
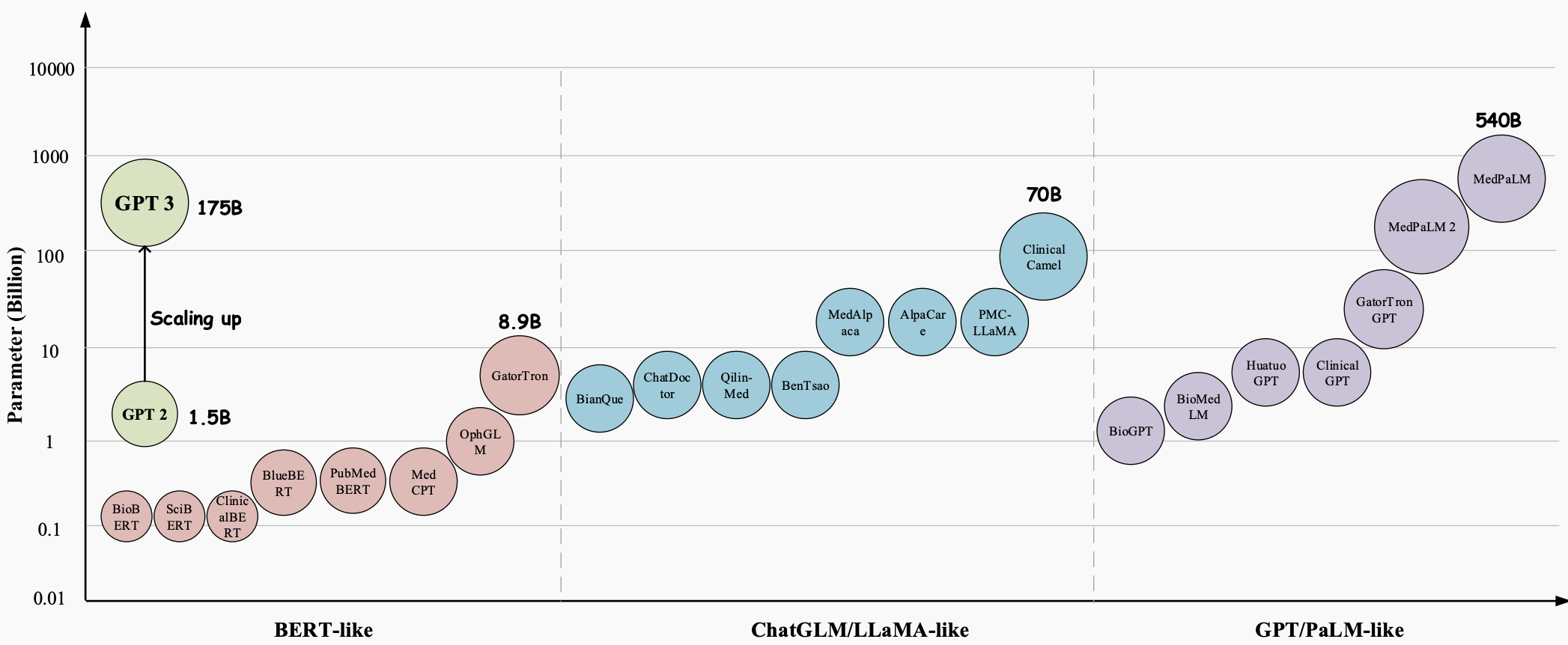
A lo largo de los años, los modelos de lenguaje grande (LLM) han evolucionado hasta convertirse en una tecnología innovadora con un enorme potencial para revolucionar todos los aspectos de la industria de la salud. Estos modelos, como GPT-3 , GPT-4 y Med-PaLM 2 , han demostrado capacidades superiores para comprender y generar texto similar a un humano, lo que los convierte en herramientas valiosas para manejar tareas médicas complejas y mejorar la atención al paciente. Son muy prometedores en una variedad de aplicaciones médicas, como respuesta a preguntas médicas (QA), sistemas de diálogo y generación de texto. Además, con el crecimiento exponencial de los registros médicos electrónicos (EHR), la literatura médica y los datos generados por los pacientes, los LLM pueden ayudar a los profesionales médicos a extraer información valiosa y tomar decisiones informadas.
Sin embargo, a pesar del enorme potencial de los grandes modelos de lenguaje (LLM) en el campo médico, todavía quedan algunos desafíos importantes y específicos que deben resolverse.
