Journal segmenté
Divisez les fichiers volumineux en plusieurs fichiers plus petits qui sont plus faciles à gérer.
Contexte du problème
Un seul fichier journal peut atteindre une grande taille et être lu au démarrage du programme, devenant ainsi un goulot d'étranglement des performances. Les anciens journaux doivent être nettoyés régulièrement, mais le nettoyage d'un fichier volumineux est très laborieux.
Solution
Divisez un seul journal en plusieurs, et lorsque le journal atteint une certaine taille, il passera à un nouveau fichier pour continuer à écrire.
//写入日志
public Long writeEntry(WALEntry entry) {
//判断是否需要另起新文件
maybeRoll();
//写入文件
return openSegment.writeEntry(entry);
}
private void maybeRoll() {
//如果当前文件大小超过最大日志文件大小
if (openSegment.
size() >= config.getMaxLogSize()) {
//强制刷盘
openSegment.flush();
//存入保存好的排序好的老日志文件列表
sortedSavedSegments.add(openSegment);
//获取文件最后一个日志id
long lastId = openSegment.getLastLogEntryId();
//根据日志id,另起一个新文件,打开
openSegment = WALSegment.open(lastId, config.getWalDir());
}
}Si le journal est segmenté, un mécanisme pour localiser rapidement un fichier avec un emplacement de journal (ou un numéro de séquence de journal) est nécessaire. Cela peut être réalisé de deux manières:
- Le nom de chaque fichier de fractionnement du journal contient un décalage de position de début et de journal spécifique (ou numéro de séquence du journal)
- Chaque numéro de séquence de journal contient le nom du fichier et le décalage de transaction.
//创建文件名称
public static String createFileName(Long startIndex) {
//特定日志前缀_起始位置_日志后缀
return logPrefix + "_" + startIndex + "_" + logSuffix;
}
//从文件名称中提取日志偏移量
public static Long getBaseOffsetFromFileName(String fileName) {
String[] nameAndSuffix = fileName.split(logSuffix);
String[] prefixAndOffset = nameAndSuffix[0].split("_");
if (prefixAndOffset[0].equals(logPrefix))
return Long.parseLong(prefixAndOffset[1]);
return -1l;
}Une fois que le nom de fichier contient ces informations, l'opération de lecture est divisée en deux étapes:
- Étant donné un offset (ou un identifiant de transaction), obtenez le fichier où le journal est plus grand que cet offset
- Lire tous les journaux plus grands que ce décalage dans le fichier
//给定偏移量,读取所有日志
public List<WALEntry> readFrom(Long startIndex) {
List<WALSegment> segments = getAllSegmentsContainingLogGreaterThan(startIndex);
return readWalEntriesFrom(startIndex, segments);
}
//给定偏移量,获取所有包含大于这个偏移量的日志文件
private List<WALSegment> getAllSegmentsContainingLogGreaterThan(Long startIndex) {
List<WALSegment> segments = new ArrayList<>();
//Start from the last segment to the first segment with starting offset less than startIndex
//This will get all the segments which have log entries more than the startIndex
for (int i = sortedSavedSegments.size() - 1; i >= 0; i--) {
WALSegment walSegment = sortedSavedSegments.get(i);
segments.add(walSegment);
if (walSegment.getBaseOffset() <= startIndex) {
break; // break for the first segment with baseoffset less than startIndex
}
}
if (openSegment.getBaseOffset() <= startIndex) {
segments.add(openSegment);
}
return segments;
}Par exemple
Fondamentalement, tous les stockages MQ traditionnels, tels que RocketMQ, Kafka et le stockage sous-jacent BookKeeper de Pulsar, utilisent tous des journaux segmentés.
RocketMQ :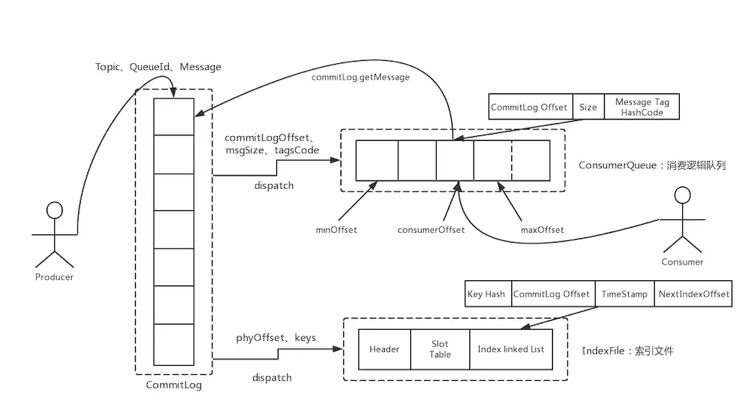
Kafka :
Les outils de stockage Pulsar BookKeeper: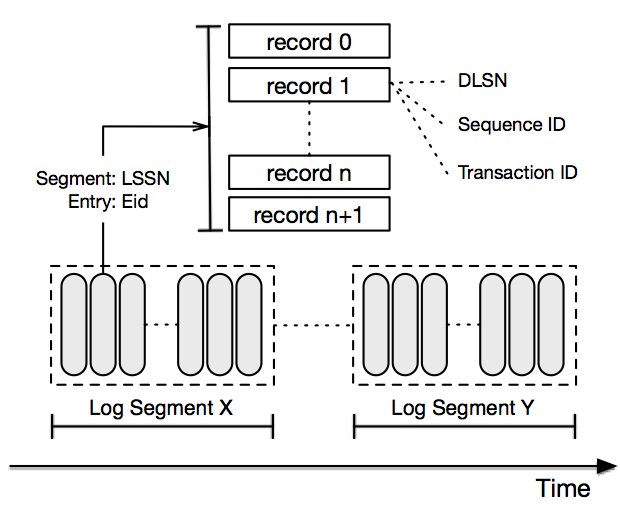
De plus, le stockage basé sur le protocole de cohérence Paxos ou Raft utilise généralement des logs segmentés, tels que Zookeeper et TiDB.
Un seul coup tous les jours, vous pouvez facilement améliorer vos compétences et obtenir diverses offres:
