Supposons que vous ayez maintenant les données et le budget, que tout soit prêt et que vous soyez prêt à commencer à former un grand modèle. Une fois que vous avez montré vos compétences, "voir toutes les fleurs à Chang'an en une journée" semble être à portée de main le coin... Attendez une minute ! La formation n'est pas aussi simple que la prononciation de ces deux mots, il peut être utile de voir la formation de BLOOM.
Ces dernières années, il est devenu la norme pour les modèles de langage de devenir de plus en plus gros. Les gens critiquent généralement le fait que les informations de ces grands modèles eux-mêmes ne sont pas divulguées pour la recherche, mais peu d'attention est accordée aux connaissances derrière la technologie de formation des grands modèles. Cet article vise à prendre le modèle de langage BLOOM avec 176 milliards de paramètres comme exemple pour clarifier l'ingénierie logicielle et matérielle et les points techniques derrière la formation de tels modèles, afin de promouvoir la discussion sur la technologie de formation de grands modèles.
Tout d'abord, nous tenons à remercier les entreprises, les individus et les groupes qui ont permis ou parrainé l'aboutissement de l'incroyable exploit de notre groupe consistant à former un modèle de 176 milliards de paramètres.
Ensuite, nous commençons à discuter de la configuration matérielle et des principaux composants techniques.

Voici un bref résumé du projet :
| matériel | 384 GPU A100 de 80 Go |
| logiciel | Megatron-DeepSpeed |
| architecture modèle | Basé sur GPT3 |
| base de données | 350 milliards de mots dans 59 langues |
| temps de formation | 3,5 mois |
Composition du personnel
Le projet a été conçu par Thomas Wolf (Co-Fondateur et CSO de Hugging Face), qui a osé rivaliser avec les grandes entreprises, proposant non seulement de former un modèle qui se dresse sur la plus grande forêt de modèles multilingues au monde, mais aussi de le faire accessible à tous L'accès public aux résultats de la formation répond aux rêves de la plupart des gens.
Cet article se concentre sur les aspects techniques de la formation de modèles. Certaines des parties les plus importantes de la technologie derrière BLOOM sont les personnes et les entreprises qui partagent leur expertise et nous aident à coder et à former.
Nous devons principalement remercier 6 groupes :
- L'équipe BigScience de HuggingFace a consacré plus de six employés à temps plein à la recherche et au fonctionnement de la formation, et ils ont également fourni ou remboursé toute infrastructure autre que l'ordinateur de Jean Zay.
- Les développeurs de l'équipe Microsoft DeepSpeed , qui ont développé DeepSpeed et l'ont ensuite intégré à Megatron-LM, ont passé des semaines à rechercher les exigences du projet et ont fourni de nombreux conseils pratiques avant et pendant la formation.
- L'équipe NVIDIA Megatron-LM qui a développé Megatron-LM a été plus qu'heureuse de répondre à nos nombreuses questions et de fournir des conseils d'utilisation de premier ordre.
- L'équipe IDRIS/GENCI, qui gère le supercalculateur Jean Zay, a fait don d'une puissance de calcul importante et d'un solide support d'administration système au projet.
- L'équipe PyTorch a créé un cadre puissant sur lequel repose le reste du logiciel et nous a beaucoup aidés à nous préparer à la formation, à corriger plusieurs bogues et à améliorer la convivialité de la formation des composants PyTorch dont nous dépendons.
- Volontaire du groupe de travail BigScience Engineering
Il est difficile de nommer toutes les personnes brillantes qui ont contribué à l'ingénierie du projet, je vais donc citer quelques personnes clés en dehors de Hugging Face qui ont jeté les bases techniques du projet au cours des 14 derniers mois :
Olatunji Ruwase, Deepak Narayanan, Jeff Rasley, Jared Casper, Samyam Rajbhandari et Rémi Lacroix
Nous remercions également toutes les entreprises qui ont permis à leurs employés de contribuer à ce projet.
aperçu
L'architecture du modèle de BLOOM est très similaire à GPT3 avec quelques améliorations, qui sont discutées plus loin dans cet article.
Le modèle a été formé sur Jean Zay, un supercalculateur financé par le gouvernement français géré par GENCI et installé à l'IDRIS, le centre de calcul national du Centre national de la recherche scientifique (CNRS). La puissance de calcul nécessaire à la formation est généreusement reversée à ce projet par GENCI (numéro de don 2021-A0101012475).
Matériel d'entraînement :
- GPU : 384 GPU NVIDIA A100 80 Go (48 nœuds) + 32 GPU de rechange
- 8 GPU par nœud, 4 interconnexions inter-cartes NVLink, 4 liaisons OmniPath
- Processeur : processeur AMD EPYC 7543 32 cœurs
- Mémoire CPU : 512 Go par nœud
- Mémoire GPU : 640 Go par nœud
- Connexion inter-nœuds : la carte réseau Omni-Path Architecture (OPA) est utilisée et la topologie du réseau est un fat tree non bloquant
- NCCL - Communications Network : un sous-réseau entièrement dédié
- Réseau Disk IO : GPFS partagé avec d'autres nœuds et utilisateurs
Points de contrôle :
- points de contrôle principaux
- Chaque point de contrôle contient un état de l'optimiseur avec une précision de fp32 et un poids avec une précision de bf16+fp32, et occupe un espace de stockage de 2,3 To. Si seul le poids de bf16 est enregistré, seuls 329 Go d'espace de stockage seront occupés.
base de données:
- 1,5 To de texte fortement dédupliqué et nettoyé dans 46 langues, converti en jetons de 350 B
- Le vocabulaire du modèle contient 250 680 jetons
- Pour plus de détails, veuillez vous référer à The BigScience Corpus A 1.6TB Composite Multilingual Dataset
La formation du modèle 176B BLOOM a duré environ 3,5 mois, de mars à juillet 2022 (environ 1 million d'heures de calcul).
Megatron-DeepSpeed
Le modèle 176B BLOOM est formé à l'aide de Megatron-DeepSpeed , qui combine deux techniques principales :
- Megatron-DeepSpeed :
- DeepSpeed est une bibliothèque d'optimisation d'apprentissage en profondeur qui rend la formation distribuée simple, efficace et efficiente.
