
Todos son bienvenidos a destacarnos en GitHub:
Sistema distribuido de aprendizaje causal de enlace completo OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Gran gráfico de conocimiento basado en modelos OpenSPG: https://github.com/OpenSPG/openspg
Sistema de aprendizaje de gráficos a gran escala OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
¡Los días 25 y 26 de abril, se celebró la Conferencia Global de Tecnología de Aprendizaje Automático en el Hotel Hyatt Regency Global Harbour en Shanghai! Wang Qinlong, director de DLRover de código abierto en Ant Group, pronunció un discurso de apertura sobre "Autocuración de fallas de entrenamiento de DLRover: mejora significativa de la eficiencia de la potencia informática del entrenamiento de IA a gran escala" en la conferencia, y compartió cómo autocurarse rápidamente de fallas en operaciones de entrenamiento de modelos a gran escala de kilocalorías Wang Qinlong presentó los principios técnicos y los casos de uso detrás de DLRover, así como los efectos prácticos de DLRover en modelos comunitarios grandes.

Wang Qinlong, quien ha estado involucrado en la investigación y el desarrollo de la infraestructura de inteligencia artificial en Ant durante mucho tiempo, dirigió la construcción de los proyectos de tolerancia elástica a fallas y expansión y contracción automática de la capacitación distribuida de Ant. Ha participado en múltiples proyectos de código abierto, como ElasticDL y DLRover, un vibrante colaborador de código abierto de la Open Atomic Foundation en 2023 y un ingeniero destacado T-Star de Ant Group en 2022. Actualmente, es el arquitecto del proyecto de código abierto DLRover de Ant AI Infra, que se centra en la construcción de sistemas de formación distribuidos a gran escala estables, escalables y eficientes.
Entrenamiento y desafíos de modelos grandes.
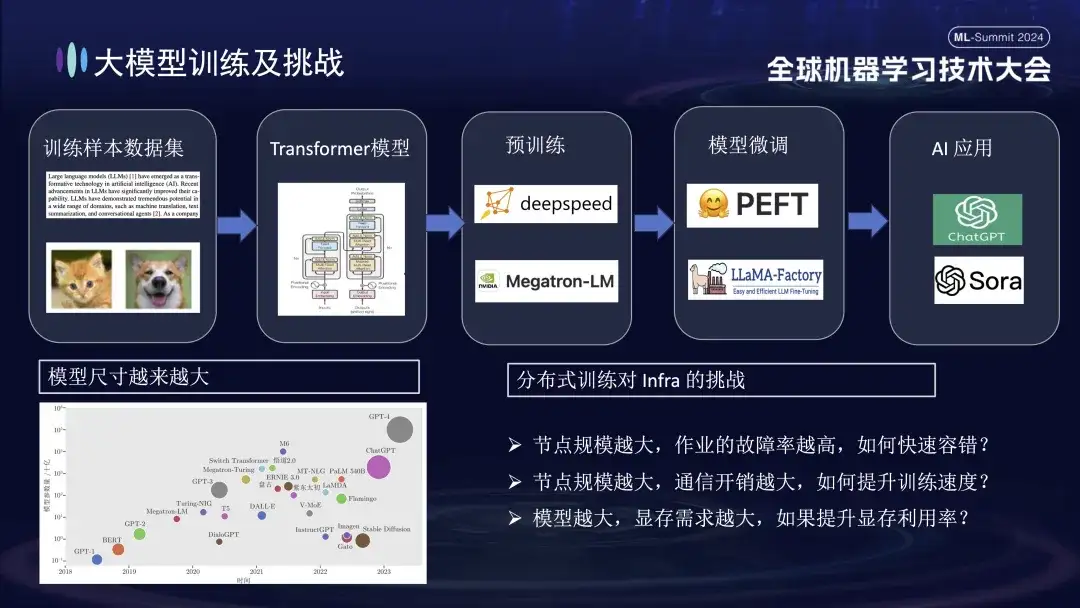
El proceso básico del entrenamiento de modelos grandes se muestra en la figura anterior. Requiere la preparación de conjuntos de datos de muestra de entrenamiento, la construcción del modelo Transformer, el entrenamiento previo, el ajuste fino del modelo y, finalmente, la construcción de una aplicación de IA de usuario. A medida que los modelos grandes pasan de mil millones de parámetros a un billón de parámetros, el crecimiento en la escala de capacitación ha provocado un aumento en los costos del clúster y también ha afectado la estabilidad del sistema. Los altos costos de operación y mantenimiento que trae consigo un sistema de tan gran escala se han convertido en un problema urgente que debe resolverse durante el entrenamiento de modelos grandes.
- Cuanto mayor sea el tamaño del nodo, mayor será la tasa de fallas en el trabajo. ¿Cómo tolerar fallas rápidamente ?
- Cuanto mayor sea el tamaño del nodo, mayor será la sobrecarga de comunicación. ¿Cómo mejorar la velocidad del entrenamiento ?
- Cuanto mayor sea el tamaño del nodo, mayor será el requisito de memoria. ¿Cómo mejorar la utilización de la memoria ?
Pila de tecnología de ingeniería Ant AI
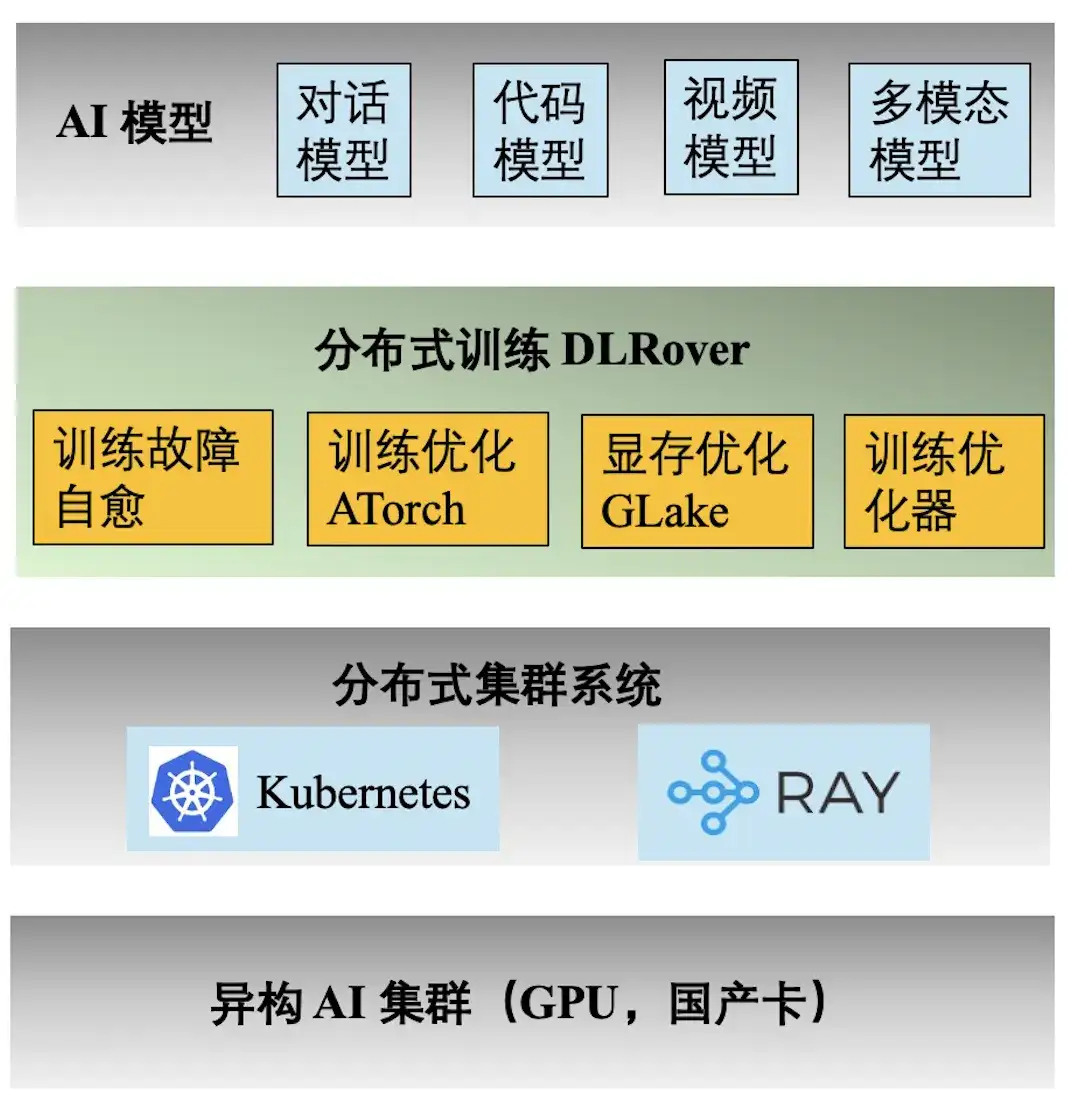
La figura anterior muestra la pila de tecnología de ingeniería del entrenamiento de Ant AI. El motor de entrenamiento distribuido DLRover admite una variedad de tareas de entrenamiento para el diálogo, el código, el video y los modelos multimodales de Ant. Las siguientes son las características principales proporcionadas por DLRover:
- **Autocuración de fallas de entrenamiento:** Incrementar el tiempo efectivo del entrenamiento distribuido de kilocalorías a >97%, reduciendo el costo de la potencia de cálculo de las fallas de entrenamiento a gran escala;
