ingénierie des fonctionnalités
Convertissez les caractéristiques en données facilement reconnaissables par les machines et convertissez la caractéristique a en un langage facilement lisible et quantifiable par les machines
Min-Max normalisé
Mappez les données d'origine sur
X ′ = x − minmax − min X'= \frac{x-min}{max-min} entre [0,1]X′=ma x−minX−min
Mais la normalisation a des inconvénients. Par exemple, s'il y a une erreur de valeur, cela affectera la valeur globale, et la normalisation ne peut pas résoudre cette valeur aberrante. Par conséquent, la normalisation ne convient qu'aux scénarios traditionnels de petites données précises.
standardisation
Transformez les données en une moyenne de 0 et un écart type de 1 en transformant les données d'origine. Autrement dit, les données obéissent à la distribution normale.
X ′ = x − moyenne σ X'=\frac{x-moy}{\sigma}X′=pX−moi et _
Algorithme K-Nearest Neighbor (K-Nearest Neighboor)
définition
Si la plupart des k échantillons les plus similaires dans l'espace des caractéristiques (c'est-à-dire les voisins les plus proches dans l'espace des caractéristiques) d'un échantillon appartiennent à une certaine catégorie, l'échantillon appartient également à cette catégorie.
idée
L'essence de prendre les voisins les plus proches est que ceux qui sont proches du vermillon sont rouges et ceux qui sont proches de l'encre sont noirs.Par exemple, vous pouvez prédire qui livrera de la nourriture dans la région à travers les résidents autour de vous. Il faut donc utiliser la distance euclidienne pour calculer la distance au voisin et trouver le voisin le plus proche (k=1).
Problème : S'il n'y en a qu'un, les données ne sont pas assez précises, l'interférence par le bruit est trop forte, et s'il y a une erreur dans les données, elles seront complètement biaisées.
Solution : Pour trouver k voisins, écrivez votre propre code pour implémenter knn. L'algorithme knn peut également être utilisé pour l'anti-escalade de polices chargées dynamiquement.
Comprendre les K-plus proches voisins
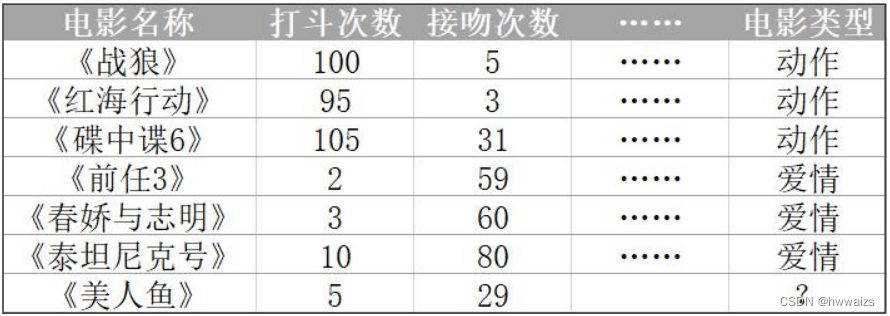
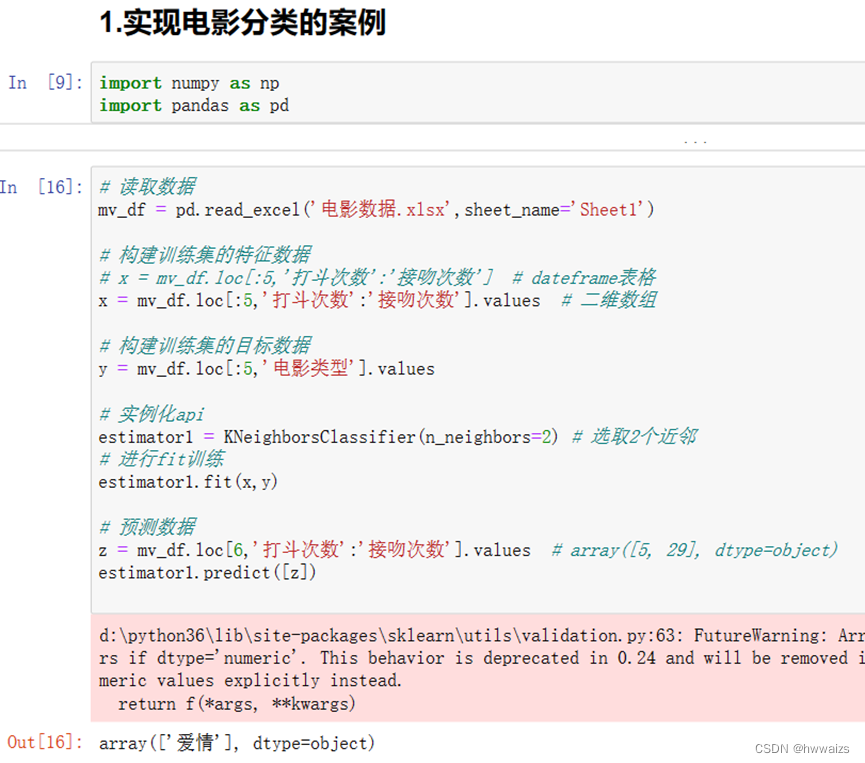
On sait que "Wolf Warrior", "Operation Red Sea" et "Mission: Impossible 6" sont des films d'action, tandis que "Predecessor 3", "Chun Jiao and Zhi Ming" et "Titanic" sont des films d'amour. Chaque ligne (un film) est un échantillon de données, et les caractéristiques sont répertoriées comme le nombre de combats et le nombre de baisers. Selon le nombre de combats et le nombre de baisers, les films d'amour et les films d'action sont distingués. S'il y a un nouveau film tel que "La Sirène", les gens peuvent classer le film en fonction de leur propre expérience, et la machine peut également maîtriser une règle de classification pour classer automatiquement le nouveau film.
Organisez les données dans la figure et tracez un nuage de points comme suit :
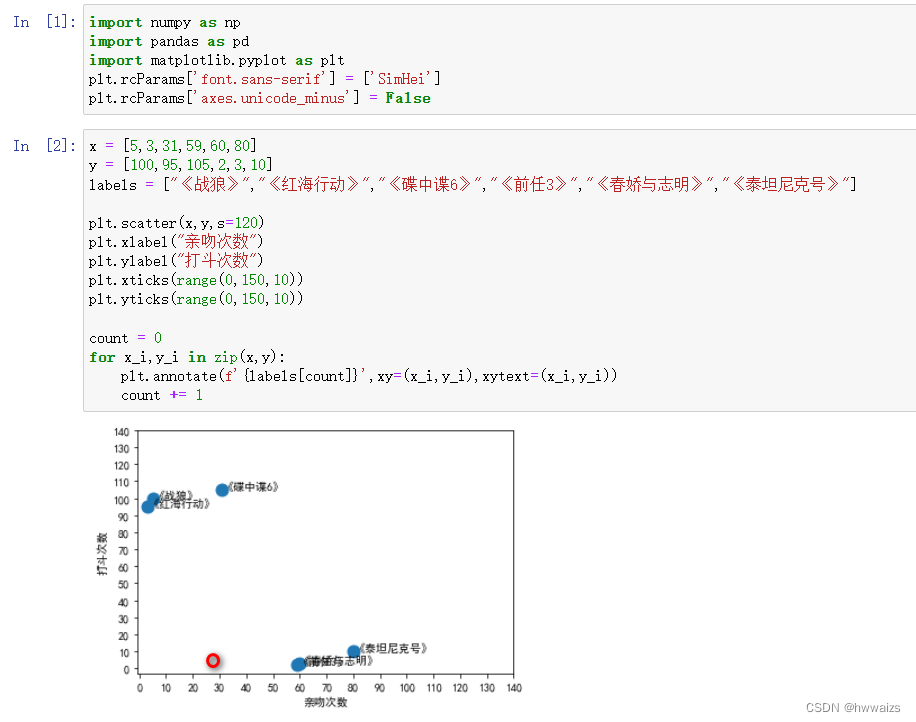
D'après les résultats de l'analyse, on peut voir qu'il existe de nombreuses scènes de combat dans les films d'action.Selon les données du film "Mermaid", la position du cercle rouge dans l'image peut être grossièrement jugée. Maintenant, il est nécessaire de déterminer de quel point d'échantillonnage le cercle rouge est le plus proche. S'il est plus proche de "Chunjiao et Zhiming", il peut être classé comme un film d'amour, et s'il est plus proche de "Operation Red Sea", il peut être classé comme un film d'action.
