01 Problèmes de coûts liés à l'utilisation généralisée d'Elasticsearch
Elasticsearch (ci-après dénommé "ES") est un moteur de recherche distribué qui peut également être utilisé comme une base de données distribuée. Il est souvent utilisé dans des scénarios tels que le traitement, l'analyse et la recherche de journaux ; au niveau du dépannage d'exploitation et de maintenance, la solution ELK (Elasticsearch+ Logstash+ Kibana), qui est facile à utiliser, rapide en réponse et fournit des rapports riches ; en termes de haute disponibilité, ES fournit une expansion distribuée et horizontale ; la couche de données prend en charge la fragmentation et les copies multiples.
ES est facile à utiliser et possède une écologie complète, et a été largement utilisé dans les entreprises. Ceci est suivi d'une augmentation des ressources physiques et des coûts.Comment réduire le coût des scénarios ES est devenu un sujet de préoccupation générale.
Comment réduire le coût des SE
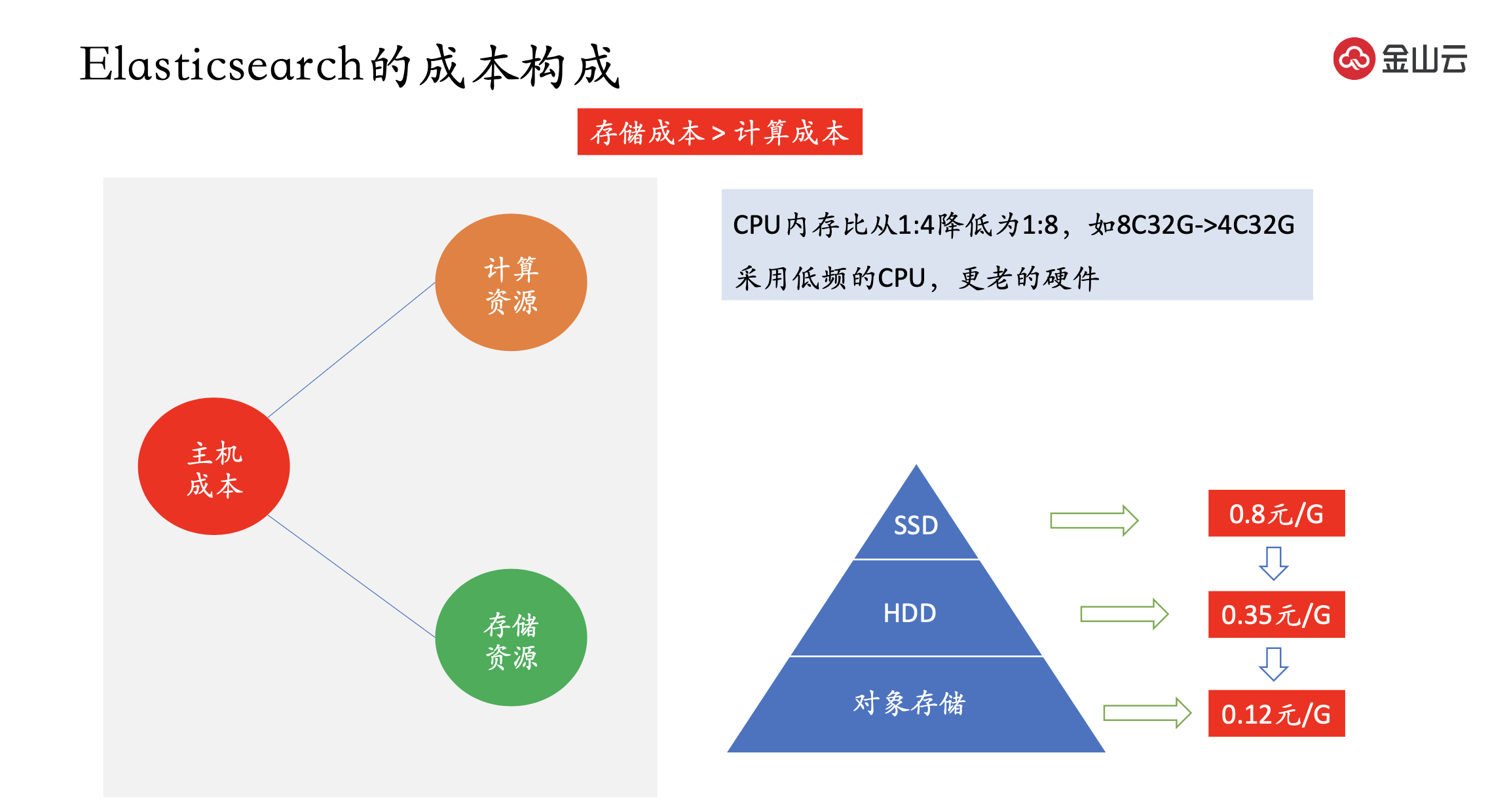
Le coût principal de l'ES est le coût de l'hôte, qui est ensuite divisé en ressources informatiques et en ressources de stockage.
La compréhension simple des ressources informatiques est le processeur et la mémoire. Si le nombre de processeurs et d'hôtes est réduit, la puissance de calcul diminuera, de sorte que les nœuds chauds et froids sont généralement utilisés ; les nœuds chauds utilisent des machines haut de gamme et les nœuds froids utilisent des machines bas de gamme. machines finales ; telles que la mémoire CPU Le rapport est réduit de 1:4 à 1:8, comme 8C32G->4C32G. Mais la mémoire n'est pas réduite, car ES a une demande plus élevée de mémoire pour améliorer la vitesse de réponse. Ou utilisez un processeur basse fréquence et du matériel plus ancien.
Le coût de stockage est largement supérieur au coût de calcul, et c'est un coût à prendre en compte . Les supports de stockage actuels sont généralement SSD et HDD. Le coût du SSD chez les fournisseurs de cloud est de 0,8 yuan/G, le coût du disque dur est de 0,35 yuan/G et le prix du stockage d'objets est de 0,12 yuan/G. Cependant, les deux premiers périphériques sont des périphériques de bloc et fournissent le protocole du système de fichiers, mais le stockage d'objets prend en charge le protocole S3, qui sont incompatibles entre eux.
Comment combiner le stockage d'objets et ES, nous avons étudié deux solutions.
La première solution consiste à modifier le moteur de stockage ES pour s'adapter aux appels de stockage objet. Cette méthode nécessite de modifier le code source d'ES, et l'équipe doit investir beaucoup de main-d'œuvre dans le développement, la conception, la recherche et la vérification finale, et le rapport entrée-sortie est très faible.
La deuxième solution consiste à utiliser le stockage d'objets comme un disque et à le monter sur le système d'exploitation. Divisez ES en nœuds chauds et chauds. Les nœuds chauds stockent des données chaudes et montent des périphériques de bloc. les nœuds chauds utilisent le stockage d'objets.