- **Optimización de entrenamiento ATorch:** Seleccione automáticamente la estrategia de entrenamiento distribuida óptima según el modelo y el hardware. Aumentar la tasa de utilización de la potencia informática del hardware del clúster Kcal (A100) a >60%;
- **Optimizador de entrenamiento:** El optimizador es equivalente a la navegación de la iteración del modelo, lo que puede ayudarnos a lograr el objetivo en el camino más corto. Nuestro optimizador mejora la aceleración de la convergencia 1,5 veces en comparación con AdamW. Los resultados relevantes se publicaron en ECML PKDD '21, KDD'23, NeurIPS '23;
- ** Memoria de video y optimización de transmisión GLake: ** Durante el proceso de entrenamiento de modelos grandes, se generarán muchos fragmentos de memoria de video, lo que reduce en gran medida la utilización de recursos de memoria de video. Reducimos los requisitos de memoria de entrenamiento entre 2 y 10 veces mediante la memoria integrada + optimización de transmisión y la optimización de la memoria global. Los resultados se publicaron en ASPLOS'24.
Por qué los fallos provocan un desperdicio de potencia informática
La razón por la que Ant presta especial atención al problema de las fallas en la capacitación es principalmente porque las fallas de las máquinas durante el proceso de capacitación aumentan significativamente el costo de la capacitación. Por ejemplo, Meta anunció los datos reales para el entrenamiento de su modelo grande en 2022. Al entrenar el modelo OPT-175B, utilizó 992 GPU A100 de 80 GB, un total de 124 máquinas de 8 tarjetas, según los precios de GPU de AWS, cuesta alrededor de 700.000. por día. . Debido al fallo, el ciclo de formación se extendió más de 20 días, aumentando así el coste de la potencia informática en decenas de millones de yuanes.

La siguiente imagen muestra la distribución de las fallas encontradas al entrenar modelos grandes en clústeres de Alibaba Cloud. Algunas de estas fallas se pueden resolver reiniciando, mientras que otras no se pueden reparar reiniciando. Por ejemplo, el problema de la caída de la tarjeta, porque la tarjeta defectuosa todavía está dañada después de reiniciar. La máquina dañada debe reemplazarse antes de que se pueda reiniciar y restaurar el sistema.
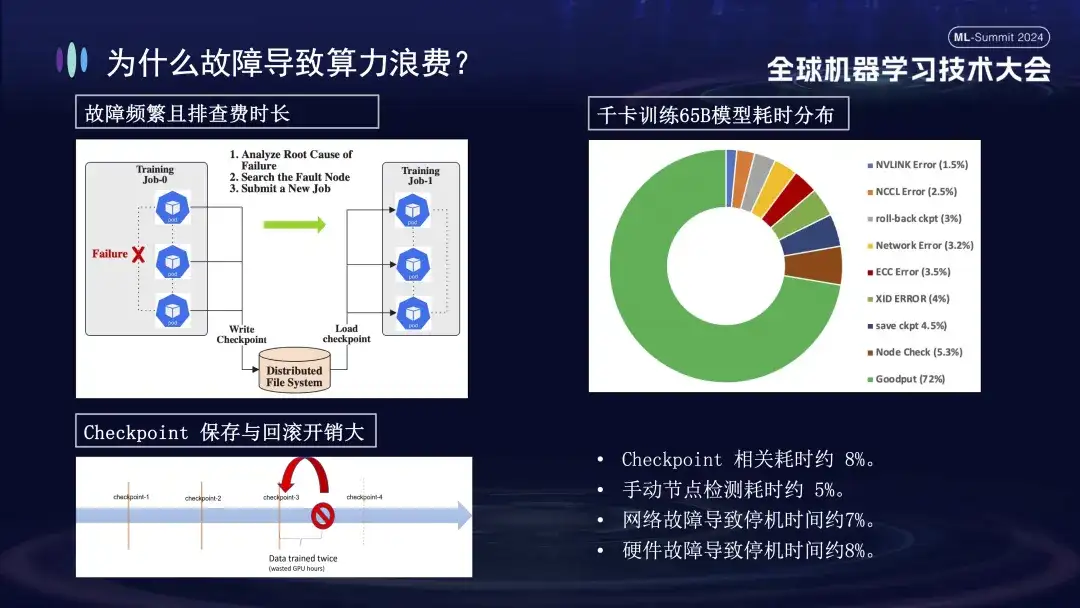
¿Por qué los fracasos en el entrenamiento tienen un impacto tan grande? En primer lugar, la capacitación distribuida requiere que varios nodos trabajen juntos. Si algún nodo falla (ya sea un problema de software, hardware, tarjeta de red o GPU), se debe suspender todo el proceso de capacitación. En segundo lugar, después de que se produce una falla en la capacitación, la resolución de problemas requiere mucho tiempo y es laboriosa. Por ejemplo, el método de inspección manual comúnmente utilizado ahora requiere al menos 1 o 2 horas para realizar una verificación. Finalmente, el entrenamiento tiene estado. Para reiniciar el entrenamiento, debe recuperarse del estado de entrenamiento anterior antes de continuar, y el estado de entrenamiento debe guardarse después de un período de tiempo. El proceso de guardar lleva mucho tiempo y la reversión de fallas también provocará un desperdicio de cálculos. La imagen de arriba a la derecha muestra la distribución del tiempo de entrenamiento antes de conectarnos para realizar la autocuración. Se puede ver que el tiempo relevante de Checkpoint es aproximadamente el 8%, el tiempo de detección manual de nodos es aproximadamente el 5% y el tiempo de inactividad causado. por fallas de red es aproximadamente el 7%, las fallas de hardware causan aproximadamente el 8% del tiempo de inactividad y el tiempo de capacitación efectivo final es solo aproximadamente el 72%.
