
Todos son bienvenidos a destacarnos en GitHub:
Sistema distribuido de aprendizaje causal de enlace completo OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Gran gráfico de conocimiento basado en modelos OpenSPG: https://github.com/OpenSPG/openspg
Sistema de aprendizaje de gráficos a gran escala OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
Título del artículo: PEACE: Prototipo de marco transferible aumentado de aprendizaje para recomendaciones entre dominios
Unidad organizativa: Grupo Ant
Conferencia de admisión: WSDM 2024
Enlace del artículo : https://arxiv.org/abs/2312.0191 6
El autor de este artículo: Gan Chunjing. Las principales direcciones de investigación son los algoritmos de gráficos, los algoritmos de recomendación, los modelos de lenguaje grandes y la aplicación de gráficos de conocimiento. Los resultados de la investigación se incluyen en las principales conferencias relacionadas con el aprendizaje automático (WSDM/SIGIR/AAAI). El trabajo principal del equipo durante el año pasado ha sido modelos de recomendación previamente entrenados basados en gráficos de conocimiento, modelos de lenguaje grandes basados en la mejora del conocimiento y sus aplicaciones, incluido el marco de red neuronal de gráficos basado en desacoplamiento de granularidad múltiple en el escenario de gestión financiera. publicado en SIGIR'23 MGDL, el prototipo del marco de recomendación entre dominios de preentrenamiento de gráficos de entidades basado en aprendizaje PEACE publicado en WSDM'24.
fondo
Con el desarrollo del ecosistema de miniprogramas de Alipay, cada vez más comerciantes han comenzado a operar miniprogramas en Alipay. Al mismo tiempo, Alipay también espera lograr una estrategia descentralizada a través de la ecología de miniprogramas + la autooperación del comerciante.
En el proceso de autooperación de los comerciantes, cada vez más pequeños y medianos comerciantes necesitan operaciones digitales e inteligentes, como mejorar la eficiencia del marketing de las posiciones de dominio privado de su mini programa a través de capacidades de recomendación personalizadas, pero para las pequeñas y medianas empresas. Para las empresas comerciales medianas, el costo técnico y el costo laboral de crear capacidades de recomendación personalizadas de IA autoconstruidas son muy altos.
En este contexto, esperamos brindar a los comerciantes recomendaciones personalizadas visibles pero inaccesibles y capacidades de búsqueda basadas en los datos masivos de comportamiento del usuario de Ant para ayudar a los comerciantes a crear mini programas inteligentes para aumentar los ingresos de los comerciantes en la plataforma Alipay y brindar a los usuarios una mejor experiencia personalizada. mejorar la retención de usuarios en Alipay y también puede acumular soluciones técnicas comunes para optimizar aún más la experiencia del comerciante/usuario.
Ha habido muchos casos de aplicaciones exitosas en la industria que utilizan datos de escenarios ricos en comportamiento para mejorar el efecto de recomendación en escenarios de cola media y larga. Por ejemplo, Taobao utiliza los datos de comportamiento de la primera suposición para mejorar el efecto de recomendación en otros pequeños. escenarios Fliggy utiliza la aplicación y Alipay pequeños escenarios para mejorar el efecto de recomendación. El terminal modela conjuntamente para mejorar el efecto de recomendación general.
Sin embargo, este tipo de método generalmente enfrenta múltiples escenarios de recomendación con mentalidades similares y utiliza datos de escenarios con comportamientos ricos para mejorar el efecto de recomendación de escenarios similares con comportamientos escasos, como Taobao, Fliggy, etc. Sin embargo, las súper aplicaciones como Alipay generalmente incluyen varios mini programas como viajes, asuntos gubernamentales, arrendamiento, viajes, catering, necesidades diarias, etc. Las diferencias mentales entre los usuarios en varios mini programas son muy grandes, lo que nos da un modelo. desafíos:
- Los mini programas de Alipay se encuentran dispersos en industrias verticales con tipos de negocios muy diferentes, como asuntos gubernamentales, alimentos, arrendamiento, comercio minorista y gestión financiera. En términos generales, estos mini programas no comparten información y es posible que elementos similares no tengan atributos similares. Al transferir directamente múltiples comportamientos en todo el dominio a un escenario de clase vertical específico sin alinear tales diferencias entre dominios, es difícil para el modelo aprender conocimientos útiles para la clase vertical a partir de los comportamientos mixtos de múltiples clases verticales, e incluso puede serlo. provocar una migración negativa;
- Aunque la migración punto a punto del comportamiento del usuario, por ejemplo, la industria alimentaria solo utiliza el comportamiento del usuario relacionado con el catering en Alipay, puede aliviar los problemas anteriores hasta cierto punto, pero cada vez que se agrega una nueva industria, se requiere intervención manual. Esto es costoso y no puede implementar toda la cadena. Además de la automatización de carreteras, algunos comerciantes también esperan que la plataforma Alipay pueda proporcionar soluciones de recomendación personalizadas plug-and-play cuando se conectan por primera vez, incluso cuando no hay datos de comportamiento del usuario. . Un modelo así no es viable en este contexto.