02 Sélection du système de fichiers de stockage d'objets
Il y a trois considérations principales lors de la sélection d'un système de fichiers. Le premier est la fonction, les exigences fonctionnelles les plus élémentaires doivent être satisfaites en premier, le second est la performance et le troisième est la fiabilité . Nous avons enquêté sur s3fs, goofys et JuiceFS.
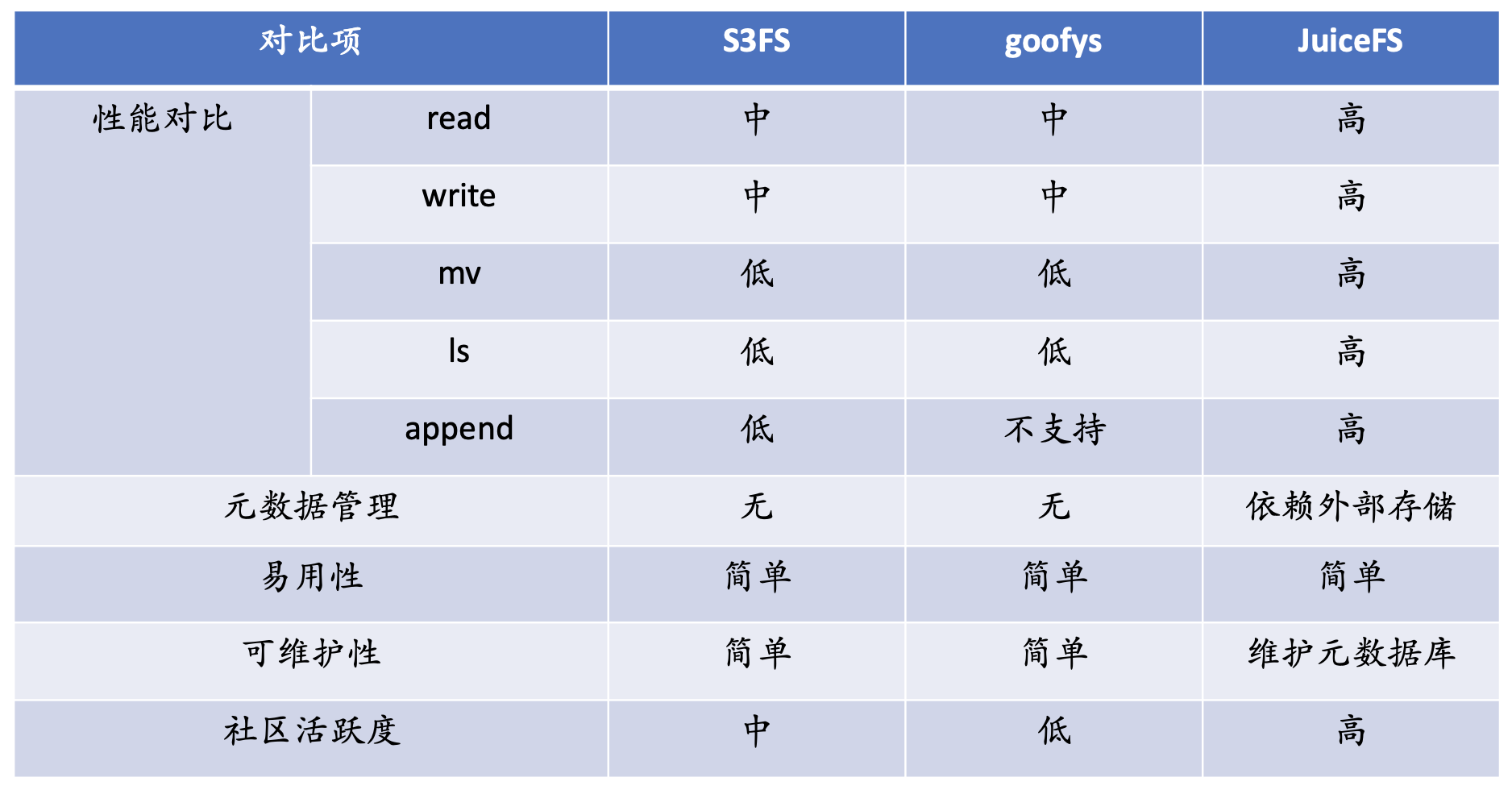
En termes de performances, s3fs et goofys n'ont pas de cache local en termes de lecture et d'écriture, et leurs performances sont soutenues par les performances de s3. Les performances globales de ces deux systèmes de fichiers seront inférieures à celles de JuiceFS.
Le plus évident est mv. Il n'y a pas d'opération de renommage dans le stockage d'objets. L'opération de renommage dans le stockage d'objets est une copie plus une suppression, et le coût des performances est très élevé.
En termes de ls, le type de stockage du stockage d'objets est le stockage kv, qui n'a pas de sémantique de répertoire. Par conséquent, pour s3, toute la structure de répertoire de ls est en fait une traversée de l'ensemble des métadonnées et le coût des appels est très élevé. Dans le scénario Big Data, les performances sont très faibles et certaines caractéristiques et fonctions ne sont pas prises en charge.
En termes de métadonnées, s3fs et goofys n'ont pas leurs propres métadonnées indépendantes. Toutes les métadonnées dépendent de s3. JuiceFS a son propre stockage de métadonnées indépendant.
En termes de facilité d'utilisation, ces produits sont très faciles à utiliser et s3 peut être monté avec une simple commande ; en termes de maintenabilité, JuiceFS a son propre moteur de métadonnées indépendant, nous devons mettre à jour les métadonnées Les services de données sont exploités et maintenus ; du point de vue de la communauté, JuiceFS a l'activité communautaire la plus élevée. Sur la base des considérations détaillées ci-dessus, Kingsoft Cloud a choisi JuiceFS.