Descripción general de las funciones de autorreparación de fallas de entrenamiento de DLRover

La imagen de arriba muestra las dos funciones principales de DLRover en la tecnología de autorreparación de fallas. En primer lugar, Flash Checkpoint puede guardar rápidamente el estado sin detener el proceso de capacitación y lograr una copia de seguridad de alta frecuencia. Esto significa que, en caso de falla, el sistema puede recuperarse inmediatamente desde el punto de control más reciente, lo que reduce la pérdida de datos y el tiempo de capacitación. En segundo lugar, DLRover utiliza Kubernetes para implementar un mecanismo de programación elástica inteligente. Este mecanismo puede responder automáticamente a fallas de nodos. Por ejemplo, si uno falla en un grupo de 100 máquinas, el sistema se ajustará automáticamente a 99 máquinas para continuar el entrenamiento sin intervención manual. Además, es compatible con Kubeflow y PyTorchJob, y fortalece las capacidades de monitoreo del estado del nodo para garantizar que cualquier falla se identifique rápidamente y se responda en 10 minutos, manteniendo la continuidad y estabilidad de las operaciones de capacitación.
Entrenamiento de tolerancia a fallas elástica DLRover
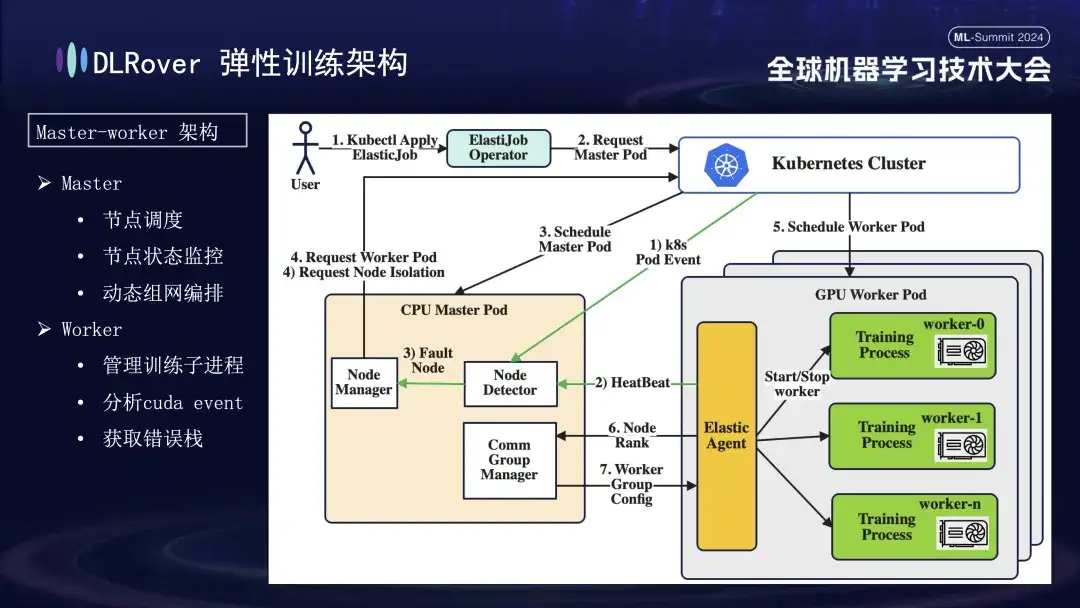
DLRover adopta una arquitectura maestro-trabajador, que no era común en los primeros días del aprendizaje automático. En este diseño, el maestro actúa como centro de control y es responsable de tareas clave como la programación de nodos, el monitoreo del estado, la gestión de la configuración de la red y el análisis del registro de fallas, sin ejecutar el código de capacitación. Generalmente implementado en nodos de CPU. Los trabajadores soportan la carga de entrenamiento real y cada nodo ejecutará múltiples subprocesos para utilizar las múltiples GPU del nodo para acelerar las tareas informáticas. Además, para mejorar la solidez del sistema, hemos personalizado y mejorado el Agente Elástico en el trabajador para permitir una detección y localización de fallas más efectiva, garantizando estabilidad y eficiencia durante el proceso de capacitación.
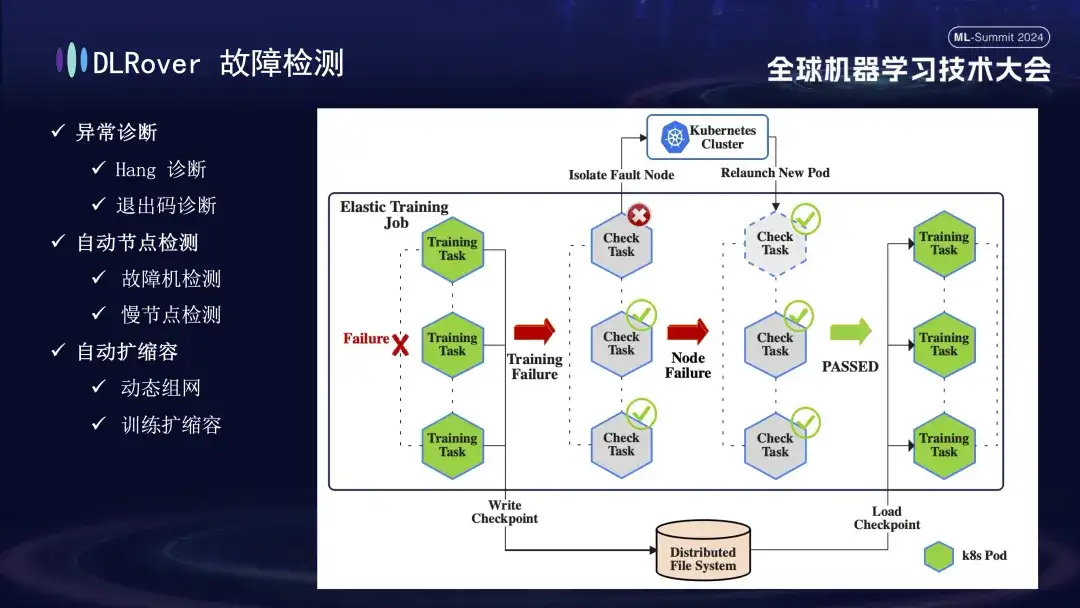
El siguiente es el proceso de detección de fallas. Cuando ocurre una falla durante el proceso de capacitación y se interrumpe la tarea, la interpretación intuitiva es que la capacitación se suspende, pero la causa específica y el origen de la falla no son directamente evidentes, porque una vez que ocurre una falla, todas las máquinas relacionadas se detendrán simultáneamente. . Para resolver este problema, ejecutamos inmediatamente el script de detección en todas las máquinas después de que ocurrió la falla. Una vez que se detecta que un nodo no pasa la inspección, se notificará inmediatamente al clúster de Kubernetes para que elimine el nodo fallido y vuelva a implementar un nuevo nodo de reemplazo. El nuevo nodo completa más comprobaciones de estado con los nodos existentes. Una vez que todo está correcto, la tarea de capacitación se reinicia automáticamente. Vale la pena señalar que si un nodo defectuoso está aislado y causa recursos insuficientes, implementaremos una estrategia de reducción (se presentará en detalle más adelante). Cuando la máquina defectuosa original vuelva a la normalidad, el sistema realizará automáticamente operaciones de expansión de capacidad para garantizar una capacitación eficiente y continua.
