
Este artículo es el primero de una serie que celebra el segundo aniversario de CloudWeGo.
El intercambio de hoy se divide principalmente en tres partes. La primera es la actualización de capacidades de Kitex. Echemos un vistazo a algunos avances en
rendimiento
,
funcionalidad
y
facilidad de uso
durante el año pasado. El segundo es el progreso de los proyectos de cooperación comunitaria, especialmente dos proyectos clave, la interoperabilidad
Kitex-Dubbo
y la integración del centro de configuración . El tercero es darles algunos spoilers sobre algunas de las cosas que estamos haciendo actualmente y que planeamos hacer.
Actualización de capacidad
actuación
En septiembre de 2021, publicamos un artículo "
ByteDance Go RPC Framework Kitex Performance Optimization Practice
", que se puede encontrar en el sitio web oficial de CloudWeGo. Este artículo presenta cómo editar a través de la biblioteca de red de desarrollo propio Netpoll y el Thrift Decoder de desarrollo propio. fastCodec para optimizar el rendimiento de Kitex.
Desde entonces, ha sido muy difícil mejorar el rendimiento en el enlace de solicitud principal de Kitex. De hecho, tenemos que trabajar duro para evitar la degradación del rendimiento de Kitex mientras agregamos nuevas funciones constantemente.
A pesar de ello, nunca hemos dejado de intentar optimizar el rendimiento de Kitex. Dentro de Byte, ya estamos experimentando y promoviendo algunas mejoras de rendimiento en los enlaces principales, que les presentaremos más adelante.
Llamadas generalizadas basadas en DynamicGo
Primero, presentaremos una optimización de rendimiento que se ha lanzado: llamadas generalizadas basadas en DynamicGo.
Las llamadas genéricas
son una característica avanzada de Kitex. Puede usar Kitex Generic Client para llamar directamente a la API del servicio de destino sin generar previamente el código SDK (es decir, Kitex Client).
Por ejemplo, las herramientas de prueba de interfaz interna de ByteDance, las puertas de enlace API, etc. utilizan el Cliente generalizado de Kitex, que puede recibir una solicitud HTTP (el cuerpo de la solicitud está en formato JSON), convertirla a Thrift Binary y enviarla a Kitex Server.
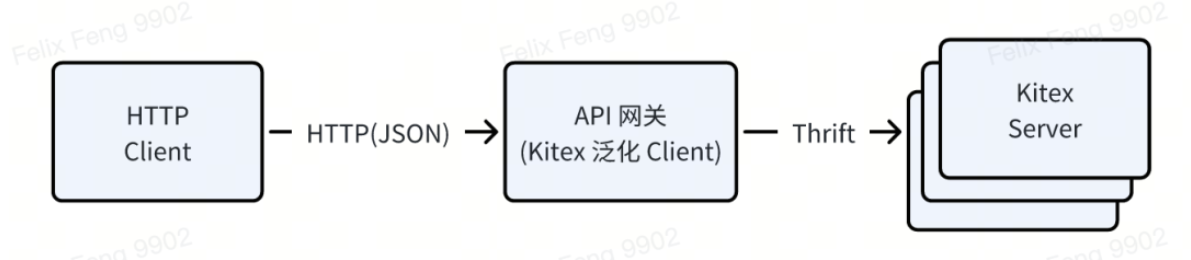
El plan de implementación es confiar en a
map[string]interface{}
como contenedor genérico, primero convertir json a mapa al realizar la solicitud y luego completar el mapa -> conversión de ahorro basada en Thrift IDL y la respuesta se procesa a la inversa;
-
La ventaja de esto es que es muy flexible y no necesita depender de código estático generado previamente. Solo necesita IDL para solicitar el servicio de destino;
-
Sin embargo, el precio es un rendimiento deficiente. Un contenedor genérico de este tipo depende del GC y la administración de memoria de Go, lo cual es muy costoso. No solo necesita asignar una gran cantidad de memoria, sino que también requiere múltiples copias de datos.
Por lo tanto, desarrollamos DynamicGo (página de inicio:
http://github.com/cloudwego/dynamicgo
), que puede usarse para mejorar el rendimiento de la conversión de protocolos. Hay una introducción muy detallada en la introducción del proyecto. Aquí solo les presentaré su idea de diseño central: según
el flujo de bytes original
,
el procesamiento y la conversión de datos
se completan in situ .
A través de la tecnología de agrupación, Dynamicgo solo necesita preasignar memoria una vez y utiliza conjuntos de instrucciones SIMD como SSE y AVX para la aceleración, logrando en última instancia mejoras considerables en el rendimiento.