Tests basés sur JuiceFS
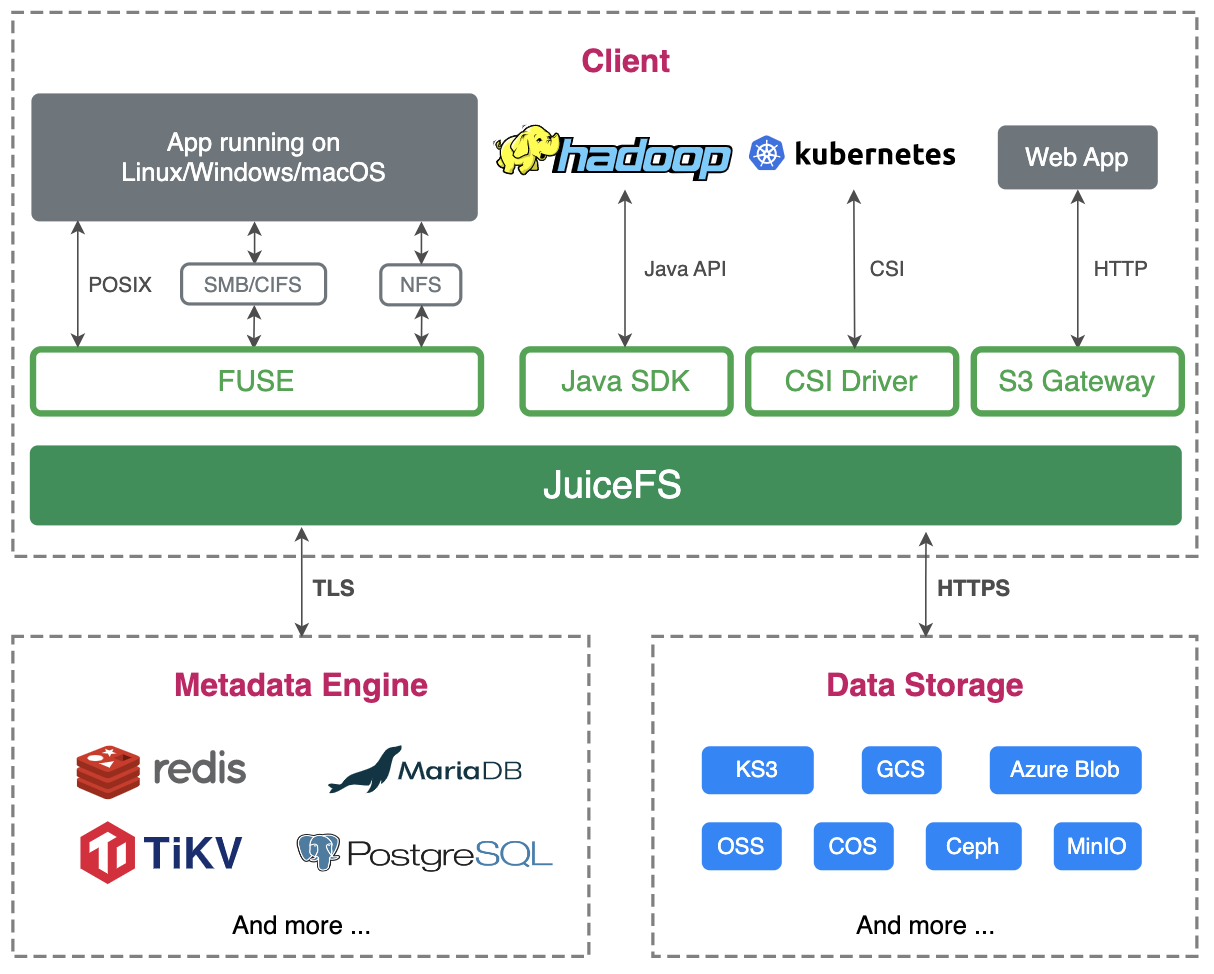
La première phrase de l'introduction du produit JuiceFS est "utiliser le stockage d'objets comme un disque local", ce qui est exactement la fonction dont nous avons besoin lorsque nous faisons ES. JuiceFS a intégré de nombreux types de stockage d'objets, et le KS3 de Kingsoft Cloud est également entièrement compatible et n'a besoin que de sélectionner une autre métabase.
Vérification de la deuxième fonction. Les bases de données de métadonnées couramment utilisées incluent Redis, les bases de données relationnelles, les bases de données KV, etc. Nous portons des jugements à partir de ces trois niveaux, la quantité de données prises en charge par la métabase, la vitesse de réponse et l'opérabilité.

En termes de volume de données, TiKV est sans aucun doute le plus élevé, mais notre intention de conception initiale est de faire de chaque cluster ES une instance de base de données de métadonnées indépendante, de sorte que les métadonnées entre les différents clusters ne soient pas partagées et qu'elles doivent être partagées entre elles pour une durée élevée. disponibilité isolement.
Deuxièmement, en termes de vitesse de réponse, ES utilise JuiceFS comme stockage de nœud froid, et les E/S de données stockées dans les nœuds froids consomment plus de performances que les performances d'appel de métadonnées, nous pensons donc que les performances d'appel de métadonnées ne sont pas une considération essentielle.
Du point de vue de l'exploitation et de la maintenance, tout le monde connaît les bases de données relationnelles et les développeurs peuvent facilement démarrer.Deuxièmement, certaines entreprises ont des produits RDS pour MySQL, et une équipe professionnelle DBA est responsable de l'exploitation et de la maintenance, donc le choix final est MySQL est utilisé comme moteur de métadonnées.
Test de fiabilité JuiceFS
Après la sélection des métadonnées, nous avons effectué un test de fiabilité sur JuiceFS. Trois étapes suffisent pour monter JuiceFS sur l'hôte :
La première étape consiste à créer un système de fichiers, nous devons spécifier le compartiment pour déterminer son AK, SK et sa base de données de métadonnées ;
La deuxième étape consiste à monter le système de fichiers sur le disque ;
La troisième étape consiste à établir un lien logiciel entre ES et le répertoire de montage de JuiceFS.
Bien que l'intention de conception originale soit d'utiliser JuiceFS comme nœud froid, mais dans le processus de test, nous voulons utiliser un moyen extrême de tester JuiceFS sous pression. Nous avons conçu deux tests d'extrême pression.
Le premier : montez JuiceFS + KS3 sur la section chaude et écrivez des données sur JuiceFS en temps réel.