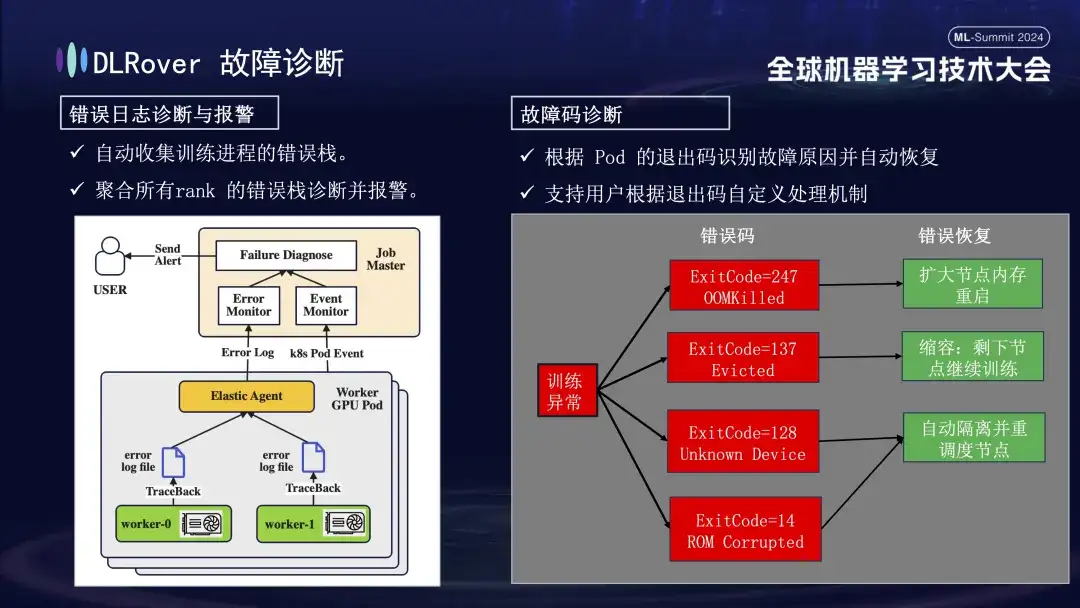
El siguiente es el proceso de diagnóstico de fallas, que utiliza los siguientes métodos integrales para lograr una localización y procesamiento de fallas rápidos y precisos:
- Primero, el Agente recopila información de errores de cada proceso de capacitación y resume estas pilas de errores en el nodo maestro. Luego, el nodo maestro analiza los datos de error agregados para identificar la máquina con el problema. Por ejemplo, si un registro de la máquina muestra un error ECC, la falla de la máquina se determina y elimina directamente.
- Además, el código de salida de Kubernetes también se puede utilizar para ayudar en el diagnóstico. Por ejemplo, el código de salida 137 normalmente indica que la plataforma informática subyacente finaliza la máquina debido a un problema detectado; el código de salida 128 significa que el dispositivo no se reconoce; El controlador de la GPU puede estar defectuoso. También hay una gran cantidad de fallas que no se pueden detectar mediante códigos de salida. Las más comunes incluyen tiempos de espera de fluctuación de la red.
- También hay muchas fallas, como tiempos de espera causados por fluctuaciones de la red, que no pueden identificarse únicamente con códigos de salida. Adoptaremos una estrategia más general: independientemente de la naturaleza específica de la falla, el objetivo principal es identificar y eliminar rápidamente el nodo defectuoso y luego notificar al maestro para que detecte específicamente dónde radica el problema.
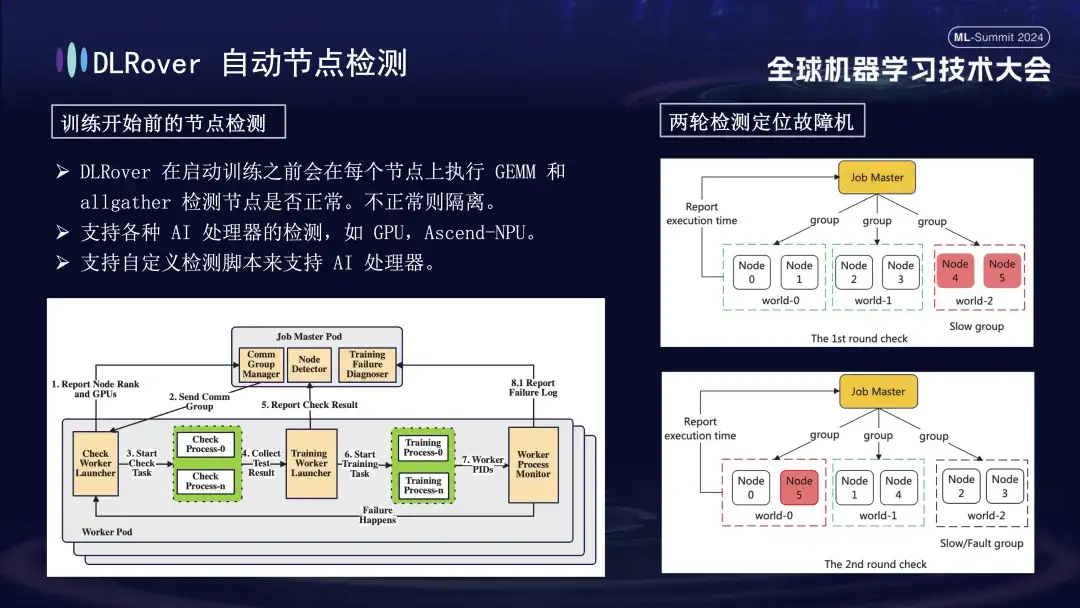
Primero, la multiplicación de matrices se realiza en todos los nodos. Posteriormente, los nodos se emparejan y agrupan. Por ejemplo, en un Pod con 6 nodos, los nodos se dividen en tres grupos (0,1), (2,3) y (4,5), y se realiza la detección de comunicación de AllGather. realizado. Si hay una falla de comunicación entre 4 y 5, pero la comunicación en otros grupos es normal, se puede concluir que la falla existe en el nodo 4 o 5. A continuación, el nodo sospechoso defectuoso se repara con el nodo normal conocido para realizar pruebas adicionales, por ejemplo, combinando 0 y 5 para la detección. Al comparar los resultados, se identifica con precisión el nodo defectuoso. Este proceso de inspección automatizado diagnostica con precisión una máquina defectuosa en diez minutos.
