
Autor: Jin Xuefeng
fondo
La ejecución de modelos de lenguaje grandes en gráficos estáticos tiene muchos beneficios, entre ellos:
-
Mejora del rendimiento aportada por la optimización de la fusión del operador/ejecución del gráfico completo; si es Ascend, también puede usar la ejecución de hundimiento del gráfico completo para mejorar aún más el rendimiento, y la ejecución de hundimiento del gráfico completo no se ve afectada por la ejecución del procesamiento de datos en el lado del host. y el rendimiento es estable y bueno;
-
La orquestación de la memoria estática permite una alta utilización de la memoria, sin fragmentación, aumenta el tamaño del lote y, por lo tanto, mejora el rendimiento del entrenamiento;
-
Optimice automáticamente la secuencia de ejecución y logre una buena comunicación y simultaneidad de cálculo;
-
......
Sin embargo, también existen desafíos al ejecutar modelos de lenguaje grandes en imágenes estáticas. El más destacado es el rendimiento de la compilación.
El proceso de compilación del modelo de red neuronal en realidad convierte el código nn expresado en Python en un gráfico de cálculo de flujo de datos:
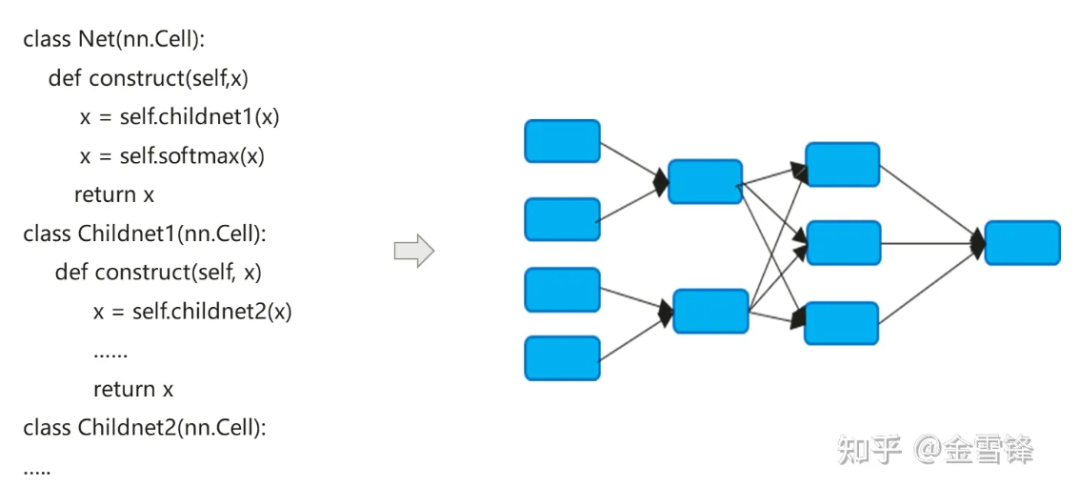
El proceso de compilación de modelos de redes neuronales es un poco diferente del de los compiladores tradicionales. El método en línea predeterminado se usa a menudo para expandir finalmente la expresión del código jerárquico en un gráfico de cálculo plano. Por un lado, busca maximizar las oportunidades de optimización de la compilación. por otro lado, también puede simplificar la lógica de ejecución y diferenciación automática.
De forma predeterminada, el gráfico de cálculo formado después de Inline incluye todos los nodos de cálculo y los nodos ya no tienen particiones de gráfico de subcálculo. Por lo tanto, la optimización en el proceso se puede realizar a mayor escala, como plegado constante, fusión de nodos y análisis paralelo. , etc., y puede realizar mejor la asignación de memoria y reducir la aplicación de memoria y la sobrecarga de rendimiento al llamar entre procedimientos. Incluso para las unidades informáticas que se llaman repetidamente, los compiladores en el campo de la IA siguen utilizando la misma estrategia en línea. Mientras pagan el precio de la expansión del tamaño del programa y el crecimiento del código ejecutable, pueden maximizar los métodos de optimización de la compilación para mejorar el rendimiento del tiempo de ejecución.