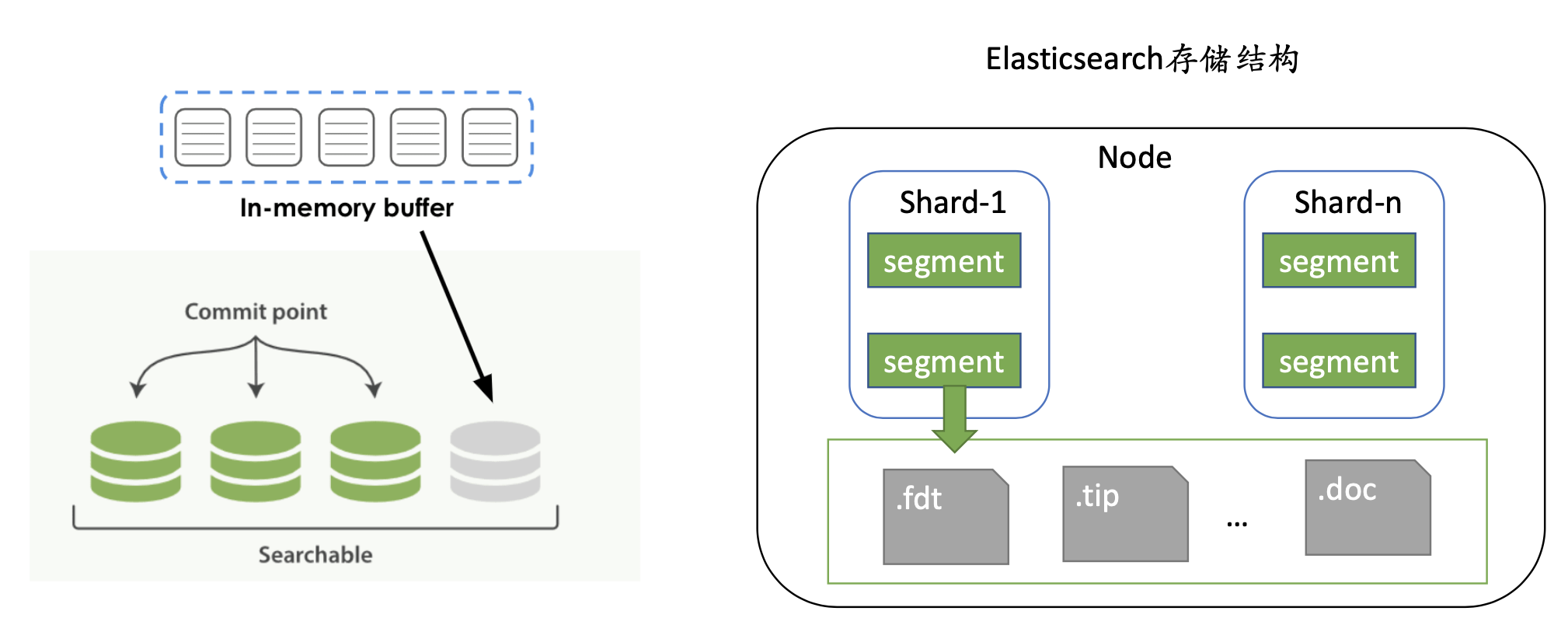
Le processus d'écriture ES consiste d'abord à écrire dans le tampon, c'est-à-dire la mémoire. Lorsque la mémoire est pleine ou atteint le seuil de temps défini par l'index, elle sera vidée sur le disque et le segment ES sera généré à ce moment. temps. Il est composé d'un ensemble de fichiers de données et de métadonnées, et chaque actualisation générera une série de segments, qui généreront des appels IO fréquents.
Nous utilisons ce test de pression pour tester la fiabilité globale de JuiceFS, et ES lui-même aura des fusions de segments. Ces scénarios ne sont pas disponibles sur les nœuds chauds, nous souhaitons donc utiliser une méthode extrême pour les tests de pression.
La deuxième stratégie consiste à migrer les données chaudes vers les données froides via la gestion du cycle de vie.
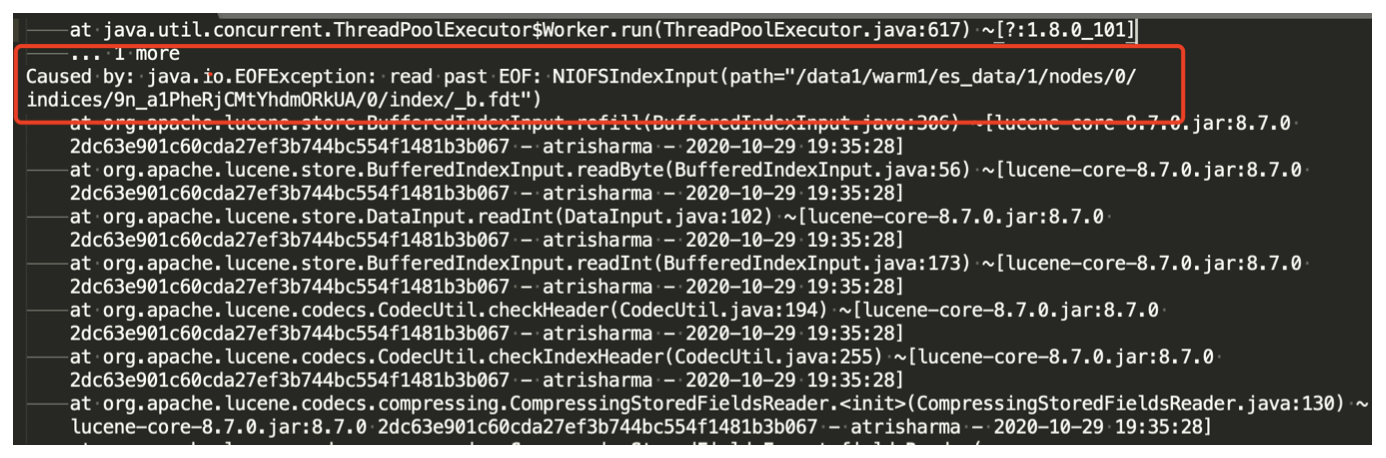
Pendant le test, JuiceFS1.0 n'est pas encore sorti. Pendant le test, des problèmes ont en effet été trouvés. Pendant le processus d'écriture en temps réel, une corruption des données peut se produire. Après avoir communiqué avec la communauté, cela peut être évité en modifiant la taille de le cache :
--attr-cache=0.1 Durée du cache d'attribut en secondes (par défaut : 1)
--entry-cache=0.1 temps de cache d'entrée de fichier en secondes (par défaut : 1)
--dir-entry-cache=0.1 Durée du cache des entrées de répertoire en secondes (par défaut : 1)
Le cache de ces trois paramètres par défaut à 1, en changeant la durée à 0,1, cela résout le problème de corruption d'index, mais cela apportera de nouveaux problèmes, car le cache de métadonnées et le temps de cache de données deviennent plus courts, ce qui conduira à Lors de l'exécution une commande système, telle que curl une commande système pour vérifier le nombre d'index ou l'état du cluster, dans des circonstances normales, l'appel peut être au deuxième niveau, et ce changement peut prendre des dizaines de secondes.
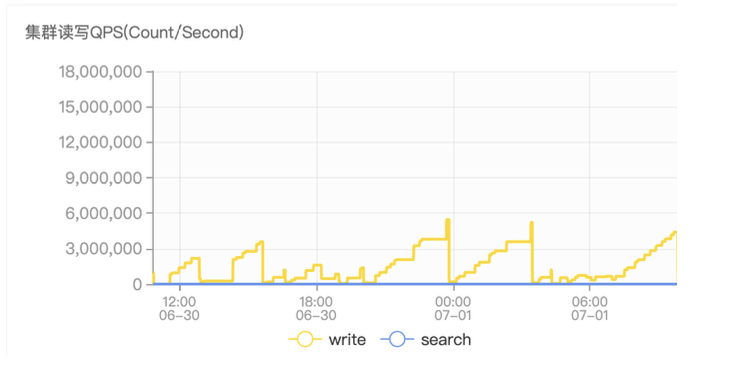
Le deuxième problème est que le QPS écrit a considérablement baissé. On peut voir que le Write QPS dans le graphe de monitoring est très instable, ce qui ne représente pas le vrai QPS d'ES, car le QPS dans le graphe de monitoring est obtenu en faisant une différence entre le nombre de documents obtenus deux fois, car l'ancienne version de JuiceFS a des problèmes de cache du noyau, obligeant ES à lire certaines anciennes données. Nous avons signalé ce problème à la communauté et il a été résolu après la sortie officielle de JuiceFS 1.0.