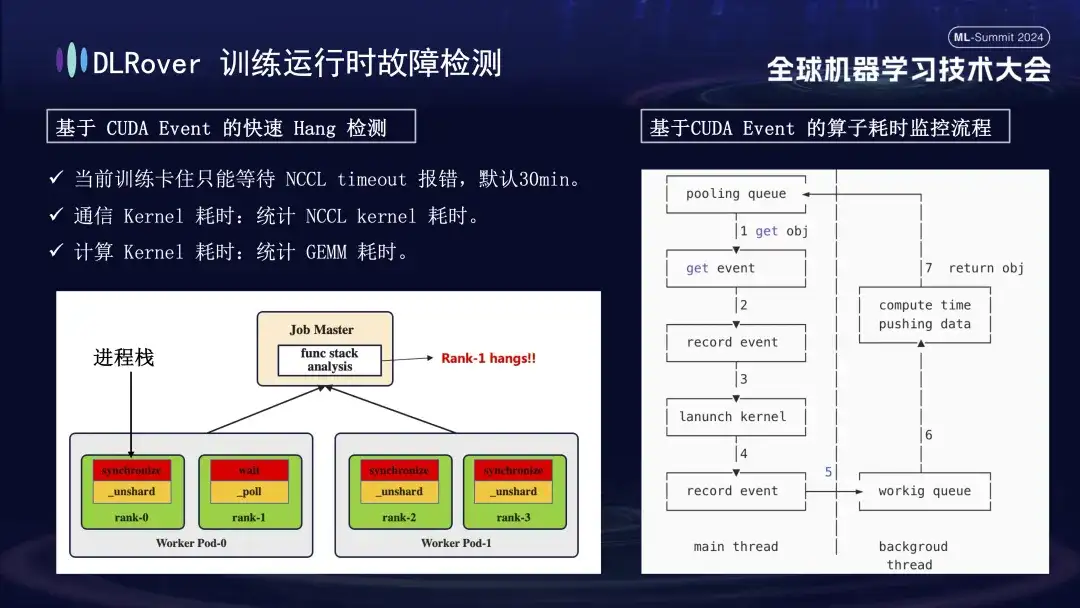
La situación de interrupción del sistema y detección de fallas se ha discutido anteriormente, pero es necesario resolver el problema de identificar la máquina atascada. El tiempo de espera predeterminado establecido por NCCL es de 30 minutos, lo que permite retransmitir datos para reducir los falsos positivos. Sin embargo, esto puede hacer que cada tarjeta espere 30 minutos en vano cuando en realidad está atascada, lo que genera enormes pérdidas acumulativas. Para diagnosticar con precisión el atasco, se recomienda utilizar una herramienta de creación de perfiles refinada. Cuando se detecta que el programa está en pausa, por ejemplo, no hay cambios en la pila del programa en un minuto, se registra la información de la pila de cada tarjeta y se comparan y analizan las diferencias. Por ejemplo, si se descubre que 3 de 4 rangos realizan la operación de sincronización y 1 realiza la operación de espera, puede localizar un problema con el dispositivo. Además, secuestramos el núcleo de comunicación clave de CUDA y el núcleo informático, insertamos monitoreo de eventos antes y después de su ejecución y juzgamos si la operación se estaba ejecutando normalmente calculando el intervalo de eventos. Por ejemplo, si una determinada operación no se completa dentro de los 30 segundos esperados, se puede considerar como bloqueada y los registros y pilas de llamadas relevantes se generarán automáticamente y se enviarán al maestro para compararlos y localizar rápidamente la máquina defectuosa.
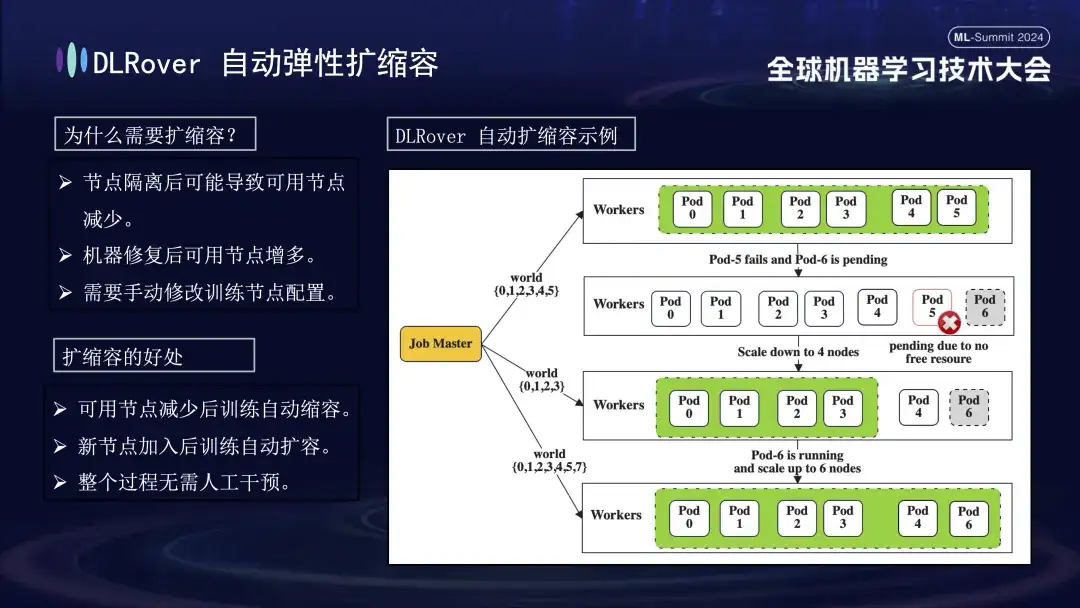
Una vez identificada la máquina defectuosa, considerando el costo y la eficiencia, aunque hubo un mecanismo de respaldo en la capacitación previa, el número fue limitado. En este momento, es particularmente importante introducir una estrategia de expansión y contracción elástica. Supongamos que el clúster original tiene 100 nodos. Una vez que falla un nodo, los 99 nodos restantes pueden continuar con la tarea de capacitación después de que se repara el nodo fallido, el sistema puede reanudar automáticamente la operación en 100 nodos y este proceso no requiere intervención manual. garantizar un entorno de formación eficiente y estable.
Punto de control de flash DLRover
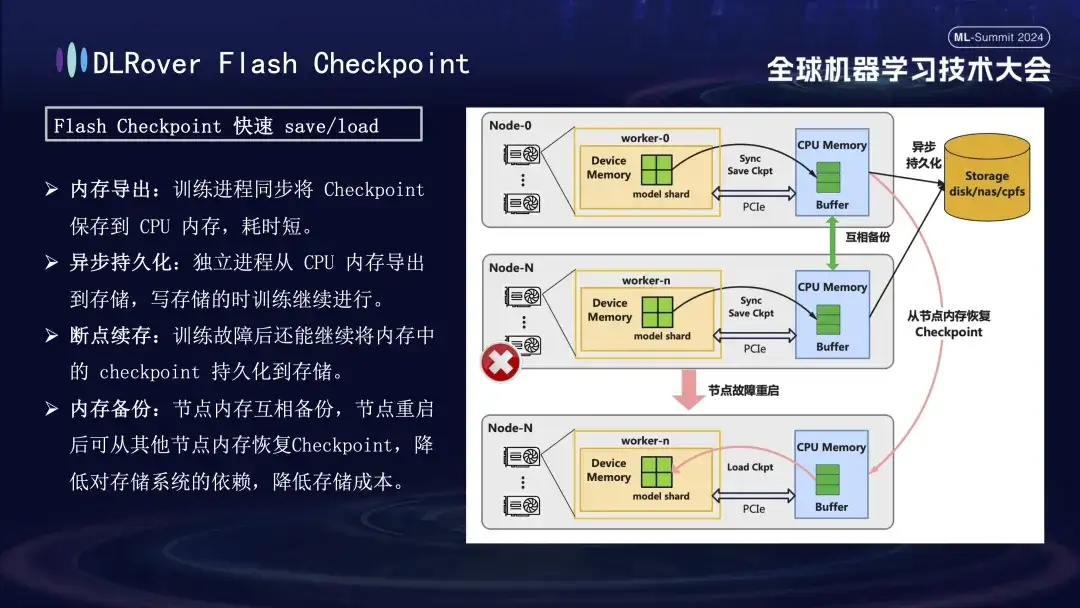
En el proceso de recuperación de fallas de entrenamiento, la clave es guardar y restaurar el estado del modelo. El método tradicional Checkpoint a menudo conduce a una baja eficiencia de la capacitación debido al gran ahorro de tiempo. Para resolver este problema, DLRover propuso de manera innovadora la solución Flash Checkpoint, que puede exportar el estado del modelo desde la memoria de la GPU a la memoria casi en tiempo real durante el proceso de entrenamiento. También se complementa con un mecanismo de copia de seguridad entre memorias para garantizar que incluso si. un nodo falla, puede restaurar rápidamente el estado de entrenamiento desde la memoria del nodo de respaldo, lo que acorta en gran medida el tiempo de recuperación de fallas. Para el Megatron-LM de uso común, el proceso de exportación de Checkpoint requiere un proceso centralizado para coordinar y completar, lo que no solo introduce una carga de comunicación y un consumo de memoria adicionales, sino que también resulta en mayores costos de tiempo. DLRover ha adoptado un enfoque innovador después de la optimización, utilizando una estrategia de exportación distribuida para que cada nodo informático (rango) pueda guardar y cargar de forma independiente su propio punto de control, evitando así de manera efectiva requisitos adicionales de comunicación y memoria y mejorando en gran medida la eficiencia.
