Les systèmes SIEM ont de nombreuses règles rédigées par des experts pour aider à détecter les comportements suspects. Cependant, il existe de nombreux scénarios d'attaque qui ne peuvent pas être décrits par des règles strictes et peuvent donc être tracés efficacement.
Compte tenu du volume de données que les systèmes SIEM traitent au quotidien, et des enjeux spécifiques d'analyse de ces données (dans le but de trouver le comportement des attaquants), l'application du machine learning est aujourd'hui nécessaire et très efficace.
détails de la mission
Dans ce cas précis, nous avons relevé le défi suivant : une fois que les attaquants ont accès à une infrastructure informatique, ils utilisent diverses tactiques et techniques pour prendre pied et avancer plus loin, toutes leurs activités laissent des traces d'une manière ou d'une autre, qui trouve alors son entrée dans le système SIEM.
L'utilisation de la plupart des tactiques sera consignée dans les événements du journal Windows liés au démarrage du processus (Sysmon EventID 1 et Windows Security Event ID 4688). Laissant de côté les informations inutiles, nos données initiales peuvent être exprimées dans le tableau suivant :
| Nom d'utilisateur |
Nom du processus |
| Ivan Ivan |
cmd.exe |
| Petrov Petr |
outlook.exe |
| Sidorov Nikolaï |
whoami.exe |
Nous pouvons voir une liste de tous les processus et utilisateurs s'exécutant dans l'infrastructure, sous le compte desquels ils s'exécutent. Il est important pour nous d'apprendre au système SIEM à reconnaître quels processus sont normaux pour un utilisateur particulier et lesquels sont atypiques - anormaux. Et, comme vous pouvez probablement le deviner, un processus anormal pour un utilisateur peut sembler parfaitement normal pour un autre.
Grâce à cette fonctionnalité (la capacité de détecter les processus anormaux des utilisateurs), nous serons en mesure de détecter de nombreuses tentatives d'attaque à un stade précoce. Par exemple, imaginez deux situations : un comptable exécute un utilitaire sur son poste de travail pour interroger les informations des services de domaine Active Directory, et une secrétaire qui ne travaillait qu'avec un logiciel de bureau exécute soudainement un logiciel de comptabilité. Ce n'est probablement rien, l'ordinateur du comptable n'est qu'un administrateur système assis pour diagnostiquer les problèmes de réseau, et la secrétaire a des tâches supplémentaires. Mais il pourrait aussi y avoir une autre explication - le compte avait été pris en charge par des intrus et recherché pour une promotion. Ou cette secrétaire est en fait un initié qui essaie de voler la base de données de l'entreprise.
De tels cas nécessitent certainement l'attention et l'élaboration d'un opérateur SIEM, en tenant compte du contexte de la situation et des événements tiers, indépendamment du déclencheur d'événement spécifique.
approche de base de la résolution de problèmes
Quels sont les moyens de résoudre ce problème ? La première chose qui vient à l'esprit est de contrôler tous les processus lancés par un utilisateur particulier et de vérifier ses autorisations pour cet utilisateur.
À première vue, un algorithme aussi simple semble résoudre le problème. Mais lorsque nous l'avons testé, nous avons obtenu la situation suivante.
Imaginez que nous ayons un programmeur dans notre organisation qui aime écrire du code dans son IDE préféré - Visual Studio Code. Un jour, un ami lui a suggéré d'essayer un autre outil - PyCharm, et il a suivi ses conseils. Du point de vue de notre algorithme, il y a une anomalie, un comportement atypique. Nos utilisateurs n'ont jamais travaillé dans ce programme. Mais du point de vue d'un opérateur SIEM, il n'y a rien à surveiller. C'est un faux positif - un faux positif. Et il y aura de nombreux cas de ce genre, ce qui réduira à néant l'utilité de notre algorithme.
Comment résoudre ce problème ? Une idée m'est immédiatement venue à l'esprit : n'opérons pas avec des applications concrètes, mais avec leur finalité fonctionnelle. Catégorisons toutes les applications et combinons-les en groupes. Par exemple, PyCharm et Visual Studio Code seront dans un groupe appelé "Outils de développement", et Microsoft Word et Microsoft Excel seront dans le groupe "Programmes Office".
La même chose peut être faite pour les certificats d'utilisateur. Notre système ne traite pas les utilisateurs comme des individus, mais plutôt comme un ensemble de rôles fonctionnels. Par exemple, l'un est développeur et administrateur système à temps partiel, et l'autre est comptable. Et le système apprendra qu'il est acceptable pour les développeurs d'utiliser des outils de développement et que les comptables peuvent utiliser un logiciel de comptabilité. Et qu'ils utilisent tous des logiciels bureautiques, c'est aussi possible.
Cette approche peut fonctionner, mais malheureusement uniquement dans les entreprises où le service informatique met constamment à jour la liste des employés et leurs responsabilités. De plus, les inventaires de logiciels doivent être suivis et mis à jour, ce qui est également un défi car de nombreuses agences utilisent des logiciels ad hoc ou développés en interne.
