
Autor | Invisible (Xing Ying), ingeniero senior del kernel de bases de datos en NetEase
Edición y acabado|Equipo técnico de SelectDB
Introducción: Como importantes líneas de negocios de NetEase, Lingxi Office y Yunxin han construido respectivamente la plataforma de monitoreo Lingxi Eagle y la plataforma de datos Yunxin para abordar los desafíos del procesamiento y análisis de datos de series temporales/registros a gran escala. Este artículo se centrará en la aplicación de Apache Doris en registros de NetEase y escenarios de series temporales, y en cómo utilizar Apache Doris para reemplazar Elasticsearch e InfluxDB, logrando así menores recursos del servidor y una mayor experiencia de rendimiento de consultas. En comparación con Elasticsearch, la velocidad de consulta de Apache Doris es. al menos Mejorado 11 veces, ahorrando recursos de almacenamiento hasta en un 70%.
Con el rápido desarrollo de la tecnología de la información, la cantidad de datos empresariales se ha disparado. Para una gran empresa de Internet como NetEase, todos los días se genera una gran cantidad de registros y datos de series de tiempo, ya sean sistemas de oficina internos o servicios proporcionados externamente. Estos datos se han convertido en una piedra angular importante para la resolución de problemas, el diagnóstico de problemas, el monitoreo de seguridad, las advertencias de riesgos, el análisis del comportamiento del usuario y la optimización de la experiencia. Aprovechar al máximo el valor de estos datos ayudará a mejorar la confiabilidad, el rendimiento, la seguridad y la satisfacción del usuario del producto.
Como importantes líneas de negocios de NetEase, Lingxi Office y Yunxin han construido la plataforma de monitoreo Lingxi Eagle y la plataforma de datos Yunxin, respectivamente, para hacer frente a los desafíos que plantea el procesamiento y análisis de datos de registros/series temporales a gran escala. A medida que el negocio continúa expandiéndose, los datos de registros/series temporales también han crecido exponencialmente, lo que ha provocado problemas como mayores costos de almacenamiento, tiempos de consulta prolongados y deterioro de la estabilidad del sistema. La plataforma inicial era insostenible, lo que llevó a NetEase a buscar mejores soluciones.
Este artículo se centrará en la implementación de Apache Doris en escenarios de series de tiempo y registros de NetEase, presentará la práctica de actualización de la arquitectura de Apache Doris en NetEase Lingxi Office y NetEase Cloud Letter Business, y compartirá la experiencia de creación, importación y consulta de tablas. basado en escenarios reales.
Arquitectura temprana y puntos débiles
01 Plataforma de monitoreo Lingxi-Eagle
NetEase Lingxi Office es una plataforma de oficina colaborativa de correo electrónico de nueva generación. Integre módulos como correo electrónico, calendario, documentos en la nube, mensajería instantánea y gestión de clientes. La plataforma de monitoreo Eagle es un sistema APM de enlace completo que puede proporcionar análisis de rendimiento multidimensional y de diferente granularidad para NetEase Lingxi Office.
La plataforma de monitoreo Eagle almacena y analiza principalmente datos de registros comerciales, como Lingxi Office, Enterprise Email, Youdao Cloud Notes y Lingxi Documents. Los datos de registro primero se recopilan y procesan a través de Logstash y luego se almacenan en Elasticsearch, que realiza registros en tiempo real. recuperación y análisis. También proporciona servicios de búsqueda de registros y consulta de registros de enlace completo para Lingxi Office.

A medida que pasa el tiempo y crecen los datos de registro, gradualmente salen a la luz algunos problemas en el proceso de uso de Elasticsearch:
- Alta latencia de consulta: en las consultas diarias, la latencia de respuesta promedio de Elasticsearch es alta, lo que afecta la experiencia del usuario. Esto está restringido principalmente por factores como el tamaño de los datos, la racionalidad del diseño del índice y los recursos de hardware.
- Altos costos de almacenamiento: en el contexto de la reducción de costos y la mejora de la eficiencia, las empresas tienen una necesidad cada vez más urgente de reducir los costos de almacenamiento. Sin embargo, dado que Elasticsearch tiene múltiples almacenes de datos, como almacenamiento de filas directas, filas invertidas y columnas, el grado de redundancia de datos es alto, lo que plantea ciertos desafíos para la reducción de costos y la mejora de la eficiencia.
02 Plataforma de datos Yunxin
NetEase Yunxin es un experto en comunicaciones convergentes y servicios PaaS nativos de la nube construido sobre los 26 años de tecnología de NetEase. Proporciona comunicaciones convergentes y productos y soluciones centrales nativos de la nube, que incluyen mensajería instantánea de mensajería instantánea, video en la nube, SMS, microservicios de Qingzhou y middleware PaaS. . esperar.
La plataforma de datos Yunxin analiza principalmente datos de series temporales generados por IM, RTC, SMS y otros servicios. La arquitectura de datos inicial se construyó principalmente en base a la base de datos de series temporales InfluxDB. La fuente de datos se informó primero a través de la cola de mensajes de Kafka. Después del análisis y la limpieza del campo, se almacenó en la base de datos de series temporales InfluxDB para proporcionar consultas en línea y fuera de línea. El lado fuera de línea admite el análisis de datos T + 1 fuera de línea, y el lado en tiempo real debe proporcionar generación en tiempo real de informes y facturas de seguimiento de indicadores.
