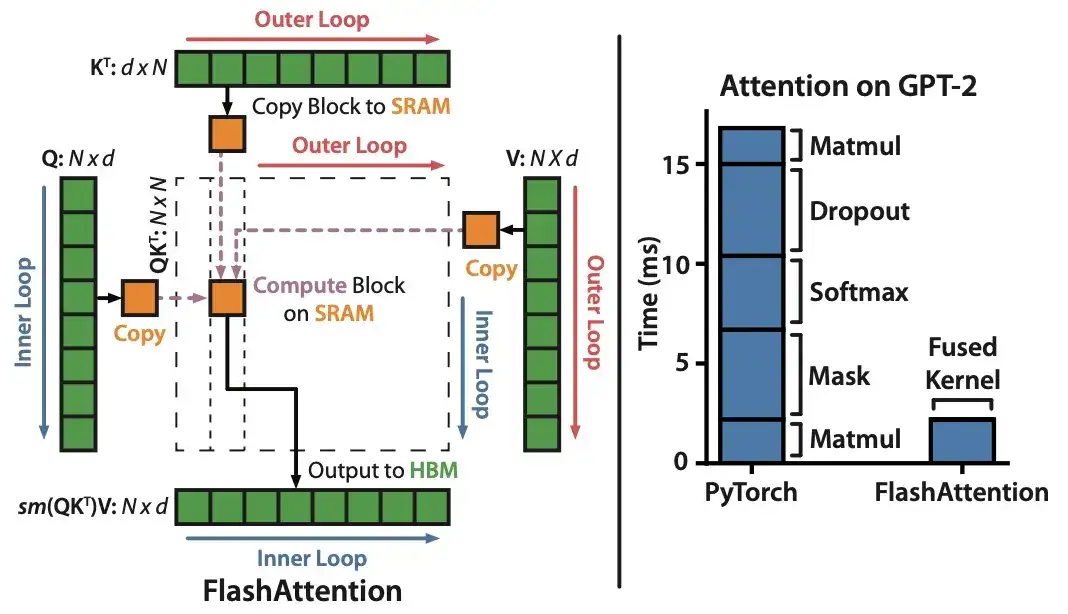
10. FlashAttention: Atención exacta, rápida y con uso eficiente de la memoria con IO-Awareness (2022)
Autor: Dao, Fu, Ermon, Rudra, Ré
Enlace del artículo: https://arxiv.org/abs/2205.14135 .
Aunque la mayoría de los artículos de Transformer no se molestan en reemplazar el mecanismo original del producto escalado para lograr la autoatención, el único mecanismo que veo citado más recientemente es FlashAttention.
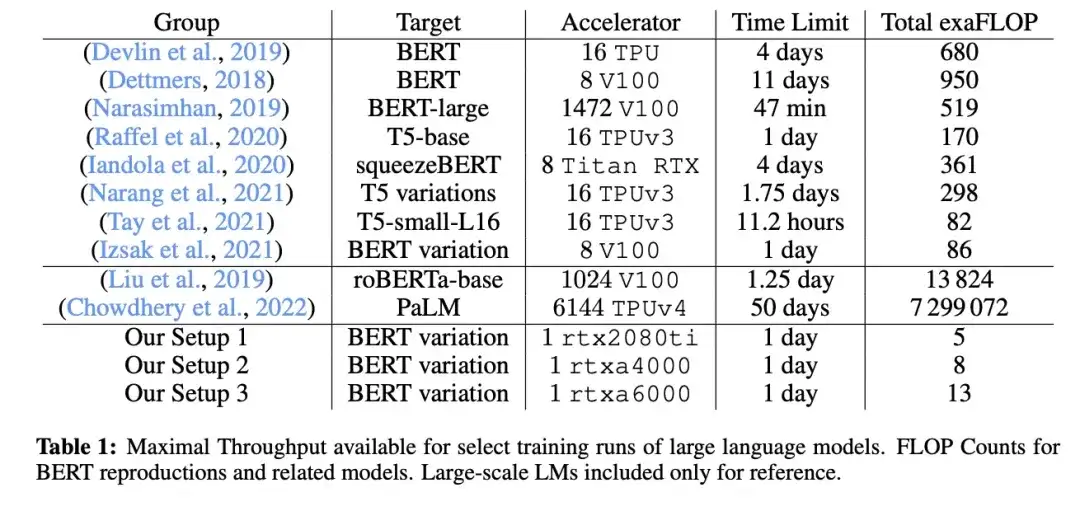
11. Cramming: entrenar un modelo de lenguaje en una sola GPU en un día (2022)
_Autor:_Geiping y Goldstein,
Enlace del artículo: https://arxiv.org/abs/2212.14034
En este artículo, los investigadores utilizaron una única GPU para entrenar un modelo de lenguaje grande estilo codificador/modelo de lenguaje enmascarado (aquí BERT) durante 24 horas. A modo de comparación, el documento BERT original de 2018 se entrenó en 16 TPU durante cuatro días. Un hallazgo interesante es que, aunque los modelos más pequeños tienen un mayor rendimiento, también aprenden de manera menos eficiente. Por lo tanto, los modelos más grandes no requieren tiempos de entrenamiento más largos para alcanzar un cierto umbral de rendimiento predictivo.