Como se puede ver en la descripción anterior, la optimización en línea es muy útil para mejorar el rendimiento en tiempo de ejecución, pero en consecuencia, una optimización en línea excesiva también genera una carga de tiempo de compilación; A medida que el gráfico de subcómputo se integra en el gráfico completo, desde una perspectiva global, la cantidad de nodos del gráfico de cálculo que el compilador tiene que procesar se está expandiendo rápidamente. Los compiladores generalmente utilizan el mecanismo Pass para organizar y organizar diferentes métodos de optimización conectados en serie en forma de Pass, y un proceso de procesamiento pasará por cada nodo del gráfico de cálculo. El número de pases de procesamiento depende del proceso de coincidencia y conversión del nodo y del Pase. A veces se necesitan varios pases para completar el procesamiento. En términos generales, si el número de pases es M y el número de nodos del gráfico calculado es N, el tiempo de todo el proceso de compilación y optimización está directamente relacionado con el valor de M * N. En la era de los modelos de lenguaje grandes, este problema se ha vuelto más prominente. Hay dos razones principales: primero, la estructura del modelo de los modelos de lenguaje grandes es profunda y tiene una gran cantidad de nodos, en segundo lugar, cuando se entrenan modelos de lenguaje grandes; Al habilitar el paralelismo de la tubería, la escala del modelo y los nodos se reducen. El número aumenta aún más. Si el tamaño del gráfico original es O, habilite el paralelismo de la tubería y el tamaño del gráfico de un solo nodo se convierte en (O/X)*Y. , donde X es el número de etapas en la tubería e Y es el número de microlotes. En realidad, durante el proceso de configuración, Y es mucho mayor que X. Por ejemplo, X es 16 y Y generalmente se establece en 64-192. De esta manera, una vez habilitada la paralelización de la canalización, la escala de compilación del gráfico aumentará aún más hasta 4-12 veces el tamaño original.

Tomando como ejemplo una determinada red 13B de decenas de miles de millones de modelos de lenguaje, el número de nodos informáticos en el gráfico de cálculo alcanza 135.000 y un tiempo de compilación único puede ser cercano a las 3 horas.
**1.** Ideas de optimización
Hemos observado que la estructura de la red neuronal del aprendizaje profundo se compone de múltiples capas. En el modelo de lenguaje de modelo grande, estas capas son pilas de bloques Transformer, especialmente cuando el paralelismo de canalización está activado, las capas de cada micro lote son exactamente las mismas. mismo. Por lo tanto, nos preguntamos si podemos conservar estas estructuras de capas sin Inline o Inline de antemano, de modo que el rendimiento de la compilación pueda mejorar exponencialmente. Por ejemplo, si seguimos el microlote como límite y conservamos la estructura de subgrafo del microlote. entonces, en teoría, el tiempo de compilación puede ser el doble del Y original (Y es el número de microlotes).
Específicamente para el código escrito en el modelo, podemos ver que la forma de reutilizar la misma capa es generalmente un bucle o una llamada iterativa. La capa generalmente corresponde a un elemento de la estructura secuencial en el proceso iterativo, a menudo un subgrafo; usando un bucle O iterar para llamar a la misma unidad informática varias veces, como se muestra en el código a continuación, el bloque corresponde a un subgrafo de capa o micro lote.
class Block(nn.Cell):
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block)
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
Por lo tanto, si consideramos el cuerpo del bucle como un subgrafo llamado con frecuencia y le decimos al compilador que posponga el procesamiento en línea marcándolo como Lazy Inline, entonces se pueden obtener ganancias de rendimiento en la mayoría de las etapas de la compilación. Por ejemplo, cuando la red neuronal llama cíclicamente a la misma estructura de subgrafo, no expandimos el subgrafo durante la fase de compilación; luego, al final de la compilación, se activa la optimización en línea para realizar la optimización y el procesamiento de pase de conversión necesarios; De esta manera, para el compilador, la mayoría de las veces es código de menor escala en lugar de código expandido en línea, lo que mejora en gran medida el rendimiento de la compilación.