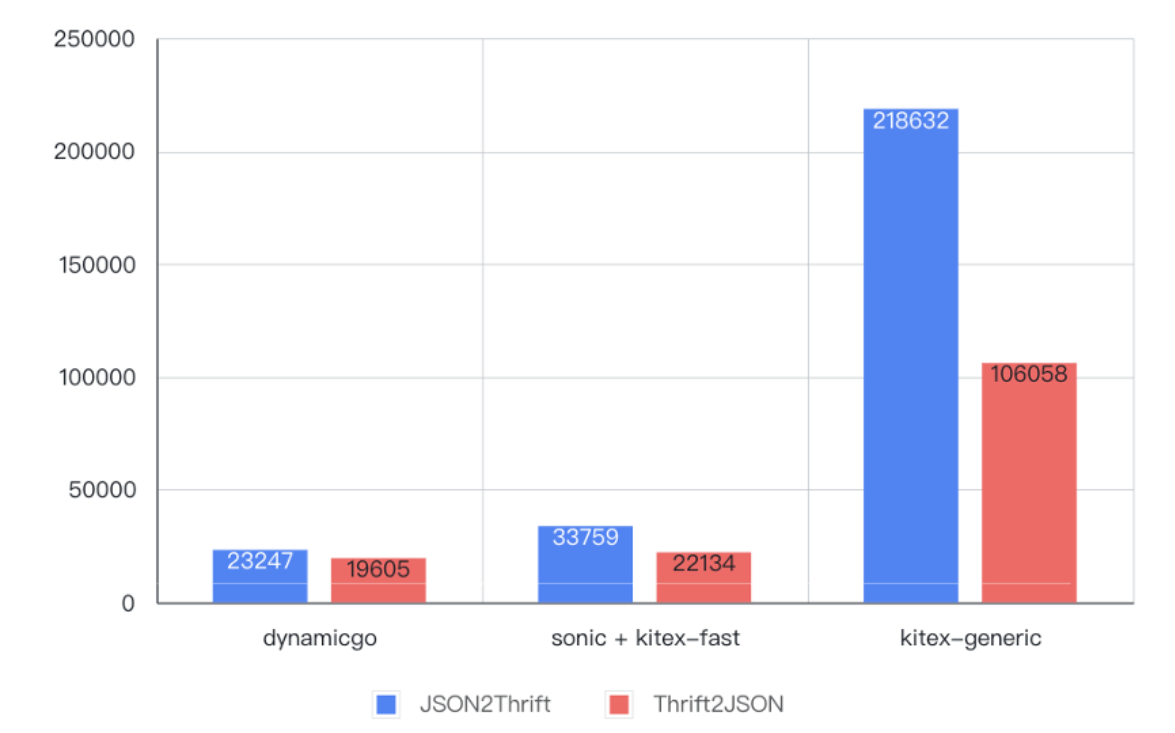
Como se muestra en la figura siguiente, en comparación con la implementación original de llamadas generalizadas, en la prueba de codificación y decodificación de datos de 6 KB, el rendimiento mejoró de
4 a 9 veces
, incluso
mejor que
el código estático generado previamente.
El principio real es muy simple: genere un descriptor de tipo basado en el análisis de IDL y realice el siguiente proceso de conversión de protocolo
-
Lea un par clave/valor del flujo de bytes JSON cada vez;
-
Busque el campo Thrift correspondiente a la clave según el descriptor IDL;
-
Complete la codificación del Valor de acuerdo con la especificación de codificación Thrift del tipo correspondiente y escríbalo en el flujo de bytes de salida;
-
Repita este proceso hasta que se procese todo el JSON.
Además de optimizar la conversión del protocolo JSON/Thrift, DynamicGo también proporciona el método Thrift DOM para optimizar el rendimiento de los escenarios de orquestación de datos. Por ejemplo, un equipo empresarial de Douyin necesita borrar datos ilegales en la solicitud, pero solo en un determinado campo de la solicitud; usar la API Thrift DOM de DynamicGo es muy adecuado y puede lograr una mejora de rendimiento 10 veces mayor. La documentación de DynamicGo no se ampliará aquí.
Frugal: un códec Thrift de alto rendimiento basado en JIT
Frugal es un códec Thrift de alto rendimiento basado en tecnología de compilación
JIT .
Los códecs predeterminados oficiales de Thrift y Kitex se basan en analizar Thrift IDL y generar el código Go de codificación y decodificación correspondiente. A través de la tecnología JIT, podemos generar dinámicamente códigos de codificación y decodificación con mejor rendimiento en
tiempo de ejecución
: generar código de máquina más compacto, reducir errores de caché, reducir errores de rama, usar instrucciones SIMD para acelerar y usar llamadas a funciones basadas en registros (el valor predeterminado de Go se basa en en la pila).
Estos son los indicadores de rendimiento de las pruebas de codificación y decodificación:

Como puede verse, el rendimiento de Frugal es significativamente mayor que el de los métodos tradicionales.
Además de las ventajas de rendimiento, también existen beneficios adicionales porque no se genera código códec.
Por un lado ,
el almacén es más conciso
. Tenemos un proyecto en el que el código generado es de 700 MB, después de cambiar a frugal, ocupa solo 37 millones, que es aproximadamente el 5% del tamaño original y reduce considerablemente la presión sobre el mantenimiento del almacén. Y no se generará una gran cantidad de código después de modificar el código IDL que en realidad no se puede revisar. Por otro lado,
la velocidad de carga del IDE y
la velocidad de compilación
del proyecto también se pueden mejorar significativamente.
De hecho, Frugal se lanzó el año pasado, pero la cobertura de la primera versión en ese momento no fue suficiente. Este año nos centramos en optimizar su estabilidad y solucionamos todos los problemas conocidos. La versión v0.1.12 lanzada recientemente se puede utilizar de forma estable en operaciones de producción. Por ejemplo, en la línea de negocios de comercio electrónico ByteDance, el QPS máximo de un determinado servicio es de aproximadamente 25K. Se cambió por completo a Frugal y ha estado funcionando de manera estable durante varios meses.
Frugal actualmente admite Go1.16 ~ Go1.21, actualmente solo admite la arquitectura AMD64 y también admitirá la arquitectura ARM64 en el futuro. Es posible que usemos Frugal como el códec predeterminado de Kitex en una versión futura.
Función
Kitex se actualizó de v0.4.3 a v0.7.2 el año pasado. Hay más de 40 solicitudes de extracción relacionadas con funciones, que cubren
herramientas de línea de comandos
,
gRPC
, codificación y decodificación
de ahorro
, reintentos , llamadas generalizadas y configuraciones de gobernanza de servicios
.