12. LoRA: Adaptación de bajo rango de modelos de lenguaje grandes (2021)
Autor: por Hu, Shen, Wallis, Allen-Zhu, Li, L Wang, S Wang, Chen
Enlace del artículo: https://arxiv.org/abs/2106.09685 .
Los modelos de lenguaje modernos a gran escala exhiben capacidades emergentes a través de un entrenamiento previo en conjuntos de datos a gran escala y funcionan bien en una variedad de tareas, incluida la traducción de idiomas, la generación de resúmenes, la programación y la respuesta a preguntas. Sin embargo, es valioso ajustar un transformador para mejorar sus capacidades en datos de dominios específicos y tareas especializadas. La adaptación de rango bajo (LoRA) es uno de los métodos más influyentes para el ajuste eficiente de parámetros de modelos de lenguaje grandes.
Aunque existen otros métodos para un ajuste eficiente de parámetros, LoRA merece especial atención porque es elegante y muy general y se puede aplicar a otros tipos de modelos. Los pesos de un modelo previamente entrenado tienen rango completo en la tarea para la que fueron entrenados previamente, mientras que los autores de LoRA señalan que los modelos de lenguaje grandes tienen una "dimensionalidad intrínseca" más baja cuando se adaptan a nuevas tareas. Por lo tanto, la idea central de LoRA es descomponer el cambio de peso ΔW en representaciones de rango inferior para lograr una mayor eficiencia de los parámetros.

13_. Reducir para ampliar: una guía para el ajuste fino eficiente de los parámetros (2022)_
Autor: Lialin, Deshpande, Rumshisky
Enlace del artículo: https://arxiv.org/abs/2303.15647 .
Esta revisión revisa más de 40 artículos sobre métodos eficientes de ajuste de parámetros (que cubren técnicas populares como ajuste de prefijo, adaptadores y adaptación de rango bajo), con el objetivo de hacer que el proceso de ajuste sea (extremadamente) computacionalmente eficiente.
