
Autor: Wu Jipeng, director de tecnología de big data del Wuxi Xishang Bank
Edición y acabado: equipo técnico de SelectDB
Introducción: para lograr la transformación del valor de los activos de datos y la gestión integral de riesgos digital e inteligente, la plataforma de big data de Wuxi Xishang Bank ha experimentado la evolución del almacén de datos fuera de línea de Hive al almacén de datos en tiempo real Apache Doris , y actualmente tiene acceso. a cientos de tablas en tiempo real, cientos de interfaces de servicios de datos y la interfaz QPS alcanza millones de niveles, resolviendo los problemas de puntualidad insuficiente, alto costo y baja eficiencia de los almacenes de datos fuera de línea, acelerando las consultas más de 10 veces. y brindar a los usuarios servicios de datos y experiencia de uso oportunos, efectivos y seguros.
Ante los cambios traídos a la industria financiera por tecnologías emergentes como big data, Internet de las cosas e inteligencia artificial, Wuxi Xishang Bank pone un énfasis importante en el desarrollo de capacidades tecnológicas y capacidades de big data. Para lograr la transformación del valor de los activos de datos y la gestión integral de riesgos digital e inteligente, Wuxi Xishang Bank estableció una plataforma de big data basada en el diseño tecnológico integrado de tres alas: "negocios en línea, control de riesgos basado en datos y basado en plataformas". arquitectura". Para gestionar la entrada masiva de registros de transacciones y datos de solicitudes de crédito todos los días, y con la ayuda de retratos de usuarios, informes en tiempo real, control de riesgos en tiempo real y otras aplicaciones, proporciona a los usuarios información más oportuna, efectiva y segura. Servicios de datos y experiencia de usuario.
La plataforma de big data de Wuxi Xishang Bank ha evolucionado desde un almacén de datos fuera de línea basado en Hive hasta un almacén de datos en tiempo real basado en Apache Doris . Mediante la actualización de la arquitectura, se resolvieron los problemas de puntualidad insuficiente, alto costo y baja eficiencia del almacén de datos fuera de línea, y la velocidad de consulta se incrementó 10 veces, lo que permitió a los bancos percibir el comportamiento del cliente más rápido y obtener información oportuna. en comportamientos de transacciones anormales, e identificar y prevenir riesgos potenciales. Este artículo presentará en detalle la evolución de la plataforma de big data de Wuxi Xishang Bank y la implementación de Apache Doris en consultas en tiempo real, servicios de marketing, servicios de control de riesgos y otros escenarios.
Almacén de datos fuera de línea de big data basado en Hive
01 Escenario de demanda
Wuxi Xishang Bank construyó un almacén de datos fuera de línea de big data en la etapa inicial, que sirve principalmente escenarios como informes de datos, control de riesgos de datos, operaciones de datos, consultas ad hoc y recuperación de datos diarios. Los escenarios de demanda incluyen, entre otros:
-
Informes de datos: riesgo del cliente, informes EAST, 1104, gran concentración, informes crediticios, informes de tipos de interés, lucha contra el blanqueo de capitales, informes de datos financieros básicos, etc.
-
Control de riesgos de datos: incluido el control de riesgos sobre indicadores de control de riesgos de préstamos, indicadores de comportamiento del usuario, antifraude, alerta temprana posterior al préstamo, gestión posterior al préstamo y otros controles de riesgo.
-
Operación de datos: proporcione datos por lotes periódicos para informes comerciales de BI, cabinas de gestión, canales externos y diversos sistemas dentro de la industria.
-
Consulta ad hoc y recuperación diaria de datos: realice análisis de datos, desarrollo de datos y extracción de datos según las necesidades del negocio.
02 Arquitectura y puntos débiles
En los primeros almacenes de datos fuera de línea, los datos provenían principalmente de Oracle, MySQL, MongoDB, Elasticsearch y archivos. Al utilizar herramientas como Sqoop, Spark, fuentes de datos externas y Shell, los datos se extraen sin conexión al almacén de datos fuera de línea de Hive y se procesan jerárquicamente a través de ODS, DWD, DWS y ADS en Hive. Los resultados finales brindan soporte. la capa de servicio de la aplicación.
