


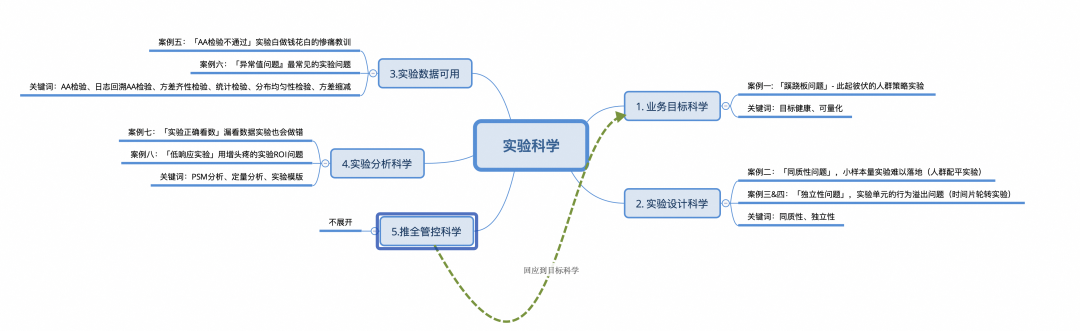

Ciencia de los objetivos empresariales: los objetivos de crecimiento deben ser a largo plazo, saludables y cuantificables.
▐Caso 1: "Problema Skysaw": experimentos operativos sucesivos

analisis de CASO
De la conclusión experimental se puede ver que el experimento aumentó significativamente el GMV per cápita , al tiempo que redujo significativamente la experiencia del usuario . Indicadores de cobertura que no son infrecuentes en el negocio, como aumentar el número de transacciones per cápita sin reducir el precio unitario; y aumentar el tiempo de visualización per cápita, aunque no se reduce el monto de las transacciones per cápita, etc., si a diferentes equipos pequeños se les asignan indicadores de cobertura (problemas comunes en la estructura organizacional), el equipo grande debe establecer objetivos de manera razonable y prestar especial atención. a los indicadores de cobertura.
Solución actual
-
Un equipo grande mantiene indicadores básicos e indicadores de valla, que generalmente requieren la determinación de los líderes empresariales, financieros y de BI.
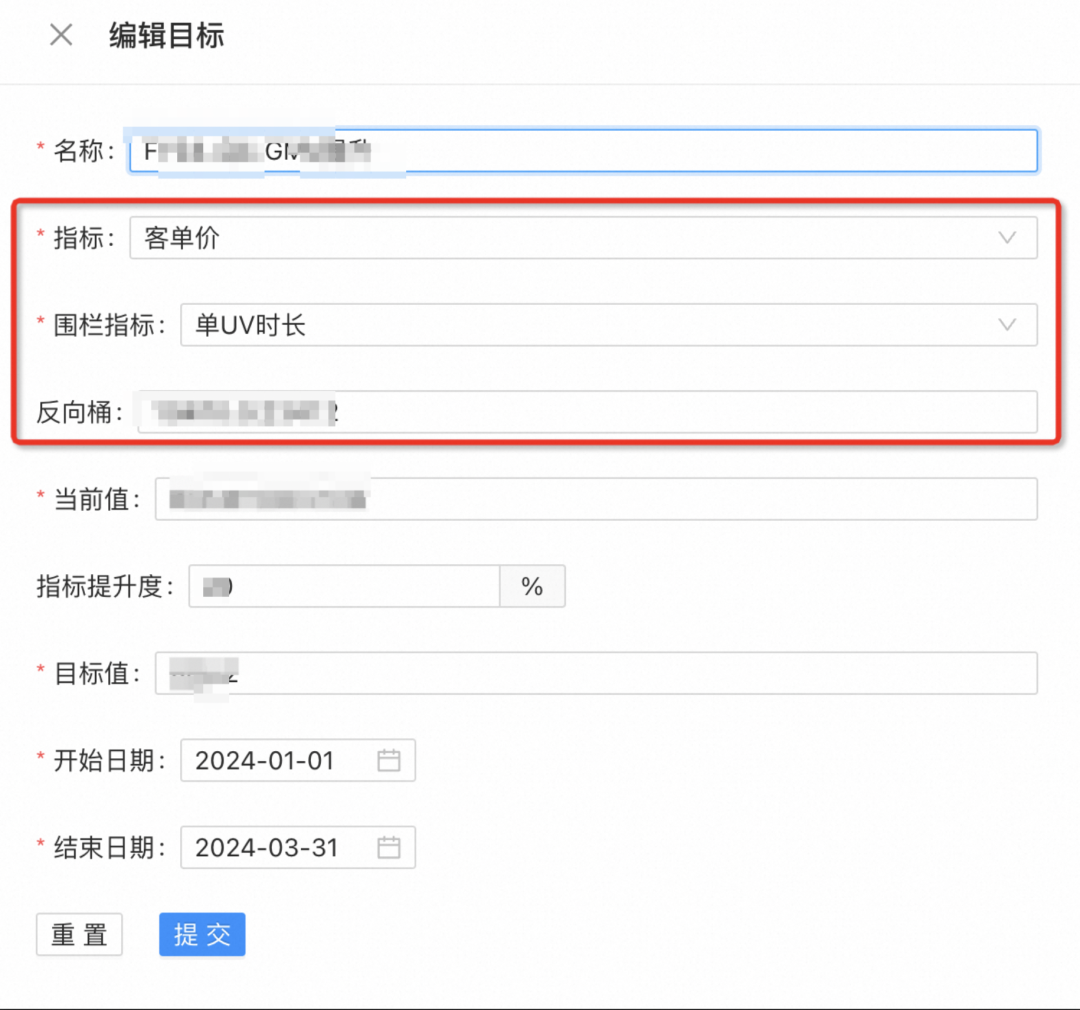
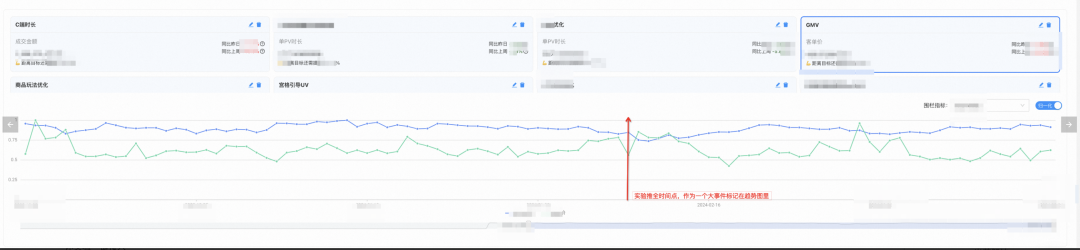
Normalice la tendencia de renderizar indicadores centrales y indicadores de valla, y observe los cambios intuitivos causados por el impulso experimental de todos los nodos;
-
Combinado con el depósito inverso a largo plazo, se verifica el valor incremental del experimento. (no se muestra en la imagen)
Pensamiento: ¿Cómo deberían determinarse los indicadores OKR empresariales desde la perspectiva de la gestión experimental?
-
OKR se establece como un indicador que puede probarse experimentalmente (como el GMV per cápita), y este indicador se utiliza para evaluar cuantitativamente el valor de los experimentos; -