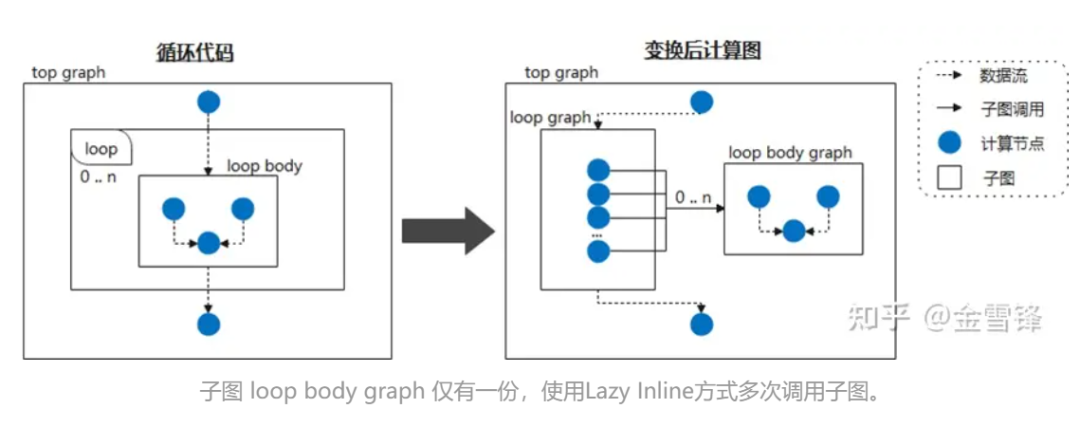
Durante la implementación específica, puede colocar una marca similar a @ lazy-inline en la clase de capa relevante para indicarle al compilador si la capa marcada se llama en el cuerpo del bucle o de otra manera, no se incluirá durante la expansión en línea. no se realiza hasta antes de la ejecución.
**2. ** Práctica de MindSpore
Parece que los principios e ideas de Lazy Inline no son complicados, pero el mecanismo de compilación de gráficos AI existente generalmente no es el tipo de compilador que admite funciones de compilación completas, por lo que sigue siendo un gran desafío implementar esta función.
Afortunadamente, el compilador de gráficos de MindSpore ha considerado la versatilidad al diseñar IR, incluidas llamadas a subfunciones, cierres y otras características.
① Las instancias de celda se compilan en gráficos de cálculo reutilizables
Cell es el componente básico de la red neuronal MindSpore y la clase base de todas las redes neuronales. Cell puede ser una única unidad de red neuronal, como conv2d, relu, batch_norm, etc., o puede ser una combinación de unidades que construyen una. red. En GRAPH_MODE (modo de gráfico estático), la celda se compilará en un gráfico de cálculo.
Cuando necesite personalizar la red, deberá heredar la clase Cell y anular los métodos __init__ y de construcción. La clase Cell anula el método __call__. Cuando se llama a una instancia de clase Cell, se ejecuta el método constructor. Definir la estructura de la red en el método de construcción.
En el siguiente ejemplo, se construye una red simple para implementar la función de cálculo de convolución. Los operadores de la red se definen en __init__ y se utilizan en el método de construcción. La estructura de red del caso es: Conv2d -> BiasAdd.
En el método de construcción, x son los datos de entrada y la salida es el resultado obtenido después de calcular la estructura de la red.
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Parameter
from mindspore.common.initializer import initializer
from mindspore._extends import lazy_inline
class MyNet(nn.Cell):
@lazy_inline
def __init__(self, in_channels=10, out_channels=20, kernel_size=3):
super(Net, self).__init__()
self.conv2d = ops.Conv2D(out_channels, kernel_size)
self.bias_add = ops.BiasAdd()
self.weight = Parameter(initializer('normal', [out_channels, in_channels, kernel_size, kernel_size]))
def construct(self, x):
output = self.conv2d(x, self.weight)
output = self.bias_add(output, self.bias)
return output
@Lazy_Inline es el decorador de Cell::__init__. Su función es generar todos los parámetros de __init__ en el valor del atributo cell_init_args de Cell, self.cell_init_args = type(self).__name__ + str(arguments). El atributo cell_init_args sirve como identificador único de la instancia de Cell en la compilación de MindSpore. El mismo valor de cell_init_args indica que el nombre de la clase de celda y los valores del parámetro de inicialización son los mismos.