La droite entre deux points est la plus proche.
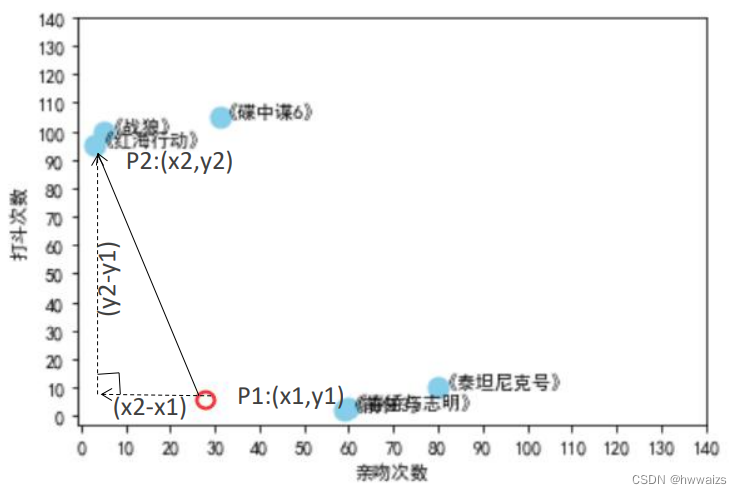
Lorsqu'il s'agit de la distance entre deux points en apprentissage automatique, il s'agit généralement de la distance euclidienne. La formule de distance euclidienne à deux dimensions est la suivante : d 12 = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 d_{12} = \sqrt{(x_1-x_2)^2+(y_1-y_2)^2
}d12=( x1−X2)2+( y1−y2)2
Il est impossible de dire qu'il n'y en a que deux. Chaque élément représente une dimension. La même raison est que la formule de distance tridimensionnelle est la suivante : D 12 = (x 1 − x 2) 2 + (y 1 − y 2) 2 + (z 1 − z 2) 2 d_ {12} = \ sqrt {(x_1-x_2)^2 + (y_1-y2) ^2+(z_1-z_2)^2
}d12=( x1−X2)2+( y1−y2)2+( z1−z2)2
S'il est à quatre dimensions ou plus, la formule de distance euclidienne à N dimensions se résume comme suit :
d 12 = ∑ k = 1 n ( xi − yi ) 2 d_{12} = \sqrt{\sum_{k=1}^n(x_i-y_i)^2}d12=k = 1∑n( xje−yje)2
Calculez précisément la distance, prenez deux points (Mermaid, Mission : Impossible 6) comme exemple à résoudre,
# 美人鱼:5 29
# 碟中谍6: 105 31
np.sqrt((105-5)**2+(31-29)**2) # 100.0199980003999
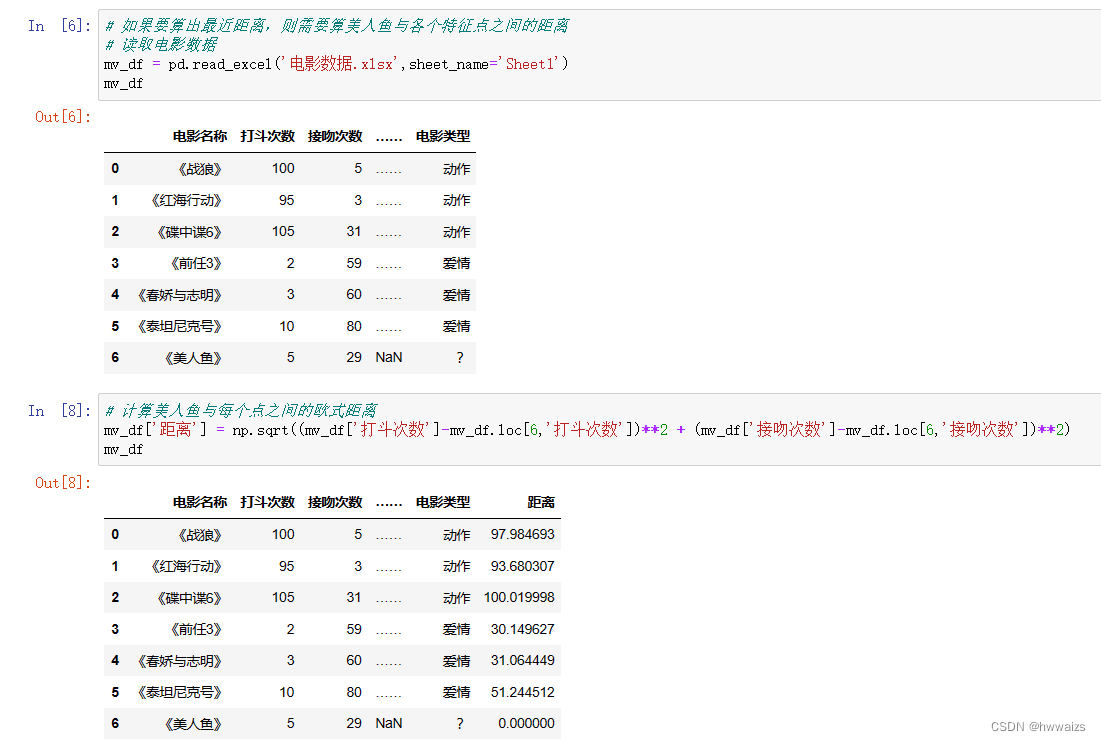
Si vous souhaitez calculer la distance la plus courte, vous devez calculer la distance entre "Mermaid" et chaque point caractéristique. D'après les résultats du calcul, on peut voir que le film le plus proche de "Mermaid" est "Predecessor 3". S'il est jugé à partir d'un seul point caractéristique, le résultat peut être inexact. À ce moment, il est nécessaire de sélectionner plus de valeurs propres proches (valeur K) pour comparaison. Si K = 3, sélectionnez les 3 plus proches, et les valeurs propres sélectionnées sont "Prédécesseur 3", "Chunjiao et Zhiming" et "Titanic". Si vous choisissez K = 4, il y aura des films d'amour 3 et un film d'action 1. À ce stade, sélectionnez le mode et classez les données dans la fonction avec le plus d'occurrences.
