Cet article est partagé par la communauté HUAWEI CLOUD « Huawei Cloud GaussDB (for Influx) Revealing the Fifth Issue : Sub-Query of Best Practices », auteur : base de données GaussDB.
"Alerte ! Alerte !".
"Quelle est l'alarme?" Xiao Wang, qui était hébété dans son sommeil, a été soudainement réveillé par un appel téléphonique d'un collègue d'exploitation et de maintenance, et son visage a été surpris.
"Requête lente ! Le client a signalé un problème ! Dépêchez-vous et résolvez-le !"
Xiao Wang a rapidement ouvert le portable, connecté à distance à l'environnement pour trouver le problème, et a finalement découvert que la requête lente était une sous-requête. "Non, la même déclaration n'a pas signalé une requête lente hier ?"
Mais Xiao Wang a rapidement compris pourquoi. Le problème avec cette requête lente est que la requête interne de la sous-requête aurait pu agréger les données puis les envoyer à la requête externe, mais comme il n'y a pas d'agrégation, elle sera très lente lorsque la quantité de données est importante !
Trouvant le point crucial, Xiao Wang a immédiatement transmis l'instruction SQL optimisée au client par l'intermédiaire de ses collègues d'exploitation et de maintenance, et l'alarme a finalement été résolue.
"On dirait qu'il est temps de trier la question!" Profitant de sa pensée claire, Xiao Wang a commencé à trier...
0 1 Qu'est-ce qu'une sous-requête ?
Une sous-requête est une requête imbriquée dans une autre requête et est généralement placée dans l'instruction from de la syntaxe InfluxQL pour améliorer la flexibilité du code. Les sous-requêtes appartiennent principalement aux catégories suivantes :
Sous-requête scalaire (scalarsubquery) : retourne une valeur dans 1 ligne et 1 colonne
Sous-requête de ligne (rowsubquery) : le jeu de résultats renvoyé est de 1 ligne et N colonnes
Sous-requête de colonne (columnsubquery) : le jeu de résultats renvoyé est de N lignes et 1 colonne
Sous-requête de table (tablesubquery) : le jeu de résultats renvoyé est de N lignes et N colonnes
Par exemple, dans l'instruction de requête :
select first(sum_f1)/first(sum_f2) from (select sum(f1) as sum_f1 from mst), (select sum(f2) as sum_f2 from mst)Deux sous-requêtes sont utilisées, qui doivent obtenir la somme des deux colonnes f1 et f2 de la table mst, respectivement, et utiliser les résultats sum_f1 et sum_f2 comme source de la requête externe pour l'instruction de requête externe.
La syntaxe générale d'une sous-requête GaussDB (pour Influx) est SELECT_clause FROM (SELECT_statement ) [...]. La logique de traitement des sous-requêtes est illustrée dans la figure ci-dessous.
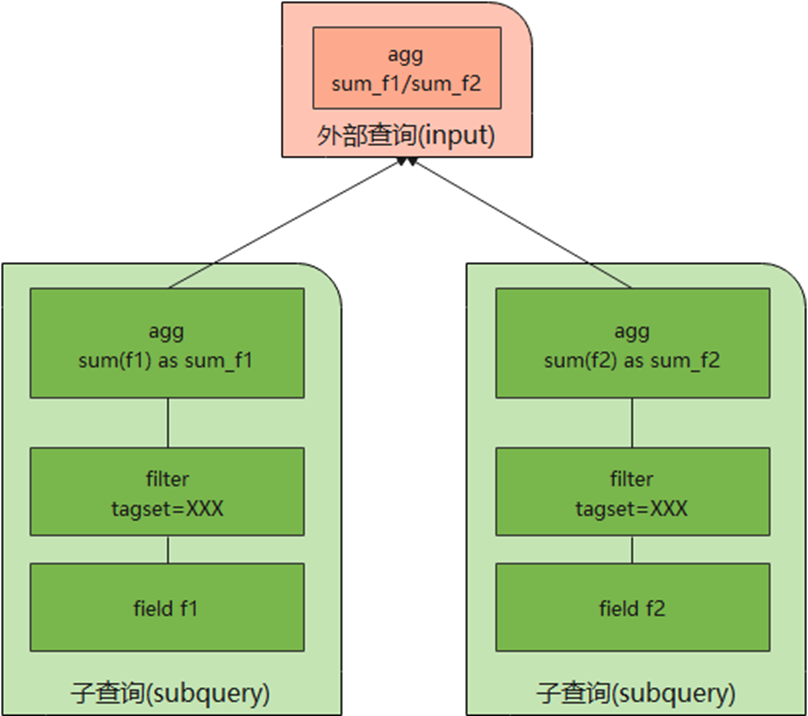
Le système traitera d'abord l'instruction de sous-requête et le résultat de la sous-requête sera mis en cache en tant que source de données de la requête externe. Enfin, la requête externe sera traitée et le résultat sera renvoyé au client.
