

Autor de este artículo:
Tarik Bennett, Beinan Wang, Hope Wang
Este artículo analizará los desafíos del acceso a datos en la inteligencia artificial (IA) y revelará que "el NAS/NFS de uso común puede no ser la mejor opción " .
1. Arquitectura temprana de inteligencia artificial/aprendizaje automático
La investigación de Gartner muestra que, aunque los modelos de lenguajes grandes (LLM) han atraído mucha atención, la mayoría de las organizaciones todavía se encuentran en las primeras etapas de uso de modelos grandes y solo algunas han entrado en la etapa de producción.
El objetivo de construir una plataforma de IA en las primeras etapas es hacer que el sistema funcione para que se puedan realizar proyectos piloto y pruebas de conceptos. Estas primeras arquitecturas, o arquitecturas de preproducción, están diseñadas para satisfacer las necesidades básicas de capacitación e implementación de modelos. Actualmente, muchas organizaciones ya están utilizando este tipo de arquitectura de IA temprana para entornos de producción.
A medida que los datos y los modelos crecen, las primeras arquitecturas de IA a menudo se vuelven ineficientes. Las empresas entrenan modelos en la nube y, a medida que los proyectos se expanden, se espera que su uso de datos y de la nube aumente significativamente dentro de 12 meses. Muchas organizaciones comienzan con volúmenes de datos que coinciden con sus tamaños de memoria actuales, pero son conscientes de la necesidad de prepararse para cargas mayores.
Las empresas pueden optar por utilizar una pila de tecnología existente o una implementación totalmente nueva. Este artículo se centrará en cómo utilizar su pila de tecnología existente o comprar hardware adicional para diseñar una pila de tecnología más escalable, ágil y eficaz.
2. Desafíos en el acceso a los datos
Con la evolución de la arquitectura AI/ML, el tamaño de los conjuntos de datos de entrenamiento de modelos continúa creciendo significativamente, y la potencia informática y la escala de las GPU también están aumentando rápidamente. Además de la informática, el almacenamiento y la red, creemos que el acceso a los datos es otro elemento clave en la construcción de una plataforma de IA con visión de futuro .

El acceso a datos se refiere a tecnologías como servicios de datos, almacenamiento de respaldo (NFS, NAS) y caché de alto rendimiento (como Alluxio) que ayudan al motor informático a obtener datos para el entrenamiento y la implementación del modelo.
El enfoque del acceso a los datos es el rendimiento y la eficiencia de la carga de datos, lo cual es cada vez más importante para las arquitecturas AI/ML donde los recursos de GPU son escasos : la optimización de la carga de datos puede reducir en gran medida el tiempo de espera inactivo de la GPU y mejorar la utilización de la GPU. Por lo tanto, el acceso a datos de alto rendimiento debería ser el objetivo principal de la implementación de la arquitectura.
A medida que las empresas amplían las tareas de capacitación de modelos en las primeras arquitecturas de IA, han surgido algunos desafíos comunes en el acceso a los datos:
1
La eficiencia del entrenamiento del modelo es menor de lo esperado: debido a los cuellos de botella en el acceso a los datos, el tiempo de entrenamiento es mayor que el estimado en función de los recursos informáticos. Los flujos de datos de bajo rendimiento no proporcionan suficientes datos a la GPU.
2
Cuellos de botella relacionados con la sincronización de datos: copiar o sincronizar manualmente datos desde el almacenamiento a un servidor GPU local genera retrasos en la creación de la cola de datos que se debe preparar.
3
Problemas de simultaneidad y metadatos: cuando se lanzan trabajos grandes en paralelo, pueden producirse conflictos en el almacenamiento compartido. La latencia aumenta cuando las operaciones de metadatos en el almacén backend son lentas.
4
Rendimiento lento o baja utilización de GPU: la infraestructura de GPU de alto rendimiento requiere una gran inversión y, una vez que el acceso a los datos es ineficiente, generará recursos de GPU inactivos y subutilizados.
Además, estos desafíos se ven agravados por una serie de otras cuestiones que los equipos de datos deben gestionar. Estos problemas incluyen velocidades lentas de E/S de almacenamiento que no pueden satisfacer las necesidades de los clústeres de GPU de alto rendimiento. Depender de la copia y sincronización manual de datos aumenta la latencia mientras el equipo de datos espera que los datos se entreguen al servidor de GPU. El desafío del acceso a los datos también se ve agravado por la complejidad arquitectónica de múltiples silos de datos en infraestructuras híbridas o entornos de múltiples nubes.