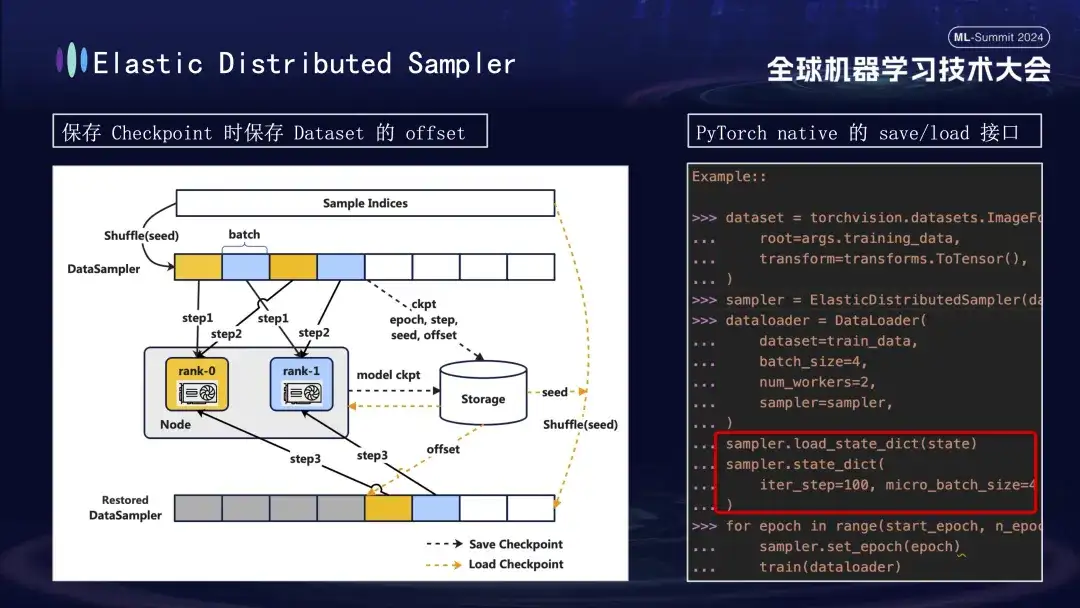
Al crear el modelo Checkpoint, hay otro detalle al que vale la pena prestar atención. El entrenamiento del modelo se basa en datos, asumiendo que guardamos el Checkpoint en el paso 1000 del proceso de entrenamiento. Si el entrenamiento se reinicia más tarde sin considerar el progreso de los datos, volver a consumir datos directamente desde cero generará dos problemas: es posible que se pierdan datos nuevos posteriores y que se puedan reutilizar los datos anteriores. Para resolver este problema, introdujimos la estrategia Distributed Sampler. Al guardar el punto de control, esta estrategia no solo registra el estado del modelo, sino que también guarda la posición de desplazamiento de la lectura de datos. De esta manera, al cargar el punto de control para reanudar el entrenamiento, el conjunto de datos continuará cargándose desde el punto de compensación previamente guardado y luego avanzará en el entrenamiento, asegurando así la continuidad y coherencia de los datos de entrenamiento del modelo y evitando errores de datos o procesamiento repetido. .
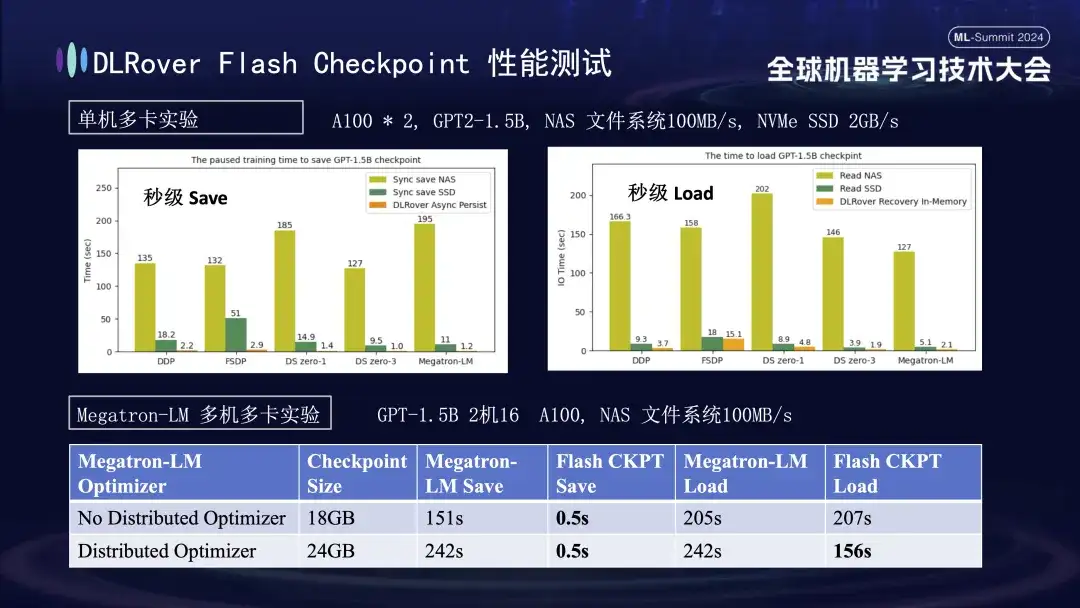
En el gráfico anterior, mostramos los resultados experimentales en un entorno de múltiples GPU (A100) de una sola máquina, con el objetivo de comparar el impacto de diferentes soluciones de almacenamiento en el tiempo de bloqueo causado por el ahorro de Checkpoint durante el proceso de capacitación. Los experimentos muestran que el rendimiento del sistema de almacenamiento afecta directamente la eficiencia: cuando se utiliza un método de almacenamiento menos eficiente para escribir puntos de control directamente en el disco, el entrenamiento se bloqueará significativamente y el tiempo se extenderá. Específicamente, para un Checkpoint modelo 1.5B con un tamaño de aproximadamente 20 GB, si se utiliza almacenamiento NAS, el tiempo de escritura es de aproximadamente 2 a 3 minutos, adoptando una estrategia de optimización, es decir, el almacenamiento temporal asincrónico de los datos en la memoria puede acortarse considerablemente; el tiempo. Este proceso solo toma alrededor de 1 segundo en promedio, lo que mejora significativamente la continuidad y eficiencia del entrenamiento.

La función Flash Checkpoint de DLRover es ampliamente compatible con los principales marcos de entrenamiento de modelos grandes, incluidos DDP, FSDP, DeepSpeed, Megatron-LM, transformadores.Trainer y Ascend-DDP. Tiene API personalizadas para cada marco para garantizar una flexibilidad de uso extremadamente fácil para los usuarios. Rara vez es necesario ajustar el código de capacitación existente, funciona de inmediato. Específicamente, los usuarios del marco DeepSpeed solo necesitan llamar a la interfaz de guardado de DLRover al ejecutar Checkpoint, mientras que la integración de Megatron-LM es aún más simple. Solo necesitan reemplazar la declaración de importación nativa de Checkpoint con el método de importación proporcionado por DLRover. . Poder.
