1. Une partie du système de contrôle du vent
1.Blaze
Blaze est un produit de FICO, utilisé pour la gestion des règles, et est le prédécesseur du développement de cartes modèles ABC. Lorsque les sociétés de crédit commencent à prêter, la quantité de données est faible et il y a peu de candidats, il est donc difficile de construire un modèle. Par conséquent, au début, l'expérience des experts est généralement utilisée pour juger des bons ou des mauvais clients, puis un fonctionnement efficace est effectué par le biais du système de gestion décisionnel en matière de contrôle des risques.Parmi eux, Blaze est un système de gestion décisionnelle en matière de contrôle des risques avec haute efficacité utilisée depuis de nombreuses années. Cependant, Blaze est un produit commercial et est généralement utilisé dans les grandes sociétés de crédit à la consommation telles que les grandes banques et Home Credit. Les frais peuvent être supérieurs à 1 million de RMB par an. Si des services plus personnalisés sont requis, les frais seront plus élevés.
1.1 Une
définition de carte : Carte de pointage de demande de carte de pointage, les règles d'attribution de valeurs aux matériaux soumis lors de la phase d'octroi du crédit.
Par exemple : « Incoming » est un terme utilisé par les banques traditionnelles, qui fait référence au formulaire de candidature. Une carte de pointage est un jugement complet sur une série d’informations utilisateur. Avec l'augmentation du nombre d'informations sur les utilisateurs pouvant être collectées, les décideurs en matière de crédit ne se contentent plus d'une simple logique si et sinon, mais espèrent attribuer des pondérations et des scores à chaque information, juger les risques sur la base du score global final des utilisateurs et ajuster en conséquence. délimitant la ligne de score Tolérance au risque, le tableau de bord est né. Le tableau de bord est un dérivé de l'algorithme de régression logistique.
1.2
Définition de la carte B : Carte de score de comportement Carte de score de comportement, les règles de notation des informations sur les utilisateurs qui peuvent être collectées après le prêt.
Exemple : Semblable à la carte A, la carte B est également un ensemble de règles de notation. Une fois le prêt émis, en collectant les données de comportement de l'utilisateur après avoir reçu l'argent, on spécule si l'utilisateur sera en retard et si le l'utilisateur peut continuer à emprunter de l'argent. Par exemple, après qu'un utilisateur a obtenu un prêt auprès d'une certaine banque, puis a demandé des prêts auprès de plusieurs autres banques, on peut considérer que cette personne manque de fonds et pourrait ne pas être en mesure de rembourser le prêt. à nouveau un prêt bancaire, il doit prêter de l'argent avec précaution. Dans le modèle de la carte B, il existe de nombreux sous-modèles pour la gestion des stocks, notamment l'activation du modèle client silencieux, la recherche de clients de grande valeur, l'augmentation du modèle de montant du prêt, etc.
1.3 Définition de la carte C
: Collection Scorecard Collection Scorecard, une règle de notation permettant de juger de la capacité des utilisateurs ayant expiré dans le futur à envoyer des rappels.
Exemple : Collection Scorecard est une application dérivée de Behaviour Scorecard, et sa fonction est de prédire l'intensité de la collecte des utilisateurs en retard. Pour les utilisateurs de bonne réputation, l’argent peut être récupéré sans collecte ni collecte légère. Pour les utilisateurs qui ont tendance à être en retard depuis longtemps, il est nécessaire de se concentrer sur le recouvrement des retards. Plus il y a de jours de retard, plus il est difficile de les recouvrer.
La collecte est généralement divisée en plusieurs agents, et l'expérience et les capacités commerciales des différents agents tels que M1, M2 et M3 varient considérablement. L’intelligence artificielle IA est souvent utilisée au début de la collecte automatique.
La carte de score d'application, la carte de score de comportement et la carte de score de collecte sont souvent combinées et appelées « carte ABC », qui est utilisée dans la gestion avant, prêt et post-prêt. . . . . . . .
2. Indicateurs de contrôle des risques
- 1 Analyse du vieillissement
Interprétation : analyse du vieillissement. Affiche le taux de décalage de chaque période jusqu'au point d'observation, qui est caractérisé par le même point final de règlement, et combine les prêts dispersés au cours de chaque mois en un seul point temporel d'observation pour calculer le taux de retard.
- 2 Analyse du millésime
Interprétation : Les statistiques sur l'arriéré des nouveaux prêts chaque mois au cours des mois suivants sont également une analyse vieillissante. À la différence de l’analyse chronologique, le millésime est basé sur la chronologie du prêt, en observant le taux d’arriérés de N mois après le prêt. Il peut également être utilisé pour analyser la qualité du suivi des prêts au cours de chaque période et observer l'impact de l'ajustement des règles d'entrée sur la qualité des droits des créanciers. Exemple : Deliquency Vintage 30+ : principal restant de plus de 30 mois en souffrance / montant mensuel du prêt correspondant à la génération de la facture. Manuel de terminologie chinoise et anglaise du contrôle des risques (Bank_Consumer Finance and Credit Business)_v4_Manuel de terminologie
- 3C、M
Interprétation : C et M sont des noms propres décrivant des tranches de périodes de retard. M0 est un actif normal, Mx est en retard depuis x périodes et Mx+ est en retard depuis x périodes (inclus). La tranche sans remboursement normal en souffrance est M0, qui est C, et M1 s'étend sur 1 période (1 à 29 jours). M2+ signifie plus de 2 périodes et plus (30+). M2 et M4 sont deux nœuds d'observation importants.On considère généralement que M1 est la phase précoce, M2-M3 est la phase intermédiaire et au-dessus de M4 est la phase tardive.Les transferts de créances douteuses supérieures à M6 sont pris en compte.