- Megatron-LM est un cadre de modèle de transformateur vaste et puissant développé par l'équipe de recherche appliquée en apprentissage profond de NVIDIA.
L'équipe DeepSpeed a développé un schéma basé sur le parallèle 3D en combinant le partitionnement ZeRO et le parallélisme de pipeline dans la bibliothèque DeepSpeed avec le parallélisme tenseur dans Megatron-LM. Voir le tableau ci-dessous pour plus de détails sur chaque composant.
Veuillez noter que Megatron-DeepSpeed de BigScience est basé sur la base de code Megatron-DeepSpeed d'origine , et nous y avons ajouté pas mal de codes.
Le tableau suivant répertorie les composants de chacun des deux frameworks que nous utilisons lors de la formation de BLOOM :
| Composants | DeepSpeed | Mégatron-LM |
|---|---|---|
| Parallèle de données Zéro | Oui | |
| Tenseur Parallèle | Oui | |
| Pipeline Parallèle | Oui | |
| Optimiseur BF16 | Oui | |
| Fonction noyau de fusion CUDA | Oui | |
| chargeur de données | Oui |
Notez que Megatron-LM et DeepSpeed ont des implémentations de parallélisme en pipeline et d'optimiseur BF16, mais nous utilisons l'implémentation de DeepSpeed car elles sont intégrées à ZeRO.
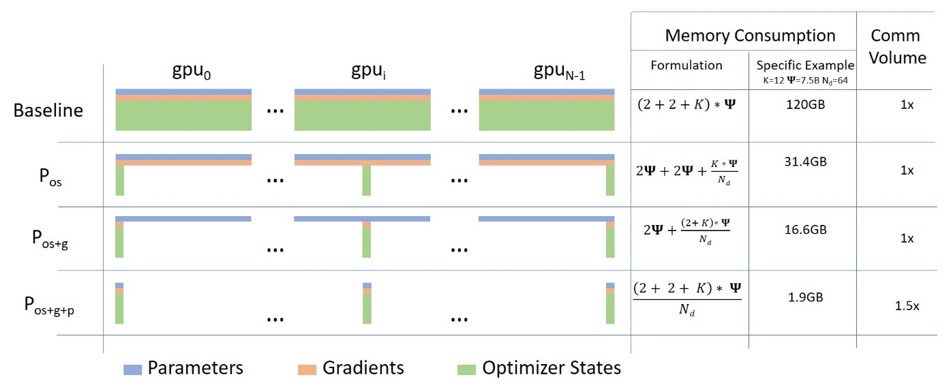
Megatron-DeepSpeed atteint le parallélisme 3D pour permettre à de grands modèles d'être entraînés de manière très efficace. Discutons brièvement de ce que sont les composants 3D.
- Parallélisme des données (DP) - La même configuration et le même modèle sont répliqués plusieurs fois, chacun alimenté avec une copie différente des données à chaque fois. Le traitement est effectué en parallèle, avec tous les partages synchronisés à la fin de chaque étape de formation.
- Parallélisme du tenseur (TP) - Chaque tenseur est divisé en morceaux, de sorte que chaque tranche du tenseur réside sur son GPU attribué, plutôt que d'avoir le tenseur entier sur un seul GPU. Lors du traitement, chaque shard est traité séparément et en parallèle sur un GPU différent, et les résultats sont synchronisés à la fin de l'étape. C'est ce qu'on appelle le parallélisme horizontal, car il se fait horizontalement.
- Parallélisme de pipeline (PP) - Le modèle est divisé verticalement (c'est-à-dire par couche) sur plusieurs GPU afin qu'une ou plusieurs couches de modèle soient placées sur un seul GPU. Chaque GPU traite différentes étapes du pipeline en parallèle et traite une partie du lot.
- Zero Redundancy Optimizer (ZeRO) - effectue également un partage de tenseur similaire à TP, mais le tenseur entier est reconstruit à temps pour le calcul direct ou inverse, donc aucune modification du modèle n'est nécessaire. Il prend également en charge diverses techniques de déchargement pour compenser la mémoire GPU limitée.
parallélisme des données
La plupart des utilisateurs ne disposant que de quelques GPU connaissent probablement (DDP), qui est la documentation PyTorchDistributedDataParallel correspondante . Dans cette approche, les modèles sont entièrement répliqués sur chaque GPU, puis tous les modèles synchronisent leurs états les uns avec les autres après chaque itération. Cette méthode peut accélérer la formation et résoudre les problèmes en investissant davantage de ressources GPU. Mais il a la limitation qu'il ne fonctionne que si le modèle tient sur un seul GPU.
Parallèle de données Zéro
Le diagramme suivant illustre bien le parallélisme des données ZeRO (à partir de ce billet de blog ).
Il semble être relativement grand, ce qui peut vous empêcher de vous concentrer sur la compréhension, mais en fait, le concept est très simple. Il s'agit simplement du DDP habituel, sauf qu'au lieu que chaque GPU réplique les paramètres complets du modèle, les gradients et l'état de l'optimiseur, chaque GPU n'en stocke qu'une partie. Lors des exécutions suivantes, lorsque les paramètres de couche complets pour une couche donnée sont requis, tous les GPU se synchronisent pour se fournir mutuellement leurs pièces manquantes - rien de plus.
Ce composant est implémenté par DeepSpeed.
Tenseur Parallèle
Dans le parallélisme tenseur (TP), chaque GPU ne traite qu'une partie d'un tenseur, et les opérations d'agrégation ne sont déclenchées que lorsque certains opérateurs nécessitent le tenseur complet.
Dans cette section, nous utilisons des concepts et des diagrammes de l' article Megatron-LM Efficient Large-Scale Language Model Training on GPU Clusters .
Les principaux modules du modèle de classe Transformer sont : une couche entièrement connectée nn.Linearsuivie d'une couche d'activation non linéaire GeLU.
En suivant la notation de l'article Megatron, nous pouvons écrire la partie produit scalaire sous la forme Y = GeLU (XA), où Xet Ysont les vecteurs d'entrée et de sortie, Aet est la matrice de pondération.
