CeresDB est une base de données de séries temporelles cloud native distribuée hautes performances écrite en Rust. Son équipe de développement a récemment annoncé qu'après près d'un an de recherche et développement open source, la base de données de séries chronologiques CeresDB 1.0 est officiellement publiée, atteignant les normes de disponibilité de production .
Documentation chinoise officielle CeresDB 1.0 : https://docs.ceresdb.io/cn/
Introduction aux principales fonctionnalités de CeresDB 1.0
moteur de stockage
-
Prise en charge du stockage hybride en colonne
-
Filtre XOR efficace
Cloud natif distribué
-
Réaliser la séparation de l'informatique et du stockage (prise en charge de l'OSS en tant que stockage de données, l'implémentation WAL prend en charge OBKV, Kafka)
-
Prise en charge de la table de partition HASH
Déploiement et O&M
-
Prise en charge du déploiement autonome
-
Prise en charge du déploiement de clusters distribués
-
Soutenez Prometheus + Grafana pour construire l'auto-surveillance
protocole de lecture-écriture
-
Prend en charge la requête et l'écriture SQL
-
Implémentation du protocole de lecture et d'écriture hautes performances intégré de CeresDB et fourniture d'un SDK multilingue
-
Prend en charge Prometheus, peut être utilisé comme stockage à distance de Prometheus
SDK de lecture et d'écriture multilingue
- Implémentation de SDK client en quatre langages : Java, Python, Go, Rust
Introduction à l'architecture CeresDB
CeresDB est une base de données de séries chronologiques. Par rapport aux bases de données de séries chronologiques classiques, l'objectif de CeresDB est de pouvoir traiter les données à la fois en mode série chronologique et en mode analytique, et de fournir une lecture et une écriture efficaces.
Dans une base de données de séries chronologiques classique, Tagla colonne ( InfluxDBappelée Tag, Prometheusappelée Label) génère généralement un index inversé pour elle, mais en utilisation réelle, Tagla cardinalité de la colonne est différente dans différents scénarios ——— dans certains Dans le scénario, Tagla cardinalité est très élevé (les données dans ce scénario sont appelées données analytiques), et la lecture et l'écriture basées sur l'indice inversé en paieront le prix fort. D'autre part, la méthode de balayage + élagage couramment utilisée dans les bases de données analytiques peut traiter ces données analytiques plus efficacement.
Par conséquent, le concept de conception de base de CeresDB consiste à adopter un format de stockage hybride et les méthodes de requête correspondantes, afin de traiter efficacement les données de séries chronologiques et les données analytiques en même temps.
La figure ci-dessous montre l'architecture de la version autonome de CeresDB
┌──────────────────────────────────────────┐
│ RPC Layer (HTTP/gRPC/MySQL) │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ SQL Layer │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Parser │ │ Planner │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌───────────────────┐ ┌───────────────────┐
│ Interpreter │ │ Catalog │
└───────────────────┘ └───────────────────┘
┌──────────────────────────────────────────┐
│ Query Engine │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Optimizer │ │ Executor │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ Pluggable Table Engine │
│ ┌────────────────────────────────────┐ │
│ │ Analytic │ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Wal ││ Memtable ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Flush ││ Compaction ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Manifest ││ Object Store ││ │
│ │└────────────────┘└────────────────┘│ │
│ └────────────────────────────────────┘ │
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ Another Table Engine │ │
│ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
└──────────────────────────────────────────┘
Optimisation des performances et résultats expérimentaux
CeresDB utilise une combinaison de stockage hybride en colonne, de partitionnement des données, d'élagage et d'analyse efficace pour résoudre le problème des mauvaises performances des requêtes d'écriture dans des délais très longs (cardinalité élevée).
optimisation de l'écriture
CeresDB adopte le modèle d'écriture de type LSM (Log-structured merge-tree), qui n'a pas besoin de traiter des index inversés complexes lors de l'écriture, de sorte que les performances d'écriture sont meilleures.