- 4 Délinquance
Interprétation : taux de retard/taux de retard. Les indicateurs d'évaluation de la qualité des actifs peuvent être divisés en méthodes d'observation coïncidente et décalée.
- 5 Coïncidence
Interprétation : indicateurs ponctuels. Il permet d'analyser la qualité de tous les comptes clients de la période en cours et de calculer le taux de retard. La méthode de calcul consiste à diviser le montant différé de chaque tranche de la période en cours par le total des comptes clients (AR) de la période en cours. Coïncident est un aperçu de l'ensemble au point d'observation actuel, il est donc vulnérable aux fluctuations causées par le niveau des créances au cours de la période en cours, ce qui est approprié pour observer la qualité des actifs lorsque le volume total des affaires ne fluctue pas beaucoup. Exemple : DPD coïncident 30+, un indicateur couramment observé
- 6 en retard
Interprétation : Indicateurs différés. De la même manière que la coïncidence, c'est également un indicateur pour calculer le taux de retard. La différence est que le dénominateur du décalage est les comptes clients de la période au cours de laquelle le montant en souffrance a été généré. Lagged observe le taux de retard généré au cours de la période de prêt en cours, il n'est donc pas affecté par la fluctuation des comptes clients au cours de la période en cours. Exemple : DPD décalé 30+$(%)= M2 décalé+M3 décalé+M4 décalé+M5 décalé+M6 décalé Solde d'actif M1 à la fin du mois (1-29 jours) : Actifs à la fin du mois statistique satisfaisant 1≤jours de retard actuels≤29 La somme du principal restant de la commande, les jours de retard actuels correspondent au nombre maximum de jours de retard actuels de la commande, à l'exclusion des commandes de créances irrécouvrables. M1 décalé = solde du prêt de M1 à la fin du mois/solde du prêt à la fin du mois précédent (M0 ~ M6) Manuel de terminologie chinoise et anglaise du contrôle des risques (Bank_Consumer Finance and Credit Business)_v4_Risk Control_02
- 7.0 PD (en souffrance)
Par exemple, les lettres devant FPD1, SPD7, TPD30..., F : premier, signifient que la première période est en retard. De même, S, T et Q représentent respectivement deux, trois et quatre, et seront représentés par chiffres plus tard. Tel que 5PD30. Le nombre suivant fait référence au nombre de jours de retard. Si un client a une note de FPD30, il doit y avoir une note inférieure à 30, comme FPD1 et FPD7. dpd (jours de retard) est le nombre de jours de retard. Pour les produits de prêt, il est calculé à partir du lendemain de la date limite de paiement (généralement la prochaine date de clôture du compte). Parmi les 4 versements, si un versement est en retard de plus de 30 jours, il sera considéré comme un mauvais client. Une chose à noter est que les indicateurs PD s'excluent généralement mutuellement, c'est-à-dire si une personne a le Marque FPD, il n'aura pas la marque SPD.Clients dont le paiement est en retard lors du deuxième versement.
- 7PDJ
Interprétation : Les jours de retard sont le nombre de jours de retard, le nombre de jours entre le lendemain de la date de remboursement et la date de remboursement effective. Exemple : DPD7+/30+, historique de retard de plus de 7 jours et 30 jours. La formule de calcul du taux de retard relativement stricte dans l'industrie est la suivante : à un moment donné, diviser le capital total restant impayé des comptes de prêt actuellement en souffrance depuis plus de 90 jours par le montant total des contrats accumulés pouvant donner lieu à plus de 90 jours. en retard. Le concept de son numérateur est que tant qu'il est en souffrance depuis plus de 90 jours, le capital total restant du contrat qui n'a pas été remboursé est considéré comme en souffrance, tandis que le dénominateur considère que certains prêts avec une échéance très courte le temps est absolument impossible à générer 90+ jours de retard Le montant du contrat est exclu (par exemple, emprunter il y a seulement 2 jours, il est de toute façon impossible d'avoir plus de 90 jours de retard).
- 8 écrans par jour
Interprétation : premier retard de paiement, premier remboursement en retard. Après l'approbation du crédit de l'utilisateur, la première facture à rembourser, la proportion de clients qui n'ont pas remboursé dans les 7 jours suivant la dernière date de remboursement et n'ont pas demandé de prolongation est FPD 7, et le numérateur est la commande passée lors de la période d'observation et est en retard depuis plus de 7 jours Le nombre d'utilisateurs, le dénominateur est le nombre d'utilisateurs dans la période d'observation qui ont passé toutes les premières commandes dans la période en cours et ont respecté la date de remboursement 7 jours plus tard. Les indicateurs FPD couramment utilisés sont le FPD 30. Exemple : Supposons que l'utilisateur ait approuvé le crédit le 10.1, généré le premier prêt en trois versements le 10.5 et fixé le 8 de chaque mois comme date de remboursement. Le 11.08 est alors la date de remboursement de la première facture, et le remboursement après la date de facturation et avant la fin de la date de remboursement n'est pas considéré comme en souffrance. Si le prêt n'a pas été remboursé le 11.16, il sera inclus dans le numérateur du manuel de terminologie chinoise et anglaise de contrôle des risques (bank_consumer finance and credit business)_v4_bank_03 FPD7 pour la période du 10.1-10.30. Habituellement, les utilisateurs en retard depuis quelques jours peuvent avoir oublié de rembourser le prêt ou être à court d'argent pendant un certain temps, mais l'indicateur FPD 7 peut être utilisé par les utilisateurs pour évaluer le risque de crédit des groupes d'octroi de crédit et prédire la santé. des actifs futurs. Semblable au FPD 7, le FPD 30 est également un indicateur permettant d'observer la situation de retard de la première facture impayée de l'utilisateur. Pour les utilisateurs en retard de plus de 30 jours, certaines pertes peuvent être récupérées en augmentant les efforts de recouvrement. Pour les utilisateurs en retard de plus de 30 jours, la probabilité de recouvrement sera considérablement réduite et une collecte externalisée pourra être effectuée. Si le FPD 7 des utilisateurs est relativement élevé pendant un certain temps et que la plupart des remboursements inférieurs tombent dans le FPD 30, cela prouve que la proportion de non-partants dans ce groupe d'utilisateurs est élevée et qu'ils n'ont jamais pensé à rembourser. le prêt du tout, sinon cela signifie que les utilisateurs Le risque de crédit du groupe est plus grave.