Il est facile de voir comment la multiplication matricielle peut être répartie sur plusieurs GPU si elle est exprimée sous forme matricielle :
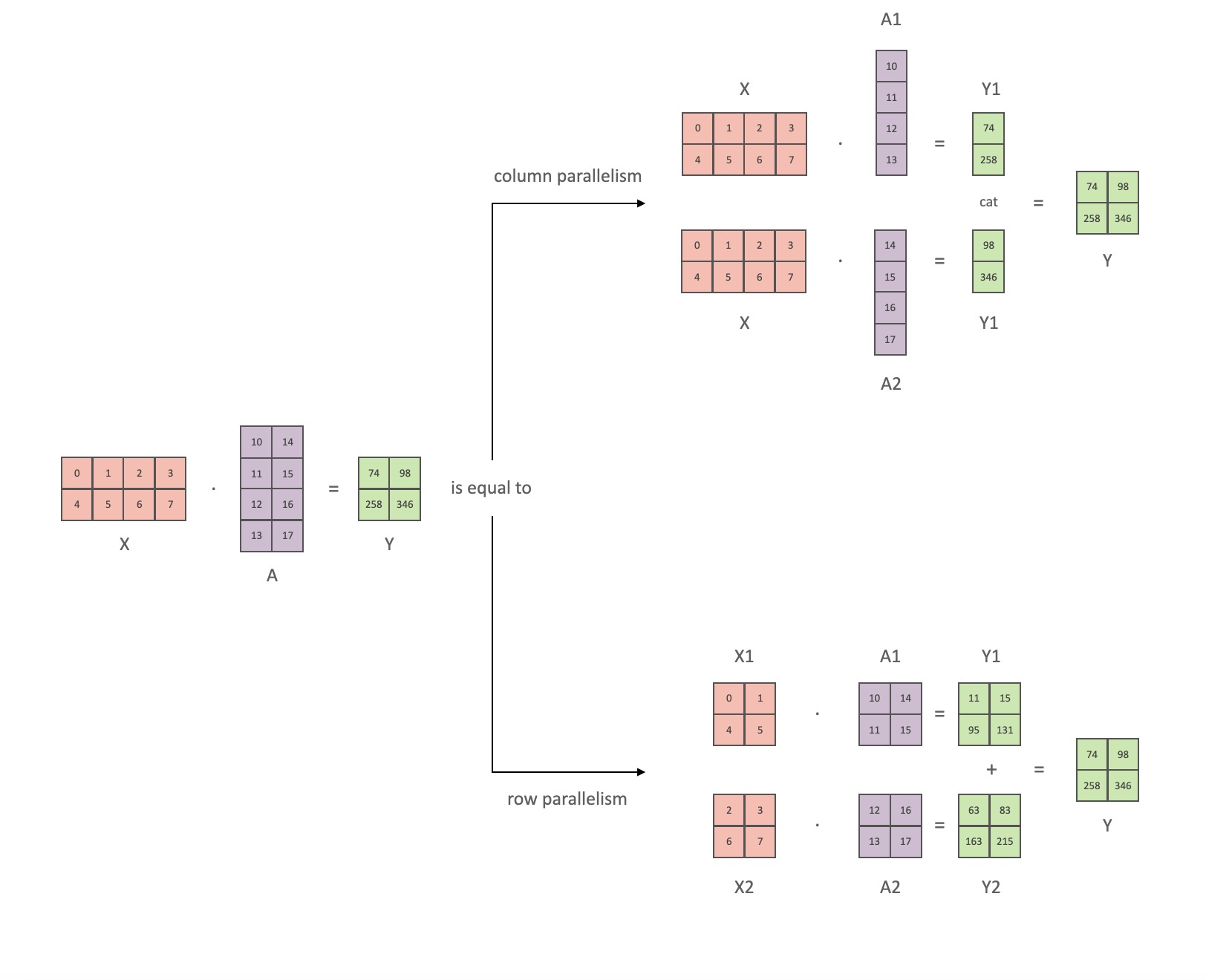
Si nous divisons les matrices de poids Apar colonnes Nsur les GPU, puis effectuons des multiplications matricielles XA_1en XA_n, nous nous retrouvons Navec des vecteurs de sortie Y_1、Y_2、…… 、 Y_n, qui peuvent être alimentés indépendamment GeLU:
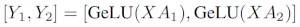
Notez que parce que Yla matrice est divisée par colonne, nous pouvons choisir le schéma de division par ligne pour le GEMM suivant, afin qu'il puisse obtenir directement la sortie du GeLU de la couche précédente sans aucune communication supplémentaire.
En utilisant ce principe, nous pouvons mettre à jour un MLP de profondeur arbitraire, simplement en synchronisant le GPU après chaque 拆列 - 拆行séquence . Les auteurs de l'article Megatron-LM en fournissent une belle illustration :
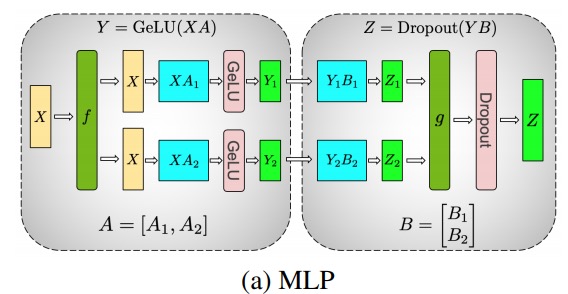
fVoici l'opérateur d'identité dans la passe avant et tout réduit dans la passe arrière, et gest le tout réduit dans la passe avant et l'identité dans la passe arrière.
La parallélisation des couches d'attention multi-têtes est encore plus simple car elles sont intrinsèquement parallèles en raison de plusieurs têtes indépendantes !