0 2 Scénarios d'utilisation des sous-requêtes
Les sous-requêtes sont utilisées lorsqu'une requête simple ne peut pas être traitée, ou pour un traitement ultérieur basé sur les données d'une requête, par exemple, pour trouver les trois plus grandes parmi les valeurs minimales de chaque groupe :
SELECT top (v,3)
FROM (
SELECT min (value) AS v
FROM mst
GROUP BY tag1
)Les sous-requêtes nous donnent beaucoup de flexibilité, mais les sous-requêtes ne sont pas recommandées en principe. La raison est très simple : par rapport aux requêtes ordinaires, les sous-requêtes ont des appels de fonction plus profonds et des volumes de données plus importants, qui consomment plus de ressources et augmentent la latence.
0 3 Analyse de cas
Dans le processus de développement avec GaussDB (pour Influx), nous rencontrons souvent des difficultés dans les sous-requêtes, telles que :
1. Quand utiliser les sous-requêtes ?
2. Face à un scénario complexe, comment le décomposer en sous-requêtes pour le résoudre ?
3. La sous-requête écrite est-elle optimale ? Peut-il être optimisé à nouveau ?
Ensuite, nous combinons un cas spécifique pour analyser brièvement comment utiliser efficacement les sous-requêtes et les idées d'analyse.
Un utilisateur de HUAWEI CLOUD utilise GaussDB (pour Influx) pour écrire environ 540 millions de points chaque jour, et la chronologie est de 100w +. Dans l'entreprise, la requête de temps et d'espace, la requête de taux de réussite et la requête topN.
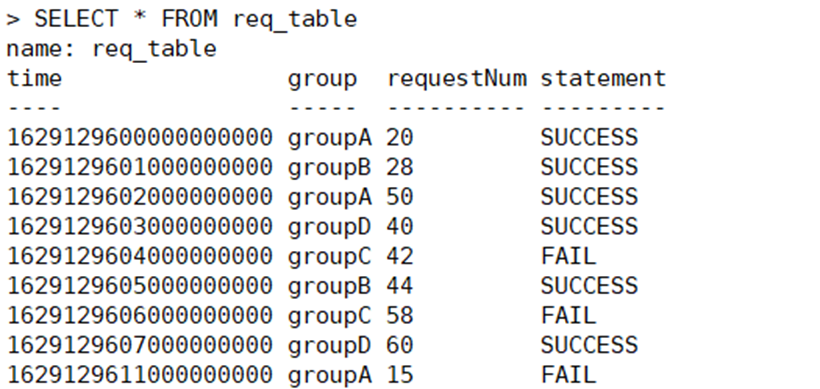
Prenez les données désensibilisées suivantes comme exemples de données pour l'analyse de cas et la pratique :
-
Cas 1 Quand utiliser les sous-requêtes ?
L'utilisateur utilise des sous-requêtes pour le regroupement spatio-temporel et comme source de la requête externe, qui agrège les résultats du regroupement spatio-temporel. L'instruction de la requête est :
SELECT SUM(req_nums)
FROM(
SELECT requestNum AS req_nums
FROM req_table
WHERE statement=’SUCCESS’ AND time >= 1629129600000000000
AND time<=1629129611000000000 )
WHERE time>=1629129600000000000 AND time<=1629129611000000000
AND req_nums < 50
GROUP BY time(1s), group
ORDER BY time ASCLe problème qui en résulte :
Dans le scénario d'utilisation de l'utilisateur, on peut constater que la sous-requête de la requête implémente uniquement le filtrage conditionnel et le changement de nom de colonne, de sorte que la requête interne équivaut à SELECT requestNum AS req_nums + filtrage. La requête dans le scénario sans agrégation nécessite un grand quantité de données brutes à récupérer, ce qui entraîne une vitesse de requête lente, de sorte que l'efficacité de la requête ne répond pas aux exigences de l'utilisateur.