Con base en los desafíos anteriores, propusimos PEACE, un marco de aprendizaje de transferencia de múltiples escenarios previo al entrenamiento gráfico basado en el aprendizaje de prototipos, basado en el problema de las grandes diferencias entre los dominios de la industria vertical.
Introdujimos el gráfico de entidad y esperábamos utilizarlo como un puente para conectar las diferencias entre diferentes dominios para mitigar su impacto negativo en el modelado. Sin embargo, el gráfico de entidad en el entorno de producción suele ser enorme, aunque contiene una gran cantidad de. Sin embargo, también introducirá mucho ruido. La agregación indiscriminada de información estructural en el mapa de entidades generalmente reducirá la solidez del modelo. Por lo tanto, introdujimos el aprendizaje de prototipos para mejorar la representación de la entidad y el usuario en el proceso de modelado. para limitar.
En general, el marco PEACE es la idea de diseño de migración de ONE FOR ALL. Utilizamos el comportamiento de dominio público de múltiples fuentes de los usuarios en Alipay como entrada del modelo de capacitación previa y aprendemos los intereses y preferencias de los usuarios de múltiples industrias. uno a través de la idea de representación desacoplada en el modelo, combinado con la red prototipo que captura señales de la industria, solo necesita entrenar previamente un modelo unificado para migrar de manera adaptativa los múltiples intereses de los usuarios a diferentes industrias verticales posteriores para obtener recomendaciones personalizadas ( recomendación normal + se recomienda disparo cero).
PEACE: marco de recomendación entre dominios previo al entrenamiento de gráficos de entidades basado en el aprendizaje de prototipos
Alineación preliminar de conocimientos entre dominios basada en un gráfico de entidades
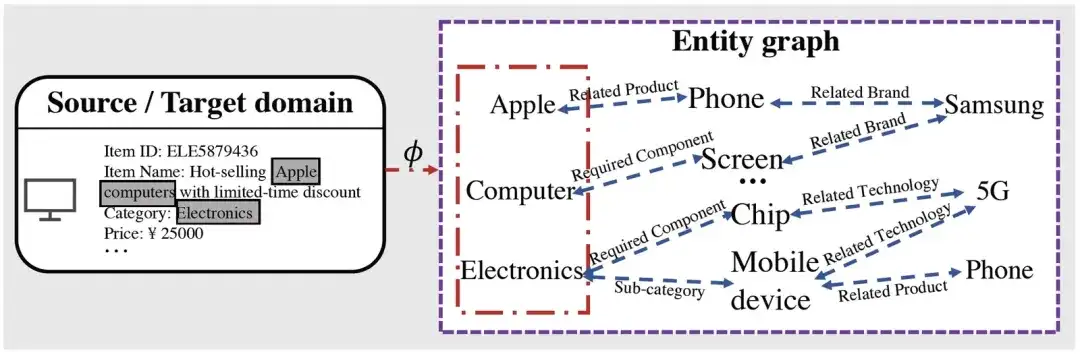

Se puede ver que después de obtener la entidad relacionada con el elemento correspondiente a través del mapeo, según el proceso de razonamiento gráfico, podemos obtener mucha información de alto nivel relacionada con la entidad mapeada. Por ejemplo, Apple tiene productos de telefonía móvil. empresas relacionadas con productos de telefonía móvil Hay Samsung, etc., que potencialmente pueden acortar la relación con otras entidades relacionadas (como los teléfonos móviles producidos por Samsung, etc.).
marco modelo
En esta sección, presentaremos el marco de recomendación entre dominios previo al entrenamiento gráfico PEACE propuesto en este artículo. La siguiente figura muestra la arquitectura general de PEACE. En general, para lograr una mejor alineación entre dominios y utilizar mejor la información estructural en el gráfico de entidades, nuestro marco general se basa en el módulo de capacitación previa orientado a entidades para mejorar aún más la relación entre usuarios y entidades; módulo de preentrenamiento Representación para hacerlo más versátil y transferible, proponemos un módulo de mejora de representación de entidad basado en aprendizaje de contraste de prototipo y un módulo de mejora de representación de usuario basado en mecanismo de atención de mejora de prototipo para mejorar su representación, definimos Objetivos de optimización ; y proceso de implementación en línea liviano en la fase previa a la capacitación y la fase de ajuste . A continuación, presentaremos cada módulo uno por uno.
