Parlons avec vous. Si vous voulez trouver un emploi bien rémunéré, il est le plus élémentaire d'acquérir de solides connaissances de base et des compétences professionnelles. Aujourd'hui, j'ai intégré quelques questions d'entrevue qui ont permis d'obtenir des emplois bien rémunérés dans de grandes usines et j'ai résumé les éléments essentiels de l'entretien suivant. Points de connaissance, j'espère que cela sera utile à tout le monde. {Il y a plusieurs questions sur les informations d'entretien à la fin de l'article}
1. Quelle est la différence entre String, StringBuffer et StringBuilder? Pourquoi String est-il immuable?
- String est une constante de chaîne, StringBuffer et StringBuilder sont des variables de chaîne. Le contenu de caractère des deux derniers est variable, tandis que le contenu du premier est immuable après la création.
- String est immuable car la classe String est déclarée comme classe finale dans le JDK.
- StringBuffer est thread-safe, tandis que StringBuilder n'est pas thread-safe.
Note supplémentaire: la sécurité des threads entraînera une surcharge système supplémentaire, donc StringBuilder est plus efficace que StringBuffer. Si vous savez si les threads du système sont sûrs, vous pouvez utiliser StringBuffer et ajouter le mot-clé Synchronize là où les threads ne sont pas sûrs.
2. Quelle est la différence entre Vector, ArrayList et LinkedList?
- Vector et ArrayList sont stockés en mémoire sous forme de tableaux, et LinkedList est stocké sous forme de listes liées.
- Les éléments de List sont ordonnés et les éléments répétitifs sont autorisés, tandis que les éléments de Set sont désordonnés et les éléments répétitifs ne sont pas autorisés.
- Le thread Vector est synchronisé et les threads ArrayList et LinkedList ne sont pas synchronisés.
- LinkedList convient aux opérations d'insertion et de suppression à un emplacement spécifié, mais pas à la recherche; ArrayList et Vector conviennent à la recherche, mais ne conviennent pas à l'insertion et à la suppression à un emplacement spécifié.
- ArrayList étendra automatiquement environ 50% de la taille du conteneur lorsque les éléments remplissent le conteneur, tandis que Vector est de 100%, donc ArrayList économise plus d'espace.
3. Quelle est la différence entre HashTable, HashMap et TreeMap?
- Synchronisation des threads HashTable, synchronisation HashMap sans thread.
- HashTable ne permet pas à <clé, valeur> d'avoir des valeurs nulles, HashMap permet à <clé, valeur> d'avoir des valeurs nulles.
- HashTable utilise Enumeration et HashMap utilise Iterator.
- La taille par défaut du tableau de hachage dans HashTable est 11, et la méthode d'augmentation est ancienne * 2 + 1. La taille par défaut du tableau de hachage dans HashMap est 16 et la méthode d'augmentation doit être un multiple exponentiel de 2.
- TreeMap peut trier les enregistrements qu'il enregistre en fonction de la clé, la valeur par défaut est l'ordre croissant.
Les trois questions ci-dessus sont toutes liées à certaines des structures de données les plus avancées du langage Java, de la corrélation de chaînes aux conteneurs en passant par les structures de données telles que les tables de hachage et les arbres. Par conséquent, lorsque nous apprenons le langage Java, nous devons également aller plus loin. Comparez les scénarios d'utilisation de structures de données similaires et leurs avantages et inconvénients.
4. Quelle est la différence entre Tomcat, Apache et JBoss?
- Apache est un serveur HTTP, Tomcat est un serveur Web et JBoss est un serveur d'applications.
- Apache analyse les fichiers Html statiques; Tomcat peut analyser les pages dynamiques jsp et peut également agir comme un conteneur.
Pour le serveur, l'interview n'est peut-être pas trop impliquée et, relativement parlant, les principes sous-jacents tels que Linx et Tomcat peuvent être plus favorisés par les intervieweurs.
