

Compartiendo invitados:
Inteligencia de Yang Linsan-Huixi
Acerca de la inteligencia Huixi:
Huixi Intelligence es una empresa de nueva creación que fabrica chips de conducción autónoma, fundada en 2022. Comprometida con la construcción de una innovadora plataforma informática inteligente para vehículos, proporciona chips de conducción inteligentes de alta gama, cadenas de herramientas abiertas fáciles de usar y soluciones de conducción autónoma de pila completa para ayudar a las empresas automotrices a lograr una producción en masa de conducción autónoma eficiente y de alta calidad. y entrega, y desarrollar capacidades de iteración automatizadas, a gran escala y de bajo costo, liderando los viajes inteligentes de alto nivel en la era basada en datos.
Comparte el esquema:
- ¿Cómo utilizar Alluxio en una startup?
- El proceso de uso de Alluxio de 0 a 1 (investigación-implementación-producción).
- Intercambio de experiencias prácticas.
La siguiente es la versión de texto completo del contenido compartido.
Compartir tema:
"Aplicación y Despliegue de Alluxio en la Formación del Modelo de Conducción Autónoma"
Circuito cerrado de datos de conducción autónoma
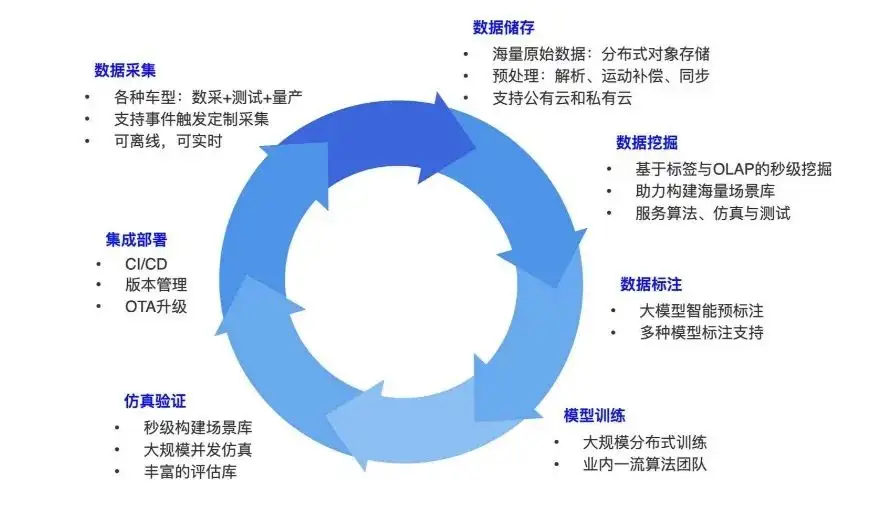
Primero, permítanme compartirles cómo construir un circuito cerrado de datos en la conducción autónoma. Es posible que todos conozcan este proceso comercial. La conducción autónoma incluirá una variedad de tipos de vehículos, como vehículos de extracción de datos y automóviles que circulan por la carretera con algoritmos. La recopilación de datos consiste en recopilar varios datos del automóvil autónomo durante el proceso de ejecución: por ejemplo, los datos de la cámara son imágenes y los datos LIDAR son nubes de puntos.
Cuando se recopilan los datos de los sensores, un automóvil puede generar varios terabytes de datos cada día. Este tipo de datos se almacena en su conjunto a través del disco base u otros métodos de carga y se transfiere al almacenamiento de objetos. Una vez almacenados los datos originales, habrá una canalización para el análisis y preprocesamiento de datos, como cortarlos en marcos de datos un marco a la vez, y se pueden realizar operaciones de sincronización y alineación entre diferentes datos de sensores en cada marco.
Después de completar el análisis de datos, es hora de investigar más al respecto. Construya conjuntos de datos uno por uno. Porque ya sea en algoritmos, simulación o pruebas, se debe construir un conjunto de datos. Por ejemplo, si queremos datos sobre una determinada noche en un día lluvioso, en una determinada intersección o en algunas áreas densamente pobladas, entonces tendremos una gran cantidad de requisitos de datos de este tipo en todo el sistema y debemos etiquetar los datos. datos y agregar algunas etiquetas. Por ejemplo, en la puerta este de la Universidad de Tsinghua, debe obtener la longitud y latitud de esta ubicación y analizar los puntos de interés circundantes. Luego etiquete los datos extraídos. Las anotaciones comunes incluyen: objetos, peatones, tipos de objetos, etc.