Il n'est pas fiable de juger le type uniquement par la distance d'un point caractéristique. Comme le montre la figure ci-dessous,
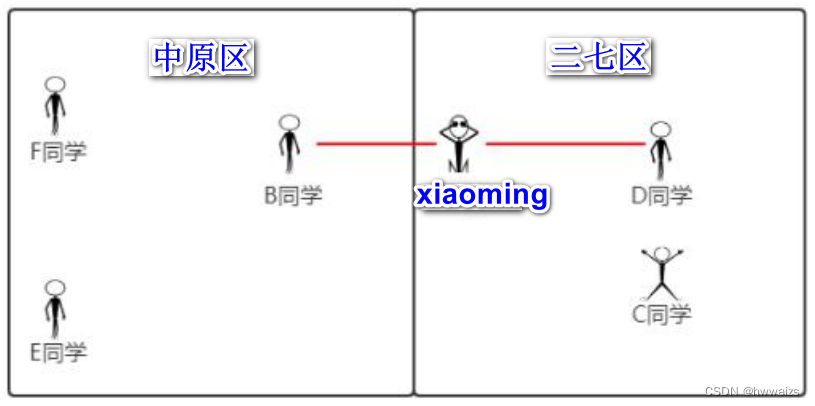
xiaoming se trouve en fait dans le district d'Erqi, mais la distance à l'élève B est la plus proche. Il s'agit d'un problème de classification. Dans l'algorithme du voisin le plus proche K, le rayon est utilisé pour dessiner un cercle, mais on ne peut pas dire que xiaoming se trouve dans le district des plaines centrales et le problème de classification ne peut pas être considéré comme une moyenne. Si vous choisissez cinq élèves à calculer et que vous calculez la distance à chaque élève séparément, vous devez choisir la catégorie avec le nombre majoritaire, afin de pouvoir déterminer de manière plus fiable la zone où se trouve xiaoming. Xiaoming est le plus proche des étudiants C et D, et les étudiants E et F sont plus éloignés, vous pouvez donc juger avec précision dans quelle zone se trouve xiaoming.
Flux de travail KNN
- Calculer la distance entre l'objet à classer et les autres objets ;
- Comptez les K voisins les plus proches ;
- Pour les K plus proches voisins, à quelle catégorie ils appartiennent le plus, l'objet à classer appartient à quelle catégorie.
En fonction du processus, utilisez numpy et pandas pour implémenter l'algorithme.

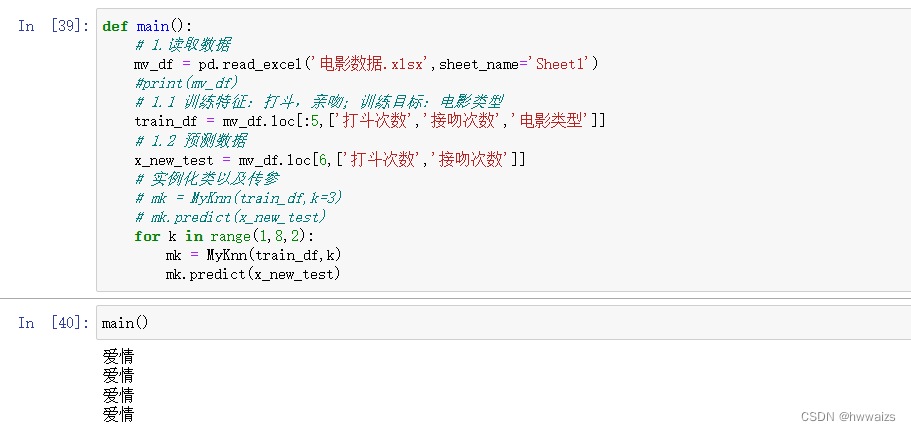
Pour le réaliser par programmation, il est nécessaire d'utiliser des idées de programmation orientée objet, qui peuvent réaliser le passage dynamique de paramètres, l'héritage, etc., en évitant l'acceptation et l'appel répétés entre les fonctions, et les attributs d'instance peuvent être utilisés dans toutes les méthodes d'instance. Encapsulez d'abord une classe, puis définissez une méthode main(), instanciez et appelez la méthode dans la méthode principale du programme.
Après avoir lu les données dans la méthode main(), toutes les données ne peuvent pas être transmises pour traitement, mais les données doivent être divisées en fonctionnalités initialisées, fonctionnalités d'entraînement : nombre de combats, nombre de baisers ; cible d'entraînement : type de film ; données de prédiction ; classe d'instanciation, caractéristiques d'entraînement d'entrée, données cibles et valeur K.
Pour transmettre les données obtenues à la classe, créez une méthode d'initialisation dans la classe pour initialiser la propriété.
Créez une méthode de prédiction pour prédire à quelle catégorie appartient le film "Mermaid", calculez la distance euclidienne entre les données prédites et les données réelles, obtenez les valeurs K supérieures avec la plus petite distance et effectuez des statistiques sur la classification des points K. À ce stade, les statistiques sont les résultats obtenus lorsque k est une certaine valeur. Si vous souhaitez en tester plusieurs, vous pouvez effectuer une traversée de boucle. Il est préférable de prendre un nombre impair pour k.
résumé
- Calculer la distance euclidienne
- Prenez les k voisins les plus proches
- L'utilisation du mécanisme de diffusion de numpy et pandas est plus efficace que la boucle de python
- Sélectionnez les données.
-
- df.loc [étiquette de ligne, étiquette de colonne], sélectionnez les données par étiquette
- 2.df.iloc[table de lignes, indice de colonne], sélectionnez les données par indice/index
-
- Un voisin n'est pas fiable et plusieurs voisins doivent être sélectionnés, et la catégorie est calculée, pas la moyenne.
Présentation de l'API de l'algorithme K-Nearest Neighbor
Introduction aux outils scikit-learn
scikit-learn est un outil d'apprentissage automatique basé sur le langage python. Documentation de référence : http://scikitlearn.com.cn
- Le langage Python est un outil d'exploration et d'analyse de données simple et efficace
- Scikit-learn inclut des implémentations de nombreux algorithmes d'apprentissage automatique bien connus
- Scikit-learn a une documentation complète, facile à utiliser et une API riche
installation scikit-learn
pip3 install scikit-learn
Remarque : Pour installer scikit-learn, vous devez installer numpy, Scipy et d'autres bibliothèques à l'avance
scikit-learn implémente l'algorithme du plus proche voisin K - problème de classification
À partir du module voisins sous le package sklearn, appelez le classificateur KNeighborsClassifier utilisé, n_neighbors est la valeur K spécifiée,
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto')
n_neighbors:查询默认使用的邻居数(默认为 5)
weights:默认为 “uniform” 表示为每个近邻分配同一权重;
可指定为 “distance” 表示分配权重与查询点的距离成反比;同时还可以自定义权重。
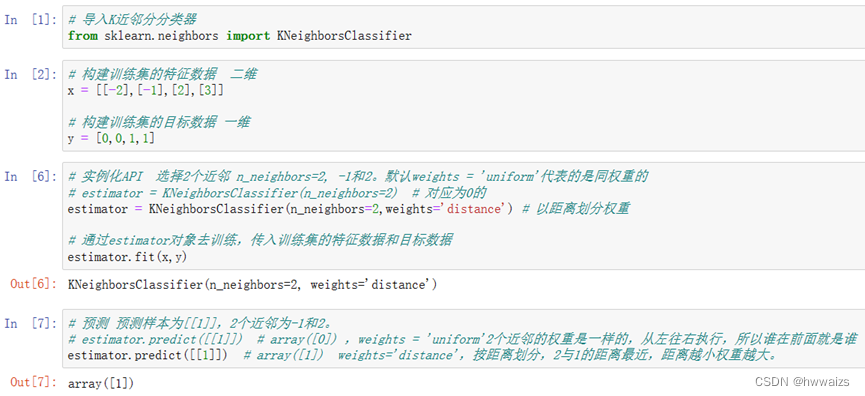
On peut voir d'après le titre que 1-, -2 sont de la même catégorie, qui est la catégorie 0 ; 2, 3 sont de la même catégorie, qui est la catégorie 1. L'entité entrante 1 sélectionne 2 voisins, non seulement les 2 les plus proches de 1 seront trouvés, mais également le -1 le plus proche de 1 sera trouvé. À ce moment, -1 et 2 ont le même poids. Entraînez le modèle en fonction des données et des résultats de l'entité existante, et utilisez weights='distance' pour augmenter le poids en fonction de la distance.