En última instancia, estos problemas dan como resultado que la eficiencia de extremo a extremo de la arquitectura no cumpla con las expectativas.
Los desafíos relacionados con el acceso a los datos suelen tener dos soluciones comunes.
Compre almacenamiento más rápido: muchas empresas intentan resolver el problema del acceso lento a los datos implementando opciones de almacenamiento más rápidas. Los proveedores de nube ofrecen almacenamiento de alto rendimiento, mientras que los proveedores de hardware profesionales venden almacenamiento HPC para mejorar el rendimiento.
Agregue NAS/NFS además del almacenamiento de objetos: Agregar NAS o NFS centralizado como respaldo al almacenamiento de objetos como S3, MinIO o Ceph es una práctica común y ayuda a los equipos a consolidar datos en sistemas de archivos compartidos, simplificando la colaboración y el intercambio de usuarios y cargas de trabajo. Además, también puede aprovechar las funciones de gestión de datos relacionadas, como coherencia, disponibilidad, copia de seguridad y escalabilidad de los datos, proporcionadas por proveedores de NAS maduros.
Sin embargo, es posible que estas dos soluciones comunes anteriores no resuelvan su problema.
Aunque un almacenamiento más rápido y NFS/NAS centralizado pueden lograr gradualmente algunas mejoras de rendimiento, también existen desventajas.
1
Un almacenamiento más rápido significa migración de datos, lo que fácilmente puede generar problemas de confiabilidad de los datos.
Para aprovechar el alto rendimiento que ofrece el almacenamiento dedicado, los datos se deben migrar del almacenamiento existente a un nuevo nivel de almacenamiento de alto rendimiento. Esto hace que los datos se migren en segundo plano. La migración de grandes conjuntos de datos puede provocar tiempos de transferencia prolongados y problemas de confiabilidad de los datos, como corrupción o pérdida de datos durante la migración. Mientras el equipo espera a que se complete la sincronización de datos, pausar las operaciones puede interrumpir el servicio y ralentizar el progreso del proyecto.
2
NFS/NAS: Mantenimiento y cuellos de botella
Como capa de almacenamiento adicional, persisten los desafíos de mantenimiento, estabilidad y escalabilidad de NFS/NAS. Copiar datos manualmente desde NFS/NAS a un servidor GPU local aumentará la latencia y desperdiciará recursos causados por copias de seguridad repetidas. Los aumentos repentinos en la demanda de lectura causados por trabajos paralelos pueden agrupar servidores NFS/NAS y servicios interconectados. Además, todavía existen problemas de sincronización de datos en clústeres de GPU NFS/NAS remotos.
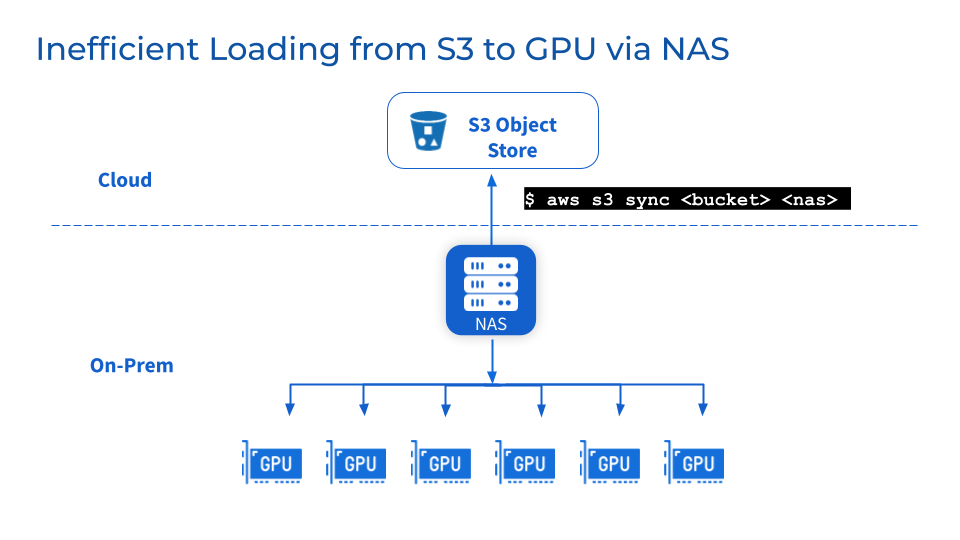
3
¿Qué pasa si necesito cambiar de proveedor por motivos comerciales?
