Structure des tables de la base de données :
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
select id,name where name='shenjian'
select id,name,sex where name='shenjian'
Un autre attribut est demandé, pourquoi le processus de récupération est-il complètement différent ?
Qu'est-ce qu'une requête de retour de formulaire ?
Qu'est-ce que la couverture de l'indice ?
Comment obtenir une couverture indicielle ?
Dans quels scénarios la couverture d'index peut-elle être utilisée pour optimiser SQL ?
Celles-ci, c'est ce que je veux partager aujourd'hui.
Remarque : L'expérience décrite dans cet article est basée sur MySQL5.6-InnoDB.
1. Qu'est-ce qu'une demande de formulaire de retour ?
Cela commence par l'implémentation d'index d'InnoDB. InnoDB a deux types d'index :
- index clusterisé
- index ordinaire (index secondaire)
Quelle est la différence entre un index clusterisé InnoDB et un index normal ?
Les nœuds feuilles de l' index clusterisé InnoDB stockent les enregistrements de lignes. Par conséquent, InnoDB doit avoir un seul index clusterisé :
(1) Si la table définit un PK, alors le PK est un index clusterisé ;
(2) Si la table ne définit pas PK, la première colonne unique non NULL est un index clusterisé ;
(3) Sinon, InnoDB créera un identifiant de ligne caché en tant qu'index clusterisé ;
Remarque : la requête PK est donc très rapide et l'enregistrement de ligne est directement localisé.
Les nœuds feuilles d'un index commun InnoDB stockent la valeur de la clé primaire.
Voiceover : notez qu'au lieu de stocker des pointeurs d'en-tête d'enregistrement de ligne, les nœuds feuilles d'index de MyISAM stockent des pointeurs d'enregistrement.
Par exemple, prenons un tableau :
t(id PK, nom KEY, sexe, flag);
Remarque : id est un index clusterisé et name est un index commun.
Il y a quatre enregistrements dans la table :
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
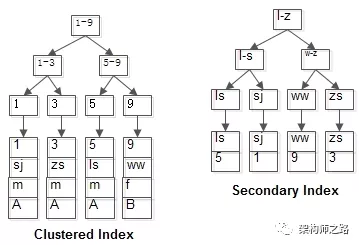
Les deux index d'arbre B+ sont comme indiqué ci-dessus :
(1) id est PK, index clusterisé et les nœuds feuilles stockent les enregistrements de ligne ;
(2) le nom est KEY, index commun, le nœud feuille stocke la valeur PK, c'est-à-dire l'identifiant ;
Étant donné que l'enregistrement de ligne ne peut pas être localisé directement à partir de l'index ordinaire, quel est le processus de requête de l'index ordinaire ?
Habituellement, vous devez parcourir l'arborescence d'index deux fois.
Par exemple:
select * from t where name='lisi';
Comment ça marche?
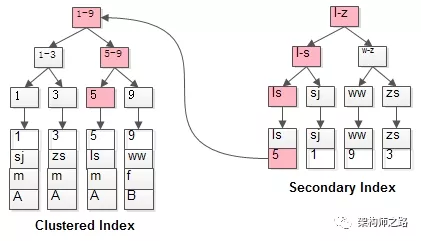
Par exemple , le chemin rose doit parcourir deux fois l'arborescence d'index :
(1) Localisez d'abord la valeur de clé primaire id=5 via l'index ordinaire ;
(2) Localisez l'enregistrement de ligne dans l'index cluster ;
Il s'agit de la requête dite de retour à la table , qui localise d'abord la valeur de la clé primaire, puis localise l'enregistrement de la ligne. Ses performances sont inférieures à l'analyse de l'arborescence d'index une fois.
Deuxièmement, qu'est-ce que la couverture de l'indice (indice de couverture) ?
Eh bien, je n'ai pas trouvé ce concept sur le site officiel de MySQL.
Voix off : Êtes-vous rigoureux dans vos études ?
Pour emprunter la déclaration sur le site officiel de SQL-Server.

Sur le site Web officiel de MySQL, une déclaration similaire apparaît dans le chapitre sur l'optimisation du plan de requête d'explication, c'est-à-dire que lorsque le champ Extra du résultat de sortie de l'explication est Utilisation de l'index , la couverture de l'index peut être déclenchée.

Qu'il s'agisse du site officiel de SQL-Server ou du site officiel de MySQL, il est exprimé que toutes les données de colonne requises par SQL ne peuvent être obtenues que sur un arbre d'index, sans revenir à la table, et la vitesse est plus rapide.
