Récupération d'image-texte : une enquête sur la recherche et le développement récents
Revue des progrès de la recherche sur la récupération d'image-texte
2022.03
Cet article a remplacé les citations de la littérature par les titres d'articles correspondants un par un pour faciliter la recherche et la lecture.
Résumé
Cet article fournit une étude complète et à jour des méthodes ITR sous quatre aspects. En disséquant le système ITR en deux processus : l'extraction de fonctionnalités et l'alignement de fonctionnalités , nous résumons les progrès récents des méthodes ITR sous ces deux perspectives. Sur cette base, l’ étude de l’efficacité des systèmes ITR est présentée comme troisième perspective. Afin de suivre le rythme de notre temps, nous fournissons également un aperçu révolutionnaire de la méthode ITR pré-entraînée multimodale du quatrième point de vue . Enfin, nous fournissons un aperçu des ensembles de données de référence et des mesures d’évaluation courantes pour l’ITR et effectuons une comparaison de précision des méthodes ITR représentatives. L’article se termine par une discussion de certaines questions critiques mais peu étudiées.
1. Introduction
La récupération d'image en texte multimodale (ITR) consiste à récupérer des échantillons pertinents d'une autre modalité en fonction de l'expression d'un utilisateur donné dans une modalité, et comprend généralement deux sous-tâches : image en texte (i2t) et texte-Image. (t2i) récupération. L'ITR a de larges perspectives d'application dans le domaine de la recherche et constitue un sujet de recherche précieux. Au cours des dernières années, nous avons été témoins de l’énorme succès d’ITR en raison de l’essor des modèles profonds de langage et de vision. Par exemple, avec l'essor du BERT, le paradigme de pré-formation intermodale basé sur le transformateur a été développé et sa forme de pré-formation et de réglage fin a été étendue aux tâches ITR en aval, accélérant ainsi son développement.
Limites des revues précédentes : 1) En plus des tâches ITR, d'autres tâches multimodales telles que la récupération de texte vidéo et la réponse visuelle aux questions ont également été explorées, ce qui a donné lieu à des investigations moins approfondies de l'ITR ; 2) Les paradigmes de pré-formation sont essentiellement absent dans les revues existantes a été développé et il est effectivement courant aujourd’hui. Compte tenu de cela, nous présentons dans cet article une étude complète et de pointe sur les tâches ITR, en particulier un aperçu des paradigmes de pré-formation.
Un système ITR comprend généralement le processus d'extraction de fonctionnalités de la branche de traitement d'image/texte et le processus d'alignement de fonctionnalités du module d'intégration. Dans le contexte d'un tel système ITR, nous construisons une taxonomie sous quatre perspectives pour décrire les méthodes ITR. La figure 1 montre le squelette de classification de la méthode ITR.
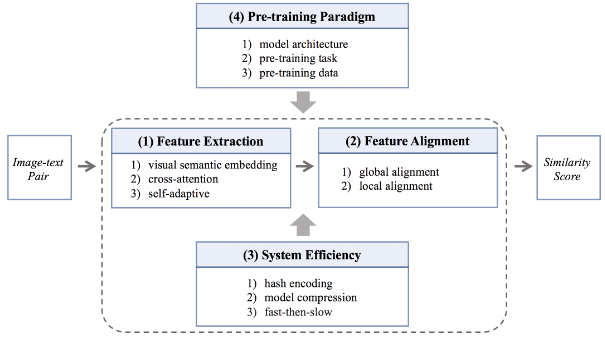
Figure 1 : Squelette de classification illustrant la méthode ITR sous quatre perspectives
(1) Extraction de fonctionnalités . Les méthodes existantes pour extraire des caractéristiques d'image et de texte robustes et discriminantes se répartissent en trois catégories. 1) Les méthodes basées sur l'intégration sémantique visuelle s'engagent à apprendre les fonctionnalités de manière indépendante. 2) En revanche, la méthode d’attention croisée apprend les fonctionnalités de manière interactive. 3) Les méthodes adaptatives visent à apprendre des fonctionnalités dans une modalité adaptative.
(2) Alignement des fonctionnalités . L'hétérogénéité des données multimodales rend le module d'intégration très important pour l'alignement des fonctionnalités d'image et de texte. Il existe deux variantes de la méthode existante. 1) La méthode basée sur l'alignement global aligne les caractéristiques globales entre chaque modalité. 2) En plus de cela, certaines méthodes tentent de trouver explicitement un alignement local à un niveau plus fin, ce qu'on appelle les méthodes impliquant un alignement local.
(3) Efficacité du système . L’efficacité joue un rôle essentiel dans un bon système ITR. En plus des recherches visant à améliorer la précision de l'ITR, une série de travaux étudient des systèmes de récupération efficaces de trois manières différentes. 1) La méthode de codage par hachage réduit les coûts de calcul en binarisant les fonctionnalités au format à virgule flottante. 2) La méthode de compression du modèle met l'accent sur une faible consommation d'énergie et un fonctionnement léger. 3) La méthode rapide d'abord puis lente effectue la récupération d'abord par une récupération rapide à gros grains, puis par une récupération lente à grains fins.
(4) Paradigme de pré-formation . Afin de rester à la pointe du développement de la recherche, nous avons également mené des recherches approfondies sur les méthodes de pré-formation intermodales pour les tâches ITR qui ont récemment attiré beaucoup d'attention. Par rapport à l'ITR traditionnel, les méthodes ITR pré-entraînées peuvent bénéficier de la richesse des connaissances implicites dans les modèles pré-entraînés intermodaux à grande échelle et peuvent produire des performances encourageantes même sans ingénierie de récupération complexe. Dans le contexte des tâches ITR, les méthodes de pré-formation multimodales sont toujours appliquées aux trois taxonomies prospectives ci-dessus. Cependant, afin de décrire plus clairement les caractéristiques des méthodes ITR de pré-formation, nous les reclassons à partir de trois dimensions : structure du modèle, tâches de pré-formation et données de pré-formation .
Ensuite, nous résumerons les méthodes ITR basées sur la taxonomie mentionnée ci-dessus des trois premières perspectives dans la deuxième section, et mentionnerons spécifiquement la méthode ITR de pré-formation, la quatrième perspective, dans la troisième section. La section 4 détaille les comparaisons de précision entre les ensembles de données communs, les mesures d'évaluation et les méthodes représentatives, puis donne les conclusions et les travaux futurs dans la section 5.