Las empresas pueden cambiar de proveedor por motivos de optimización de costes o contractuales. La flexibilidad de los entornos de múltiples nubes requiere la capacidad de transferir fácilmente grandes conjuntos de datos sin depender de ningún proveedor. Sin embargo, trasladar el almacenamiento de datos a escala de petabytes puede provocar un tiempo de inactividad significativo y una interrupción en el desarrollo del modelo.
En resumen, las soluciones existentes, si bien son útiles a corto plazo, no pueden proporcionar una arquitectura de acceso a datos escalable y optimizada para satisfacer el crecimiento exponencial de las necesidades de datos de AI/ML.
3. Soluciones proporcionadas por Alluxio
Alluxio se puede implementar entre fuentes informáticas y de datos. Proporcione abstracción de datos y almacenamiento en caché distribuido para mejorar el rendimiento y la escalabilidad de la arquitectura AI/ML.
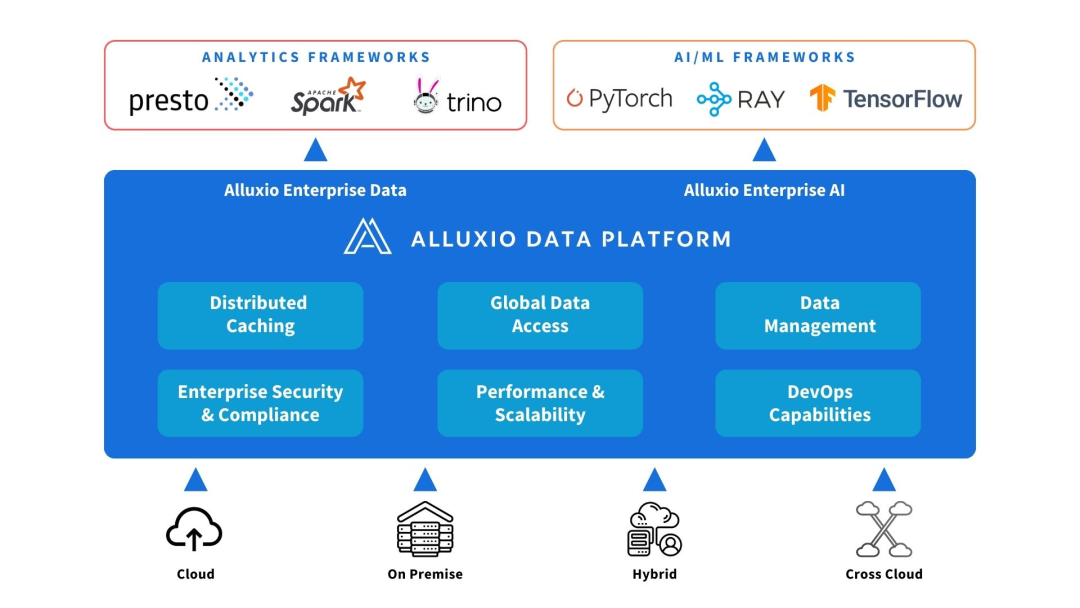
Alluxio ayuda a resolver los desafíos que enfrentan las primeras arquitecturas de IA en escalabilidad, rendimiento y gestión de datos a medida que aumenta la cantidad de datos, la complejidad del modelo y los clústeres de GPU.
1
incrementar la capacidad
Alluxio escala más allá del límite de un solo nodo para acomodar conjuntos de datos de entrenamiento más grandes que los que pueden acomodar la memoria del clúster o los SSD locales. Conecta diferentes sistemas de almacenamiento y proporciona una capa de acceso a datos unificada para montar lagos de datos a nivel de petabytes. Alluxio almacena en caché de forma inteligente los archivos y metadatos de uso frecuente en niveles de memoria y SSD cercanos al proceso, eliminando la necesidad de copiar todo el conjunto de datos.
2
Reducir la gestión de datos
Alluxio simplifica el movimiento y el almacenamiento de datos entre clústeres de GPU mediante el almacenamiento en caché distribuido automatizado. Los equipos de datos no necesitan copiar ni sincronizar datos manualmente con archivos provisionales locales. El clúster Alluxio puede capturar automáticamente archivos u objetos activos en una ubicación cercana al nodo informático sin pasar por operaciones complejas de flujo de trabajo. Alluxio simplifica los flujos de trabajo incluso con 50 millones o más de objetos por nodo.