5. La différence entre la demande GET et POST?
Connaissances de base: Le format de requête HTTP est le suivant.
Il contient principalement trois informations:
-
Le type de demande (GET ou POST)
-
La ressource à laquelle accéder (par exemple resimga.jif)
-
Version HTTP (http / 1.1)
la différence:
-
Get récupère les données du serveur et Post envoie les données au serveur.
-
Côté client, la méthode Get soumet les données via l'URL et le message de demande est visible dans la barre d'adresse URL. Le message a été codé; les données de publication sont soumises dans l'en-tête Html.
-
Pour la méthode Get, le serveur utilise Request.QueryString pour obtenir la valeur de la variable; pour la méthode Post, le serveur utilise Request.Form pour obtenir la valeur des données soumises.
-
Le nombre maximum de données soumises par Get est de 1024 octets, tandis que Post n'a pas de limite.
-
Les paramètres et les valeurs de paramètre soumis par la méthode Get seront affichés dans la barre d'adresse, ce qui n'est pas sûr, mais Post ne le sera pas, ce qui est relativement sûr.
6. Quelle est la différence entre Session et Cookie?
- La session est un espace de stockage côté serveur géré par le serveur d'applications; le cookie est l'espace de stockage côté client et est géré par le navigateur.
- L'utilisateur peut décider d'enregistrer le cookie via les paramètres du navigateur, mais ne peut pas décider d'enregistrer la session, car la session est gérée par le serveur.
- Les objets sont stockés dans Session et les chaînes sont stockées dans les cookies.
- La session et le cookie ne peuvent pas être utilisés dans plusieurs fenêtres. À chaque fois qu'un navigateur est ouvert, le système attribue un SessionID. À ce stade, le SessionID est différent. Pour terminer l'accès aux données entre les navigateurs, vous pouvez utiliser Application.
- La session et le cookie ont une date d'expiration et seront automatiquement supprimés après l'expiration, ce qui réduit la surcharge du système.
Sept, le message HTTP contient du contenu
Il se compose principalement de quatre parties:
-
ligne de demande
-
ligne d'en-tête
-
ligne blanche
-
demande de corps
Les trois questions ci-dessus sont les connaissances de base de la programmation réseau. En tant qu'ingénieur Java, vous devez également maîtriser les connaissances de HTTP, et maintenant HTTPS est également devenu un standard, et vous devez mieux comprendre. De plus, par rapport aux protocoles HTTP 1.0 / 1.1 que tout le monde a appris dans les manuels ou les salles de classe, de nombreuses entreprises sont entrées dans l'ère HTTP 2.0, donc la différence entre les deux nous oblige également à mieux comprendre.
Huit, cycle de vie du servlet
Grosso modo divisé en 4 parties: chargement de classe de servlet -> instanciation -> service -> destruction
Le diagramme de séquence de Servlet dans Tomcat est le suivant: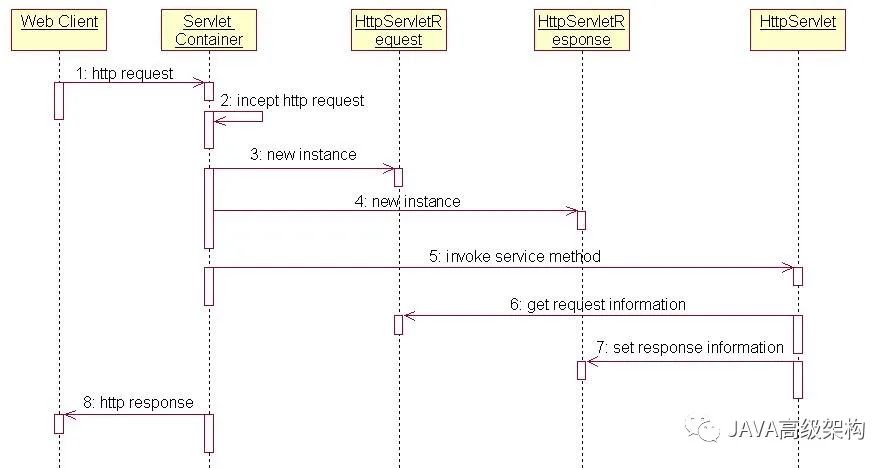
-
Le client Web envoie une requête HTTP au conteneur Servlet (Tomcat).