3. Comment obtenir une couverture indicielle ?
La méthode courante consiste à créer le champ à interroger dans l'index conjoint.
Toujours l'exemple d'avant :
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
La première instruction SQL :
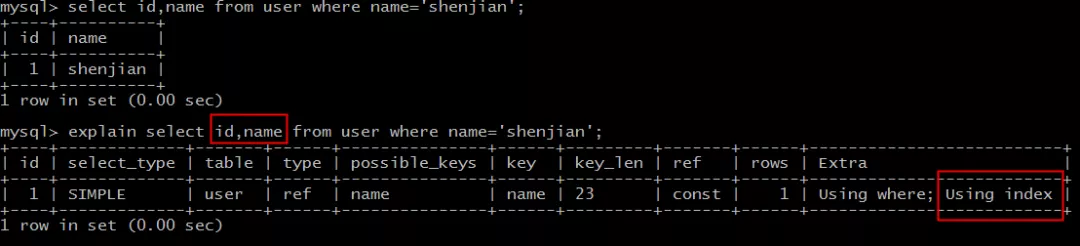
select id,name from user where name='shenjian';
Il peut atteindre l'index de noms, le nœud feuille d'index stocke l'identifiant de clé primaire, et l'identifiant et le nom peuvent être obtenus via l'arborescence d'index de nom, sans revenir à la table, conformément à la couverture de l'index et à une efficacité élevée.
Voix off, Extra : Utilisation de l'index .
Deuxième instruction SQL :
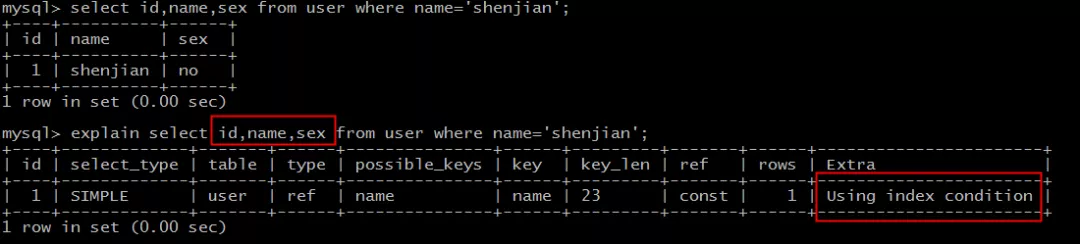
select id,name,sex from user where name='shenjian';
L'index de noms peut être atteint et le nœud feuille d'index stocke l'ID de la clé primaire, mais le champ sexe ne peut être obtenu qu'en interrogeant la table, qui ne correspond pas à la couverture de l'index.
Voiceover, Extra : Utilisation de la condition d'index .
Si l'index à colonne unique (nom) est mis à niveau vers un index conjoint (nom, sexe), ce sera différent.
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name, sex)
)engine=innodb;
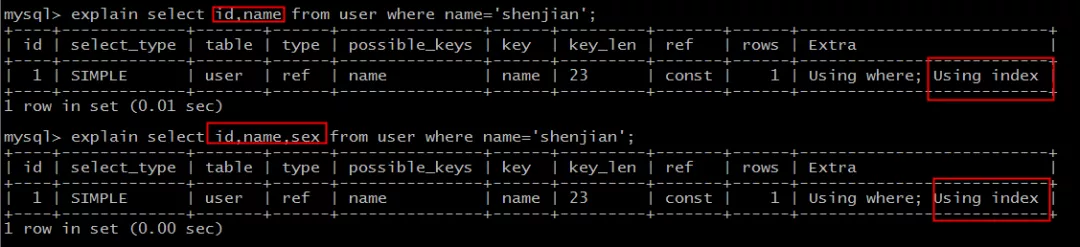
peut être vu:
select id,name ... where name='shenjian';
select id,name,sex ... where name='shenjian';
Tous peuvent atteindre la couverture de l'indice sans retourner à la table.
Voix off, Extra : Utilisation de l'index .