Estos datos etiquetados se utilizarán para el entrenamiento. Las tareas típicas incluyen detección de objetivos, detección de líneas de carril o modelos de extremo a extremo más grandes. Una vez entrenado el modelo, es necesario realizar alguna verificación de simulación. Después de la verificación, impleméntelo en el automóvil, ejecute los datos y recopile más datos en función de esto. Es un ciclo de ese tipo, que enriquece constantemente los datos y construye constantemente modelos con mejor rendimiento. Esto es lo que debe hacer todo el circuito cerrado de capacitación y datos, y también es el núcleo de la investigación y el desarrollo actuales de la conducción autónoma.
Entrenamiento de algoritmos: NAS
Nos centramos en el entrenamiento de modelos: el entrenamiento de modelos obtiene datos principalmente a través de la minería de datos para generar un conjunto de datos. El conjunto de datos es internamente un archivo pkl, que incluye datos, canal y ubicación de almacenamiento. Finalmente, los estudiantes que se capacitan en algoritmos de datos escribirán sus propios scripts de descarga para extraer los datos del almacenamiento de objetos al local.
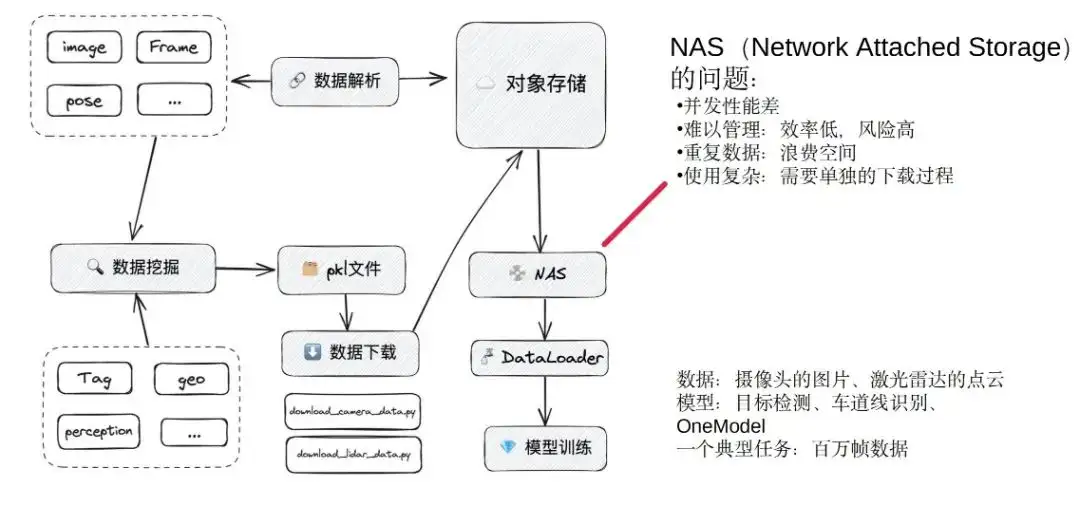
Antes de elegir Alluxio, usamos el sistema NAS para actuar como caché, extrayendo datos de almacenamiento de objetos al NAS y, finalmente, usando diferentes modelos para cargar los datos para el entrenamiento. Este es el proceso de formación aproximado antes de utilizar Alluxio.
Uno de los mayores problemas en NAS:
- El rendimiento de concurrencia es relativamente pobre : podemos entender NAS como un disco duro grande, lo cual es suficiente cuando solo se ejecutan unas pocas tareas juntas. Sin embargo, cuando se realizan docenas de tareas de entrenamiento simultáneamente y se entrenan muchos modelos, a menudo se producen atascos. Hubo un momento en el que estábamos muy estancados y el equipo de I+D se quejaba todos los días. Está tan estancado que la disponibilidad y el rendimiento de concurrencia son muy pobres.
- Dificultad de gestión : cada uno utiliza su propio script descargado y luego descarga los datos deseados en su propio directorio. Otra persona puede descargar otra pila de datos por sí misma y colocarla en otro directorio del NAS. Esto dificultará la limpieza cuando el espacio del NAS esté lleno. En ese momento, básicamente nos comunicábamos en persona o en grupos de WeChat. Por un lado, la eficiencia es extremadamente baja y depender de la gestión de mensajes grupales se quedará atrás. Por otro lado, la extracción manual también puede conllevar algunos riesgos. Hemos tenido situaciones en las que se eliminaron conjuntos de datos de otras personas al eliminar datos. Esto también provocará errores en el área de tareas en línea, que es otro punto débil.