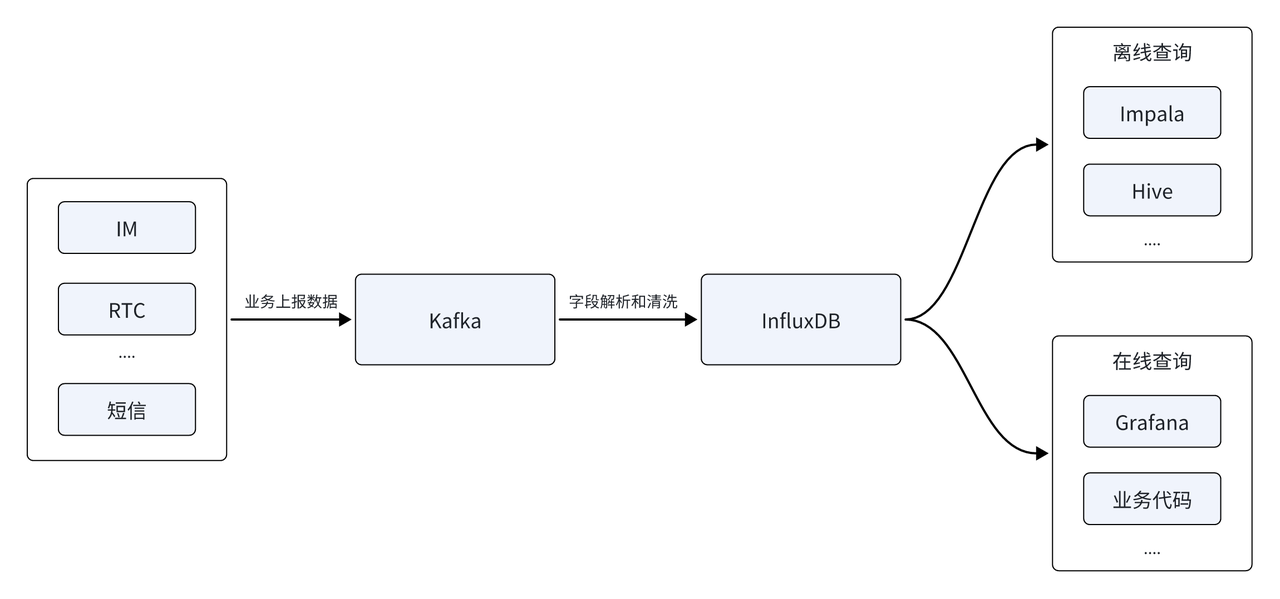
Con la rápida cobertura de la escala de clientes, la cantidad de fuentes de datos reportadas continúa aumentando e InfluxDB también enfrenta una serie de nuevos desafíos:
- Desbordamiento de memoria OOM: a medida que aumenta la cantidad de fuentes de datos, es necesario realizar un análisis fuera de línea en función de múltiples fuentes de datos y aumenta la dificultad del análisis. Limitada por las capacidades de consulta de InfluxDB, la arquitectura actual puede causar falta de memoria (OOM) cuando se enfrenta a consultas complejas de múltiples fuentes de datos, lo que plantea un gran desafío para la disponibilidad empresarial y la estabilidad del sistema.
- Altos costos de almacenamiento: el desarrollo de los negocios también ha provocado un crecimiento continuo del volumen de datos del clúster, y una gran proporción de los datos en el clúster son datos fríos y calientes que se almacenan de la misma manera, lo que genera altos costos de almacenamiento. Esto es incompatible con la reducción de costos y aumenta el conflicto con objetivos corporativos efectivos.
Selección del motor principal
Por esta razón, NetEase comenzó a buscar nuevas soluciones de bases de datos, con el objetivo de resolver los desafíos que enfrentan las dos empresas principales mencionadas anteriormente en escenarios de sincronización de registros. Al mismo tiempo, NetEase espera utilizar solo una base de datos para adaptarse al sistema empresarial y la arquitectura técnica de los dos escenarios de aplicaciones principales, satisfaciendo las necesidades de actualización de extrema facilidad de uso y baja inversión. En este sentido, Apache Doris cumple con nuestros requisitos de selección, concretamente en los siguientes aspectos:
- Optimización de costos de almacenamiento : Apache Doris ha realizado muchas optimizaciones en la estructura de almacenamiento para reducir el almacenamiento redundante. Tiene una relación de compresión más alta y admite almacenamiento por niveles frío y caliente basado en S3 y NOS (Netease Object Storage), lo que puede reducir eficazmente los costos de almacenamiento y mejorar la eficiencia del almacenamiento de datos.
- Alto rendimiento y alto rendimiento : Apache Doris admite escritura en disco de alto rendimiento de almacenamiento en columnas, compactación secuencial e importación de transmisión eficiente de Stream Load, y puede admitir decenas de GB de escritura de datos por segundo. Esto no solo garantiza la escritura a gran escala de datos de registro, sino que también proporciona visibilidad de consultas de baja latencia.
- Recuperación de registros en tiempo real : Apache Doris no solo admite la recuperación de texto completo de los registros, sino que también permite la respuesta a consultas en tiempo real. Doris admite la adición de un índice invertido internamente, que puede satisfacer la recuperación de texto completo de tipos de cadenas y la recuperación equivalente y de rango de tipos numéricos/de fecha ordinarios. Al mismo tiempo, puede optimizar aún más el rendimiento de la consulta del índice invertido y hacerlo más. adecuado para el análisis de datos de registros.
- Admite el aislamiento de inquilinos a gran escala : Doris puede alojar miles de bases de datos y decenas de miles de tablas de datos, y puede permitir que un inquilino use una base de datos de forma independiente, satisfaciendo las necesidades de aislamiento de datos de múltiples inquilinos y garantizando la privacidad y seguridad de los datos.
Además, el año pasado, Apache Doris continuó profundizando en el escenario de registro y lanzó una serie de capacidades centrales, como índice invertido eficiente, tipo de datos variante flexible, etc., para proporcionar un mejor procesamiento y análisis de registro/tiempo. Datos en serie. Soluciones eficientes y flexibles . Basándose en las ventajas anteriores, NetEase finalmente decidió introducir Apache Doris como el motor central de la nueva arquitectura.
Plataforma unificada de análisis y almacenamiento de registros basada en Apache Doris
01 Plataforma de monitoreo Lingxi-Eagle

Primero, en la plataforma de monitoreo Lingxi Office-Eagle, NetEase actualizó con éxito Elasticsearch a Apache Doris, creando así una plataforma unificada de análisis y almacenamiento de registros. Esta actualización arquitectónica no sólo mejora significativamente el rendimiento y la estabilidad de la plataforma, sino que también le proporciona un servicio de recuperación de registros potente y eficiente. Los beneficios específicos se reflejan en:
- Los recursos de almacenamiento se ahorran en un 70 %: gracias a la alta relación de compresión del almacenamiento de columnas de Doris y ZSTD, Elasticsearch requiere 100 T de espacio de almacenamiento para almacenar los mismos datos de registro, pero solo se requieren 30 T de espacio de almacenamiento para almacenarlos en Doris, lo que ahorra un 70 %. % de recursos de almacenamiento . Debido al importante ahorro en espacio de almacenamiento, se puede utilizar SSD para almacenar datos activos en lugar de HDD al mismo costo, lo que también traerá una mayor mejora en el rendimiento de las consultas.