4. Quels scénarios peuvent utiliser la couverture d'index pour optimiser SQL ?
Scénario 1 : Optimisation complète des requêtes en nombre de tables
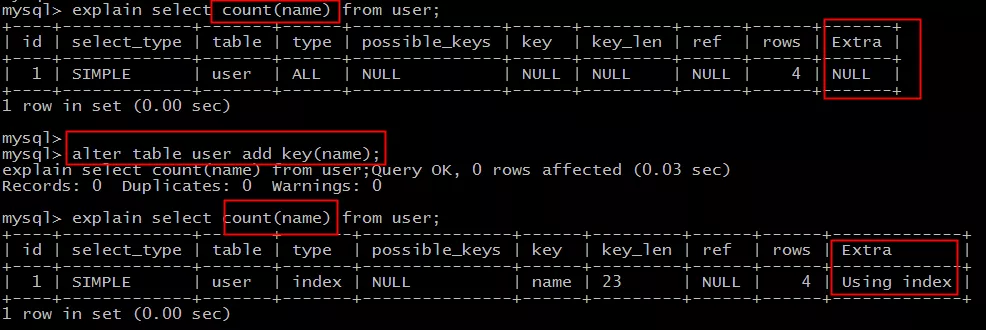
Le tableau d'origine est :
utilisateur (identifiant PK, nom, sexe) ;
direct:
select count(name) from user;
La couverture d'index ne peut pas être utilisée.
Ajouter un index :
alter table user add key(name);
Vous pouvez utiliser la couverture d'index pour améliorer l'efficacité.
Scénario 2 : Optimisation de la table de retour de requête de colonne
select id,name,sex ... where name='shenjian';
Cet exemple ne sera pas repris ici, l'index mono-colonne (nom) est mis à jour en index joint (nom, sexe) pour éviter de revenir à la table.
Scénario 3 : Requête de pagination
select id,name,sex ... order by name limit 500,100;
La mise à niveau d'un index à colonne unique (nom) vers un index conjoint (nom, sexe) peut également éviter de revenir à la table.
index clusterisé InnoDB index commun , table de retour , couverture d'index
Qu'est-ce qu'un indice de recouvrement ?
## Avant-propos
Pour comprendre un index de couverture, vous devez d'abord comprendre la différence entre un index de clé primaire et un index secondaire , et comment le moteur fonctionne lors de l'interrogation.
Bien entendu, les éléments ci-dessus sont tous basés sur le moteur innoDB.
La différence entre l'index de clé primaire et l'index secondaire
Je crois que tout le monde a également appris cette connaissance, donc je ne vais pas la développer ici, mais la résumer directement.
index de clé primaire
Les nœuds feuilles enregistrent les données
Indice secondaire
Le nœud feuille enregistre la valeur de la clé primaire
Comment fonctionne l'interrogation d'une donnée ?
Parlons d'abord du processus de requête :
Étant donné que l'index secondaire ne stocke que la valeur de la clé primaire, si vous utilisez l'index secondaire pour rechercher des données, vous devez d'abord obtenir la valeur de la clé primaire à partir de l'index secondaire, puis utiliser la valeur de la clé primaire pour interroger sur l'index de clé primaire jusqu'à ce que les données du nœud feuille soient trouvées et renvoyées. ---- Ceci est également appelé la table de retour
Alors, comment éviter les requêtes de retour à la table ?
Si les données dont nous avons besoin existent déjà sur l'index secondaire, le moteur n'ira pas à la clé primaire pour rechercher des données. ---- C'est ce qu'on appelle " l'indice de recouvrement "
Ensuite, nous allons le prouver.
formulaire de retour de requête
S'il existe un tel tableau :
CREATE TABLE `test` (
`id` int(11) NOT NULL,
`age` int(11) NOT NULL,
`name` varchar(255) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`age`,`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Nous ajoutons un index à l'âge, puis insérons quelques données à volonté
insert into test(`id`,`age`,`name`) VALUES(1,10,"小明"),(2,11,"小红"),(3,12,"小伟");
interroger une donnée
select * from test where age = 10
Vérifiez l'heure

Analysez la phrase :
desc select * from test where age = 10
Afficher le plan d'exécution :
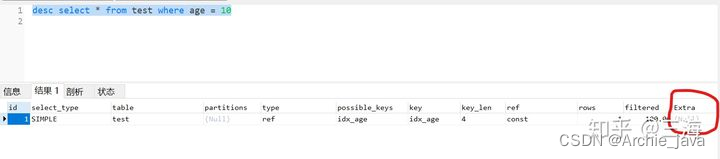
Vous pouvez voir que la colonne supplémentaire est vide et que la clé utilise l'index idx_age. Le temps de requête approximatif est d'environ 0,024 seconde.
Une telle requête est-elle rapide ?
J'ai dit que je pouvais l'optimiser à nouveau, pouvez-vous le croire ? - Lu Xun (je n'ai pas dit ça)
indice couvrant
Avec juste un léger changement dans les champs de la requête, nous pouvons voir la différence.
sélectionnez l'âge, le nom du test où l'âge = 10
Découvrez combien de temps cela a pris :

Vous pouvez voir que le temps est réduit !