construct(self, x) define la estructura de la red, que es la misma que la clase Cell. La estructura de la red depende de los parámetros de entrada self y x. Self contiene parámetros como pesos. Estos pesos se inicializan aleatoriamente o son los resultados del entrenamiento, por lo que estos pesos son diferentes para cada instancia de celda. Otros atributos propios están determinados por el parámetro __init__, y @lazy_inline calcula el parámetro __init__ para obtener la identificación de instancia de celda cell_init_args. Por lo tanto, el gráfico de cálculo de compilación de la instancia de Cell construct(self, x) se transforma en construct(x, self.cell_init_args, self.trainable_parameters()).
Si es la misma clase Cell y los parámetros cell_init_args son los mismos, llamamos a estas instancias de neuronas instancias de neuronas reutilizables, y el gráfico de cálculo correspondiente a esta instancia de neurona se denomina gráfico de cálculo reutilizable reuse_construct(X, self. trainable_parameters()). Se puede deducir que el gráfico de cálculo de cada instancia de Cell se puede convertir en:
def construct(self, x)
Reuse_construct(x, self.trainable_parameters())
Después de la introducción de gráficos informáticos reutilizables, las células neuronales (gráficos informáticos reutilizables) con los mismos cell_init_args solo necesitan componerse y compilarse una vez. Cuantas más células haya en la red, mejor será el rendimiento. Pero todo tiene dos lados, si el gráfico de cálculo de estas celdas es demasiado pequeño o demasiado grande, conducirá a una mala compilación y optimización de ciertas características, como la fusión de operadores, la multiplexación de memoria, el sumidero de gráficos completos y la llamada de múltiples gráficos, etc. .
Por lo tanto, la versión MindSpore actualmente solo admite la identificación manual de qué etapas de compilación de células generan gráficos de cálculo reutilizables. Las versiones posteriores planificarán estrategias automáticas para generar gráficos de cálculo reutilizables, como cuántos operadores contiene una celda, cuántas veces se usa una celda y otros factores para sopesar si se debe generar un gráfico de cálculo reutilizable y dar sugerencias de optimización.
A continuación se utiliza la estructura GPT para una explicación abstracta y simplificada:
class Block(nn.Cell):
@lazy_inline
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block(config, None))
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
GPT se compone de múltiples capas de Bloques. Los parámetros de inicialización de estos Bloques son todos la misma Configuración, por lo que las estructuras de estos Bloques son las mismas y el compilador las convertirá internamente en la siguiente estructura:
def Reuse_Block(x, attention_mask, layer_past,block_parameters) :
......
具体的Block 实例的计算图如下:
def construct(self, x, attention_mask, layer_past):
return Reuse_Block(x, attention_mask, layer_past,
self. trainable_parameters())
Con esta estructura, en la primera mitad del proceso de compilación, es un gráfico de cálculo independiente y no está integrado en el gráfico de cálculo general. Solo la pequeña cantidad final de optimización del paso se integra en el gráfico de cálculo grande.
② La combinación de L****azy Inline y diferenciación/paralelo/recálculo automático y otras características
Después de adoptar la solución de Lazy Inline, tendrá cierto impacto en el proceso original y requerirá adaptaciones relevantes, principalmente diferenciación automática, paralelismo y recálculo.