- 9Cpd30mob4
cpd est utilisé dans le modèle de collecte et est un indicateur de collecte. La performance de remboursement est de savoir si le délai de retard du quatrième mois est supérieur à 30 jours, hors historique.
- 0 maxdpd30_mob4
Au cours des quatre périodes d'observation (mois), si le retard dépasse 30 jours, y compris l'historique
- 1 MOB en compte mois
Exemple du mois après décaissement : MOB0, la date de décaissement jusqu'à la fin du mois MOB1, le deuxième mois complet après décaissement MOB2, le troisième mois complet après décaissement mob3-3 mois est la courte période d'observation, mob6-6 mois est la longue période d'observation
- 2 Débit
Interprétation : Taux de migration. Observez la probabilité que le montant en souffrance au cours de la période précédente continue de tomber dans la période suivante après le recouvrement. Exemple : M0-M1=Solde d'actif M1 à la fin du mois M / solde du prêt de M0 à la fin du mois dernier août M0-M1 : solde du prêt entrant dans M1 en août / solde du prêt de M0 à fin juillet au début du mois d'août Informations complémentaires : macro Les risques économiques à moyen et court terme peuvent être mesurés à l'aide de FDP, SPD, TPD ; les risques à moyen terme peuvent être mesurés à l'aide de 30+@MOB4 ; les risques à long terme peuvent être mesurés à l'aide de 90+@MOB6, etc. Pour mesurer le risque à court terme, FPD, SPD, TPD pourraient être utilisés ; Pour mesurer le risque à moyen terme, 30+@MOB4 pourrait être utilisé ; Pour mesurer le risque à long terme, 90+@MOB6 pourrait être utilisé ; différents les produits appliquent différents indicateurs Fpd30 (produits de prêt en espèces) maxdpd30_mob4 (clients existants) Cpd30mob4 (clients de recouvrement)) Définition des mauvais clients pour les prêts automobiles (pour référence uniquement) Manuel de terminologie chinoise et anglaise du contrôle des risques (Bank_Consumer Finance and Credit Business)_v4_Bank_04 Remarque : En raison de la subdivision des scénarios, les différents scénarios sont très différents et les indicateurs ci-dessus sont uniquement à titre de référence.
3. Partie du modèle de contrôle des risques
3.1
Interprétation du benchmark : benchmark. Chaque version du nouveau modèle est comparée à un modèle de référence en ligne ou à un ensemble de règles.
3.2
Interprétation de IV : valeur de l'information Valeur de l'information, également appelée VOI, valeur de l'information, plage de valeurs (0,1). Cette valeur est utilisée pour représenter la capacité prédictive d’une variable, plus elle est grande, mieux c’est. Le seuil des variables de contrôle du contrôle des risques financiers est de 0,02. Si le iv de la variable est inférieur à 0,02, alors la variable sera expulsée. En tant qu'expert en modèles, je rappelle à tous que la valeur iv ne peut pas être mémorisée par cœur et que le seuil doit être personnalisé en fonction des caractéristiques de distribution des données de la scène. La répartition des valeurs variables iv dans différents scénarios peut varier considérablement, comme par exemple les prêts, les prêts automobiles et les prêts de trésorerie.
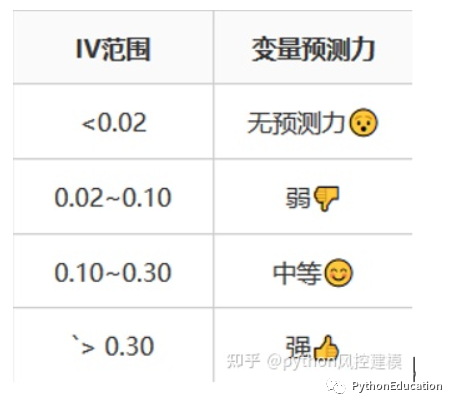
3.3 Interprétation de la valeur KS
: KS fait référence à klmogrov-smirnov, qui est un indice de différenciation. Le pouvoir de différenciation fait référence à la capacité du modèle à distinguer les bons et les mauvais clients. La valeur KS varie de 0 à 1, plus elle est grande, mieux c'est, plus elle est petite, pire c'est. Dans des scénarios réels, le modèle ks dans le domaine du contrôle des risques peut rarement dépasser 0,4.
