
¿Qué es la alta cardinalidad?
La cardinalidad se define en matemáticas como un escalar utilizado para representar el número de elementos de un conjunto. Por ejemplo, la cardinalidad de un conjunto finito A = {a, b, c} es 3. También existe un concepto de cardinalidad para conjuntos infinitos. Hoy hablamos principalmente del campo de las computadoras, no nos extenderemos aquí.
En el contexto de una base de datos, no existe una definición estricta de cardinalidad, pero el consenso de todos sobre la cardinalidad es similar a la definición en matemáticas: se utiliza para medir el número de valores diferentes contenidos en una columna de datos. Por ejemplo , una tabla de datos que registra usuarios generalmente tiene varias columnas UIDy Obviamente, la cardinalidad de tan alta como la de , y Nameuna columna de puede tener relativamente pocos valores. Entonces, en el ejemplo de la tabla de usuarios, se puede decir que la columna pertenece a la base alta y la columna pertenece a la base baja.GenderUIDIDNameUIDGenderUIDGender
Si se subdivide aún más en el campo de la base de datos de series de tiempo, la cardinalidad a menudo se refiere al número de líneas de tiempo. Tomemos como ejemplo la aplicación de la base de datos de series de tiempo en el campo observable. Servicios API. Para dar el ejemplo más simple, hay dos etiquetas para el tiempo de respuesta de cada interfaz del servicio API de diferentes instancias: API Routesy InstanceSi hay 20 interfaces y 5 instancias, la base de la línea de tiempo es (20+1)x(5. +1)-1 = 125 ( +1teniendo en cuenta que el tiempo de respuesta de todas las interfaces de una Instancia o el tiempo de respuesta de una interfaz en todas las Instancias se puede ver por separado), el valor no parece grande, pero cabe señalar que el operador es un producto, por lo que siempre que una cierta cardinalidad de una etiqueta sea alta o se agregue una nueva etiqueta, la cardinalidad de la línea de tiempo aumentará dramáticamente.
Por qué es importante
Como todos sabemos, las bases de datos relacionales como MySQL, con las que todo el mundo está más familiarizado, generalmente tienen columnas de ID, así como columnas comunes como correo electrónico, número de pedido, etc. Estas son columnas de alta cardinalidad y rara vez se oye hablar de ellas. Sin embargo, surgen ciertos problemas debido a dicho modelado de datos. El hecho es que en el campo OLTP que conocemos, la alta cardinalidad a menudo no es un problema, pero en el campo de la temporización, a menudo causa problemas debido al modelo de datos. Antes de entrar en el campo de la temporización, todavía lo discutimos primero. Echemos un vistazo a lo que realmente significa un conjunto de datos de base alta.
En mi opinión, en términos sencillos, un conjunto de datos de base alta significa una gran cantidad de datos para una base de datos, el aumento en la cantidad de datos inevitablemente tendrá un impacto en la escritura, las consultas y el almacenamiento. El impacto al escribir es el índice.
Alta cardinalidad de las bases de datos tradicionales.
Tomemos como ejemplo el árbol B, la estructura de datos más común utilizada para crear índices en bases de datos relacionales. Normalmente, la complejidad de la inserción y la consulta es O (logN), y la complejidad del espacio es generalmente O (N). N es el número de elementos, que es la cardinalidad de la que hablamos. Naturalmente, un N mayor tendrá un cierto impacto, pero debido a que la complejidad de la inserción y la consulta es el logaritmo natural, el impacto no es tan grande cuando la magnitud de los datos no es particularmente grande.
Por lo tanto, parece que los datos de base alta no tienen ningún impacto que no pueda ignorarse. Por el contrario, en muchos casos, el índice de datos de base alta es más selectivo que el índice de datos de base baja. Puede filtrar datos grandes a través de una condición de consulta. Datos parciales que no cumplen con las condiciones, reduciendo así la sobrecarga de E / S del disco. En las aplicaciones de bases de datos, es necesario evitar la sobrecarga excesiva de E / S del disco. Por ejemplo select * from users where gender = "male";, el conjunto de datos resultante será muy grande y la E/S del disco y la E/S de la red serán muy grandes. En la práctica, usar este índice de baja cardinalidad por sí solo no tiene mucho sentido.