Práctica de entrenamiento distribuido DLRover
Realizamos una serie de experimentos para cada escenario de falla para evaluar la tolerancia a fallas del sistema, la capacidad para manejar nodos lentos y la flexibilidad para escalar hacia arriba y hacia abajo. Los experimentos específicos son los siguientes:
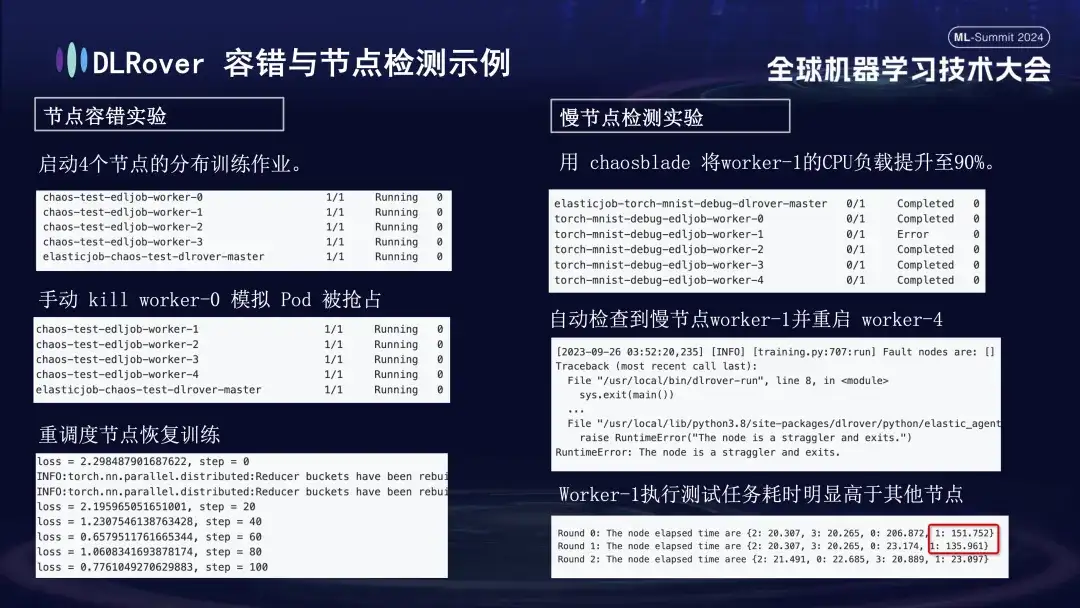
- Experimento de tolerancia a fallas de nodos: apague manualmente algunos nodos para probar si el clúster puede recuperarse rápidamente;
- Experimento de nodo lento: utilice la herramienta Chaosblade para aumentar la carga de CPU del nodo al 90% para simular una situación de nodo lento que requiere mucho tiempo;
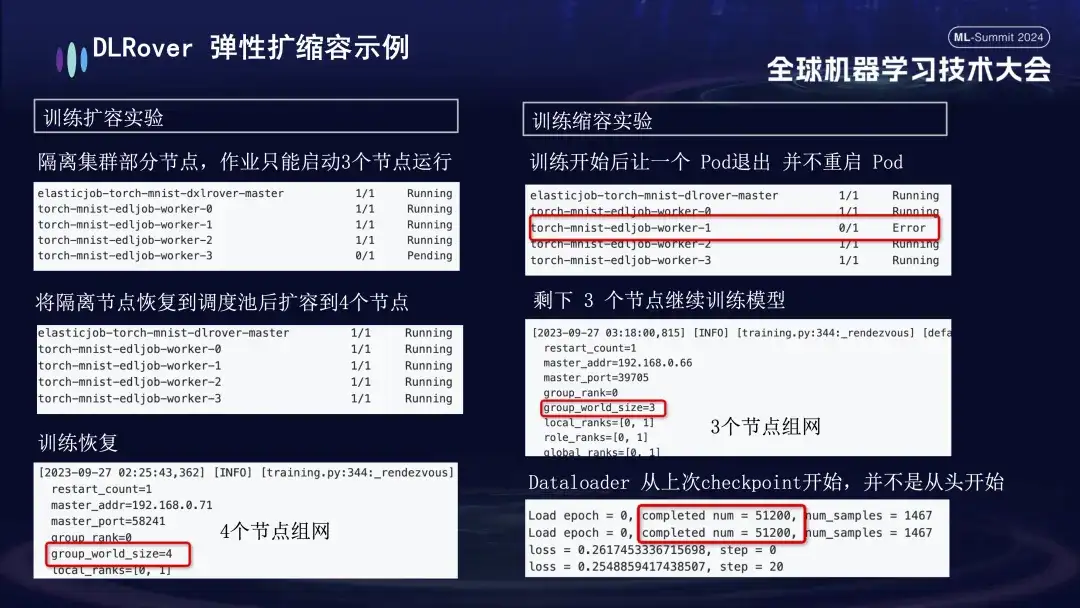
- Experimento de expansión y contracción: simula un escenario en el que los recursos de la máquina son escasos. Por ejemplo, si un trabajo está configurado con 4 nodos, pero en realidad solo se inician 3, estos 3 nodos aún se pueden entrenar normalmente. Después de un período de tiempo, simulamos aislar un nodo y la cantidad de Pods disponibles para entrenamiento se redujo a 3. Cuando esta máquina regresa a la cola de programación, la cantidad de Pods disponibles se puede aumentar a 4. En este momento, el cargador de datos continuará entrenando desde el último punto de control en lugar de comenzar de nuevo.
La práctica de DLRover en tarjetas nacionales.
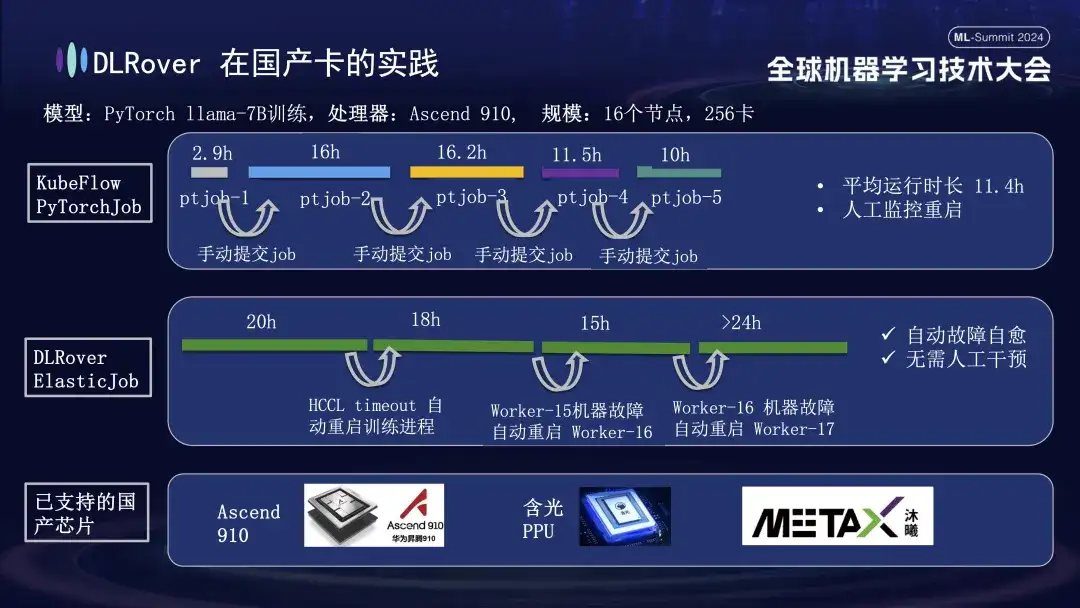
Además de admitir GPU, la autorreparación de fallas de DLRover también admite el entrenamiento distribuido de tarjetas aceleradoras domésticas. Por ejemplo, cuando ejecutamos el modelo LLama-7B en la plataforma Huawei Ascend 910, utilizamos 256 tarjetas para entrenamiento a gran escala. Al principio, usamos PyTorchJob de KubeFlow, pero esta herramienta no tenía tolerancia a fallas, lo que provocó que el proceso de capacitación finalizara automáticamente después de unas diez horas. Una vez que esto sucedió, el usuario tuvo que volver a enviar la tarea manualmente; inactivo. El segundo diagrama muestra todo el proceso de entrenamiento con la autorreparación de fallas de entrenamiento habilitada. Cuando la capacitación avanzó durante 20 horas, se produjo una falla en el tiempo de espera de comunicación. En ese momento, el sistema reinició automáticamente el proceso de capacitación y reanudó la capacitación. Aproximadamente cuarenta horas después, se encontró una falla en el hardware de la máquina. El sistema aisló rápidamente la máquina defectuosa y reinició un módulo para continuar con el entrenamiento. Además de admitir Huawei Ascend 910, también somos compatibles con la PPU Hanguang de Alibaba y cooperamos con Muxi Technology para utilizar DLRover para entrenar el modelo LLAMA2-65B en su GPU Qianka desarrollada de forma independiente.