Estricto proceso de gestión y control de la cubeta inversa, y estimación de la contribución de GMV a través de la cubeta inversa;

▐Caso 2: "Problema de homogeneidad", es difícil realizar un experimento con un tamaño de muestra pequeño: nuevo experimento ancla
analisis de CASO
Hipótesis empresarial: normalmente hacemos muchos experimentos estratégicos para mejorar la experiencia de los nuevos presentadores en Taobao. Tomando una determinada estrategia como ejemplo, asumimos que esta estrategia puede mejorar efectivamente el entusiasmo de los nuevos presentadores.
Situación real: la cantidad de muestras de nuevos anclajes que se pueden probar después de la selección empresarial es pequeña y las diferencias individuales entre los anclajes son enormes. Por lo tanto, los indicadores entre los dos grupos de muestras seleccionados al azar fluctúan mucho, lo que hace imposible realizar experimentos. .
Ideas de soluciones actuales
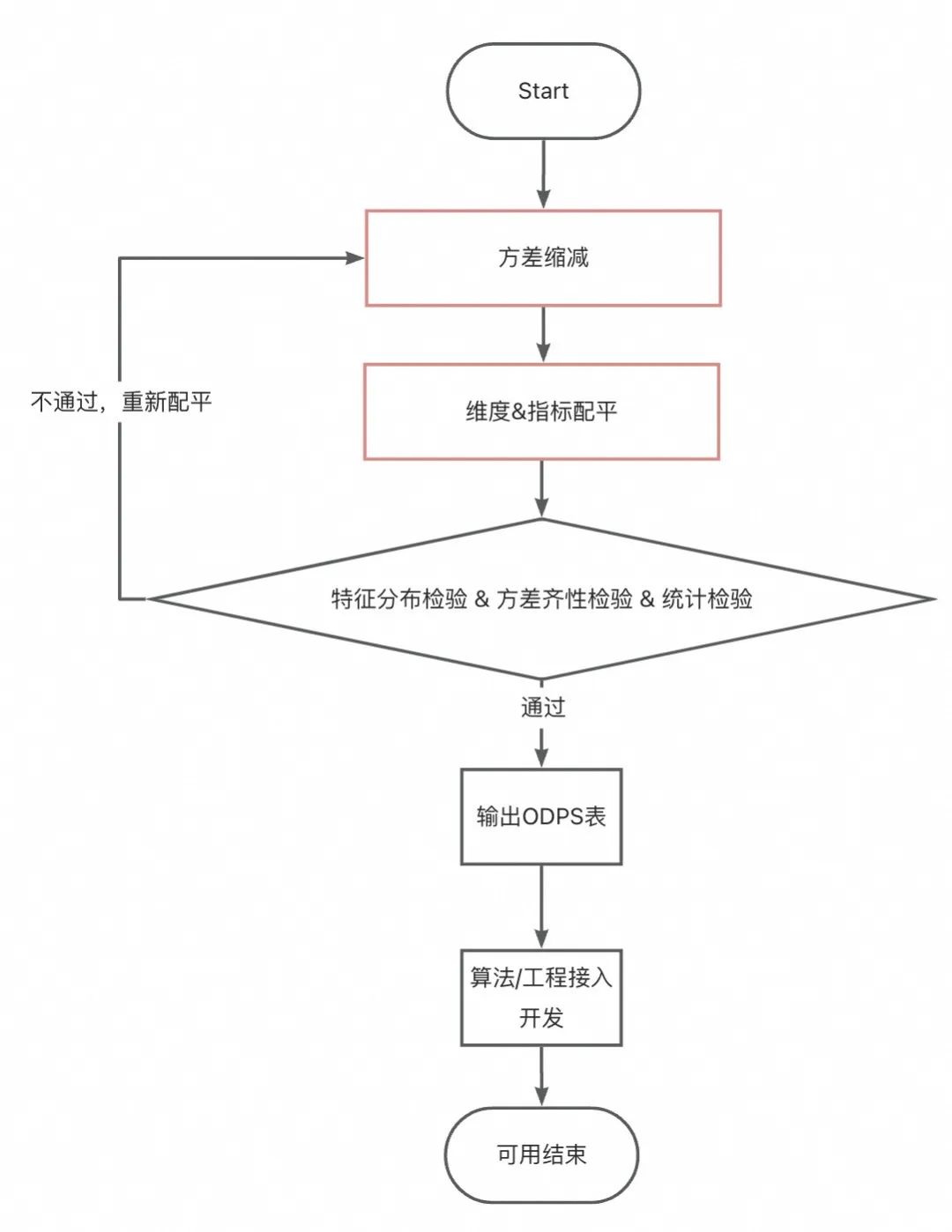
-
Reducción de la varianza: alrededor de los indicadores que se verificarán en el experimento, elimine una cantidad adecuada de valores atípicos (nota: eliminar demasiado conducirá a un efecto experimental menor, y eliminar muy poco provocará fluctuaciones excesivas. Empíricamente, al menos manténgalo en el percentil 99). Si la variación aún es demasiado alta, es grande y se puede procesar adecuadamente en un indicador a largo plazo . En este caso, la diferencia en el monto de la transacción de un solo día del ancla es demasiado grande, por lo que tomamos los tres. -Monto promedio de transacción por día. Sin embargo, esto hará que el ciclo de recuperación de datos experimentales se alargue y la interpretabilidad experimental pueda empeorar . Por lo tanto, es necesario aclarar el propósito del experimento antes del procesamiento de calibre. -