Un exemple de mise en œuvre de la classification de films
scikit-learn implémente l'algorithme du plus proche voisin K - résumé
- Construire des données d'entités et des données cibles
- Construire un classifieur avec k plus proches voisins (deux paramètres : n_neighbors, weights)
- Utiliser fit pour l'entraînement
- données prévisionnelles
Sélection de la valeur K
Si la valeur K est relativement petite, cela signifie que l'objet non classé est très proche de ses voisins. Un problème qui se pose de cette manière est que si le point voisin est un point de bruit, la classification des objets non classés produira également des erreurs, de sorte que la classification KNN produira un surajustement. Pour prédire la catégorie à travers les données d'entrée, les données d'entrée doivent être proches de l'exemple de formation pour produire des résultats. Si un seul exemple est pris (la valeur de k est trop petite), cela revient à pratiquer un seul type de question chaque jour. Lorsque vous rencontrez des types de questions complexes pendant l'examen, vous serez perdu. Vous ne vous souviendrez que des modèles que vous avez formés. Si vous entraînez trop un type de question, un surajustement se produira.
Si la valeur K est relativement grande, cela signifie que les points trop éloignés affecteront également la classification des objets inconnus.Bien que l'avantage de cette situation soit une forte robustesse, l'inconvénient est également évident.Il sera affecté par l'équilibre de l'échantillon et provoquera un sous-ajustement, c'est-à-dire que les objets non classés ne sont pas réellement classés. La valeur k est trop grande et la capacité à résister aux risques est relativement forte. Par exemple, lors de la préparation d'un examen, vous pouvez lire toutes sortes de questions (tout est inclus), et tout film qui arrive en verra des similaires. Les points de connaissance de l'examen proviennent du collège. Lors de la préparation de l'examen, j'ai passé en revue le contenu de l'école primaire, du collège, du lycée et de l'université.
Utilisez les valeurs N K pour tester de petit à grand, et sélectionnez la valeur K avec le meilleur résultat. Les tests artificiels un par un seront fastidieux et la validation croisée peut être utilisée. L'idée de la validation croisée est d'utiliser la plupart des échantillons de l'ensemble d'échantillons comme ensemble d'apprentissage, et la petite partie restante des échantillons est utilisée pour la prédiction afin de vérifier l'exactitude du modèle de classification. Par conséquent, dans l'algorithme KNN, nous sélectionnons généralement la valeur K dans une plage plus petite, et en même temps, celle avec la plus grande précision sur l'ensemble de vérification est finalement déterminée comme la valeur K.
calcul des distances
- Distance euclidienne (distance euclidienne)
- Manhattan distance
- Distance Minkowski
- Distance de Tchebychev
- distance cosinus
Distance euclidienne
La distance euclidienne représente la dérivation de la distance entre deux points. Par exemple, dans la classe 408, un élève se rend dans la classe 508 voisine. Il ne peut pas passer directement en fonction de la distance. La formule de la distance euclidienne bidimensionnelle est la suivante :
}d12=( x1−X2)2+( y1−y2)2
La formule de distance euclidienne tridimensionnelle dérivée est la suivante :
d 12 = ( x 1 - x 2 ) 2 + ( y 1 - y 2 ) 2 + ( z 1 - z 2 ) 2 d_{12} = \sqrt{(x_1-x_2)^2+(y_1-y_2)^2+(z_1-z_2)^2}d12=( x1−X2)2+( y1−y2)2+( z1−z2)2
La formule de distance euclidienne inductive à N dimensions est la suivante :
d 12 = ∑ k = 1 n ( xi − yi ) 2 d_{12} = \sqrt{\sum_{k=1}^n(x_i-y_i)^2}d12=k = 1∑n( xje−yje)2
- En ce qui concerne le nombre racine, cela impliquera des nombres à virgule flottante, et même des décimales infinies en boucle infinie. Les fonctionnalités de l'apprentissage automatique sont généralement de latitude élevée (au-delà de 3 dimensions), et lorsque des décimales sont impliquées, il y aura des erreurs, la consommation de mémoire sera importante et l'ordinateur fonctionnera très lentement. Afin de résoudre ce problème, essayez d'effectuer des calculs d'entiers et introduisez la distance de Manhattan.
Manhattan distance
Il est souvent utilisé dans l'espace géométrique. Par exemple, l'élève a est en 408 et l'élève b en 512. De a à b, la grille au milieu est un mur. Il est impossible de prendre la ligne verte de a pour passer à travers le mur. Le but ultime est de rendre la distance la plus courte possible. Vous pouvez monter du point a, la distance est y 2 y_2y2和y 1 y_1y1La différence, puis marcher horizontalement, la distance est x 2 x_2X2et x 1 x_1X1différence pour atteindre la destination finale. Trouver la distance entre deux points en additionnant les deux distances.
Comme on peut le voir sur la figure ci-dessous, quelle que soit la façon dont vous marchez le long de la grille, la distance entre deux points est certaine.