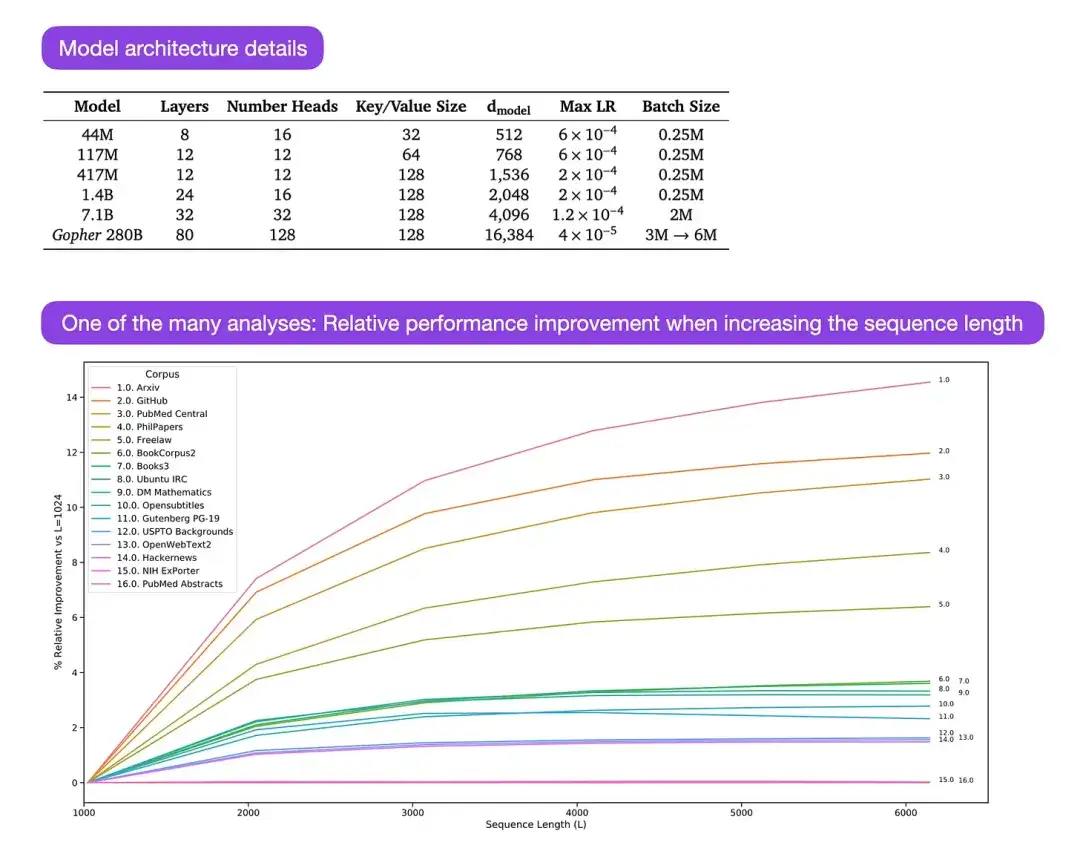
** 14. Escalamiento de modelos de lenguaje: métodos, análisis e información de Training Gopher (2022)** Autor: Rae y 78 colegas
Enlace del artículo: https://arxiv.org/abs/2112.11446
Gopher es un artículo particularmente bueno que contiene una gran cantidad de análisis para comprender el proceso de capacitación de modelos de lenguaje grandes (LLM). El investigador entrenó aquí un modelo con 280B de parámetros y 80 capas. El modelo se entrenó en base a 300B de tokens. Contiene algunas mejoras arquitectónicas interesantes, como el uso de RMSNorm (normalización cuadrática media) en lugar de LayerNorm (normalización de capas). Se prefieren tanto LayerNorm como RMSNorm a BatchNorm porque no dependen del tamaño del lote y no requieren sincronización, lo cual es especialmente ventajoso cuando se utilizan lotes más pequeños en entornos distribuidos. Sin embargo, en general se cree que RMSNorm es más eficaz para estabilizar el proceso de entrenamiento de arquitecturas profundas.
Aparte de estos interesantes detalles, el objetivo principal del artículo es analizar el desempeño de tareas a diferentes escalas. Las evaluaciones de 152 tareas diversas muestran que aumentar el tamaño del modelo tiene el efecto de mejora más significativo en tareas como la comprensión, la verificación de hechos y la identificación de lenguaje dañino. Sin embargo, las tareas relacionadas con el razonamiento lógico y matemático se benefician menos de las extensiones arquitectónicas.
15. Entrenamiento de modelos de lenguaje grande óptimos para la computación (2022)
作者:Hoffmann, Borgeaud, Mensch, Buchatskaya, Cai, Rutherford, de Las Casas, Hendricks, Welbl, Clark, Hennigan, Noland, Millican, van den Driessche, Damoc, Guy, Osindero, Simonyan, Elsen, Rae, Vinyals, 和 Sifre
Enlace del artículo: https://arxiv.org/abs/2203.15556 .
Este artículo presenta un modelo de parámetros de 70B llamado Chinchilla, que supera al popular modelo GPT-3 de parámetros de 175B en tareas de modelado generativo. Sin embargo, su punto central es señalar que los grandes modelos de lenguaje actuales están "significativamente subcapacitados". El artículo define una ley de escala lineal para el entrenamiento de modelos de lenguaje grandes. Por ejemplo, aunque Chinchilla tiene sólo la mitad del tamaño de GPT-3, supera a GPT-3 porque fue entrenado con 1,4 billones de tokens (en lugar de sólo 300 mil millones). En otras palabras, la cantidad de tokens de entrenamiento es tan importante como el tamaño del modelo.
