Leere Textinvertierung bearbeiteter realer Bilder mithilfe eines geführten Diffusionsmodells
Code-Links: https://null-textinversion.github.io/.
Abstrakt
In diesem Artikel stellen wir eine genaue Inversionstechnik vor, die eine intuitive textbasierte Bildmodifikation ermöglicht.
Unsere vorgeschlagene Umkehrung enthält zwei neue Schlüsselkomponenten:
- (i) Schlüsselinversion des Diffusionsmodells. Wir verwenden für jeden Zeitstempel einen einzelnen Schlüsselrauschvektor und optimieren ihn entsprechend. Wir zeigen, dass die direkte Inversion allein nicht ausreicht, aber einen guten Anker für unsere Optimierung darstellt.
- (ii) Leere Textoptimierung: Wir ändern nur die bedingungslosen Texteinbettungen für klassifikatorloses Bootstrapping, nicht die Eingabetexteinbettungen. Dadurch können Modellgewichtungen und bedingte Einbettungen konstant gehalten werden, sodass hinweisbasierte Änderungen vorgenommen werden können und gleichzeitig eine mühsame Abstimmung der Modellgewichte vermieden wird.
Erzielte Ergebnisse: Umfangreiche Auswertungen werden an einer Vielzahl von Bild- und Cue-Bearbeitungen durchgeführt und zeigen hochauflösende Bearbeitungen an echten Bildern.
Einführung
In diesem Artikel stellen wir ein effizientes Inversionsschema vor, das nahezu perfekte Rekonstruktionen erreicht und gleichzeitig die Rich-Text-gesteuerten Bearbeitungsmöglichkeiten des Originalmodells beibehält (siehe Abbildung 1). Unser Ansatz basiert auf der Analyse von zwei Schlüsselaspekten geführter Diffusionsmodelle: klassifikatorfreie Führung und DDIM-Inversion.
Nach unserem besten Wissen ist unsere Methode die erste, die die Textbearbeitungstechnik „Prompt-to-Prompt“ [16] für echte Bilder ermöglicht. Darüber hinaus passen wir im Gegensatz zu neueren Methoden [19, 39] die Modellgewichte nicht an und vermeiden so die Zerstörung der Priors des trainierten Modells und die Replikation des gesamten Modells für jedes Bild. Durch umfassende Ablationsstudien und Vergleiche demonstrieren wir den Beitrag unserer Schlüsselkomponenten zur Erzielung einer hochauflösenden Rekonstruktion eines bestimmten realen Bildes und ermöglichen gleichzeitig aussagekräftige und intuitive Bearbeitungsmöglichkeiten.
Methode
Rahmen
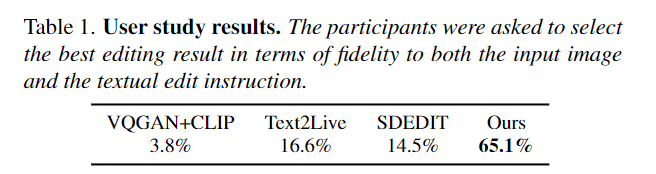
- Erste Reihe: Tastenumkehr. Wir wenden zunächst eine anfängliche DDIM-Inversion auf das Eingabebild an und schätzen die Diffusionsbahn. Der Beginn des Diffusionsprozesses beim letzten latenten z*T führt zu einer unbefriedigenden Rekonstruktion, da sich der latente Code immer weiter von der ursprünglichen Flugbahn entfernt.
- Wir verwenden die anfängliche Trajektorie als Dreh- und Angelpunkt für die Optimierung, um die Diffusionsumkehrtrajektorie {*zt}T1 näher an die ursprüngliche Bildkodierung z*0 heranzuführen.