Une approche d'apprentissage automatique
Ainsi, lorsque les gens trouvent que les algorithmes rigoureux standard demandent trop d'efforts, il est temps d'utiliser la « magie » de l'apprentissage automatique. Nous devons appliquer un algorithme qui "comprend" vraiment les responsabilités fonctionnelles de chaque utilisateur et le but de chaque programme spécifique.
Cela s'annonce compliqué. Mais il s'avère que nos besoins peuvent être entièrement satisfaits par une classe d'algorithmes appelés systèmes de recommandation.
Un système de recommandation est une classe d'algorithmes d'apprentissage automatique conçus pour recommander des produits ou du contenu aux utilisateurs.
Comme vous pouvez le deviner, les systèmes de recommandation sont omniprésents dans nos vies. Utilisez un algorithme chaque fois que vous souhaitez retenir l'attention d'un utilisateur avec un nouveau contenu ou recommander un nouveau produit à acheter.
Il existe deux manières de créer un système de recommandation :
• basé sur le contenu ;
• filtrage collaboratif.
Les techniques basées sur le contenu nécessitent des informations supplémentaires pour fonctionner. Dans ce cas, il est nécessaire de décrire chaque produit ou utilisateur avec un ensemble d'attributs. Par exemple, dans le cas de la sélection d'un film pour l'utilisateur, il peut s'agir du genre, des acteurs des rôles principaux, de l'année de sortie, du pays de production. Comme nous l'avons vu, ce type de système de recommandation ne répond pas à nos exigences dans cette tâche particulière.
Les techniques de filtrage collaboratif, en revanche, n'utilisent que des informations sur le degré d'appréciation d'un utilisateur pour un certain produit. Nous n'avons pas besoin de collecter des données pour chaque attribut.
Examinons de plus près le fonctionnement du filtrage collaboratif. Imaginons qu'un produit premium ait été acheté par un petit pourcentage d'utilisateurs qui ont acheté d'autres produits premium. Il est logique de recommander le produit au reste de ces utilisateurs.
Il est clair que les personnes qui donnent des notes similaires aux mêmes produits ont des goûts et des préférences similaires. Et l'inverse est également vrai : si un certain groupe d'utilisateurs aime un contenu, il est bien caractérisé. Le filtrage collaboratif repose sur ces principes simples.
Notre tâche dans la formation du modèle est d'obtenir des vecteurs pour chaque utilisateur et produit qui, une fois multipliés les uns avec les autres, nous donneront la note du produit que l'utilisateur donnerait lors de l'achat.
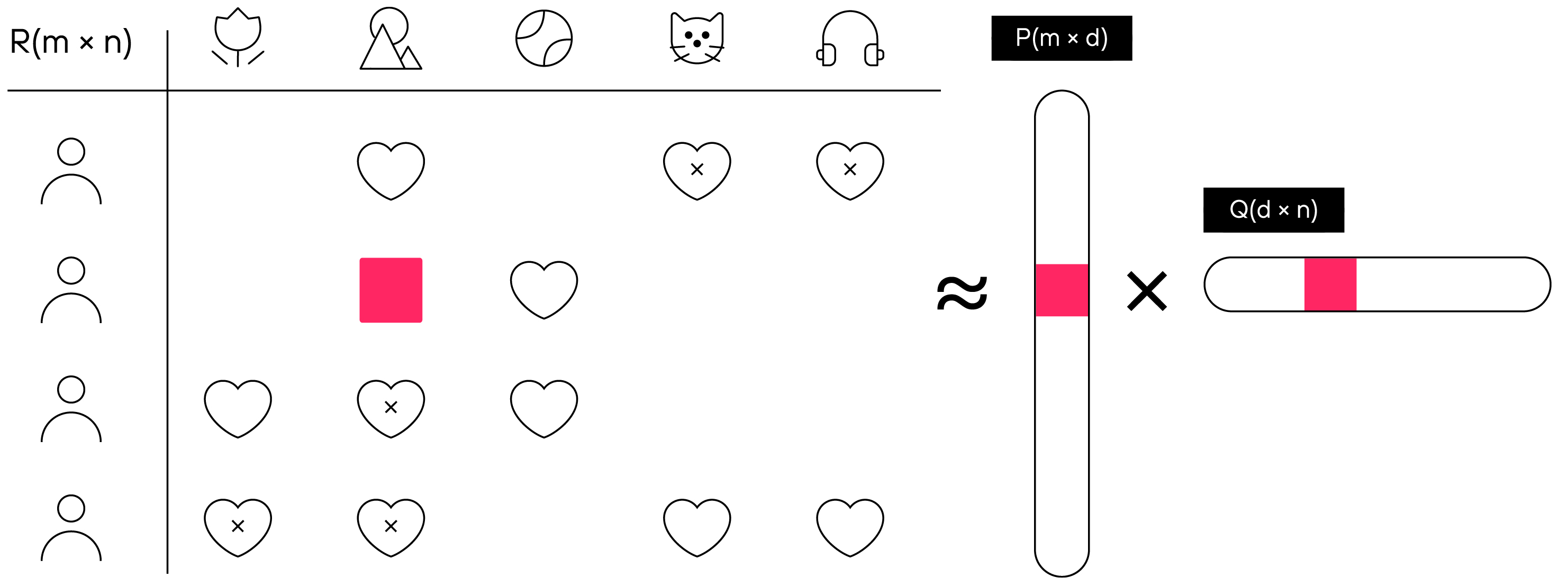
Le principe de la technologie de filtrage collaboratif, où P est une matrice vectorielle utilisateur de dimension m×d, et Q est une matrice vectorielle produit de dimension d×n.