Cuando el modelo se utiliza en el contexto de conversaciones de entretenimiento, el impacto de los errores es mínimo; sin embargo, este no es el caso cuando se utiliza en el campo médico, donde las interpretaciones y respuestas incorrectas pueden tener graves consecuencias para la atención y los resultados del paciente. La precisión y confiabilidad de la información proporcionada por los modelos de lenguaje puede ser una cuestión de vida o muerte, ya que puede afectar las decisiones médicas, el diagnóstico y los planes de tratamiento.
Por ejemplo, cuando se preguntó a GPT-3 qué medicamentos podrían usar las mujeres embarazadas, GPT-3 recomendó incorrectamente la tetraciclina, aunque también afirmó correctamente que la tetraciclina es dañina para el feto y no debe ser utilizada por mujeres embarazadas. Si realmente sigue este consejo equivocado y le da medicamentos a mujeres embarazadas, puede provocar que los huesos del niño crezcan mal en el futuro.

Para hacer un buen uso de modelos de lenguaje tan grandes en el campo médico, estos modelos deben diseñarse y compararse de acuerdo con las características de la industria médica. Dado que los datos y aplicaciones médicos tienen sus propias características especiales, éstas deben tenerse en cuenta. Y en realidad es importante desarrollar métodos para evaluar estos modelos para uso médico, no sólo para la investigación, sino porque podrían plantear riesgos si se usan incorrectamente en el trabajo médico del mundo real.
El Open Source Medical Large Model Ranking tiene como objetivo abordar estos desafíos y limitaciones proporcionando una plataforma estandarizada para evaluar y comparar el rendimiento de varios modelos de lenguaje grandes en una variedad de tareas y conjuntos de datos médicos. Al proporcionar una evaluación integral del conocimiento médico y las capacidades de respuesta a preguntas de cada modelo, la clasificación promueve el desarrollo de modelos médicos más efectivos y confiables.
Esta plataforma permite a investigadores y profesionales identificar las fortalezas y debilidades de diferentes enfoques, impulsar un mayor desarrollo en el campo y, en última instancia, ayudar a mejorar los resultados de los pacientes.
Conjuntos de datos, tareas y configuraciones de evaluación
El Medical Large Model Ranking contiene una variedad de tareas y utiliza la precisión como su principal métrica de evaluación (la precisión mide el porcentaje de respuestas correctas proporcionadas por el modelo de lenguaje en varios conjuntos de datos de preguntas y respuestas médicas).
MedQA
El conjunto de datos MedQA contiene preguntas de opción múltiple del Examen de Licencia Médica de los Estados Unidos (USMLE). Cubre una amplia gama de conocimientos médicos e incluye 11,450 preguntas de conjunto de capacitación y 1,273 preguntas de conjunto de prueba. Con 4 o 5 opciones de respuesta por pregunta, este conjunto de datos está diseñado para evaluar el conocimiento médico y las habilidades de razonamiento necesarios para obtener una licencia médica en los Estados Unidos.

MedMCQA
MedMCQA es un conjunto de datos de preguntas y respuestas de opción múltiple a gran escala derivado del examen de ingreso médico de la India (AIIMS/NEET). Cubre 2400 temas de campo médico y 21 materias médicas, con más de 187 000 preguntas en el conjunto de capacitación y 6100 preguntas en el conjunto de prueba. Cada pregunta tiene 4 opciones de respuesta con explicaciones. MedMCQA evalúa el conocimiento médico general y la capacidad de razonamiento de un modelo.

PubMedQA
PubMedQA es un conjunto de datos de respuesta a preguntas de dominio cerrado donde cada pregunta se puede responder observando el contexto relevante (resumen de PubMub). Contiene 1000 pares de preguntas y respuestas etiquetados por expertos. Cada pregunta va acompañada de un resumen de PubMed para contextualizar, y la tarea es proporcionar una respuesta de sí/no/tal vez basada en la información resumida. El conjunto de datos se divide en 500 preguntas de formación y 500 preguntas de prueba. PubMedQA evalúa la capacidad de un modelo para comprender y razonar sobre la literatura científica biomédica.