En muchos aspectos, aquí nos centramos en algunas características más importantes.
Respaldo: degradación personalizada empresarial
La primera es la función alternativa agregada por Kitex en la versión v0.5.0.
El trasfondo de la demanda es que cuando la solicitud RPC falla y no se puede obtener la respuesta, el código comercial a menudo necesita implementar algunas estrategias de degradación.
Por ejemplo, en el negocio del flujo de información, si la capa de acceso API encuentra un error ocasional (como el tiempo de espera) al solicitar servicios recomendados, el enfoque simple y burdo es decirle al usuario que ocurrió un error y dejar que vuelva a intentarlo, pero esto resultará en una mala experiencia. Una mejor estrategia de degradación es intentar devolver algunos artículos populares. Los usuarios casi no tendrán idea al respecto y la experiencia será mucho mejor.
El problema con la versión anterior de Kitex es que el middleware personalizado para la empresa no se puede implementar en el middleware integrado, como el disyuntor y el tiempo de espera. La única forma es modificar el código comercial directamente, lo cual es bastante intrusivo y. Requiere modificar cada método llamado, fácil de pasar por alto. Al agregar lógica de negocios que llama a un determinado método, no existe ningún mecanismo para garantizar que no se pierda.
A través de la nueva función de respaldo,
la empresa puede especificar un método de respaldo al inicializar el cliente para implementar la estrategia de degradación
.
Aquí hay un ejemplo de uso simple:

Este método especificado al inicializar el cliente se llamará antes del final de cada solicitud. Se puede obtener el contexto, los parámetros de la solicitud y la respuesta de esta solicitud. En base a esto, se puede implementar una estrategia de degradación personalizada, haciendo converger así la implementación. estrategia.
Thrift FastCodec: admite campos desconocidos
En escenarios comerciales reales, un enlace de solicitud a menudo involucra varios nodos.
Tomando el enlace A -> B -> C -> D como ejemplo, una determinada estructura del nodo A debe transmitirse de forma transparente al nodo D a través de B y C. En la implementación anterior, si se agrega un nuevo campo a A, por ejemplo
Extra
,
necesito usar el nuevo
IDL
para regenerar el código de todos los nodos
y volver a implementarlo para obtener el valor del campo adicional en el nodo D. Todo el proceso es complejo y el ciclo de actualización es relativamente largo. Si el nodo intermedio es un servicio de otro equipo, se requiere coordinación entre equipos, lo cual es muy laborioso.
En Kitex v0.5.2, implementamos la función Campos desconocidos en nuestro fastCodec de desarrollo propio, que puede resolver muy bien este problema.
Por ejemplo, en el mismo enlace A -> B -> C -> D, los códigos de los nodos B y C permanecen sin cambios (como se muestra en la figura siguiente. Al analizar, se encuentra que hay un campo
id=2
y el ). el campo correspondiente no se puede encontrar en la estructura. Por lo tanto,
_unknownFields
se escribe este campo no exportado (en realidad, un alias de un segmento de bytes);

Los servicios A y D se regeneran con el nuevo IDL (como se muestra en la figura siguiente) e incluyen
Extra
el campo. Por lo tanto, al analizar
id=2
el campo, puede escribir en este
Extra
campo y el código comercial se puede usar normalmente.

Además, también realizamos una optimización del rendimiento de esta función en v0.7.0, utilizando "
sin
serialización
" (copia directa de flujos de bytes) para mejorar el rendimiento de codificación y decodificación de campos desconocidos entre
6 y 7
veces.
Mecanismo de entrega de sesiones basado en GLS
Otra característica que vale la pena presentarle también está relacionada con los enlaces largos.
Dentro de Byte, utilizamos LogID para rastrear toda la cadena de llamadas, lo que requiere que todos los nodos en el enlace transmitan este ticket de forma transparente según sea necesario. En nuestra implementación, LogID no se coloca en el cuerpo de la solicitud, sino que se transmite de forma transparente en forma de metadatos.
Tome el enlace A -> B -> C como ejemplo. Cuando A llama al
A_Call_B
método de B, el LogID entrante se almacenará en el parámetro de entrada del controlador
ctx
. Cuando B solicita a C, el uso correcto es pasarlo
ctx
al
client
C.B_Call_C
método. De esta manera se puede transmitir el LogID.

Pero la situación real es a menudo que el código que solicita el servicio C está empaquetado en varias capas y
es fácil pasar por alto la transmisión transparente de ctx.
La situación que encontramos es más problemática: la solicitud del servicio C la
completa un tercero ; biblioteca
y la interfaz de la biblioteca no admite el código entrante
ctx
, y dicha transformación del código es muy costosa y puede requerir la coordinación de varios equipos para completarse.
Para resolver este problema, introdujimos un mecanismo de transferencia de sesión basado en GLS (almacenamiento local de rutina). El plan específico es:
-
En el lado del servidor Kitex, después de recibir la solicitud, primero hace una copia de seguridad del contexto en GLS y luego llama al controlador, que es el código comercial;
-
Al llamar al cliente en el código comercial para enviar una solicitud, primero verifique si la entrada ctx contiene el ticket esperado. De lo contrario, sáquelo de la copia de seguridad de GLS y luego envíe la solicitud.
Aquí hay un ejemplo específico:

ilustrar:
-
ContextBackupEncienda el interruptor al inicializar el servidor -
Especifique uno al inicializar el Cliente
backupHandler -
Antes de realizar cada solicitud, se llamará a este controlador para verificar si los parámetros de entrada incluyen
LogID -
ctxSi no está incluido, léalo desde la copia de seguridad , combínelo con el actualctxy devuélvalo (devolverlouseNewCtx =truesignifica que Kitex debe usar este nuevoctxpara enviar la solicitud)
Después de activar la configuración anterior, incluso si el código comercial utiliza el contexto incorrecto, todo el enlace se puede conectar en serie.