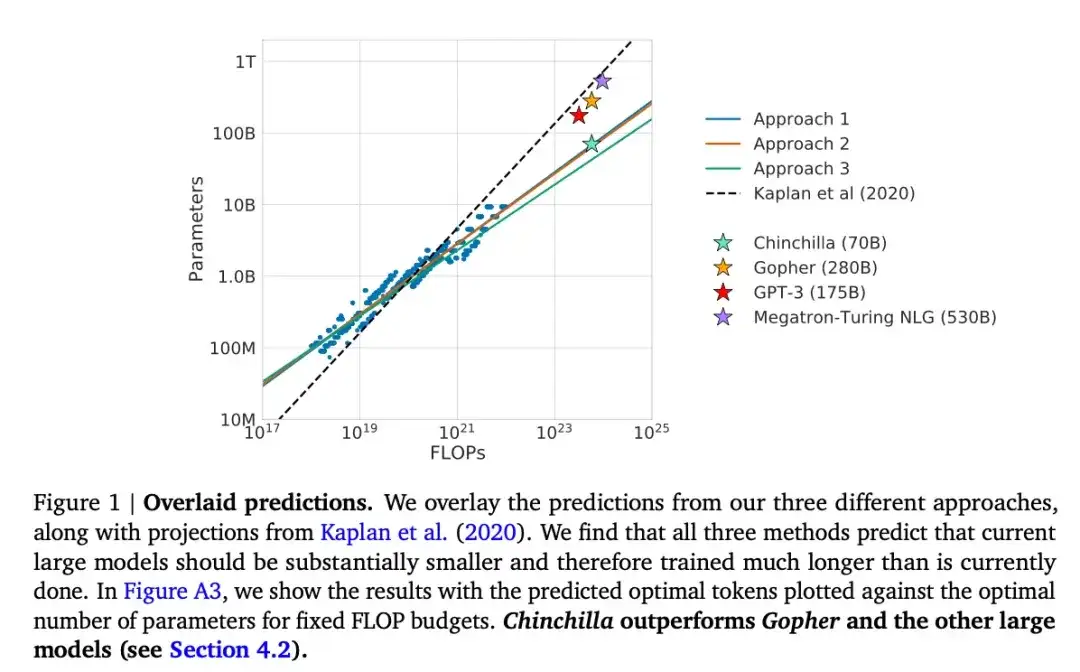
16.Pythia : una suite para analizar modelos de lenguaje grandes mediante capacitación y escalamiento (2023)
Traducción: Biderman, Schoelkopf, Anthony, Bradley, O'Brien, Hallahan, Khan, Purohit, Prashanth, Raff, Skowron, Sutawika, 和van der Wal
Enlace del artículo: https://arxiv.org/abs/2304.01373
Pythia es una serie de modelos de lenguajes grandes de código abierto (que van desde 700M a 12B de parámetros), diseñados para estudiar la evolución de modelos de lenguajes grandes durante el proceso de capacitación. Su arquitectura es similar a GPT-3, pero incluye algunas mejoras, como Flash Attention (similar a LLaMA) y Rotary Positional Embeddings (similar a PaLM). Pythia se entrena en el conjunto de datos The Pile (825 Gb) y el entrenamiento utiliza 300 mil millones de tokens (aproximadamente equivalente a 1 época en PILE normal o 1,5 épocas en PILE deduplicado).