Nous avons effectué une nouvelle série de tests. La nouvelle série de tests a identifié 3 nœuds chauds, 8C16G 500G SSD, 2 nœuds chauds, 4C16G 200G SSD, le test a duré 1 semaine et la quantité de données écrites chaque jour était de 1 To (1 copie ). , passez au nœud chaud après 1 jour. Aucune corruption de données d'index ne s'est produite à nouveau. Grâce à ce test de pression, les problèmes rencontrés auparavant ne sont pas réapparus. Cela nous a donné confiance. Ensuite, nous allons progressivement migrer l'intégralité de l'ES vers cet aspect.
Différences entre le stockage de données JuiceFS et le stockage d'objets
JuiceFS a ses propres métadonnées, donc la structure de répertoire vue sur le stockage d'objets et JuiceFS est différente.
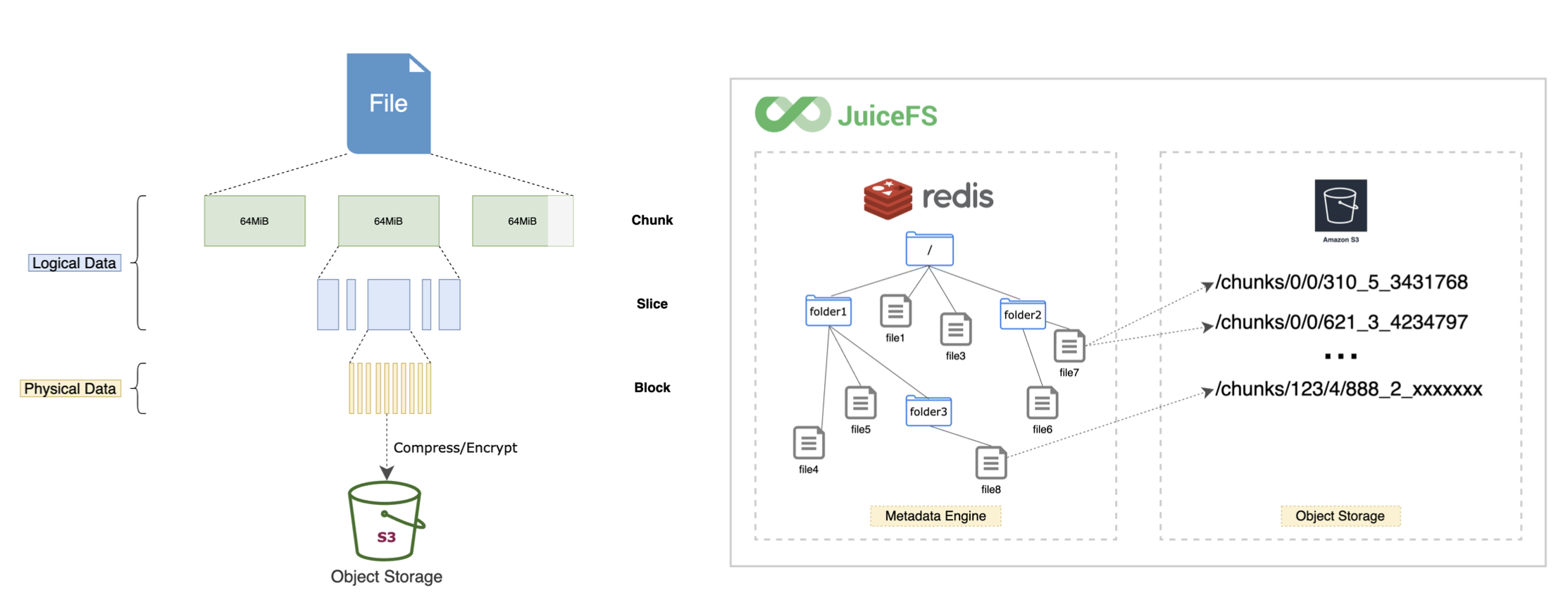
JuiceFS est divisé en trois couches, bloc, tranche et bloc.Par conséquent, ce que nous voyons sur le stockage d'objets est le bloc de données après que JuiceFS a divisé le fichier. Mais toutes les données sont gérées via ES, les utilisateurs n'ont donc pas besoin de prêter attention à ce point, ils n'ont qu'à effectuer toutes les opérations du système de fichiers via ES. JuiceFS gère correctement les blocs de données dans le stockage d'objets.
Après cette série de tests, Kingsoft Cloud a appliqué JuiceFS au service de journalisation (Klog) pour fournir aux utilisateurs d'entreprise un service de données de journalisation unique, réalisant que les données sur le cloud peuvent être collectées directement sans quitter le cloud. pour l'analyse du stockage et l'alarme ; les données sous le cloud fournissent le client SDK, via l'outil de collecte pour réaliser l'intégralité du lien des données vers le cloud, et enfin les données peuvent être livrées à KS3 et KMR pour réaliser le calcul du traitement des données.

03 Gestion des données chaudes et froides Elasticsearch
ES a plusieurs concepts couramment utilisés : rôle de nœud, gestion du cycle de vie de l'index et flux de données.
Rôle de nœud, rôle de nœud. Chaque nœud ES se voit attribuer différents rôles, tels que maître, données et ingestion. Concentrons-nous sur le nœud de données. L'ancienne version est divisée en trois types, à savoir les nœuds chauds, chauds et froids. Dans la dernière version, les nœuds gelés et gelés sont ajoutés.
La gestion du cycle de vie des index (ILM) est divisée en 4 phases :
- hot : l'index est mis à jour et interrogé fréquemment.
- warm : l'index n'est plus mis à jour, mais le volume de requêtes est moyen.
- cold : L'index n'est plus mis à jour et est rarement interrogé. Les informations doivent toujours être consultables, mais peu importe si les requêtes sont lentes.
- delete : l'index n'est plus nécessaire et peut être supprimé en toute sécurité.