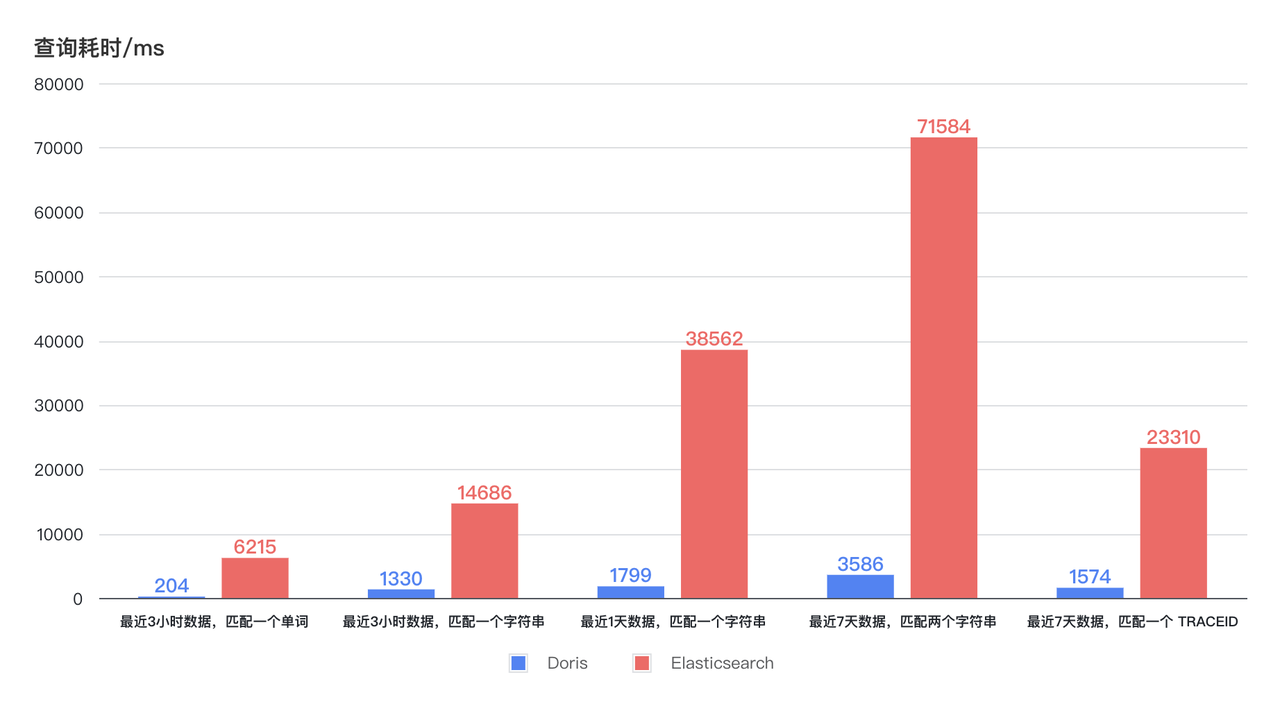
- La consulta se acelera 11 veces: la nueva arquitectura ofrece una mejora decenas de veces en la eficiencia de las consultas con un menor consumo de recursos de CPU. Como se puede ver en el diagrama a continuación, el tiempo de consulta de Doris para la recuperación de registros en las últimas 3 horas, 1 día y 7 días permanece estable y es inferior a 4 segundos, y la respuesta más rápida puede ser en 1 segundo. El tiempo de consulta de Elasticsearch muestra grandes fluctuaciones, siendo el tiempo más largo de hasta 75 segundos, e incluso el tiempo más corto de 6 a 7 segundos. Con un menor uso de recursos, la eficiencia de las consultas de Doris es al menos 11 veces mayor que la de Elasticsearch .
02 Plataforma de datos Yunxin
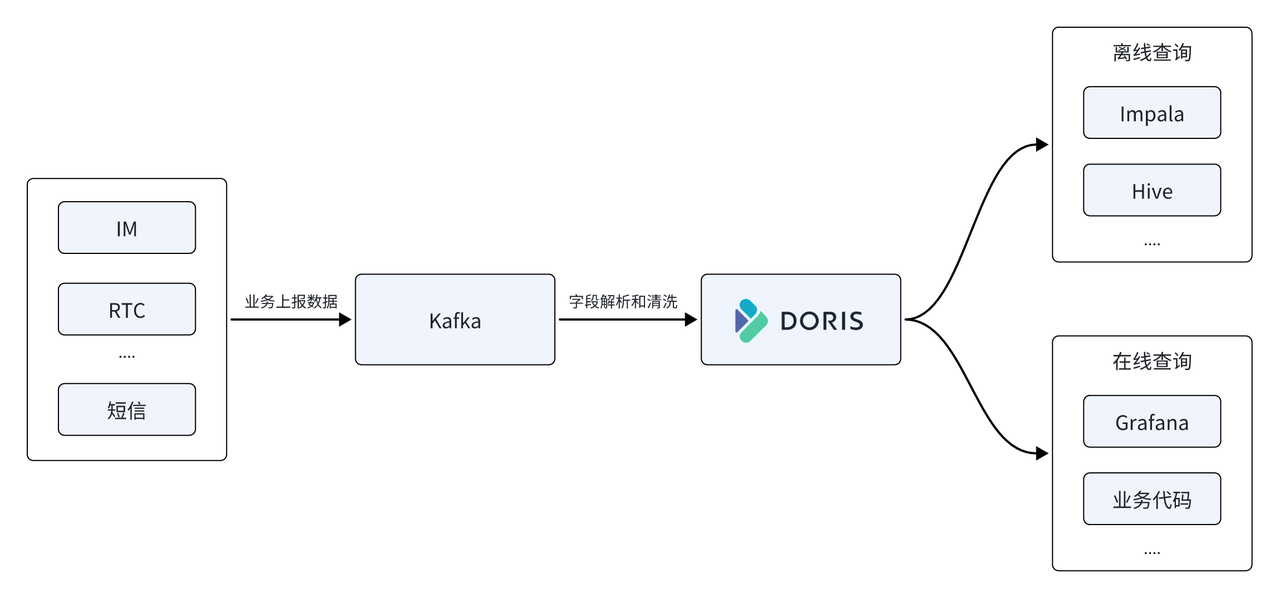
En la plataforma de datos Yunxin, NetEase también utiliza Apache Doris para reemplazar la base de datos de series temporales InfluxDB en la arquitectura inicial, usándola como el motor informático y de almacenamiento central de la plataforma de datos, y Apache Doris proporciona servicios de consulta unificados fuera de línea y en tiempo real.