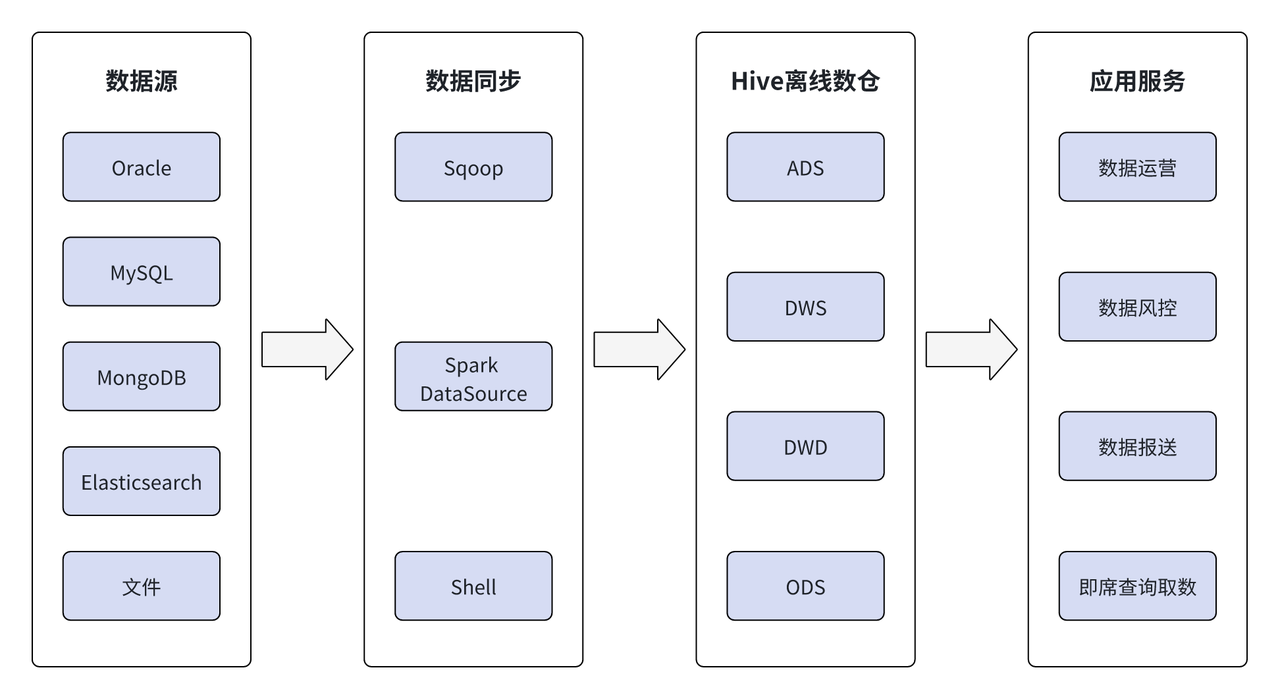
En los últimos años, con el desarrollo y expansión del negocio de Wuxi Xishang Bank, los departamentos comerciales relevantes tienen requisitos cada vez mayores para el procesamiento de datos. El almacén de datos fuera de línea ya no puede satisfacer las nuevas necesidades, lo que se refleja principalmente en:
-
Puntualidad de los datos insuficiente: el almacén de datos fuera de línea utiliza una solución de extracción fuera de línea y la puntualidad de los datos es T+1. Sin embargo, los informes, los paneles de datos, los indicadores de marketing y las variables de control de riesgos requieren actualizaciones de datos en tiempo real, que la arquitectura actual no puede cumplir. .
-
La eficiencia de la consulta de datos es baja: se requiere una respuesta de consulta en el segundo nivel y en el nivel de milisegundos. Los motores de ejecución del almacén de datos fuera de línea son principalmente Hive y Spark. Cuando se ejecuta Hive, descompondrá la consulta en múltiples tareas de MapReduce y necesita leer y escribir datos en HDFS. El tiempo de ejecución generalmente es de minutos, lo que afecta seriamente la consulta. eficiencia.