Finalmente, introduzcamos el parámetro asíncrono de inicialización del servidor, que resuelve el problema de enviar solicitudes en una nueva rutina en el controlador. Dado que no son la misma rutina, el almacenamiento local no se puede compartir directamente; aprendemos del mecanismo de pprof para colorear rutinas y pasar la copia de seguridad
ctx
a la nueva rutina, logrando así la capacidad de pasar tickets implícitamente en escenarios
asincrónicos
.
Facilidad de uso
Además del alto rendimiento y la rica funcionalidad, también prestamos gran atención a mejorar la facilidad de uso de Kitex.
Documentación |
Como todos sabemos, hay dos cosas que los programadores odian más: una es escribir documentación y la otra es no escribir documentación. Por lo tanto, damos gran importancia a reducir el costo inicial de redactar documentos y trabajamos arduamente para promover la construcción de documentos.
Dentro de ByteDance, los documentos de Kitex están organizados en forma de base de conocimientos de Feishu, que puede integrarse mejor en la búsqueda de Feishu y facilitar las consultas de los empleados de Byte porque los documentos de Feishu son fáciles de actualizar y están más actualizados que los documentos del sitio web oficial; Se desarrollan nuevas funciones, los documentos a menudo se escriben primero en la base de conocimientos de Feishu y algunos no se sincronizan con el sitio web oficial a tiempo. Varias razones han llevado a las crecientes diferencias entre las ramas internas y externas.
Por lo tanto, en los últimos dos trimestres, lanzamos una nueva ronda de trabajo de optimización de documentos: según los comentarios de los usuarios, reorganizamos todos los documentos y agregamos más ejemplos, los tradujimos al inglés y los sincronizamos con el sitio web oficial. Se espera que este trabajo se complete este año. Ya puede ver algunos documentos actualizados en el sitio web oficial, como control de tiempo de espera, Frugal, procesamiento de pánico, etc. Le invitamos a visitar el sitio web oficial y ayudar a detectar errores.
Además, también estamos creando un mecanismo para sincronizar automáticamente documentos internos con el sitio web oficial. Esperamos que los usuarios de código abierto también puedan obtener documentos actualizados oportunamente como los usuarios internos en el futuro.
Otras optimizaciones | Varios
Además de la documentación, Kitex también realiza otros trabajos relacionados con la usabilidad.
Hemos publicado un proyecto de muestra "Servicio de notas", que demuestra el uso de varias funciones como middleware, limitación de corriente, reintento, control de tiempo de espera, etc. en el ejemplo, y proporciona referencias a los usuarios de Kitex a través del código de proyecto real. Puede consultar el ejemplo aquí: https://github.com/cloudwego/kitex-examples/tree/main/bizdemo/easy_note.
En segundo lugar, también estamos trabajando arduamente para mejorar la eficiencia de la resolución de problemas. Por ejemplo, hemos agregado información contextual más específica al mensaje de error según las necesidades diarias de guardia (como el motivo específico del error de tiempo de espera, el nombre del método para el pánico). mensaje y el mensaje de error del códec de ahorro. Nombres de campos específicos, etc.) para localizar rápidamente puntos problemáticos específicos.
Además, las herramientas de línea de comandos de Kitex continúan mejorando.
-
Por ejemplo, muchos usuarios empresariales desarrollan en Windows. Anteriormente, Kitex no podía generar código normalmente en Windows. Como resultado, estos usuarios también necesitaban un entorno Linux para ayudar, lo cual era muy inconveniente. Hicimos optimizaciones basadas en los comentarios de estos usuarios. .
-
También implementamos una herramienta de recorte IDL que puede identificar estructuras a las que no se hace referencia y filtrarlas directamente al generar código. Esto es muy útil para algunos proyectos antiguos que están estancados.
proyectos de cooperación comunitaria
El año pasado, con el apoyo de la comunidad CloudWeGo, también logramos muchos resultados, especialmente los dos proyectos de interoperabilidad de Dubbo e integración del centro de configuración.