2. Récupération image-texte
2.1 Extraction de fonctionnalités
L'extraction de caractéristiques d'image et de texte est le premier et le plus critique processus dans un système ITR. Comme le montre la figure 2, sous les trois tendances de développement différentes que sont l'intégration sémantique visuelle, l'attention croisée et l'adaptation , la technologie d'extraction de fonctionnalités d'ITR est en plein essor.
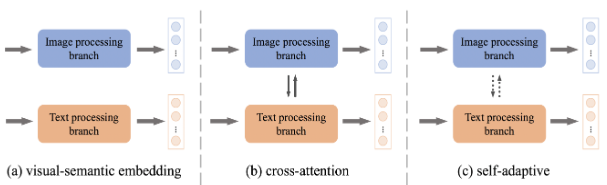
Figure 2 : Illustration de différentes architectures d'extraction de fonctionnalités
Incorporation sémantique visuelle (VSE) . L’encodage indépendant des fonctionnalités d’image et de texte est une manière intuitive et simple d’ITR. Cette méthode basée sur le VSE a été largement développée et comporte grossièrement deux aspects.
1) En termes de données, une série de travaux [Learning fragment self-attention embeddings for image-text matching. Dans ACM MM, 2019 ; Probabilistic embeddings for cross-modal retrieval. Dans CVPR, 2021] tentent d'exploiter des données d'ordre élevé. informations pour l'apprentissage de fonctionnalités puissantes. Ils traitent toutes les paires de données de la même manière lors de l’apprentissage des fonctionnalités. En revanche, certains chercheurs [Vse++ : Improving visual-semantic embeddings with hard negatifs. Dans BMVC, 2017] ont proposé de pondérer les paires de données avec une grande quantité d'informations pour améliorer la reconnaissance des caractéristiques, et certains chercheurs [Apprentissage de la récupération multimodale avec des étiquettes bruitées". CVPR, 2021] accorde plus d'attention à la correspondance de bruit non adaptée dans les paires de données pour l'extraction de caractéristiques. Récemment, surfant sur la tendance de la technologie de pré-formation multimodale à grande échelle, certains travaux [Scaling up visual and vision-langage représentation learning with noise text su-pervision. InICML, 2021 ; Wenlan : Bridging vision and language by large- pré-formation multimodale à grande échelle, 2021] utilisent directement des données réseau à grande échelle pour pré-entraîner les extracteurs de fonctionnalités d'images et de texte, montrant des performances impressionnantes dans les tâches ITR en aval.
2) Concernant la fonction de perte, la perte de classement est souvent utilisée dans les méthodes basées sur VSE [modèle d'intégration visuel-sémantique profond. InNeurIPS, 2013 ; Vse++ : Improving visual-semantic embeddings with hard négatifs. In BMVC, 2017], et contraint le modèle des fonctionnalités d'apprentissage.Relations de données entre les états. En plus de cela, [Apprentissage des réseaux neuronaux à deux branches pour les tâches de correspondance image-texte. Dans TPAMI, 2018.] propose une perte de classement marginale maximale avec des contraintes de voisinage pour une meilleure extraction des caractéristiques. [Incorporations image-texte convolutives Dualpath avec perte d'instance. Dans TOMM, 2020.] proposent une perte d'instance qui prend explicitement en compte la distribution de données intra-modale.
Grâce au codage indépendant des caractéristiques, la méthode basée sur VSE implémente un système ITR efficace dans lequel les caractéristiques d'un grand nombre d'échantillons de galerie peuvent être précalculées hors ligne. Cependant, il peut apporter des fonctionnalités sous-optimales et des performances ITR limitées en raison d’une exploration moindre de l’interaction entre les données image et texte.
Attention croisée (CA) . [Attention croisée empilée pour la correspondance image-texte. Dans ECCV, 2018] était la première tentative de considérer des interactions intermodales denses par paires et a produit d'énormes améliorations de précision à l'époque. Depuis, diverses méthodes d’AC ont été proposées pour extraire des fonctionnalités. Grâce à l'architecture du transformateur, les chercheurs peuvent simplement faire fonctionner l'architecture du transformateur sur la concaténation d'images et de texte pour apprendre les fonctionnalités contextuelles intermodales. Il ouvre une riche ligne de recherche sur les méthodes d'AC de type transformateur [Vilbert : Pretraining task-agnostic visiolin-guistic représentations for vision-and- Language Tasks. Dans NeurIPS, 2019 ; Uniter : Universal image-text Representative Learning. Dans ECCV, 2020 ]. De plus, l’injection de contenu ou d’opérations supplémentaires dans l’attention croisée pour faciliter l’extraction de fonctionnalités constitue également une nouvelle direction de recherche. [Réseau d'attention guidé par la saillance pour la correspondance image-phrase. Dans ICCV, 2019] adopte un module de détection de la saillance visuelle pour guider l'association intermodale. [Rosita : Améliorer les alignements sémantiques de la vision et du langage via l'intégration des connaissances intermodales et intramodales. Dans ACM MM, 2021] intègre les connaissances intramodales et intermodales pour apprendre conjointement les fonctionnalités d'image et de texte.
Les méthodes d'AC réduisent l'écart d'hétérogénéité des données et ont tendance à obtenir des résultats de récupération de haute précision, mais sont d'un coût prohibitif puisque chaque paire image-texte doit être saisie en ligne dans le module d'attention croisée.
Adaptatif (SA) . Dans les méthodes basées sur VSE et CA, il n'y a pas de processus de calcul fixe pour extraire les caractéristiques. [Modélisation d'interaction de modalité dynamique pour la récupération image-texte. Dans SIGIR, 2021] construit un réseau d'interaction de modalité adaptative à partir de zéro, dans lequel différentes paires de peuvent être entré de manière adaptative dans différents mécanismes d’extraction de fonctionnalités. Elle hérite effectivement des avantages respectifs des deux groupes de méthodes ci-dessus et est classée comme méthode SA.
2.2 Alignement des fonctionnalités
Après l'extraction des caractéristiques, les caractéristiques entre états doivent être alignées pour calculer la similarité par paire et réaliser la récupération. L'alignement global et l'alignement local sont deux directions.