-
Altos costos de mantenimiento: la capa inferior del almacén de datos fuera de línea involucra muchas pilas de tecnología, incluidos LDAP, Ranger, ZooKeeper, HDFS, YARN, Hive, Spark y otros sistemas, lo que generará altos costos de mantenimiento del sistema. Aunque también hay almacenamiento y servicios en tiempo real de HBase + Phoenix en línea, todavía no puede resolver completamente el problema actual porque sus componentes son relativamente "pesados", la comunidad no está activa y algunas características no pueden satisfacer las necesidades del tiempo real. escenarios.
Selección de tecnología
Frente a los puntos débiles de la puntualidad insuficiente de los almacenes de datos fuera de línea, la baja eficiencia de las consultas y los altos costos de mantenimiento causados por múltiples pilas de tecnología, la construcción de almacenes de datos en tiempo real es imperativa. Después de realizar una investigación en profundidad sobre múltiples bases de datos MPP, Wuxi Xishang Bank decidió construir una plataforma de almacenamiento de datos en tiempo real con Apache Doris como núcleo. Esta selección de tecnología tiene como objetivo garantizar que la plataforma pueda cumplir con los altos requisitos del análisis empresarial en tiempo real en los niveles de escritura, consulta y servicio de datos. Las razones para elegir Apache Doris son las siguientes:
-
Actualización de datos eficiente: Apache Doris Unique Key admite actualizaciones de datos por lotes grandes, escritura en tiempo real de datos por lotes pequeños y modificaciones ligeras de la estructura de tablas. Especialmente al procesar una gran cantidad de datos y particiones, puede evitar eficazmente el problema de grandes cantidades de modificaciones y modificaciones inexactas, proporcionando así actualizaciones de datos más convenientes y en tiempo real.
-
Escritura en tiempo real de baja latencia: admite la escritura, actualización y eliminación de datos en tiempo real en el segundo nivel; admite la fusión en tiempo de escritura del modelo de tabla de clave primaria, lo que permite la escritura de microlotes en tiempo real de alta frecuencia; Modelo de clave principal Configuración de la columna de secuencia para garantizar la importación de datos. Orden en el proceso.
-
Excelente rendimiento de consultas: Apache Doris tiene poderosas capacidades de unión de múltiples tablas. Confiando en el motor de ejecución vectorizada, el optimizador de consultas CBO, la arquitectura MPP, las vistas materializadas inteligentes y otras funciones, puede lograr una respuesta de consulta a nivel de milisegundos para datos masivos, satisfaciendo datos instantáneos. consultas. Al mismo tiempo, Apache Doris versión 2.0 admite el almacenamiento mixto de filas y columnas y puede lograr decenas de miles de respuestas simultáneas a nivel de milisegundos en escenarios de consultas puntuales.
-
La plataforma es extremadamente fácil de usar: es compatible con el protocolo MySQL y proporciona interfaces API enriquecidas, lo que puede reducir la dificultad de usar aplicaciones de capa superior. Al mismo tiempo, Apache Doris tiene una arquitectura optimizada, con solo dos procesos, FE y BE. Simplifica la expansión y contracción de los nodos, y la administración de clústeres y la administración de copias de datos admiten la automatización. Tiene las características de implementación simple, bajo costo de uso y. Bajo costo de operación y mantenimiento.
Presentamos Apache Doris para construir un almacén de datos en tiempo real de big data
En abril de 2022, Wuxi Xishang Bank presentó Apache Doris para construir una plataforma de almacenamiento de datos en tiempo real. Teniendo en cuenta que la escala de datos bancarios es muy grande, es difícil sincronizar la cantidad total de datos históricos de la base de datos empresarial mientras se accede a datos en tiempo real. Por lo tanto, la construcción inicial de datos en tiempo real se basa principalmente en datos fuera de línea.