-
Le conteneur Servlet reçoit la demande du client.
-
Le conteneur Servlet crée un objet HttpRequest et encapsule les informations de demande du client dans cet objet.
-
Le servlet crée un objet HttpResponse.
-
Servlet appelle la méthode de service de l'objet HttpServlet, en passant l'objet HttpRequest et l'objet HttpResponse en tant que paramètres à l'objet HttpServlet.
-
HttpServlet appelle la méthode de l'objet HttpRequest pour obtenir la requête Http et la traiter en conséquence.
-
Après le traitement, HttpServlet appelle la méthode de l'objet HttpResponse et renvoie les données de réponse.
-
Le conteneur Servlet renvoie le résultat de la réponse de HttpServlet au client.
Trois des méthodes illustrent le cycle de vie d'un servlet:
- init (): Responsable de l'initialisation de l'objet Servlet.
- service (): Responsable de répondre aux demandes des clients.
- destroy (): Lorsque l'objet Servlet est lancé, il est responsable de la libération des ressources occupées.
9. La différence entre Statement et PreparedStatement, qu'est-ce que l'injection SQL et comment empêcher l'injection SQL?
- PreparedStatement prend en charge la définition dynamique des paramètres, mais pas Statement.
- PreparedStatement peut éviter les problèmes de codage tels que les guillemets simples, mais Statement ne le peut pas.
- PreparedStatement prend en charge la précompilation, contrairement à Statement.
- PreparedStatement n'est pas facile à vérifier lorsque l'instruction SQL est incorrecte, mais Statement est plus facile à vérifier.
- PreparedStatement peut empêcher SQL d'aider et est plus sécurisé, mais Statement ne le peut pas.
Explication supplémentaire - qu'est-ce que l'injection SQL et les contre-mesures:
Une méthode pour interroger des données de base de données sans paramètres via l'épissage d'instructions SQL. Si l'instruction SQL à exécuter est select * from table where name = "+ appName +", utilisez l'entrée de la valeur du paramètre appName pour générer une instruction SQL malveillante. Par exemple, transmettez ['or'1' = '1']. Exécuté dans la base de données. Par conséquent, vous pouvez utiliser PrepareStatement pour éviter l'injection SQL. Après avoir reçu les données de paramètre côté serveur, vérifiez-les. À ce stade, PrepareStatement sera automatiquement détecté, mais l'instruction ne fonctionne pas et nécessite une détection manuelle.
Ten, la différence entre sendRedirect et Foward
-
Le transfert est la redirection de la page de contrôle côté serveur et l'adresse redirigée ne sera pas affichée dans l'adresse du navigateur du client; sendRedirect est une redirection complète et le navigateur affichera l'adresse redirigée et renverra le lien de demande. Principe: Le transfert est le serveur qui demande des ressources. Le serveur accède directement à l'URL de l'adresse cible, lit le contenu de la réponse de cette URL, puis renvoie le contenu au navigateur. Le navigateur ne sait pas d'où vient le contenu envoyé par le serveur. Oui, la barre d'adresse est donc toujours l'adresse d'origine.
-
Rediriger signifie que le serveur envoie un code d'état basé sur la logique pour dire au navigateur de demander à nouveau l'adresse, et le navigateur renverra la nouvelle demande avec tous les paramètres tout à l'heure.
Les trois questions ci-dessus vont un peu plus loin sur les connaissances précédentes liées au réseau et permettent d'acquérir les connaissances pertinentes de la programmation de réseau Java. Cette partie vise à examiner la maîtrise par l'intervieweur des connaissances pertinentes de la programmation de réseau Java.