3
Mejorar el rendimiento
Alluxio está diseñado para acelerar las cargas de trabajo, eliminando los cuellos de botella de E/S en el almacenamiento tradicional que limitan el rendimiento de la GPU. El almacenamiento en caché distribuido aumenta la velocidad de acceso a los datos en órdenes de magnitud. En comparación con el acceso al almacenamiento remoto a través de la red, Alluxio proporciona acceso a datos locales a nivel de memoria y SSD, mejorando así la utilización de la GPU.
En resumen, Alluxio proporciona una capa de acceso a datos escalable y de alto rendimiento que puede maximizar el uso de los recursos de GPU en escenarios de expansión de datos de IA/ML.
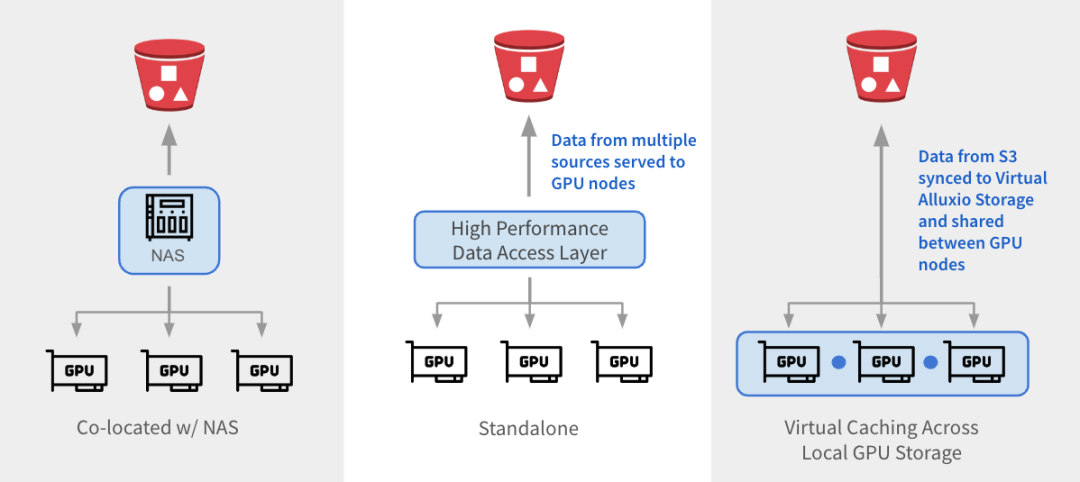
Alluxio se puede integrar con arquitecturas existentes de tres maneras.
1
与 NAS 并置:Alluxio 作为透明缓存层与现有 NAS并置部署,增强 I/O 性能。Alluxio将NAS中的活跃数据缓存在跨GPU节点的本地 SSD 中。作业将读取请求重新定向到Alluxio上的SSD缓存,绕过NAS,从而消除NAS瓶颈。写入操作通过 Alluxio 对 SSD 进行低延迟写入,然后异步持久化保存到 NAS中。