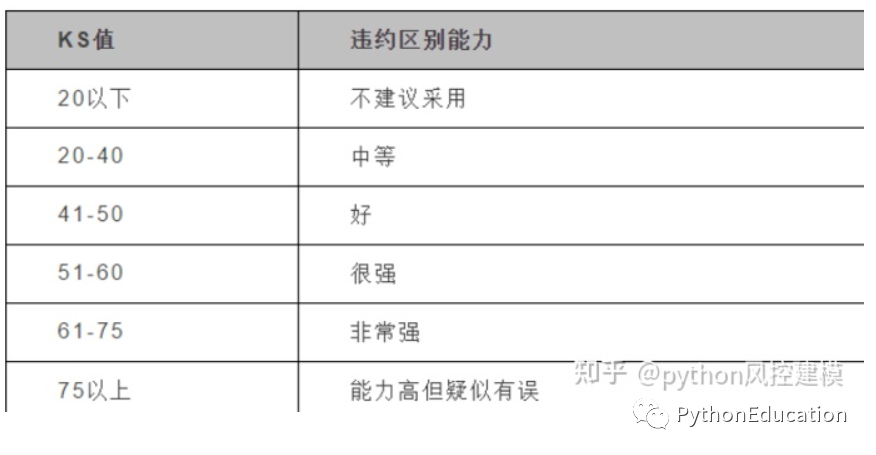
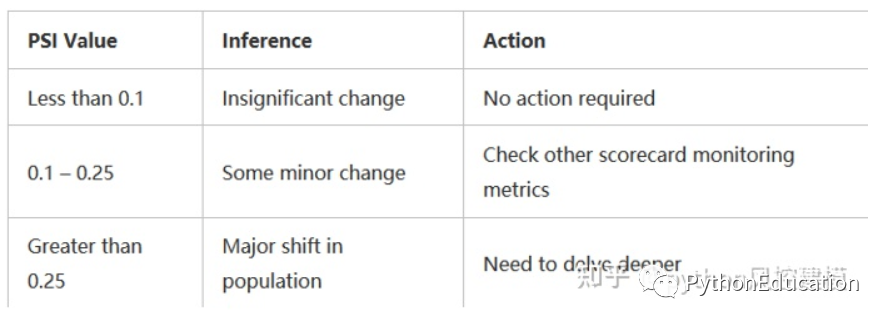
3.4 Interprétation PSI : indice de stabilité de la population, indice de stabilité, plus il est bas, plus il est stable. Il est utilisé pour comparer le degré de différence entre le groupe de clients actuel et le groupe de clients de l'échantillon de développement de modèle, et évaluer si l'effet du modèle répond aux attentes. Plus le PSI est proche de 0, meilleure est la stabilité du modèle. Lorsque le PSI est inférieur à 0,1, le modèle est relativement stable. Lorsque le psi est compris entre 0,1 et 0,25, la stabilité du modèle fluctue et le modèle doit être vérifié et redéveloppé si nécessaire.
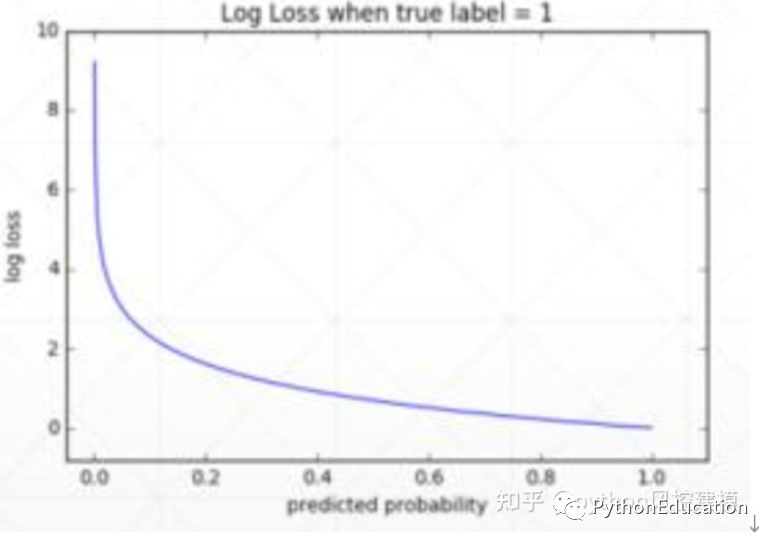
3.6 Perte de log
Interprétation : fonction de perte logarithmique
À mesure que la probabilité prédite se rapproche de 1, la perte logarithmique diminue lentement. Mais la perte logarithmique augmente rapidement à mesure que la probabilité prédite diminue. Plus la valeur de la perte logarithmique est élevée, moins le modèle est précis, et vice versa.
3.7
Interprétation des échantillons de formation : échantillons de modélisation, un ensemble de données utilisateur expressives utilisées pour entraîner le modèle. Il existe également un échantillon hors temps (échantillon de vérification) en conjonction avec cet échantillon. Les deux échantillons prennent la même dimension utilisateur. Habituellement, le modèle formé par l'échantillon de modélisation est utilisé pour la vérification sur l'échantillon de vérification.
3.8
Interprétation du WOE : poids de la preuve, poids de la preuve, plage de valeurs (-1,1). La proportion d'éléments violés est supérieure à celle des éléments normaux et le WOE est négatif. Plus la valeur absolue est élevée, plus ce groupe de facteurs est capable de distinguer les bons et les mauvais clients. Les données du modèle de tableau de bord doivent convertir les données originales en données de malheur, afin de réduire la variance des variables et de les rendre lisses. La valeur IV est également convertie à partir de la valeur malheur. Puisque le malheur présente certains défauts dans l’évaluation des variables, il utilise généralement la valeur iv pour évaluer l’importance des variables.