- Zweite Zeile: Leertextoptimierung für Zeitstempel t. Das klassifikatorfreie Bootstrapping besteht aus der Durchführung von zwei Vorhersagen θ – bedingt unter Verwendung von Texteinbettungen und bedingungslos unter Verwendung von leeren Texteinbettungen ∅, und diese werden dann mit der Anleitung von w (Mitte) extrapoliert.
- Wir optimieren die unbedingte Einbettung ∅t nur, indem wir den rekonstruierten MSE-Verlust (rot) verwenden.
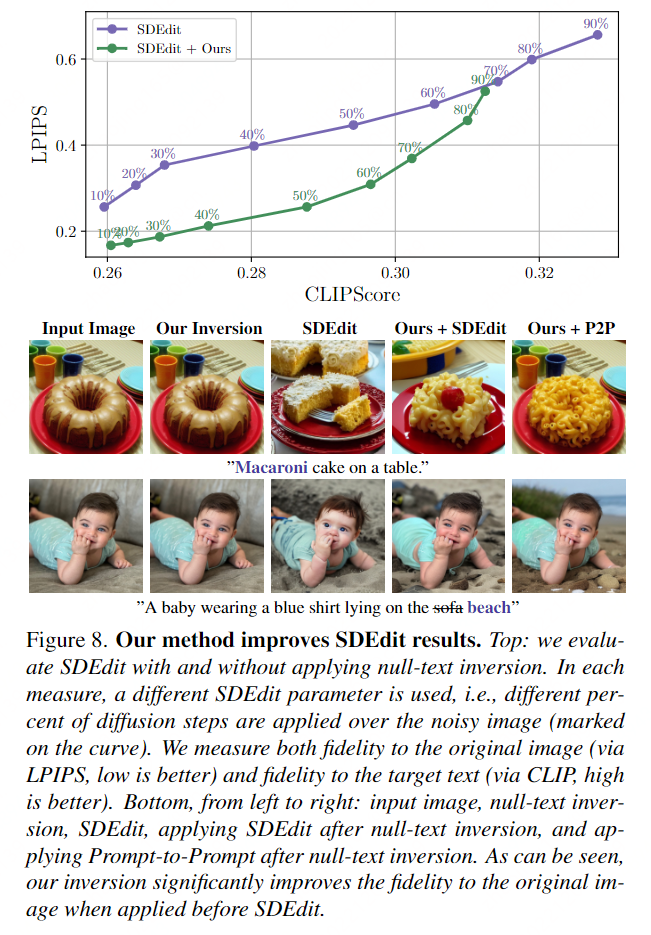
Bearbeiten Sie echte Bilder mit unserer Methode.

- Wir wenden zunächst eine Leertextinvertierung auf reale Eingabebilder an, um eine High-Fidelity-Rekonstruktion zu ermöglichen.
- Anschließend wenden Sie verschiedene Eingabeaufforderungs-basierte Textbearbeitungsvorgänge an.
- Es ist ersichtlich, dass unser Inversionsschema eine hohe Wiedergabetreue bietet und gleichzeitig eine hohe Bearbeitbarkeit beibehält. Weitere Beispiele finden Sie in Anhang C (Abbildung 10).
Unser Ansatz basiert auf zwei Hauptbeobachtungen:
- Die DDIM-Inversion funktioniert bei der Rekonstruktion nicht gut, wenn eine klassifikatorlose Führung angewendet wird, bietet jedoch einen guten Ausgangspunkt für die Optimierung, sodass wir eine Inversion mit hoher Wiedergabetreue effizient erreichen können.
- Zweitens sind bedingungslose leere Einbettungen für klassifikatorloses Bootstrapping optimiert, was eine genaue Rekonstruktion ermöglicht und gleichzeitig Modell- und bedingte Einbettungsoptimierungen vermeidet.