Alta cardinalidad de las bases de datos de series temporales.
Entonces, ¿qué diferencia a las bases de datos de series temporales que hacen que las columnas de datos con una base alta causen problemas? En el campo de los datos de series de tiempo, ya sea modelado de datos o diseño de motores, el núcleo girará en torno a la línea de tiempo. Como se mencionó anteriormente, el problema de la alta cardinalidad en la base de datos de series de tiempo se refiere al número y tamaño de las líneas de tiempo. Este tamaño no es solo la cardinalidad de una columna, sino el producto de la cardinalidad de todas las columnas de etiquetas. Se puede entender que en las bases de datos relacionales comunes, la base alta está aislada en una determinada columna, es decir, la escala de datos crece linealmente, mientras que en las bases de datos de series de tiempo la base alta es el producto de múltiples columnas, lo cual no es lineal. crecimiento. Echemos un vistazo más de cerca a cómo se genera la línea de tiempo de base alta en la base de datos de series de tiempo. Veamos primero el primer escenario:
Cantidad de series temporales
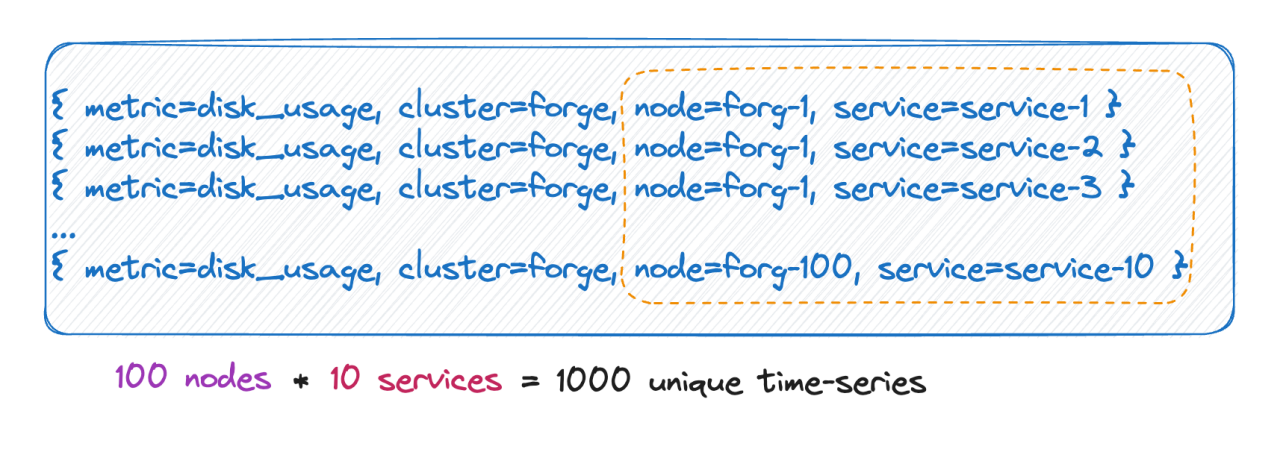
Sabemos que el número de líneas de tiempo es en realidad igual al producto cartesiano de todas las bases de etiquetas. Como se muestra en la imagen anterior, la cantidad de líneas de tiempo es 100 * 10 = 1000 líneas de tiempo. Si se agregan 6 etiquetas a esta métrica, cada valor de etiqueta tiene 10 valores y la cantidad de líneas de tiempo es 10^9, que es 100 millones. Una línea de tiempo, puedes imaginar esta magnitud.