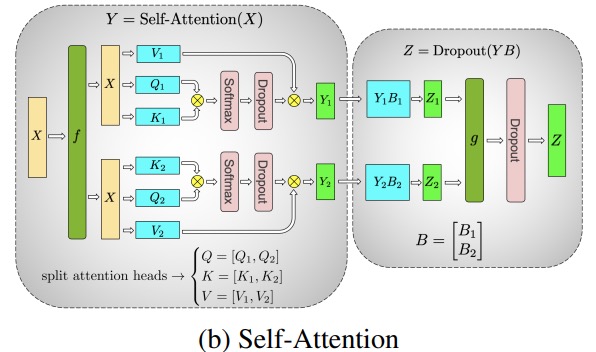
Considérations spéciales : étant donné qu'il existe deux réductions totales par couche dans les passes avant et arrière, TP nécessite des interconnexions très rapides entre les appareils. Par conséquent, à moins que vous n'ayez un réseau très rapide, il n'est pas recommandé de faire du TP sur plusieurs nœuds. Dans notre configuration matérielle pour la formation BLOOM, la vitesse entre les nœuds est beaucoup plus lente que PCIe. En fait, si le nœud a 4 GPU, un degré TP maximum de 4 est préférable. Si vous avez besoin d'un degré TP de 8, vous devez utiliser un nœud avec au moins 8 GPU.
Ce composant est mis en œuvre par Megatron-LM. Megatron-LM a récemment étendu la capacité parallèle du tenseur et ajouté la capacité de parallélisme de séquence pour les opérateurs qui sont difficiles à utiliser l'algorithme de segmentation susmentionné, tel que LayerNorm. L'article sur la réduction du recalcul d'activation dans les modèles de grands transformateurs fournit des détails sur cette technique. Le parallélisme de séquence a été développé après la formation de BLOOM, donc BLOOM a été formé sans cette technique.
Pipeline Parallèle
Le parallélisme de pipeline naïf (PP naïf) consiste à répartir les couches de modèle en groupes sur plusieurs GPU et à déplacer simplement les données d'un GPU à l'autre comme s'il s'agissait d'un seul grand GPU composite. Le mécanisme est relativement simple - vous liez la couche souhaitée au périphérique correspondant avec .to()la méthode , et maintenant chaque fois que des données entrent ou sortent de ces couches, les couches basculent les données vers le même périphérique que la couche, et le reste reste le même.
Il s'agit en fait d'un parallélisme de modèle vertical, car si vous vous souvenez de la façon dont nous dessinons la topologie de la plupart des modèles, nous divisons en fait les couches du modèle verticalement. Par exemple, si l'image ci-dessous montre un modèle à 8 couches :
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
GPU0 GPU1
Nous l'avons coupé verticalement en 2 parties, en plaçant les couches 0-3 sur GPU0 et les couches 4-7 sur GPU1.
Désormais, lorsque les données sont transmises de la couche 0 à la couche 1, de la couche 1 à la couche 2 et de la couche 2 à la couche 3, c'est comme une transmission normale sur un seul GPU. Mais lorsque les données doivent passer de la couche 3 à la couche 4, elles doivent être transférées de GPU0 à GPU1, ce qui introduit une surcharge de communication. Si les GPU participants se trouvent sur le même nœud de calcul (par exemple, la même machine physique), le transfert est très rapide, mais si les GPU se trouvent sur différents nœuds de calcul (par exemple, plusieurs machines), la surcharge de communication peut être beaucoup plus importante.
Ensuite, les couches 4 à 5 à 6 à 7 ressemblent à nouveau à des modèles normaux, et lorsque la couche 7 est terminée, nous devons généralement renvoyer les données à la couche 0 où se trouvent les étiquettes (ou envoyer les étiquettes à la dernière couche). Maintenant, la perte peut être calculée et l'optimiseur peut être utilisé pour mettre à jour les paramètres.
question:
- Pourquoi cette méthode est-elle appelée parallélisme de pipeline naïf et quels sont ses inconvénients ? Principalement parce que le schéma a tous sauf un GPU inactif à un moment donné. Donc, si vous utilisez 4 GPU, vous quadruplez presque la quantité de mémoire sur un seul GPU, et les autres ressources (comme le calcul) sont pratiquement inutiles. Ajoutez les frais généraux liés à la copie de données entre les appareils. Ainsi, 4 cartes de 6 Go en parallèle utilisant un pipeline naïf pourront contenir le même modèle de taille qu'une carte de 24 Go qui s'entraîne plus rapidement car elle n'a pas de surcharge de transfert de données. Mais, par exemple, si vous avez une carte de 40 Go, mais que vous devez exécuter un modèle de 45 Go, vous pouvez utiliser 4 cartes de 40 Go (ce qui est juste suffisant, car il existe également des gradients et des états d'optimisation qui nécessitent de la mémoire vidéo).
- Le partage d'incorporations peut nécessiter une copie dans les deux sens entre les GPU. Le parallélisme pipeline (PP) que nous utilisons est presque le même que le PP naïf ci-dessus, mais il résout le problème d'inactivité du GPU en fragmentant les lots entrants en micros lots et en créant artificiellement des pipelines qui permettent à différents GPU de participer simultanément au processus de calcul.
La figure ci-dessous est tirée du papier GPipe , la partie supérieure représente le schéma PP naïf et la partie inférieure est la méthode PP :

Dans la moitié inférieure de la figure, il est facile de voir que PP a moins de zone morte (ce qui signifie que le GPU est inactif), c'est-à-dire moins de "bulles".
Le degré de parallélisme des deux schémas de la figure est de 4, c'est-à-dire que le pipeline est composé de 4 GPU. Il y a donc quatre chemins aller de F0, F1, F2 et F3, puis le chemin inverse de B3, B2, B1 et B0.
PP introduit un nouvel hyperparamètre à régler, appelé 块 (chunks). Il définit le nombre de blocs de données envoyés séquentiellement via le même niveau de canal. Par exemple, dans la moitié inférieure de la figure, vous pouvez voir chunks = 4. GPU0 exécute le même chemin vers l'avant sur les morceaux 0, 1, 2 et 3 (F0,0, F0,1, F0,2, F0,3) puis attend que les autres GPU terminent leur travail avant que GPU0 ne recommence à fonctionner, exécutez le chemin de retour pour les blocs 3, 2, 1 et 0 (B0,3, B0,2, B0,1, B0,0).
Notez que c'est conceptuellement le même que les étapes d'accumulation de gradient (GAS). PyTorch l'appelle 块, et DeepSpeed l'appelle GAS.