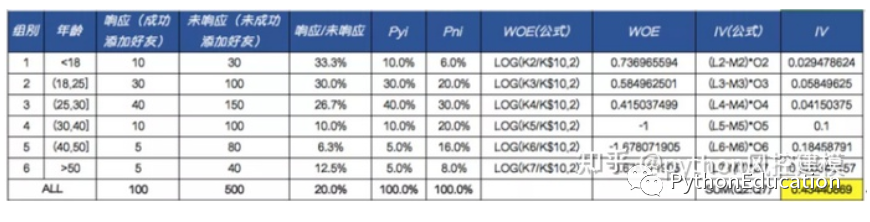 3.9 Mauvais taux de capture
3.9 Mauvais taux de capture
Interprétation : mauvais taux de capture des utilisateurs. Il s'agit d'un indicateur permettant d'évaluer les performances du modèle, et plus le ratio est élevé, mieux c'est.
Exemple : Le taux de capture des 10 % de mauvais utilisateurs fait référence au rapport entre les 10 % des pires utilisateurs évalués par le modèle et les mauvais utilisateurs de l'échantillon.
3.10
Définition de la population : toute la population, tous les utilisateurs d'échantillons, y compris les échantillons de modélisation et les échantillons de vérification.
3.11
Interprétation des variables : nom de la variable. Chaque modèle s'appuie sur de nombreuses variables de base et dérivées comme paramètres d'entrée. La dénomination des variables doit être conforme à la spécification, facile à comprendre et à développer. Les variables doivent être examinées avant la modélisation. Dans les modèles Big Data, plus de 90 % des variables sont des variables de bruit. Les variables vraiment utiles sont très peu nombreuses.
3.12
Interprétation du CORR : coefficient de corrélation. Plus la valeur absolue de Corr est proche de 1, plus le degré de corrélation linéaire est élevé, et plus la valeur absolue de Corr est proche de 0, plus le degré de corrélation est faible. Le calcul du coefficient de corrélation dépend de la distribution des données : si les données présentent une distribution normale, la précision de la méthode Pearson est plus élevée ; sinon, la méthode Spearman est plus appropriée.
3.13 matrice de confusion matrice de confusion
Sensibilité : Dans des conditions vraiment positives, le test est également positif
spécificité : Dans des conditions vraiment négatives, le test est également négatif
FAUX positif : le test est positif dans des conditions vraiment négatives
FAUX négatif : le test est négatif dans des conditions vraiment positives

3.14 Algorithme du modèle
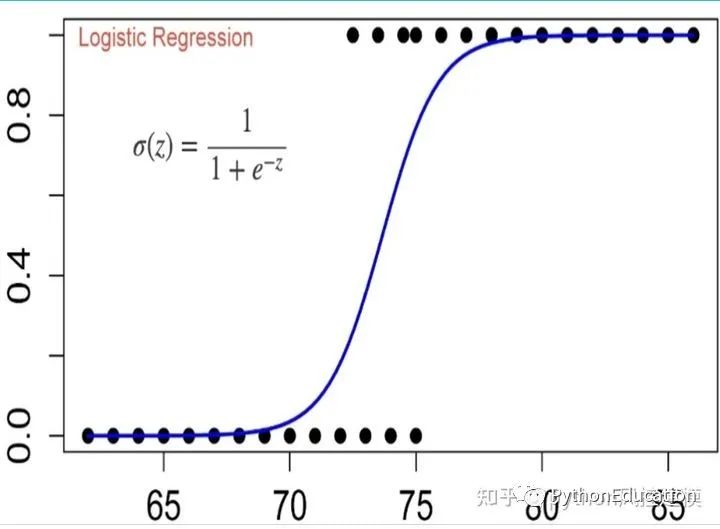
Régression logistique
La régression logistique est un modèle linéaire généralisé, elle présente donc de nombreuses similitudes avec l'analyse de régression linéaire multiple. Leurs formes de modèle sont fondamentalement les mêmes, les deux ont w'x+b, où w et b sont les paramètres à rechercher, et la différence est que leurs variables dépendantes sont différentes. La régression linéaire multiple utilise directement w'x+b comme paramètre variable dépendante, c'est-à-dire y = w'x+b, et la régression logistique utilise la fonction L pour faire correspondre w'x+b à un état caché p, p = L(w'x+b), puis détermine la variable dépendante variable en fonction de la taille de p et de la valeur 1-p. Si L est une fonction logistique, c'est une régression logistique, et si L est une fonction polynomiale, c'est une régression polynomiale.
La variable dépendante de la régression logistique peut être binaire ou multi-catégories, mais la catégorie binaire est plus couramment utilisée et plus facile à expliquer, et les multi-catégories peuvent être traitées à l'aide de la méthode softmax. La plus couramment utilisée en pratique est la régression logistique des deux classifications.
modèle de tableau de bord
Le modèle de tableau de bord est un dérivé de l'algorithme de régression logistique. Appliquez des techniques de regroupement des malheurs et d’étirement des scores pour convertir les scores de probabilité de régression logistique en scores standard. Les scores standard sont similaires aux scores FICO ou aux scores Sesame Credit, allant de 300 à 900. La figure ci-dessous montre le mode de notation de la carte de score
Tutoriels liés au tableau de bord : https://edu.csdn.net/course/detail/30611
Machine à vecteurs de support (SVM)
Support Vector Machine (SVM) est une sorte de classificateur linéaire généralisé (classificateur linéaire généralisé) qui effectue une classification binaire sur les données selon l'apprentissage supervisé, et sa limite de décision est la marge maximale pour résoudre les échantillons d'apprentissage Hyperplan (hyperplan à marge maximale ). SVM a été proposé en 1964, s'est développé rapidement après les années 1990 et a dérivé une série d'algorithmes améliorés et étendus, qui ont été appliqués à des problèmes de reconnaissance de formes tels que la reconnaissance de portraits et la classification de texte. L'algorithme de la machine à vecteurs de support fonctionne mieux sur de petits échantillons de données, mais la formation de données volumineuses prend beaucoup de temps.
