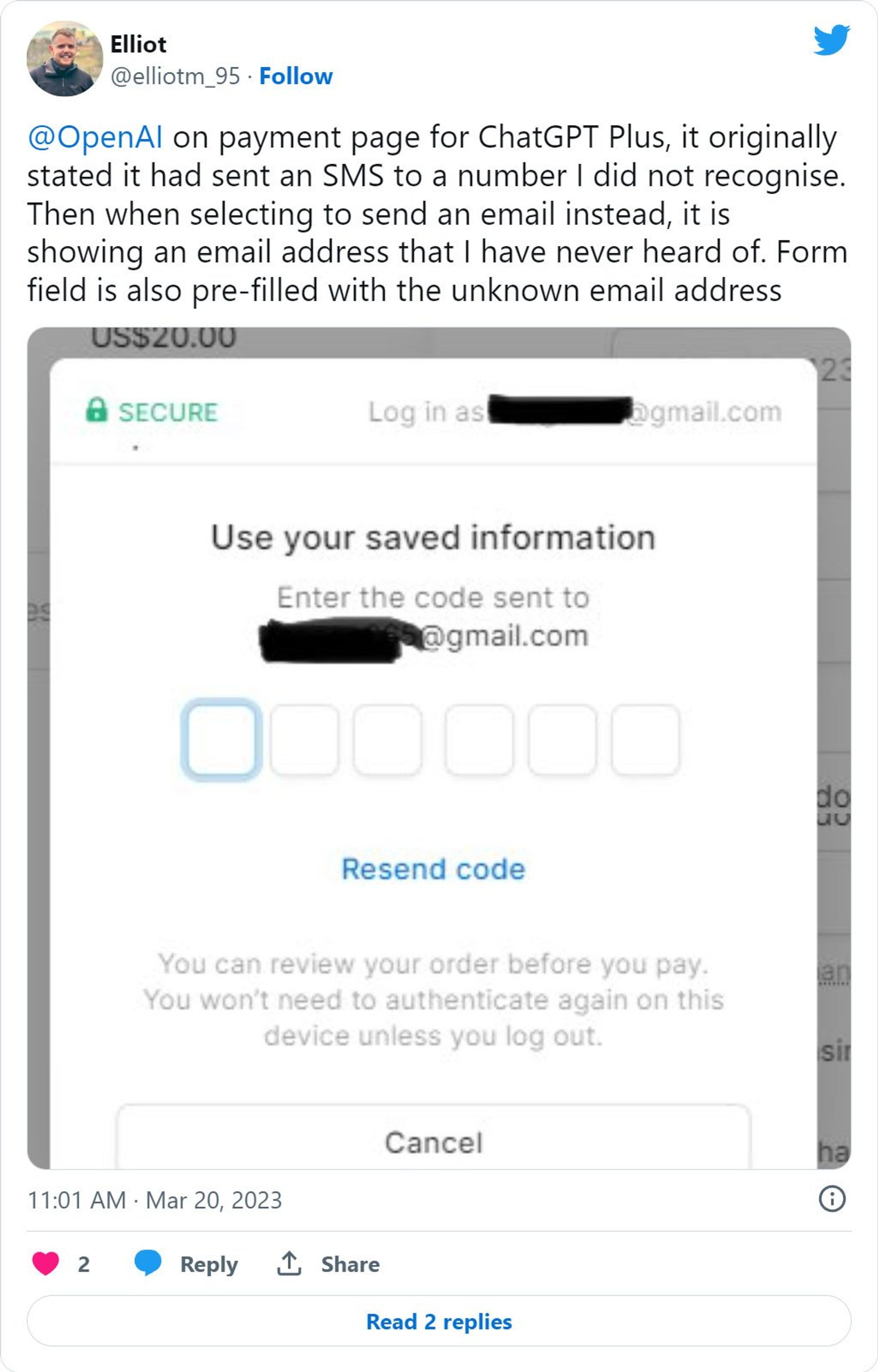
Lundi, ChatGPT a subi une fuite de données utilisateur et de nombreux utilisateurs de ChatGPT ont vu les enregistrements de conversation d'autres personnes dans leurs conversations historiques. Non seulement l'historique de la conversation, mais de nombreux utilisateurs de ChatGPT Plus ont également envoyé des captures d'écran sur des plateformes telles que Reddit et Twitter, affirmant qu'ils avaient vu les adresses e-mail d'autres personnes sur leurs pages d'abonnement.