La question principale est de savoir comment créer ces vecteurs si nous n'avons aucune information sur l'utilisateur ou le contenu ? Mais ce n'est qu'à première vue. Nous avons leur historique de notation et cela nous suffit.
Par exemple, nous pouvons le faire en utilisant l'algorithme des moindres carrés alternés (ALS). Sans entrer dans les maths, on peut expliquer son fonctionnement de la manière suivante : on fixe une matrice de vecteurs utilisateurs, on l'optimise et on fait varier la matrice de contenu. Nous prenons la dérivée (gradient) de la fonction de perte et nous nous déplaçons dans la direction opposée du gradient - dans la direction que nous voulons, là où se trouve la "vérité", et nos prédictions ne peuvent pas être fausses. Ensuite, nous fixons la matrice de contenu et faisons de même pour la matrice utilisateur. Nous répétons plusieurs fois, en nous rapprochant de la valeur souhaitée, en "entraînant" notre modèle.
De cette façon, nous obtiendrons le vecteur dont nous avons besoin. Bien sûr, si on prend un vecteur concret, on ne pourra rien comprendre d'un point de vue humain. Pour nous, ce ne sera qu'un ensemble de chiffres. Mais chaque nombre dans ce vecteur et les positions relatives entre ces nombres seront significatifs et refléteront la situation réelle.
Une question raisonnable se pose : comment pouvons-nous utiliser les systèmes de recommandation pour repérer les anomalies ?
Il est logique que si un utilisateur exécute un processus, il aime le processus. Si nous parlons du point de vue du système de recommandation, ce processus aura un score élevé.
Et l'inverse est le cas : si le processus est anormal, si cet utilisateur particulier et d'autres utilisateurs similaires n'ont jamais exécuté tel ou tel processus, le système de recommandation donnera un score faible - il dira, notre utilisateur N'a pas aimé le processus . Alors il/elle commence quelque chose qu'il/elle aime même s'il/elle ne devrait pas (selon le système de recommandation) - c'est une valeur aberrante.
Cette approche s'est avérée efficace lors des tests. Il s'avère que les vecteurs utilisateur décrivent bien les responsabilités fonctionnelles d'un utilisateur, tandis que les vecteurs d'application décrivent bien l'ensemble des fonctionnalités d'une application. Les vecteurs utilisateurs reflètent bien la réalité, comme on peut le voir dans les exemples suivants.
Réfléchissons tous les vecteurs utilisateur dans un espace à deux dimensions. Nous obtenons une image comme celle-ci.

Affichage 2D des comptes utilisateurs
Un point est un utilisateur spécifique, et la couleur du point est sa responsabilité fonctionnelle, qui est extraite du tableau des effectifs. Nous pouvons voir que les utilisateurs d'un même service sont regroupés côte à côte, ce qui signifie que notre modèle est bien formé et que son état interne reflète la réalité. Bien sûr, il y aura des exceptions dans ce cas, mais elles sont liées au comportement spécifique d'une personne en particulier.
Une autre caractéristique de perspective importante à noter est le mouvement des points (utilisateurs) sur ce graphique. Si un utilisateur est engagé dans approximativement la même activité, il sera dans la même position dans l'espace. En revanche, si une activité atypique démarre sous son compte, on assistera à un net « saut » de points. Faire un outil pratique pour détecter et analyser ces "sauts" serait utile pour protéger les opérateurs.
Voyons maintenant à quoi pourrait ressembler une utilisation traditionnelle du modèle dans la pratique.

Une série temporelle de prédictions de modèle pour un utilisateur
Ce graphique trace les lectures du modèle pour un utilisateur particulier. Plus le nombre sur l'axe des ordonnées est bas, moins le comportement de l'utilisateur est "normal". Avant le 7 juillet, il n'y avait rien d'inhabituel dans le comportement de cet utilisateur - aucune des valeurs aberrantes n'est descendue en dessous de 0,9. Cependant, le 11 juillet, un intrus s'est emparé du compte - et le modèle a commencé à générer des valeurs faibles.
en conclusion
Dans cette expérience, les services publics ont été utilisés pour effectuer une reconnaissance de l'infrastructure. Ce n'est certainement pas un comportement typique pour un utilisateur. Nous avons appliqué un système de parrainage simple et basique. Pour développer davantage cette idée, nous pouvons nous diriger vers des systèmes de recommandation communs utilisant un filtrage basé sur le contenu et collaboratif, et nous pouvons également mettre en œuvre des systèmes d'apprentissage en profondeur. La principale conclusion tirée de nos expériences est que l'utilisation de systèmes de recommandation pour trouver des anomalies a un grand potentiel pour aider à résoudre un large éventail de problèmes de cybersécurité.