Equilibrio de indicadores y dimensiones : mediante el procesamiento fuera de línea, se obtienen múltiples grupos de muestras con igual distribución de datos de indicadores y distribución de dimensiones iguales.
-
Si el tamaño de la muestra no es muy pequeño y las diferencias dentro de los grupos no son demasiado obvias , puede intentar un equilibrio de grupos simple , es decir, la misma proporción de anclas de cada grupo participará en el experimento. -
Si el tamaño de la muestra es demasiado pequeño o las diferencias dentro del grupo son grandes , el modelo se puede utilizar para equilibrar indicadores y dimensiones. En este caso, se utiliza el método de aleatorización adaptativa de covariables , que puede pasar de manera estable la prueba AA.
-
Prueba AA: asegúrese de que los resultados de la agrupación sean homogéneos y que las conclusiones experimentales sean utilizables. Esta sección se analizará en detalle a continuación.
pensar
Los experimentos con muestras pequeñas a menudo se ignoran fácilmente debido a su pequeño impacto en el mercado más amplio y a la dificultad de implementación. Sin embargo, en operaciones refinadas, dichos experimentos han comenzado gradualmente a tomarse en serio. También debemos prestar atención a lo "pequeño" del tamaño de muestra pequeño. En un caso real de reducción del precio de un producto, se muestrearon aleatoriamente 500 productos 1.000 veces y se descubrió que el conjunto medio no se ajustaba a la distribución normal. Ajustándose al muestreo aleatorio de 10.000 productos, la media comienza a mostrar una distribución normal obvia, por lo que el número de muestras que se pueden muestrear en el experimento en este contexto no debe ser inferior a 10.000.