Après l"incident, OpenAI a temporairement fermé le service ChatGPT pour enquêter sur le problème. Plus tard, le PDG d"Open AI, Sam Altman, s"est également tweeté , admettant qu"ils avaient effectivement rencontré un problème majeur, mais n"a pas annoncé les détails du problème à l"époque, disant seulement que cela a été causé par un bogue dans une bibliothèque open source.

Nous avons eu un problème majeur dans ChatGPT en raison d'un bogue dans une bibliothèque open source, et maintenant un correctif a été publié et nous venons de terminer la vérification.
Un petit pourcentage d'utilisateurs peut voir les titres des historiques de conversation des autres utilisateurs.
Après plusieurs jours d'enquête, OpenAI a publié un rapport d'incident avec des détails techniques. L'incident a été causé par un bogue dans la bibliothèque open source du client Redis, qui a amené le service ChatGPT à exposer l'historique des requêtes de chat d'autres utilisateurs et environ 1,2 % Informations personnelles des utilisateurs de ChatGPT Plus.
détails techniques
Ce bogue a été découvert dans la bibliothèque open source du client Redis redis-py. Après avoir découvert ce bogue, OpenAI a immédiatement contacté les responsables de Redis et fourni un correctif pour résoudre ce problème. Voici les détails spécifiques de cette erreur :
- OpenAI utilise Redis pour mettre en cache les informations des utilisateurs dans leurs serveurs, de sorte que ChatGPT n'a pas besoin de vérifier la base de données pour chaque demande.
- OpenAI utilise Redis Cluster pour répartir cette charge sur plusieurs instances Redis.
- OpenAI utilise la bibliothèque redis-py pour permettre à un serveur Python utilisant Asyncio de s'interfacer avec Redis.
- La bibliothèque gère un pool partagé de connexions entre le serveur et le cluster, et recycle les connexions une fois terminées pour les utiliser pour une autre demande.
- Lors de l'utilisation d'Asyncio, les demandes et les réponses de redis-py se comportent comme deux files d'attente : l'appelant place la demande dans la file d'attente entrante, retire la réponse de la file d'attente sortante et renvoie la connexion au pool.
- Si la requête est annulée après que la requête ait été poussée vers la file d'attente entrante, mais avant que la réponse ne soit extraite de la file d'attente sortante, nous voyons une erreur : la connexion est ainsi détruite, et la prochaine réponse retirée de la file d'attente pour une requête non liée peut Recevoir des données laissé sur la connexion.
- Dans la plupart des cas, cela entraînera une erreur de serveur irrécupérable et l'utilisateur devra réessayer sa demande.
- Mais dans certains cas, les données corrompues correspondent au type de données que le demandeur attendait, de sorte que les données renvoyées par le cache semblent être valides, même si les données appartenaient à un autre utilisateur.
- À 1 h 00 PT le lundi 20 mars, OpenAI a introduit par inadvertance une modification de ses serveurs qui a provoqué une augmentation des annulations de demandes Redis. Cela augmente quelque peu la possibilité que chaque connexion renvoie des données incorrectes.
- Ce bogue n'est apparu que dans le client Asyncio redis-py pour Redis Cluster et a maintenant été corrigé.
Après une enquête approfondie, OpenAI a découvert que certains utilisateurs pouvaient avoir vu les noms, les adresses e-mail, les adresses de facturation, les quatre derniers chiffres des numéros de carte de crédit et les dates d'expiration des cartes de crédit d'autres utilisateurs actifs. OpenAI a souligné que le numéro de carte de crédit complet n'a pas été exposé. .
Cette partie des utilisateurs concernés représente 1,2 % du nombre total d'utilisateurs de ChatGPT Plus, et ils contactent actuellement tous les utilisateurs de ChatGPT concernés.