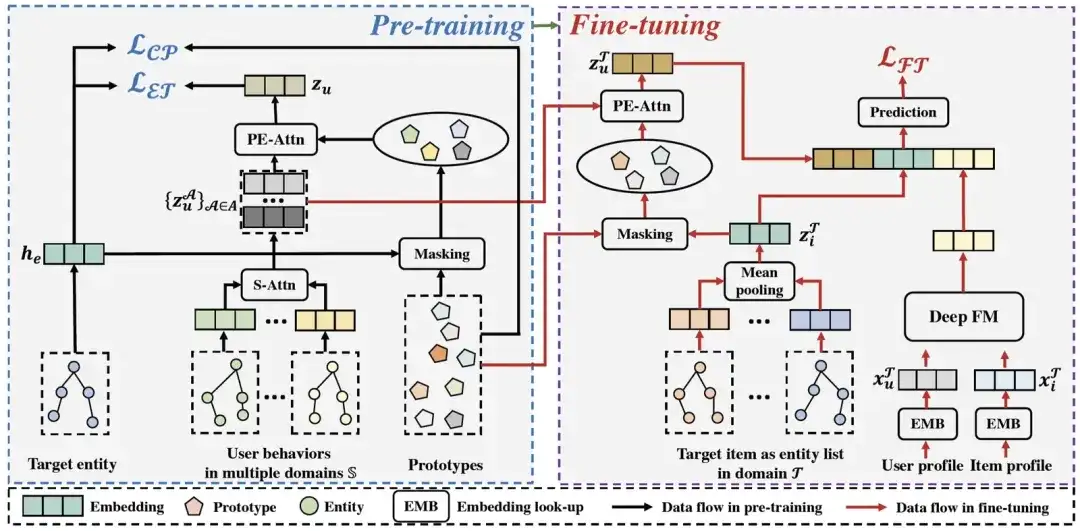
Arquitectura general de PAZ
01. Módulo de preformación orientado a entidades
Las plataformas de servicios en línea como Alipay reúnen una variedad de pequeños programas/escenarios proporcionados por diferentes proveedores de servicios. En términos generales, la información entre estos escenarios no es interoperable y, por lo tanto, no existe un sistema de datos compartido, incluso si son de la misma marca. categoría, los atributos de los productos actuales no se pueden alinear completamente (por ejemplo, el iPhone 14 vendido en diferentes mini programas tiene diferentes ID de producto y nombres de categoría. Por ejemplo, la categoría es productos electrónicos en un mini programa y la categoría es electrónica en otro mini programa). Para reducir las diferencias causadas por estos problemas potenciales y su impacto en el rendimiento del modelado, y al mismo tiempo hacer un mejor uso de esta información interactiva, realizamos un entrenamiento previo basado en el mapa de entidades, con la esperanza de introducir información granular de entidades en de esta manera lograr un preentrenamiento con una generalización más fuerte.


Tomando la Figura 1 como ejemplo, si es artículo → entidad → entidad, a partir de este producto, para Apple, solo podemos saber que sus productos relacionados son Teléfono, pero mediante el entrenamiento previo de entidad → entidad → entidad, podemos saber que Apple no solo tiene productos relacionados como Phone, también podemos saber que está relacionado con la empresa Samsung, mejorando así aún más la generalización de las representaciones que aprendimos).
02. Módulo de mejora de representación de entidades basado en prototipo de aprendizaje contrastivo

03. Módulo de mejora de la representación del usuario basado en un prototipo de mecanismo de atención mejorado
En la etapa de capacitación previa, los datos recopilados en el dominio de origen contienen el comportamiento del usuario en diferentes escenarios. Por ejemplo, al hacer planes de viaje, los usuarios visitarán escenarios relacionados con viajes y, cuando busquen trabajo, visitarán trabajos en línea. escenarios relacionados, sin embargo, la representación general del usuario aprendida en el paso anterior no tiene en cuenta el contexto relacionado con el usuario y la escena, lo que hace que sea imposible capturar la representación relacionada con la escena en diferentes escenas. utilizar el mecanismo de atención para mejorar el contexto. Captura para mejorar la representación del usuario.