2
独立数据访问层:Alluxio 作为专用的高性能数据访问层,整合来自 S3、HDFS、NFS 或本地数据湖等多个数据源的数据,为GPU节点提供数据访问服务。Alluxio 将不同的数据孤岛统一在一个命名空间下,并将存储后端挂载为底层存储。经常访问的数据会被缓存在 Alluxio Worker节点的SSD中,从而加速GPU对数据的本地访问。
3
跨GPU存储的虚拟缓存:Alluxio充当跨本地GPU存储的虚拟缓存。S3中的数据会被同步到虚拟 Alluxio存储并在GPU节点之间共享,无需在节点之间手动拷贝数据。
1
参考架构
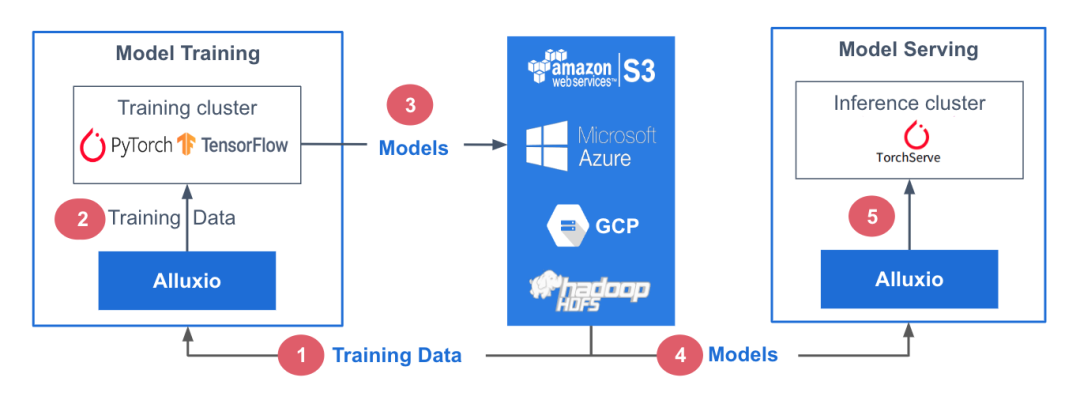
在此参考架构中,训练数据存储在中心化数据存储平台AWS S3中。Alluxio可帮助实现模型训练集群对训练数据的无缝访问。PyTorch、TensorFlow、scikit-learn和XGBoost等ML训练框架都在CPU/GPU/TPU集群上层执行。这些框架利用训练数据生成机器学习模型,模型生成后被存储在中心化模型库中。
在模型服务阶段,使用专用服务/推理集群,并采用TorchServe、TensorFlow Serving、Triton 和 KFServing等框架。这些服务集群利用Alluxio从模型存储库中获取模型。模型加载后,服务集群会处理输入的查询、执行必要的推理作业并返回计算结果。
训练和服务环境都基于Kubernetes,有助于增强基础设施的可扩展性和可重复性。
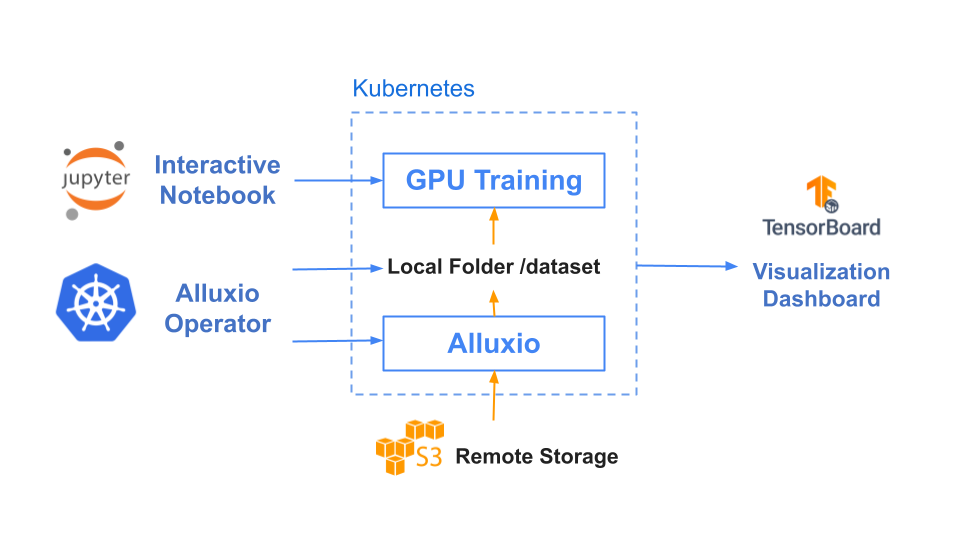
2
基准测试结果
在本基准测试中,我们用计算机视觉领域的典型应用场景之一——图片分类任务作为示例,其中我们以ImageNet的数据集作为训练集,通过ResNet来训练图片分类模型。
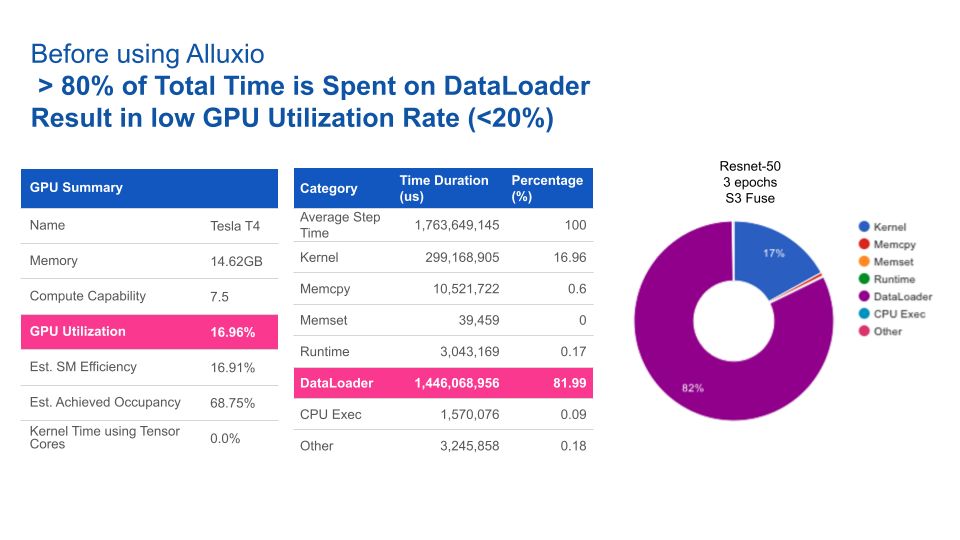
