Introducción : ArcGraph es una base de datos de gráficos distribuida con arquitectura nativa de la nube e inventario y análisis integrados. Este artículo explicará en detalle cómo ArcGraph puede hacer frente de manera flexible al análisis de gráficos con memoria limitada.
01 Introducción
Ahora que la tecnología de análisis de gráficos se utiliza ampliamente, los círculos académicos y los principales fabricantes de bases de datos de gráficos están interesados en mejorar los indicadores de alto rendimiento de la tecnología de análisis de gráficos. Sin embargo, en el proceso de búsqueda de computación de alto rendimiento, a menudo se adopta el método de "intercambiar espacio por tiempo", es decir, aumentar la cantidad de uso de memoria para acelerar los cálculos. Sin embargo, la computación de gráficos de memoria externa aún no está madura en esta etapa, y el análisis de gráficos todavía depende de la computación de memoria completa. Esto hace que los motores de computación de gráficos de alto rendimiento dependan en gran medida de una gran cantidad de memoria. Cuando la memoria es insuficiente, las tareas de análisis de gráficos. no será ejecutado.
En el pasado, hemos descubierto en muchos casos de clientes que los recursos de hardware que los clientes invierten en el análisis de gráficos suelen ser fijos y limitados, y que los recursos del entorno de prueba son más limitados que los del entorno de producción. Los requisitos de puntualidad de los clientes para el análisis de gráficos suelen ser T+1, que es un requisito típico de análisis fuera de línea. Por lo tanto, los clientes esperan que el motor de computación gráfica reduzca la demanda de recursos como CPU y memoria, en lugar de buscar un alto rendimiento del algoritmo, siempre que cumpla con T+1. Este es un gran desafío para la mayoría de los motores de computación gráfica. Los requisitos de CPU son relativamente fáciles de controlar, mientras que los requisitos de memoria son difíciles de optimizar significativamente en un ciclo de desarrollo corto.
ArcGraph también enfrenta los desafíos anteriores, pero a través del resumen y pulido continuos en las prácticas de entrega al cliente, nuestro motor de computación gráfica tiene la flexibilidad de equilibrar el procesamiento en el tiempo y el espacio. Actualmente, el motor de computación de gráficos integrado de ArcGraph lidera la industria en términos de indicadores de rendimiento del análisis de gráficos y aún se está optimizando y mejorando. A continuación, explicaremos cómo ArcGraph intercambia inteligentemente tiempo por espacio para hacer frente al análisis de gráficos en memoria limitada desde múltiples perspectivas, incluida la estructura de datos subyacente del motor y la invocación de algoritmos de nivel superior.
02 Selección del tipo de ID de punto
El motor de cálculo de gráficos ArcGraph admite tres tipos de ID de puntos: cadena, int64 e int32. La compatibilidad con el tipo de punto de cadena puede mejorar la compatibilidad con los datos de origen, pero en comparación con int64, aumentará el uso de memoria porque es necesario mantener en la memoria una tabla de asignación de ID de punto de cadena a int64. Si el tipo de punto especificado es int64, ArcGraph generará una tabla de mapeo int64 a partir del ID de punto de tipo cadena en los datos de origen y la colocará en la memoria externa. Solo se retendrán en la memoria los datos de borde de punto de tipo int64 mapeados. Una vez completado el cálculo, la tabla de mapeo se lee en la memoria y se restaura la identificación de la cadena. Por lo tanto, usar el ID de punto de tipo int64 aumentará el consumo de tiempo adicional para intercambiar la tabla de mapeo entre la memoria externa y la memoria, pero también reducirá significativamente el uso general de la memoria. El tamaño de la memoria guardada depende de la longitud y el punto del original. Volumen de datos.
Además, el motor de cálculo de gráficos ArcGraph también admite int32. Para escenarios en los que el número total de puntos de datos de origen es inferior a 40 millones, el uso de memoria se puede reducir aún más en aproximadamente un 30% en comparación con int64.
El siguiente es un ejemplo de cómo especificar el tipo de ID del punto de carga del gráfico en la API del algoritmo de gráfico de ejecución de ArcGraph:
curl -X 'POST' 'http://myhost:18000/graph-computing?reload=true&use_cache=true' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"algorithmName": "pagerank",
"graphName": "twitter2010",
"taskId": "pagerank",
"oid_type": "int64",
"subGraph": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"props": [],
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
]
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": []
}
]
},
"algorithmParams": {
}
}'
03 Activar la codificación Varint
La codificación Varint se utiliza para comprimir y codificar números enteros y es un método de codificación de longitud variable. Tomando int32 como ejemplo, normalmente se requieren 4 bytes para almacenar un valor. En la codificación Varint convencional, los últimos 7 bits de cada byte se utilizan para representar datos y el bit más alto es el bit de bandera.