04. Entrenamiento y predicción de modelos.
- Enlace de preformación del dominio de origen
Al combinar el módulo de preformación orientado a entidades y el módulo prototipo de mejora del aprendizaje, el objetivo de optimización general se puede definir de la siguiente manera:
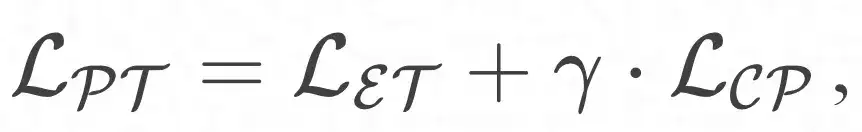

- Enlace de ajuste del dominio de destino

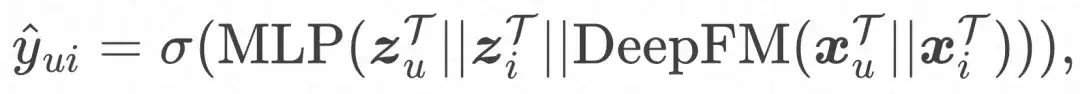
Y la función de pérdida final:
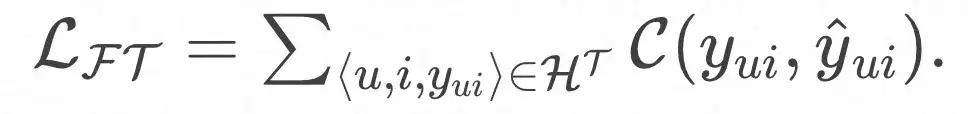

Implementación en línea
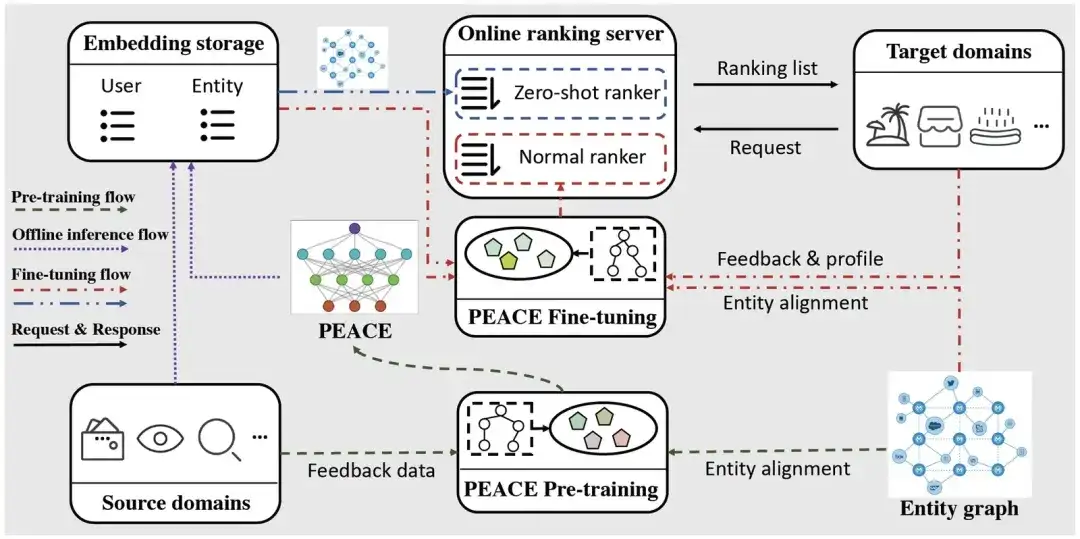
Para aliviar la presión sobre los servicios en línea, utilizamos un método liviano para implementar el modelo PEACE. El flujo de implementación se divide principalmente en tres partes:
- Flujo previo a la capacitación: con base en los datos de comportamiento de múltiples fuentes y los mapas de entidades recopilados, actualizamos el modelo PEACE diariamente para que el modelo pueda aprender conocimientos transferibles universales y urgentes. Para el modelo previamente entrenado, lo almacenamos en ModelHub para facilitar la carga ligera de los parámetros del modelo para uso posterior.
- Flujo de inferencia fuera de línea: para reducir la carga que la red neuronal gráfica trae al sistema de servicios en línea, inferiremos las representaciones del usuario y la entidad por adelantado y luego las almacenaremos en la tabla ODPS durante el ajuste fino posterior. el MLP final La red se ajusta sin rehacer el proceso de propagación de información en la red neuronal gráfica, lo que reduce en gran medida la latencia de los servicios en línea.