- Admite escritura de alto rendimiento: tráfico de escritura en línea promedio de 500 M/s, pico de 1 GB/s, InfluxDB usa 22 servidores y el uso de recursos de CPU es aproximadamente del 50 %, mientras que Doris solo usa 11 máquinas y el uso de CPU es aproximadamente del 50 % , el consumo total de recursos es sólo la mitad del anterior .
- Los recursos de almacenamiento se ahorraron un 67 %: se utilizaron 11 máquinas físicas Doris para reemplazar 22 InfluxDB. Para almacenar la misma escala de datos, InfluxDB requiere 150 T de espacio de almacenamiento, mientras que almacenarlo en Doris solo requiere 50 T de espacio de almacenamiento, lo que ahorra un 67 % en recursos de almacenamiento .
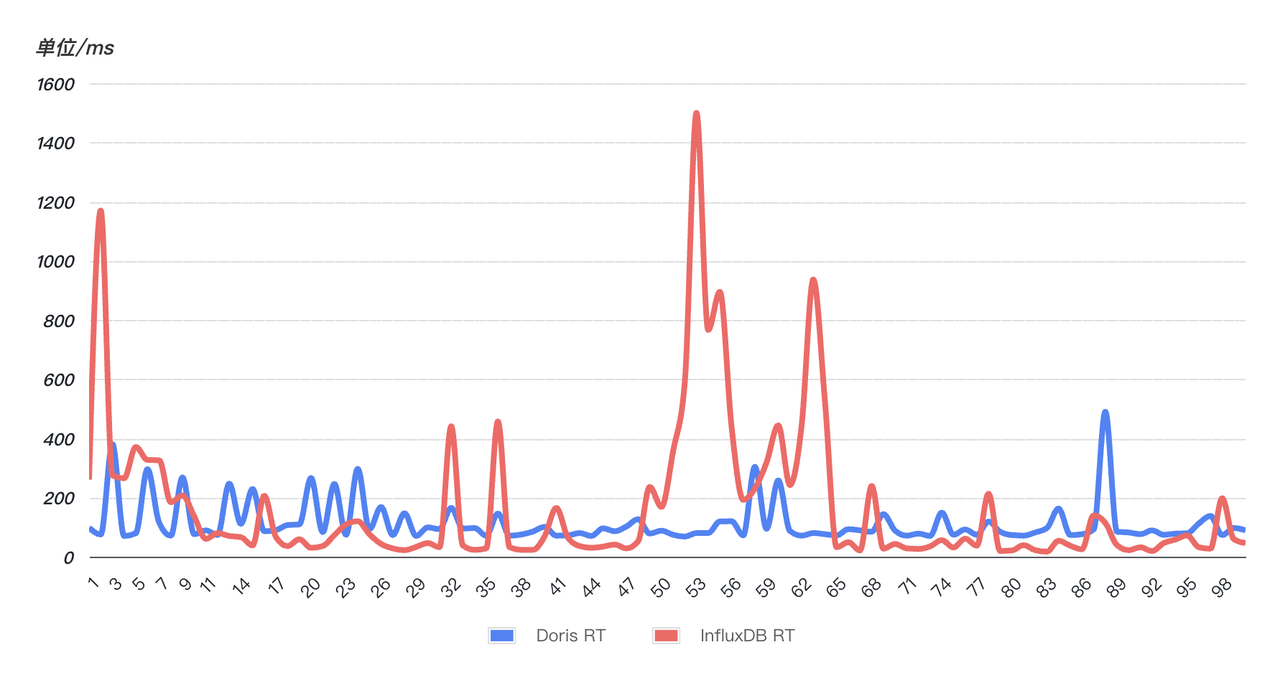
- La respuesta a la consulta es rápida y más estable: para verificar la velocidad de respuesta a la consulta, se seleccionó aleatoriamente un SQL en línea (que coincide con una cadena en los últimos 10 minutos) y se consultó el SQL 99 veces seguidas. Como se puede ver en la figura siguiente, el rendimiento de las consultas de Doris (azul) es más estable que el de InfluxDB (rojo). 99 consultas son relativamente estables y no tienen fluctuaciones obvias . Sin embargo, InfluxD ha experimentado múltiples fluctuaciones anormales. El tiempo de consulta se ha disparado y la estabilidad de la consulta se ha visto afectada.
Práctica y afinación
En el proceso de implementación comercial, NetEase también encontró algunos problemas y desafíos. Me gustaría aprovechar esta oportunidad para compilar y compartir estas valiosas experiencias de optimización, con la esperanza de brindar orientación y ayuda para el uso de todos.
01 Optimización de la creación de tablas.
El diseño del esquema de base de datos es fundamental para el rendimiento, y esto no es una excepción cuando se trata de datos de registros y series de tiempo. Apache Doris proporciona algunas opciones de optimización especializadas para estos dos escenarios, por lo que es fundamental habilitar estas opciones de optimización durante la creación de la tabla. Estas son las opciones de optimización específicas que utilizamos en la práctica:
- Cuando se utiliza un campo de hora de tipo DATETIME como clave principal, la velocidad de consulta de los n registros más recientes mejorará significativamente.