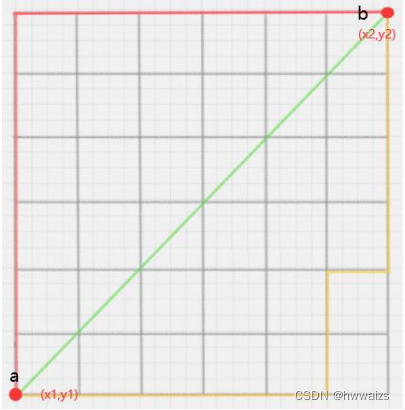
Plan bidimensionnel deux points a ( x 1 , y 1 ) a(x_1,y_1)un ( x1,y1) étant donnéb ( x 2 , y 2 ) b(x_2,y_2)b ( x2,y2) entre les distances de Manhattan :
d 12 = ∣ x 1 − x 2 ∣ + ∣ y 1 − y 2 ∣ d_{12}=| x_1-x_2 | +\mid y_1-y_2 \midd12=∣ x1−X2∣ +∣y1−y2∣
point d'espace à n dimensionsa ( x 11 , x 12 , . . . , x 1 n ) a(x_{11},x_{12},...,x_{1n})un ( x11,X12,... ,X1 n) étant donnéb ( x 21 , x 22 , . . . , x 2 n ) b(x_{21},x_{22},...,x_{2n})b ( x21,X22,... ,X2 n) Distance de Manhattan :
ré 12 = ∑ k = 1 n ( X 1 k - X 2 k ) d_{12} = {\sum_{k=1}^n(x_{1k}-x_{2k})}d12=k = 1∑n( x1 k−X2k _)
- La distance de Manhattan est également connue sous le nom de géométrie de taxi. Conduire dans la ville ne peut pas traverser les murs, mais ne peut que suivre l'itinéraire autour de la maison. Les calculs d'entiers en grandes dimensions n'utilisent que des opérations d'addition et de soustraction, évitant le calcul des décimales (afin qu'il n'y ait pas de décimales récurrentes infinies ou de nombres irrationnels), la vitesse de calcul est relativement rapide et l'erreur est très faible.
Distance de Tchebychev
Aux échecs, le roi peut aller droit, horizontalement ou en diagonale, de sorte que le roi peut se déplacer vers l'une des 8 cases adjacentes en faisant un pas. Roi du réseau ( x 1 , y 1 ) (x_1,y_1)( x1,y1) à la grille( x 2 , y 2 ) (x_2,y_2)( x2,y2) Quel est le nombre minimum d'étapes requises ? Cette distance s'appelle la distance de Chebyshev.
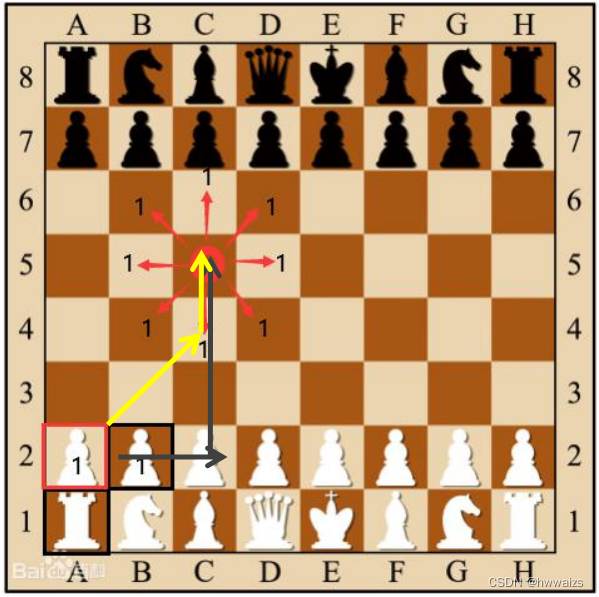
Sur la figure ci-dessus, nous pouvons voir la distance de 2A à 5C. Elle peut être de 2A à 2C (2 pas), puis de 2C à 5C (3 pas) ou de 2A à 4C (2 pas), puis de 4C à 5C (1 pas). Le nombre de pas effectués par le deuxième type est juste la valeur maximale des deux parties du nombre de pas effectués dans le premier.
Plan bidimensionnel deux pointsa ( x 1 , x 2 ) a(x_1,x_2)un ( x1,X2) étant donnéb ( x 2 , y 2 ) b(x_2,y_2)b ( x2,y2) entre les distances de Chebyshev :
d 12 = max ( ∣ x 1 − x 2 ∣ , ∣ y 1 − y 2 ∣ ) d_{12}=max(| x_1-x_2 | ,\mid y_1-y_2 \mid)d12=ma x ( ∣ x1−X2∣ ,∣y1−y2∣)
point d'espace à n dimensionsa ( x 11 , x 12 , . . . , x 1 n ) a(x_{11},x_{12},...,x_{1n})un ( x11,X12,... ,X1 n) étant donnéb ( x 21 , x 22 , . . . , x 2 n ) b(x_{21},x_{22},...,x_{2n})b ( x21,X22,... ,X2 n) Distance de Tchebychev :
d 12 = max ( ∣ x 1 je - x 2 je ∣ ) d_{12}=max(| x_{1i}-x_{2i} | )d12=ma x ( ∣ x1 je−X2 je∣ )
Distance Minkowski
La distance de style min est une sorte de distance entre les villes, et c'est une expression générale de plusieurs formules de mesure de distance. La distance de Minkowski est un indice passant, en changeant les paramètres pour remplacer la forme limite,
deux variables à n dimensions a ( x 11 , x 12 , . . . , x 1 n ) a(x_{11},x_{12},...,x_{1n})un ( x11,X12,... ,X1 n) étant donnéb ( x 21 , x 22 , . . . , x 2 n ) b(x_{21},x_{22},...,x_{2n})b ( x21,X22,... ,X2 n) La distance de Minkowski est définie comme :
d 12 = ∑ k = 1 n ∣ x 1 k − x 2 k ∣ pp d_{12} = \sqrt[p]{\sum_{k=1}^n|x_{1k}-x_{2k}|^p}d12=pk = 1∑n∣ x1 k−X2k _∣p
où p est un paramètre variable :
- quand p = 1 p=1p=Lorsque 1 , le signe racine n'existe pas, qui est la distance de Manhattan ;
- quand p = 2 p=2p=2 est la distance euclidienne ;
- Ce p → ∞ p\to \inftyp→∞ , prenez la valeur maximale de la limite et ignorez la valeur minimale, qui est la distance de Chebyshev
distance cosinus
La distance cosinus calcule en fait l'angle entre deux vecteurs et calcule la différence entre eux dans la direction, et n'est pas sensible aux valeurs absolues. La fonction sin est le rapport du côté opposé à l'hypoténuse, et la fonction cos est le rapport du côté adjacent à l'hypoténuse, et la formule cosinus de l'angle entre les deux vecteurs est dérivée. Le cosinus de l'angle inclus varie de -1 à 1, et plus le cosinus est grand, plus l'angle inclus du vecteur est petit.
Vecteur A dans un espace à deux dimensions ( x 1 , y 1 ) A(x_1,y_1)Un ( x1,y1) et vecteurB ( x 2 , y 2 ) B(x_2,y_2)B ( x2,y2) Formule du cosinus de :
cos θ = x 1 x 2 + y 1 y 2 x 1 2 + y 1 2 x 2 2 + y 2 2 cosθ=\frac{x_1x_2+y_1y_2}{\sqrt{x_1^2+y_1^2}\sqrt{x_2^2+y_2^2}}cos θ=X12+y12X22+y22X1X2+y1y2
Deux points d'échantillonnage à n dimensions a ( x 11 , x 12 , . . . , x 1 n ) a(x_{11},x_{12},...,x_{1n})un ( x11,X12,... ,X1 n) étant donnéb ( x 21 , x 22 , . . . , x 2 n ) b(x_{21},x_{22},...,x_{2n})b ( x21,X22,... ,X2 n) est :
cos θ = une ⋅ b ∣ une ∣ ∣ b ∣ cosθ=\frac{a \cdot b}{|a||b|}cos θ=∣ une ∣∣ b ∣un⋅b
即 : cos ( θ ) = ∑ k = 1 nx 1 kx 2 k ∑ k = 1 nx 1 k 2 ∑ k = 1 nx 2 k 2 cos(θ)=\frac{\sum_{k=1}^nx_{1k}x_{2k}}{\sqrt{\sum_{k=1}^nx_{1k}^2}\ sqrt{\sum_{k=1}^nx_{2k}^2}}cos ( θ )=∑k = 1nX1 k2∑k = 1nX2k _2∑k = 1nX1 kX2k _
- La distance cosinus est également appelée similarité cosinus, qui permet de juger de la corrélation entre deux éléments.