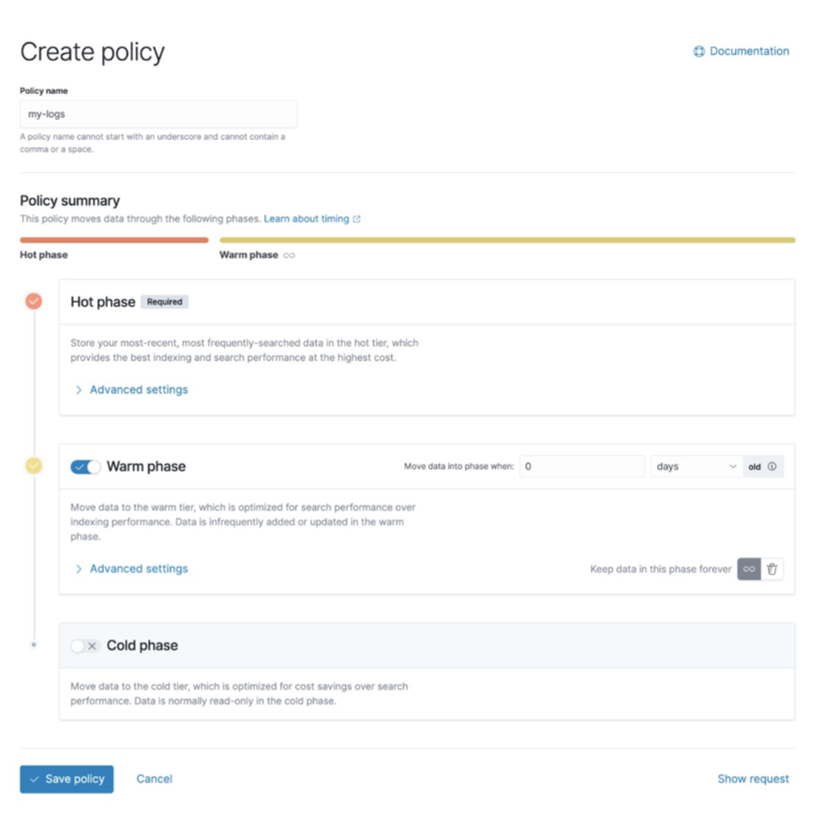
ES fournit officiellement un outil de gestion du cycle de vie. Nous pouvons diviser un grand index en plusieurs petits index en fonction de la taille de l'index, du nombre de documents et de la politique de temps. Un index volumineux est interrogé par la gestion et la maintenance, et sa surcharge est très coûteuse. La fonction de gestion du cycle de vie nous permet de gérer les index de manière plus flexible.
Data Stream est une nouvelle fonctionnalité introduite dans la version 7.9. Elle est basée sur la gestion du cycle de vie des index pour implémenter une écriture de flux de données, qui peut facilement traiter des données de séries chronologiques.
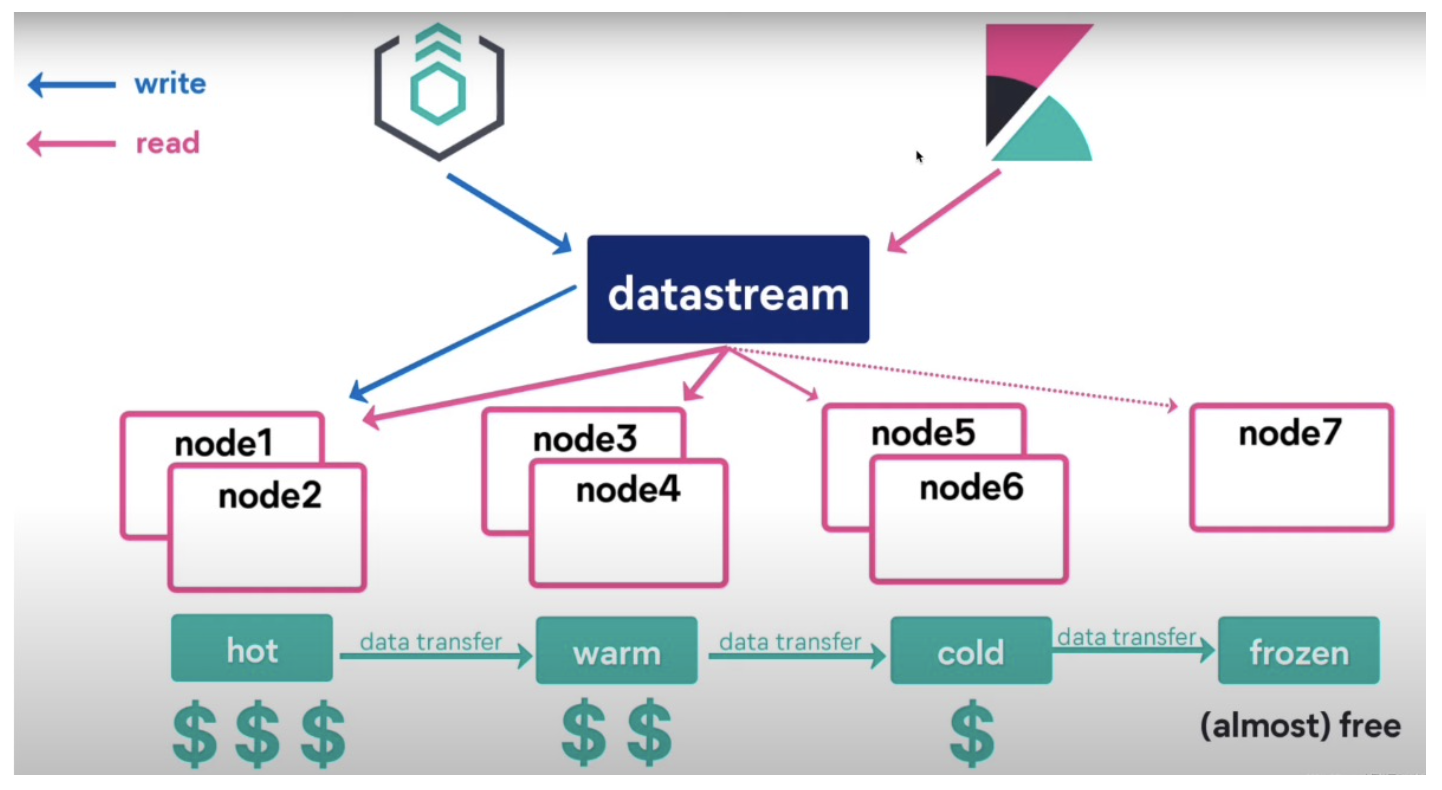
Lors de l'interrogation de plusieurs index, ces index sont généralement combinés pour interroger. Nous pouvons utiliser Data Stream, qui est comme un alias et peut être acheminé vers différents index par lui-même. Data Stream est plus convivial pour la gestion du stockage et l'interrogation des données de séries chronologiques, ce qui se rapproche de la gestion à chaud et à froid d'ES, ce qui est pratique pour l'ensemble de la gestion de l'exploitation et de la maintenance.