- Utilice la partición RANGE basada en campos de tiempo y habilite Partiiton dinámico para administrar particiones automáticamente a diario, mejorando la flexibilidad de la consulta y administración de datos.
- En cuanto a la estrategia de agrupación, puede usar RANDOM para la agrupación aleatoria, y la cantidad de depósitos se establece aproximadamente en 3 veces la cantidad total de discos del clúster.
- Para los campos que se consultan con frecuencia, se recomienda crear índices para mejorar la eficiencia de la consulta; y para los campos que requieren recuperación de texto completo, se debe especificar un analizador de parámetros de segmentación de palabras adecuado para garantizar la precisión y eficiencia de la recuperación.
- Para escenarios de registros y series de tiempo, se utiliza una estrategia de compactación de series de tiempo especialmente optimizada.
- El uso de la compresión ZSTD puede lograr mejores efectos de compresión y ahorrar espacio de almacenamiento.
CREATE TABLE log
(
ts DATETIME,
host VARCHAR(20),
msg TEXT,
status INT,
size INT,
INDEX idx_size (size) USING INVERTED,
INDEX idx_status (status) USING INVERTED,
INDEX idx_host (host) USING INVERTED,
INDEX idx_msg (msg) USING INVERTED PROPERTIES("parser" = "unicode")
)
ENGINE = OLAP
DUPLICATE KEY(ts)
PARTITION BY RANGE(ts) ()
DISTRIBUTED BY RANDOM BUCKETS 250
PROPERTIES (
"compression"="zstd",
"compaction_policy" = "time_series",
"dynamic_partition.enable" = "true",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "250"
);
02 Optimización de la configuración del clúster
configuración FE
# 开启单副本导入提升导入性能
enable_single_replica_load = true
# 更加均衡的tablet分配和balance测量
enable_round_robin_create_tablet = true
tablet_rebalancer_type = partition
# 频繁导入相关的内存优化
max_running_txn_num_per_db = 10000
streaming_label_keep_max_second = 300
label_clean_interval_second = 300
configuración ser
write_buffer_size=1073741824
max_tablet_version_num = 20000
max_cumu_compaction_threads = 10(cpu的一半)
enable_write_index_searcher_cache = false
disable_storage_page_cache = true
enable_single_replica_load = true
streaming_load_json_max_mb=250
03 Ajuste de importación de carga de flujo
Durante los períodos de mayor actividad comercial, la plataforma de datos Yunxin enfrenta más de 1 millón de TPS de escritura y un tráfico de escritura de 1 GB/s, lo que sin duda impone exigencias extremadamente altas al rendimiento del sistema. Sin embargo, dado que hay muchas tablas pequeñas concurrentes en el lado comercial y el lado de la consulta tiene requisitos de datos en tiempo real extremadamente altos, es imposible acumular el procesamiento por lotes en un lote lo suficientemente grande en poco tiempo. Después de realizar conjuntamente una serie de optimizaciones con partes comerciales, Stream Load aún no puede consumir datos rápidamente en Kafka, lo que resulta en una acumulación de datos cada vez más grave en Kafka.
Después de un análisis en profundidad, se descubrió que durante el período pico del negocio, el programa de importación de datos en el lado comercial había sufrido cuellos de botella en el rendimiento, que se reflejaban principalmente en la ocupación excesiva de recursos de CPU y memoria. Sin embargo, el rendimiento del lado de Doris aún no ha experimentado un cuello de botella significativo, pero el tiempo de respuesta de Stream Load tiene una clara tendencia ascendente.
Dado que el programa empresarial llama a Stream Load sincrónicamente, esto significa que la velocidad de respuesta de Stream Load afecta directamente la eficiencia general del procesamiento de datos. Por lo tanto, si el tiempo de respuesta de una única carga de flujo se puede reducir de manera efectiva, el rendimiento de todo el sistema mejorará significativamente.
