1. Introduction aux ensembles de données
L'ensemble de données CIFAR-10 comprend 60 000 images couleur 32 x 32 réparties en 10 catégories , 6000avec 1 image dans chaque catégorie. Il existe 50000des images de formation et 10000des images de test.
L'ensemble de données est divisé en 5 lots de formation et 1 lot de test, chaque lot contient 10 000 images. Le lot de test contient exactement 1 000 images sélectionnées au hasard dans chaque classe. Les lots de formation contiennent les images restantes dans un ordre aléatoire, mais certains lots de formation peuvent contenir plus d'images d'une classe que d'une autre. À eux deux, le lot de formation contient exactement 5 000 images de chaque classe.
Résumer:
Size(大小):Image RVB 32 × 32, l'ensemble de données lui-même est un canal BGR,
Num(数量):un ensemble d'entraînement 50 000 et un ensemble de test 10 000, un total de 60 000 images
Classes(十种类别):d'avion (avion), de voiture (voiture), d'oiseau (oiseau), de chat (chat), de cerf (cerf). ), chien (chien), grenouille (grenouille), cheval (cheval), bateau (bateau), camion (camion)

Lien de téléchargement
Dream是个帅哥Partage depuis le blogueur ( ) :
Lien : https://pan.baidu.com/s/1gKazlkk108V_1nrc68VoSQ code d'extraction : 0213
Dossier de l'ensemble de données
Ensemble de données CIFAR-100 (étendu)
Cet ensemble de données est similaire au CIFAR-10 sauf qu'il comporte 100 classes et que chaque classe contient 600 images. Il y a 500 images de formation et 100 images de test pour chaque classe. Les 100 sous-catégories du CIFAR-100 sont divisées en 20 grandes catégories. Chaque image possède une balise « fine » (la sous-catégorie à laquelle elle appartient) et une balise « grossière » (la catégorie principale à laquelle elle appartient).
Comparaison entre l'ensemble de données CIFAR-10 et l'ensemble de données MNIST
- Les dimensions sont différentes : l'ensemble de données CIFAR-10 a 4 dimensions, et l'ensemble de données MNIST a 3 dimensions (les quatre dimensions du CIRAR-10 : le nombre d'échantillons à la fois, la hauteur de l'image, la largeur de l'image, le nombre de canaux d'image -> NHWC ; les trois dimensions de MNIST : une fois le nombre d'échantillons, la hauteur d'image, la largeur d'image -> NHW)
- Les types d'images sont différents : l'ensemble de données CIFAR-10 est une image RVB (avec trois canaux) et l'ensemble de données MNIST est une image en niveaux de gris, c'est pourquoi l'ensemble de données CIFAR-10 a une dimension de plus que l'ensemble de données MNIST. .
- Le contenu des images est différent : l'ensemble de données CIFAR-10 montre une variété d'objets différents (chats, chiens, avions, voitures...), et l'ensemble de données MNIST montre les nombres manuscrits de 0 à 9 par différentes personnes.
2. Lecture de l'ensemble de données
Lire l'ensemble de données
Sélectionnez data_batch_1 pour visualiser l'une des images :
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
print(dict)
Résultats de sortie :
il y a 4 clés de dictionnaire dans un lot d'ensembles de données. Ce que nous devons utiliser, c'est l'étiquette de données et le contenu des données (10 000 × 32 × 32 × 3, 10 000 images à trois canaux RVB 32 × 32).