Réseau neuronal
La pensée logique fait référence au processus de raisonnement selon des règles logiques ; elle convertit d'abord les informations en concepts et les exprime avec des symboles, puis effectue un raisonnement logique en mode série selon des opérations symboliques ; ce processus peut être écrit sous forme d'instructions sérielles, permettant à l'ordinateur à mettre en œuvre. La pensée intuitive, cependant, est la synthèse d’informations stockées distribuées et le résultat est une idée ou une solution soudaine à un problème. Le point fondamental de cette façon de penser réside dans les deux points suivants : 1. L’information est stockée sur le réseau grâce à la distribution de modèles d’excitation sur les neurones ; 2. Le traitement de l’information est complété par le processus dynamique d’interaction simultanée entre les neurones.
Remarque : Les principes de fonctionnement des réseaux de neurones informatiques et des réseaux de neurones biologiques du cerveau humain sont différents.
Un petit peu : efficace dans le traitement du big data, capable de gérer des données complexes et multidimensionnelles, flexible et rapide
Inconvénient : les données doivent être prétraitées
xgboost
XGBoost est une bibliothèque distribuée optimisée d'amélioration des dégradés conçue pour être efficace, flexible et portable. Il implémente des algorithmes d'apprentissage automatique sous le framework Gradient Boosting. XGBoost fournit une amélioration d'arbre parallèle (également connue sous le nom de GBDT, GBM) qui peut résoudre de nombreux problèmes de science des données rapidement et avec précision. Le même code s'exécute sur les principaux environnements distribués (Hadoop, SGE, MPI) et peut résoudre des problèmes au-delà de milliards d'exemples. xgboost est un algorithme d'arbre d'ensemble, inventé par Chen Tianqi, qui a remporté de nombreux championnats dans des compétitions Kaggle.
lumièregbm
Light Gradient Boosted Machine, LightGBM en abrégé, est une bibliothèque open source qui fournit une implémentation efficace de l'algorithme d'amplification de gradient. L'algorithme développé par Microsoft a de meilleures performances globales que xgboost.
LightGBM étend l'algorithme d'amélioration des dégradés en ajoutant une forme de sélection automatique des fonctionnalités et en se concentrant sur des exemples améliorés avec des dégradés plus grands. Cela peut considérablement accélérer la formation et améliorer les performances de prédiction.
Par rapport à d’autres frameworks liés au boosting, il présente les avantages suivants :
-
Entraînez-vous plus rapidement sans compromettre l’efficacité.
-
L'utilisation de la mémoire est également faible.
-
Il offre une meilleure précision.
-
Il prend en charge les méthodes d'apprentissage parallèles et GPU.
-
Il a la capacité de traiter des données à grande échelle.
chat boost
Le géant russe de la recherche Yandex a annoncé qu'il soumettrait CatBoost, une bibliothèque d'apprentissage automatique améliorant les gradients, à la communauté open source. Il est capable « d’enseigner » l’apprentissage automatique avec des données clairsemées. Surtout lorsqu'il n'y a pas de données sensorielles comme la vidéo, le texte, les images, CatBoost peut également fonctionner sur des données transactionnelles ou historiques.
Caractéristiques du catboost :
Peu ou pas besoin d'ajuster les paramètres, les paramètres par défaut fonctionnent très bien
Prise en charge des variables catégorielles
Prise en charge des GPU
Tutoriels liés à Catboost : https://edu.csdn.net/course/detail/30742
4. Vocabulaire de base du contrôle des risques
4.1 Interprétation du TAEG
: taux effectif annuel, taux effectif annuel, taux d'intérêt du calcul des intérêts composés annuels. taux d'intérêt nominal TAEG nominal, taux d'intérêt réel TAEG effectif.
4.2
Interprétation du RA : comptes clients, comptes clients courants.
4.3
Interprétation de la fraude à l'application : application contrefaite
4.4 Interprétation de la fraude à la transaction
: transaction frauduleuse
4.5
Interprétation du transfert de solde : compensation de solde, c'est-à-dire activité de remboursement par carte de crédit.
4.6
Interprétation de la collection : Collection. Selon le temps de collecte de l'utilisateur, de court à long, il est divisé en Collecte précoce (collecte précoce), Front end (collecte initiale), Gamme intermédiaire (collecte intermédiaire), Hot core (collecte ultérieure) Récupération ( recouvrement de créances douteuses/revenus de créances douteuses) Plusieurs étapes correspondent à des modalités et fréquences de recouvrement différentes.
4.7
Interprétation du DBR : taux de charge débitrice, taux d’endettement. En règle générale, les dettes non garanties globales du débiteur dans chaque canal ne doivent pas dépasser 22 fois son revenu mensuel moyen.
4.8
Interprétation de Acompte : paiement échelonné
4.9
Interprétation de IIP : provision pour créances douteuses
4.10
Interprétation de PIP : perte de valeur d'actifs
4.11 Interprétation NCL : perte de crédit nette, taux de perte nette. Le montant des créances irrécouvrables transférées dans la période en cours moins le recouvrement des créances irrécouvrables dans la période en cours constitue le montant de la perte nette.
4.12 Interprétation du montant du prêt
: montant total du prêt
4.13
Interprétation MOB : mois selon l'ancienneté comptable
Exemple : MOB0, date du prêt jusqu'à la fin du mois en cours. MOB1, le deuxième mois complet après le décaissement
4.14 Interprétation non-starter
: Clients malveillants en retard
4.15
Interprétation du prêt sur salaire : prêt sur salaire. Prêt de crédit non garanti, rapidité de prêt rapide, faible montant, court terme mais taux d'intérêt élevé. Des quotas faibles et des taux d’intérêt élevés sont des conditions nécessaires à ce modèle.