Después de comunicarme con estudiantes de la comunidad Apache Doris, descubrí que Doris ha lanzado dos importantes optimizaciones del rendimiento de importación para escenarios de registro y sincronización:
- Importación de copia única: escriba primero en una copia y otras copias extraen datos de la primera copia. Este método puede evitar la sobrecarga causada por la clasificación repetida y la creación de índices de múltiples copias.
- Importación de una sola tableta: en comparación con el método de escritura de distribuir datos en varias tabletas en modo normal, se puede adoptar una estrategia de escribir solo en una sola tableta a la vez. Esta optimización reduce la cantidad de archivos pequeños y la sobrecarga de E/S generada durante la escritura, mejorando así la eficiencia general de la importación. Esta característica se puede habilitar configurando
load_to_single_tabletel parámetro durante la importación .true
Después de optimizar utilizando los métodos anteriores, el rendimiento de la importación ha mejorado significativamente:
- La velocidad de consumo de Kafka aumenta más de 2 veces
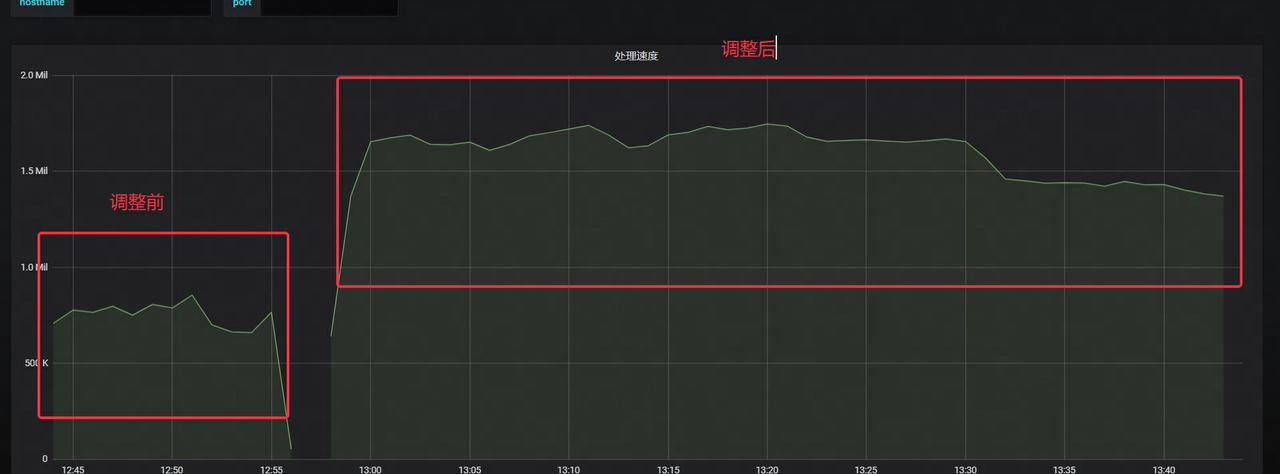
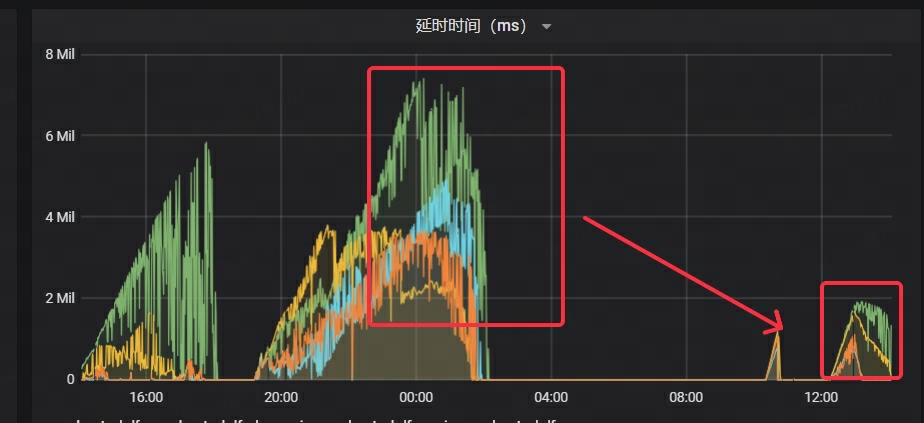
- La latencia de Kafka se ha reducido significativamente, a sólo 1/4 del tiempo original.
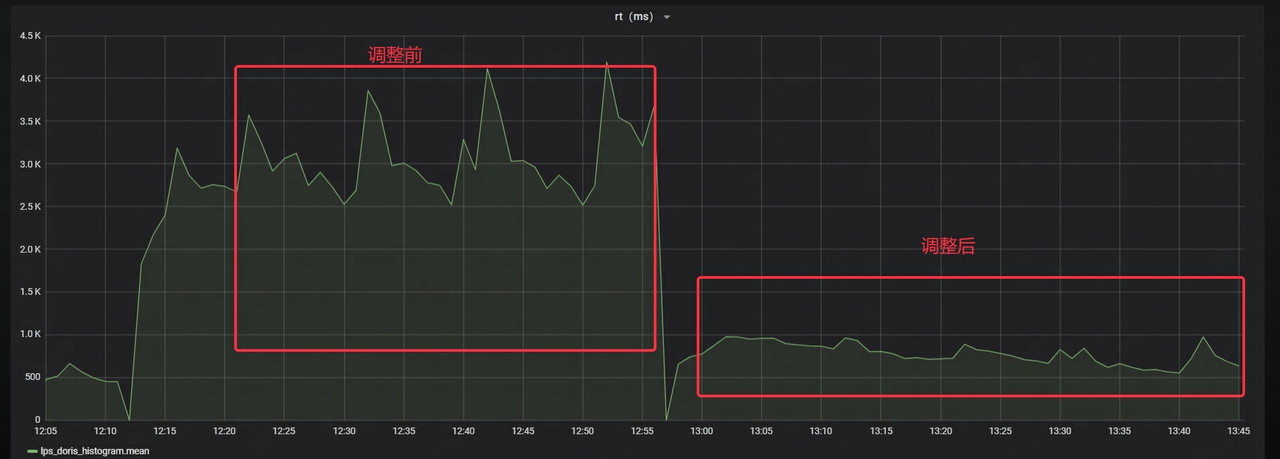
- El RT de Stream Load se reduce en aproximadamente un 70%
NetEase también llevó a cabo pruebas de estrés intensas y operaciones de prueba en escala de grises antes del lanzamiento oficial. Después de un trabajo de optimización continuo, finalmente aseguró que el sistema pueda funcionar de manera estable en línea en escenarios a gran escala, brindando un fuerte soporte para el negocio.
1. Tiempo de espera de carga de transmisión:
Al comienzo de la prueba de estrés, hubo un problema de tiempo de espera frecuente y informes de errores en la importación de datos, y cuando el proceso y el estado del clúster eran normales, el monitoreo no pudo recopilar los datos de métricas de BE normalmente.
Obtenga la pila de Doris BE a través de Pstack y use PT-PMT para analizar la pila. Se descubrió que la razón principal fue que cuando el cliente inició una solicitud, no se configuró ni la codificación HTTP Chunked ni la longitud del contenido, lo que provocó que Doris creyera erróneamente que la transmisión de datos aún no había finalizado y, por lo tanto, permaneció en espera. estado. Después de agregar la configuración de codificación fragmentada en el cliente, la importación de datos volvió a la normalidad.
2. La cantidad de datos importados de una sola vez por Stream Load supera el umbral:
El problema se resuelve aumentando streaming_load_json_max_mbel parámetro a 250M (100M por defecto).
3. Copias insuficientes y error de escritura: alive replica num 0 < quorum replica num 1
Se show backendsdescubre que un BE tiene un estado anormal y se muestra como SIN CONEXIÓN. Verifique el archivo de configuración correspondiente be_customy descubra que existe broken_storage_path. Una inspección más detallada del registro de BE reveló que el mensaje de error indicaba "demasiados archivos abiertos", lo que significa que la cantidad de identificadores de archivos abiertos por el proceso de BE excedió el máximo establecido por el sistema, lo que provocó que la operación de IO fallara.
Cuando el sistema Doris detecta esta anomalía, marca el disco como inutilizable. Dado que la tabla está configurada con una estrategia de copia única, cuando hay un problema con el disco donde se encuentra la única copia, no se pueden seguir escribiendo datos porque el número de copias es insuficiente.
