


Las principales ideas de aceleración actuales incluyen optimización de operadores, compilación de modelos, almacenamiento en caché de modelos, destilación de modelos, etc. A continuación se presentarán brevemente varias soluciones representativas de código abierto utilizadas en las pruebas.
▐Optimización del operador : FlashAttention2
▐Compilación del modelo : oneflow/stable-fast
oneflow acelera la inferencia del modelo al compilarlo en un gráfico estático y combinarlo con la fusión de operadores integrada de oneflow.nn.Graph y otras estrategias de aceleración. La ventaja es que el modelo SD básico solo necesita una línea de código compilado para completar la aceleración, el efecto de aceleración es obvio, la diferencia en el efecto de generación es pequeña y se puede usar en combinación con otras soluciones de aceleración (como deepcache) Y la frecuencia de actualización oficial es alta. Las deficiencias se discutirán más adelante.
Stable-fast también es una biblioteca de aceleración basada en la compilación de modelos y combina una serie de métodos de aceleración de fusión de operadores, pero su optimización del rendimiento se basa en herramientas como xformer, triton y torch.jit.
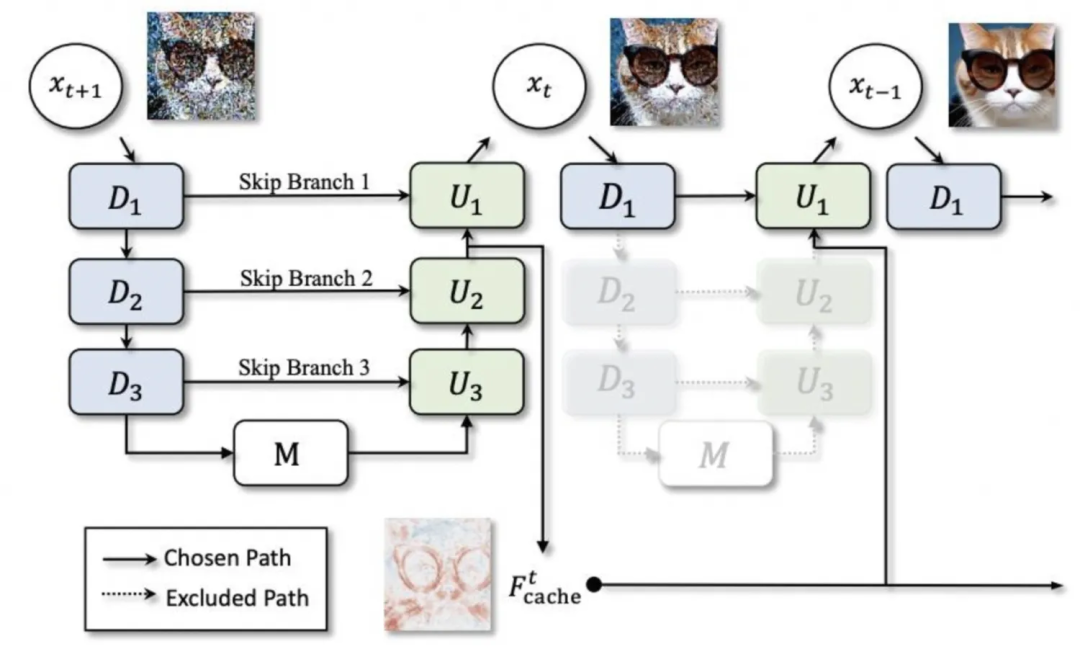
▐Almacenamiento en caché del modelo: deepcache
▐Modelo de destilación: lcm-lora
Combinando lcm (modelo de consistencia latente) y lora, lcm destilará todo el modelo sd para lograr un razonamiento de pocos pasos, mientras que lcm-lora usa la forma de lora para optimizar solo la parte de lora, que también se puede combinar directamente. con el uso regular de lora.

