

Aunque los cachés externos son excelentes para reducir la latencia, a menudo causan más problemas que beneficios. A continuación se explica cómo solucionar este problema.
Traducido de Por qué y cómo los equipos están reemplazando las cachés de bases de datos externas por Felipe Cardeneti Mendes.
Los equipos a menudo consideran el almacenamiento en caché externo cuando una base de datos existente no puede cumplir con el acuerdo de nivel de servicio (SLA) requerido. Se trata de una decisión decididamente orientada al rendimiento. A menudo se coloca una memoria caché externa delante de la base de datos para compensar la latencia subóptima causada por diversos factores (por ejemplo, componentes internos de la base de datos ineficientes, uso de controladores, opciones de infraestructura, picos de tráfico, etc.).
El almacenamiento en caché parece ser una solución rápida y sencilla, ya que la implementación se puede implementar sin grandes complicaciones y sin incurrir en costos significativos de expansión de la base de datos , rediseño del esquema de la base de datos o incluso conversiones tecnológicas más profundas. Sin embargo, el almacenamiento en caché externo no es tan sencillo como suele decirse. Pueden ser uno de los componentes más problemáticos de la arquitectura de aplicaciones distribuidas.
En algunos casos, esto es un mal necesario, como cuando necesita acceso frecuente a datos transformados como resultado de cálculos largos y costosos, y ha intentado todas las demás formas de reducir la latencia. Pero en muchos casos, el aumento de rendimiento simplemente no vale la pena. Resuelves un problema, pero creas otros.
A continuación se detallan los riesgos asociados con el almacenamiento en caché externo que a menudo se pasan por alto y las formas en que tres equipos lograron mejoras en el rendimiento y ahorros de costos al reemplazar su base de datos central y el almacenamiento en caché externo con una única solución. Spoiler: utilizan ScyllaDB, una base de datos de alto rendimiento que logra una latencia de cola larga mejorada aprovechando un caché interno especializado.
¿Por qué no almacenar en caché?
En ScyllaDB, trabajamos con innumerables equipos que lidian con el costo, las molestias y las limitaciones de los intentos tradicionales de mejorar el rendimiento de las bases de datos. Estas son las principales dificultades que vemos que encuentran los equipos al colocar almacenamiento en caché externo delante de sus bases de datos.
El almacenamiento en caché externo aumenta la latencia
Un caché separado significa un salto más en el camino. Cuando el almacenamiento en caché rodea la base de datos, el primer acceso se produce en la capa de caché. Si los datos no están en el caché, la solicitud se enviará a la base de datos. Esto agrega latencia al ya lento camino hacia los datos no almacenados en caché. Se podría afirmar que cuando todo el conjunto de datos cabe en la caché, la latencia adicional no entra en juego. Sin embargo, a menos que su conjunto de datos sea bastante pequeño, almacenarlos todos en la memoria aumenta significativamente el costo, lo que lo hace prohibitivamente costoso para la mayoría de las organizaciones.
El almacenamiento en caché externo tiene un costo adicional
El almacenamiento en caché significa DRAM costosa, lo que significa que el costo por gigabyte es mayor que el de los discos de estado sólido. (Para obtener más detalles sobre esto, consulte la charla de Danny Kopping de Grafana en P99 CONF ). En lugar de aprovisionar una infraestructura completamente separada para el almacenamiento en caché, a menudo es mejor usar la memoria de la base de datos existente o incluso aumentarla para acomodar el caché interno. Cuando tienen el tamaño correcto, las cachés de bases de datos modernas pueden ser tan eficientes como las soluciones tradicionales de almacenamiento en caché en memoria. Las bases de datos a menudo hacen un buen trabajo al optimizar el acceso de E/S al almacenamiento flash cuando el tamaño del conjunto de trabajo es demasiado grande para caber en la memoria, lo que hace que una base de datos separada (sin caché externa) sea la opción preferida y más económica.
El almacenamiento en caché externo reduce la disponibilidad
Ninguna solución de almacenamiento en caché de alta disponibilidad puede rivalizar con la propia base de datos. Las bases de datos distribuidas modernas tienen múltiples réplicas; también son conscientes de la topología y la velocidad, y pueden soportar múltiples fallas sin perder datos.