11. Parlez de la compréhension d'Hibernate, du rôle des caches primaire et secondaire, comment Hibernate utilise-t-il le cache dans le projet?
Hibernate est un framework de mapping objet-relationnel (ORM) développé. Il a une encapsulation très objet de JDBC, Hibernate permet aux programmeurs d'exploiter des bases de données relationnelles de manière orientée objet.
Avantages de Hibernate:
- Le programme est plus orienté objet
- Augmentation de la productivité
- Facile à transplanter
- Non invasif
Inconvénients de Hibernate:
- Légèrement moins efficace que JDBC
- Ne convient pas aux opérations par lots
- Une seule relation peut être configurée
Hibernate a quatre méthodes de requête:
- Les méthodes get et load interrogent l'objet en fonction du numéro d'identification.
- Langage de requête Hibernate, HQL
- Langage de requête standard
- Requête via SQL
Comment fonctionne Hibernate:
- Configurer le fichier de mappage objet-relationnel Hibernate, démarrer le serveur
- Le serveur lit le contenu de configuration du fichier hibernate.cfg.xml en instanciant l'objet Configuration et crée les tables et la relation de mappage entre les tables en fonction des exigences associées.
- Créez une instance SessionFactory via l'objet Configuration instancié et créez un objet Session via l'instance SessionFactory.
- La base de données est ajoutée, supprimée, modifiée et vérifiée via l'objet Session.
Transition d'état dans Hibernate:
état temporaire (transitoire)
- Pas dans le cache de session
- Aucun enregistrement d'objet dans la base de données
Explication supplémentaire sur la façon dont Java entre dans un état temporaire:
- Lors de la création d'un objet via la nouvelle instruction.
- Lorsque la méthode delete () de Session est appelée pour la première fois, lorsqu'un objet est supprimé du cache de session.
État persistant (persistant)
- Dans le cache de session
- Il n'y a pas d'enregistrement d'objet dans la base de données d'objets persistants
- La session enregistrera les deux synchronisations à un moment précis
Remarque supplémentaire sur la façon dont Java entre dans l'état persistant:
- Save () méthode de Session.
- Objet retourné par la méthode load (). Get () de Session.
- Les objets stockés dans la collection de listes retournés par la méthode Session find ().
- La méthode update (). Save () de Session.
Détaché
- Plus dans le cache de session
- Les objets libres sont transformés à partir de l'état persistant et il n'y a pas d'enregistrement correspondant dans la base de données.
Explication supplémentaire-comment Java entre dans l'état de déplacement:
- Session 的 close ()。
- La méthode evict () de Session supprime un objet du cache.
Le cache dans Hibernate comprend principalement le cache de session (cache de premier niveau) et le cache de SessionFactory (cache de second niveau, généralement fourni par un tiers).
12. Parlez de la différence entre Hibernate et iBatis, dont les performances seront plus élevées
- Hibernate préfère les opérations sur les objets pour atteindre l'objectif des opérations liées à la base de données; iBatis préfère l'optimisation des instructions SQL.
- L'instruction de requête utilisée par Hibernate est son propre HQL, tandis que iBatis est une instruction SQL standard.
- Hibernate est relativement compliqué et pas facile à apprendre; iBatis est similaire aux instructions SQL, simple et facile à apprendre.
Aspects de performance:
-
Si le système a un volume de traitement de données énorme et des exigences de performances extrêmement élevées, il est souvent nécessaire d'écrire manuellement des instructions SQL hautes performances ou des procédures de stockage d'erreurs. À ce stade, iBatis a une meilleure contrôlabilité, donc les performances sont meilleures que Hibernate.
-
Sous la même exigence, étant donné qu'Hibernate peut générer automatiquement des instructions HQL et qu'iBatis doit écrire des instructions SQL manuellement, l'efficacité de l'utilisation d'Hibernate est supérieure à celle d'iBatis.