4.16
Interprétation de Revolving : crédit renouvelable. Tiqianle Credit Wallet offre aux utilisateurs des quotas renouvelables, correspondant à des quotas spéciaux pour l'esthétique médicale et l'éducation.
4.17 Interprétation du WO
: Radiation, transfert de créances douteuses, généralement en souffrance depuis plus de 6 périodes.
4.18 RA
Taux d'approbation de crédit AR = SUM (compte d'approbation de demande de prêt) / SUM (compte de demande)
4.19 DR
Taux par défaut DR = SUM (compte par défaut) / SUM (compte crédit utilisé)
4,20 DEC
Exposition au crédit EAD=SUM(C0+M1+M2+…+M6+)
4.2 Taux de conversion de 1 crédit
Taux de conversion de crédit = SOMME (compte de crédit utilisé) / SOMME (compte appliqué)
4.22 Taux de retard/taux de retard (débit en %)
Le calcul peut être divisé en deux méthodes : coïncidente et décalée. En plus du taux de décalage de chaque tranche, le taux de décalage au-dessus d'une tranche spécifique sera également observé. Pour des indicateurs tels que M2+lagged% et M4+lagged%, en prenant comme exemple M2+lagged%, le dénominateur est les créances d'il y a deux mois, et le numérateur est le montant en souffrance de M2 (y compris) qui n'a pas été transféré aux créances irrécouvrables ce mois-ci. Dans la gestion des risques du crédit à la consommation, M2 et M4 sont deux points d'observation importants. La raison en est que le client peut être trop occupé ou oublier de provoquer un retard de compte, mais après le recouvrement de M1, il tombe toujours au-dessus de M2, ce qui peut être confirmée comme une incapacité de paiement ou un défaut délibéré.
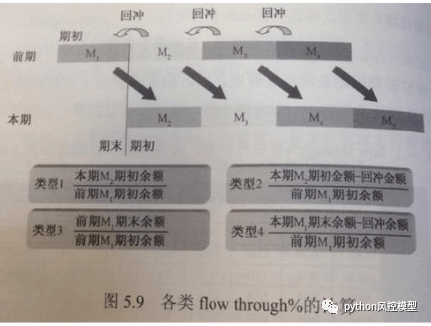
4,23**** Taux de défauts (mauvais %)
En plus de l'analyse générale des risques liés à l'application du mauvais, la construction du modèle de notation de crédit doit également prendre en compte la définition du mauvais.
Outre les comptes en souffrance et les comptes à haut risque, la définition générale des comptes irréguliers concerne principalement les comptes en souffrance.
4,24**** Taux de transfert des créances irrécouvrables (annulation%)
Il est abrégé en wo%, le montant des créances irrécouvrables transférées dans le mois en cours/comptes clients du mois de début en retard. Après annualisation, le taux mensuel des créances douteuses est converti en un taux de perte annuel.
4,2****5 Taux de sinistralité nette (NCL)
Elle se définit comme : le montant des créances irrécouvrables transférées dans la période en cours - le recouvrement des créances irrécouvrables dans la période en cours, qui est la notion de perte nette. Du point de vue de la performance globale de la gestion des risques, le recouvrement des créances douteuses constitue également un élément important, c'est pourquoi NCL% et WO% sont souvent affichés ensemble.
4.26 Taux de crédits
Également connu sous le nom de ratio allocation/prêt, il fait référence au ratio des provisions par rapport au total des prêts. Plus le ratio allocation/prêt est élevé, plus la capacité de la banque à se défendre contre les risques de créances irrécouvrables est forte. La formule de calcul est la suivante : solde des provisions/total des prêts = taux de couverture des provisions * taux des prêts non performants.
4.27 Taux de couverture des provisions
Également connu sous le nom de ratio d'adéquation des provisions, il s'agit en fait de la proportion de réserves de créances irrécouvrables pouvant apparaître dans les prêts bancaires. Le ratio de couverture des provisions est le rapport entre la provision réelle pour pertes sur prêts et les prêts non performants. Le meilleur ratio est de 100 % . La formule de calcul est la suivante : réserve pour pertes sur prêts/solde des prêts non performants.
4.28 Ratio des prêts non performants
Désigne le ratio des prêts non performants des institutions financières par rapport au solde total des prêts. Les prêts non performants signifient que lors de l'estimation de la qualité des prêts implicites, les prêts sont divisés en cinq catégories en fonction du risque : normal, mention spéciale, de qualité inférieure, douteux et perte, ces trois dernières catégories étant collectivement appelées prêts non performants. Formule de calcul : taux de créances douteuses = (prêts douteux + prêts douteux) / prêts divers * 100 % = taux de provisionnement des prêts / taux de couverture des provisions * 100 %. Le ratio de provisionnement des prêts, le ratio de prêts non performants et le ratio de couverture des provisions sont les trois indicateurs de base de la qualité des actifs du secteur bancaire commercial.
4.29 Ratio d’endettement (DBR)
Le ratio de charge débitrice (DBR) est le principal indicateur auquel les banques prêtent attention. Un indicateur courant pour mesurer le stress de remboursement d'un emprunteur est l'encours total de la dette non garantie (cartes de crédit, cartes de débit, marges de crédit)/revenu mensuel moyen.
4.30 Taux de retard malveillant (% de non-démarreur)
La définition originale est « les clients qui n'ont jamais payé après le prêt », et l'objectif principal est de détecter les cas de fraude brutale.