Parce que 块, PP introduit le concept de micro-lots (MBS). DP divise la taille de lot globale en petites tailles de lot, donc si le degré DP est de 4, la taille de lot globale 1024 sera divisée en 4 petites tailles de lot, et chaque petite taille de lot est de 256 (1024/4). Et si 块le nombre (ou GAS) est 32, nous nous retrouvons avec une taille de micro-lot de 8 (256/32). Chaque étage de tube traite un micro-lot à la fois.
La formule pour calculer la taille de lot globale pour le paramètre DP+PP est : mbs * chunks * dp_degree( 8 * 32 * 4 = 1024).
Revenons en arrière et regardons à nouveau l'image.
En utilisant un PP naïf, chunks=1vous vous retrouvez avec un PP naïf, qui est très inefficace. Et avec de très grands 块nombres , vous vous retrouvez avec de petites tailles de micro-lots, qui ne sont probablement pas très efficaces non plus. Par conséquent, il faut expérimenter pour trouver 块le nombre .
Le graphique montre qu'il existe des bulles de temps "mortes" qui ne peuvent pas être parallélisées car la dernière forwardétape doit attendre backwardla fin du pipeline. Ensuite, le problème de trouver le 块nombre pour que tous les GPU participants puissent atteindre une utilisation simultanée élevée est en fait transformé en minimisation du nombre de bulles.
Ce mécanisme d'ordonnancement est appelé 全前全后. Certaines autres options sont Tandem et Interleaved Tandem .
Alors que Megatron-LM et DeepSpeed ont leurs propres implémentations du protocole PP, Megatron-DeepSpeed utilise l'implémentation DeepSpeed car elle est intégrée à d'autres fonctionnalités de DeepSpeed.
Un autre problème important ici est la taille de la matrice d'incorporation de mots. Alors que les matrices d'intégration de mots nécessitent généralement moins de mémoire que les blocs transformateurs, dans le cas de BLOOM avec un vocabulaire de 250k, la couche d'intégration nécessite 7,2 Go pour les poids bf16, contre seulement 4,9 Go pour le bloc transformateur. Par conséquent, nous avons dû faire en sorte que Megatron-Deepspeed traite la couche d'intégration comme un bloc transformateur. Nous avons donc un pipeline de 72 étapes, dont 2 sont dédiées à l'intégration (première et dernière). Cela nous permet d'équilibrer la consommation mémoire du GPU. Si nous ne le faisions pas, les première et dernière étapes consommeraient beaucoup de mémoire GPU, et 95 % de l'utilisation de la mémoire GPU serait très faible, de sorte que l'entraînement serait très inefficace.
DP+PP
Il y a une image dans le tutoriel DeepSpeed Pipeline Parallel qui montre comment combiner DP et PP, comme indiqué ci-dessous.
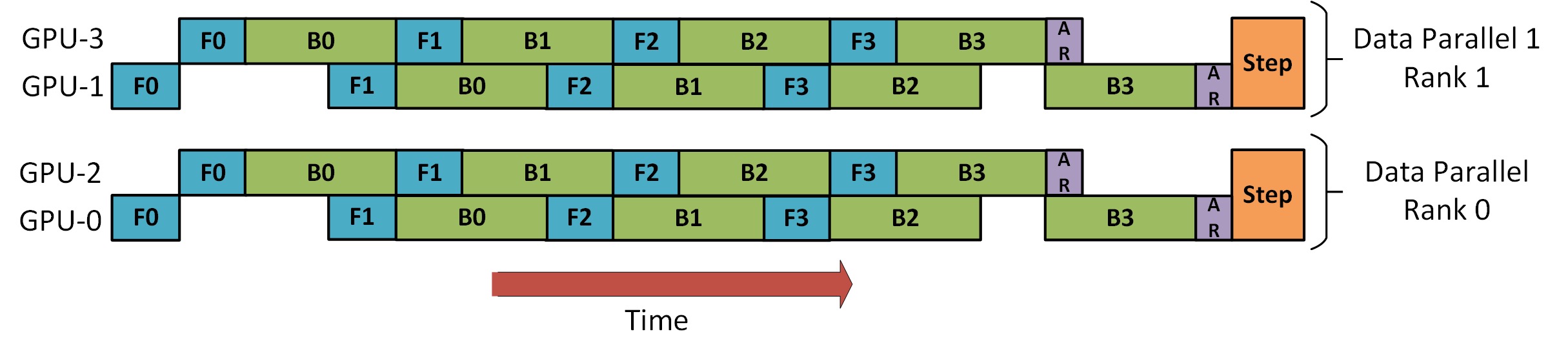
La chose importante à comprendre ici est que le rang DP 0 ne peut pas voir GPU2, et le rang DP 1 ne peut pas voir GPU3. Pour DP, il n'y a que les GPU 0 et 1, et les données leur sont transmises. GPU0 utilise PP pour décharger "secrètement" une partie de sa charge sur GPU2. De même, GPU1 recevra également l'aide de GPU3.
Étant donné qu'au moins 2 GPU sont nécessaires pour chaque dimension, au moins 4 GPU sont nécessaires ici.
DP+PP+TP
Pour un entraînement plus efficace, PP, TP et DP peuvent être combinés, appelé parallélisme 3D, comme illustré dans la figure ci-dessous.
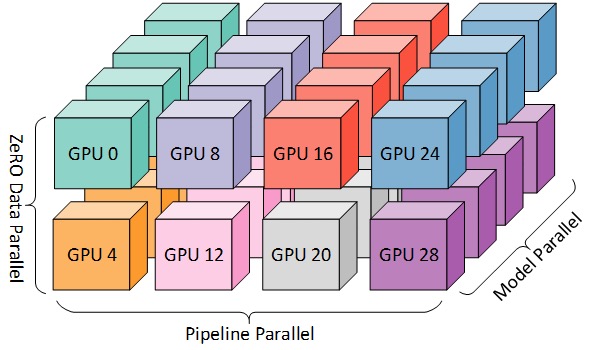
Ce chiffre est tiré du billet de blog 3D Parallelism: Scaling to Trillion Parameter Models ), qui est également un bon article.