- Si el bit más alto es 0, significa que los últimos 7 bits del byte actual son todos los datos y los bytes posteriores no tienen nada que ver con los datos. Por ejemplo, el entero 1 en la figura anterior solo requiere un byte para representar: 00000001, y los bytes posteriores no pertenecen a los datos del entero 1.
- Si el bit más alto es 1, significa que los bytes posteriores siguen formando parte de los datos. Por ejemplo, el número entero 511 en la imagen de arriba requiere 2 bytes para representar: 11111111 00000011, y los bytes posteriores son los datos de 131071.
Usando esta idea, los enteros de 32 bits se pueden representar con entre 1 y 5 bytes. En consecuencia, un entero de 64 bits se puede representar mediante entre 1 y 10 bytes. En escenarios de uso reales, la tasa de uso de números pequeños es mucho mayor que la de números grandes, especialmente para enteros de 64 bits. Por lo tanto, la codificación Varint normalmente puede lograr efectos de compresión significativos. Hay muchas variantes de codificación Varint y muchas implementaciones de código abierto.
El motor de cálculo de gráficos ArcGraph admite el uso de codificación Varint para comprimir el almacenamiento de datos en el borde de la memoria (principalmente CSR/CSC). Cuando la codificación Varint está activada, la memoria ocupada por los datos de borde se puede reducir significativamente, hasta aproximadamente un 50% en mediciones reales. Al mismo tiempo, la pérdida de rendimiento causada por la codificación y decodificación también alcanzará aproximadamente el 20%. Por lo tanto, antes de encenderlo, debe comprender claramente los escenarios de uso y las necesidades del cliente para asegurarse de que la pérdida de rendimiento causada por el ahorro de memoria esté dentro de un rango aceptable.
El siguiente es un ejemplo de codificación Varint para habilitar el cálculo de gráficos en la API de carga de gráficos de ArcGraph:
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true"
}'
04 Activar Perfect HashMap
La diferencia entre Perfect HashMap y otros HashMap es que utiliza Perfect Hash Function (PHF). La función H asigna N valores clave a M enteros, donde M>= N, y satisface H (clave1) ≠ H (clave2) ∀clave1, clave2, entonces la función es una función hash perfecta. Si M = N, entonces H es la función Hash mínima perfecta (MPHF para abreviar). En este momento, N valores clave se asignarán a N números enteros consecutivos.
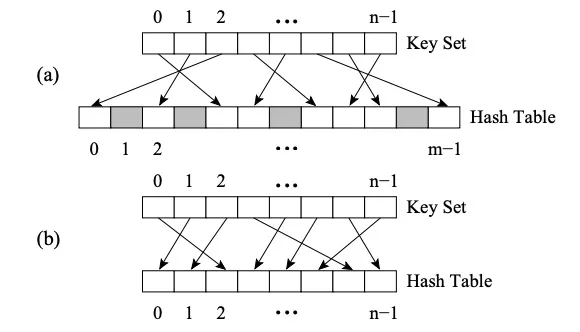 La imagen (a) es PHF, la imagen (b) es MPHF
La imagen (a) es PHF, la imagen (b) es MPHF
La imagen de arriba es la estrategia FKS de hash de dos niveles. Primero, los datos se asignan al espacio T a través del hash de primer nivel, y luego los datos en conflicto se seleccionan aleatoriamente y se asignan al espacio S usando una nueva función hash, y el tamaño m del espacio S es el cuadrado del conflicto. datos (por ejemplo, hay tres en T2. Si los números entran en conflicto, se asignan al espacio S2 donde m es 9. En este momento, es fácil encontrar una función hash que evite colisiones). La selección adecuada de la función hash reduce las colisiones durante el hash de un nivel, por lo que el espacio de almacenamiento esperado puede ser O(n).
El motor de cálculo de gráficos ArcGraph mantendrá una asignación desde la identificación del punto original a la identificación del punto interno en la memoria. El punto interno es un tipo entero largo continuo, lo cual es conveniente para la compresión de datos y la optimización de la vectorización. El mapeo es esencialmente un mapa hash, pero ArcGraph proporciona dos métodos en términos de implementación subyacente:
- Flat HashMap: la ventaja es que la velocidad de construcción es rápida, pero la desventaja es que generalmente requiere más espacio de memoria para reducir las frecuentes colisiones de hash.
- Perfect HashMap: la ventaja es que se puede usar menos memoria para garantizar una consulta con eficiencia O (1) en el peor de los casos, pero la desventaja es que es necesario conocer todas las claves de antemano y el tiempo de construcción es largo.