3.1 Hintergrund und Vorbemerkungen
Das textgesteuerte Diffusionsmodell zielt darauf ab, einen zufälligen Rauschvektor zt und eine Textbedingung P auf ein Ausgabebild z0 abzubilden, das einer gegebenen bedingten Eingabeaufforderung entspricht. Um eine Sequenzentrauschung zu erreichen, wird das Netzwerk εθ darauf trainiert, künstliches Rauschen vorherzusagen, wobei das Ziel verfolgt wird:
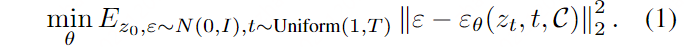
wobei , 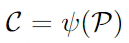
die textbedingte Einbettung ist.
Zum Zeitpunkt der Schlussfolgerung: Verwenden Sie bei einem gegebenen Rauschvektor zT unser trainiertes T-Schritt-Netzwerk, um das Rauschen kontinuierlich vorherzusagen und dadurch das Rauschen schrittweise zu entfernen.
Verwendung der deterministischen DDIM-Stichprobe [35]:

Diffusionsmodelle arbeiten typischerweise im Bildpixelraum, wobei z0 ein Beispiel des realen Bildes ist.
Wir verwenden das beliebte und veröffentlichte stabile Diffusionsmodell [30], bei dem der Diffusionsvorwärtsprozess auf die Kodierung des latenten Bildes z0 = E(x0) angewendet wird und der Bilddecoder am Ende des Diffusionsrückwärtsprozesses x0 = D( z0).
Klassifizierungsfreie Anleitung.
Formaler sei ∅ = ψ("") der Einbettungswert des leeren Textes und sei w der Bootstrap-Skalenparameter, dann ist die klassifikatorfreie Bootstrap-Vorhersage wie folgt definiert:
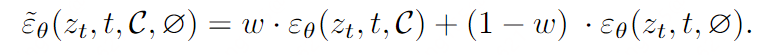
KEINE Umkehrung
Der ODE-Prozess kann innerhalb der Beschränkung kleiner Schritte umgekehrt werden:
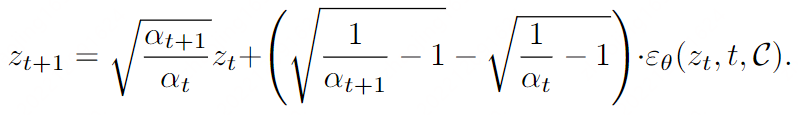
Mit anderen Worten, der Diffusionsprozess verläuft in die entgegengesetzte Richtung, d. h. z0→zT statt zT→z0, wobei z0 so eingestellt ist, dass es für ein gegebenes reales Bild kodiert.
3.2 Pivotale Inversion
Unser Ziel ist insbesondere die Optimierung um einen kritischen Rauschvektor herum , der eine gute Näherung darstellt und somit eine effizientere Inversion ermöglicht.
Wir nehmen diese anfängliche DDIM-Inversion mit w = 1 als unsere Pivot-Trajektorie
Unsere Optimierung maximiert die Ähnlichkeit mit dem Originalbild und behält gleichzeitig unsere Fähigkeit bei, sinnvolle Bearbeitungen vorzunehmen.
In der Praxis führen wir für jeden Zeitstempel t eine separate Optimierung in der Reihenfolge des Diffusionsprozesses t = t → t = 1 durch, mit dem Ziel, so nah wie möglich an die anfängliche Trajektorie z*t,...,z*0 zu kommen:
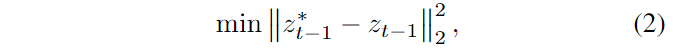
Wobei zt - 1 das Zwischenergebnis der Optimierung ist.
3.3. Nulltextoptimierung
Wir nutzen Schlüsselfunktionen, die nicht von Klassifikatoren geleitet werden – die Ergebnisse werden stark von bedingungslosen Vorhersagen beeinflusst. Daher ersetzen wir die standardmäßige Nulltext-Einbettung durch eine optimierte, sogenannte Nulltext-Optimierung. Das heißt, wir optimieren für jedes Eingabebild nur die bedingungslose Einbettung ∅ und initialisieren sie mit einer leeren Texteinbettung. Modell- und bedingte Texteinbettungen bleiben unverändert.