基于Resnet-50上3个epochs性能基准测试的结果,使用Alluxio比使用S3-FUSE的速度快5倍。一般来说,提高数据访问性能可缩短模型训练的总时间。
|
|
Alluxio |
S3 - FUSE |
|
Total training time (3 epochs) |
17 minutes |
85 minutes |
使用Alluxio后,GPU利用率得到大幅提升。Alluxio将数据加载时间由82%缩短至1%,从而将GPU利用率由17%提升至93%。
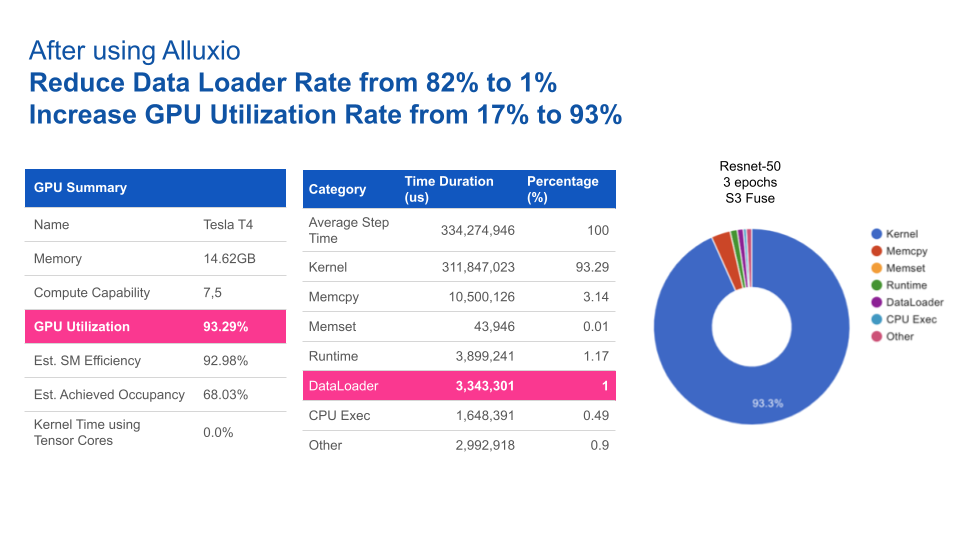
四、结论
随着AI/ML学习架构从早期的预生产架构向着可扩展架构发展,数据访问始终是瓶颈。仅靠添加更快的存储硬件或中心化NAS/NFS无法完全消除性能不达标以及影响系统操作的管理问题。
Alluxio提供了一种专为优化AI/ML任务数据流而设计的软件解决方案。与传统存储方案相比,其优势包括:
1
优化数据加载:Alluxio智能地加速训练任务和模型服务的数据访问,从而将GPU利用率最大化。
2
维护需求低:无需在节点或集群之间手动拷贝数据。Alluxio通过其分布式缓存层处理热文件传输。
3
支持扩展:当数据量大到需要扩展更多节点的情况下,Alluxio也能维持性能稳定。Alluxio通过使用SSD扩展内存,可缓存任何大小的文件,避免拷贝全部文件。
4
更快的切换:Alluxio将底层存储抽象化,使得数据团队能够轻松地在云厂商、本地或多云环境中迁移数据。数据迁移无需替换硬件,也不会导致停机。
部署Alluxio后,企业通过针对数据访问进行优化的数据架构,可以构建出性能卓越、可扩展的数据平台,从而加速模型开发,满足不断增长的数据需求。
✦
【近期热门】
✦

✦
【宝典集市】
✦






本文分享自微信公众号 - Alluxio(Alluxio_China)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。