- Desperdicio de espacio : los datos descargados por diferentes personas se colocan en diferentes directorios. Es posible que el mismo marco de datos aparezca en varios conjuntos de datos, lo que genera un grave desperdicio de espacio.
- Es muy complicado de usar , porque los formatos de archivo en pkl son diferentes, la lógica de descarga también es diferente y todos tienen que escribir el programa de descarga por separado.
Estas son algunas de las dificultades y problemas que enfrentamos antes al usar NAS. Para resolver estos problemas, investigamos. Después de la investigación, nos centramos en Alluxio. Descubrí que Alluxio puede proporcionar un caché relativamente unificado. El caché puede mejorar nuestra velocidad de entrenamiento y reducir los costos de administración. También utilizaremos el sistema Alluxio para solucionar el problema de las salas de ordenadores duales. A través del espacio de nombres unificado y los métodos de acceso, por un lado, el diseño de nuestro sistema se puede simplificar y, por otro lado, la implementación del código también será muy simple.
Entrenamiento de algoritmos introducido en Alluxio
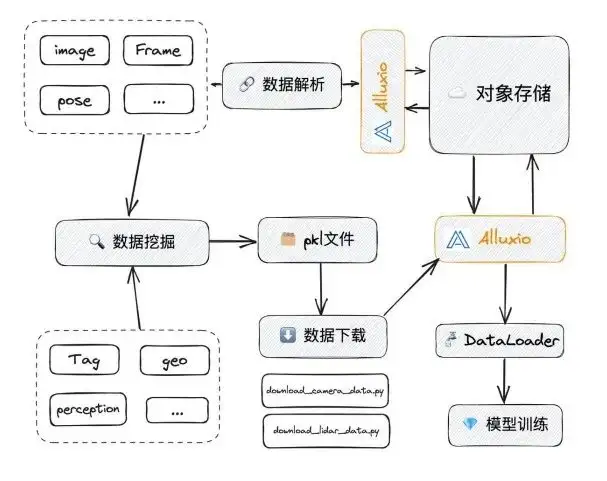
Cuando reemplazamos NAS con Alluxio, Alluxio puede resolver específicamente algunos de los problemas que acabamos de mencionar:
- En términos de concurrencia: NAS en sí no es un sistema completamente distribuido, pero Alluxio sí lo es. Cuando el IO al que accede el NAS alcanza una cierta velocidad, se congelará. Puede comenzar a congelarse cuando alcance varios G/s. El límite superior de Alluxio es muy alto. Tenemos pruebas especiales a continuación para ilustrar este punto.
- La limpieza o gestión manual será muy problemática: Alluixo configura la política de desalojo de caché. Por lo general, a través de LRU, cuando alcanza un umbral (como 90%), desalojará y limpiará automáticamente el caché. El efecto de esto:
- La eficiencia ha mejorado enormemente;
- Puede evitar problemas de seguridad causados por una eliminación accidental;
- Resolvió el problema de los datos duplicados.
En Alluxio, un archivo en UFS corresponde a una ruta en Alluxio. Cuando todos acceden a esta ruta, pueden obtener los datos correspondientes, por lo que no habrá problemas de datos duplicados. Además, usar lo anterior es relativamente simple. Solo necesitamos acceder a él a través de la interfaz FUSE y ya no necesitamos descargar archivos.
Lo anterior resuelve los diversos problemas de los que acabamos de hablar desde un nivel lógico. Hablemos de todo nuestro proceso de implementación, cómo realizar Alluxio de 0 a 1, desde las pruebas POC iniciales, hasta la verificación de diversos rendimientos, hasta la implementación, operación y mantenimiento finales. Algunas de nuestras experiencias prácticas.