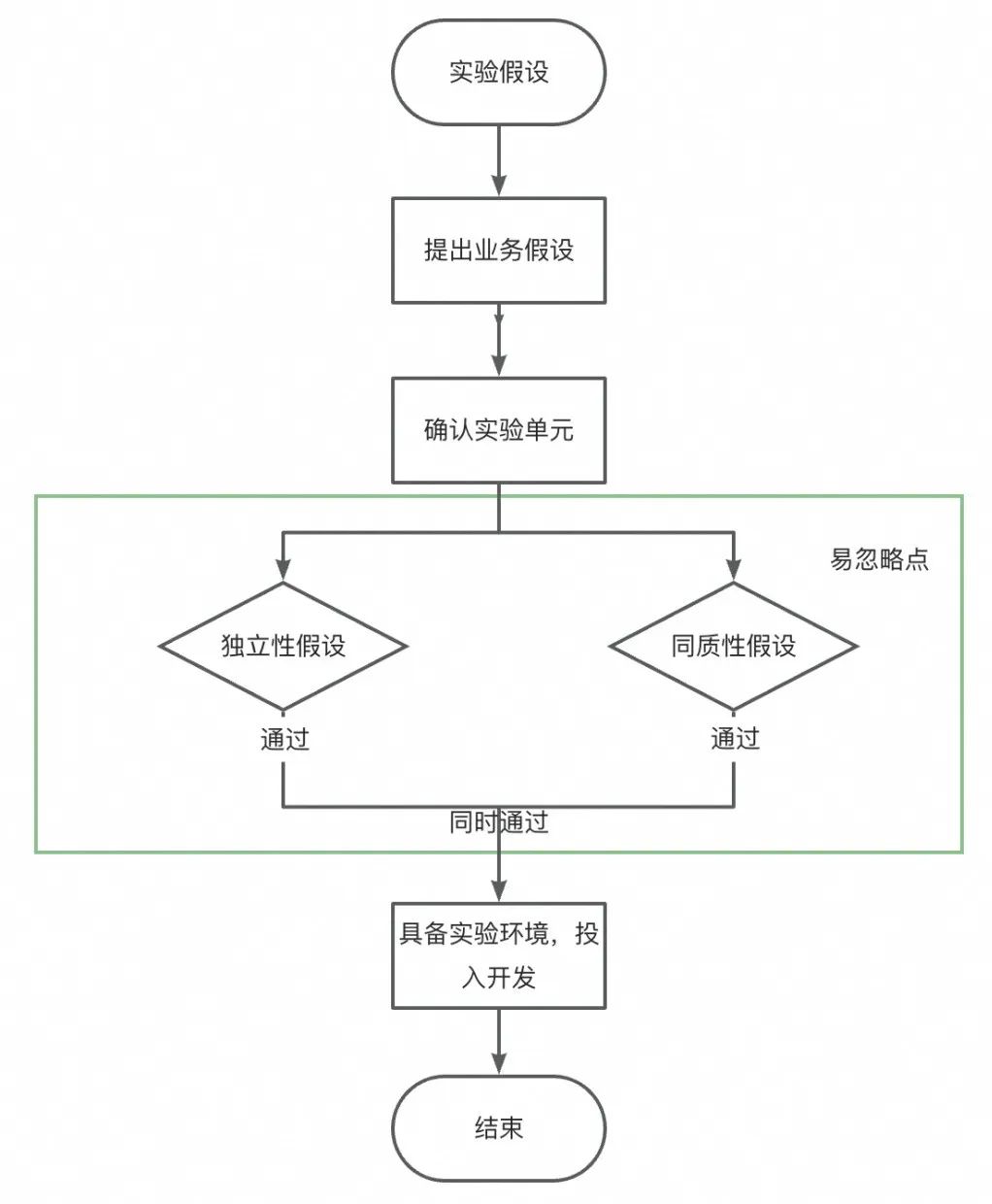
▐Caso 3 y 4: "Problema de independencia", el desbordamiento del comportamiento del usuario causado por la relación comunitaria entre los fanáticos y el desbordamiento del comportamiento del ancla causado por la relación de competencia de tráfico entre los anclas. ¿Cómo realizar estos experimentos?
analisis de CASO
Solución actual
Al dividir el tiempo en múltiples intervalos de tiempo y utilizar cada intervalo de tiempo como una unidad experimental independiente, podemos garantizar que todos los usuarios en el mismo intervalo de tiempo experimenten la misma estrategia. Este diseño evita eficazmente el problema de la inconsistencia en la experiencia del usuario. De manera similar, en cada intervalo de tiempo, todo el tráfico se asignará uniformemente a una política. Esta disposición previene fundamentalmente la competencia de tráfico y la inconsistencia en la experiencia del usuario, asegurando la equidad y efectividad del experimento. Los experimentos de rotación de intervalos de tiempo nos permiten brindar una experiencia unificada para todos los usuarios en un momento dado, manteniendo la coherencia y evitando posibles interrupciones durante el experimento.