Solutions:
En analysant l'instruction de la requête, on constate que la demande de l'utilisateur est d'agréger les données qui remplissent les conditions (instruction='SUCCESS' AND requestNum < 50) dans une agrégation spatio-temporelle (GROUPBY TAG, time(5m)), et après avoir clarifié la cible de la requête, elle peut être écrite plus clairement. Instruction de requête efficace : rassemblez toutes les conditions de filtre et effectuez directement l'agrégation spatio-temporelle.
Améliorations de la grammaire :
SELECT SUM(requestNum)
FORM req_table
WHERE statement=’SUCCESS’ AND requestNum < 50
AND time>=1629129600000000000 AND time<=1629129611000000000
GROUP BY time(1s), group
ORDER BY time ASC-
Cas 2 Utiliser des sous-requêtes pour résoudre des problèmes complexes
Dans le scénario d'entreprise de l'utilisateur, le taux de réussite de la demande doit être calculé, c'est-à-dire qu'une certaine colonne de données est filtrée et comptée selon différentes conditions de filtre, et enfin le ratio est calculé. GaussDB (pour Influx) ne prend pas en charge l'instruction case when, il est donc difficile de filtrer différentes données dans la même colonne en fonction de différents cas. Lorsque de nombreux développeurs rencontrent un tel problème, ils n'en ont aucune idée.
Solutions:
Étape 1 : Utilisez la fonctionnalité sous-requête + multi-table pour modifier la même colonne de données en deux colonnes en fonction des conditions de filtrage :
SELECT * FROM
(SELECT requestNum AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT requestNum AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)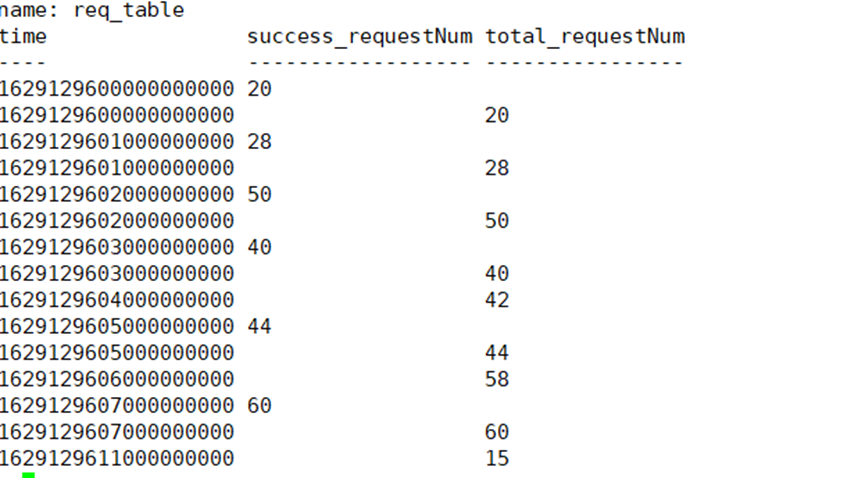
Étape 2 : Comptez les données interrogées :
SELECT SUM(success_requestNum) AS total_success_reqNum, SUM(total_requestNum) AS total_requestNum
FROM
(SELECT requestNum AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT requestNum AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)
GROUP BY time ASC
Étape 3 : Rédigez une instruction de requête pour le taux de réussite final :
SELECT SUM(success_requestNum)/SUM(total_requestNum) AS success_ratio
FROM
(SELECT requestNum AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT requestNum AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)
GROUP BY time ASC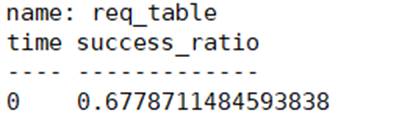
-
Cas 3 Comment optimiser l'instruction de sous-requête ?
Sur la base du cas 2, nous avons obtenu la méthode pour trouver le taux de réussite. L'instruction de la requête est la suivante :
SELECT SUM(success_requestNum)/SUM(total_requestNum) AS success_ratio
FROM
(SELECT requestNum AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT requestNum AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)
GROUP BY time ASCLe problème qui en résulte :
L'instruction de requête écrite par l'utilisateur dont le temps de requête est supérieur à 120 s ne répond pas aux exigences de l'entreprise et doit être encore optimisée.