Comme vous avez besoin d'au moins 2 GPU par dimension, ici vous avez besoin d'au moins 8 GPU pour un parallélisme 3D complet.
Zéro DP+PP+TP
L'une des principales fonctionnalités de DeepSpeed est ZeRO, qui est une version améliorée super évolutive de DP, dont nous avons parlé dans la section [ZeRO Data Parallel] (#ZeRO- Data Parallel). Il s'agit généralement d'une fonction indépendante et ne nécessite ni PP ni TP. Mais il peut aussi être combiné avec PP, TP.
Lorsque ZeRO-DP est combiné avec PP (et donc TP), il n'active généralement que la phase 1 de ZeRO, qui ne fragmente que l'état de l'optimiseur. L'étape 2 de ZeRO fragmente également les gradients, et l'étape 3 fragmente également les poids du modèle.
Bien qu'il soit théoriquement possible d'utiliser ZeRO stage 2 avec le parallélisme de pipeline, cela peut avoir un impact négatif sur les performances. Chaque micro-lot nécessite une communication de réduction de diffusion supplémentaire pour agréger les gradients avant le partitionnement, ce qui ajoute une surcharge de communication potentiellement importante. Selon la nature parallèle du pipeline, nous utiliserons de petits micro-lots et nous concentrerons sur le compromis entre l'intensité arithmétique (taille du micro-lot) et la minimisation des bulles de pipeline (nombre de micro-lots). Par conséquent, l'augmentation des frais généraux de communication nuit au parallélisme du pipeline.
De plus, en raison du PP, le nombre de couches est déjà inférieur à la normale, donc cela n'économise pas beaucoup de mémoire. PP a réduit la taille du gradient 1/PP, de sorte que la tranche de gradient sur cette base n'économise pas beaucoup de mémoire par rapport au DP pur.
ZeRO stage 3 peut également être utilisé pour entraîner des modèles de cette taille, cependant, il nécessite plus de communication que DeepSpeed 3D en parallèle. Il y a un an, après une évaluation minutieuse de notre environnement, nous avons constaté que le parallélisme 3D Megatron-DeepSpeed fonctionnait le mieux. Les performances de ZeRO Phase 3 se sont considérablement améliorées depuis lors, et si nous devions la réévaluer aujourd'hui, nous choisirions peut-être la Phase 3.
Optimiseur BF16
La formation d'énormes modèles LLM avec FP16 est un non-non.
Nous l'avons démontré par nous-mêmes en passant des mois à former le modèle 104B, qui, comme vous pouvez le voir sur Tensorboard , a complètement échoué. Dans le processus de lutte contre la lm-loss toujours divergente, nous avons beaucoup appris :
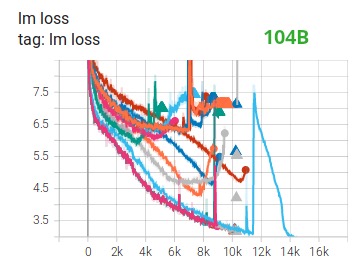
Nous avons également reçu la même suggestion des équipes Megatron-LM et DeepSpeed après avoir formé le modèle 530B . L' OPT-175B récemment sorti a également signalé qu'il s'était entraîné très dur sur le FP16.
Donc, en janvier, nous savions que nous allions nous entraîner sur l'A100 qui prend en charge le format BF16. Olatunji Ruwase a développé un "BF16Optimizer" pour la formation BLOOM.
Si vous n'êtes pas familier avec ce format de données, consultez sa disposition en bits . La clé du format BF16 est qu'il a le même nombre d'exposants que FP32, donc il ne débordera pas, mais FP16 déborde souvent ! FP16 a une plage de valeurs maximale de 64k, vous ne pouvez multiplier que des nombres plus petits. Par exemple, vous pouvez faire 250*250=62500, mais si vous essayez 255*255=65025, vous allez déborder, ce qui est la principale cause de problèmes d'entraînement. Cela signifie que vos poids doivent rester petits. Une technique appelée mise à l'échelle des pertes aide à atténuer ce problème, mais la petite portée du FP16 peut toujours être un problème lorsque les modèles deviennent très volumineux.
Le BF16 n'a pas ce problème, vous pouvez le faire facilement 10_000*10_000=100_000_000, pas de problème du tout.
Bien sûr, puisque BF16 et FP16 ont la même taille, 2 octets, il n'y a pas de repas gratuit, et le compromis lors de l'utilisation de BF16 est qu'il a une très mauvaise précision. Cependant, il faut se souvenir que la méthode de descente de gradient stochastique et ses variantes que nous utilisions à l'entraînement, cette méthode est un peu comme l'étalement, si vous ne trouvez pas la direction parfaite à cette étape, ce n'est pas grave, vous la corrigerez dans la suivante étape Propre.
Que vous utilisiez BF16 ou FP16, il y a une copie des poids qui est toujours dans FP32 - c'est ce qui est mis à jour par l'optimiseur. Ainsi, le format 16 bits n'est utilisé que pour les calculs, l'optimiseur met à jour les poids FP32 avec une précision totale, puis les convertit au format 16 bits pour la prochaine itération.
Tous les composants PyTorch ont été mis à jour pour garantir qu'ils effectuent toute accumulation dans FP32, afin qu'aucune perte de précision ne se produise.
Un problème clé est l'accumulation de gradients, qui est l'une des principales caractéristiques du parallélisme de pipeline, puisque les gradients traités par chaque micro-lot sont accumulés. La mise en œuvre de l'accumulation de gradient dans FP32 pour la précision de l'entraînement est essentielle, et c'est exactement BF16Optimizerce qui a été fait .
Entre autres améliorations, nous pensons que l'utilisation de l'entraînement à précision mixte BF16 a transformé un cauchemar potentiel en un processus relativement fluide, comme le montre le diagramme de perte de lm suivant :
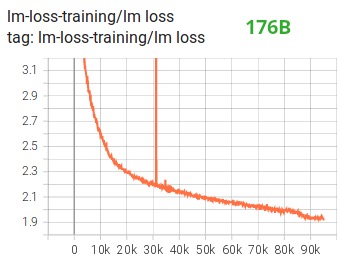
Fonction noyau de fusion CUDA
Le GPU fait principalement deux choses. Il peut écrire et lire des données dans la mémoire vidéo et effectuer des calculs sur ces données. Lorsque le GPU est occupé à lire et à écrire des données, les unités de calcul du GPU sont inactives. Si nous voulons utiliser efficacement le GPU, nous voulons réduire au minimum le temps d'inactivité.