Bien planifier la taille des nœuds froids
Lorsque nous mettrons des données froides sur du stockage objet, cela impliquera la gestion de nœuds froids, qui se divisent principalement en trois aspects :
Premièrement : mémoire et CPU et espace de stockage. La taille de la mémoire détermine le nombre de fragments. Nous divisons généralement la mémoire physique en moitié-moitié sur le nœud chaud : la moitié est pour ES JVM, et l'autre moitié est pour Lucene. Lucene est le moteur de recherche d'ES, allouer suffisamment de mémoire pour qu'il puisse améliorer les performances de requête d'ES. Par conséquent, en conséquence, nous pouvons allouer de manière appropriée la mémoire JVM dans le nœud de données froides, puis réduire la mémoire Lucene, mais la mémoire JVM ne doit pas dépasser 31G.
Deuxièmement : le rapport CPU/mémoire est réduit de 1:4 à 1:8. L'utilisation de JuiceFS et du stockage d'objets sur l'espace de stockage peut être considérée comme un espace de stockage illimité, mais comme il est suspendu au nœud froid, bien qu'il y ait un espace illimité disponible, il est limité par la taille de la mémoire, ce qui détermine que l'espace de stockage illimité est juste idéal. S'il est encore étendu, il y aura un danger caché relativement important dans la stabilité du nœud froid de l'ensemble de l'ES.
Troisièmement : espace de stockage. En prenant la mémoire 32G comme exemple, l'espace de stockage raisonnable est de 6,4 To. L'espace peut être étendu en augmentant le nombre de fragments, mais sur les nœuds chauds, le nombre de fragments doit être strictement contrôlé, car la stabilité des nœuds chauds doit être prise en compte, et il est possible d'augmenter de manière appropriée ce ratio sur les nœuds froids.
Il y a deux facteurs importants à considérer ici, l'un est la stabilité et l'autre est le temps de récupération des données. Parce que lorsque le nœud raccroche, comme le processus JuiceFS raccroche, ou le nœud froid raccroche, ou il doit être remonté pendant le fonctionnement et la maintenance, alors toutes les données doivent être rechargées dans ES, ce qui générera beaucoup de fréquent Pour les demandes de lecture de données, si la quantité de données est plus importante, le temps de récupération de la fragmentation de l'ensemble de l'ES sera plus long.
Méthodes de gestion de la fragmentation d'index couramment utilisées
L’approche managériale considère principalement trois aspects :
- Un fragment trop volumineux : récupération lente après une panne de cluster ; il est facile de provoquer des points chauds d'écriture de données, ce qui entraîne une file d'attente en masse pleine et une augmentation du taux de rejet ;
- Le fragment est trop petit : davantage de fragments sont créés, davantage de métadonnées sont occupées et la stabilité du cluster est affectée ; le débit du cluster est réduit ;
- Trop de partitions : résultant en plus de segments, grave gaspillage de ressources d'E/S, réduction de la vitesse des requêtes ; utilisation de plus de mémoire, affectant la stabilité.
Lorsque les données sont écrites, la taille globale des données est incertaine. Généralement, un modèle est créé en premier, la taille d'une partition fixe est déterminée en premier, le nombre de partitions est déterminé, puis le mappage et l'index sont créés.
À ce stade, il peut y avoir deux problèmes. Le premier est qu'il y a trop de fragments, car je ne sais pas combien de données seront écrites au moment prévu. Il est possible que j'aie créé de nombreux fragments, mais pas plus les données arrivent. .
La seconde est que le nombre de fragments créés est trop petit, ce qui rendra l'index trop grand. A ce moment, il est nécessaire de fusionner les petits fragments. Il est nécessaire de faire tourner les données plus longtemps, puis fusionnez certains petits segments en segments plus grands pour éviter d'utiliser plus d'E/S et de mémoire. Dans le même temps, certains index vides doivent être supprimés. Bien que les index vides ne contiennent aucune donnée, ils occupent de la mémoire. Il est recommandé que la taille raisonnable des fragments soit contrôlée entre 20 et 50 g.
04 Effet d'utilisation de JuiceFS et précautions
Prenons l'exemple d'un cluster en ligne, échelle de données : 5 To écrits chaque jour, stockage de données pendant 30 jours, stockage de données à chaud pendant une semaine, nombre de nœuds : 5 nœuds chauds, 15 nœuds froids.
Après l'adoption de JuiceFS, les nœuds chauds sont restés inchangés et le nombre de nœuds froids est passé de 15 à 10. Dans le même temps, nous avons utilisé un disque dur mécanique de 1 To pour JuiceFS comme cache.
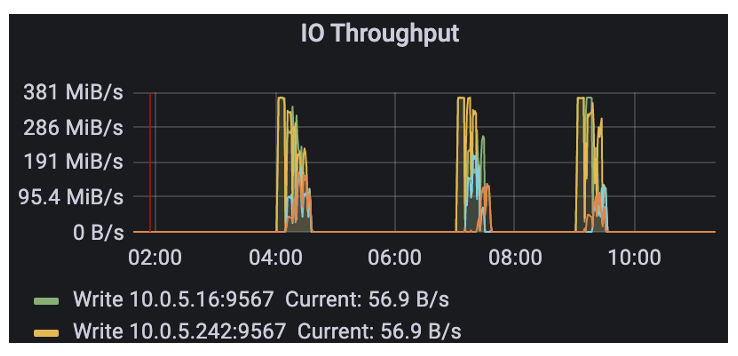
On peut voir qu'il y aura un grand nombre d'appels de stockage d'objets dans les premières heures du matin, car nous mettons l'ensemble des opérations de gestion du cycle de vie en heures creuses à exécuter.
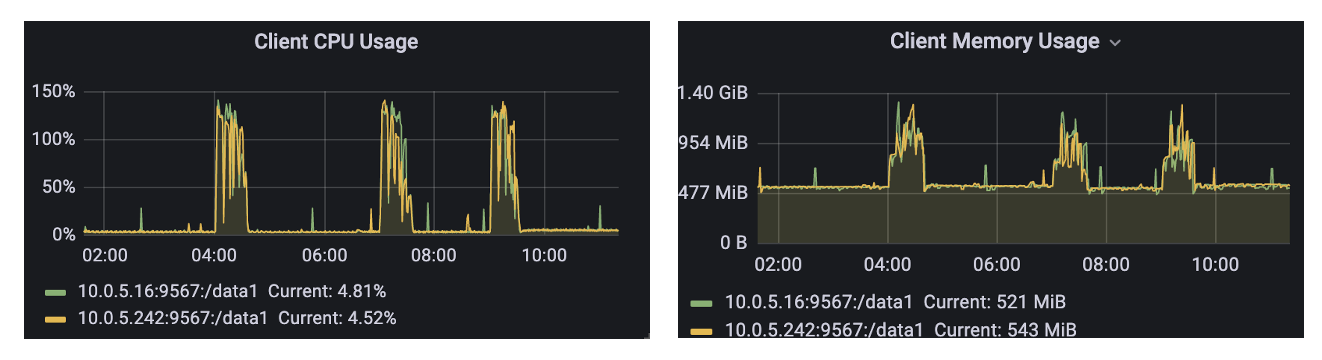
L'utilisation de la mémoire de JuiceFS est généralement de centaines de Mo, et elle sera inférieure à 1,5 G et son utilisation du processeur lorsqu'il est appelé pendant la période de pointe, et les performances sont normales.