- Flujo de ajuste: dado que los miniprogramas/servicios recientemente lanzados no tienen datos interactivos, PEACE proporciona servicios de recomendación a través de los dos pasos siguientes:
- Para el escenario de inicio en frío, al hacer directamente el producto interno de las representaciones del usuario y del elemento, podemos obtener las preferencias del usuario por diferentes elementos y ordenarlos directamente;
- Para escenarios que no son de arranque en frío donde se ha acumulado una cierta cantidad de datos, realizamos ajustes en función de la representación de usuario/elemento previamente entrenado y la información básica del usuario/elemento, y luego utilizamos el modelo ajustado para servicios en línea.
Análisis de efectividad
Experimento sin conexión
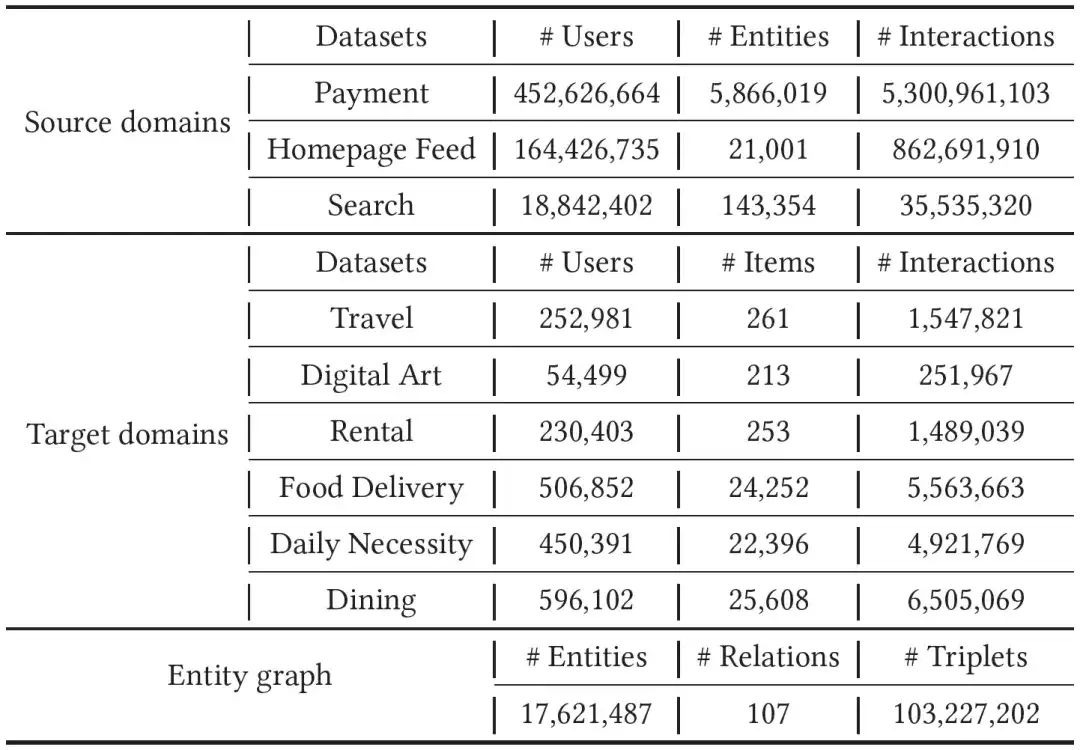
01. Introducción de datos
Recopilamos las facturas, huellas y datos de búsqueda de Alipay de un mes como datos del dominio de origen. Para el dominio de destino, realizamos experimentos en seis tipos de miniprogramas, a saber, alquiler, viajes, colecciones digitales, artículos de primera necesidad, comida gourmet y entrega de alimentos. Experimento, dado que los datos del dominio de destino son más escasos que los del dominio de origen, recopilamos datos de comportamiento en los últimos dos meses para el entrenamiento del modelo. Para salvar las enormes diferencias entre diferentes dominios, introdujimos un gráfico de entidades con decenas de millones de nodos, cientos de relaciones y miles de millones de aristas. Los datos específicos se pueden encontrar en la siguiente tabla.