defecto:
由于其实验单元为时间,所以可统计样本量较少,导致实验效果评估周期长,同时日期切片容易受热点事件影响,导致实验结论偏差。
由于需保证实验单元的独立性,且日期天然存在延续性,因此要减少日期之间的影响,例如1号的策略会影响到2号凌晨的主播(因为主播的场次容易跨天),所以日期切割需要结合业务特点,灵活选择时间切片大小和切割点。

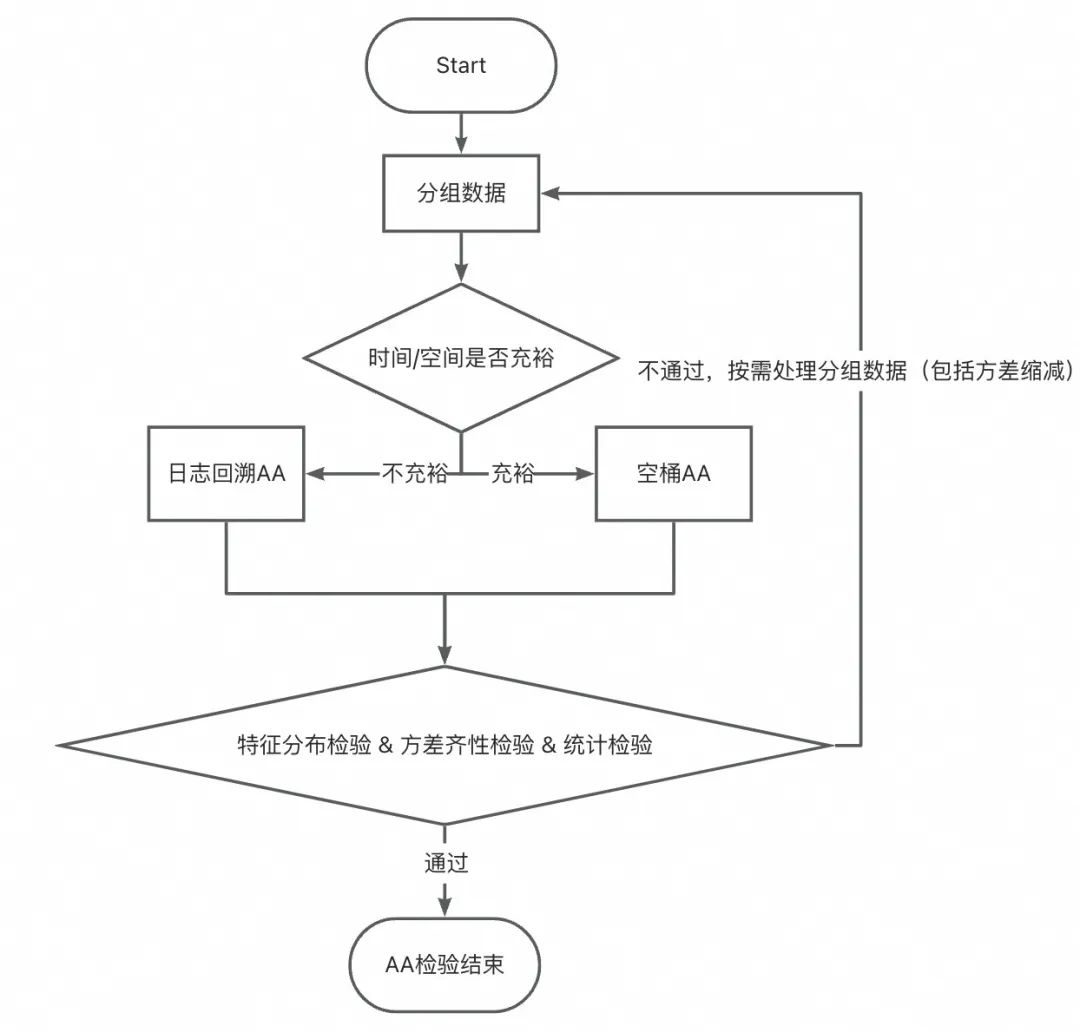
▐ 案例五:「AA检验不通过」在一次下单返红包的实验中,在分析实验数据时才发现用户分布不均匀,导致实验结论严重错误,甚至得出相反结论,浪费实验期间投入的预算等资源。
案例分析
当前解法
1、分布均匀性检验
在这次案例中,实验组和对照组在购买力分层上严重不均,从而导致其核心指标也显著不均,无法获得实验效果。注意:
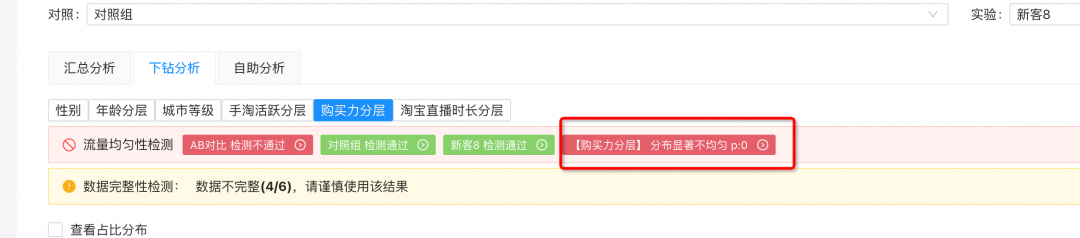
注意:分布不均匀并不一定表示实验数据不可用,本次案例是由于分布不均匀引起了核心指标不同质,导致了实验效果无法验证;
2、方差齐性检验 & 统计检验
在这次案例中,购买力的分布不均已经引起了指标不同质。从下图可以直观理解不同质现象,假设实验组和对照组本身同质,那么他们的数据分布应该都在绿色区域中,随后因为实验组施加了不同策略,导致实验组数据分布从绿色区域移动到了黄色区域。如果实验组未上策略就已经移动到了黄色区域,那么我们是无法证明策略对实验的影响。