Por lo tanto, el límite máximo de apertura del proceso FD se ajustó a 1 millón, be_custom.confse eliminó el archivo de configuración, se reinició el nodo BE y el servicio finalmente reanudó su funcionamiento normal.
4. Fluctuación de la memoria FE
Durante la prueba empresarial en escala de grises, ocurrió el problema de que no se podía conectar a FE. Al verificar los datos de monitoreo, se descubrió que la memoria JVM 32G se había agotado y el directorio de archivos bdb en el metadirectorio FE se había expandido anormalmente a 50G.
Dado que la empresa ha estado realizando operaciones de importación de datos de carga de flujo altamente concurrentes y FE registrará información de carga relevante durante el proceso de importación, la información de memoria generada por cada importación es de aproximadamente 200 K. El tiempo de limpieza de esta información de la memoria streaming_label_keep_max_secondestá controlado por parámetros. El valor predeterminado es 12 horas. Después de ajustarlo a 5 minutos, la memoria FE no se agotará. Sin embargo, después de funcionar durante un período de tiempo, se descubre que la memoria. Jitters según el ciclo de 1 hora y el uso máximo de memoria La tasa alcanza el 80%. Después de analizar el código, encontramos que el hilo que limpia las etiquetas label_clean_interval_secondse ejecuta cada dos veces. El valor predeterminado es 1 hora. Después de ajustarlo a 5 minutos, la memoria FE es muy estable.
04 Ajuste de consultas
Cuando la plataforma de monitoreo Lingxi-Eagle estaba realizando pruebas de consulta, se sospechó que leyó resultados que no cumplían con las condiciones coincidentes. Este fenómeno obviamente no cumplió con la lógica de recuperación esperada. Como se muestra en el primer registro a continuación:
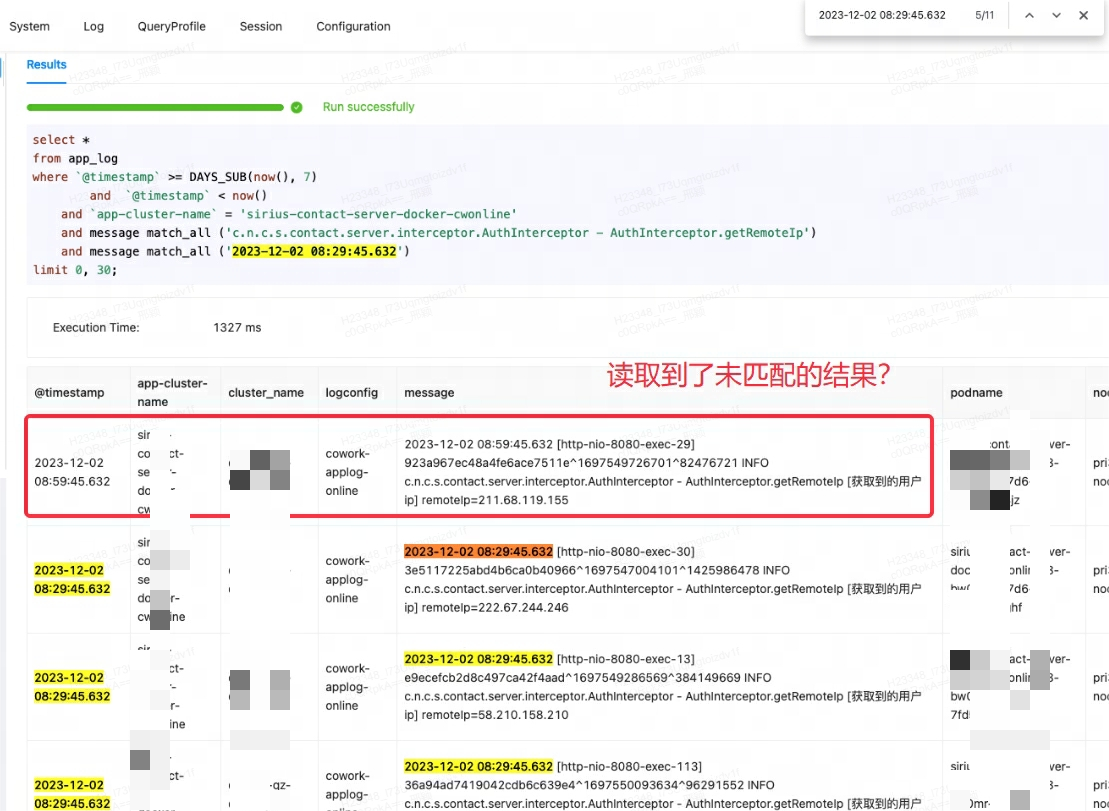
Al principio, pensé erróneamente que se trataba de un error de Doris, así que intenté buscar problemas similares y soluciones alternativas. Sin embargo, después de consultar a los miembros de la comunidad y revisar cuidadosamente los documentos oficiales, se descubrió que la raíz del problema era match_alluna mala comprensión del escenario de uso.
match_allEl principio de funcionamiento es que siempre que exista segmentación de palabras, la coincidencia se puede realizar y la segmentación de palabras se basa en espacios o puntuación . En este caso, match_allel '29' coincide con el '29' en el contenido posterior del primer registro, lo que genera resultados inesperados.