Subconjunto MMLU (medicina y biología)
El punto de referencia MMLU (Medición de la comprensión del lenguaje multitarea a gran escala) contiene preguntas de opción múltiple de varios dominios. Para las clasificaciones de grandes modelos médicos de código abierto, nos centramos en el subconjunto más relevante para el conocimiento médico:
- Conocimiento clínico: 265 preguntas que evalúan el conocimiento clínico y las habilidades para la toma de decisiones.
- Genética Médica: 100 preguntas que cubren temas relacionados con la genética médica.
- Anatomía: 135 preguntas que evalúan el conocimiento de la anatomía humana.
- Medicina Profesional: 272 preguntas que evalúan los conocimientos requeridos a los profesionales médicos.
- Biología universitaria: 144 preguntas que cubren conceptos de biología a nivel universitario.
- Medicina universitaria: 173 preguntas que evalúan los conocimientos médicos de nivel universitario. Cada subconjunto de MMLU contiene preguntas de opción múltiple con 4 opciones de respuesta diseñadas para evaluar la comprensión del modelo de un dominio médico y biológico específico.

Las clasificaciones de modelos médicos grandes de código abierto proporcionan una evaluación sólida del rendimiento del modelo en diversos aspectos del conocimiento y razonamiento médicos.
Perspectivas y análisis
El Open Source Medical Large Model Ranking evalúa el rendimiento de varios modelos de lenguaje grandes (LLM) en una variedad de tareas de respuesta a preguntas médicas. Éstos son algunos de nuestros hallazgos clave:
- Los modelos comerciales como GPT-4-base y Med-PaLM-2 logran constantemente puntuaciones altas de precisión en varios conjuntos de datos médicos, lo que demuestra un sólido rendimiento en diferentes campos médicos.
- Los modelos de código abierto, como Starling-LM-7B , gemma-7b , Mistral-7B-v0.1 y Hermes-2-Pro-Mistral-7B , aunque el número de parámetros es solo de unos 7 mil millones, funcionan bien con ciertos datos. conjuntos y tareas entregaron un desempeño competitivo.
- Los modelos comerciales y de código abierto funcionan bien en tareas como la comprensión y el razonamiento sobre la literatura biomédica científica (PubMedQA) y la aplicación de conocimientos clínicos y habilidades de toma de decisiones (subconjunto de conocimientos clínicos de MMLU).

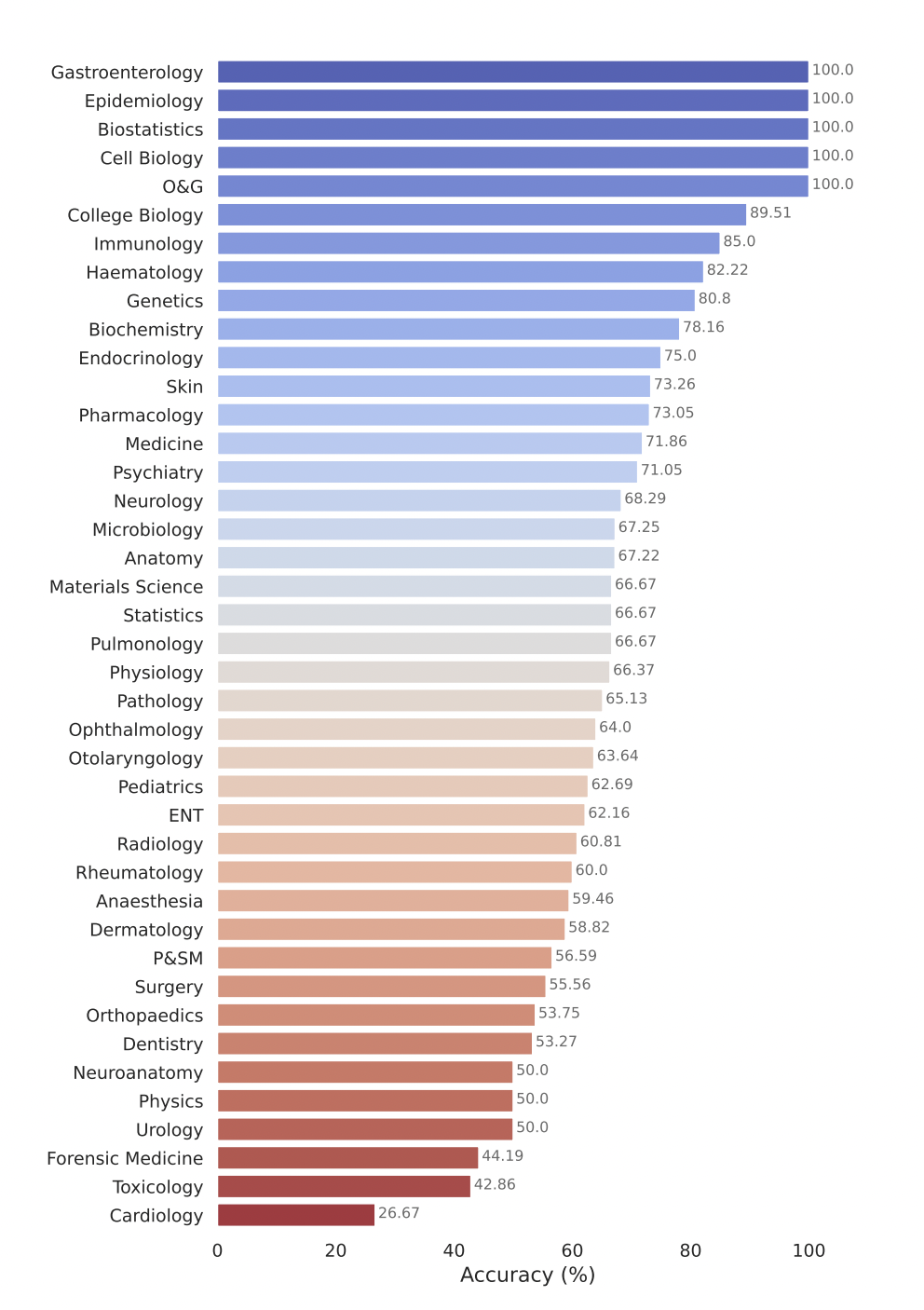
El modelo Gemini Pro de Google ha demostrado un sólido rendimiento en múltiples campos médicos, especialmente en tareas de procedimiento y con uso intensivo de datos, como bioestadística, biología celular y obstetricia y ginecología. Sin embargo, mostró un rendimiento de moderado a bajo en áreas clave como anatomía, cardiología y dermatología, lo que revela lagunas que requieren mayores mejoras para su aplicación en una medicina más integral.