4,31 taux de réussite (%)
Il est utilisé dans les rapports de crédit intermédiaire et d'alerte précoce des cartes de crédit.Le soi-disant taux de réussite fait référence à la probabilité de retard du client dans un certain laps de temps après le contrôle. Un taux de réussite trop faible peut indiquer une inondation ou une mauvaise orientation du jugement sur les risques.
4.32 Solde disponible (OTB)
Il apparaît souvent avec l'indicateur du taux de réussite. La méthode de calcul consiste à rechercher d'abord les clients qui ont confirmé la réussite du contrôle, puis à ajuster le solde disponible de la carte de crédit de ces clients lorsqu'ils sont contrôlés. Ce chiffre peut être considéré comme le perte réduite de la banque due au contrôle.
4.33 Taux de recouvrement des créances irrécouvrables
Taux de recouvrement des créances douteuses de la période en cours = recouvrement des créances douteuses de la période en cours / montant transféré en créances douteuses de la période en cours
Taux de recouvrement total des créances douteuses de la période en cours = recouvrement des créances douteuses de la période en cours / solde total des créances douteuses de la période précédente
Taux de recouvrement des créances douteuses pour cette année = montant total du recouvrement des créances douteuses pour cette année / solde moyen des créances douteuses pour cette année
Taux de recouvrement des créances douteuses des 12 dernières périodes = montant total des créances douteuses recouvrées des 12 dernières périodes / solde moyen des créances douteuses des 12 dernières périodes
Le taux de recouvrement sur 12 périodes après cession de créances douteuses = le montant total de recouvrement des 12 périodes après cession de créances douteuses / la moyenne des créances douteuses des 12 périodes après cession de créances douteuses
équilibre

5. Dictionnaire de données
client_no : compte client
apply_time : heure de candidature
genre : sexe âge
: âge
revenue_range : fourchette de revenus
éducation : niveau d'éducation ;
carrière : travail ;
credit_score :
pointage de crédit ; credit_score_range : plage de
pointage de crédit ; : s'il est en retard ; used_time : durées d'utilisation du prêt ; credit_approved : montant du crédit approuvé
5. Modélisation du contrôle des risques financiers, étude de cas d'enseignement classique du combat réel
5.1 Ensemble de données sur le crédit allemand (crédit allemand)
5.2 La compétition de modèles Kaggle me donne un ensemble de données de crédit
5.3 Notation de crédit des entreprises d’investissement de la ville de Jiangsu
Tutoriels associés aux versions 5.1-5.3 : https://edu.csdn.net/course/detail/30611
5.4 Ensemble de données de crédit de la société américaine Fintech Lendingclub
5.5 Portraits de consommateurs : notation de crédit intelligente
Organisateur Bureau du Groupe leader de la construction numérique de la province du Fujian, Département provincial de l'industrie et des technologies de l'information du Fujian, Gouvernement populaire municipal de Fuzhou et Institut de recherche sur le développement de l'industrie de l'information électronique de Chine, Institut de recherche numérique de Chine et Fonds d'investissement Internet de Chine
Tutoriels associés aux versions 5.4-5.5 : https://edu.csdn.net/course/detail/30742
6. Sites Web de collecte d'informations financières
6.1 économie commerciale****
Le site officiel https://tradingnomics.com/ contient des centaines d'indicateurs économiques du monde entier, notamment le PIB, l'IPC, l'IPP, le taux d'endettement, l'indice des prix des matières premières, etc.
6.2 Données économiques du FRED
Site officiel https://fred.stlouisfed.org/, requête de données financières
6.3 Banque du Japon
https://www.boj.or.jp/
6.4 base de données sur le vent
Site officiel : https://www.wind.com.cn/Default.html, base de données du secteur financier CICC
6.5 Or papier
Requête sur le prix de l'or et le volume des transactions, téléchargement de données spécifiques http://www.zhijinwang.com/etf/
6.6 Analyse de l’opinion publique sur les marchés boursiers et obligataires et sites Web liés à l’alerte précoce
Vent (https://www.wind.com.cn/)
Réseau East Money (https://www.eastmoney.com/)
Données Hexun (http://data.hexun.com/)
Bloomberg (https://www.bloomberg.net/)
6.7 Enquête anti-blanchiment d'argent
GAFIhttp://www.fatf-gafi.org/
Groupe d'action financière sur le blanchiment d'argent. Organisation internationale intergouvernementale créée à Paris en 1989 par sept pays occidentaux pour étudier les dangers du blanchiment d'argent, prévenir le blanchiment d'argent et coordonner les actions internationales contre le blanchiment d'argent. L'une des plus grandes organisations internationales au monde. Comprenant actuellement 36 juridictions membres et 2 organisations régionales, représentant la plupart des grands centres financiers du monde. Ses quarante recommandations sur la lutte contre le blanchiment d'argent et ses neuf recommandations spéciales sur la lutte contre le financement du terrorisme (appelées recommandations 40+9 du GAFI) sont les documents les plus faisant autorité en matière de lutte contre le blanchiment d'argent et le financement du terrorisme dans le monde.
6.8 Extraction intelligente des informations sur les annonces financières de l'entreprise pour aider les gestionnaires de comptes bancaires dans le marketing
Réseau d'information Juchao (http://www.cninfo.com.cn/new/index)
L'Almanach du banquier (https://accuity.com/)
Dow Jones (https://www.dowjones.com/)
Déclaration de droit d'auteur : L'article provient du compte officiel (modèle de contrôle des risques python), sans autorisation, le plagiat n'est pas autorisé. Conformément à l'accord de droits d'auteur CC 4.0 BY-SA, veuillez joindre le lien source original et cette déclaration pour la réimpression.