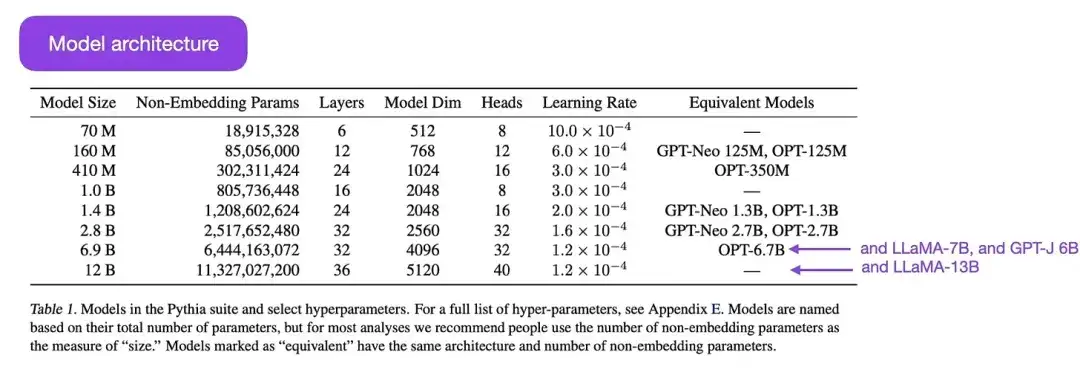
Los principales hallazgos del estudio de Pythia son los siguientes:
- El entrenamiento con datos repetidos (lo que significa entrenamiento para más de una época debido a la forma en que se entrenan los modelos de lenguaje grandes) no ayuda ni perjudica el rendimiento;
- El orden del entrenamiento no afecta el efecto memoria. Esto es desafortunado, porque si fuera cierto lo contrario, podríamos aliviar el problema indeseable de la memoria palabra por palabra reordenando los datos de entrenamiento;
- La frecuencia de las palabras durante el entrenamiento previo afecta el desempeño de la tarea. Por ejemplo, para las palabras que aparecen con más frecuencia, la precisión con un número menor de muestras tiende a ser mayor;
- Duplicar el tamaño del lote reduce el tiempo de entrenamiento a la mitad sin afectar la convergencia.
Alineación: guiar modelos de lenguaje grandes hacia los objetivos e intereses deseados
En los últimos años, hemos sido testigos de una serie de modelos de lenguaje a gran escala que son relativamente poderosos y capaces de generar texto realista (como GPT-3 y Chinchilla, etc.). Parece que hemos llegado al límite de lo que se puede lograr con los paradigmas de preformación comúnmente utilizados.
Para hacer que el modelo de lenguaje sea más útil y reducir la generación de información errónea y lenguaje dañino, los investigadores diseñaron paradigmas de entrenamiento adicionales para ajustar el modelo base previamente entrenado.
17. Capacitar modelos de lenguaje para seguir instrucciones con retroalimentación humana **** (2022)
Ejemplos: Ouyang, Wu, Jiang, Almeida, Wainwright, Mishkin, Zhang, Agarwal, Slama, Ray, Schulman, Hilton, Kelton, Miller, Simens, Askell, Welinder, Christiano, Leike, y Lowe,
Enlace del artículo: https://arxiv.org/abs/2203.02155 .
En el artículo llamado InstructGPT, los investigadores utilizaron un mecanismo de aprendizaje por refuerzo combinado con retroalimentación humana (RLHF). Primero utilizaron el modelo base GPT-3 previamente entrenado y lo perfeccionaron mediante aprendizaje supervisado en pares de señal-respuesta generados por humanos (paso 1). A continuación, entrenaron un modelo de recompensa haciendo que los humanos clasificaran los resultados del modelo (paso 2). Finalmente, utilizaron el modelo de recompensa para actualizar el modelo GPT-3 previamente entrenado y ajustado a través del método de aprendizaje por refuerzo de optimización de políticas próximas (paso 3).
Por cierto, este documento también se considera el documento que explica la idea detrás de ChatGPT: según rumores recientes, ChatGPT es una versión escalada de InstructGPT que ha sido ajustada con un conjunto de datos más grande.