Envíe su modelo para evaluación
Para enviar su modelo para su evaluación en el Open Source Healthcare Large Model Ranking, siga estos pasos:
1. Convierta los pesos del modelo al formato Safetensors
Primero, convierta los pesos de su modelo al formato de tensores de seguridad. Los Safetensores son un nuevo formato para almacenar pesas más seguro y rápido de cargar y utilizar. Convertir su modelo a este formato también permitirá que la tabla de clasificación muestre la cantidad de parámetros de su modelo en la tabla principal.
2. Garantizar la compatibilidad con AutoClasses
Antes de enviar el modelo, asegúrese de poder cargar el modelo y el tokenizador usando AutoClasses en la biblioteca de Transformers. Utilice el siguiente fragmento de código para probar la compatibilidad:
from transformers import AutoConfig, AutoModel, AutoTokenizer
config = AutoConfig.from_pretrained(MODEL_HUB_ID)
model = AutoModel.from_pretrained("your model name")
tokenizer = AutoTokenizer.from_pretrained("your model name")
Si falla en este paso, siga el mensaje de error para depurar su modelo antes de enviarlo. Lo más probable es que tu modelo se haya subido incorrectamente.
3.Haz público tu modelo
Asegúrese de que su modelo sea de acceso público. Las tablas de clasificación no pueden evaluar modelos privados o modelos que requieran acceso especial.
4. Ejecución remota de código (próximamente)
Actualmente, las clasificaciones de modelos médicos grandes de código abierto no admiten los use_remote_code=Truemodelos requeridos. Sin embargo, el equipo de clasificación está agregando activamente esta función, así que estad atentos a las actualizaciones.
5. Envíe su modelo a través del sitio web de clasificación.
Una vez que su modelo se haya convertido al formato de tensores de seguridad, sea compatible con AutoClasses y sea de acceso público, podrá evaluarlo utilizando el panel Enviar aquí en el sitio web Open Source Medical Large Model Ranking. Complete la información requerida, como el nombre del modelo, la descripción y cualquier detalle adicional, y haga clic en el botón Enviar. El equipo de clasificación procesará su envío y evaluará el rendimiento de su modelo en varios conjuntos de datos de preguntas y respuestas médicas. Una vez que se complete la evaluación, la puntuación de su modelo se agregará a la tabla de clasificación y podrá comparar su rendimiento con otros modelos.