Por ejemplo, un patrón de replicación común son tres réplicas locales, lo que a menudo permite que las lecturas se equilibren entre estas réplicas para utilizar de manera efectiva el mecanismo de almacenamiento en caché interno de la base de datos. Considere un clúster de nueve nodos con un factor de replicación de tres: esencialmente, cada nodo contendrá aproximadamente un tercio del tamaño total del conjunto de datos. Dado que las solicitudes se equilibran entre diferentes réplicas, esto le brinda más espacio para almacenar en caché los datos, lo que puede eliminar la necesidad de almacenamiento en caché externo. Por el contrario, si el caché externo invalida una entrada justo antes de una gran cantidad de solicitudes en frío, la disponibilidad puede verse afectada durante un período de tiempo porque la base de datos no tiene esos datos en su caché interno (más sobre esto a continuación).
Los cachés a menudo carecen de propiedades de alta disponibilidad y pueden fallar o invalidar registros fácilmente según su heurística. Los fracasos parciales son más comunes y aún peores en términos de consistencia. Cuando el caché falla inevitablemente, la base de datos se verá afectada por una avalancha de consultas no mitigadas y puede romper su SLA. Además, incluso si el caché en sí tiene algunas características de alta disponibilidad, no puede coordinar el manejo de tales fallas con la base de datos persistente que tiene delante. En pocas palabras : confíe en la base de datos, en lugar de que su SLA de latencia dependa del caché.
Complejidad de la aplicación: su aplicación necesita manejar más situaciones
El almacenamiento en caché externo introduce complejidad operativa y de aplicaciones. Una vez que tenga un caché externo, es su responsabilidad mantenerlo actualizado con la base de datos. Independientemente de su estrategia de almacenamiento en caché (por ejemplo, escritura simultánea, omisión de caché, etc.), habrá casos extremos en los que su caché puede no estar sincronizado con la base de datos, y debe tener en cuenta estas situaciones durante el desarrollo de la aplicación. La configuración de su cliente (como las políticas de conmutación por error, reintento y tiempo de espera) debe coincidir con las propiedades de la caché y la base de datos para funcionar cuando la caché no está disponible o se queda inactiva. Normalmente, estos escenarios son difíciles de probar e implementar.
El caché externo corrompe el caché de la base de datos
Las bases de datos modernas tienen cachés integrados y estrategias complejas para administrarlas. Cuando coloca un caché delante de la base de datos, la mayoría de las solicitudes de lectura solo llegarán al caché externo y la base de datos no retendrá estos objetos en su memoria. Como resultado, la caché de la base de datos deja de ser válida. Cuando la solicitud finalmente llegue a la base de datos, su caché estará fría y la respuesta provendrá principalmente del disco. Como resultado, el viaje de ida y vuelta desde la memoria caché a la base de datos y de regreso a la aplicación puede aumentar la latencia.
El almacenamiento en caché externo puede aumentar los riesgos de seguridad
El almacenamiento en caché externo agrega una superficie de ataque completamente nueva a su infraestructura. Los controles de cifrado, aislamiento y acceso a los datos colocados en la memoria caché pueden diferir de los de la propia capa de base de datos.
El almacenamiento en caché externo ignora el conocimiento y los recursos de la base de datos
La base de datos es compleja y está diseñada para cargas de trabajo de E/S especializadas en el sistema. Muchas consultas acceden a los mismos datos y una cierta cantidad del tamaño del conjunto de trabajo se puede almacenar en caché en la memoria para ahorrar acceso al disco. Una buena base de datos debe tener una lógica compleja para decidir qué objetos, índices y accesos debe almacenar en caché. La base de datos también debe tener una política de desalojo para determinar cuándo los nuevos datos deben reemplazar los objetos de caché existentes (más antiguos).
El almacenamiento en caché resistente al escaneo es un ejemplo. Al escanear grandes conjuntos de datos, como escaneos de gran rango o de tabla completa, se lee una gran cantidad de objetos del disco. La base de datos puede darse cuenta de que se trata de un escaneo (en lugar de una consulta normal) y optar por mantener sus objetos fuera de su caché interna. Sin embargo, el almacenamiento en caché externo (que sigue la política de lectura directa) trata el conjunto de resultados como cualquier otro conjunto de resultados e intenta almacenar en caché los resultados. La base de datos sincroniza automáticamente el contenido almacenado en caché con el disco según las tasas de solicitudes entrantes, por lo que los usuarios y desarrolladores no necesitan hacer nada para garantizar el rendimiento y la coherencia en las búsquedas de datos escritos recientemente. Entonces, si por alguna razón su base de datos no responde lo suficientemente rápido, significa:
- Error de configuración de caché.
- No hay suficiente RAM para el caché.
- El tamaño del conjunto de trabajo y el patrón de solicitud no son adecuados para el almacenamiento en caché.
- La implementación de la caché de la base de datos es deficiente.