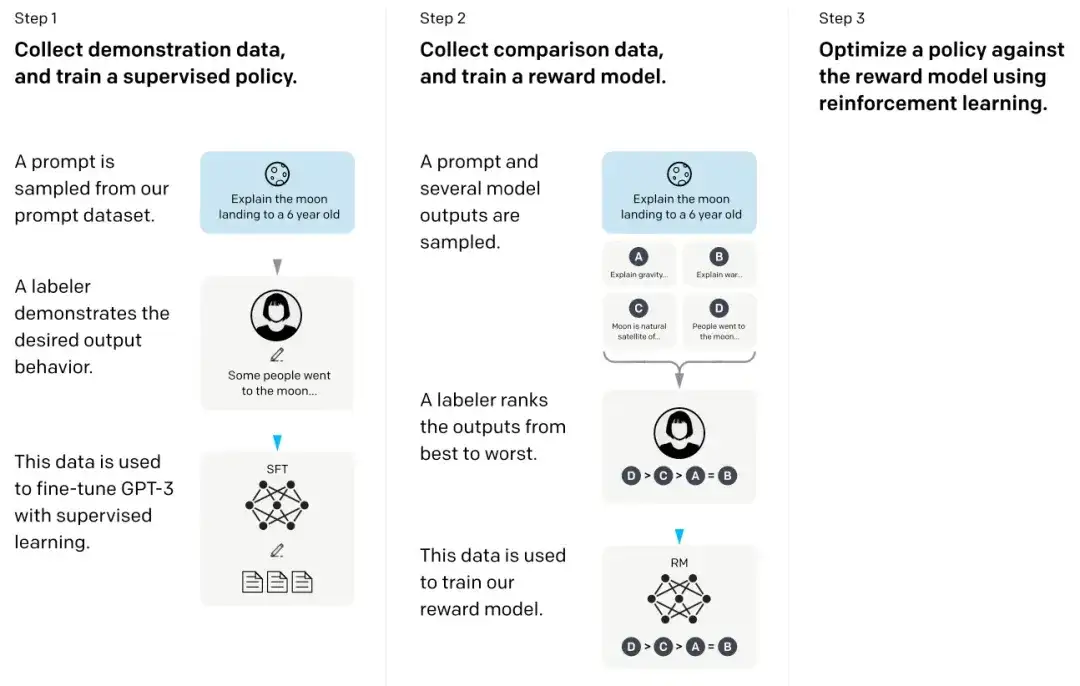
18. IA constitucional: inocuidad de los comentarios de la IA (2022 )
Destacados:Yuntao, Saurav, Sandipan, Amanda, Jackson, Jones, Chen, Anna, Mirhoseini, McKinnon, Chen, Olsson, Olah, Hernandez, Drain, Ganguli, Li, Tran-Johnson, Perez, Kerr, Mueller, Ladish, Landau, Ndousse, Lukosuite, Lovitt, Sellitto, Elhage, Schiefer, Mercado, DasSarma, Lasenby, Larson, Ringer, Johnston, Kravec, El Showk, Fort, Lanham, Telleen-Lawton, Conerly, Henighan, Hume, Bowman, Hatfield-Dodds, Mann , Amodei, Joseph, McCandlish, Brown, Kaplan
Enlace del artículo: https://arxiv.org/abs/2212.08073 .
En este artículo, los investigadores desarrollan aún más la idea de "alineación" y proponen un mecanismo de entrenamiento para crear sistemas de IA "inofensivos". En lugar de una supervisión humana directa, los investigadores proponen un mecanismo de autoentrenamiento basado en una lista de reglas proporcionadas por los humanos. De manera similar al artículo de InstructGPT mencionado anteriormente, el método propuesto utiliza métodos de aprendizaje por refuerzo.