Que s'est-il passé, analysons à nouveau la déclaration
desc select age,name from test where age = 10

Vous pouvez voir que la colonne supplémentaire a un using idnex , ce qui signifie que l'index de couverture est utilisé et qu'il n'est pas nécessaire d'interroger la table.
Résumer
La pratique est le seul critère pour tester les principes. Grâce à cette pratique, vous devez avoir pleinement compris et expérimenté le concept et la signification de l'indice de couverture. Son cœur est de ne demander que des données à partir d'index auxiliaires . Ensuite, l'index ordinaire (champ unique) et l'index conjoint, ainsi que l'index unique peuvent réaliser le rôle d'index de couverture.
# Qu'est-ce qu'un indice de recouvrement ?
- Explication 1 : C'est-à-dire que la colonne de données de la sélection ne peut être obtenue qu'à partir de l'index et n'a pas besoin d'être lue à partir de la table de données. En d'autres termes, la colonne de requête doit être couverte par l'index utilisé.
- Explication 2 : Les index sont un moyen efficace de rechercher des lignes. Lorsque les données souhaitées peuvent être lues en récupérant l'index, il n'est pas nécessaire de lire les lignes dans la table de données. Si un index contient (ou couvre) des données qui satisfont les champs et les conditions de la requête, il est appelé index de couverture.
- Explication 3 : Il s'agit d'une forme d'index composite non clusterisé, qui inclut toutes les colonnes utilisées dans les clauses Select, Join et Where de la requête (c'est-à-dire que le champ indexé est exactement l'instruction de requête de couverture [clause select] et les conditions de requête [ Clause Where], c'est-à-dire que l'index contient toutes les données recherchées par la requête). Tous les types d'index ne peuvent pas être des index couverts. L'index de couverture doit stocker les colonnes indexées, et l'index de hachage, l'index spatial et l'index de texte intégral ne stockent pas la valeur de la colonne indexée, donc MySQL ne peut utiliser que l'index B-Tree comme index de couverture lors du lancement d'une requête couverte par l'index (également appelée requête de couverture d'index), vous pouvez voir les informations "Utilisation de l'index" dans la colonne Extra de EXPLAIN.
Remarque : Dans les cas suivants, le plan d'exécution ne choisira pas de couvrir la requête.
- Les champs sélectionnés par select contiennent des champs qui ne sont pas dans l'index, c'est-à-dire que l'index ne couvre pas toutes les colonnes.
- La condition where ne peut pas contenir d'opération similaire sur l'index.
index clusterisé mysql, index auxiliaire, index union, index de couverture
Index clusterisé : il ne peut y en avoir qu'un dans une table, et l'ordre de l'index clusterisé est cohérent avec l'ordre de stockage physique réel des données. La vitesse de requête est très rapide. Le nœud feuille de l'index clusterisé contient toutes les données de la ligne. L'index de données peut accélérer la requête de plage (l'ordre de l'index clusterisé est cohérent avec l'ordre logique de stockage des données). Clé primaire != index clusterisé.
Index auxiliaire (index non clusterisé) : Il peut y en avoir plus d'un dans une table. Le nœud feuille ne stocke pas une ligne entière de données, mais la valeur clé. La ligne d'index du nœud feuille contient également un 'signet', qui pointe vers l'index agrégé Pointeur vers un index clusterisé pour rechercher une ligne entière de données dans l'arborescence de l'index clusterisé.
Index joint : C'est un index composé de plusieurs colonnes. Suivez la règle de préfixe la plus à gauche. Valable pour où, trier par, grouper par.
Index de couverture : Cela signifie que les enregistrements requis peuvent être obtenus à partir de l'index auxiliaire sans rechercher les enregistrements dans l'index clusterisé. L'un des avantages de l'utilisation d'un index de couverture est que, comme l'index auxiliaire n'inclut pas l'intégralité des informations de ligne d'un enregistrement, la quantité de données est inférieure à celle de l'index clusterisé, ce qui peut réduire de nombreuses opérations d'E/S.
La différence entre un index clusterisé et un index auxiliaire : si le nœud feuille stocke une ligne entière de données
Règle de préfixe la plus à gauche : en supposant que l'index joint se compose de colonnes (a, b, c), l'ordre suivant satisfait la règle de préfixe la plus à gauche : a, ab, abc ; select, where, order by et group by peuvent tous correspondre à la règle de préfixe la plus à gauche préfixe. Dans d'autres cas, si la règle de préfixe la plus à gauche n'est pas satisfaite, l'index d'union ne sera pas utilisé.