Mejor opción: dejar que la base de datos se encargue de ello
¿Cómo cumplir con su SLA sin el riesgo de almacenamiento en caché de bases de datos externas? Muchos equipos descubren que al migrar a una base de datos más rápida (como ScyllaDB) y utilizar un caché interno dedicado , pueden cumplir sus SLA de latencia con menos complicaciones y menores costos. Por supuesto, los resultados variarán según las características de la carga de trabajo y los requisitos técnicos. Pero para lo que es posible, considere lo que estos equipos pueden lograr.
SecurityScorecard logra una reducción de latencia del 90 % con un ahorro anual de 1 millón de dólares
SecurityScorecard tiene como objetivo hacer del mundo un lugar más seguro cambiando la forma en que miles de organizaciones entienden, mitigan y comunican sobre la ciberseguridad. Su plataforma de calificación es una medida objetiva, basada en datos y cuantificable de la ciberseguridad general y la exposición al riesgo cibernético de una organización.
La arquitectura de datos anterior del equipo les resultó útil durante un tiempo, pero no pudo seguir el ritmo de su crecimiento. La API de su plataforma consulta uno de los tres almacenes de datos: Redis (para búsquedas más rápidas de 12 millones de cuadros de mando), Aurora (para almacenar 4 mil millones de estadísticas de medición en nodos) o el sistema de archivos distribuido Hadoop, el clúster Presto (para consultas SQL complejas sobre resultados históricos). ).
A medida que crecen los datos y las solicitudes, surgen desafíos. Aurora y Presto experimentan picos de latencia a alto rendimiento. La instancia más grande posible de Redis todavía no era suficiente y no querían utilizar la complejidad de Redis Cluster.
Para reducir la latencia en la nueva escala requerida para un rápido crecimiento empresarial, el equipo recurrió a ScyllaDB Cloud y desarrolló una nueva API de puntuación para enrutar solicitudes menos sensibles a la latencia al almacenamiento Presto y S3. Aquí hay una visualización de esta arquitectura, y es bastante simple:
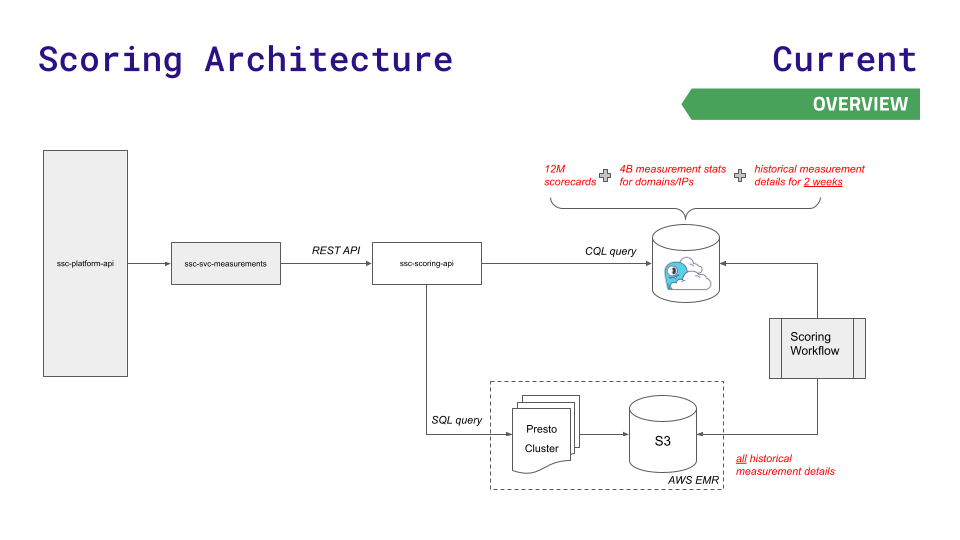
Este movimiento resultó en:
- Latencia un 90% menor para la mayoría de los puntos finales de servicio
- Reducción del 80% en incidentes de producción relacionados con el desempeño de Presto/Aurora
- $1 millón en ahorros anuales en costos de infraestructura
- La velocidad de procesamiento de la canalización de datos aumentó en un 30%
- Mejorar drásticamente la experiencia del cliente
[Lea más sobre los casos de uso de SecurityScorecard]
IMVU reduce el costo de Redis a 100 veces
IMVU es una comunidad social popular que permite a personas de todo el mundo interactuar utilizando avatares 3D en computadoras de escritorio, tabletas y dispositivos móviles. Para satisfacer los crecientes requisitos de escala, IMVU decidió que necesitaba una solución de mayor rendimiento que su arquitectura de base de datos anterior (MySQL y Memcached frente a Redis). El equipo buscó algo que fuera más fácil de configurar, más fácil de escalar y (si tiene éxito) más fácil de escalar.