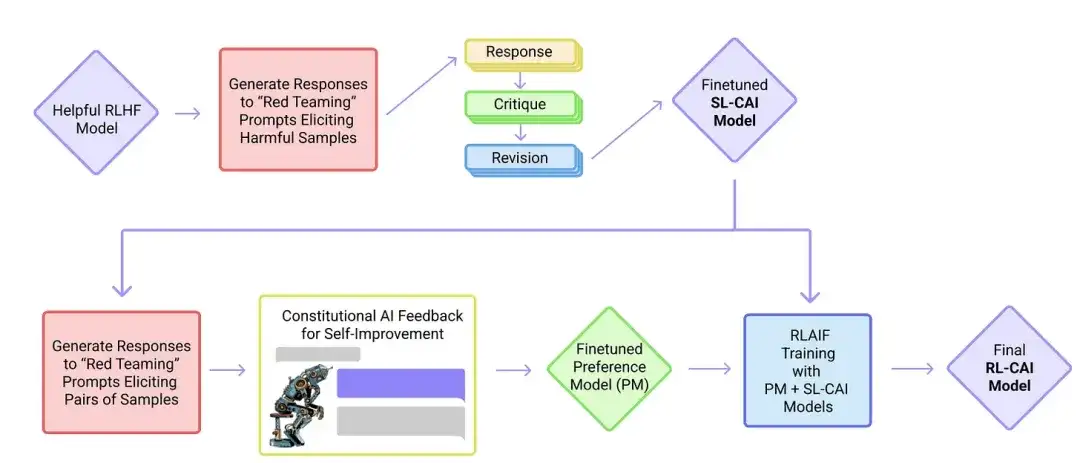
19. Autoinstrucción: Alinear el modelo lingüístico con la instrucción autogenerada (2022)
Autores del artículo: Wang, Kordi, Mishra, Liu, Smith, Khashabi y Hajishirzi
Enlace del artículo: https://arxiv.org/abs/2212.10560
El ajuste de instrucciones es la forma en que pasamos de modelos base previamente entrenados como GPT-3 a LLM más potentes como ChatGPT. Los conjuntos de datos de instrucciones de código abierto generados por humanos, como databricks-dolly-15k, pueden ayudar a que este proceso sea posible. Pero ¿cómo lograr escala? Un enfoque es permitir que LLM realice un aprendizaje de arranque basado en su propio contenido generado.
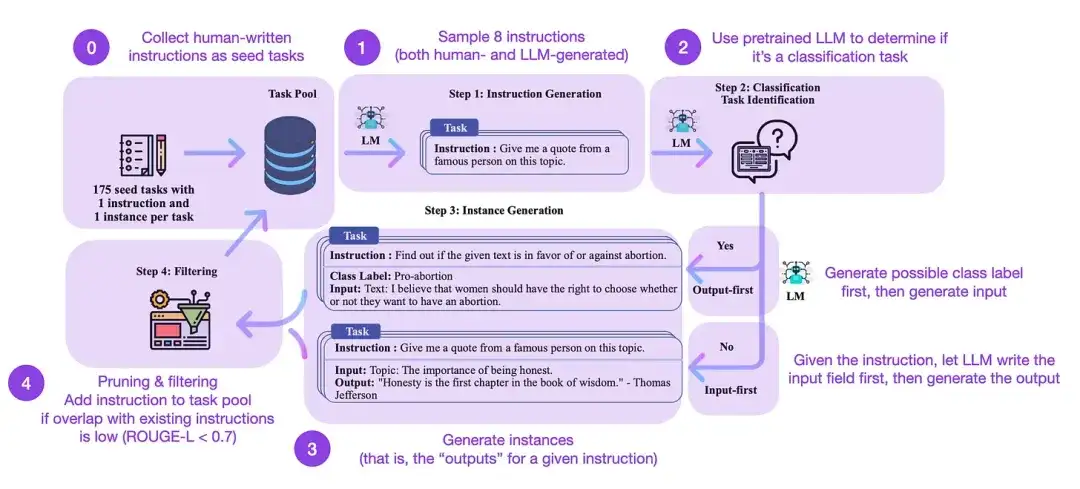
La autoinstrucción es un método (casi sin anotaciones) para alinear los LLM previamente capacitados con las instrucciones. ¿Cómo funciona este proceso? En resumen, consta de cuatro pasos:
- Inicialice un grupo de tareas con un conjunto de instrucciones escritas por humanos (175 en este caso) e instrucciones de muestra del mismo;
- Utilice un LLM previamente capacitado (como GPT-3) para determinar la categoría de la tarea;
- Para obtener nuevas instrucciones, deje que el LLM previamente capacitado genere respuestas;
- Estas respuestas se recopilan, filtran y filtran antes de agregarlas al grupo de tareas.
De esta manera, el método de autoinstrucción puede mejorar efectivamente la capacidad del modelo de lenguaje previamente entrenado para seguir y generar instrucciones mientras reduce la anotación manual, expandiendo y optimizando así las capacidades del modelo.
En la práctica, este método funciona relativamente bien según la puntuación de ROUGE. Por ejemplo, el ajuste fino autoguiado de modelos de lenguaje grandes (LLM) superó al modelo base GPT-3 y pudo competir con LLM previamente capacitados en grandes conjuntos de instrucciones escritas por humanos. Además, la autoorientación también puede beneficiar a los LLM que han sido perfeccionados mediante instrucciones humanas.
