Préface
Utilisation environnementale
- Interpréteur Python 3.8
- Éditeur PyCharm
modules requis
import parsel >>> pip install parsel
import requests >>> pip install requests
import csv
1. Analyse de la source de données :
1. Exigences claires :
Quel est le site Web collecté ?
https://movie.douban.com/subject/35267208/comments?limit=20&status=P&sort=new_score
-
Quelles données sont collectées ?
Examiner les données pertinentes2. Sources de données liées à la capture et à l'analyse des paquets :
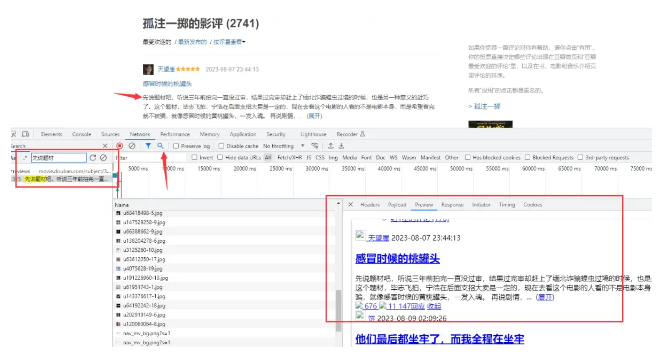
capturez et analysez les paquets via les propres outils de développement du navigateur <Points clés> -
Ouvrez les outils de développement : F12 ou faites un clic droit et cochez pour sélectionner le réseau
-
Actualiser la page Web : laissez le contenu des données de cette page Web être rechargé
-
Recherche par mot-clé : utilisez le mot-clé <données requises> pour rechercher le paquet de données correspondant.
https://movie.douban.com/subject/35267208/comments?limit=20&status=P&sort=new_score
2. Étapes de mise en œuvre du code : quatre étapes de base --> envoyer une demande, obtenir des données, analyser les données, enregistrer des données
- Envoyer une requête, simuler le navigateur envoyant une requête à l'adresse URL
https://movie.douban.com/subject/35267208/comments?limit=20&status=P&sort=new_score
-
Obtenir des données, obtenir les données de réponse renvoyées par le serveur
Outils de développement --> réponse -
Analyser les données, extraire le contenu des données souhaité
et commenter les données pertinentes -
Enregistrez les données et enregistrez le contenu des données dans le fichier de table
Acquisition de données de commentaires
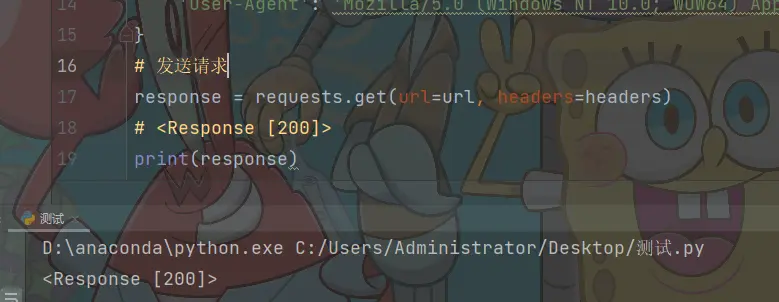
Envoyer une requête, simuler le navigateur envoyant une requête à l'adresse URL
Renvoyer <Response [200]> signifie que la demande est réussie
# 请求链接
url = f'https://movie.douban.com/subject/35267224/comments?start=20&limit=20&status=P&sort=new_score'
# 伪装模拟
headers = {
# User-Agent 用户代理, 表示浏览器基本身份标识
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, headers=headers)
print(response)
Données analytiques
Méthode d'analyse :
- Regular re -> Analyser directement les données de chaîne
- sélecteur CSS -> extraire les données en fonction des attributs de la balise
- extraction de nœud XPath -> extraire les données en fonction des nœuds d'étiquette
Convertissez les données de chaîne HTML obtenues <response.text> en un objet analysable
Extraire des données spécifiques content.comment
-info a --> Localiser la balise a a::text sous le nom de la classe comment-info --> Extraire le texte dans la balise a