Prueba de aceleración SD1.5
▐Entorno de prueba
▐Resultados de la prueba
-
Al comparar las imágenes generadas con una semilla fija, podemos encontrar que la compilación de oneflow puede reducir rt en más del 40% sin casi ninguna pérdida de precisión. Sin embargo, cuando se utiliza una nueva canalización para generar imágenes por primera vez, se necesitan decenas de horas. segundos de tiempo de compilación como calentamiento. -
Deepcache puede reducir rt entre un 15% y un 25% adicional sobre esta base, pero al mismo tiempo, a medida que aumenta el intervalo de caché, la diferencia en el efecto de generación se vuelve cada vez más obvia. -
oneflow también es efectivo para el modelo SD1.5 usando controlnet -
stable-fast depende en gran medida de paquetes externos y es propenso a varios problemas de versión y errores de herramientas externas. Al igual que oneflow, se necesita una cierta cantidad de tiempo de compilación para generar imágenes por primera vez y el efecto de aceleración final es ligeramente inferior. un flujo.
▐Datos comparativos detallados
Mejoramiento |
Tiempo medio de generación (segundos) 512*512,50 pasos |
efecto de aceleración |
Generar efecto 1 |
Generar efecto 2 |
Generar efecto 3 |
difusores |
3.3701 |
0 |
|
|
|
difusores+bf16 |
3.3669 |
≈0 |
|
|
|
difusores+controlnet |
4.7452 |
|
|||
compilación difusores+oneflow |
1.9857 |
41,08% |
|
|
|
difusores+recopilación oneflow+controlnet |
2.8017 |
|
|||
difusores+compilación oneflow+deepcache |
intervalo = 2: 1,4581 |
56,73% (15,65%) |
|
|
|
intervalo=3:1.3027 |
61,35% (20,27%) |
|
|
||
intervalo=5:1.1583 |
65,63% (24,55%) |
|
|
||
difusores+rapidos |
2.3799 |
29,38% |















▐Entorno de prueba
▐Resultados de la prueba
Modelo sdxl básico:
Bajo la condición de semilla fija, parece más probable que el modelo sdxl afecte el efecto de generar imágenes mediante el uso de diferentes esquemas de aceleración.
Oneflow solo puede reducir el rt en un 24%, pero aún puede garantizar la precisión de las imágenes generadas.
Deepcache puede proporcionar una aceleración extremadamente significativa. Cuando el intervalo es 2 (es decir, el caché solo se usa una vez), rt se reduce en un 42%. Cuando el intervalo es 5, rt se reduce en un 69%. Las imágenes también son obvias.
lcm-lora reduce significativamente la cantidad de pasos necesarios para generar gráficos y puede lograr una aceleración de inferencia en gran medida. Sin embargo, cuando se utilizan pesos previamente entrenados, la estabilidad es extremadamente pobre y es muy sensible a la cantidad de pasos. Garantizar una salida estable consistente con la imagen solicitada.
oneflow y deepcache/lcm-lora se pueden usar bien juntos
lora:
Después de cargar lora, la velocidad de inferencia de los difusores se reduce significativamente y el grado de reducción está relacionado con el tipo y la cantidad de lora utilizada.
deepcache todavía funciona y todavía hay problemas de precisión, pero la diferencia no es grande en intervalos de caché más bajos
Cuando se usa lora, la compilación de oneflow no puede arreglar la semilla para que siga siendo consistente con la versión original.
La compilación de Oneflow optimiza la velocidad de inferencia después de cargar lora. Cuando se cargan varios loras, el rt de inferencia es casi el mismo que cuando no se carga ningún lora y el efecto de aceleración es extremadamente significativo. Por ejemplo, usando dos loras de hilo + acuarela al mismo tiempo, el rt se puede reducir en aproximadamente un 65%.
oneflow ha optimizado ligeramente el tiempo de carga de lora, pero el tiempo de operación de configuración después de cargar lora ha aumentado.
▐Datos comparativos detallados
Mejoramiento |
lora |
Tiempo promedio de generación (segundos) 512*512, 50 pasos |
Tiempo de carga de Lora (segundos) |
tiempo de modificación de lora (segundos) |
Efecto 1 |
Efecto 2 |
Efecto 3 |
difusores |
ninguno |
4.5713 |
|
||||
hilo |
7.6641 |
13.9235 11.0447 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0263 |
||||||
yarn+watercolor |
10.1402 |
|
|||||
diffusers+bf16 |
无 |
4.6610 |
|
||||
yarn |
7.6367 |
12.6095 11.1033 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0192 |
||||||
yarn+ watercolor |
10.0729 |
||||||
diffusers+deepcache |
无 |
interval=2:2.6402 |
|
||||
yarn |
interval=2:4.6076 |
||||||
watercolor |
interval=2:4.3953 |
||||||
yarn+ watercolor |
interval=2:5.9759 |
|
|||||
无 |
interval=5: 1.4068 |
|
|||||
yarn |
interval=5:2.7706 |
||||||
watercolor |
interval=5:2.8226 |
||||||
yarn+watercolor |
interval=5:3.4852 |
|
|||||
diffusers+oneflow编译 |
无 |
3.4745 |
|
||||
yarn |
3.5109 |
11.7784 10.3166 |
0.5左右 移除lora 0.17 |
||||
watercolor |
3.5483 |
||||||
yarn+watercolor |
3.5559 |
|
|||||
diffusers+oneflow编译+deepcache |
无 |
interval=2:1.8972 |
|
||||
yarn |
interval=2:1.9149 |
||||||
watercolor |
interval=2:1.9474 |
||||||
yarn+watercolor |
interval=2:1.9647 |
|
|||||
无 |
interval=5:0.9817 |
|
|||||
yarn |
interval=5:0.9915 |
||||||
watercolor |
interval=5:1.0108 |
||||||
yarn+watercolor |
interval=5:1.0107 |
|
|||||
diffusers+lcm-lora |
4step:0.6113 |
||||||
diffusers+oneflow编译+lcm-lora |
4step:0.4488 |