Dubbo 互通 | Intercomunicación Dubbo
Aunque Kitex era originalmente un marco Thrift RPC, su diseño arquitectónico tiene buena escalabilidad. Como se muestra en la figura, al agregar nuevos protocolos, el trabajo principal es implementar un códec de protocolo correspondiente (Codec o PayloadCodec) de acuerdo con la interfaz del códec:
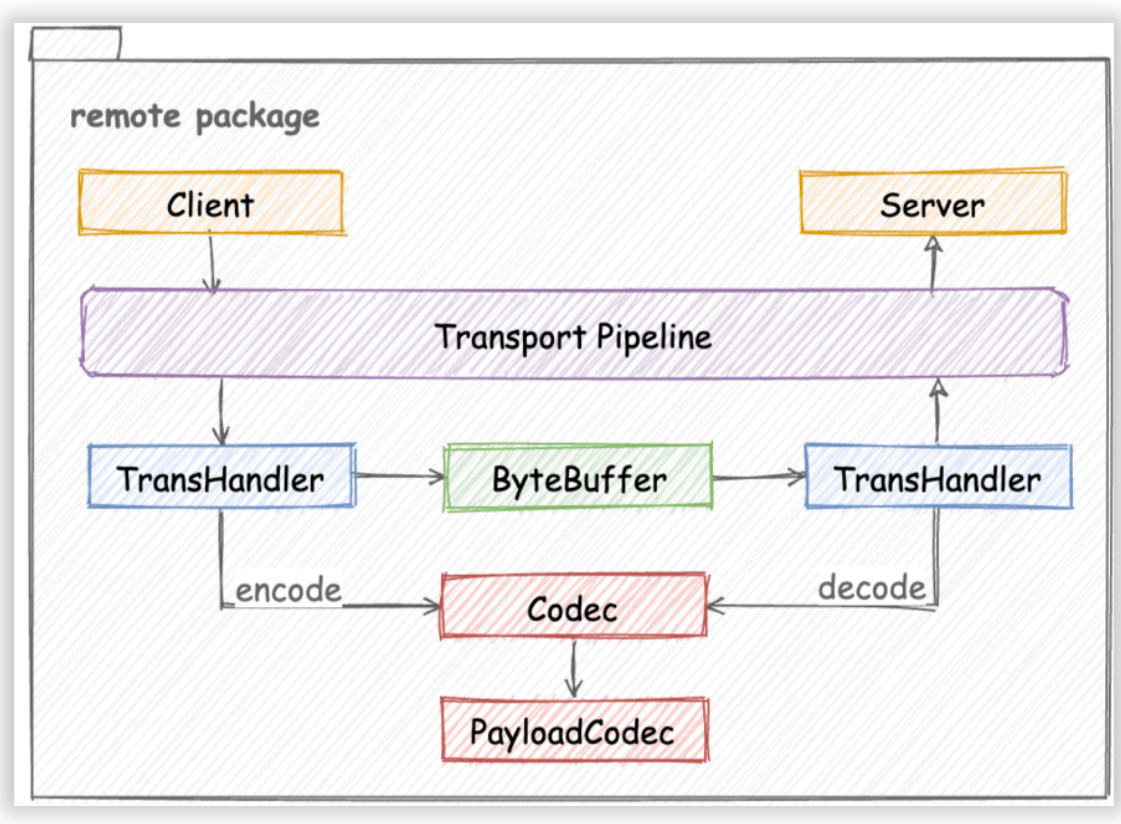
El proyecto de interoperabilidad de Dubbo surgió de las necesidades de un usuario empresarial. Tienen algunos servicios periféricos implementados por proveedores que utilizan Dubbo Java. Esperan utilizar Kitex para solicitar estos servicios y reducir los costos de gestión del proyecto.
Este proyecto ha recibido el apoyo entusiasta de los estudiantes de la comunidad y muchos estudiantes han participado en este proyecto. En particular, @DMwangnima, responsable de una de las tareas principales, también es desarrollador de la comunidad Dubbo. Dado que está familiarizado con Dubbo, el proceso de desarrollo ha evitado muchos desvíos.
Con respecto al plan de implementación específico, adoptamos una idea diferente a la del funcionario de Dubbo. Según el análisis del protocolo hessian2, su sistema de tipos básico básicamente se superpone con Thrift, por lo que generamos el andamio del proyecto Kitex Dubbo-Hessian2 basado en Thrift IDL.
Para implementar rápidamente la función en la primera fase, tomamos prestada directamente la biblioteca hessian2 del marco Dubbo-go para la serialización y deserialización, e implementamos el DubboCodec propio de Kitex consultando la documentación oficial de Dubbo y el código fuente de Dubbo-Go;
En octubre completamos la primera versión del código. La dirección del proyecto es
https://github.com/kitex-contrib/codec-dubbo
. Los usuarios interesados pueden probarlo de acuerdo con el documento anterior. se puede comparar con Kitex Similar a Thrift, escriba el IDL de Thrift, use la línea de comando de kitex para generar andamios (tenga en cuenta que el protocolo debe especificarse como hessian2) y luego especifique DubboCodec en el código donde se inicializan el cliente y el servidor. y podrá comenzar a escribir código comercial.
Esto no solo reduce el umbral de usuario, sino que también utiliza IDL para administrar la información relacionada con la interfaz, lo que mejora la capacidad de mantenimiento.
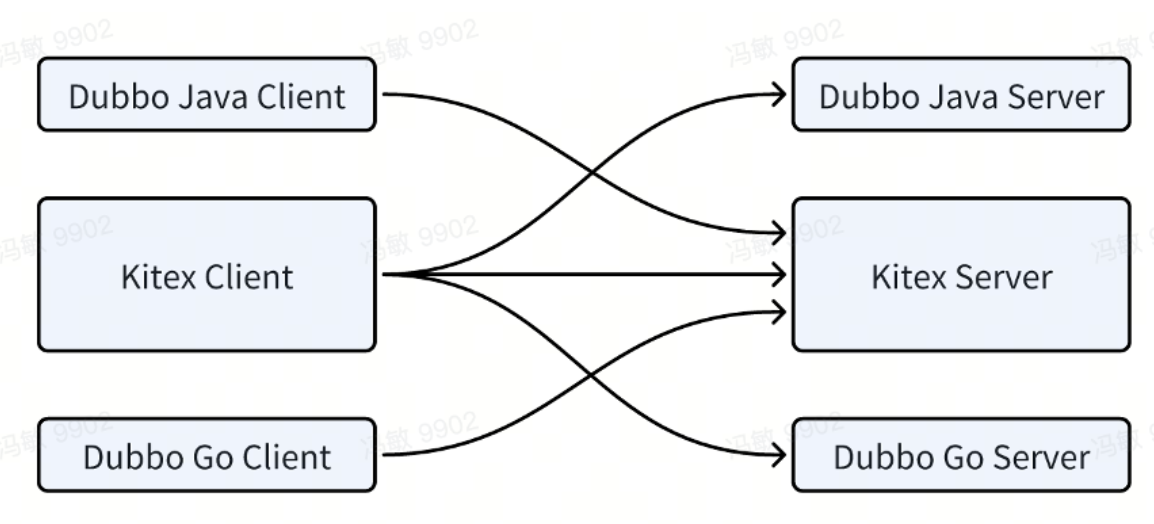
Actualmente, hemos podido lograr la interoperabilidad entre Kitex y Dubbo-Java, Kitex y Dubbo-Go :
Plan futuro:
-
El primero es mejorar la compatibilidad con dubbo-java y permitir a los usuarios especificar el tipo de Java correspondiente en las anotaciones IDL.