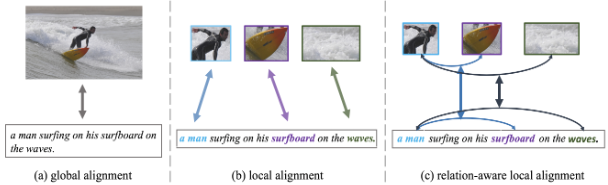
Figure 3 : Illustration de différentes architectures d'alignement de fonctionnalités
Alignement global . Dans l'approche basée sur l'alignement global, les images et le texte sont mis en correspondance dans une perspective globale, comme le montre la figure 3(a). Les premiers travaux [Vse++ : Improving visual-semantic embeddings with hard négatifs. Dans BMVC, 2017 ; Learning two-branch neural Networks for image-text matching materials. Dans TPAMI, 2018] sont généralement équipés d'une fonctionnalité globale à deux flux claire et simple. réseau d'apprentissage, la similarité par paire est calculée par comparaison entre les caractéristiques globales. Des recherches ultérieures [Apprentissage de la représentation contradictoire pour la correspondance texte-image. Dans ICCV, 2019 ; Intégrations image-texte convolutives à double chemin avec perte d'instance. Dans TOMM, 2020] se sont concentrées sur l'amélioration de cette structure de réseau à double flux pour mieux aligner les fonctionnalités globales. . Cependant, les méthodes d'alignement global uniquement mentionnées ci-dessus présentent toujours des performances limitées car les descriptions de texte contiennent généralement des détails plus fins de l'image, qui sont facilement lissés par l'alignement global . Cependant, il existe une exception. Les méthodes récentes d'alignement global dans le paradigme de pré-entraînement et de réglage fin [Scaling up visual and vision-langage représentation learning with noise text supervision. In ICML, 2021] tendent à produire des résultats satisfaisants, attribués à la petite taille des données de pré-entraînement.
En résumé, l’application d’un alignement global uniquement aux ITR peut conduire à des insuffisances dans les modèles de correspondance à granularité fine et est relativement faible pour calculer des similarités fiables par paires. Compléter l’alignement global par un alignement dans d’autres dimensions est une solution.
Alignement local . Comme le montre la figure 3 (b), les régions ou patchs de l'image correspondent aux mots de la phrase, ce qu'on appelle l'alignement local. L'alignement global et l'alignement local constituent des solutions complémentaires à l'ITR, un choix populaire classé parmi les méthodes impliquant un alignement local.
Utilisation du mécanisme d'attention vanille [Attention croisée empilée pour la correspondance image-texte. Dans ECCV, 2018 ; Camp : transmission de messages adaptatifs multimodaux pour la récupération texte-image. Dans ICCV, 2019 ; Uniter : Apprentissage universel de la représentation image-texte. Dans ECCV, 2020;Vilt : Transformateur de vision et de langage sans convolution ni supervision de région. Dans ICML, 2021] est une méthode triviale pour explorer la correspondance région sémantique/mot de patch. Cependant, en raison de la complexité sémantique, ces méthodes peuvent ne pas capturer correctement les correspondances optimales à granularité fine. Premièrement, se concentrer sélectivement sur les composants locaux est une solution pour trouver un alignement local optimal. [Concentrez votre attention : un réseau d'attention focale bidirectionnelle pour la correspondance image-texte. Dans ACM MM, 2019] est la première tentative d'aligner sélectivement la sémantique locale de différentes modalités. [Imram : Correspondance itérative avec mémoire d'attention récurrente pour la récupération d'image-texte intermodale. Dans CVPR, 2020] et [Réseau d'attention contextuel pour la récupération d'image-texte. Dans CVPR, 2020] n’est pas loin derrière. Le premier apprend à associer des composants locaux à l’aide d’un schéma d’alignement local itératif. Ce dernier remarque qu'un objet ou un mot peut avoir une sémantique différente dans différents contextes globaux et propose de sélectionner de manière adaptative des composants locaux riches en informations pour un alignement local en fonction du contexte global. Depuis, certaines méthodes ayant les mêmes objectifs que ci-dessus ont été proposées, comme la conception d'une stratégie de masquage guidée par l'alignement [Kaleido-bert : Vision-langage pre-training on fashion domain. In CVPR, 2021] ou le développement d'une technologie de filtrage de l'attention. [Raisonnement de similarité et filtration pour la correspondance image-texte. Dans AAAI, 2021]. De plus, réaliser pleinement la correspondance locale est également un moyen de se rapprocher d’un alignement local optimal. [Incorporations visuelles et sémantiques unifiées : relier la vision et le langage avec des représentations de sens structurées. Dans CVPR, 2019] permet d'aligner différents niveaux de composants de texte sur les régions de l'image. [Réseau d'alignement hiérarchique par étapes pour la correspondance image-texte. Dans IJCAI, 2021] propose un réseau d'alignement hiérarchique par étapes qui réalise un alignement local à local, global à local et global à global. Relier la vision et le langage avec des représentations de sens structurées. Dans CVPR, 2019] permet d'aligner différents niveaux de composants de texte avec les régions de l'image. [Réseau d'alignement hiérarchique par étapes pour la correspondance image-texte. Dans IJCAI, 2021] propose un réseau d'alignement hiérarchique par étapes qui réalise un alignement local à local, global à local et global à global. Relier la vision et le langage avec des représentations de sens structurées. Dans CVPR, 2019] permet d'aligner différents niveaux de composants de texte avec les régions de l'image. [Réseau d'alignement hiérarchique par étapes pour la correspondance image-texte. Dans IJCAI, 2021] propose un réseau d'alignement hiérarchique par étapes qui réalise un alignement local à local, global à local et global à global.
En plus de cela, comme le montre la figure 3(c), il existe un autre type d'alignement local, à savoir l'alignement local prenant en compte les relations, qui peut favoriser un alignement plus fin. Ces méthodes [Probing inter-modality: Visual parsing with self-attention for vision-and-lingual pre-training. In NeurIPS, 2021 ; Multi-modality cross attention network for image and phrase matching. In CVPR, 2020] explorent l'intra-modalité. relations pour faciliter l’alignement entre les modalités. De plus, certaines méthodes [Raisonnement sémantique visuel pour la correspondance image-texte. Dans ICCV, 2019 ; Ernie-vil : Connaissance améliorée des représentations de langage de vision à travers un graphe de scène. Dans AAAI, 2021 ; Raisonnement de similarité et filtration pour la correspondance image-texte. Dans AAAI , 2021] modélise les données image/texte sous la forme d'une structure graphique, dont les bords transmettent des informations sur les relations et déduit des similitudes sensibles aux relations avec l'alignement local et global via des réseaux convolutifs graphiques. De plus, [Learning relation align for calibrated cross-modal retrieval. In ACL-IJCNLP, 2021] considère la cohérence des relations, c'est-à-dire la cohérence des relations visuelles entre les objets et des relations entre le texte.
2.3 Efficacité de la recherche
L'extraction de fonctionnalités dans la section 2.1 est combinée avec l'alignement des fonctionnalités dans la section 2.2 pour former un système ITR complet et se concentrer sur l'exactitude de la récupération. De plus, l’efficacité de la récupération est la clé pour obtenir un excellent système ITR, ce qui a conduit à une série de méthodes ITR axées sur l’efficacité.