La etiqueta tiene valores infinitos
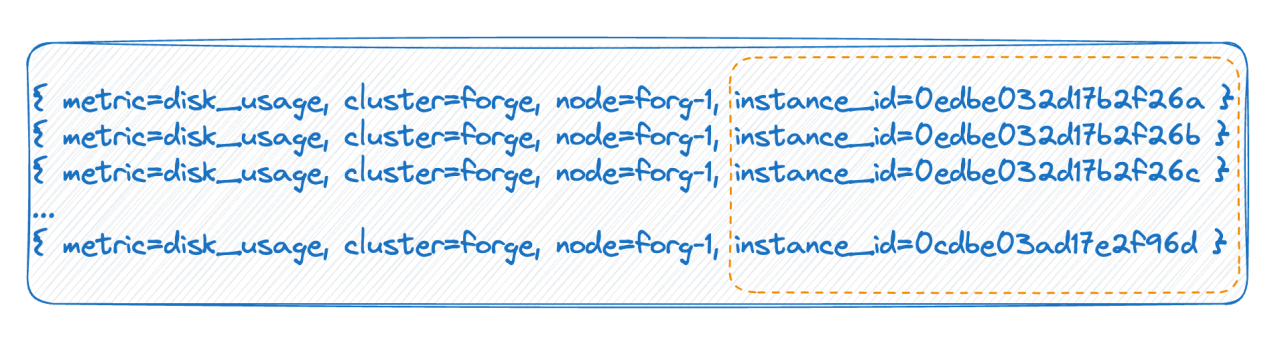
En el segundo caso, por ejemplo, en un entorno nativo de la nube, cada pod tiene una ID. Cada vez que se reinicia, el pod se elimina y se reconstruye, y se genera una nueva ID, lo que hace que el valor de la etiqueta sea muy alto. Hay muchos, y cada reinicio completo hará que la cantidad de líneas de tiempo se duplique. Las dos situaciones anteriores son las principales razones de la alta cardinalidad mencionada por la base de datos de series temporales.
Cómo organiza la base de datos de series de tiempo los datos
Sabemos qué tan alta es la cardinalidad. Necesitamos comprender qué problemas causará y también debemos comprender cómo organizan los datos las bases de datos de series temporales convencionales.
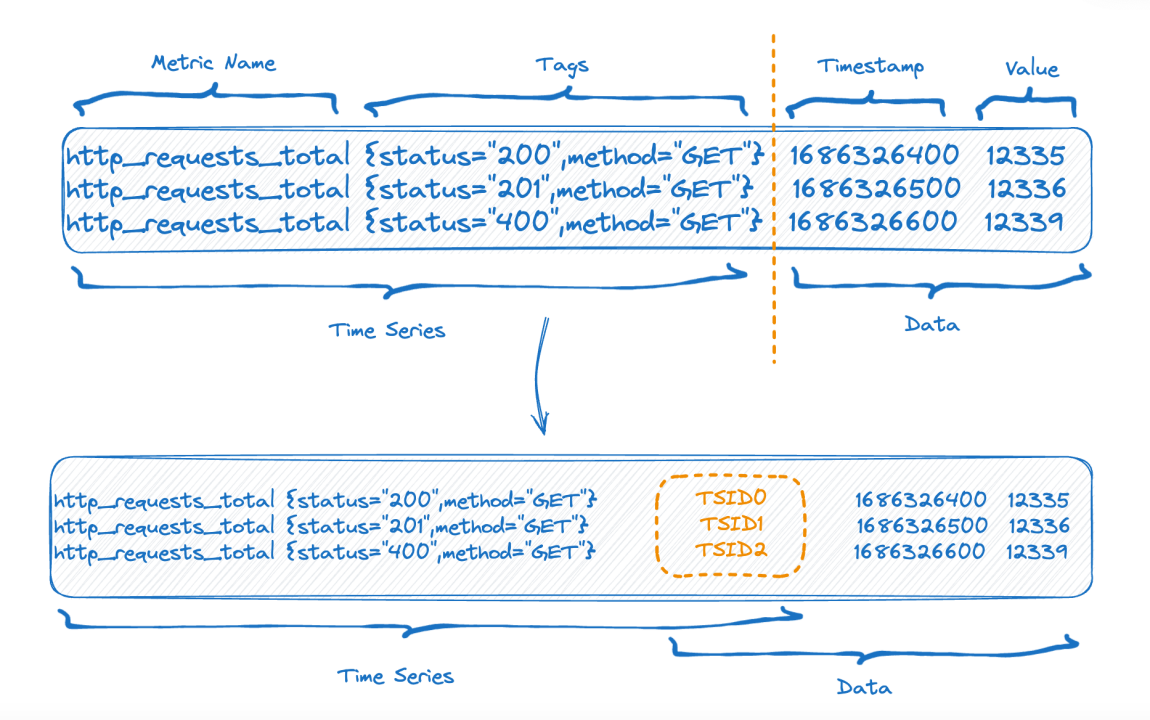
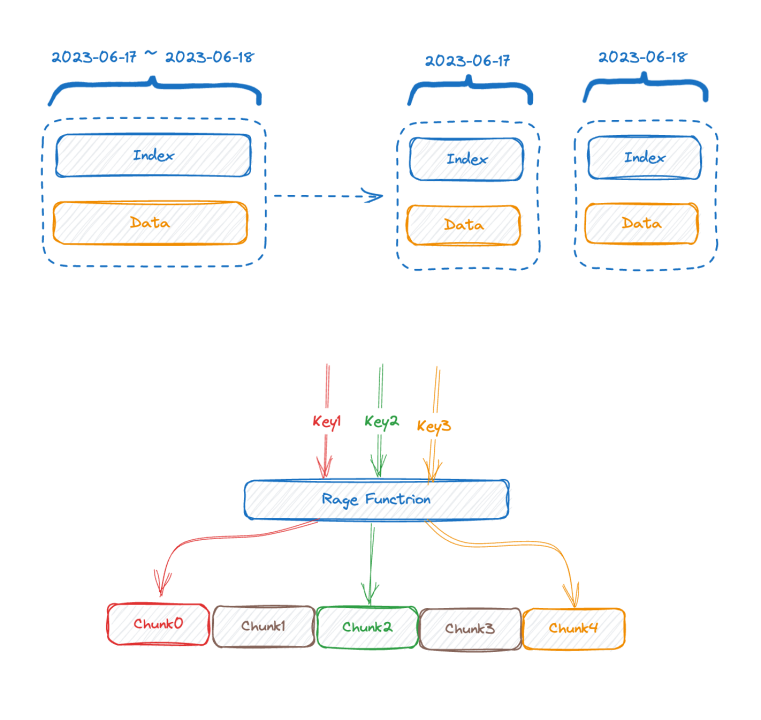
La mitad superior de la figura muestra la representación antes de escribir los datos y la mitad inferior de la figura muestra la representación lógica después del almacenamiento de datos. El lado izquierdo son los datos de índice de la parte de la serie temporal y el lado derecho son los datos. parte.
Cada serie temporal puede generar un TSID único, y el índice y los datos están relacionados a través del TSID. Es posible que amigos familiares hayan visto este índice, es un índice invertido.