La sortie est un dictionnaire. :
{ b'batch_label' : b'lot d'entraînement 1 sur 5', b'labels' : [6, 9 … 1,5], b'data' : array([[ 59, 43, …, 84, 72], …[ 62, 61, 60, …, 130, 130, 131]], dtype=uint8), b'filenames' : [b'leptodactylus_pentadactylus_s_000004.png',…b'cur_s_000170.png'] }
Parmi eux, la signification de chaque représentant est la suivante :
b'batch_label' : l'ensemble de fichiers auquel il appartient
b'labels' : étiquette d'image
b'data' : données d'image
b'filename' : nom d'image
Type de lecture
print(type(dict[b'batch_label']))
print(type(dict[b'labels']))
print(type(dict[b'data']))
print(type(dict[b'filenames']))
Résultat de sortie :
<classe 'octets'>
<classe 'liste'>
<classe 'numpy.ndarray'>
<classe 'liste'>
Lire les images
img = dict[b'data']
print(img.shape)
Résultat de sortie : (10 000, 3 072), où 3 072 = 32 * 32 * 3 (taille de l'image)
3. Appel d'ensemble de données
Appels TensorFlow
from tensorflow.keras.datasets import cifar10
(x_train,y_train), (x_test, y_test) = cifar10.load_data()
appel local
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
4. Formation aux réseaux neuronaux convolutifs
Référence ici : Portail
1.Spécifiez le GPU
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0],True)
#初始化
plt.rcParams['font.sans-serif'] = ['SimHei']
2. Charger les données
cifar10 = tf.keras.datasets.cifar10
(train_x,train_y),(test_x,test_y) = cifar10.load_data()
print('\n train_x:%s, train_y:%s, test_x:%s, test_y:%s'%(train_x.shape,train_y.shape,test_x.shape,test_y.shape))
3. Prétraitement des données
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32) #归一化
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
4. Construisez un modèle
Les paramètres de l'algorithme Adam utilisent les paramètres publics par défaut de keras, la fonction de perte utilise la fonction de perte d'entropie croisée clairsemée et la précision utilise la fonction de précision de classification clairsemée.
model = tf.keras.Sequential()
##特征提取阶段
#第一层
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu,data_format='channels_last',input_shape=X_train.shape[1:])) #卷积层,16个卷积核,大小(3,3),保持原图像大小,relu激活函数,输入形状(28,28,1)
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2))) #池化层,最大值池化,卷积核(2,2)
#第二层
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2)))
##分类识别阶段
#第三层
model.add(tf.keras.layers.Flatten()) #改变输入形状
#第四层
model.add(tf.keras.layers.Dense(128,activation='relu')) #全连接网络层,128个神经元,relu激活函数
model.add(tf.keras.layers.Dense(10,activation='softmax')) #输出层,10个节点
print(model.summary()) #查看网络结构和参数信息
#配置模型训练方法
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
5. Former le modèle
La taille de la formation par lots est de 64, l'itération est de 5 et le rapport de l'ensemble de tests est de 0,2 (48 000 données d'ensemble de formation, 12 000 données d'ensemble de test)
history = model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
6. Évaluer le modèle
model.evaluate(X_test,y_test,verbose=2) #每次迭代输出一条记录,来评价该模型是否有比较好的泛化能力
#保存整个模型
model.save('CIFAR10_CNN_weights.h5')
7. Visualisation des résultats
print(history.history)
loss = history.history['loss'] #训练集损失
val_loss = history.history['val_loss'] #测试集损失
acc = history.history['sparse_categorical_accuracy'] #训练集准确率
val_acc = history.history['val_sparse_categorical_accuracy'] #测试集准确率
plt.figure(figsize=(10,3))
plt.subplot(121)
plt.plot(loss,color='b',label='train')
plt.plot(val_loss,color='r',label='test')
plt.ylabel('loss')
plt.legend()
plt.subplot(122)
plt.plot(acc,color='b',label='train')
plt.plot(val_acc,color='r',label='test')
plt.ylabel('Accuracy')
plt.legend()
8. Utiliser des modèles
plt.figure()
for i in range(10):
num = np.random.randint(1,10000)
plt.subplot(2,5,i+1)
plt.axis('off')
plt.imshow(test_x[num],cmap='gray')
demo = tf.reshape(X_test[num],(1,32,32,3))
y_pred = np.argmax(model.predict(demo))
plt.title('标签值:'+str(test_y[num])+'\n预测值:'+str(y_pred))
plt.show()
Résultats de sortie :

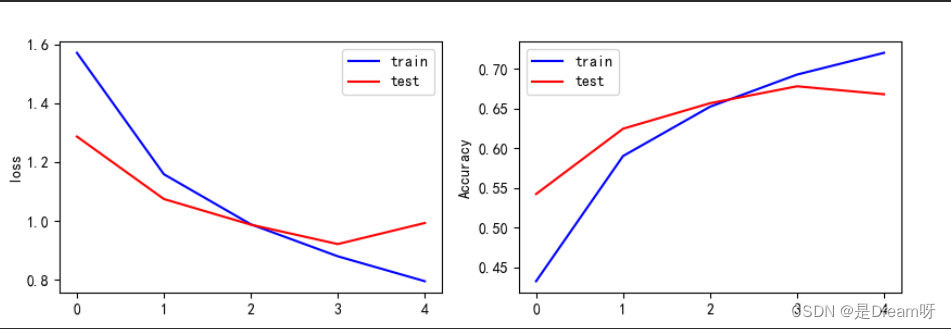
le contenu ci-dessus correspond à la valeur de la fonction de perte et à la précision de l'échantillon d'entraînement, ainsi qu'à la valeur de la fonction de perte et à la précision de l'échantillon de test. Vous pouvez voir les changements dans la fonction de perte et la précision à chaque itération d'entraînement, à partir de la dernière résultat de l'itération.Il semble que la valeur de la fonction de perte de l'échantillon de test atteigne 0,9123 et que la précision n'atteigne que 0,6839.
Ce résultat n'est pas très bon. J'ai essayé d'augmenter le nombre d'itérations et j'ai découvert que la valeur de la fonction de perte de l'échantillon d'entraînement pouvait atteindre 0,04 et la précision atteindre 0,98 ; mais en fait, le modèle d'entraînement produisait des erreurs de généralisation croissantes. C'est l'entraînement. Le phénomène de démesure est qu'après avoir essayé, la meilleure capacité de généralisation se situe à la 5ème itération, on ne peut donc choisir d'itérer que 5 fois.

Fichier de modèle entraîné - à utiliser directement
Introduction à l'ensemble de données CIFAR10 et à l'utilisation de réseaux de neurones convolutifs pour entraîner des modèles de classification d'images - code complet et fichiers de modèle entraînés joints - à utiliser directement : https://download.csdn.net/download/weixin_51390582/88788820