Por lo tanto, activar Perfect HashMap también puede lograr el propósito de intercambiar tiempo por espacio. Según la prueba, para el mapeo establecido desde el punto original hasta la ID del punto interno, el uso de memoria de Perfect HashMap suele ser solo aproximadamente 1/5 del de Flat HashMap, pero en consecuencia, su tiempo de construcción es 2-3 veces mayor.
El siguiente es un ejemplo de Perfect HashMap que permite el cálculo de gráficos en la API de carga de gráficos de ArcGraph:
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true",
"use_perfect_hash": "true"
}'
05 Implementación del algoritmo de optimización y procesamiento de resultados.
El uso de memoria en el nivel de implementación del algoritmo depende de la lógica específica del algoritmo. Hemos resumido los siguientes puntos de la práctica, que pueden lograr el propósito de intercambiar tiempo por espacio:
Reduzca adecuadamente los subprocesos múltiples y el uso de objetos ThreadLocal en el algoritmo. Los algoritmos a menudo implican el almacenamiento de colecciones temporales de puntos. Si estos almacenamientos aparecen en una lógica de subprocesos múltiples, la memoria general aumentará a medida que aumente el número de subprocesos. Reducir adecuadamente la cantidad de subprocesos simultáneos o reducir el uso de objetos grandes ThreadLocal ayudará a reducir la memoria. Incrementar adecuadamente el intercambio de datos entre la memoria interna y externa. De acuerdo con la lógica específica del algoritmo, los objetos grandes no utilizados temporalmente se serializan en la memoria externa y, cuando se usa el objeto, se lee en la memoria en forma de transmisión para evitar que varios objetos grandes ocupen una gran cantidad de memoria al mismo tiempo. tiempo.
El siguiente es un ejemplo de implementación de algoritmo que incorpora los dos puntos anteriores:
void IncEval(const fragment_t& frag, context_t& ctx,
message_manager_t& messages) {
...
...
if (ctx.stage == "Compute_Path"){
auto vertex_group = divide_vertex_by_type(frag);
//此处采用单线程for循环而非多线程并行处理,意在防止多个path_vector同时占内存导致OOM。
for(int i=0; i < vertex_group.size(); i++){
//此处path_vector是每个group中任意两点间的全路径,可理解为一个超大对象
auto path_vector = compute_all_paths(vertex_group[i]);
//拿到该对象后不会在当前stage使用,所以先序列化到外存中。
serialize_path_vector(path_vector, SERIALIZE_FOLDER);
}
...
...
}
...
...
if (ctx.stage == "Result_Collection"){
//在当前stage中,将之前stage生成的多个序列化文件合并为一个文件,并把文件路径返回。
auto result_file_path = merge_path_files(SERIALIZE_FOLDER);
ctx.set_result(result_file_path);
...
...
}
...
...
}
Una vez completado el cálculo, los resultados se escriben en la memoria externa y se libera la memoria relevante del motor de cálculo de gráficos. En algunos escenarios, el programa de procesamiento de resultados se ejecutará en el servidor del clúster de computación de gráficos para leer los resultados de la computación de gráficos y procesarlos posteriormente. Si la memoria del motor de cálculo gráfico no ha publicado los resultados del cálculo, en el peor de los casos, habrá dos copias de los datos del resultado en la memoria del servidor actual. En escenarios con grandes cantidades de datos, una copia de los datos del resultado ocupará una cantidad muy grande de memoria. Por lo tanto, en este tipo de escenario, se debe dar prioridad a escribir los resultados del cálculo en la memoria externa y liberar la memoria del motor de computación gráfica de manera oportuna.
Al mismo tiempo, el equipo de ArcGraph continuará desafiando la "necesidad y necesidad" de un alto rendimiento y un bajo uso de recursos, y trabajará con socios académicos e industriales para pulir aún más la memoria que transporta gráficos y la eficiencia informática para lograr más avances tecnológicos.
Google: La transición a Rust ha reducido significativamente las vulnerabilidades de Android. Se lanza PostgreSQL 17. Huawei anuncia que UBMC, el antiguo reproductor de música clásico , Winamp, se lanza oficialmente en 2024.2.3. ¿Se ha convertido en una marca registrada de Oracle? Open Source Daily | PostgreSQL 17; Cómo las empresas chinas de IA eluden la prohibición de chips de EE. UU. ¿Quién puede saciar la sed de los desarrolladores de IA? La startup "Zhihuijun" tiene AimRT de código abierto, un marco de desarrollo en tiempo de ejecución para el campo de la robótica moderna, Tcl/Tk 9.0, lanzó Meta y lanzó el modelo de IA multimodal Llama 3.2.