Miremos la imagen a continuación, que es una representación del índice invertido en la memoria:
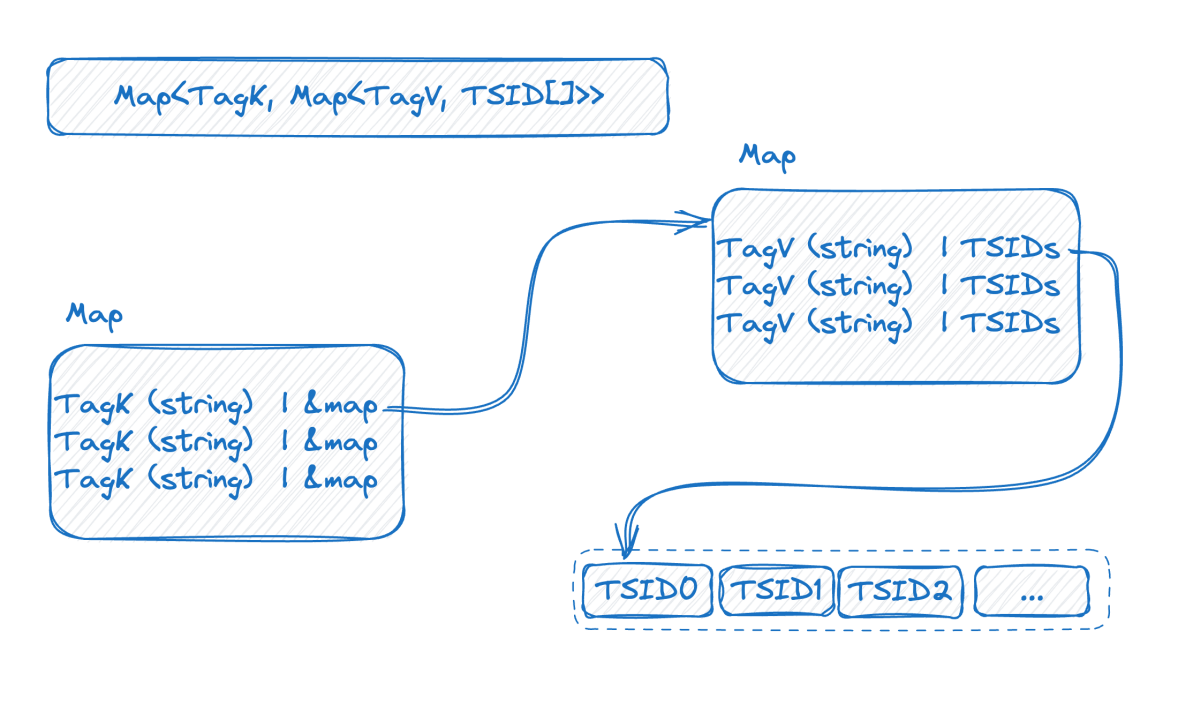
Este es un mapa de dos capas. La capa externa primero encuentra el mapa interno a través del nombre de la etiqueta. K en el mapa interno es el valor de la etiqueta y V es el conjunto de TSID que contiene el valor de la etiqueta correspondiente.
En este punto, combinado con la introducción anterior, podemos ver que cuanto mayor sea la base de datos de la serie temporal, más grande será el mapa de doble capa. Después de comprender la estructura del índice, podemos intentar comprender cómo surge el problema de base alta:
Para lograr un alto rendimiento de escritura, es mejor mantener este índice en la memoria. Una cardinalidad alta hará que el índice se expanda y no podrá caber en la memoria. Si la memoria no se puede almacenar, se debe cambiar al disco. Después de cambiar al disco, la velocidad de escritura se verá afectada debido a una gran cantidad de E/S aleatorias en el disco. Veamos la consulta nuevamente. A partir de la estructura del índice, podemos adivinar el proceso de consulta, como las condiciones de la consulta where status = 200 and method="get". El proceso consiste en encontrar primero statusel mapa con la clave, obtener el mapa interno y luego "200"obtener todos los conjuntos de TSID y verificar. nuevamente de la misma manera, y luego el nuevo conjunto de TSID obtenido después de la intersección de los dos conjuntos de TSID se usa para recuperar datos uno por uno de acuerdo con el TSID.