Implementación de Alluxio: sala de ordenadores única
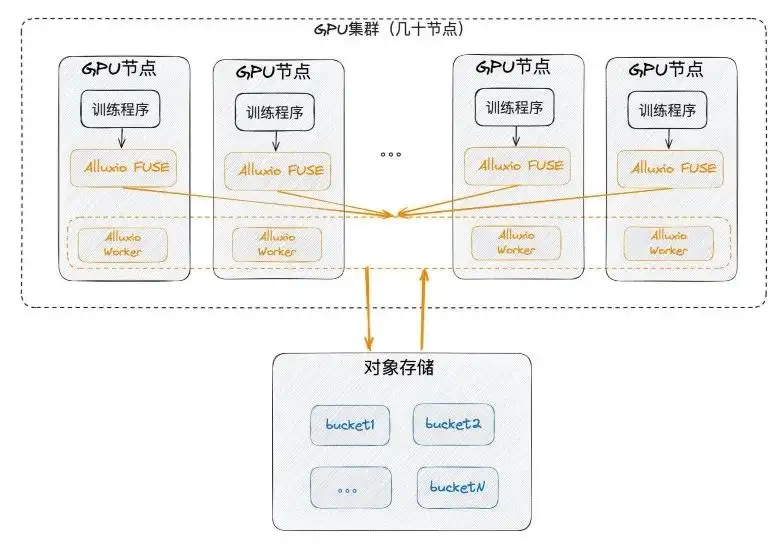
En primer lugar, podemos implementarlo en una sola sala de computadoras, lo que significa que debe estar cerca de la GPU e implementarse en el nodo de la GPU. Al mismo tiempo, se usó SSD, que antes rara vez se usaba en la GPU, para utilizar cada nodo, y luego FUSE y los trabajadores se implementaron juntos. FUSE es equivalente al cliente y el trabajador es equivalente a un pequeño clúster de caché con comunicación de intranet para proporcionar servicios FUSE. Finalmente, el trabajador se comunica con el propio almacenamiento de objetos subyacente.
Implementación de Alluxio: en salas de ordenadores
Pero por diversas razones, seguiremos teniendo salas de máquinas cruzadas. Ahora hay dos salas de computadoras, y cada sala de computadoras tendrá los servicios S3 correspondientes y los nodos informáticos GPU correspondientes. Básicamente implementaremos un Alluxio en cada sala de ordenadores. Al mismo tiempo, también debemos prestar atención a este proceso. Puede haber dos almacenes de objetos Alluxio en una sala de computadoras. Si otra sala de computadoras también necesita montar S3, intente hacer un plan unificado para los nombres de los depósitos, no lo haga. sobrecargar a los dos. Por ejemplo, si hay un depósito 1 aquí y un depósito 1 allá, causará algunos problemas cuando se monte Alluxio.
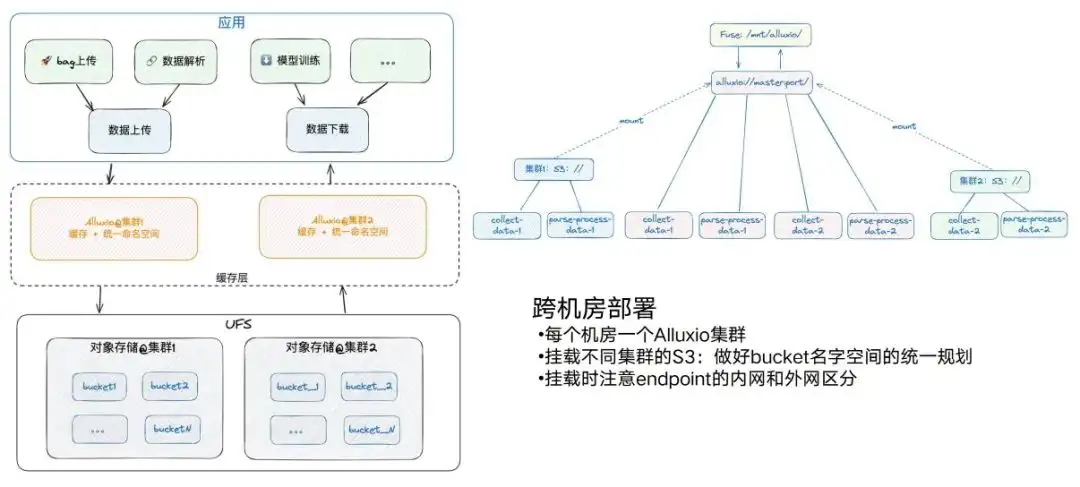
También tenga en cuenta que para diferentes puntos finales, preste atención a la distinción entre la red interna y la red externa. Por ejemplo, Alluxio del grupo 1 monta la red interna del punto final del grupo 1 y la red externa está en el otro lado. , el rendimiento se reducirá considerablemente. Después del montaje, podemos acceder a los datos de diferentes depósitos en diferentes clústeres a través de la misma ruta, de modo que toda la arquitectura será muy simple en términos de implementación entre salas de máquinas.