Para la diferenciación automática, aparece un nodo directo similar a la función de llamada y se debe proporcionar un procesamiento de diferenciación;
Para los procesos paralelos, lo principal es que el procesamiento de pases paralelos de Pipeline debe adaptarse a escenarios que no son de imagen completa, porque el corte de Pipeline anterior se basaba en la imagen completa, pero ahora debe cortarse en función del subgrafo compartido. El plan específico es primero colorear según la Etapa, dividir los nodos en la Celda compartida según la Etapa, retener solo los nodos correspondientes a la Etapa del proceso actual, insertar el operador Enviar/Recibir y luego dividir los nodos. fuera de la celda compartida, reteniendo los nodos correspondientes del proceso actual. El nodo de etapa también saca el operador de envío/recepción en la celda compartida de la celda compartida;
Para el proceso de recálculo, el antiguo proceso de recálculo procesa operadores en todo el gráfico después de Inline. Al buscar bloques de operadores continuos recalculados, los operadores que deben recalcularse y los parámetros de recálculo se determinan de acuerdo con la configuración de recálculo del usuario. operador del que depende la ejecución del operador calculado. Después de Lazy Inline, los operadores de recálculo consecutivos pueden estar en diferentes subgráficos y no se puede encontrar ninguna relación de conexión entre el nodo directo y el nodo inverso, por lo que falla la estrategia de búsqueda original basada en el operador del gráfico completo.
Nuestro plan de adaptación es procesar Células u operadores recalculados después de la diferenciación automática. El proceso de diferenciación automática generará un cierre para el subgrafo u operador único producido por Cell, que devuelve la salida directa y la función de propagación hacia atrás, y también obtenemos la relación entre cada cierre y la parte directa original. A través de esta información, según la configuración de recálculo del usuario, cada cierre se utiliza como unidad básica, la celda y el operador se procesan de manera uniforme, y la parte directa original se copia nuevamente al gráfico original y se puede pasar la relación de dependencia. La adquisición de la función de retropropagación en el cierre finalmente puede lograr un esquema de recálculo que no dependa de Inline de todo el gráfico.
③Procesamiento e impacto de backend
El IR generado después de activar Lazy Inline en el front-end se envía al back-end. El back-end necesita dividir el IR antes de que pueda ejecutarse en el dispositivo a través del sumidero de subgrafos. Sin embargo, después de Lazy Inline, todavía habrá algunos problemas en la ejecución del sumidero de subgrafos, como la imposibilidad de utilizar el método óptimo para la reutilización de memoria y la asignación de flujo, la imposibilidad de utilizar el caché interno del gráfico para acelerar la compilación durante la compilación. Y la incapacidad de realizar procesamiento de gráficos cruzados. Optimización (optimización de memoria, fusión de comunicación, fusión de operadores, etc.) y otros problemas.
Para lograr un rendimiento óptimo, el backend necesita procesar el IR de Lazy Inline en un formato adecuado para la ejecución de hundimiento del backend. Lo principal es convertir el operador parcial generado por la diferenciación automática en una llamada de subgrafo ordinaria y cambiar el. variables capturadas Páselo como parámetros ordinarios, de modo que se pueda hundir todo el gráfico y se pueda ejecutar toda la red.
En todo el proceso de hundimiento del gráfico, estas llamadas tienen dos métodos de procesamiento: en línea en el gráfico y en línea en la secuencia de ejecución. La inserción en línea en el gráfico hará que el gráfico se expanda y la velocidad de compilación posterior será más lenta; sin embargo, la secuencia de ejecución en línea hará que el ciclo de vida de la memoria de parte de la secuencia de ejecución en línea sea particularmente largo durante la reutilización de la memoria y en el proceso de ejecución. Al final la memoria no será suficiente.
Al final, el método de procesamiento que adoptamos fue reutilizar la secuencia de ejecución del proceso en línea en el paso de optimización, selección de operador, compilación de operador y otros procesos para hacer que el tamaño del gráfico sea lo más pequeño posible y evitar que demasiados nodos del gráfico afecten el back-end. elaboración del gráfico. Antes de ejecutar la optimización de secuencia, la asignación de flujo, la reutilización de la memoria y otros procesos, estas llamadas se realizan en nodos reales en línea para obtener el efecto óptimo de reutilización de la memoria. Además, mediante cierta optimización de la memoria y la comunicación, la eliminación de cálculos redundantes y otros métodos después de la integración del gráfico, es posible no lograr ninguna degradación de la memoria ni del rendimiento.
En la actualidad, no es posible lograr todas las optimizaciones a nivel de gráficos cruzados. La identificación de un solo punto solo se puede colocar en la etapa posterior a Inline, y es imposible ahorrar tiempo en la optimización del orden de ejecución, la asignación de flujo y la reutilización de memoria.