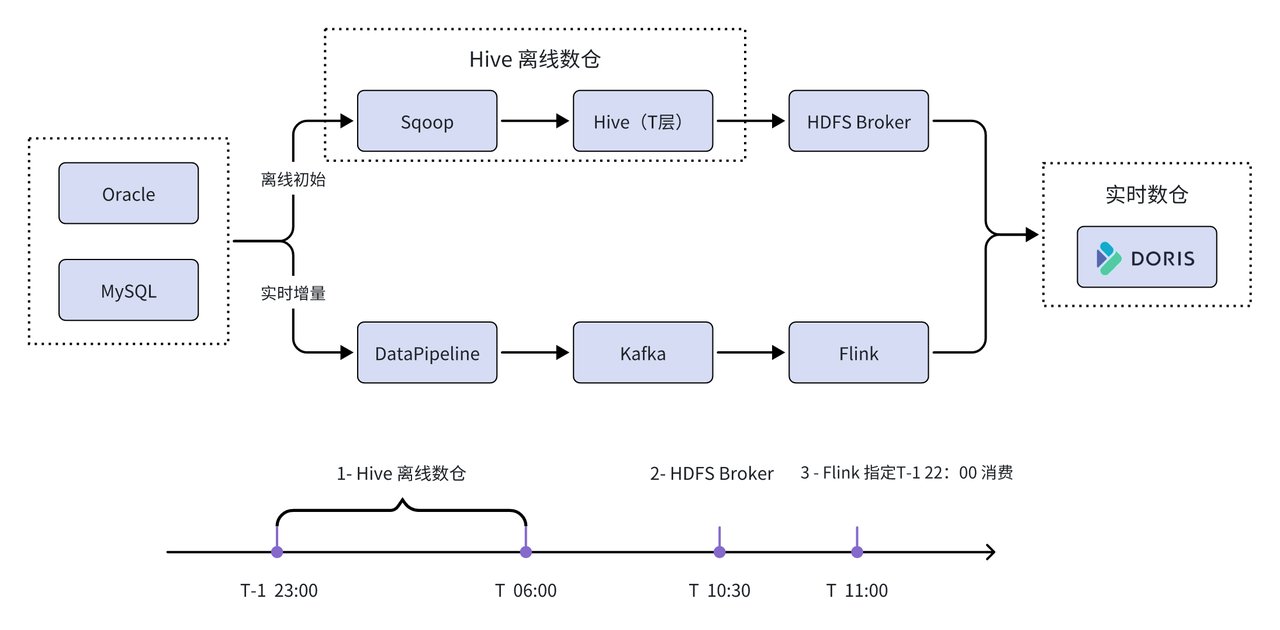
Primero, se utiliza el método HDFS Broker para inicializar de manera eficiente datos históricos en tiempo real; al mismo tiempo, se usa la herramienta de recopilación DataPipeline para recopilar los datos en el clúster de Kafka en tiempo real, y luego Flink escribe el modo codificado en escriba los datos en Apache Doris en tiempo real. Finalmente, con la ayuda de las capacidades de servicio de interfaz de la plataforma Feiliu, Apache Doris se utiliza como un motor de consulta y almacenamiento unificado para proporcionar servicios para cada línea de negocio.
La plataforma Feiliu es una plataforma integral unificada creada por Wuxi Xishang Bank para hacer frente a futuros escenarios comerciales en tiempo real. Incluye principalmente recopilación en tiempo real, herramientas de sincronización en tiempo real, almacenamiento de datos en tiempo real , cálculo en tiempo real y servicios de datos. .
01 Mejorar los enlaces de flujo de datos
Partiendo de las características de los datos bancarios y combinando las ventajas funcionales de Apache Doris, Wuxi Xishang Bank ha repensado y mejorado el enlace del flujo de datos:
-
La sincronización de datos históricos de almacenes de datos fuera de línea minimiza los riesgos: el artículo menciona que debido a la enorme escala de datos bancarios, si la cantidad total de datos históricos se sincroniza directamente desde Oracle y MySQL, una gran cantidad de datos fluirá a través de firewalls y conmutadores. provocando el bloqueo de otras solicitudes comerciales y problemas como el tiempo de espera del servicio. Para evitar estos riesgos y problemas potenciales, primero cree la estructura de la tabla Doris en lotes basados en Oracle y MySQL, y luego use HDFS Broker para sincronizar los datos T-1 completos desde la capa ODS de Hive del almacén de datos fuera de línea con Doris, minimizando así riesgos.