Encodage de hachage . Le codage binaire de hachage présente des avantages en matière de calcul et de stockage de modèles, atténuant les inquiétudes croissantes concernant les méthodes de codage de hachage pour ITR. Ces études apprennent à cartographier les caractéristiques des échantillons dans un espace de codage de hachage compact pour obtenir un ITR efficace. [Une relation par paires a guidé le hachage profond pour la récupération multimodale. Dans AAAI, 2017] a simultanément appris les caractéristiques à valeur réelle et les caractéristiques de hachage binaire des images et des textes pour bénéficier les unes des autres. [Hachage contradictoire profond sensible à l'attention pour la récupération intermodale. Dans ECCV, 2018] introduit un module d'attention pour trouver des régions et des mots ciblés afin de promouvoir l'apprentissage des fonctionnalités binaires. En plus de ces méthodes dans des environnements supervisés, le hachage multimodal non supervisé est également au centre des préoccupations. [Réseaux de hachage contradictoires auto-supervisés pour la récupération multimodale. Dans CVPR, 2018] combine des réseaux contradictoires avec un hachage multimodal non supervisé pour maximiser la corrélation sémantique et la cohérence entre les deux modalités. [Réseau profond de préservation de la cohérence graphique-voisin pour le hachage multimodal non supervisé. Dans AAAI, 2021] a conçu un réseau de cohérence graphique-voisin pour explorer les informations voisines des échantillons pour un apprentissage par hachage non supervisé. La méthode de codage par hachage est bénéfique pour améliorer l’efficacité, mais elle entraînera également une diminution de la précision en raison de la représentation simplifiée des caractéristiques des codes binaires.
Compression du modèle . Avec l’avènement de l’ère de la pré-formation multimodale, ITR a fait un énorme bond en avant en termes de précision, mais au détriment de l’efficacité. Les méthodes ITR pré-entraînées sont souvent caractérisées par des structures de réseau volumineuses, ce qui donne lieu à des méthodes de compression de modèles. Certains chercheurs [Jouer aux billets de loterie avec vision et langage. Dans AAAI, 2022] ont introduit l'hypothèse des billets de loterie pour lutter vers une architecture de réseau plus petite et plus légère. De plus, sur la base du consensus selon lequel le processus de prétraitement de l'image occupe la principale consommation de ressources informatiques dans l'architecture de pré-formation, certains chercheurs [Pixel-bert : Aligningimage pixels with text by deep multi-modal transformers, 2020 ; Seeing out of the box : Pré-formation de bout en bout pour l'apprentissage de la représentation du langage visuel. InCVPR, 2021] optimise spécifiquement le processus de prétraitement des images pour améliorer l'efficacité de la récupération. Cependant, même avec des architectures légères, la plupart de ces méthodes, qui utilisent généralement une attention croisée pour un meilleur apprentissage des fonctionnalités, prennent encore un temps de référence long en raison de l'exécution secondaire de l'extraction des fonctionnalités.
D'abord rapide, puis lentement . Les deux groupes de méthodes ci-dessus ne peuvent pas atteindre le meilleur compromis entre efficacité et précision, c'est pourquoi un troisième groupe de méthodes est produit : une combinaison de méthodes rapides et lentes. Compte tenu des avantages d'efficacité et de précision des méthodes VSE et CA dans la section 2.1, certains chercheurs [Penser vite et lentement : Récupération efficace de texte en visuel avec des transformateurs. Dans CVPR, 2021 ; Aligner avant de fusionner : Vision et représentation du langage apprendre avec distillation d'impulsion. Dans NeurIPS, 2021] a proposé d'utiliser d'abord la technologie VSE rapide pour filtrer un grand nombre de bibliothèques négatives simples, puis d'utiliser la technologie CA lente pour récupérer les bibliothèques positives, afin d'obtenir un bon équilibre entre efficacité et précision. .
3. Récupération image-texte pré-entraînée
Pour les tâches ITR, le premier paradigme consistait à affiner les réseaux pré-entraînés respectivement dans les domaines de la vision par ordinateur et du traitement du langage naturel. Le tournant s'est produit en 2019 avec un intérêt accru pour le développement d'une modalité générale de pré-formation intermodale et son extension aux tâches ITR en aval [Vilbert : Pretraining task-agnostic visiolin-guistic représentations for vision-and-langage Tasks. InNeurIPS, 2019 ; Visualbert : Une baseline simple et performante pour la vision et le langage, 2019]. Grâce à la puissante technologie de pré-formation multimodale, l'exécution des tâches ITR a connu une croissance explosive sans aucune fonctionnalité sophistiquée. Actuellement, la plupart des méthodes ITR pré-entraînées adoptent l'architecture du transformateur comme élément de base. Sur cette base, la recherche se concentre principalement sur l'architecture des modèles, les tâches de pré-formation et les données de pré-formation.
Architecture modèle . Un groupe de travaux [Vilbert : Pretraining task-agnostic visiolin-guistic représentations for vision-and- Language Tasks. In NeurIPS, 2019 ; Align before fuse : Vision and Language Representative Learning with Momental distillation. In NeurIPS, 2021] s'intéressent au double -architecture de modèle de flux, c'est à dire deux encodages indépendants, suivis d'une post-interaction optionnelle sur les branches de traitement d'image et de texte. Dans le même temps, les architectures à flux unique qui encapsulent les branches de traitement d'image et de texte en une seule deviennent de plus en plus populaires [Visualbert : Une base de référence simple et performante pour la vision et le langage, 2019 ; Unicoder-vl : Un encodeur universel pour la vision et le langage par croisement -pré-formation modale. InAAAI, 2020 ; Vilt : Transformateur de vision et de langage sans con-volution ni supervision de région. InICML, 2021]. La plupart des méthodes s'appuient fortement sur des processus de prétraitement d'image, impliquant généralement des modules de détection d'objets ou des architectures convolutives, pour extraire des caractéristiques visuelles préliminaires et servir d'entrée aux transformateurs ultérieurs. Le problème qui en résulte est double. Premièrement, ce processus consomme plus de ressources informatiques que les processus ultérieurs, ce qui entraîne une inefficacité du modèle. Ensuite, le vocabulaire visuel prédéfini issu de la détection d’objets limite la capacité d’expression du modèle, entraînant une faible précision.