Pruebas de Alluxio: funcionalidad
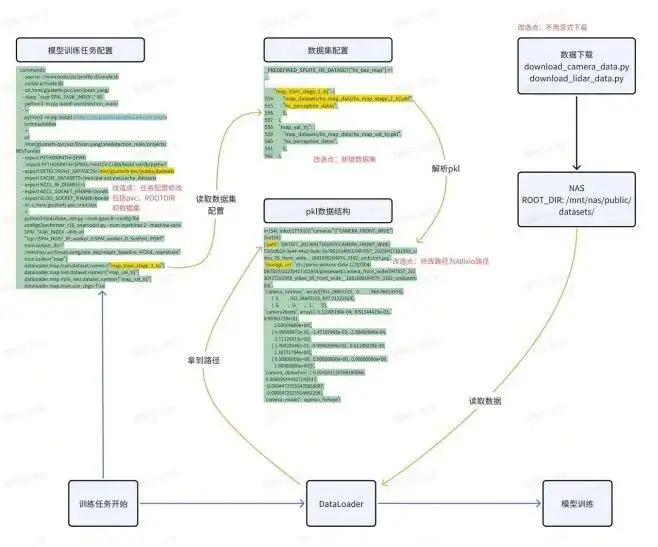
Si realmente desea reemplazar su NAS con Alluxio, debe realizar muchas pruebas funcionales antes de la implementación. El propósito de este tipo de prueba funcional es modificar mínimamente el proceso del algoritmo existente para que los estudiantes de algoritmos también puedan usarlo. Esto puede depender de su situación real. Hicimos casi 2 o 3 semanas de verificación POC con Alluxio, que implicó, por ejemplo:
- Configuración de acceso a PVC en K8S;
- Cómo está organizado el conjunto de datos;
- Configuración de envío de trabajos;
- Reemplazo de vías de acceso;
- Finalmente se accedió a la interfaz de secuencias de comandos.
Es posible que sea necesario verificar muchos de los problemas encontrados anteriormente. Al menos debemos seleccionar una tarea típica a través de ella, luego realizar algunas modificaciones y finalmente reemplazar el NAS con Alluxio con relativa facilidad.
Prueba Alluxio: Rendimiento
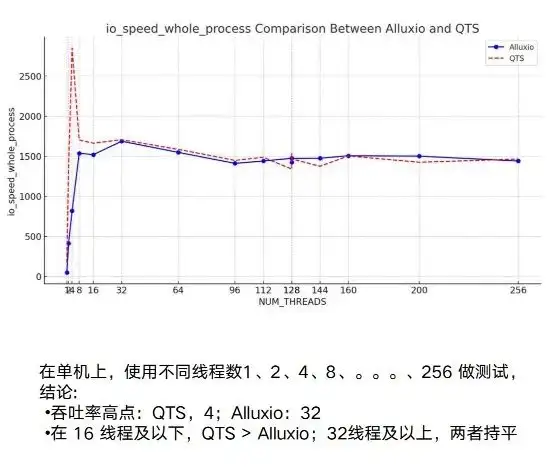
A continuación, sobre esta base, se realizarán algunas pruebas de rendimiento. En este proceso, hemos realizado pruebas relativamente suficientes, ya sea en una sola máquina o en varias máquinas. En una sola máquina, el rendimiento de Alluxio y el NAS original es básicamente el mismo.
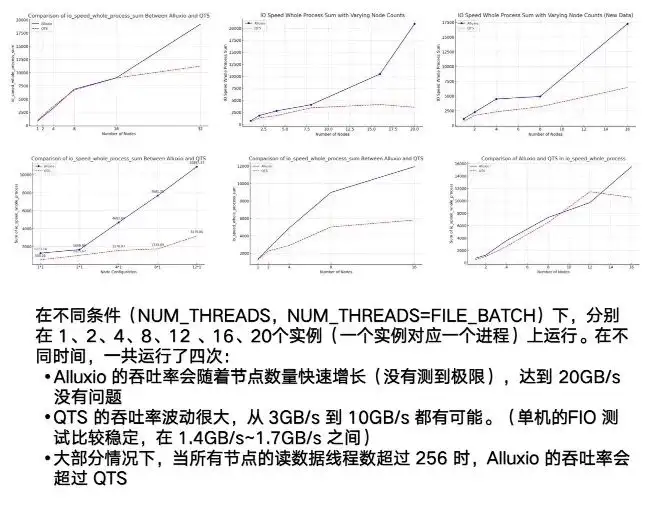
De hecho, lo que realmente representa las ventajas de Alluxio son sus capacidades distribuidas y de host múltiple. Puedes ver NAS o nuestro ejemplo de QTS, que tiene un punto muy obvio: la inestabilidad. La fluctuación entre las pruebas de 3G y 10G será relativamente grande. Al mismo tiempo, tendrá un cuello de botella obvio. Cuando alcance aproximadamente 7/8G, será básicamente estable.