-
Extracción incremental en tiempo real, modo de extracción más seguro: la extracción en tiempo real producirá una cantidad muy pequeña de consumo de E/S de disco, memoria y CPU para evitar afectar la base de datos empresarial principal, de forma predeterminada, la base de datos esclava empresarial o la misma. Se seleccionará la recuperación de desastres de la ciudad en tiempo real. Para las necesidades comerciales con altos requisitos de puntualidad, se requiere una evaluación completa antes de que se puedan extraer los datos de la base de datos comercial principal.
-
Cree la capa Kafka para garantizar la coherencia de los datos: cree la capa Kafka como una capa de transmisión de datos intermedia para garantizar el orden y la coherencia de los datos. La Clave de los datos enviados por Datapipeline se configura como Database-Table-PK, y se envía a una partición (Partition) de Kafka Topic de manera ordenada según la misma dimensión. Dado que las respectivas particiones de Kafka Topic se almacenan en orden, los consumidores intermedios pueden procesar datos para evitar efectos desordenados en la precisión de los datos del almacén de datos en tiempo real. Además, la capa Kafka se puede utilizar como capa pública de datos y se puede utilizar en marketing, control de riesgos y otros escenarios comerciales.
-
Los datos se escriben en tiempo real para garantizar que no se pierdan ni se dupliquen: en escenarios de aplicaciones reales, el enlace fuera de línea realiza un procesamiento por lotes de datos fuera de línea desde las 11 p.m. hasta las 6 a.m. del día T-1 y utiliza el método HDFS Broker a las 10 en punto. reloj del día T. Inicialización de datos históricos de la tabla. El enlace en tiempo real utiliza Flink para señalar directamente el tema de Kafka consumido en T-1 a las 10 p.m. para la sincronización de datos en tiempo real. Sin embargo, aparecerán algunos datos superpuestos durante el proceso de consumo en tiempo real. Para abordar este problema, se selecciona el modelo de clave única de Apache Doris (este modelo admite idempotencia de datos), que puede cubrir rápidamente datos superpuestos, y se utiliza Flink-Doris-Connector para mejorar el enlace del almacén de datos en tiempo real para garantizar; sincronización consistente de datos en tiempo real. No es pesado desechar.
02 Servicios de datos flexibles
Para brindar respuestas a consultas precisas y eficientes, Wuxi Xishang Bank ha adoptado los siguientes tres métodos para implementar servicios de datos:
-
Consulta de datos sin conexión: para requisitos fuera de línea, los datos deben consultarse rápidamente. Wuxi Xishang Bank importa periódicamente datos del almacén de datos fuera de línea a la tabla Doris del almacén de datos en tiempo real. Esto permite realizar consultas rápidas en el almacén de datos en tiempo real para satisfacer las necesidades del análisis de datos y la toma de decisiones fuera de línea.
-
Requisitos simples en tiempo real: para requisitos sencillos en tiempo real, Wuxi Xishang Bank utiliza las capacidades de consulta eficientes de Apache Doris para brindar la capacidad de configurar directamente la interfaz del servicio de datos en la plataforma "Fei Liu". Los usuarios pueden usar SQL basado en. Capa ODS del almacén de datos en tiempo real Realizar configuración manual. De esta manera, se pueden satisfacer rápidamente las necesidades de consultas de datos simples en tiempo real.
-
Requisitos complejos en tiempo real: para requisitos complejos en tiempo real, Wuxi Xishang Bank utiliza el flujo de datos Kafka en tiempo real y la computación ligera Flink para escribir el flujo de datos en la tabla de capas DWD del almacén de datos en tiempo real, y en función de los detalles sobre en la plataforma "Fei Liu" El SQL de la tabla se agrega nuevamente y la interfaz del servicio de datos se configura manualmente para satisfacer las necesidades de consultas complejas de datos en tiempo real.