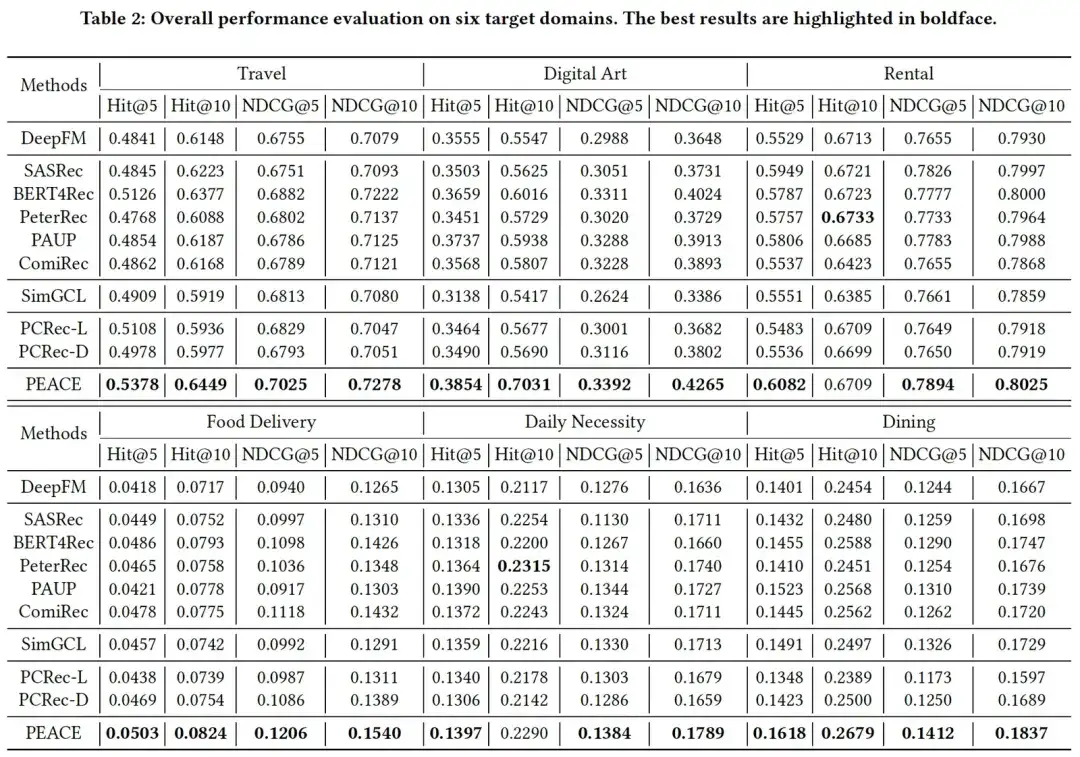
02. Experimento de eficacia
Combinando los resultados experimentales en las dos tablas podemos encontrar que, en general, los resultados experimentales muestran:
- PEACE ha logrado mejoras significativas en comparación con la línea de base en escenarios de arranque en frío y sin arranque en frío, lo que demuestra la efectividad de la combinación de preentrenamiento basado en granularidad de entidades y mecanismos de mejora basados en prototipos de aprendizaje;
- En la mayoría de los casos, el modelo previamente entrenado + ajustado tiene una mejora mayor que el DeepFM básico sin entrenamiento previo, lo que ilustra la efectividad de introducir datos de múltiples fuentes para el entrenamiento previo. Sin embargo, en algunos casos, algunos El rendimiento. del modelo no es tan bueno como el DeepFM de referencia, y hay un cierto grado de transferencia negativa, lo que ilustra aún más la importancia de los métodos de preentrenamiento;
- En muchos casos, los modelos de recomendación entre dominios basados en gnn no han logrado buenos resultados experimentales. Esto se debe en gran parte al gran ruido en el gráfico de entidades desde que introdujimos el aprendizaje de prototipos en el modelo PEACE, a través de la agrupación El método de clase crea entidades similares. tienen distancias similares en el espacio de representación, mientras que la distancia entre diferentes entidades se extiende más, aliviando así el impacto negativo de estos ruidos en el modelo.