-
El segundo es la conexión con el centro de registro. Aunque Kitex ya tiene un módulo de centro de registro correspondiente, el formato de datos específico no es consistente con Dubbo. Esta área aún necesita algunas modificaciones y el trabajo relevante está a punto de completarse.
-
Finalmente, está el problema del rendimiento. Actualmente existe una gran brecha en comparación con Kitex Thrift. Debido a que la biblioteca dubbo-go-hessian2 se basa completamente en la reflexión, todavía hay mucho espacio para la optimización del rendimiento. Está previsto implementar FastCodec de Hessian2 para resolver el cuello de botella en el rendimiento de la codificación y decodificación.
Durante el avance de este proyecto, experimentamos profundamente el impacto positivo de la cooperación entre comunidades. Kitex absorbió los logros de la comunidad Dubbo y también descubrió áreas donde el proyecto Dubbo-go podría mejorarse. Las soluciones de compatibilidad y rendimiento mencionadas anteriormente. También se espera que beneficie a la comunidad dubbo.
También me gustaría expresar mi agradecimiento especial a los contribuyentes de la comunidad a este proyecto, @DMwangnima, @Lvnszn, @ahaostudy, @jasondeng1997, @VaderKai y otros estudiantes, por dedicar gran parte de su tiempo libre a completar este proyecto.
Integración del centro de configuración | Integración del centro de configuración
Otro proyecto clave de cooperación comunitaria es la "Integración del Centro de Configuración".
Kitex proporciona capacidades de gestión de servicios configurables dinámicamente, incluido el tiempo de espera del cliente, reintento, disyuntor y limitación de corriente del servidor.
Estas capacidades de gobernanza de servicios se utilizan mucho en Byte. Los desarrolladores de microservicios pueden editar estas configuraciones en la plataforma de configuración de gobernanza de servicios construida por Byte. La granularidad se refina a esta tupla de cinco y entra en vigor en tiempo casi real. muy útil para mejorar el SLA de microservicios.
Sin embargo, nos comunicamos con usuarios empresariales y descubrimos que estas capacidades generalmente son muy simples de usar, con granularidad gruesa y poca puntualidad. Es posible que solo sean configuraciones específicas codificadas o configuradas a través de archivos simples y requieran un reinicio para que surtan efecto. .
Para permitir a los usuarios utilizar mejor las capacidades de gobernanza de servicios de Kitex, lanzamos el proyecto de integración del centro de configuración para que Kitex pueda
obtener dinámicamente configuraciones de gobernanza de servicios
desde el centro de configuración del usuario y entrar en vigor casi en tiempo real.
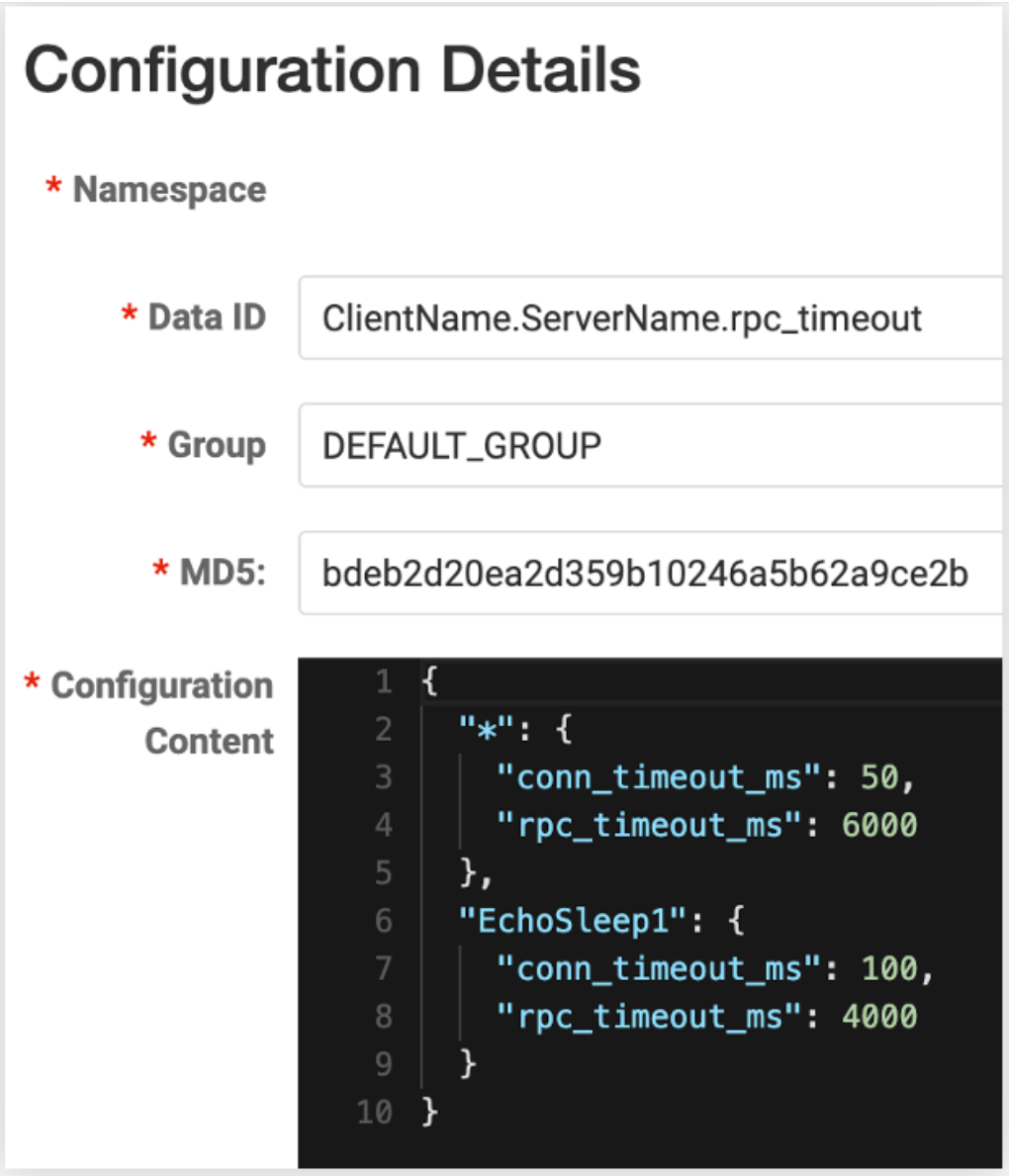
Hemos lanzado la versión v0.1.1 de config-nacos (nota: se actualizó a v0.3.0 en el momento de la publicación, gracias a @whalecold por su continua inversión al agregar un cliente al proyecto Kitex existente)
NacosClientSuite
. Se puede
hacer fácilmente que Kitex
cargue la configuración de gobierno de servicio correspondiente desde
Nacos
.

Dado que utilizamos la capacidad de vigilancia proporcionada por el propio cliente nacos, podemos recibir notificaciones de cambios de configuración casi en tiempo real, por lo que la puntualidad también es muy alta y no es necesario reiniciar el servicio.