Frente a escenarios de servicios más diversos
01 Respuesta a la consulta del informe de BI en segundos
Basado en Apache Doris, Wuxi Xishang Bank satisface las necesidades de múltiples escenarios, como análisis de datos diarios, recuperación de datos diarios e informes de BI en tiempo real. El tiempo de respuesta de la consulta se reduce considerablemente y los resultados de la consulta se pueden devolver en 1 segundo . Reduce en gran medida el tiempo de espera de los analistas de datos. Costo y consumo de recursos del servidor.
Por ejemplo, en términos de informes de BI en tiempo real, Wuxi Xishang Bank ha establecido tablas de datos de préstamos en tiempo real, tablas de datos de depósitos en tiempo real, tablas de saldos de cuentas y otros informes. **Estos informes tienen un promedio de 253 líneas de código SQL y un tiempo de respuesta promedio de 1,5 segundos. **Además, al optimizar el rendimiento de las consultas y el diseño del modelo de datos, Wuxi Xishang Bank puede generar informes precisos en tiempo real en un corto período de tiempo para brindar soporte de datos oportuno para las decisiones comerciales.
02 Apoyar planes de marketing personalizados
En términos de servicios de datos de marketing, Wuxi Xishang Bank se basó en Apache Doris para enriquecer las etiquetas de los clientes y mejorar los retratos precisos de los clientes, y llevó a cabo diversas actividades de marketing, como actividades de aumento de activos netos y actividades de caja ciega de artistas. Mediante el análisis de datos en tiempo real, los bancos pueden observar el estado de conversión de los usuarios activos de manera oportuna y ajustar rápidamente la estrategia de selección de operaciones para lograr un marketing personalizado desde "mil personas tienen una cara" hasta "mil personas tienen una". rostro".
Por ejemplo, en actividades de marketing como actividades de aumento de activos netos y actividades de caja ciega de artistas, Wuxi Xishang Bank utiliza las capacidades del almacén de datos en tiempo real de Apache Doris para recopilar, analizar y retroalimentar continuamente datos de actividad. Al observar las conversiones de los usuarios en tiempo real, podemos ajustar rápidamente la estrategia de selección de operaciones para garantizar la coincidencia entre el personal y las actividades. Esta estrategia de marketing personalizada permite a los bancos satisfacer mejor las necesidades de los clientes y aumentar la participación, las tasas de respuesta y la fidelidad de los usuarios.
03 Identificación y control eficiente de riesgos
La introducción de Apache Doris permite a Wuxi Xishang Bank calcular más rápidamente las variables características de control de riesgos y los comportamientos anormales de las transacciones. Tomando como ejemplo el registro de nuevos usuarios, cuando los usuarios completan información, el sistema puede determinar rápidamente los resultados de la estrategia de aprobación en función de las variables características de control de riesgos en tiempo real, optimizar el modelo de estrategia de manera oportuna y garantizar la calidad y precisión. de aprobación.
Wuxi Xishang Bank también puede identificar y prevenir riesgos potenciales de manera oportuna. Por ejemplo, los bancos pueden recopilar y monitorear datos de transacciones, como una gran cantidad de transacciones y montos de transacciones anormales, en un corto período de tiempo en tiempo real para detectar comportamientos de transacciones anormales y fraude de manera oportuna. A través del análisis de datos en tiempo real, los bancos pueden identificar rápidamente riesgos potenciales y tomar medidas adecuadas para prevenirlos y responder.
Además, Wuxi Xishang Bank también utiliza el almacén de datos en tiempo real Apache Doris para realizar análisis en tiempo real del historial crediticio de los clientes y la información de las solicitudes de crédito. Al determinar rápidamente si el monto de la solicitud del cliente cumple con su capacidad de pago, los bancos pueden realizar evaluaciones de riesgo y tomar decisiones oportunas para controlar eficazmente los riesgos crediticios.