Une fonction noyau est un ensemble d'instructions qui implémentent une opération PyTorch spécifique. Par exemple, torch.addlorsque , il passe par un planificateur PyTorch , qui décide quel code il doit exécuter en fonction des valeurs des tenseurs d'entrée et d'autres variables, et finalement l'exécute. Les noyaux CUDA utilisent CUDA pour implémenter ces codes et ne fonctionnent donc que sur les GPU NVIDIA.
Maintenant, c = torch.add (a, b); e = torch.max ([c,d])lors de , ce que PyTorch fera généralement est de lancer deux noyaux distincts, l'un qui fait l'ajout ade bet , cet l'autre qui prend le maximum des ddeux . Dans ce cas, le GPU arécupère bla somme de sa mémoire vidéo, effectue l'addition, puis réécrit le résultat dans la mémoire vidéo. Il prend ensuite cet det exécute maxl'opération , et réécrit le résultat dans la mémoire vidéo.
Si nous devions fusionner ces deux opérations, c'est-à-dire les placer dans une "fonction de noyau fusionné", puis lancer ce noyau, au lieu d' cécrire le résultat intermédiaire dans la mémoire vidéo, nous le conserverions dfaire le calcul final. Cela permet d'économiser beaucoup de frais généraux et empêche le GPU de tourner au ralenti, de sorte que l'ensemble de l'opération est beaucoup plus efficace.
La fonction du noyau de fusion fait exactement cela. Ils remplacent principalement les multiples calculs discrets et les mouvements de données vers et depuis la mémoire vidéo par des calculs fusionnés avec très peu de mouvements de données. De plus, certains noyaux de fusion transforment mathématiquement les opérations afin que certaines combinaisons de calculs puissent être effectuées plus rapidement.
Afin de former BLOOM rapidement et efficacement, il est nécessaire d'utiliser plusieurs fonctions personnalisées du noyau fusionné CUDA fournies par Megatron-LM. En particulier, il existe un noyau de fusion LayerNorm et des noyaux pour diverses combinaisons d'opérations de mise à l'échelle, de masquage et de softmax de fusion. Bias Add est également intégré à GeLU via la fonction JIT de PyTorch. Ces opérations sont toutes liées à la mémoire, il est donc important de les fusionner pour maximiser la quantité de calcul après chaque lecture de la mémoire vidéo. Ainsi, par exemple, l'exécution de Bias Add lors de l'exécution d'une opération GeLU dont le goulot d'étranglement est en mémoire n'augmentera pas le temps d'exécution. Ces fonctions du noyau se trouvent dans la bibliothèque de codes Megatron-LM .
base de données
Une autre caractéristique importante de Megatron-LM est le chargeur de données efficace. Avant le début de la première formation, chaque échantillon de chaque ensemble de données est divisé en échantillons de longueur de séquence fixe (BLOOM est 2048), et un index est créé pour numéroter chaque échantillon. Sur la base des hyperparamètres de formation, nous déterminerons le nombre d'époques auxquelles chaque ensemble de données doit participer, et sur cette base, créerons une liste ordonnée d'indices d'échantillons, puis la mélangerons. Par exemple, si un jeu de données comporte 10 échantillons qui doivent être formés pour 2 époques, le système trie d'abord les indices d'échantillons dans [0, ..., 9, 0, ..., 9]l'ordre puis mélange l'ordre pour créer l'ordre global final pour le jeu de données. Notez que cela signifie que la formation ne se contentera pas d'itérer sur l'ensemble de données et de se répéter, vous pouvez voir le même échantillon deux fois avant d'en voir un autre, mais à la fin de la formation, le modèle ne verra chaque échantillon que deux fois. Cela permet d'assurer une courbe d'entraînement fluide tout au long de l'entraînement. Ces indices, y compris le décalage de chaque échantillon dans l'ensemble de données d'origine, sont enregistrés dans un fichier pour éviter de les recalculer à chaque démarrage de l'apprentissage. Enfin, plusieurs de ces ensembles de données peuvent être combinés avec différents poids dans les données finales utilisées pour la formation.
Intégrer LayerNorm
Dans nos efforts pour empêcher la divergence du modèle 104B, nous avons constaté que l'ajout d'un LayerNorm supplémentaire après la première couche d'incorporation de mots rendait la formation plus stable.
Cette idée provient d' expériences avec bitsandbytes , qui a une opération qui est une intégration normale avec un LayerNorm initialisé avec une fonction xavier uniforme.StableEmbedding
code de localisation
Sur la base de l'article Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation , nous remplaçons également les plongements positionnels normaux par AliBi, qui permet l'extrapolation de séquences d'entrée plus longues que les séquences d'entrée utilisées pour former le modèle. Par conséquent, même si nous nous entraînons avec des séquences de longueur 2048, le modèle peut gérer des séquences plus longues lors de l'inférence.
difficultés de formation
Avec l'architecture, le matériel et les logiciels en place, nous avons pu commencer la formation début mars 2022. Depuis lors, cependant, les choses n'ont pas été sans heurts. Dans cette section, nous discutons de certains des principaux obstacles que nous avons rencontrés.
Avant le début de la formation, il y a beaucoup de questions à résoudre. En particulier, nous avons trouvé plusieurs problèmes qui ne sont apparus qu'après avoir commencé la formation sur 48 nœuds, et non à petite échelle. Par exemple, CUDA_LAUNCH_BLOCKING=1pour éviter que le cadre ne se bloque, nous devons diviser le groupe d'optimiseurs en groupes plus petits, sinon le cadre se bloquera à nouveau. Vous pouvez en savoir plus à ce sujet dans les chroniques de pré-formation.