optimisation des requêtes
Les moyens techniques suivants sont principalement utilisés pour améliorer les performances des requêtes :
Taille:
-
taille min/max : le coût de construction est relativement faible et les performances sont meilleures dans des scénarios spécifiques
-
Filtre XOR : améliore la précision du filtrage du groupe de lignes dans le fichier parquet
Numérisation efficace :
-
Concurrence entre plusieurs SST : analysez plusieurs fichiers SST en même temps
-
Concurrence interne d'un seul SST : prend en charge la couche Parquet pour extraire plusieurs groupes de lignes en parallèle
-
Fusionner les petites E/S : pour les fichiers sur OSS, fusionnez les petites demandes d'E/S pour améliorer l'efficacité de l'extraction
-
Cache local : fichiers de cache extraits par OSS, prise en charge de la mémoire et du cache disque
résultats des tests de performances
Les tests de performance ont été effectués à l'aide du TSBS. Les paramètres de mesure de pression sont les suivants :
-
10 balises
-
10 champs
-
Chronologie (Numéro de combinaison de balises) Niveau 100w
Configuration de la machine d'essai de pression : 24c90g
Version InfluxDB : 1.8.5
Version CeresDB : 1.0.0
Comparaison des performances d'écriture
Les performances d'écriture d'InfluxDB se dégradent davantage avec le temps. Une fois l'écriture de CeresDB stable, le taux d'écriture a tendance à être stable et les performances d'écriture globales sont plus de 1,5 fois supérieures à celles d'InfluxDB (l'écart peut être supérieur à 2 fois après un certain temps)
Dans la figure ci-dessous, une seule ligne contient 10 champs.
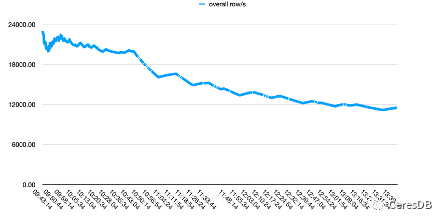
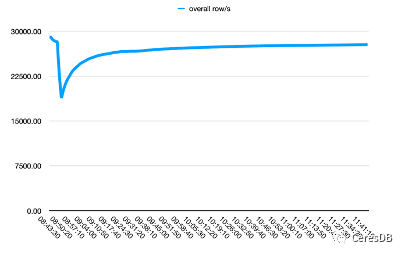
L'image ci-dessus est Influxdb, et l'image ci-dessous est CeresDB
Comparaison des performances des requêtes
Condition de filtrage basse (condition : os=Ubuntu15.10), CeresDB est 26 fois plus rapide qu'InfluxDB, les données spécifiques sont les suivantes :
-
Temps de requête CeresDB : 15 s
-
Temps de requête InfluxDB : 6m43s
Conditions de filtrage élevées (moins d'accès aux données, condition : hostname=[8], à ce moment l'index inversé traditionnel sera plus efficace en théorie), c'est un scénario où InfluxDB a plus d'avantages, et à ce moment sous la condition que le le préchauffage est terminé, CeresDB est 5 fois plus lent qu'InfluxDB.
-
CeresDB:85ms
-
InfluxDB:15ms
feuille de route 2023
L'équipe de développement a déclaré qu'en 2023, après la sortie de CeresDB 1.0, la plupart de leurs travaux se concentreront sur les performances, la distribution et l'écologie environnante. En particulier, le support d'amarrage de l'écologie environnante espère faciliter l'utilisation de CeresDB par divers utilisateurs :
Écologie environnante
-
Compatibilité écologique, y compris la compatibilité avec les protocoles de base de données de séries chronologiques courants tels que PromQL, InfluxdbQL et OpenTSDB
-
Prise en charge des outils d'exploitation et de maintenance, y compris la prise en charge de k8s, le système d'exploitation et de maintenance CeresDB, l'autosurveillance, etc.
-
Outils de développement, y compris l'importation et l'exportation de données, etc.
performance
-
Explorer de nouveaux formats de stockage
-
Améliorer différents types d'index pour améliorer les performances de CeresDB sous différentes charges de travail
distribué
-
équilibrage de charge automatique
-
Améliorer la disponibilité, la fiabilité