图为检验结果
-
统计检验:通过双样本T检验或者多样本ANOVA检验,比较两个独立样本或配对样本的均值差异,具体检验方法可以根据实验样本量大小、样本均衡性情况、样本组数量决定。 -
方差齐性检验:通过Levene's Test或Bartlett's Test来验证实验组和对照组的数据方差是否一致。如果p值大于常用的显著性水平(如0.05),则可以认为组间方差是同质的。
▐ 案例六:「异常值问题』在一次打赏实验中,发现实验效果波动较大,排查后发现榜一大哥竟能左右实验效果
案例分析
在这个案例中,由于实验的用户一致性,榜一大哥会持续进入同一个实验组,于是大哥上线的天数该实验组效果就很好,大哥不在的天数则表现平平。这种实验如果没有找到这个异常值,按照常规经验难以进行分析和迭代。
当前解法
方差缩减:因为异常值会影响到指标的均值、方差,因此异常值除了引起汇总结果的波动外,实验的AA检验、AB检验也都会受影响。目前根据参与实验的实际样本量,采用常用手段:四分位数间距法、标准差法、Z-Score、孤立森林等方式做动态处理。
思考
A/B实验是验证因果关系的黄金标准。错误的因,只会带来错误的果。做好数据可用性验证,保证因果关系的正确发现,是沉淀实验经验,建立实验文化的必要基础。