Il est encourageant de constater que la recherche visant à améliorer les procédures de prétraitement des images est récemment devenue populaire. En termes d'amélioration de l'efficacité, [Seeing out of the box : End-to-end pre-training for vision-langage représentation learning. InCVPR, 2021] adopte un dictionnaire visuel rapide pour apprendre les caractéristiques de l'image entière. [Pixel-bert : Alignement des pixels de l'image avec le texte par des transformateurs multimodaux profonds.2020] Alignez directement les pixels de l'image avec le texte dans le transformateur. De plus, [Vilt : Transformateur de vision et de langage sans supervision de convolution ou de région. InICML, 2021 ; Fashionbert : Correspondance de texte et d'image avec perte adaptative pour la récupération multimodale. Dans SIGIR, 2020] alimente les fonctionnalités au niveau des correctifs du image dans le transformateur , [Kd-vlp : Improving end-to-end vision-and-langage pretraining with object knowledge distillation. Dans EMNLP, 2021] segmentez l'image en grilles, alignées avec le texte. En termes d'amélioration de la précision, [Vinvl : Revisiter les représentations visuelles dans les modèles de langage de vision. Dans CVPR, 2021] a développé un modèle de détection d'objets amélioré pour améliorer les caractéristiques visuelles. [E2e-vlp : Pré-formation en langage visuel de bout en bout améliorée par l'apprentissage visuel. Dans ACL-IJCNLP, 2021] rassemblent les tâches de détection d’objets et de sous-titrage d’images pour améliorer l’apprentissage visuel. [Sonder l'intermodalité : analyse visuelle avec auto-attention pour la pré-formation en vision et en langage. Dans NeurIPS, 2021] Lors de l'apprentissage des caractéristiques de l'image, explorez les relations visuelles en adoptant un mécanisme d'auto-attention. En tenant compte de tout cela, [Une étude empirique sur la formation de transformateurs de vision et de langage de bout en bout.2021] étudie en profondeur ces conceptions de modèles et propose un nouveau cadre de transformateur de bout en bout qui atteint efficacité et précision. gagner. L'avancement de l'architecture du modèle de pré-formation multimodal a favorisé l'amélioration des performances de l'ITR.
Tâches de pré-formation . La tâche de pré-formation guide le modèle pour apprendre des fonctionnalités multimodales efficaces de bout en bout. Les modèles pré-entraînés sont conçus pour plusieurs tâches intermodales en aval, de sorte que diverses tâches prétextes sont souvent invoquées. Ces tâches de prétexte sont principalement divisées en deux catégories : la correspondance image-texte et la modélisation d'occlusion.
L'ITR est une tâche importante en aval dans le domaine de la pré-formation multimodale, et sa tâche prétexte associée, la correspondance image-texte, est bien accueillie dans les modèles de pré-formation. Généralement, un en-tête spécifique à la tâche ITR est attaché à une structure de type transformateur pour distinguer si les paires image-texte d'entrée correspondent sémantiquement en comparant les caractéristiques globales des différentes modalités. Cela peut être considéré comme une tâche prétexte pour une correspondance image-texte à gros grain [Vilbert : Pretraining task-agnostic visiolin-guistic représentations for vision-and- Language Tasks.InNeurIPS, 2019 ;Unicoder-vl : A universal encoder for vision and Language par pré-formation intermodale. Dans AAAI, 2020 ; Uniter : Apprentissage universel de la représentation image-texte. Dans ECCV, 2020 ; Aligner avant de fusionner : Apprentissage de la vision et de la représentation linguistique avec distillation de l'élan. Dans NeurIPS, 2021 ; Vilt : Vision-et -transformateur de langage sans convolution ni supervision de région. Dans ICML, 2021]. De plus, il a été étendu à la tâche de prétexte de correspondance fine image-texte : alignement de mots ptach [Vilt : Transformateur de vision et de langage sans convolution ni supervision de région. Dans ICML, 2021], alignement de mots de région [ Uniter : Apprentissage universel de la représentation image-texte. En ECCV, 2020] et l'alignement des expressions régionales [Kd-vlp : Improving end-to-end vision-and-langage pretraining with object knowledge distillation. Dans EMNLP, 2021]. Il ne fait aucun doute que la tâche de prétexte de correspondance image-texte pré-entraînée établit une connexion directe avec la tâche ITR en aval, ce qui réduit l'écart entre le modèle pré-entraîné indépendant de la tâche et l'ITR.
Inspirée de la pré-formation au traitement du langage naturel, la tâche prétexte de modélisation du langage masqué est souvent utilisée dans les modèles de pré-formation multimodaux. En conséquence, la tâche prétexte de modélisation visuelle d'occlusion apparaît également dans ce cas. Les deux sont collectivement appelés tâches de modélisation d’occlusion. Dans NeurIPS, 2019 ; Unicoder-vl : Un encodeur universel pour la vision et le langage par pré-entraînement multimodal. Dans AAAI, 2020 ; Vinvl : Revisiter les représentations visuelles dans les modèles de langage de vision. Dans CVPR, 2021], le texte d'entrée suit une règle de masquage spécifique, masquant aléatoirement plusieurs mots dans une phrase, puis cette tâche prétexte pilote le réseau en fonction des mots non masqués et des images d'entrée pour prédire les mots masqués. Dans les tâches de modélisation visuelle d'occlusion, le réseau régresse les caractéristiques intégrées de la région occluse [Uniter : Universal image-text représentation learning. In ECCV, 2020] ou prédit son étiquette sémantique [Unicoder-vl : A universal encoder for vision and language by cross -pré-formation modale. Dans AAAI, 2020] ou simultanément [Kd-vlp : Improving end-to-end vision-and-langage pretraining with object knowledge distillation. Dans EMNLP, 2021]. La tâche de modélisation d'occlusion capture implicitement les dépendances entre les images et le texte, offrant ainsi une prise en charge solide pour les tâches ITR en aval.