13. Compréhension de Spring, qu'utilisez-vous dans le projet? Comment l'utiliser? Compréhension et mise en œuvre des principes de la COI et de l'AOP.
Spring est un framework open source dans la couche de contrôle du modèle MVC. Il peut faire face à des changements rapides des exigences. La principale raison est qu'il présente l'avantage de la programmation orientée aspect (AOP). Deuxièmement, il améliore les performances du système grâce au mécanisme d'inversion des dépendances ( IOC), les objets utilisés dans le système ne sont pas tous instanciés lorsque le système est chargé, mais les objets de cette classe seront instanciés lors de l'appel de cette classe, améliorant ainsi les performances du système. Ces deux excellentes performances font de Spring le favori de nombreuses entreprises J2EE, par exemple les technologies liées à Spring sont les plus utilisées chez Ali.
Avantages du printemps:
-
Le couplage entre les composants est réduit et le découplage entre les couches logicielles est réalisé.
-
De nombreux services faciles à fournir peuvent être utilisés, tels que la gestion des transactions, le service de messagerie, la journalisation, etc.
-
Le conteneur fournit la technologie AOP, qui peut facilement implémenter des fonctions telles que l'interception des autorisations et la surveillance d'exécution.
La technologie AOP de Spring est un mode proxy dynamique dans les modèles de conception. Il suffit d'implémenter l'interface de proxy dynamique InvocationHandler fournie par jdk, toutes les méthodes de l'objet proxy sont prises en charge par InvocationHandler pour les tâches de traitement réelles. Dans la programmation orientée aspect, des concepts tels que le point d'entrée, l'aspect, la notification et le tissage doivent également être compris.
IOC in Spring utilise le puissant mécanisme de réflexion de Java pour y parvenir. L'injection dite de dépendance signifie que la dépendance entre les composants est déterminée par le conteneur au moment de l'exécution. Parmi eux, il existe deux méthodes d'injection de dépendances, par injection de constructeur et par méthode set.
14. Décrivez le flux de travail Struts
- Lorsque l'application Web est démarrée, l'ActionServlet est chargée et initialisée. L'ActionServlet lit les informations de configuration à partir du fichier struts-config.xml et les stocke dans chaque objet de configuration.
- Lorsque l'ActionServlet reçoit une demande client, il récupère d'abord l'instance ActionMapping qui correspond à la demande utilisateur et, si elle n'existe pas, renvoie les informations non valides du chemin d'accès de la demande utilisateur.
- Si l'instance ActionForm n'existe pas, créez un objet ActionForm et enregistrez les données de formulaire soumises par le client dans l'objet ActionForm.
- Déterminez si le formulaire doit être validé en fonction des informations de configuration. Si nécessaire, appelez la méthode validate () d'ActionForm. Si la méthode validate () d'ActionForm renvoie null ou renvoie un objet ActionErrors qui ne contient pas ActionMessage, cela signifie que la validation du formulaire est réussie.
- ActionServlet décide à quelle Action la demande est transmise en fonction des informations de mappage contenues dans l'instance ActionMapping. Si l'instance Action correspondante n'existe pas, il créera d'abord une instance, puis appellera la méthode execute () de l'Action.
Les questions connexes dans la partie ci-dessus examinent le cadre lié au langage Java utilisé par l'intervieweur dans le développement de logiciel réel et le degré de compréhension du principe du cadre. Dans cette partie, nous devons prêter attention à certains cadres communs. Non seulement besoin de savoir ce qu'ils font, mais aussi de les connaître. Le principe derrière, les frameworks souvent demandés incluent Spring Boot / Spring Cloud Family Bucket, Hibernate, MyBaits, Netty, Kafka, etc. Le plus important est le framework open source Apache Dubbo d'Alibaba.