Wir bezeichnen die Optimierung einer einzelnen bedingungslosen Einbettung ∅ als globale Leertextoptimierung.
Für jeden Zeitschritt Optimierung:
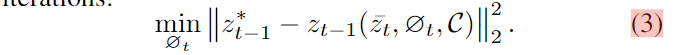
Aktualisierungsregel:


Experimente
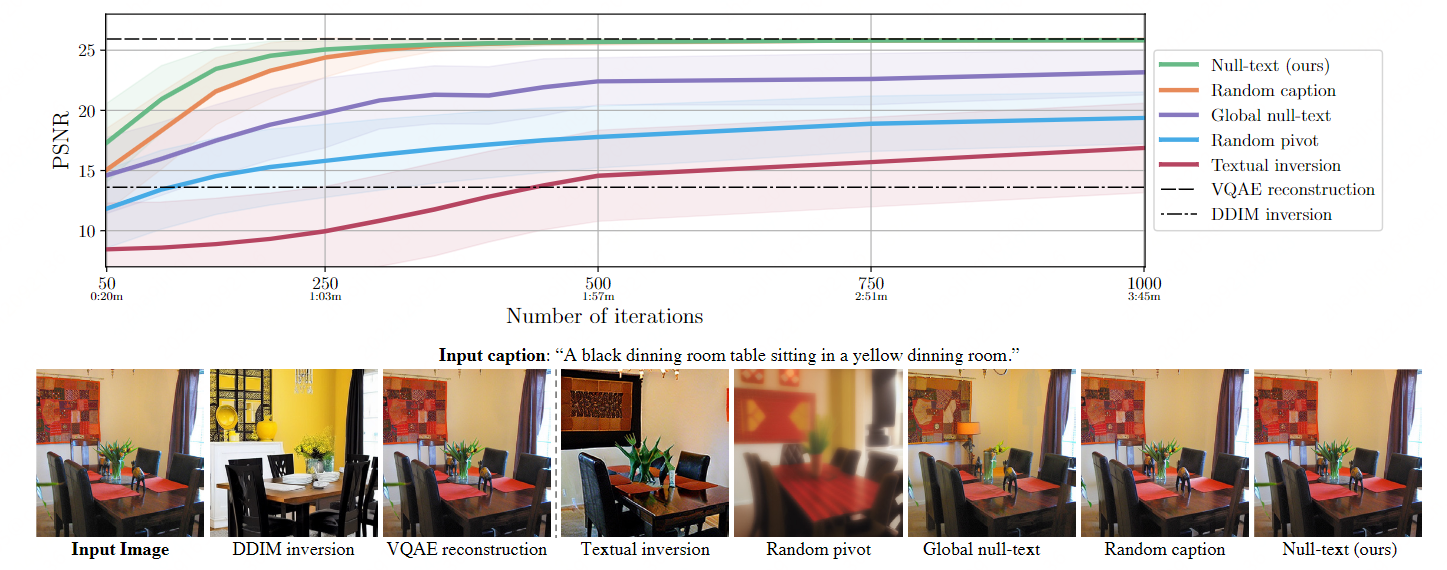
- Oben: Wir vergleichen die Leistung unseres vollständigen Algorithmus (grüne Linie) mit verschiedenen Varianten und bewerten die Rekonstruktionsqualität, indem wir den PSNR-Score als Funktion der Anzahl der Optimierungsiterationen und der Laufzeit in Minuten messen.
- Unten: Wir zeigen visuell die Inversionsergebnisse unseres vollständigen Algorithmus nach 200 Iterationen (rechts) im Vergleich zu anderen Basislinien. Die Ergebnisse aller Iterationen sind in Anhang B (Abbildungen 13 und 14) dargestellt.