Par exemple, 3 personnes vont au supermarché pour acheter des articles. Elle est exprimée dans un tableau, 1 est acheté et 0 n'est pas acheté.
| article personnel | un | b | c | d | e |
|---|---|---|---|---|---|
| UN | 1 | 1 | 0 | 0 | 1 |
| B | 0 | 1 | 1 | 0 | 0 |
| C | 1 | 0 | 0 | 0 | 1 |
La similarité entre A et B : cos ( θ ) = 1 ∗ 0 + 1 ∗ 1 + 0 ∗ 1 + 0 ∗ 0 + 1 ∗ 0 1 2 + 1 2 + 0 2 + 0 2 + 1 2 0 2 + 1 2 + 1 2 + 0 2 + 0 2 = 1 6 = 0,408 co s(θ)=\frac{ 1*0+1*1+0*1+0*0+1*0}{\sqrt{1^2+1^2+0^2+0^2+1^2}\sqrt{0^2+1^2+1^2+0^2+0^2}}=\frac{1}{\sqrt{6}}=0.408cos ( θ )=12 +12 +02 +02 +1202 +12 +12 +02 +021 ∗ 0 + 1 ∗ 1 + 0 ∗ 1 + 0 ∗ 0 + 1 ∗ 0=61=0,408
La similitude entre A et C : cos ( θ ) = 1 ∗ 1 + 1 ∗ 0 + 0 ∗ 0 + 0 ∗ 0 + 1 ∗ 1 1 2 + 1 2 + 0 2 + 0 2 + 1 2 1 2 + 0 2 + 0 2 + 0 2 + 1 2 = 2 6 = 0,816 co s(θ)=\frac{ 1*1+1*0+0*0+0*0+1*1}{\sqrt{1^2+1^2+0^2+0^2+1^2}\sqrt{1^2+0^2+0^2+0^2+1^2}}=\frac{2}{\sqrt{6}}=0.816cos ( θ )=12 +12 +02 +02 +1212 +02 +02 +02 +121 ∗ 1 + 1 ∗ 0 + 0 ∗ 0 + 0 ∗ 0 + 1 ∗ 1=62=0,816
La similarité entre B et C : cos ( θ ) = 0 ∗ 1 + 1 ∗ 0 + 1 ∗ 0 + 0 ∗ 0 + 0 ∗ 1 0 2 + 1 2 + 1 2 + 0 2 + 0 2 1 2 + 0 2 + 0 2 + 0 2 + 1 2 = 0 4 = 0 cos(θ )=\frac{0*1+ 1*0+1*0+0*0+0*1}{\sqrt{0^2+1^2+1^2+0^2+0^2}\sqrt{1^2+0^2+0^2+0^2+1^2}}=\frac{0}{\sqrt{4}}=0cos ( θ )=02 +12 +12 +02 +0212 +02 +02 +02 +120 ∗ 1 + 1 ∗ 0 + 1 ∗ 0 + 0 ∗ 0 + 0 ∗ 1=40=0
On peut voir que la similarité entre A et C est élevée, et C, qui a une forte similarité avec A, peut être recommandé selon les articles achetés par l'utilisateur A.
Arbre KD
Si vous voulez prédire la catégorie de données avec l'emplacement, trouvez les k voisins les plus proches, calculez la distance entre ce point et tous les voisins, triez-les, trouvez le k le plus proche pour prendre le mode et divisez-les en le plus de catégories. Dans le cas de données relativement petites, la vitesse de calcul est relativement rapide. Si vous souhaitez former un modèle de données, la quantité de données doit être importante, puis calculez la distance entre les données prédites et chaque voisin un par un. La quantité de calcul sera particulièrement importante et vous pouvez utiliser l'arborescence KD pour l'optimisation.
Le processus de calcul de KNN consiste à calculer la distance entre un grand nombre de points d'échantillonnage. Afin de réduire le nombre de calculs de distance et d'améliorer l'efficacité de recherche de KNN, un arbre KD (abréviation de K-Dimensional) est proposé. L'arbre KD est une structure de données qui divise les points de données dans un espace à K dimensions. Dans la construction de l'arbre KD, chaque nœud est un arbre binaire de points de valeur à k dimensions. Puisqu'il s'agit d'un arbre binaire, vous pouvez utiliser les opérations d'ajout, de suppression, de modification et de requête de l'arbre binaire, ce qui améliore considérablement l'efficacité de la recherche.
- Exemple 1 : Il existe un ensemble de données {(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}, construisez un arbre kd.
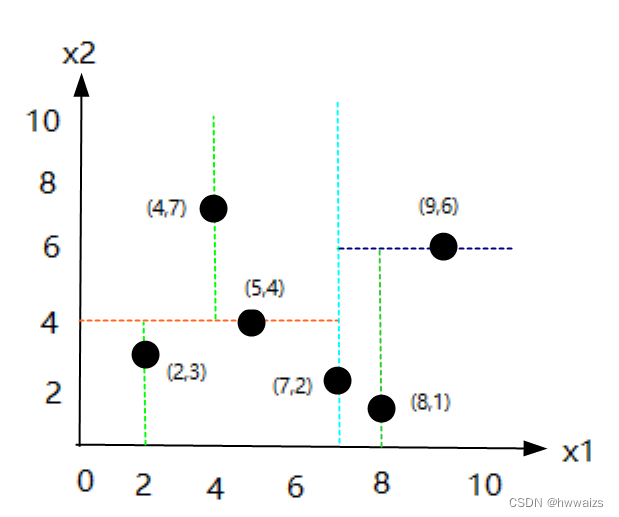
Les six points de données sont des points bidimensionnels, présentés sur des axes de coordonnées bidimensionnels, et la division de l'arbre kd :
- 1. Utilisez la médiane de l'axe x1 comme norme de segmentation, 2, 4, 5, 7, 8, 9, triez les nombres du plus petit au plus grand, si le nombre est pair, sélectionnez les deux points du milieu et additionnez-les pour trouver la médiane, (5+7)/2=6,
- 1. (5,4) est aussi proche que (7,2) de 6, prenez n'importe quel point tel que (7,2) comme nœud racine
- 2. Tracez une ligne perpendiculaire à l'axe x1 passant par (7,2) et divisez l'écran bidimensionnel en parties gauche et droite
- 2. Divisez la zone de gauche avec l'axe x2, trouvez la médiane et tracez une ligne verticale de x2,
- 1. Il y a 3 points dans la zone de gauche, les valeurs de x2 sont respectivement 3, 4, 7 et le point médian est (5,4),
- 2. Tracez une ligne perpendiculaire à x2 passant par (5,4), divisez la zone de gauche en parties supérieure et inférieure,
- 3. Divisez la zone inférieure avec l'axe x1. À l'exception des points qui sont devenus des nœuds, il ne reste que (2,3) points dans la zone inférieure. Tracez une ligne verticale de x1 à travers (2,3).