Améliorations de la grammaire
Selon les principes de sous-requête et les solutions décrites ci-dessus, la requête agrégée doit être placée à l'intérieur de la sous-requête pour réduire la quantité de données et accélérer la requête. L'instruction de requête optimisée est la suivante :
SELECT SUM(success_requestNum)/SUM(total_requestNum) AS success_ratio
FROM
(SELECT SUM(requestNum) AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT SUM(requestNum) AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)
GROUP BY time ASCLes résultats de la requête sont les mêmes :
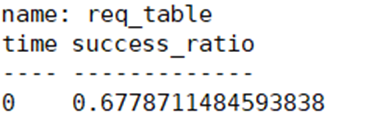
Effet d'optimisation :
La requête non optimisée prend 126 secondes et la requête optimisée prend 2,7 secondes, et les performances sont améliorées de 47 fois.
*Avis
En utilisant SUM(success_requestNum), le but de SUM(total_requestNum) est d'aligner les données. L'utilisation directe de SELECTsuccess_requestNum / total_requestNum entraînera des résultats incorrects car les données en même temps ne peuvent pas être alignées :
SELECT *
FROM
(SELECT SUM(requestNum) AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT SUM(requestNum) AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)
GROUP BY time ASC
Le volume total de données de la requête est positivement lié à la vitesse de la requête. Plus le volume de la requête de données est important, plus la vitesse de la requête est lente. Par conséquent, qu'il s'agisse d'écrire une sous-requête ou une instruction de requête non sous-requête, la première Le principe est d'essayer de réduire le volume de données dans la requête. , ce qui signifie que les requêtes agrégées (généralement des requêtes qui réduisent la quantité de données) doivent être placées autant que possible dans des sous-requêtes.
0 4 Sous-requêtes flexibles et hautes performances
GaussDB (pour Influx) fournit non seulement des capacités de sous-requêtes flexibles, mais utilise également la vectorisation, la réutilisation de la mémoire et d'autres technologies pour améliorer en permanence l'efficacité des requêtes, répondant aux exigences de performances des requêtes des utilisateurs dans des scénarios de données massives.
Requête vectorisée : GaussDB (pour Influx) utilise le jeu d'instructions SIMD pour améliorer le degré de parallélisme du traitement des données. Dans le même temps, en utilisant le modèle de données vectorisées, une itération peut traiter un lot de points, ce qui réduit considérablement le nombre d'itérations de calcul et accélère le calcul.
Réutilisation de la mémoire : le recyclage et l'allocation de mémoire par GC sont réduits autant que possible pendant le processus de requête, et la mémoire demandée est gérée séparément, ce qui résout le problème d'expansion de la mémoire pendant le processus de requête, ce qui amène le GC à réduire fréquemment la requête. la vitesse.
0 5 Résumé
GaussDB (pour Influx) prend en charge la fonction de sous-requête, ce qui nous apporte une grande flexibilité dans le traitement des problèmes, et a également des exigences élevées pour les utilisateurs. Des sous-requêtes déraisonnables entraînent souvent des problèmes tels qu'un délai de requête élevé et une consommation élevée de ressources. , donc vous devez prêter attention aux points suivants lors de l'utilisation des sous-requêtes GaussDB (pour Influx) :
1. Comprendre la logique métier applicable aux sous-requêtes. Les sous-requêtes conviennent aux scénarios dans lesquels les données interrogées sont traitées deux fois (plusieurs fois) ;
2. Essayez d'éviter d'utiliser des sous-requêtes dans les scénarios où les sous-requêtes ne peuvent pas être utilisées 3. Doit être utilisé Dans le scénario de sous-requête ,
la requête qui réduit la quantité de données est placée dans la sous-requête autant que possible pour réduire le volume global de données de la requête et ainsi accélérer la requête.
0 6 fin
L'auteur de cet article : HUAWEI CLOUD Database Innovation Lab & HUAWEI CLOUD Spatiotemporal Database Team
Bienvenue parmi nous !
Cloud Database Innovation Lab (Chengdu, Pékin) Courriel de livraison de CV : [email protected]
Équipe de base de données spatio-temporelle HUAWEI CLOUD (Xi'an, Shenzhen) Courriel de livraison de CV : [email protected]