Se puede ver que el núcleo del problema es que los datos están organizados según la línea de tiempo, por lo que primero debe obtener la línea de tiempo y luego encontrar los datos según la línea de tiempo. Cuantas más líneas de tiempo estén involucradas en una consulta, más lenta será la consulta.
Cómo resolverlo
Si nuestro análisis es correcto y conocemos la causa del problema de base alta en el campo de datos de series de tiempo, entonces será fácil de resolver.
- Nivel de datos: mantenimiento del índice y desafíos de consulta causados por C(L1) * C(L2) * C(L3) * ... * C(Ln).
- Nivel técnico: los datos están organizados según la línea de tiempo, por lo que primero debe obtener la línea de tiempo y luego buscar los datos según la línea de tiempo. Si hay más líneas de tiempo, la consulta será más lenta.
El editor discutirá las soluciones desde dos aspectos:
Optimización del modelado de datos.
1 Eliminar etiquetas innecesarias
A menudo configuramos accidentalmente algunos campos innecesarios como etiquetas, lo que hace que la línea de tiempo se hinche. Por ejemplo, cuando monitoreamos el estado del servidor, a menudo tenemos instance_name, ipDe hecho, no es necesario que estos dos campos se conviertan en etiquetas. Uno de ellos probablemente sea suficiente y el otro se puede configurar como un atributo.