De hecho, lo que realmente representa las ventajas de Alluxio son sus capacidades distribuidas y de host múltiple. Puedes ver NAS o nuestro ejemplo de QTS, que tiene un punto muy obvio: la inestabilidad. La fluctuación entre las pruebas de 3G y 10G será relativamente grande. Al mismo tiempo, tendrá un cuello de botella obvio. Cuando alcance aproximadamente 7/8G, será básicamente estable.
En cuanto a Alluxio, durante todo el proceso de prueba, a medida que aumenta el número de instancias en ejecución, el nodo puede alcanzar un límite superior muy alto. Cuando lo configuramos en 20 GB/s, todavía mostró una tendencia ascendente. Esto muestra que el rendimiento general concurrente y distribuido de Alluxio es muy bueno.
Aterrizaje Alluxio: ajustando parámetros y adaptando el entorno
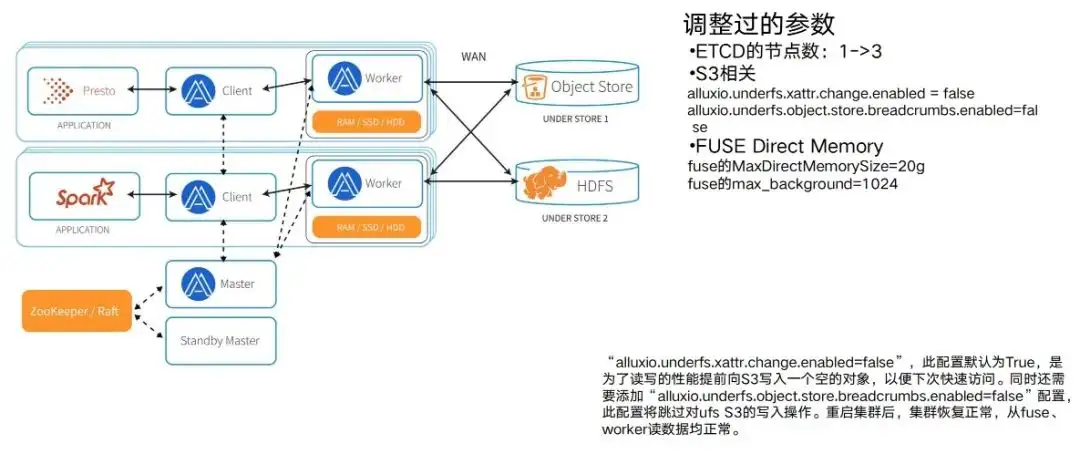
Después de completar la verificación funcional y las pruebas de rendimiento, es hora de implementar el clúster Alluxio. Después de la implementación, se requiere un proceso de ajuste y adaptación de parámetros. Porque durante la prueba, solo se utilizaron algunas tareas típicas. Después de usar realmente el entorno Alluxio, encontrará que a medida que aumentan las tareas, habrá un proceso de ajuste y adaptación de parámetros. Es necesario hacer coincidir los parámetros correspondientes en Alluxio con el entorno operativo real antes de que se pueda utilizar completamente su rendimiento. Por lo tanto, habrá un proceso de ejecución, operación, mantenimiento y ajuste de parámetros.
Hemos pasado por algunos procesos típicos de ajuste de parámetros, como:
- Los nodos de ETCD se enumeran aquí. Es 1 al principio y luego cambia a 3. Esto garantiza que sea un ETCD el que esté colgado y que todo el clúster no esté colgado.
- También los hay relacionados con S3. Por ejemplo, cuando se implemente Alluxio, permitirá que S3 genere una ruta de acceso relativamente larga y escriba algunos espacios en blanco de forma predeterminada en los nodos de la ruta intermedia para brindarle un mejor rendimiento. Pero en este caso, el S3 bajo nuestra tarea de entrenamiento tiene control de permisos y no puede escribir este tipo de datos. Ante este tipo de conflictos también es necesario un ajuste de parámetros.