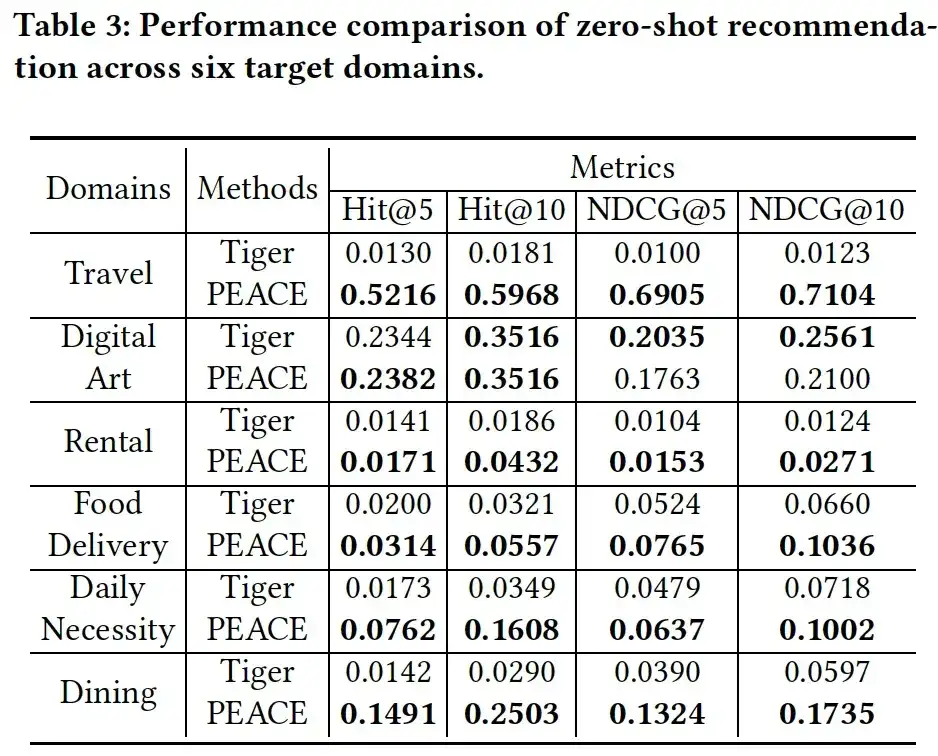
03. Análisis de ablación
Para verificar aún más el papel de cada módulo en el modelo PEACE, preparamos las siguientes tres variantes para evaluar la efectividad de cada módulo:
- PEACE w/o GL, el módulo de aprendizaje de gráficos cuando se eliminan las representaciones de entidades;
- PEACE sin CPL, es decir, eliminación del módulo de aprendizaje de prototipos basado en comparaciones;
- PEACE sin PEA, que elimina el módulo del mecanismo de atención basado en la mejora del prototipo. Como se puede ver en la Figura 4, cuando se elimina cualquier módulo, el rendimiento del modelo cae significativamente, lo que ilustra la indispensabilidad de cada módulo en el modelo. Además, se puede ver que el rendimiento de PEACE sin CPL en el peor de los casos; Esto ilustra la importancia del aprendizaje mediante prototipos para captar conocimientos generales transferibles.
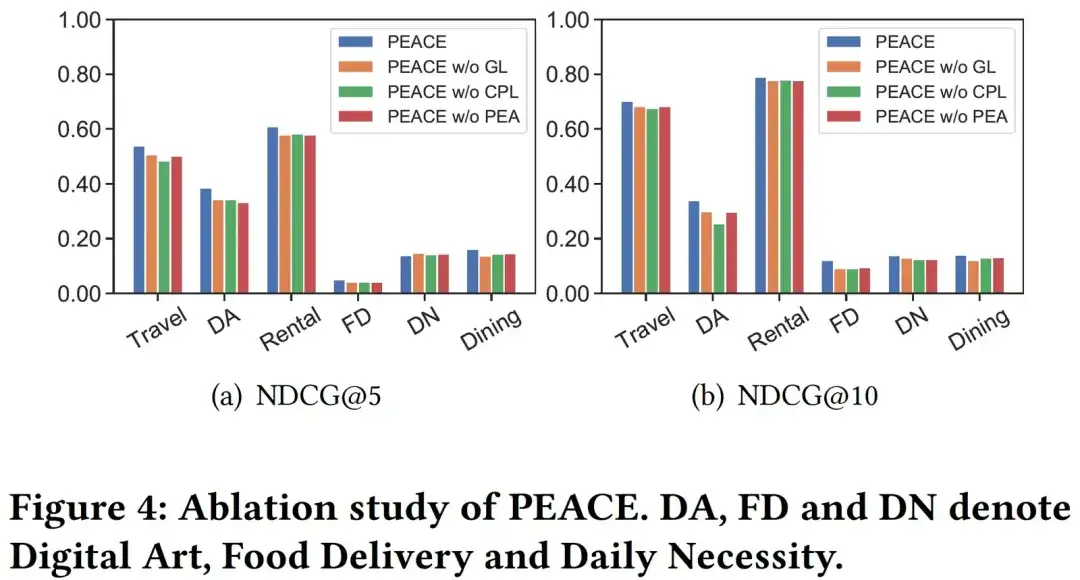
04. Análisis visual
Para analizar el efecto del módulo CPL de manera más explícita, seleccionamos aleatoriamente 6000 entidades en el mapa de entidades y sus representaciones de entidades aprendidas a través de los modelos PEACE sin CPL y PEACE para visualizarlas. Aquí hay varios Los colores corresponden a diferentes prototipos que pertenecen. a diferentes entidades. En la Figura 5 podemos ver que, en comparación con la representación de entidades aprendida por PEACE sin CPL, la representación aprendida por el modelo PEACE completo tiene una mejor coherencia en los resultados de agrupación, lo que ilustra el módulo CPL y su El prototipo aprendido puede ayudar a El modelo reduce la distancia entre entidades similares en el espacio de representación, lo que ayuda mejor al modelo a aprender un conocimiento más sólido y universal.