2. Modelado de datos basado en consultas reales.
Tomemos como ejemplo el monitoreo de sensores en el Internet de las cosas:
- dispositivos de 10w
- 100 regiones
- 10 dispositivos
Si se modela en una métrica, en Prometheus, dará como resultado una línea de tiempo de 10w * 100 * 10 = 100 millones. (Cálculo no riguroso) Piénselo, ¿se realizará la consulta de esta manera? Por ejemplo, ¿cómo consultar la línea de tiempo de un determinado tipo de equipo en una determinada región? Esto no parece razonable, porque una vez que se especifica el dispositivo, se determina el tipo, por lo que en realidad no es necesario que las dos etiquetas estén juntas, entonces puede convertirse en:
- metric_one: dispositivos de 10w
- métrica_dos:
- 100 regiones
- 10 dispositivos
- metric_tres: (suponiendo que un dispositivo se pueda mover a una región diferente para recopilar datos)
- dispositivos de 10w
- 100 regiones
El total es una línea de tiempo de 10w + 100 10 + 10w 100 ~ 1010w, que es 10 veces menor que lo anterior.
3. Administre por separado datos valiosos del cronograma de base alta
Por supuesto, si encuentra que su modelado de datos es muy consistente con la consulta, pero el cronograma aún no se puede reducir porque la escala de datos es demasiado grande, entonces coloque todos los servicios relacionados con este indicador central en una máquina mejor.
Optimización de la tecnología de bases de datos de series temporales.
- La primera solución eficaz es la segmentación vertical. La mayoría de las bases de datos de series temporales convencionales de la industria han adoptado más o menos un método similar para segmentar el índice según el tiempo, porque si no se realiza esta segmentación, el índice se expandirá a medida que avance el tiempo. más y más, y finalmente la memoria no podrá almacenarla. Si se divide según el tiempo, el fragmento de índice antiguo se puede intercambiar en el disco o incluso el almacenamiento remoto no se verá afectado.
- Lo opuesto a la segmentación vertical es la segmentación horizontal. Se utiliza una clave de fragmentación, que generalmente puede ser una o varias etiquetas con la mayor frecuencia de uso de predicados de consulta. La segmentación por rango o hash se realiza en función de los valores de estas etiquetas. equivalente a usar La idea distribuida de divide y vencerás resuelve el cuello de botella en una sola máquina. El precio es que si la condición de consulta no incluye una clave de fragmentación, el operador no puede presionarse hacia abajo y los datos solo se pueden mover a la. capa superior para el cálculo.
Los dos métodos anteriores son soluciones tradicionales, que solo pueden aliviar el problema hasta cierto punto, pero no pueden resolverlo fundamentalmente. Las siguientes dos soluciones no son soluciones convencionales, pero son las direcciones que GreptimeDB está tratando de explorar. Aquí solo se mencionan brevemente sin un análisis en profundidad, solo como referencia:
-
Es posible que queramos pensar si las bases de datos de series de tiempo realmente necesitan índices invertidos. TimescaleDB usa índices de árbol B, e InfluxDB_IOx no tiene índices invertidos. Para consultas de alta cardinalidad, usamos escaneos de particiones comúnmente utilizados en bases de datos OLAP combinados con min-max. índices. ¿El efecto sería mejor si realizamos alguna optimización de poda?
-
Indexación inteligente asincrónica Para ser inteligente, primero debe recopilar y analizar comportamientos, analizar y crear de forma asincrónica el índice más apropiado para acelerar las consultas en cada consulta del usuario. Por ejemplo, elegimos etiquetas que aparecen muy raramente en las condiciones de consulta del usuario. No se crea ninguna inversión para ello. Combinando las dos soluciones anteriores, al escribir, debido a que la inversión se construye de forma asincrónica, no afecta la velocidad de escritura en absoluto.