- También hay capacidades como la intensidad de concurrencia que el propio nodo FUSE puede tolerar. Incluyendo el tamaño de la Memoria Directa que utiliza, en realidad tiene mucho que ver con la intensidad de concurrencia real de todo el negocio. En realidad, tiene mucho que ver con la cantidad de datos a los que se puede acceder al mismo tiempo. También existe un proceso de ajuste de parámetros, etc. Se pueden encontrar diferentes problemas en diferentes entornos. Esta es también la razón para elegir Alluxio Enterprise Edition. Debido a que Alluxio tendrá un soporte muy sólido durante la versión empresarial, puede adaptarse y cooperar cuando encuentre problemas las 24 horas del día, los 7 días de la semana. Sólo con ciclos mutuamente coordinados puede todo el grupo funcionar mejor.
Implementación de Alluxio: operación y mantenimiento.
El primer compañero de operación y mantenimiento de nuestro equipo solo tenía una persona, que era responsable de gran parte del mantenimiento de infraestructura subyacente y el trabajo relacionado. Cuando quise implementar Alluxio, los recursos en el lado de operación y mantenimiento en realidad no eran suficientes, por lo que era equivalente. Para mí también hago trabajo a tiempo parcial. Desde la perspectiva de operar y mantener algo usted mismo, es importante mantener muchos registros y conocimientos sobre operación y mantenimiento, especialmente para un principiante. Por ejemplo, cómo resolver mejor el problema la próxima vez y si ya ha tenido esa experiencia antes.
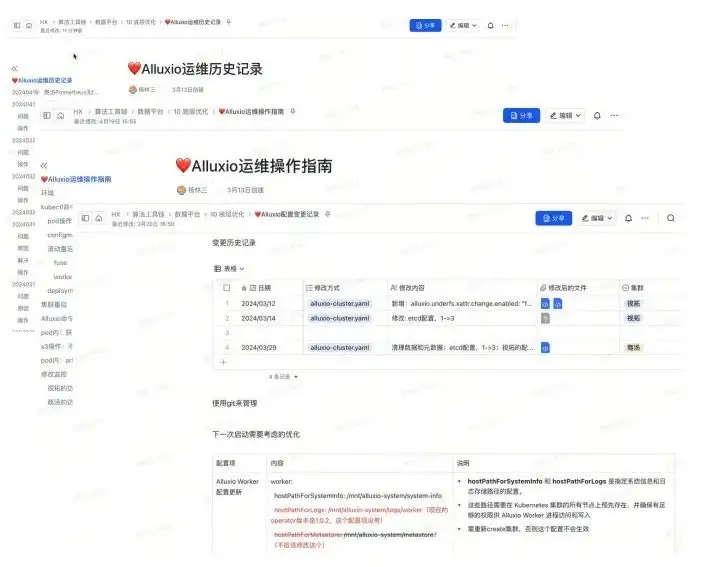
Según nuestro entorno en ese momento, se mantendrán tres documentos.
- Documentos históricos de operación y mantenimiento : por ejemplo, ¿qué problemas ocurrieron en qué día? ¿Cuál es la causa raíz de estos problemas y cuál es su solución? ¿Cuáles son las operaciones específicas?
- Documentación de operación : por ejemplo, si operamos y mantenemos K8S, cuáles son los pasos para reiniciarlo, cuáles son las operaciones, cómo leer los registros cuando ocurren problemas, cómo solucionar problemas y qué tarea y trabajo se deben ejecutar para ver. los datos correspondientes a FUSE, monitorización, etc. Estas son algunas operaciones de uso común.
- Cambios de configuración: Porque Alluxio está en proceso de ajustar parámetros. En diferentes momentos, puede encontrar diferentes archivos de configuración y archivos yaml, y es posible que necesite realizar algunas copias de seguridad. Puedes usar Git para administrarlo, o simplemente puedes usar la administración de documentos. De esta manera es posible rastrear la configuración actual y las versiones de configuración históricas.
Sobre esta base, también tendremos algunas construcciones de soporte relacionadas para utilizar mejor Alluxio. Los estudiantes de I+D piensan que Alluxio es bastante fácil de usar después de usarlo. Pero cuando se realizan múltiples tareas, algunas necesidades de construcción de apoyo quedan expuestas. Por ejemplo, necesitamos cambiar el tamaño de la imagen y reducirla de alta definición 4K a 720P para admitir más almacenamiento en caché de tareas.
El conjunto de datos de entrenamiento se sincroniza entre clústeres para una mejor precarga de datos. Todos estos se centran en la construcción sistemática que Alluxio necesita realizar.