Por supuesto, el estándar de oro para evaluar un LLM es invitar a evaluadores humanos a participar. Basados en la evaluación humana, los métodos autoguiados van más allá del LLM básico, así como el LLM capacitado en conjuntos de datos de instrucción humana de manera supervisada (como SuperNI, T0 Trainer). Pero, curiosamente, la autoorientación no superó a aquellos entrenados mediante métodos de aprendizaje por refuerzo que incorporan retroalimentación humana (RLHF).
¿Qué es más prometedor: los conjuntos de datos de instrucciones generados por humanos o los conjuntos de datos autoguiados? Soy optimista en ambos. ¿Por qué no comenzar con un conjunto de datos de instrucciones generado por humanos, como las 15 000 instrucciones en databricks-dolly-15k, y luego ampliarlo de forma autodirigida?
Aprendizaje por refuerzo y retroalimentación humana (RLHF) Para obtener más explicaciones sobre el aprendizaje por refuerzo y la retroalimentación humana (RLHF), así como artículos relacionados sobre la optimización de políticas próximas para implementar RLHF, consulte mi artículo más detallado a continuación:
Cuando hablo de modelos de lenguaje grandes (LLM), ya sea en actualizaciones de investigación o tutoriales, a menudo me refiero a un proceso llamado aprendizaje reforzado con retroalimentación humana (RLHF). RLHF se ha convertido en una parte importante del proceso de formación LLM moderno porque puede incorporar las preferencias humanas en el marco de optimización, mejorando así la utilidad y seguridad del modelo.
Lee el artículo completo:
https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives
Conclusión y lectura adicional
Intenté mantener la lista anterior concisa y concisa, centrándome en los diez artículos principales (más tres artículos sobre RLHF) que comprenden el diseño, las limitaciones y la evolución de los modelos lingüísticos contemporáneos a gran escala. Para estudios adicionales, se recomienda consultar los documentos citados en los artículos anteriores. Aquí hay algunos recursos adicionales:
Alternativas de código abierto a GPT:
- BLOOM: un modelo de lenguaje multilingüe de acceso abierto con parámetros 176B (2022), https://arxiv.org/abs/2211.05100
- OPT: Modelos abiertos de lenguaje transformador previamente entrenados (2022), https://arxiv.org/abs/2205.01068
- UL2: Unificación de paradigmas de aprendizaje de idiomas (2022), https://arxiv.org/abs/2205.05131
Alternativas a ChatGPT:
- LaMDA: modelos de lenguaje para aplicaciones de diálogo (2022), https://arxiv.org/abs/2201.08239
- (Bloomz) Generalización multilingüe mediante ajuste multitarea (2022), https://arxiv.org/abs/2211.01786
- (Gorrión) Mejora de la alineación de los agentes de diálogo mediante juicios humanos específicos (2022), https://arxiv.org/abs/2209.14375
- BlenderBot 3: un agente conversacional implementado que aprende continuamente a participar de manera responsable, https://arxiv.org/abs/2208.03188
Grandes modelos en biocomputación:
- ProtTrans: hacia descifrar el lenguaje del código de la vida mediante el aprendizaje profundo autosupervisado y la informática de alto rendimiento (2021), https://arxiv.org/abs/2007.06225
- Predicción de estructura de proteínas altamente precisa con AlphaFold (2021), https://www.nature.com/articles/s41586-021-03819-2
- Los modelos de lenguaje grandes generan secuencias de proteínas funcionales en familias diversas (2023), https://www.nature.com/articles/s41587-022-01618-2
Recomendaciones de artículos
7 consejos rápidos para que tu conversación con IA sea más efectiva
En una era en la que todo el mundo es desarrollador, ¿sigue siendo útil aprender a programar?
Si hay alguna infracción, comuníquese con nosotros para eliminarla. Enlaces de referencia:
https://magazine.sebastianraschka.com/p/understanding-large-language-models
Síganos
OpenSPG:
Sitio web oficial: https://spg.openkg.cn
Github: https://github.com/OpenSPG/openspg
OpenASCE:
Sitio web oficial: https://openasce.openfinai.org/
GitHub: [https://github .com /motor-causal-abierto-a-toda-escala/OpenASCE ]