- 4. Divisez la zone supérieure avec l'axe x1. À l'exception des points qui sont devenus des nœuds, il ne reste que (4,7) points dans la zone supérieure. Tracez une ligne verticale vers x1 passant par (4,7).
- 5. Les points placés sur l'arbre binaire sont petits à gauche et grands à droite, donc mettez (2,3) points à gauche et (4,7) points à droite
- 3. Divisez la zone de droite avec l'axe x2, trouvez la médiane et tracez une ligne verticale de x2
- 1. Il ne reste que (8,1) et (9,6), donc la distance entre la médiane et les deux points est la même, et un point est sélectionné au hasard comme nœud, tel que (9,6)
- 2. Tracez une ligne verticale vers l'axe x2 passant par (9,6), divisez la zone droite en parties supérieure et inférieure, et la partie supérieure n'a pas de points
- 3. Trouvez la médiane de (8,1) dans la seconde moitié, il n'y a qu'un seul point, ce point est la médiane, et tracez une ligne verticale vers l'axe x1 passant par ce point, le dernier nœud obtenu est (8,1)
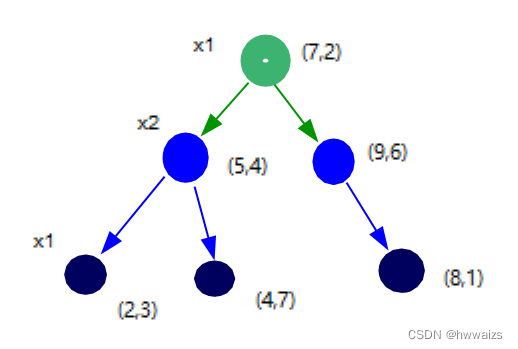
- Exemple 2, il y a un point cible (3,4.5), comment rechercher le voisin le plus proche du point cible dans l'ensemble de données ?
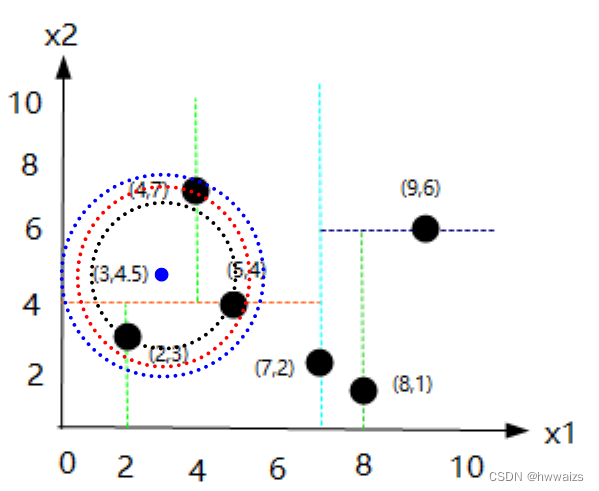
Si vous calculez la distance de chaque point, vous devez calculer fois 6. Si la quantité de données est importante, la quantité de calcul augmentera. Le calcul avec kd tree lui-même est un processus récursif et répétitif.
- 1. A en juger par le nœud racine (7,2), le nombre sur l'axe x1 du point (3,4,5) est 3, 3 est inférieur à 7, et le côté gauche est un nombre plus petit, et le point (5,4) est trouvé. Le nombre sur la dimension x2 est 4, et 4,5 est supérieur à 4. Vous chercherez la bonne direction (nombre plus grand), trouverez le point (4,7) et le voisin le plus proche temporaire sera (4,7).
- 2. Dessinez un cercle avec (3,4.5) comme centre et la distance au point (4,7) comme rayon, et obtenez un cercle bleu. Évidemment (4,7) n'est pas le voisin le plus proche du point (3,4.5). À ce moment, l'algorithme doit revenir en arrière, prendre le point cible comme centre du cercle et utiliser le point adjacent temporaire comme rayon pour faire un cercle. Le rayon entre les deux points est de 2,69.
- 3. Revenez au nœud précédent (5,4), faites un cercle avec le point cible comme centre et le point adjacent temporaire (5,4) comme rayon, et le rayon entre les deux points est de 2,06
- 4. Continuez à revenir en arrière jusqu'à (2,3), prenez le point cible comme centre du cercle et prenez le point adjacent temporaire (2,3) comme rayon pour former un cercle. Le rayon entre les deux points est de 1,8 et (2,3) est le point voisin le plus proche. À ce stade, il n'est pas nécessaire de calculer la distance entre (7,2), (9,6) et (8,1), ce qui réduit la quantité de calcul