④Lograr efectos
La optimización del rendimiento de la compilación de modelos grandes utiliza la solución Lazy Inline para mejorar el rendimiento de la compilación de 3 a 8 veces. Tomando como ejemplo la red 13B del modelo grande de 10 mil millones, después de aplicar la solución Lazy Inline, la escala de compilación del gráfico de cálculo cayó de 130,000+. nodos a más de 20,000 nodos, el tiempo de compilación se ha reducido de 3 horas a 20 minutos y, combinado con el almacenamiento en caché de los resultados de la compilación, la eficiencia general ha mejorado enormemente.
⑤Restricciones de uso y próximos pasos
1. Cell El identificador de la instancia de Cell se genera en función del nombre de la clase Cell y el valor del parámetro __init__. Esto se basa en el supuesto de que los parámetros de init determinan todas las propiedades de Cell y que las propiedades de Cell al comienzo de la composición de la construcción son consistentes con las propiedades después de ejecutar init. Por lo tanto, las propiedades de Cell relacionadas con la composición no se pueden cambiar. después de ejecutar init.
2. Los parámetros de la función de construcción no pueden tener valores predeterminados. Si la versión existente de MindSpore tiene valores predeterminados para los parámetros de la función de construcción, cada vez que se use, se especializará en un nuevo gráfico de cálculo y las versiones posteriores optimizarán el mecanismo de especialización original.
3. Cell consta de varias instancias Cell_X compartidas y cada Cell_X consta de varias instancias Cell_Y compartidas. Si el inicio de Cell_X y Cell_Y están decorados como @lazy_inline, solo el Cell_X más externo se puede compilar en un gráfico de cálculo reutilizado, y el gráfico de cálculo del Cell_Y interno todavía está en línea. Las versiones posteriores planean admitir esta línea diferida de varios niveles; mecanismo.
Cómo ayudar a los clientes a escribir código con alta cohesión y bajo acoplamiento también es uno de los objetivos que persigue el marco MindSpore. Por ejemplo, en uso, existe este parámetro Block:: __init__ que incluye el índice de capa y los valores. de otros parámetros son los mismos Dado que el índice de capa cada capa es diferente, lo que hace que el bloque no se pueda reutilizar debido a diferencias sutiles. Por ejemplo, el siguiente código existe en una determinada versión de GTP:
class Block (nn.Cell):
"""
Self-Attention module for each layer
Args:
config(GPTConfig): the config of network
scale: scale factor for initialization
layer_idx: current layer index
"""
def __init__(self, config, scale=1.0, layer_idx=None):
......
if layer_idx is not None:
self.coeff = math.sqrt(layer_idx * math.sqrt(self.size_per_head))
self.coeff = Tensor(self.coeff)
......
def construct(self, x, attention_mask, layer_past=None):
......
Para que el bloque sea reutilizable, podemos optimizarlo, extraer los cálculos relacionados con el índice de capa y luego usarlos como parámetros de Construct para ingresarlos en la composición original, de modo que los parámetros iniciales del bloque sean los mismos.
Modifique el segmento de código anterior al siguiente segmento de código, elimine las partes relacionadas con Init y Layer Index y agregue el parámetro coeff para construir.
class Block (nn.Cell):
def __init__(self, config, scale=1.0):
......
def construct(self, x, attention_mask, layer_past, coeff):
......
En versiones posteriores de Shengsi MindSpore, planeamos identificar bloques sutilmente diferentes y brindar sugerencias de optimización para estos bloques para su optimización y mejora.
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Google confirmó despidos, relacionados con la "maldición de 35 años" de los codificadores chinos en los equipos Python Flutter Arc Browser para Windows 1.0 en 3 meses oficialmente GA La participación de mercado de Windows 10 alcanza el 70%, Windows 11 GitHub continúa disminuyendo. GitHub lanza la herramienta de desarrollo nativo de IA GitHub Copilot Workspace JAVA. es la única consulta de tipo fuerte que puede manejar OLTP + OLAP. Este es el mejor ORM. Nos encontramos demasiado tarde.