Mirando la consulta nuevamente, debido a que los datos de la serie temporal tienen atributos de tiempo, los datos se pueden agrupar según la marca de tiempo. No indexamos el último segmento de tiempo. La solución es realizar un escaneo exhaustivo y combinar algunos índices mínimo-máximo para optimizar la poda. Todavía es posible escanear decenas de millones o cientos de millones de líneas en segundos.
Cuando llegue una consulta, primero calcule cuántas líneas de tiempo involucrará. Si involucra una cantidad pequeña, use la inversión, y si involucra mucho, vaya directamente a escanear + filtrar sin inversión.
Todavía estamos explorando las ideas anteriores y aún no somos perfectos.
Conclusión
Una base alta no siempre es un problema. A veces es necesaria una base alta. Lo que debemos hacer es construir nuestro propio modelo de datos en función de nuestras propias condiciones comerciales y la naturaleza de las herramientas que utilizamos. Por supuesto, a veces las herramientas tienen ciertas limitaciones de escenario. Por ejemplo, Prometheus indexa etiquetas bajo cada métrica de forma predeterminada. Esto no es un gran problema en un escenario de una sola máquina, pero también será conveniente para los usuarios. cuando se trata de datos a gran escala. GreptimeDB se compromete a crear una solución unificada tanto en escenarios independientes como a gran escala. También estamos explorando intentos técnicos para problemas de base alta, y todos pueden discutirlo.
Referencia
- https://en.wikipedia.org/wiki/Cardinality
- https://www.cncf.io/blog/2022/05/23/what-is-high-cardinality/
- https://grafana.com/blog/2022/10/20/how-to-manage-high-cardinality-metrics-in-prometheus-and-kubernetes/
Acerca de Greptime:
Greptime Greptime Technology se compromete a proporcionar servicios de análisis y almacenamiento de datos eficientes y en tiempo real para campos que generan grandes cantidades de datos de series temporales, como automóviles inteligentes, Internet de las cosas y observabilidad, ayudando a los clientes a extraer el profundo valor de los datos. Actualmente existen tres productos principales:
-
GreptimeDB es una base de datos de series temporales escrita en lenguaje Rust. Es distribuida, de código abierto, nativa de la nube y altamente compatible. Ayuda a las empresas a leer, escribir, procesar y analizar datos de series temporales en tiempo real al tiempo que reduce los costos de almacenamiento a largo plazo.
-
GreptimeCloud puede proporcionar a los usuarios servicios DBaaS totalmente gestionados, que pueden integrarse altamente con la observabilidad, el Internet de las cosas y otros campos.
-
GreptimeAI es una solución de observabilidad diseñada para aplicaciones LLM.
-
La solución integrada de vehículo-nube es una solución de base de datos de series de tiempo que profundiza en los escenarios comerciales reales de las empresas automotrices y resuelve los puntos débiles comerciales reales después de que los datos de los vehículos de la empresa crecen exponencialmente.
GreptimeCloud y GreptimeAI han sido probados oficialmente. ¡Bienvenido a seguir la cuenta oficial o el sitio web oficial para conocer los últimos desarrollos! Si está interesado en la versión empresarial de GreptimDB, puede comunicarse con el asistente (busque greptime en WeChat para agregar el asistente).
Sitio web oficial: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Documentación: https://docs.greptime.cn/
Gorjeo: https://twitter.com/Greptime
Holgura: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Los estudiantes de secundaria crean su propio lenguaje de programación de código abierto como una ceremonia de mayoría de edad: comentarios agudos de los internautas: debido al fraude desenfrenado, confiando en RustDesk, el servicio doméstico Taobao (taobao.com) suspendió los servicios domésticos y reinició el trabajo de optimización de la versión web Java 17 es la versión Java LTS más utilizada. Cuota de mercado de Windows 10. Alcanzando el 70%, Windows 11 continúa disminuyendo. Open Source Daily | Google apoya a Hongmeng para hacerse cargo de los teléfonos Android de código abierto respaldados por Docker; Electric cierra la plataforma abierta Apple lanza el chip M4 Google elimina el kernel universal de Android (ACK) Soporte para la arquitectura RISC-V Yunfeng renunció a Alibaba y planea producir juegos independientes para plataformas Windows en el futuro