Voici les précautions d'utilisation de JuiceFS : Premièrement : Ne partagez pas le système de fichiers. Parce que nous montons JuiceFS sur le nœud froid, ce que chaque machine voit est une quantité complète de données. Une manière plus conviviale consiste à utiliser plusieurs systèmes de fichiers, et chaque nœud ES utilise un système de fichiers, ce qui peut faire de l'isolation, mais avec une gestion correspondante. problèmes.
Nous avons finalement sélectionné un modèle dans lequel un ensemble d'ES correspond à un système de fichiers.Le problème posé par cette pratique est : chaque nœud verra la quantité totale de données, et il est facile de faire quelques erreurs de manipulation à ce moment-là. Si l'utilisateur veut faire quelques rm dessus, les données sur d'autres machines peuvent être supprimées, mais étant donné que nous ne partageons pas le système de fichiers entre différents clusters, et dans le même cluster, nous devons équilibrer la gestion et l'exploitation et la maintenance, donc un ensemble d'ES correspond à un mode de système de fichiers JuiceFS.
Deuxièmement : migrez manuellement les données vers des nœuds chauds. Dans la gestion du cycle de vie des index, ES disposera de certaines stratégies pour migrer les données des nœuds chauds vers les nœuds froids. Lorsque la stratégie est exécutée, cela peut être pendant la période de pointe de l'activité. À ce moment, les E/S seront générées sur le nœud chaud, puis les données seront copiées sur le nœud froid, puis les données sur le nœud chaud seront être supprimé. Le coût de l'ensemble du système de nœuds chauds est relativement élevé. Nous utilisons donc le manuel pour contrôler quels index sont migrés vers les nœuds froids et quand.
Troisièmement : migrez les index aux heures de pointe faibles.
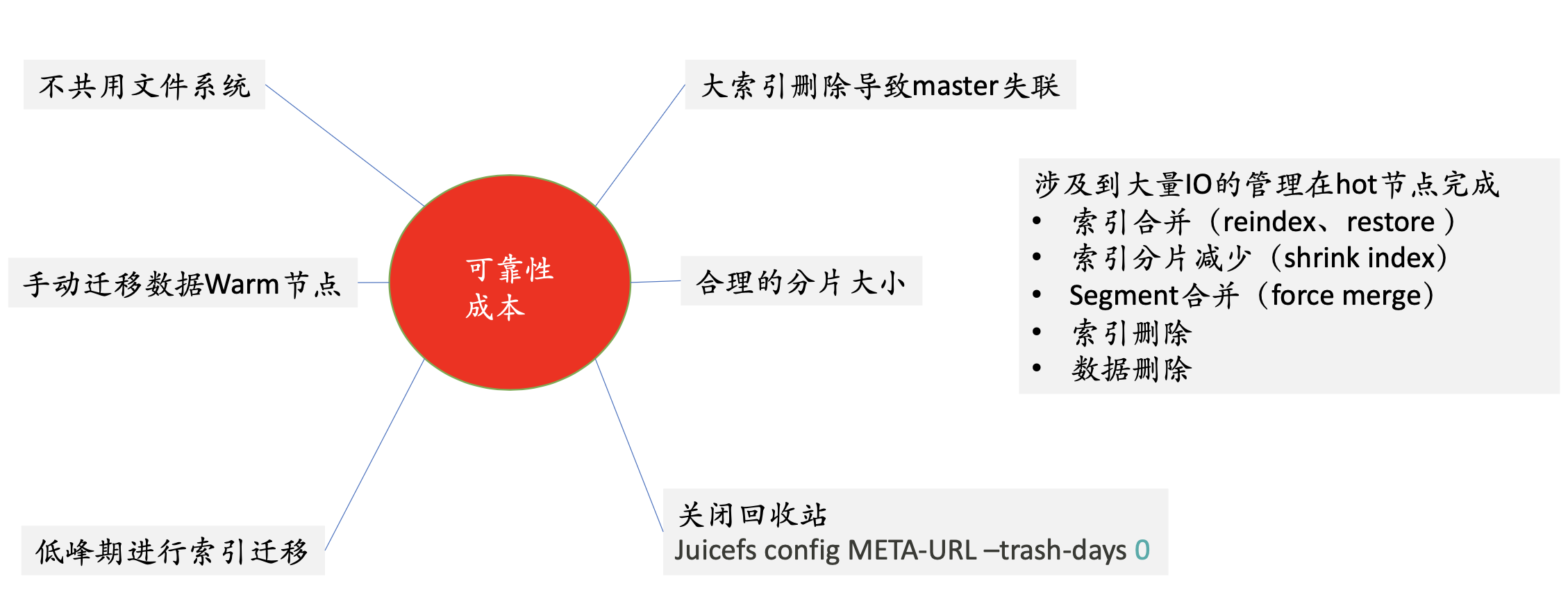
Quatrième : évitez les grands index. Lors de la suppression d'un index volumineux, ses performances CPU et E/S sont inférieures à celles du nœud chaud. À ce moment, le nœud froid perdra la connexion avec le maître. Une fois la connexion perdue, les données seront rechargées, puis les données Parce que l'ES tombe en panne et que le nœud tombe en panne, le coût est très élevé.
Cinquième : taille de fragmentation raisonnable.
** Sixièmement : fermez la corbeille. **Sur le stockage d'objets, JuiceFS enregistre les données d'une journée par défaut, mais cela n'est pas nécessaire dans le scénario ES.
Il existe également d'autres opérations impliquant beaucoup d'E/S, qui doivent être effectuées sur le nœud chaud. Par exemple, la fusion d'index, la récupération d'instantanés, la réduction de fragments, la suppression d'index et de données, etc. Si ces opérations se produisent sur des nœuds froids, le nœud maître perdra la connexion. Bien que le coût du stockage d'objets soit relativement faible, le coût des appels IO fréquents augmentera et le stockage d'objets sera facturé en fonction du nombre d'appels put et get. Par conséquent, ces grandes opérations doivent être placées sur des nœuds chauds, qui sont utilisé uniquement pour le stockage à froid du côté de l'entreprise. nœud pour effectuer certaines requêtes.
Si vous êtes utile, veuillez prêter attention à notre projet Juicedata/JuiceFS ! (0ᴗ0✿)