"Redis fue excelente para las capacidades de creación de prototipos, pero una vez que lo implementamos, el gasto se volvió difícil de justificar", dijo Ken Rudy, ingeniero de software senior de IMVU. "ScyllaDB está optimizado para mantener los datos necesarios en la memoria y todo lo demás en el disco. ScyllaDB nos permite mantener la misma capacidad de respuesta en una escala cientos de veces superior a la que Redis puede manejar".
Comcast utiliza 2,5 millones de dólares en ahorros anuales para reducir la latencia de cola larga en un 95 %
Comcast es una empresa global de tecnología y medios con tres negocios principales: Comcast Cable, uno de los mayores proveedores de video, Internet de alta velocidad y llamadas telefónicas para clientes residenciales en los Estados Unidos, NBCUniversal y Sky. El servicio Xfinity de Comcast presta servicio a 15 millones de hogares, con más de 2 mil millones de llamadas API (lectura/escritura) y más de 200 millones de objetos nuevos cada día. En siete años, el programa se ha expandido de admitir 30.000 dispositivos a más de 31 millones de dispositivos.
La latencia de cola larga de Cassandra resultó inaceptable en la escala de rápido crecimiento de la empresa. Para ocultar los problemas de latencia de Cassandra a los usuarios, el equipo colocó 60 servidores de caché frente a su base de datos. Mantener esta capa de almacenamiento en caché coherente con la base de datos genera muchos dolores de cabeza para los administradores. Debido a que el caché y la infraestructura relacionada deben replicarse entre centros de datos, Comcast necesita mantener el caché activo. Implementaron un calentador de caché que verificaba el volumen de escritura y luego copiaba los datos entre centros de datos.
Comcast rápidamente recurrió a ScyllaDB después de luchar con los gastos generales de este enfoque. ScyllaDB está diseñado para minimizar los picos de latencia a través de su mecanismo de almacenamiento en caché interno, lo que permite a Comcast eliminar las capas de almacenamiento en caché externas, proporcionando un marco simple donde los servicios de datos se conectan directamente a los almacenes de datos. Comcast pudo reemplazar 962 nodos Cassandra con solo 78 nodos ScyllaDB. Mejoraron la disponibilidad y el rendimiento generales y eliminaron por completo 60 servidores de caché. Resultados: P99, P999 y P9999 redujeron la latencia en un 95 % y pudieron manejar el doble de solicitudes, con un costo operativo del 60 %. En última instancia, esto les ahorró 2,5 millones de dólares al año en costos de infraestructura y gastos generales de personal.
Conclusión
Si bien los cachés externos son excelentes compañeros para reducir la latencia (como ofrecer contenido estático y datos personalizados que no requieren ningún nivel de persistencia), a menudo crean más problemas que beneficios cuando se colocan frente a la base de datos.
Las principales compensaciones incluyen un mayor costo, una mayor complejidad de las aplicaciones, viajes de ida y vuelta adicionales a la base de datos y superficies de seguridad adicionales. Al repensar las estrategias de almacenamiento en caché existentes y cambiar a una base de datos moderna que ofrezca una baja latencia predecible a escala, los equipos pueden simplificar su infraestructura y minimizar los costos. Al mismo tiempo, aún pueden cumplir sus SLA sin las molestias y la complejidad adicionales del almacenamiento en caché externo.
¿Cuántos ingresos puede generar un proyecto desconocido de código abierto? El equipo chino de inteligencia artificial de Microsoft empacó colectivamente y se fue a los Estados Unidos, involucrando a cientos de personas. Huawei anunció oficialmente que los cambios de trabajo de Yu Chengdong estaban clavados en el "Pilar de la vergüenza de FFmpeg" durante 15 años. Hace, pero hoy tiene que agradecernos—— ¿Tencent QQ Video venga su humillación pasada? El sitio espejo de código abierto de la Universidad de Ciencia y Tecnología de Huazhong está oficialmente abierto para acceso externo : Django sigue siendo la primera opción para el 74% de los desarrolladores. El editor Zed ha logrado avances en el soporte de Linux. Un ex empleado de una conocida empresa de código abierto . dio la noticia: después de ser desafiada por un subordinado, la líder técnica se puso furiosa y grosera, fue despedida y quedó embarazada. La empleada Alibaba Cloud lanza oficialmente Tongyi Qianwen 2.5 Microsoft dona 1 millón de dólares a la Fundación Rust.Este artículo se publicó por primera vez en Yunyunzhongsheng ( https://yylives.cc/ ), todos son bienvenidos a visitarlo.