在获得可用的数据基础后,我们开始关注实验分析的问题,图示为一个简化的实验分析流程。
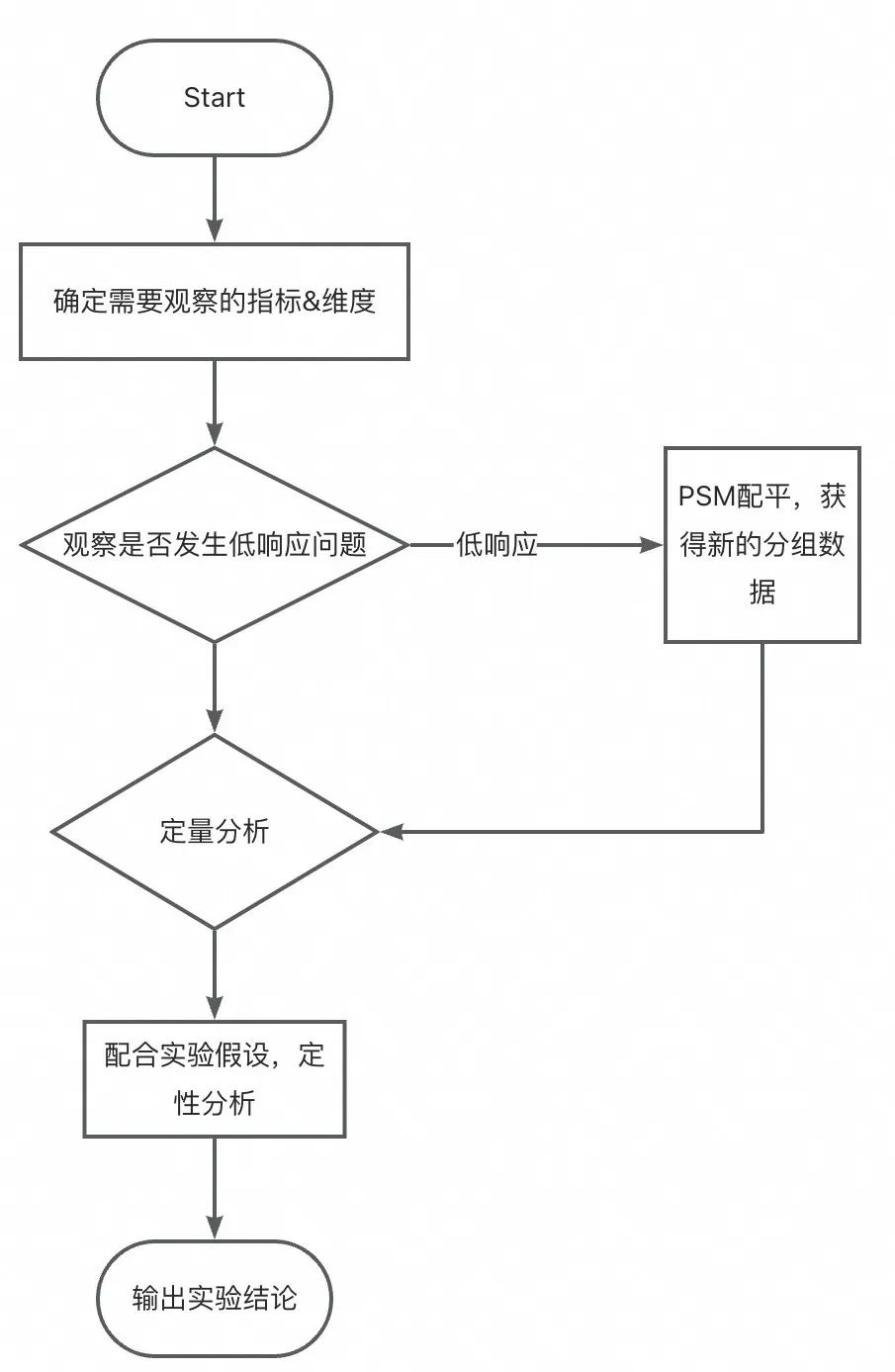
确定需要观察的指标&维度:
在上述案例中,可以发现漏看关键指标、关键维度都可能影响实验结论产出,且实际过程中实验往往需要下钻到关键维度,根据维度项里对实验的差异反应,寻找迭代方向。
▐ 案例七:「实验正确看数」在提单价的实验中,我们发现实验的GMV提升明显,但是观看时长显著降低
案例分析
由于提高了价格带,导致部分低购用户直接选择不看了,而这部分用户本身对GMV的贡献也不大,所以实验依然能够取得明显效果,然而低购群体里的较低年龄段用户他们贡献了较多的观看时长,因此该实验的观看时长也被显著降低。
因此得出一个业务经验:提单价的实验应避免波及(低GMV贡献但高观看时长贡献)的用户。
当前解法
针对不同业务背景,提前确定看数范围(指标+维度),避免经验不足引起的实验观察错误,通常这块由业务方+数据同学共同制定。
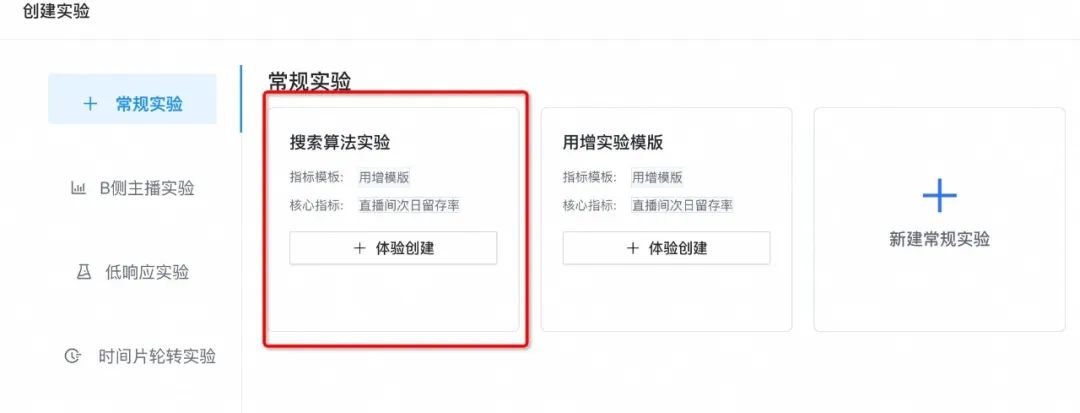
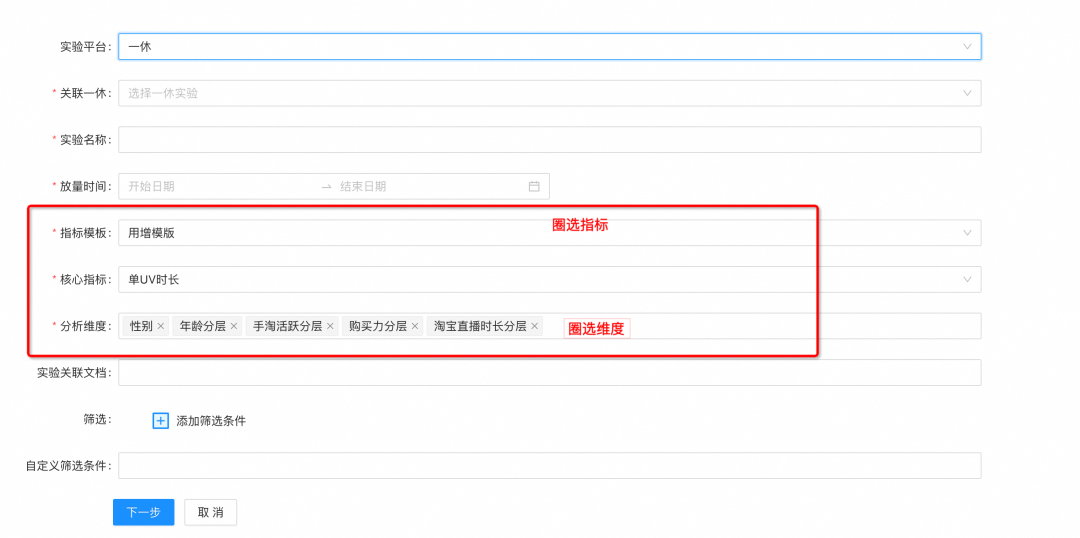
判断低响应实验
▐ 案例八:「低响应实验」活动入口做的AB实验,响应度太低无法分析实验数据。

案例分析
当前解法
▐ 定量分析