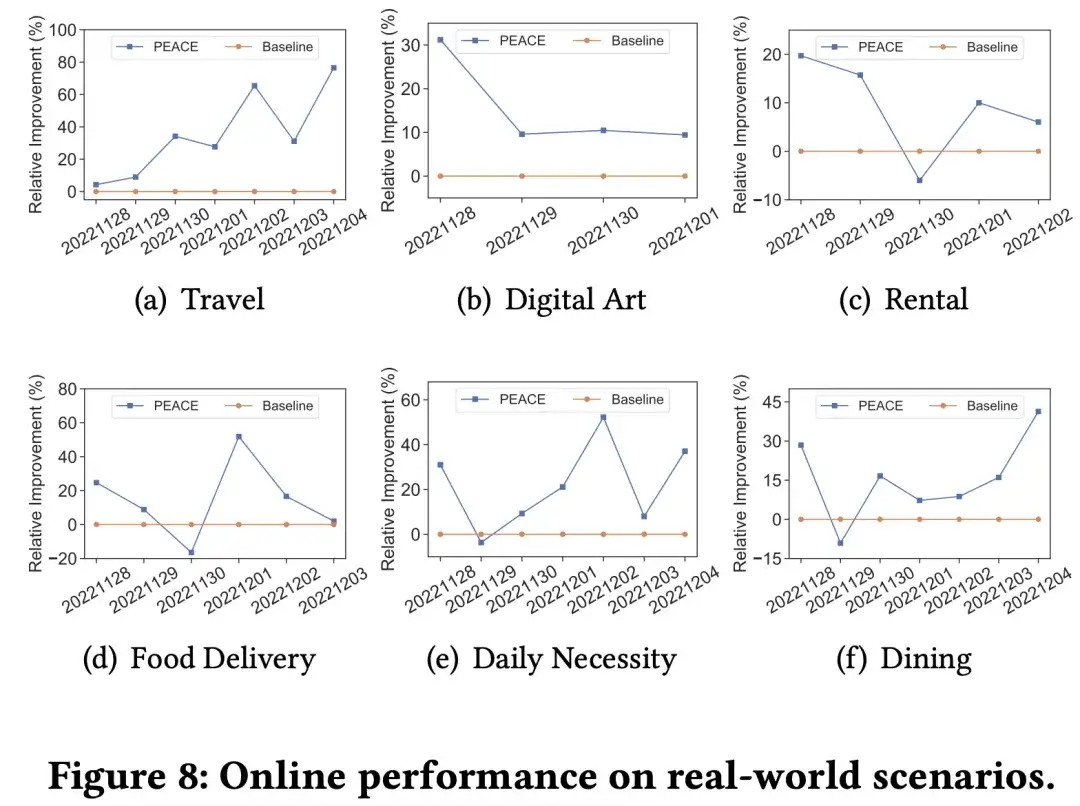
Experimentos en línea e implementación comercial.
Para verificar mejor el efecto del modelo en el entorno de producción real, hemos realizado experimentos AB en línea refinados en múltiples comerciantes en diferentes categorías verticales, en múltiples escenarios, el modelo PEACE ha logrado resultados efectivos en comparación con la promoción de referencia. En general, el modelo de recomendación de aprendizaje por transferencia + capacitación previa basado en PEACE se ha aplicado completamente como modelo de referencia a más de 50 comerciantes para brindar recomendaciones personalizadas después de haber sido verificado por efectos ab en comerciantes clave.
Recomendaciones de artículos
¡Se lanza OpenSPG v0.0.3, que agrega código abierto de extracción de conocimiento unificada y visualización de gráficos de modelos grandes! Ant Group y la Universidad de Zhejiang lanzan conjuntamente OneKE, un marco de extracción de conocimientos de modelos grandes de código abierto
Síganos
OpenSPG:
sitio web oficial: https://spg.openkg.cn
Github: https://github.com/OpenSPG/openspg
OpenASCE:
官网: https://openasce.openfinai.org/
GitHub: [https://github.com/Open-All-Scale-Causal-Engine/OpenASCE ]