.
Acquisition d'ensembles de données
Pour tester certains algorithmes, s'ils ne sont pas dans un environnement réel et manquent de données d'ingénierie de fonctionnalités, lors de l'apprentissage de ces modèles, vous pouvez apprendre des données qui ont été traitées.
obtenir la fonction
Interface pour obtenir des données
sklearn.datasets 加载获取流行数据集
datasets.load_***() 获取小规模数据集,数据包含在datasets里
datasets.fetch_***(data_home=None) 获取大规模数据集,需要从网络上下载,
函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
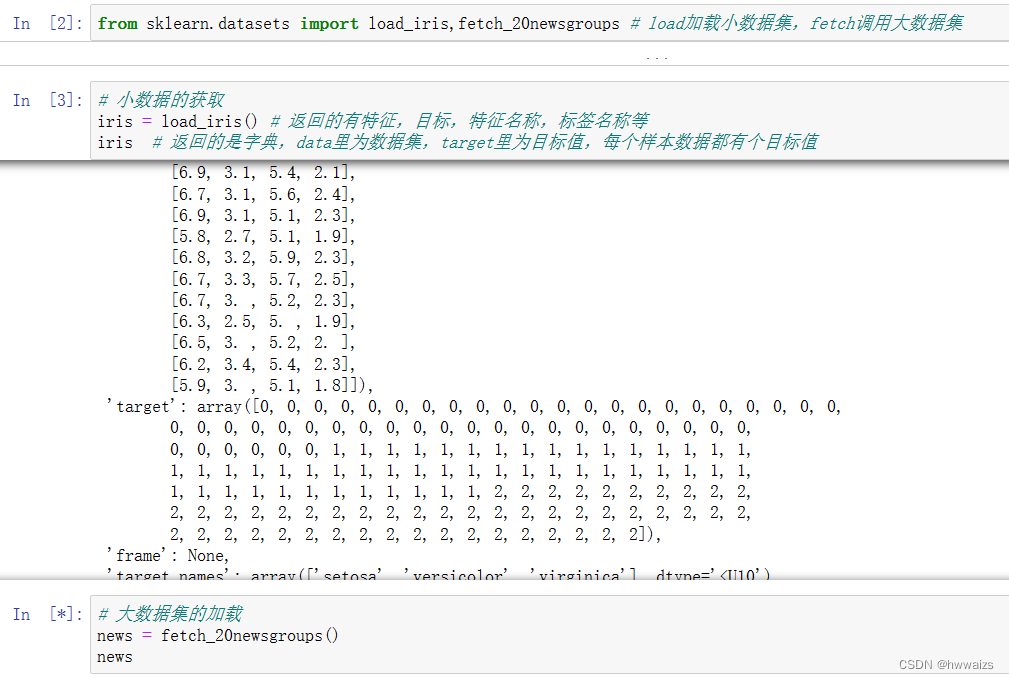
ensemble de retour
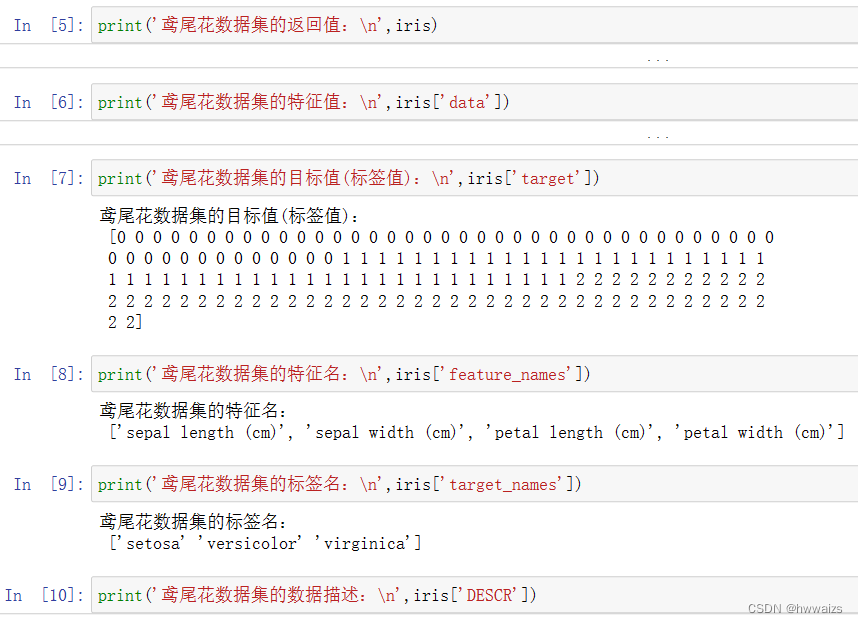
load 和 fetch 返回的数据类型(字典格式)
data:特征数据数组
target:标签数组
DESCR:数据描述
feature_names:特征名
target_names:标签名
segmentation des données
Une partie des données est nécessaire pour former le modèle, et une partie des nouvelles données est nécessaire pour évaluer la qualité du modèle. Lorsque les deux ensembles de données se chevauchent, le résultat sera faux. Par conséquent, les données sont divisées en ensemble d'apprentissage, ensemble de test et ensemble de vérification, et les données sont divisées en ensemble d'apprentissage et ensemble de test avant l'ajustement des paramètres. La méthode de segmentation des données : méthode d'implantation, diviser les données directement par 28 ou 37 ; validation croisée K-fold, diviser l'ensemble de données en 10 parties, utiliser 1 partie comme ensemble de test à son tour, et les autres comme ensemble d'apprentissage, et obtenir la moyenne des résultats de 10 fois ; la méthode d'auto-assistance, l'ensemble d'apprentissage est extrait au hasard avec remplacement. La plus couramment utilisée est la méthode du hold-out.
mettre de côté la méthode api
Réalisez avec un programme, divisez l'ensemble de données en 3 parties et 7 parties, utilisez les données sélectionnées de numpy et pandas pour le faire, trouvez la longueur totale des données, puis coupez-les, et utilisez sklearn pour faire le test fractionné de l'ensemble d'entraînement.
sklearn.model_selection.train_test_split(arrays,*options)
x 数据集的特征值
y 数据集的标签值
test_size 测试集的大小,一般为float
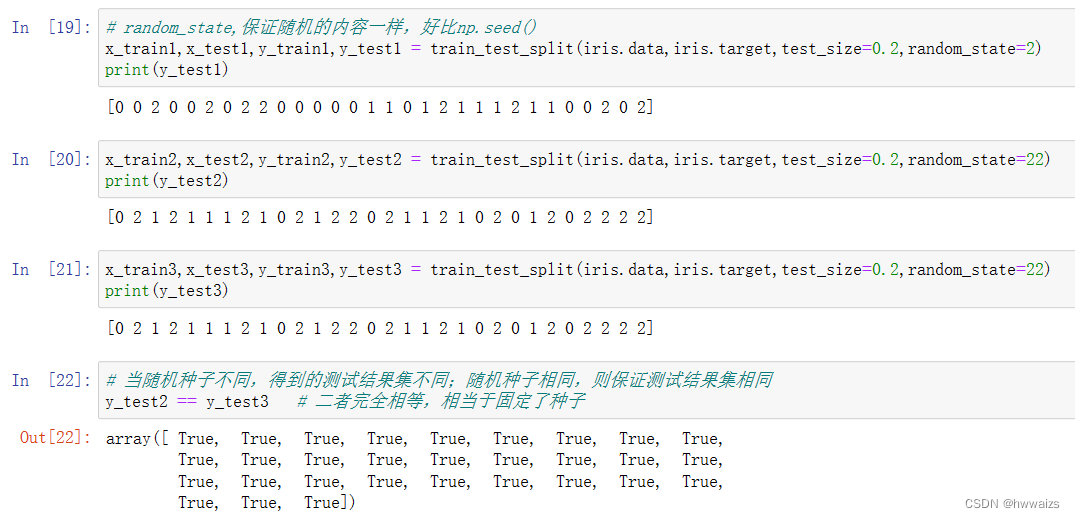
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return 训练特征值,测试特征值,训练目标值,测试目标值
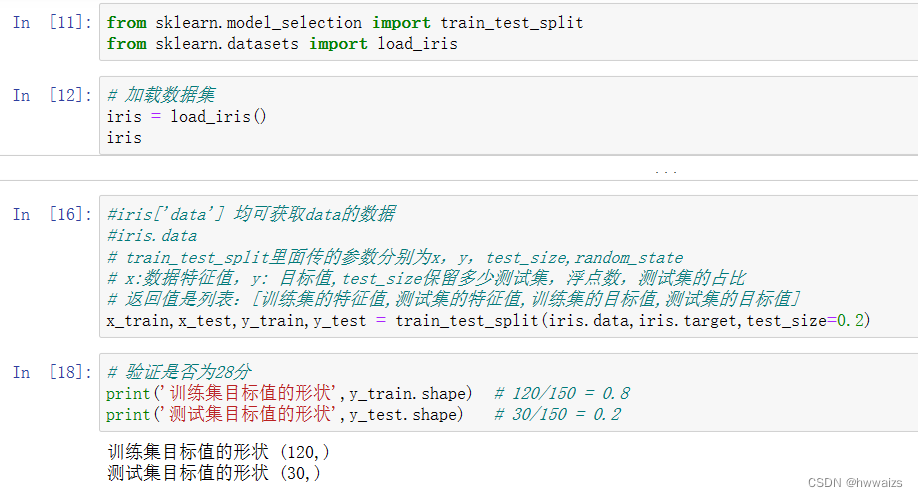
Les algorithmes et les modèles sont aléatoires. Lorsque le même algorithme et le même ensemble de données sont exécutés plusieurs fois, les résultats seront différents. Les résultats du même code et du même modèle formés par différentes personnes seront différents. La segmentation des données est également aléatoire et le paramètre random_state peut être utilisé pour s'assurer que les résultats de chaque formation sont les mêmes.