这块在第一篇文章中已经浓重介绍过,这里不再赘述。简单提及要点:没有置信度支撑的数据叫随机波动,不要当作实验结论。
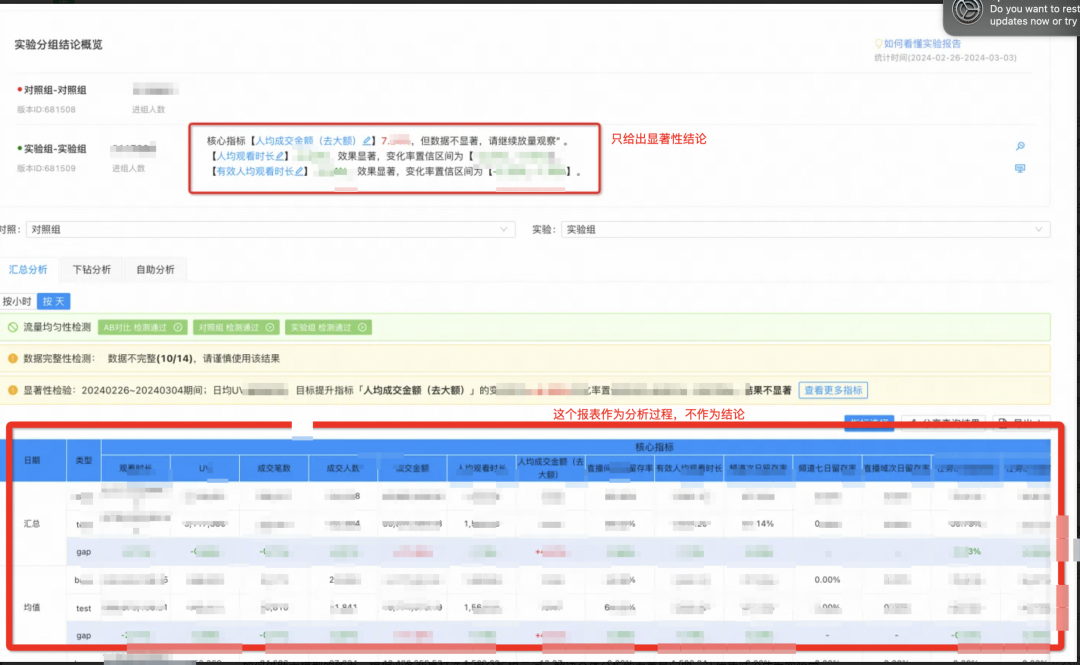
思考:

相关资料
实验推全最终会回应到业务目标达成,我在这块的推动经验较为薄弱,如何围绕业务目标建立可量化的推全标准,这需要多方的信任基础和强大的组织推力,以后补充。
感谢领导信任,让我有机会在直播业务中完善我对A/B实验的理解;感谢大佬的大力支持,感谢所有合作的产品老师、运营老师、算法老师、工程老师、数据研发老师、数据科学老师的大力支持。

技术线内容技术团队,是承接淘天内容电商最核心的技术力量,团队拥有非常全面的内容技术领域布局,不仅覆盖音视频编解码、流媒体传输、低延时直播等多媒体技术,也包含计算机视觉、自然语言处理、多模态內容理解、AIGC等人工智能领域。
在内容技术领域之外,团队拥有强大的算法、前端、客户端、服务端、测试开发、数据开发、数据科学团队、负责面向亿级消费者提供服务的淘宝直播、淘宝逛逛、点淘等核心业务场域;
面向千万级商家、品牌、机构、达人的内容创作工具、内容运营平台内容商业化解决方案;以及面向淘天集团电商板块各业务线的内容管理、内容总线等基石平台。
简历投递邮箱:[email protected]
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。