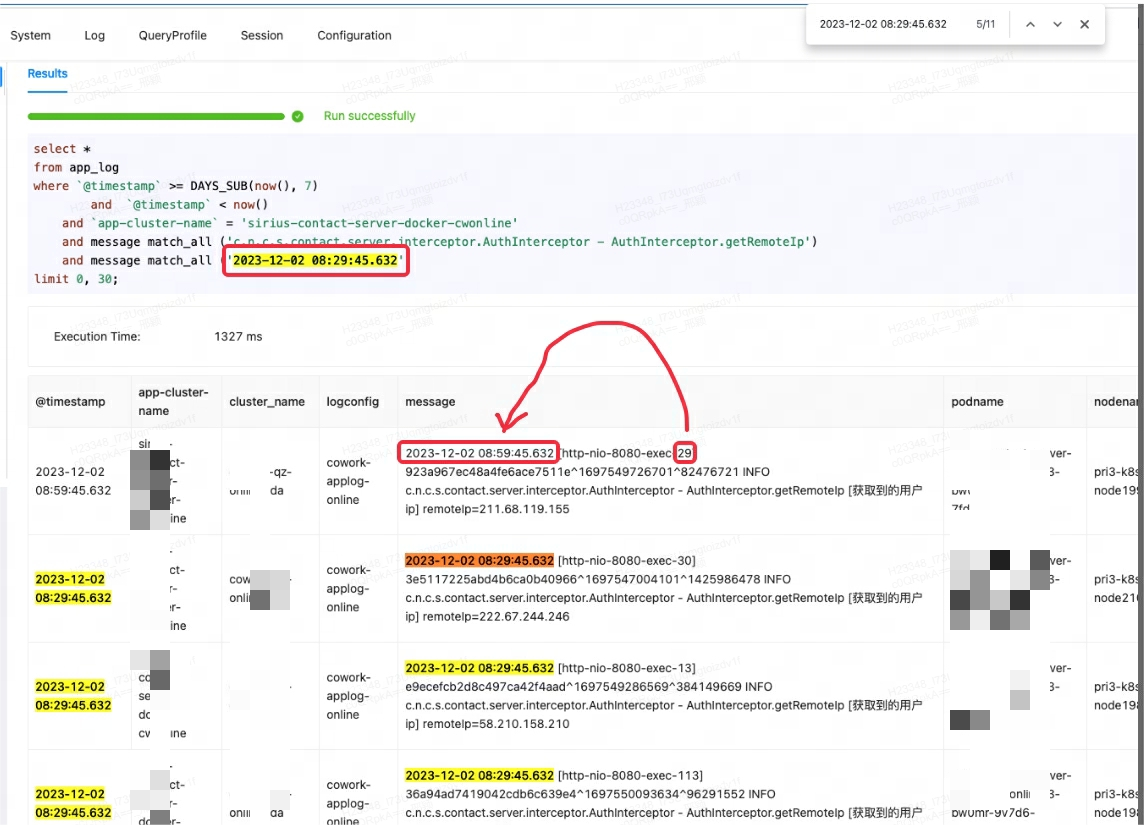
Para este caso, la forma correcta es utilizar MATCH_PHRASEpara hacer coincidir, MATCH_PHRASEque puede cumplir con los requisitos de pedido en el texto.
-- 1.4 logmsg中同时包含keyword1和keyword2的行,并且按照keyword1在前,keyword2在后的顺序
SELECT * FROM table_name WHERE logmsg MATCH_PHRASE 'keyword1 keyword2';
Cuando utilice MATCH_PHRASEla coincidencia, debe especificarla al crear el índice support_phrase; de lo contrario, el sistema realizará un escaneo completo de la tabla y realizará una coincidencia estricta, lo que dará como resultado una eficiencia de consulta deficiente.
INDEX idx_name4(column_name4) USING INVERTED PROPERTIES("parser" = "english|unicode|chinese", "support_phrase" = "true")
Para las tablas que ya tienen datos escritos, si desea habilitarlos support_phrase, puede DROP INDEXeliminar el índice anterior y luego ADD INDEXagregar un índice nuevo. Este proceso se realiza de forma incremental en la tabla existente sin reescribir los datos de toda la tabla, asegurando así la eficiencia de la operación.
En comparación con Elasticsearch, el método de gestión de índices de Doris es más flexible y puede agregar o eliminar índices rápidamente según las necesidades comerciales, lo que brinda mayor comodidad y flexibilidad.
Conclusión
La introducción de Apache Doris satisface efectivamente las necesidades de NetEase en cuanto a registros y escenarios de tiempo, y resuelve efectivamente los problemas de altos costos de almacenamiento y baja eficiencia de consultas de las primeras plataformas de análisis y procesamiento de registros de NetEase Lingxi Office y NetEase Cloud Letter.
En aplicaciones reales, Apache Doris ha transportado un tráfico de escritura en línea promedio de 500 MB/s y un valor máximo de más de 1 GB/s con menores recursos de servidor. Al mismo tiempo, la respuesta a las consultas también se ha mejorado significativamente en comparación con Elasticsearch, y la eficiencia de las consultas se ha incrementado al menos 11 veces. Además, Doris tiene una relación de compresión más alta y puede ahorrar un 70% de recursos de almacenamiento en comparación con antes.
Finalmente, un agradecimiento especial al equipo técnico de SelectDB por su continuo apoyo. En el futuro, NetEase continuará promoviendo Apache Doris y aplicándolo en profundidad en otros escenarios de big data de NetEase. Al mismo tiempo, también esperamos tener intercambios profundos con más equipos comerciales interesados en Doris para promover conjuntamente el desarrollo de Apache Doris.
Contribuciones de código abierto
Durante el proceso de implementación empresarial y resolución de problemas, los estudiantes de NetEase practicaron activamente el espíritu de código abierto y contribuyeron con una serie de relaciones públicas valiosas a la comunidad Apache Doris para promover el desarrollo y el progreso de la comunidad:
- Corrección de errores de carga de transmisión
- Optimización del código de carga de flujo
- Estratificación en frío y en caliente para encontrar la optimización adecuada del conjunto de filas
- La estratificación en frío y en caliente reduce el recorrido no válido
- Optimización del intervalo de bloqueo por niveles en frío y en caliente
- Optimización del filtrado de datos estratificados en frío y en caliente
- Optimización del juicio de capacidad de estratificación de frío y calor.
- Optimización de clasificación jerárquica en frío y en caliente
- Estandarización de informes de errores FE
- Nueva
array_aggfunción - Función de agregación Corrección de errores
- Corrección de errores del plan de ejecución
- Optimización de TaskGroupManager
- Reparación de accidentes BE
- Modificación del documento:
- https://github.com/apache/doris/pull/26958
- https://github.com/apache/doris/pull/26410
- https://github.com/apache/doris/pull/25082
- https://github.com/apache/doris/pull/25075
- https://github.com/apache/doris/pull/31882
- https://github.com/apache/doris/pull/30654
- https://github.com/apache/doris/pull/30304
- https://github.com/apache/doris/pull/29268