Además, también nos hemos reservado la capacidad de modificar la granularidad de la configuración. Por ejemplo, la granularidad de configuración predeterminada es cliente + servidor. Simplemente complete la identificación de datos de Nacos en este formato, los usuarios también pueden especificar la plantilla de esta identificación de datos. por ejemplo, agregue salas de informática, clústeres, etc., para ajustar estas configuraciones con mayor precisión.
Planeamos completar la integración con centros de configuración comunes. Hay instrucciones más detalladas en este número https://github.com/cloudwego/kitex/issues/973.
El progreso actual es:
-
Módulos como file, apollo, etcd y zookeeper han enviado RP y están bajo revisión;
-
se ha presentado el plan del cónsul;
Los compañeros interesados también pueden unirse para revisar, probar y verificar estos módulos de extensión.
perspectiva del futuro
Finalmente, déjame darte algunos spoilers sobre algunas de las direcciones que estamos probando actualmente.
fusionar implementación
Implementación de afinidad |
La mayoría de nuestras optimizaciones anteriores estaban dentro del servicio, pero a medida que la cantidad de puntos de optimización disminuyó gradualmente, comenzamos a considerar otros objetivos, como optimizar la sobrecarga de comunicación de la red de las solicitudes RPC.
Los planes específicos son los siguientes:
-
La primera es la programación por afinidad. Al modificar el mecanismo de programación en contenedores, intentamos programar el Cliente y el Servidor en la misma máquina física;
-
Por tanto, podemos utilizar la comunicación entre la misma máquina para reducir los gastos generales.
En la actualidad, la comunicación entre la misma máquina que hemos implementado incluye los siguientes tres tipos:
-
Unix Domain Socket tiene mejor rendimiento que TCP Socket estándar, pero no mucho;
-
ShmIPC (https://github.com/cloudwego/shmipc-go), comunicación entre procesos basada en memoria compartida, puede omitir directamente la transmisión de datos serializados y solo necesita decirle al receptor la dirección de memoria;
-
Finalmente, está la "tecnología negra" RPAL , que es la abreviatura de Ejecutar proceso como biblioteca. Trabajamos con el equipo del kernel de Byte para colocar dos procesos en el mismo espacio de direcciones a través de un kernel personalizado. Cuando se cumplen ciertas condiciones, luego. es posible que ni siquiera necesite realizar una serialización;
Actualmente, hemos habilitado esta capacidad en más de 100 servicios y hemos logrado algunas mejoras de rendimiento para los servicios con mejores efectos, puede ahorrar entre un 5% y un 10% de CPU y, por supuesto, reducir el consumo de tiempo entre un 10% y un 70%; En la práctica, el rendimiento depende de algunas características del servicio, como el tamaño del paquete.
Fusión en tiempo de compilación | Servicio en línea
Otra idea es la fusión en tiempo de compilación.
El punto de partida de esta solución es que descubrimos que, aunque los microservicios mejoran la eficiencia de la colaboración en equipo, también aumentan la complejidad general del sistema, especialmente en términos de implementación de servicios, ocupación de recursos, gastos generales de comunicación, etc.
Por lo tanto, esperamos implementar una solución que permita desarrollar el negocio en forma de microservicios y desplegarlo en forma de servicios únicos, comúnmente conocido como tener ambos.
Luego se nos ocurrió este plan: desarrollamos una herramienta que puede fusionar el repositorio git de dos microservicios, aislar recursos potencialmente conflictivos a través del espacio de nombres y luego compilarlo en un programa ejecutable para su implementación.