¿Que sigue? Clasificación ampliada de modelos médicos grandes de código abierto
El Open Source Healthcare Large Model Ranking se compromete a expandirse y adaptarse para satisfacer las necesidades cambiantes de la comunidad de investigación y la industria de la salud. Las áreas clave incluyen:
- Incorpore conjuntos de datos sanitarios más amplios que cubran todos los aspectos de la atención, como radiología, patología y genómica, mediante la colaboración con investigadores, organizaciones sanitarias y socios de la industria.
- Mejore las métricas de evaluación y las capacidades de generación de informes explorando medidas de rendimiento adicionales más allá de la precisión, como puntuaciones punto a punto y métricas específicas de dominio que capturan las necesidades únicas de las aplicaciones médicas.
- Ya hay algunos trabajos en marcha en esta dirección. Si está interesado en colaborar en el próximo punto de referencia que planeamos proponer, únase a nuestra comunidad de Discord para obtener más información e involucrarse. ¡Nos encantaría colaborar y generar ideas!
Si le apasiona la intersección de la IA y la atención médica, la construcción de modelos para la atención médica y le preocupan los problemas de seguridad y alucinaciones de los grandes modelos médicos, lo invitamos a unirse a nuestra comunidad activa en Discord .
Expresiones de gratitud

Un agradecimiento especial a todos los que ayudaron a hacer esto posible, incluidos Clémentine Fourrier y el equipo de Hugging Face. Me gustaría agradecer a Andreas Motzfeldt, Aryo Gema y Logesh Kumar Umapathi por las discusiones y comentarios durante el desarrollo de la tabla de clasificación. Nos gustaría expresar nuestro más sincero agradecimiento al profesor Pasquale Minervini de la Universidad de Edimburgo por su tiempo, asistencia técnica y soporte de GPU.
Acerca de la IA de ciencias biológicas abiertas
Open Life Sciences AI es un proyecto que tiene como objetivo revolucionar la aplicación de la inteligencia artificial en los campos de las ciencias de la vida y la medicina. Sirve como un centro central que enumera modelos médicos, conjuntos de datos, puntos de referencia y realiza un seguimiento de los plazos de las conferencias, promoviendo la colaboración, la innovación y el avance en el campo de la atención médica asistida por IA. Nos esforzamos por establecer Open Life Sciences AI como el destino principal para cualquier persona interesada en la intersección de la IA y la atención médica. Proporcionamos una plataforma para que investigadores, médicos, formuladores de políticas y expertos de la industria entablen un diálogo, compartan ideas y exploren los últimos avances en el campo.

Cita
Si encuentra útil nuestra evaluación, considere citar nuestro trabajo.
Ranking de modelos médicos grandes
@misc{Medical-LLM Leaderboard,
author = {Ankit Pal, Pasquale Minervini, Andreas Geert Motzfeldt, Aryo Pradipta Gema and Beatrice Alex},
title = {openlifescienceai/open_medical_llm_leaderboard},
year = {2024},
publisher = {Hugging Face},
howpublished = "\url{https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard}"
}
> Texto original en inglés: https://hf.co/blog/leaderboard-medicalllm > Autor original: Aaditya Ura (en busca de doctorado), Pasquale Minervini, Clémentine Fourrier > Traductor: innovación64
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Los estudiantes de secundaria crean su propio lenguaje de programación de código abierto como una ceremonia de mayoría de edad: comentarios agudos de los internautas: debido al fraude desenfrenado, confiando en RustDesk, el servicio doméstico Taobao (taobao.com) suspendió los servicios domésticos y reinició el trabajo de optimización de la versión web Java 17 es la versión Java LTS más utilizada. Cuota de mercado de Windows 10. Alcanzando el 70%, Windows 11 continúa disminuyendo. Open Source Daily | Google apoya a Hongmeng para hacerse cargo de los teléfonos Android de código abierto respaldados por Docker; Electric cierra la plataforma abierta Apple lanza el chip M4 Google elimina el kernel universal de Android (ACK) Soporte para la arquitectura RISC-V Yunfeng renunció a Alibaba y planea producir juegos independientes en la plataforma Windows en el futuro