04 Los datos del diagrama de flujo de negociación de siete días se actualizan automáticamente.
En escenarios de aplicaciones reales, la cantidad de datos en el hoja de flujo de transacciones es muy grande e incluye el número de serie de la transacción, la fecha de la transacción, el tipo de transacción, el monto de la transacción y otros datos. Para garantizar la actualización oportuna de los datos, Wuxi Xishang Bank optó por utilizar la función de tabla de particiones dinámicas Apache Doris. Esta función puede crear particiones automáticamente y eliminar automáticamente datos de flujo de transacciones de más de siete días para lograr la actualización automática de los datos en la tabla de flujo de transacciones de siete días. Las operaciones específicas incluyen los siguientes pasos:
-
Construya una pseudocolumna con la fecha comercial como clave principal conjunta;
-
Cuando los datos de ID se
tran_dateactualizan a lo largo de los días, el código realiza una operación de retorno de tabla; -
Busque el valor de fecha correspondiente en la tabla de inserción y partición de los datos, empalme en Update Json y actualícelo en la base de datos.

Con la ayuda de la función de partición dinámica y partición de tablas de Apache Doris, no solo puede garantizar el funcionamiento estable de la clave principal subyacente y el servidor, sino que también actualiza y retiene automáticamente solo siete días de datos de transacciones para que los analistas los consulten y cumplan con los requisitos. Requisito de respuesta a consultas de 1,5 segundos por debajo de un millón de QPS .
05 Consulta de punto de alta concurrencia
Los primeros escenarios de aplicaciones de control de riesgos y marketing se basaban principalmente en dos conjuntos de clústeres HBase para admitir servicios de enumeración. Sin embargo, en las aplicaciones reales, se encontrarán problemas como salidas anormales del servidor maestro/regional y RIT. Para evitar este problema, puede aprovechar la alta capacidad de consulta simultánea de Apache Doris y habilitar la estrategia Merge-on-Write al crear la tabla de clave única, de modo que la consulta de clave principal se pueda completar a través de una ruta de ejecución de SQL simplificada, con solo se requiere un RPC. Respuesta de consulta rápida completa.
Finalmente, a través de pruebas de estrés en tres nodos, con cada nodo configurado con 8C y 10GB, se lograron los siguientes beneficios significativos:
-
En un escenario de consulta en el que una sola tabla contiene 50 millones de datos, el QPS llega a 25 000;
-
En un escenario de lectura y escritura de múltiples tablas que involucra 50 millones de datos, QPS también llega a 20,000;
-
La estabilidad de consultas SQL complejas también se mantiene en un alto nivel de QPS 25.000;
-
En el escenario de lectura y escritura en tiempo real de varias tablas, QPS también se puede estabilizar en 25.000.
Conclusión
En la actualidad, Apache Doris ha accedido a cientos de tablas en tiempo real, cientos de interfaces de servicios de datos y QPS de interfaz que llegan a millones en Wuxi Xishang Bank. Además, Apache Doris, como puerta de enlace de consultas unificada, mejora significativamente la eficiencia del análisis de datos históricos. En comparación con el tiempo de respuesta original a nivel de minutos, la velocidad de consulta es más de 10 veces.
En el futuro, Wuxi Xishang Bank continuará explorando las ventajas de Apache Doris y promoviendo su aplicación más profunda en escenarios en tiempo real.
-
En términos de rendimiento: optimice aún más las consultas de alta concurrencia, la partición y el agrupamiento automáticos, el motor de ejecución y otras capacidades para mejorar la eficiencia de la respuesta a las consultas de datos;
-
En términos de equilibrio de carga: construir clústeres duales para lograr el equilibrio de carga arquitectónico al mismo tiempo, mejorar la alerta temprana de la arquitectura y los mecanismos de disyuntor para garantizar operaciones comerciales ininterrumpidas;
-
En términos de estabilidad del clúster: realizar la "división del trabajo y colaboración" del clúster Apache Doris, de modo que cada uno de ellos pueda realizar tareas como cálculo y almacenamiento de almacenes de datos en tiempo real, consultas aceleradas de servicios de datos, etc. para mejorar aún más la estabilidad y confiabilidad del sistema.