AI试衣业务场景使用了算法在diffusers框架基础上改造的专用pipeline,功能为根据待替换服饰图对原模特图进行换衣,基础模型为SD2.1。
根据调研的结果,deepcache与oneflow是优先考虑的加速方案,同时,由于pytorch版本较低,也可以尝试使用较新版本的pytorch进行加速。
▐ 测试环境
A10 + cu118 + py310 + torch2.0.1 + diffusers0.21.4
图生图(示意图,仅供参考):
待替换服饰 |
原模特图 |
|
|


▐ 测试结果
pytorch2.2版本集成了FlashAttention2,更新版本后,推理加速效果明显
deepcache仍然有效,为了尽量不损失精度,可设置interval为2或3
对于被“魔改”的pipeline和子模型,oneflow的图转换功能无法处理部分操作,如使用闭包函数替换forward、使用布尔索引等,而且很多错误原因较难通过报错信息来定位。在进行详细的排查之后,我们尝试了改造原模型代码,对其中不被支持的操作进行替换,虽然成功地在没有影响常规生成效果的前提下完成了改造,通过了oneflow编译,但编译后的生成效果很差,可以看出oneflow对pytorch的支持仍然不够完善
最终采取pytorch2.2.1+deepcache的结合作为加速方案,能够实现rt降低40%~50%、生成效果基本一致且不需要过多改动原服务代码
▐ 详细对比数据
优化方法 |
平均生成耗时(秒) 576*768,25step |
生成效果 |
diffusers |
22.7289 |
|
diffusers+torch2.2.1 |
15.5341 |
|
diffusers+torch2.2.1+deepcache |
11.7734 |
|
diffusers+oneflow编译 |
17.5857 |
|
diffusers+deepcache |
interval=2:18.0031 |
|
interval=3:16.5286 |
|
|
interval=5:15.0359 |
|








目前市面上有很多非常好用的开源模型加速工具,pytorch官方也不断将各种广泛采纳的优化技术整合到最新的版本中。
我们在初期的调研与测试环节尝试了很多加速方案,在排除了部分优化效果不明显、限制较大或效果不稳定的加速方法之后,初步认为deepcache和oneflow是多数情况下的较优解。
但在解决实际线上服务的加速问题时,oneflow表现不太令人满意,虽然oneflow团队针对SD系列模型开发了专用的加速工具包onediff,且一直保持高更新频率,但当前版本的onediff仍存在不小的限制。
如果使用的SD pipeline没有对unet的各种子模块进行复杂修改,oneflow仍然值得尝试;否则,确保pytorch版本为最新的稳定版本以及适度使用deepcache可能是更省心且有效的选择。

相关资料
FlashAttention:
https://github.com/Dao-AILab/flash-attention
https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
oneflow
https://github.com/Oneflow-Inc/oneflow
https://github.com/siliconflow/onediff
stable-fast
https://github.com/chengzeyi/stable-fast
deepcache
https://github.com/horseee/DeepCache
lcm-lora
https://latent-consistency-models.github.io/
pytorch 2.2
https://pytorch.org/blog/pytorch2-2/

我们是淘天集团内容技术AI工程团队,通过搭建完善的算法工程化一站式平台,辅助上千个淘宝图文、视频、直播等泛内容领域算法的工程落地、部署和优化,承接每日上亿级别的数字内容数据,支撑并推动AI技术在淘宝内容社交生态中的广泛应用。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。