get() --> Obtenir la première balise content
attr( ) --> Extraire les attributs
selector = parsel.Selector(response.text)
# 第一次提取, 所有div标签
divs = selector.css('div.comment-item')
# for循环遍历, 把列表里面元素一个一个提取出来
for div in divs:
name = div.css('.comment-info a::text').get() # 昵称
rating = div.css('.rating::attr(title)').get() # 推荐
date = div.css('.comment-time::attr(title)').get() # 时间
area = div.css('.comment-location::text').get() # 地区
votes = div.css('.votes::text').get() # 有用
short = div.css('.short::text').get().replace('\n', '') # 评论
# 数据存字典里面
dit = {
'昵称': name,
'推荐': rating,
'时间': date,
'地区': area,
'有用': votes,
'评论': short,
}
# 写入数据
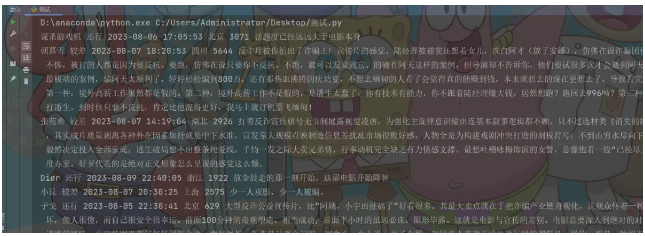
print(name, rating, date, area, votes, short)
enregistrer des données
data.csv -> Mode nom de fichier
= a -> Méthode d'enregistrement avec encodage
= 'utf-8' -> Format d'encodage
nouvelle ligne -> Caractère de nouvelle ligne
f -> Objet fichier
f = open('data10.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'昵称',
'推荐',
'时间',
'地区',
'有用',
'评论',
])
# 写入表头
csv_writer.writeheader()
Analyser les données des avis
Module d'importation
import pandas as pd
import jieba
import wordcloud
Lire des données
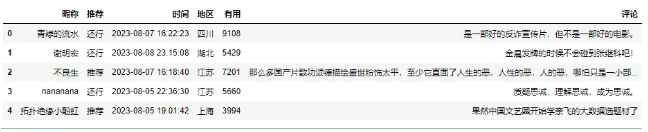
df = pd.read_csv('data10.csv')
df.head()
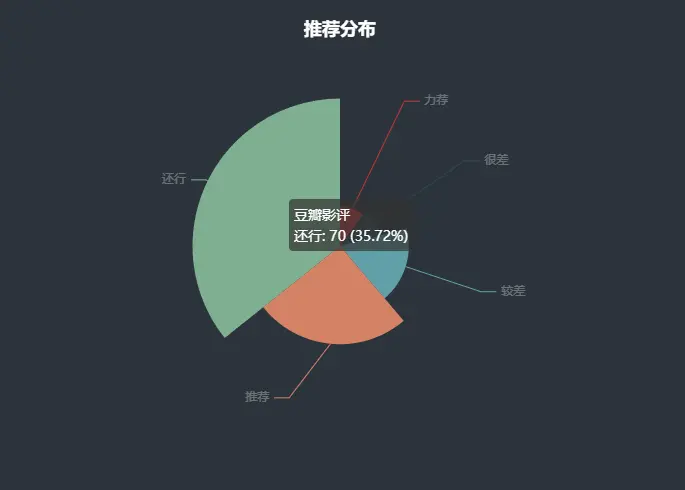
Répartition recommandée
import pyecharts.options as opts
from pyecharts.charts import Pie
data_pair = [list(z) for z in zip(evaluate_type, evaluate_num)]
data_pair.sort(key=lambda x: x[1])
c = (
Pie(init_opts=opts.InitOpts(bg_color="#2c343c"))
.add(
series_name="豆瓣影评",
data_pair=data_pair,
rosetype="radius",
radius="55%",
center=["50%", "50%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="推荐分布",
pos_left="center",
pos_top="20",
title_textstyle_opts=opts.TextStyleOpts(color="#fff"),
),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)"),
)
)
c.render_notebook()
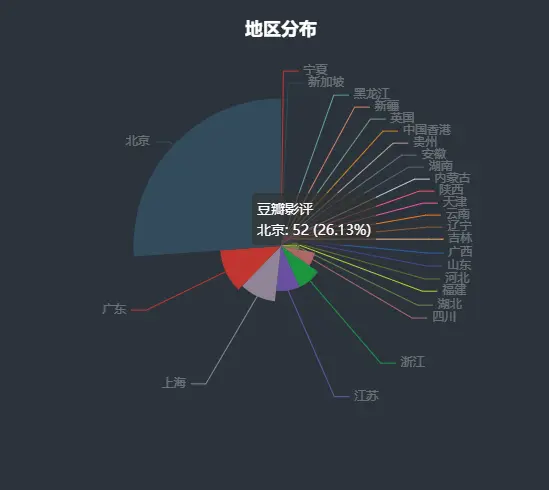
Distribution locale
import pyecharts.options as opts
from pyecharts.charts import Pie
data_pair = [list(z) for z in zip(area_type, area_num)]
data_pair.sort(key=lambda x: x[1])
d = (
Pie(init_opts=opts.InitOpts(bg_color="#2c343c"))
.add(
series_name="豆瓣影评",
data_pair=data_pair,
rosetype="radius",
radius="55%",
center=["50%", "50%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="地区分布",
pos_left="center",
pos_top="20",
title_textstyle_opts=opts.TextStyleOpts(color="#fff"),
),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)"),
)
)
d.render_notebook()
【2023|Enseignement du système de paiement VIP】Osez le téléchargement ! 80 épisodes de cours payants