Données de pré-entraînement. La recherche au niveau des données est une tendance positive dans le domaine de la pré-formation intermodale. D'une part, les connaissances intramodales et intermodales des données d'image et de texte sont pleinement exploitées dans les méthodes ITR pré-entraînées [Oscar : Pré-entraînement aligné sur la sémantique d'objet pour les tâches de langage de vision. Dans ECCV, 2020 ; Rosita : Améliorer les alignements sémantiques de la vision et du langage via l'intégration des connaissances intermodales et intramodales. Dans ACM MM, 2021]. D’un autre côté, de nombreuses études se concentrent sur l’augmentation de la taille des données de pré-entraînement. En plus des ensembles de données hors domaine à grande échelle les plus largement utilisés, en particulier ceux utilisés pour les modèles de pré-entraînement [Unicoder-vl : A universal encoder for vision and Language by cross-modal pre-training. Dans AAAI, 2020 ; Aligner avant de fusionner : apprentissage de la vision et de la représentation linguistique avec distillation de l'élan. Dans NeurIPS, 2021], des ensembles de données dans le domaine initialement utilisés pour affiner et évaluer les tâches en aval sont ajoutés aux données de pré-formation pour un meilleur apprentissage des fonctionnalités multimodales [Oscar : Pré-formation alignée sur la sémantique objet pour les tâches de langage de vision. Dans ECCV, 2020 ; Aligner avant de fusionner : Apprentissage de la représentation de la vision et du langage avec distillation de l'élan. Dans NeurIPS, 2021]. En plus de cela, de riches données monomodales non appariées peuvent également être ajoutées aux données de pré-entraînement pour apprendre des fonctionnalités plus générales [Unimo : Vers une compréhension et une génération modales unifiées via un apprentissage contrastif intermodal. 2020]. De plus, certains chercheurs [Imagebert : Cross-modal pre-training with large-scale low-supervised image-text data. 2020 ; Scaling up visual and vision-langage représentation learning with noise text su-pervision. InICML, 2021 ; Filip : Pré-formation interactive langage-image à granularité fine. InICLR, 2022] pour collecter des données nouvelles et à plus grande échelle pour le modèle de pré-formation. Des opérations aussi simples et grossières donnent généralement des résultats dans diverses tâches intermodales en aval. Excellentes performances , y compris ITR. De manière générale, l'attention portée aux données a un impact positif sur les modèles intermodaux pré-entraînés, qui favoriseront naturellement les tâches ITR en aval. 2022] pour collecter des données nouvelles et à plus grande échelle pour les modèles de pré-formation, des opérations aussi simples et grossières conduisent souvent à d'excellentes performances dans diverses tâches intermodales en aval, y compris l'ITR. De manière générale, l'attention portée aux données a un impact positif sur les modèles intermodaux pré-entraînés, qui favoriseront naturellement les tâches ITR en aval. 2022] pour collecter des données nouvelles et à plus grande échelle pour les modèles de pré-formation, des opérations aussi simples et grossières conduisent souvent à d'excellentes performances dans diverses tâches intermodales en aval, y compris l'ITR. De manière générale, l'attention portée aux données a un impact positif sur les modèles intermodaux pré-entraînés, qui favoriseront naturellement les tâches ITR en aval.
4. Ensembles de données et évaluation
4.1 Ensemble de données
Les chercheurs ont proposé divers ensembles de données pour l'ITR. Nous résumons ci-dessous les ensembles de données les plus fréquemment utilisés. 1) Les légendes COCO contiennent 123 287 images de l'ensemble de données Common Objects in COntext (COCO) de Microsoft, chaque image comporte cinq légendes générées artificiellement. Après suppression des mots rares, la longueur moyenne du titre est de 8,7. L'ensemble de données est divisé en 82 783 images d'entraînement, 5 000 images de validation et 5 000 images de test. Les chercheurs ont évalué leur modèle sur 5 images de test 1K et sur les images de test complètes 5K. 2) Flickr30K comprend 31 000 images collectées sur le site Web Flickr. Chaque image contient cinq descriptions textuelles. L'ensemble de données est divisé en trois parties, 1 000 images pour la validation, 1 000 images pour les tests et le reste pour la formation.
4.2 Indicateurs d'évaluation
R@K est l'indice d'évaluation le plus couramment utilisé dans ITR. C'est l'abréviation du taux de rappel de la Kème position dans le classement et est défini comme la proportion de correspondances correctes dans les K premiers résultats de recherche.
4.3 Comparaison de précision
Nous comparons la précision des méthodes ITR représentatives et de pointe en termes d'extraction de caractéristiques et d'alignement de caractéristiques.
Extraction de fonctionnalités . Nous listons les résultats de la comparaison dans le tableau 1. Parmi les méthodes basées sur le VSE, ALIGN [Scaling up visual and vision-langage représentation learning with noise text su-pervision. InICML, 2021] dépasse de loin celle grâce à un pré-entraînement à grande échelle sur plus d'un milliard de paires image-texte. quantité de données d'autres méthodes de pré-entraînement, il y a donc une grande amélioration de la précision par rapport aux autres méthodes. Pour la comparaison entre les méthodes CA, nous pouvons voir que la précision de ces méthodes s’améliore progressivement avec le temps. Pour la comparaison entre les méthodes basées sur VSE et les méthodes CA, 1) SCAN [Stacked cross attention for image-text matching. In ECCV, 2018], comme première tentative de la méthode CA, comparée à la méthode LTBN alors basée sur VSE [ Apprentissage des réseaux neuronaux à deux branches pour les tâches de correspondance image-texte. Dans TPAMI, 2018], il y a eu une percée en matière de précision ; 2) Dans l'ensemble, à l'exception d'ALIGN, la méthode CA est largement meilleure que la méthode basée sur VSE dans R @ 1 L'avantage est attribué à l'exploration approfondie des interactions de fonctionnalités intermodales dans la méthode CA. Cependant, à titre exceptionnel, les méthodes basées sur VSE pré-entraînées sur des données à très grande échelle peuvent compenser la dégradation des performances causée par une moindre exploration des interactions multimodales, ce qui est fortement soutenu par les résultats d' ALIGN . Pour comparer la méthode SA avec les méthodes basées sur VSE et CA, dans le même cadre, c'est-à-dire l'ITR traditionnel, la méthode SA DIME [Dynamic modality interaction mod-eling for image-text retrieval. InSIGIR, 2021] surpasse la méthode basée sur VSE sur Flickr30k et Méthodes CA, mais est inférieure au SAN [Saliency-guided attention network for image-phrase matching. Dans ICCV, 2019] sur les légendes COCO. Il est possible de poursuivre le développement de la technologie SA.