Actualmente, dentro de ByteDance, hay docenas de servicios conectados. El servicio más efectivo puede ahorrar alrededor del 80% de la CPU y reducir la latencia hasta en un 67%. Por supuesto, el rendimiento real también depende de las características del servicio, como la solicitud. Tamaño de la bolsa.
Lo anterior es nuestro intento de afinidad.
Publicación por entregas
En términos de serialización, todavía estamos haciendo algunos esfuerzos e intentos.
Frugal - Backend de SSA
El primero es Frugal. Como se mencionó anteriormente, su rendimiento es significativamente mejor que el código de codificación y decodificación tradicional de Thrift, pero aún tiene margen de mejora.
La implementación actual de Frugal usa Go para generar directamente el código ensamblador correspondiente. También hemos aplicado algunos métodos de optimización en la implementación específica, como generar código más compacto, reducir ramas, etc. Sin embargo, no podemos hacer un uso completo de la tecnología de optimización del compilador existente escribiéndola nosotros mismos.
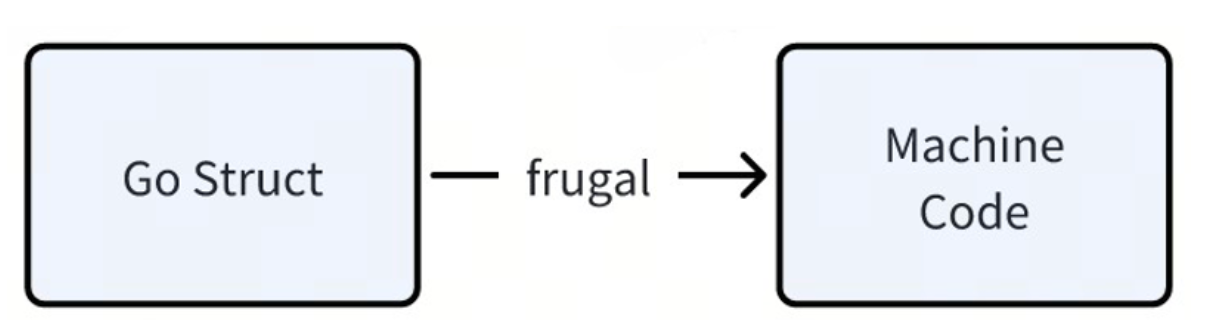
Planeamos reconstruir Frugal para generar un LLVM IR (Representación intermedia) compatible con SSA basado en go struct, de modo que podamos aprovechar al máximo las capacidades de optimización de compilación de LLVM.

Se espera que tras esta transformación el rendimiento pueda mejorarse al menos en un 30%.
Serialización bajo demanda | Serialización bajo demanda
Otra dirección de exploración es la serialización bajo demanda, que se puede dividir en tres partes.
El primero es antes de la compilación. Actualmente hemos lanzado una herramienta de recorte IDL que puede identificar tipos a los que no se hace referencia; sin embargo, es posible que los tipos a los que se hace referencia no sean necesarios. Por ejemplo, dos servicios A y B dependen del mismo tipo, pero uno de los campos puede ser A. Requerido, B no necesita. Consideramos agregar capacidades de anotación de usuario a esta herramienta, permitiendo a los usuarios especificar campos innecesarios, reduciendo así aún más la sobrecarga de serialización.
El segundo es la compilación. La idea es obtener los campos que realmente violan la referencia del código comercial y podarlos según el informe de compilación del compilador. El esquema específico y la corrección aún requieren cierta verificación.
Finalmente, después de la compilación, en tiempo de ejecución, la empresa también puede especificar campos innecesarios, ahorrando así gastos generales de codificación y decodificación.
Resumen | Resumen
Finalmente, repasemos la situación general:
En términos de mejora de capacidades,
-
Kitex ha optimizado el rendimiento de las llamadas de generalización a través de DynamicGo y el códec Frugal de alto rendimiento se ha estabilizado y puede utilizarse en entornos de producción;
-
El año pasado, se agregó un respaldo para facilitar a las empresas la implementación de estrategias de degradación personalizadas, y se utilizaron campos desconocidos y mecanismos de entrega de sesiones para resolver el problema de la transformación de enlaces largos;
-
También hemos mejorado la usabilidad de Kitex mediante la optimización de documentos, proyectos de demostración, mejoras en la eficiencia de la resolución de problemas y herramientas de línea de comandos mejoradas;
En términos de cooperación comunitaria,
-
Admitimos el protocolo hessian2 de Dubbo a través del proyecto de interoperabilidad Kitex-Dubbo, que puede interoperar con los marcos Dubbo Java y Dubbo-Go, y existen optimizaciones posteriores que también pueden retroalimentar a la comunidad Dubbo;
-
En el proyecto de integración del centro de configuración, lanzamos la extensión Nacos para facilitar la integración del usuario y actualmente continuamos promoviendo el acoplamiento de otros centros de configuración;
Todavía quedan algunas direcciones para la exploración en el futuro.
-
En términos de implementación fusionada, a través de la implementación por afinidad, la compilación y la fusión, no solo podemos conservar los beneficios de los microservicios, sino también disfrutar de las ventajas de algunos monolitos que no prestan servicios;
-
En términos de serialización, continuamos optimizando aún más Frugal y logrando capacidades de serialización bajo demanda a través de todos los aspectos de la compilación antes, durante y después de la compilación;
Lo anterior es la revisión y perspectiva de Kitex con motivo del segundo aniversario de CloudWeGo. Espero que sea de ayuda para todos, gracias.
{{o.nombre}}
{{m.nombre}}