Le principal type de problèmes rencontrés lors de la formation sont les pannes matérielles. Comme il s'agit d'un nouveau cluster avec environ 400 GPU, nous rencontrons en moyenne 1 à 2 pannes de GPU par semaine. Nous sauvegardons un point de contrôle toutes les 3 heures (100 itérations). En conséquence, nous perdons en moyenne 1,5 heure de formation par semaine à cause des pannes matérielles. L'administrateur système de Jean Zay remplacera alors le GPU défaillant et restaurera le nœud. En attendant, nous avons des nœuds de rechange disponibles.
Nous avons également rencontré divers autres problèmes qui ont entraîné plusieurs temps d'arrêt de 5 à 10 heures, certains liés à des bogues de blocage dans PyTorch, d'autres en raison d'un espace disque insuffisant. Si vous êtes intéressé par des détails, consultez les chroniques d'entraînement .
Tout ce temps d'arrêt était prévu dans l'analyse de faisabilité de la formation de ce modèle, et nous avons choisi la taille de modèle appropriée et la quantité de données que nous voulions que le modèle consomme en conséquence. Ainsi, même avec ces problèmes de temps d'arrêt, nous avons réussi à terminer la formation dans le délai estimé. Comme mentionné précédemment, il faut environ 1 million d'heures de calcul.
Un autre problème est que SLURM n'a pas été conçu pour être utilisé par un groupe de personnes. Les travaux SLURM appartiennent à un seul utilisateur, et s'ils ne sont pas là, les autres membres du groupe ne peuvent rien faire avec le travail en cours d'exécution. Nous avons un schéma de terminaison qui permet aux autres utilisateurs du groupe de terminer le processus en cours sans la présence de l'utilisateur qui a démarré le processus. Cela fonctionne très bien sur 90% des problèmes. Si les concepteurs de SLURM lisent ceci, veuillez ajouter le concept de groupe Unix afin qu'un travail SLURM puisse appartenir à un groupe.
Étant donné que la formation se déroule 24 heures sur 24, 7 jours sur 7, nous avons besoin de quelqu'un sur appel - mais comme nous avons des gens en Europe et sur la côte ouest du Canada, il n'est pas nécessaire que quelqu'un porte un téléavertisseur et nous sommes assez bons pour nous soutenir mutuellement. Bien sûr, les entraînements du week-end sont à surveiller. Nous automatisons la plupart des choses, y compris la récupération automatique après des pannes matérielles, mais parfois une intervention humaine est toujours nécessaire.
en conclusion
La partie la plus difficile et la plus stressante de la formation est les 2 mois avant le début de la formation. Nous avions beaucoup de pression pour commencer l'entraînement le plus tôt possible, et en raison du temps limité alloué par les ressources, nous n'avons eu accès à l'A100 qu'à la dernière minute. Ce fut donc une période très difficile, étant donné que BF16Optimizercela a été écrit à la dernière minute, nous devions le déboguer et corriger divers bogues. Comme mentionné dans la section précédente, nous avons trouvé de nouveaux problèmes qui ne sont apparus qu'après avoir commencé la formation sur 48 nœuds, et non à petite échelle.
Mais une fois que nous avons réglé cela, la formation elle-même s'est déroulée étonnamment bien sans accroc majeur. La plupart du temps, il n'y a qu'un seul d'entre nous qui regarde et seulement quelques personnes impliquées dans le dépannage. Nous avons eu un grand soutien de la part de la direction de Jean Zay qui a rapidement répondu à la plupart des besoins qui se sont manifestés lors de la formation.
Dans l'ensemble, ce fut une expérience super intense mais enrichissante.
La formation de grands modèles de langage reste une tâche difficile, mais nous espérons qu'en construisant et en partageant cette technique publiquement, d'autres pourront apprendre de notre expérience.
Ressource
liens importants
Documents et articles
Il nous est impossible de tout expliquer en détail dans cet article, alors si les techniques présentées ici piquent votre curiosité et vous donnent envie d'en savoir plus, merci de lire les articles suivants :
Mégatron-LM :
- Formation efficace de modèles de langage à grande échelle sur des clusters GPU .
- Réduction du recalcul d'activation dans les modèles de grands transformateurs
DeepSpeed :
- ZeRO : Optimisations de la mémoire pour former des modèles de paramètres à un billion de milliards
- ZeRO-Offload : Démocratiser la formation sur des modèles à l'échelle d'un milliard
- ZeRO-Infinity : briser le mur de la mémoire GPU pour un apprentissage en profondeur à grande échelle
- DeepSpeed : formation de modèles à grande échelle pour tous
Megatron-LM et Deepspeedeed combinés :
Alibi:
- Train court, test long : l'attention avec les biais linéaires permet l'extrapolation de la longueur d'entrée
- Quel modèle de langage entraîner si vous avez un million d'heures GPU ? - Vous y trouverez les expériences qui nous ont finalement conduits à choisir ALiBi.
BitsNBytes :
- Optimiseurs 8 bits via la quantification par bloc (nous avons utilisé l'intégration LaynerNorm dans cet article, mais d'autres parties de l'article et ses techniques sont également très bonnes, la seule raison pour laquelle nous n'avons pas utilisé d'optimiseurs 8 bits est que nous avons déjà utilisé DeepSpeed-ZeRO pour économiser la mémoire de l'optimiseur).
Article de blog merci
Un grand merci aux personnes suivantes qui ont posé de bonnes questions et contribué à améliorer la lisibilité de l'article (par ordre alphabétique) :
- Britney Müller,
- Douwe Kiela,
- Jared Caspar,
- Jeff Rasley,
- Julien Launay,
- Leandro von Werra,
- Omar Sanseviero,
- Stéphane Schweter et
- Thomas Wang.
Les graphiques de cet article ont été principalement créés par Chunte Lee.
Texte original en anglais : https://hf.co/blog/bloom-megatron-deepspeed
Auteur original : Stas Bekman
Traductrice : Matrix Yao (Yao Weifeng), ingénieur en apprentissage profond d'Intel, travaille sur l'application de modèles de famille de transformateurs sur diverses données modales et sur l'entraînement et le raisonnement de modèles à grande échelle.
Relecture et mise en page : zhongdongy (Adong)