Desembarco de Alluxio: avanzando juntos
A medida que sigamos usando Alluxio, también encontraremos algunas áreas dignas de mejora. Al brindar comentarios a Alluxio, hemos promovido la iteración de todo el producto. Aquí hay algunos puntos en particular:
De los estudiantes que desarrollan algoritmos, lo que les importa es:
- Estabilidad: debe ser estable durante la operación. No puede obstaculizar el entrenamiento de todo el sistema debido a que algo falle en Alluxio. Puede haber algunos consejos de operación y mantenimiento aquí, como intentar no reiniciar FUSE tanto como sea posible. Como se mencionó hace un momento, reiniciar FUSE significa que su ruta de acceso fallará y se producirá un error de IO al leer archivos de datos.
- Determinismo: por ejemplo, Alluxio sugirió anteriormente que no es necesario precargar los datos, es decir, no es necesario leerlos una vez antes del entrenamiento previo, solo es necesario leerlos una vez durante la primera época. Sin embargo, debido a que I+D tiene un ciclo de lanzamiento, necesita saber exactamente cuánto tiempo llevará la precarga. Si lo lee durante la primera época, es difícil estimar el tiempo total de entrenamiento. En realidad, esto también se extiende a cómo almacenar en caché a través de una lista de archivos. Esto también impone algunas exigencias a Alluxio.
- Controlabilidad: Aunque Alluxio puede proporcionar desalojo y limpieza de caché automatizados basados en LRU. Pero, de hecho, I+D todavía espera que algunos datos que se han almacenado en caché puedan limpiarse de forma proactiva. Entonces, ¿también puedes permitir que Alluxio libere estos datos proporcionando una lista de archivos? Esta es también nuestra necesidad de usar Alluxio directamente y de una manera muy controlable además del uso indirecto.
Desde el lado de operación y mantenimiento también se plantearán algunos requisitos:
- Centro de configuración: el propio Alluxio puede proporcionar un centro de configuración para guardar el historial de configuración. Al agregar una función para implementar cambios en los elementos de configuración, presupuesta de antemano qué impacto tendrá este cambio;
- Trace rastrea el proceso de ejecución de un comando: otro requisito más realista. Por ejemplo, ahora encontramos un problema: el retraso al acceder a un archivo UFS en la parte inferior es relativamente alto. Es posible que no podamos ver el motivo al mirar los registros de FUSE, por lo que debemos mirar los registros de trabajadores correspondientes a la ubicación. En realidad, este es un proceso problemático y que requiere mucho tiempo, y el problema a menudo no se puede resolver, por lo que se requiere el servicio de atención al cliente en línea de Alluxio. ¿Puede Alluxio agregar un comando Trace para rastrear los problemas de FUSE, el trabajo y la lectura desde UFS que consumen mucho tiempo al acceder al enlace completo? En realidad, esto será de gran ayuda para todo el proceso de operación y mantenimiento o para el proceso de resolución de problemas.
- Monitoreo inteligente: A veces las cosas que monitoreamos son cosas que ya sabemos. Por ejemplo, si hay un problema con la Memoria Directa, configuremos un elemento de monitoreo. Pero la próxima vez que aparezca un nuevo problema en mi registro, podría ser un problema oculto que ocurre silenciosamente sin que nadie lo sepa. Esperamos monitorear automáticamente esta situación.
Le hicimos varias sugerencias a Alluxio a través de comentarios sobre las órdenes de trabajo. Se espera que Alluxio pueda proporcionar funciones más potentes durante el proceso de iteración del producto. Hacer que todos los asuntos de I+D, operación y mantenimiento sean más satisfactorios.
resumen
En primer lugar, Alluxio proporciona muy buena usabilidad en comparación con NAS en términos de aceleración de almacenamiento en caché para todo el entrenamiento del modelo de conducción autónoma. Para nosotros también será una mejora de 10 veces. La reducción de costes proviene de dos partes:
- El costo de adquisición del producto es bajo;
- El NAS puede tener entre un 20 % y un 30 % de almacenamiento redundante, lo que Alluxio puede solucionar.
Desde la perspectiva de la mantenibilidad, puede limpiar datos automáticamente, lo cual es más oportuno y seguro. En términos de facilidad de uso, puede acceder a los datos de manera más conveniente a través de FUSE.
En segundo lugar, también compartí cómo Huixi implementa Alluxio de 0 a 1 y cómo opera y mantiene un sistema.
Lo anterior es mi participación, gracias a todos.