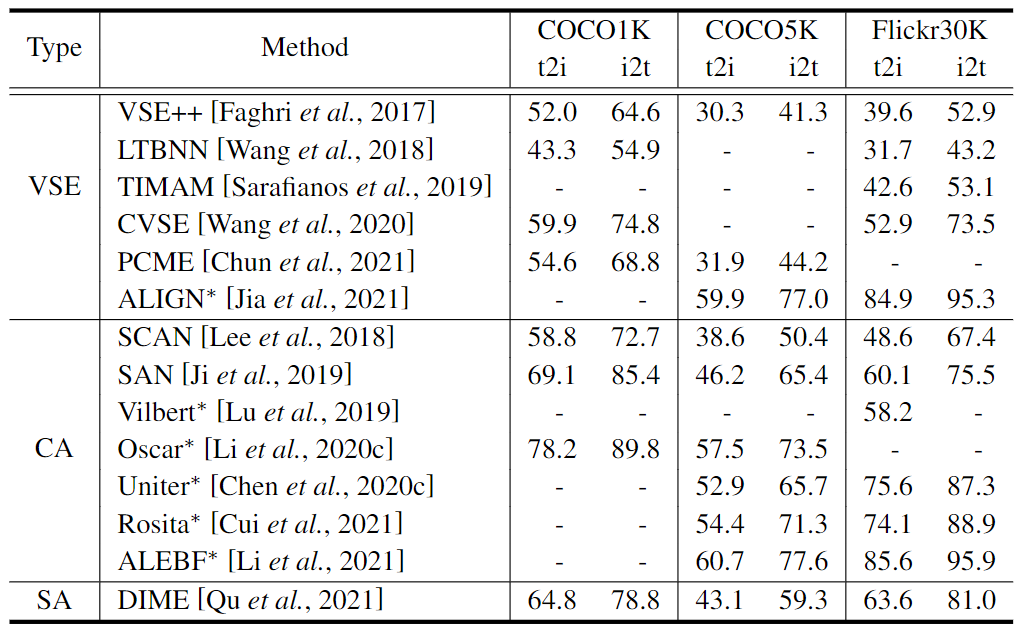
Tableau 1 : Comparaison de précision entre les méthodes ITR à R@1 du point de vue de l'extraction de fonctionnalités. Les méthodes marquées d'un "*" représentent les méthodes de pré-formation. Nous montrons les meilleurs résultats pour chaque méthode rapportée dans l'article original
alignement des fonctionnalités. Les résultats de la comparaison sont présentés dans le tableau 2. En termes de comparaison entre les méthodes basées sur l'alignement global, même si l'alignement global adopte une structure de base à deux flux, le R@1 d'ALIGN est toujours au-dessus des autres méthodes, y compris TIMAM[apprentissage de représentation contradictoire pour la correspondance texte-image. Dans ICCV, 2019 ] et PCME [Probabilistic embeddings for cross-modal retrieval. In CVPR, 2021], avec une structure de réseau complexe alignée à l'échelle mondiale. En comparant les méthodes impliquant l'alignement local, ALBEF [Align before fuse: Vision and Language Representative Learning with Moment Distillation. In NeurIPS, 2021] montre d'excellentes performances. Il convient de noter que Uniter [Uniter : apprentissage universel de la représentation image-texte. Dans ECCV, 2020] et ViLT [Vilt : Transformateur de vision et de langage sans con-volution ni supervision de région. Dans ICML, 2021] seul le mécanisme d'attention vanille peut produire de bons résultats. En revanche, SCAN [Stacked cross attention for image-text matching. In ECCV, 2018] et CAMP [Camp: Cross-modal adaptive message transmission for text-image retrieval. InICCV, 2019] adopte un mécanisme similaire et fonctionne mal à R@1. Uniter et ViLT effectuent des tâches ITR sous une forme de pré-formation et de réglage fin, et la riche connaissance des données intermodales en pré-formation est bénéfique pour les tâches ITR en aval. D’après la comparaison entre les méthodes basées sur l’alignement global et les méthodes d’alignement local, ces dernières montrent globalement de meilleures performances que les premières, indiquant l’importance de l’alignement local pour obtenir un ITR de haute précision.
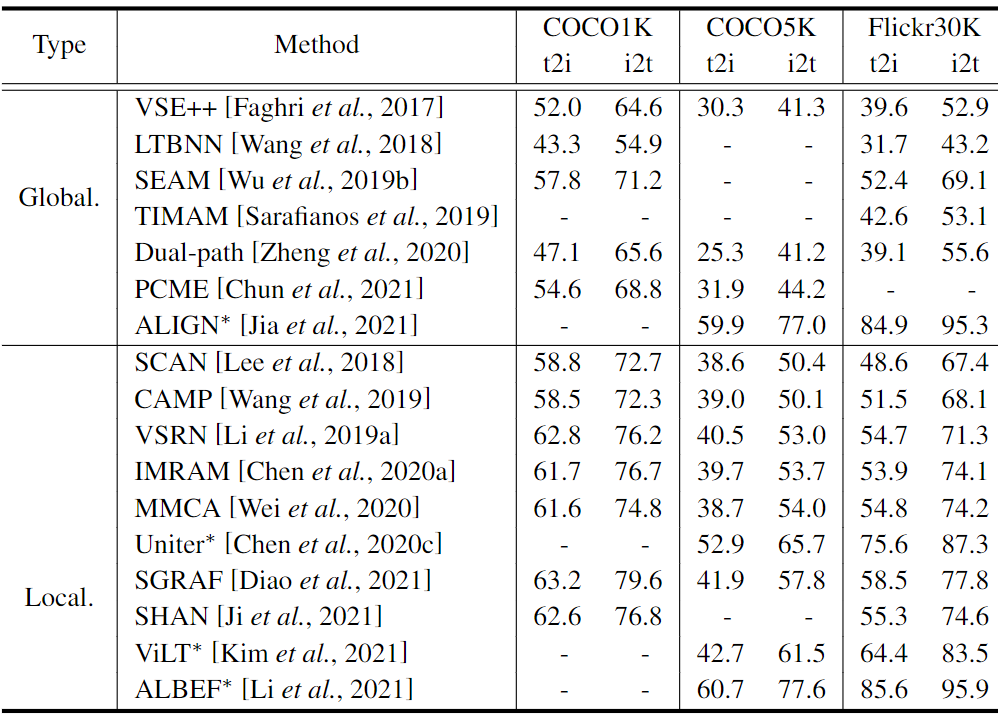
Tableau 2 : Comparaison de précision entre les méthodes ITR à R@1 du point de vue de l'alignement des fonctionnalités. Les méthodes marquées d'un "*" représentent les méthodes de pré-formation. Global et Local sont respectivement les abréviations d'alignement global et d'alignement local. Nous présentons les meilleurs résultats pour chaque méthode rapportée dans l'article original
De plus, nous résumons la tendance de développement de l’ITR de 2017 à 2021 dans la figure 4. Au fil des années, nous pouvons constater une nette tendance à l’amélioration de la précision. Plus précisément, le grand pas en avant en 2020 est dû à la technologie ITR de pré-formation. Depuis lors, la précision des méthodes ITR pré-entraînées n’a cessé de gagner du terrain. On peut constater que la technologie ITR de pré-formation joue un rôle de premier plan dans la promotion du développement de l'ITR. Il est indissociable de la prise en charge d’une échelle de données de formation en constante expansion. Nous pouvons constater qu'avec l'émergence de l'ITR de pré-formation, la quantité de données de formation augmente considérablement.