DLR Práctica de entrenamiento de más de 1000 tarjetas y 100 mil millones de modelos
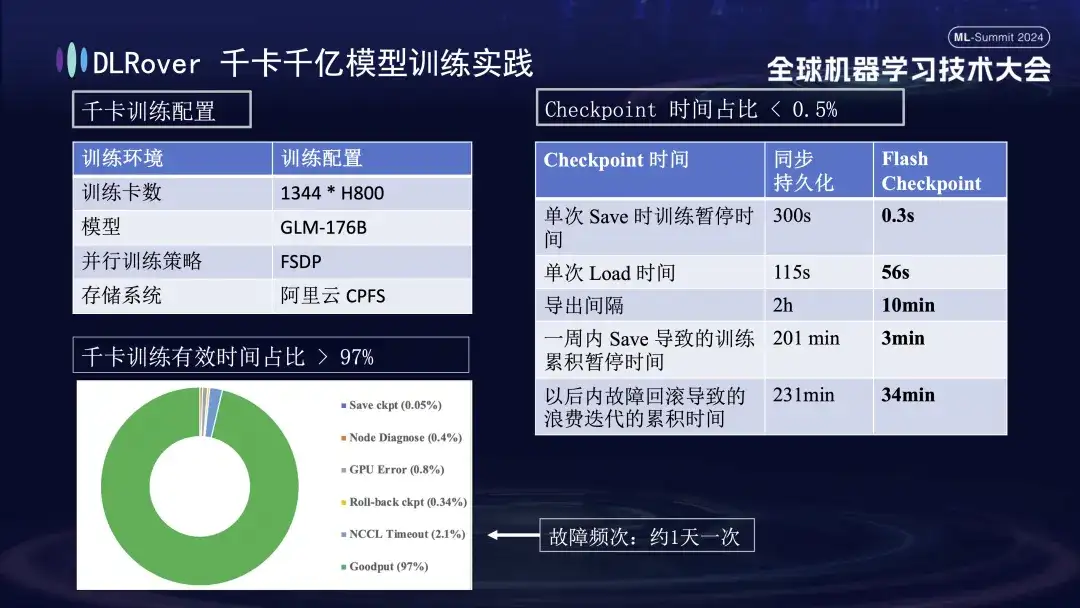
La figura anterior muestra el efecto práctico de la autocuración de fallas de entrenamiento de DLRover en el entrenamiento de kilotarjetas: se utilizan más de 1,000 tarjetas H800 para ejecutar el entrenamiento de modelos a gran escala. Cuando la frecuencia de fallas es una vez al día, después de la autocuración de fallas de entrenamiento. Se introduce la función curativa, el tiempo de entrenamiento efectivo representa más del 97%. La tabla de comparación a la derecha muestra que cuando se utiliza el FSDP de almacenamiento de alto rendimiento de Alibaba Cloud, un solo guardado todavía demora unos cinco minutos, mientras que nuestra tecnología Flash Checkpoint solo demora 0,3 segundos en completarse. Además, gracias a la optimización, la eficiencia del nodo se ha mejorado en casi un minuto. En términos de intervalo de exportación, la operación de exportación se realizaba originalmente cada 2 horas, pero después de iniciar la función Flash Checkpoint, se puede lograr una exportación de alta frecuencia cada 10 minutos. El tiempo acumulado dedicado a las operaciones de guardado en una semana es casi insignificante. Al mismo tiempo, el tiempo de reversión se reduce aproximadamente 5 veces en comparación con antes.
Plan DLRover y construcción de comunidad

DLRover ha lanzado actualmente tres versiones principales. Se espera que lance V0.4.0 en junio, que lanzará la detección de fallas en tiempo de ejecución basada en CUDA Event.
- V0.1.0 (2023/07): Tolerancia elástica a fallas y expansión y contracción automática de TensorFlow PS en k8s/ray;
- V0.2.0 (2023/09): Detección de nodos y tolerancia elástica a fallas para entrenamiento sincrónico de PyTorch en k8;
- V0.3.5(2024/03): Flash Checkpoint y detección de fallas en tarjetas domésticas;
En términos de planificación futura, DLRover continuará optimizando y mejorando las funciones de DLRover en los aspectos de programación y gestión de nodos, compilación y optimización de lynx, marco de optimización de capacitación AToch y capacitación de tarjetas nacionales:
- **Programación y gestión de nodos: **Programación basada en la topología de la comunicación, que reduce el tráfico de comunicación de los conmutadores de nivel superior durante la comunicación AllReduce basada en anillo; recopilación de métricas y predicción de fallas;
- ** Optimización de la compilación Lynx: ** Optimización de la programación del gráfico de cálculo, logrando una superposición óptima de comunicación y cálculo, ocultando el retraso de la comunicación en el entrenamiento distribuido automático de SPMD;
- **Marco de optimización de entrenamiento ATorch: **Optimización de entrenamiento RLHF; aceleración de inicialización de entrenamiento distribuido configuración de aceleración de entrenamiento auto_accelerate;
- **Capacitación con tarjetas nacionales: **Ampliar funciones como la autocuración de fallas y la aceleración del entrenamiento a tarjetas nacionales proporciona mejores prácticas para la capacitación con tarjetas nacionales;

El progreso tecnológico comienza con la colaboración abierta. Todos son bienvenidos a seguir y participar en nuestros proyectos de código abierto en GitHub.
DLRover:
https://github.com/intelligent-machine-learning/dlrover
GLAKE:
https://github.com/intelligent-machine-learning/glake
Nuestra cuenta pública de WeChat "AI Infra" también publicará periódicamente artículos técnicos de vanguardia sobre infraestructura de IA, con el objetivo de compartir los últimos resultados de investigación y conocimientos técnicos. Al mismo tiempo, para promover mayores intercambios y debates, también hemos creado un grupo DingTalk. Todos pueden unirse y hacer preguntas y discutir cuestiones técnicas relacionadas aquí. ¡gracias a todos!
Recomendaciones de artículos