15. À propos du modèle de mémoire Java
Un objet (deux propriétés, quatre méthodes) est instancié 100 fois, l'état de stockage actuel en mémoire, plusieurs objets, plusieurs propriétés et plusieurs méthodes. Étant donné que les nouveaux objets en Java sont tous placés dans le tas, si vous voulez instancier 100 fois, 100 objets seront générés dans le tas. En général, l'objet, ses propriétés et méthodes appartiennent à un tout, mais si les propriétés et méthodes sont Static est déclaré avec le mot-clé static, alors les attributs et méthodes appartenant à la classe n'existeront toujours qu'en mémoire.
16. Parlons de réflexion
C'est avant tout un concept, où avez-vous besoin d'un mécanisme de réflexion, comment optimiser la performance de la réflexion?
La définition du mécanisme de réflexion:
à l'état de fonctionnement, pour n'importe quelle classe, vous pouvez connaître tous les attributs et méthodes de cette classe, et pour n'importe quel objet, vous pouvez appeler n'importe quelle méthode d'une classe via le mécanisme de réflexion. Ce type d'acquisition dynamique d'informations de classe Et la fonction d'appel dynamique des méthodes des objets de classe est appelée le mécanisme de réflexion de java.
Le rôle de la réflexion:
1. Créer dynamiquement une instance de la classe, lier la classe à un objet existant ou obtenir le type à partir d'un objet existant.
2. L'application doit charger une classe spécifique à partir d'un assembly spécifique au moment de l'exécution.
17. Synchronisation des threads, comment contrôler les opérations simultanées?
En Java, vous pouvez ajouter le mot-clé syschronized avant le nom de la méthode pour gérer le problème lorsque plusieurs threads accèdent aux ressources partagées en même temps. syschronisé équivaut à un verrou. Lorsqu'un candidat postule pour la ressource, si la ressource n'est pas occupée, la ressource est remise au candidat pour utilisation. Pendant cette période, les autres candidats ne peuvent postuler que pour la ressource et ne peuvent pas utiliser la ressource. Une fois la ressource utilisée, le verrou sur la ressource sera libéré et d'autres candidats peuvent demander à être utilisés. Le contrôle d'accès concurrentiel concerne principalement les problèmes de lecture et d'écriture des ressources causés par les opérations multi-thread. Si aucun espace n'est ajouté, des blocages peuvent se produire, tels que la lecture de données modifiées, la lecture non répétable et les mises à jour manquantes.
Les opérations simultanées peuvent être contrôlées par verrouillage, qui peut être divisé en verrous optimistes et verrous pessimistes.
Verrou pessimiste: le mode d'accès concurrentiel de verrouillage pessimiste suppose qu'il y a suffisamment d'opérations de modification de données dans le système pour que toute opération de lecture donnée puisse être affectée par les modifications de données effectuées par des utilisateurs individuels. Autrement dit, le verrouillage pessimiste suppose que les conflits se produiront toujours et éviteront les conflits en monopolisant les données en cours de lecture. Mais les données exclusives empêcheront les autres processus de modifier les données, ce qui entraînera un blocage. La lecture et l'écriture de données se bloquent mutuellement.
Verrouillage optimiste: le verrouillage optimiste suppose que la modification des données du système ne produira que très peu de conflits, ce qui signifie qu'il est peu probable qu'un processus modifie les données auxquelles d'autres processus accèdent. Dans le mode de concurrence optimiste, il n'y aura pas de conflits entre les données de lecture et les données d'écriture, uniquement des conflits entre les données d'écriture et d'écriture. Autrement dit, la lecture de données ne provoquera pas de blocage, seule l'écriture de données provoquera un blocage.
Ce qui précède est l'intégralité du contenu de cet article.Enfin, je partagerai gratuitement du matériel d'entrevue avec vous, j'espère qu'il sera utile à tout le monde: cliquez ici, cliquez ici, mot de passe: CSDN