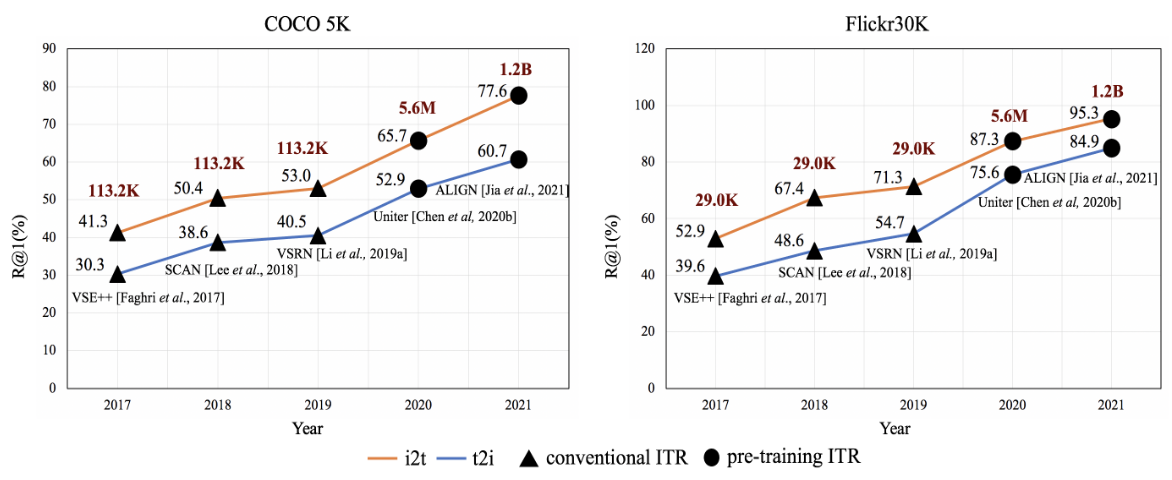
Figure 4 : Tendance de développement de l’ITR au cours des dernières années. Le nombre noir au-dessus du graphique linéaire est la valeur R@1 de la méthode et le nombre rouge est le nombre de données d'entraînement multimodales.
5. Conclusion et travaux futurs
Dans cet article, nous proposons un examen complet des méthodes ITR sous quatre aspects : l'extraction de fonctionnalités, l'alignement des fonctionnalités, l'efficacité du système et le paradigme de pré-formation. Nous résumons également les ensembles de données et les mesures d'évaluation largement utilisés dans ITR, et sur cette base, nous analysons quantitativement les performances des méthodes représentatives. Le rapport conclut que la technologie ITR a fait de grands progrès au cours des dernières années, notamment avec l'avènement de l'ère de la pré-formation multimodale. Cependant, il existe encore des questions moins explorées dans l'ITR. Nous avons fait les observations intéressantes suivantes sur les développements futurs possibles.

Figure 5 : Illustration des données de bruit dans l’en-tête COCO. (a) Sur la base de la description textuelle appariée marquée en orange, il est difficile de capturer le contenu de l'image. (b) En plus des paires image-texte positives avec des flèches pleines, il semble également y avoir une correspondance pour les paires image-texte négatives avec des flèches pointillées.
données . Les méthodes ITR actuelles sont essentiellement basées sur les données. En d’autres termes, les chercheurs conçoivent et optimisent les réseaux pour rechercher le meilleur schéma de récupération basé sur les ensembles de données de référence existants. Premièrement, l’hétérogénéité des données intermodales et l’ambiguïté de la sémantique apportent inévitablement du bruit à l’ensemble de données. Par exemple, comme le montre la figure 5, il existe des descriptions textuelles insaisissables pour les images, et il existe de multiples correspondances entre les images et le texte dans les légendes COCO. Par conséquent, dans une certaine mesure, les résultats des méthodes ITR actuelles sur de tels ensembles de données restent controversés. Il y a eu quelques explorations sur la diversité des données [Incorporation polysémique visuelle-sémantique pour la récupération intermodale. Dans CVPR, 2019 ; Intégrations probabilistes pour la récupération intermodale. Dans CVPR, 2021 ; Apprentissage de la récupération intermodale avec des étiquettes bruyantes. InCVPR, 2021 ], cependant, seules les données d'entraînement sont prises en compte et les données de test sont ignorées. De plus, en plus des informations de données ordinaires, c'est-à-dire des images et des textes, le texte de la scène apparaissant dans l'image constitue un indice précieux pour l'ITR, qui est généralement ignoré dans les méthodes existantes. [Stacmr : Scene-Tex-Aware Cross-Modal Retrieval. In WACV, 2021] est un travail pionnier qui intègre explicitement les informations sur le texte de la scène dans le modèle ITR. Ces études laissent place à un développement ultérieur de l’ITR au niveau des données.
connaissance . Les humains ont une puissante capacité à établir des liens sémantiques entre la vision et le langage. Cela est dû à leur connaissance accumulée du bon sens et à leur capacité à raisonner de manière causale. Naturellement, l’intégration de ces connaissances de haut niveau dans le modèle ITR est précieuse pour améliorer ses performances. CVSE [Consensus-aware visual-semantic embedding for image-text matching. InECCV, 2020] est un travail pionnier qui calcule des corrélations statistiques dans un corpus de légendes d'images en tant que connaissance de bon sens pour l'ITR. Cependant, ces connaissances de bon sens sont limitées par le corpus et ne sont pas totalement adaptées à l’ITR. À l’avenir, l’adaptation des connaissances de bon sens à l’ITR et la création de modèles d’inférence causale pourraient s’avérer prometteuses.
Nouveau paradigme . Dans le cadre de la tendance actuelle, les méthodes ITR pré-entraînées présentent un avantage considérable en termes de précision par rapport aux méthodes ITR traditionnelles. La pré-formation puis l'ajustement sur un modèle multimodal à grande échelle sont devenus un paradigme de base pour obtenir des résultats de récupération de pointe. Cependant, ce paradigme nécessite une grande quantité de données étiquetées lors de la phase de réglage fin et est difficile à appliquer à des scénarios réels. Il est logique de rechercher et de développer un nouveau paradigme RTI respectueux des ressources. Par exemple, la technologie de réglage basée sur des invites récemment apparue, avec ses excellentes capacités en quelques tirs, fournit des conseils pour le développement d'un tel nouveau paradigme, ce que l'on appelle l'invite de pré-entraînement.