

Auteur | Un jour
Introduction
Cet article présente principalement les concepts et applications de la business intelligence (BI) et de Turing Data Analysis (TDA). La BI aide les entreprises à prendre de meilleures décisions et à planifier leur stratégie en collectant, organisant, analysant et présentant des données. Cependant, les idées traditionnelles de construction de BI présentent des problèmes, tels que la nécessité d'un réaménagement lorsque l'entreprise modifie ses exigences en matière de données et la faible efficacité de l'analyse des données sous-jacentes. Par conséquent, TDA est apparue comme une plate-forme d'analyse en libre-service unique. Elle crée des ensembles de données publiques en fonction de thèmes d'analyse basés sur des données détaillées. Les utilisateurs peuvent librement glisser-déposer l'analyse et enregistrer les résultats en un seul clic, et peuvent également les partager avec. d'autres pour le visionnement. Cependant, la construction de TDA est également confrontée à des défis tels que des indicateurs de dimension d'analyse complets, un calibre de données précis et des performances de requête. En réponse à ces défis, nous mettons en avant les objectifs d'exhaustivité, d'exactitude, d'efficacité et de rapidité, et atteignons ces objectifs grâce à des mécanismes de processus et à la construction de fonctions ainsi qu'au moteur de données MPP.
Le texte intégral compte 4 766 mots et le temps de lecture estimé est de 15 minutes.
01 Contexte et objectifs
BI signifie Business Intelligence, qui aide les entreprises à garder une longueur d'avance sur leurs concurrents et à prendre de meilleures décisions commerciales et une meilleure planification stratégique en collectant, organisant, analysant et présentant des données. Le processus de collecte et d'organisation est la construction d'un entrepôt de données, et l'analyse et la présentation des données sont la construction d'une plateforme d'analyse visuelle.
Une idée de construction BI courante dans l'industrie : si l'entreprise souhaite voir les modifications des données d'un certain indicateur, elle demande au middle office. Les données RD sont modélisées couche par couche à partir de ODS>DWD>DWS>ADS, puis les données personnalisées Le tableau des résultats ADS est développé et implémenté dans Palo/Mysql. , et enfin configurez plusieurs graphiques et enregistrez-les dans des rapports pour une visualisation professionnelle. Bien que cette idée de construction réponde aux besoins d'analyse des données de l'entreprise, elle est confrontée à deux problèmes : 1. Lorsque l'entreprise modifie ses exigences en matière de données, le tableau de résultats ADS doit être personnalisé et développé à nouveau, ce qui occupera à plusieurs reprises du personnel de R&D ; 2. Elle ne résout que le problème. problème de l'analyse commerciale. Si vous souhaitez approfondir et analyser les raisons des fluctuations, cela sera difficile car la table sous-jacente est une table agrégée qui contient uniquement les données du graphique actuel. Si vous souhaitez l'analyser, vous pouvez uniquement télécharger les données détaillées puis les analyser via Excel ou d'autres méthodes, ce qui est relativement inefficace.
TDA (Turing Data Analysis) est une plate-forme d'analyse en libre-service unique conçue pour résoudre le problème mentionné ci-dessus des longs liens d'analyse dans la BI.
L'idée de construction de TDA : sur la base du tableau large détaillé DWD, les ensembles de données publiques sont construits en fonction du thème d'analyse (les données sur une seule journée représentent des dizaines de millions + les utilisateurs peuvent faire glisser et déposer une analyse basée sur les ensembles de données publiques). librement, et les résultats de l'analyse peuvent être enregistrés dans des tableaux de bord personnels ou publiés en un seul clic. Créez un tableau de bord public et partagez-le avec d'autres personnes qui peuvent vérifier la tendance de fluctuation sur le tableau de bord public, accéder à la page d'analyse visuelle pour continuer à explorer ; causes des fluctuations et compléter l'analyse unique de « voir les tendances, décomposer les dimensions et découvrir les détails » Trois axes.
La figure suivante représente le processus global des idées de construction TDA :
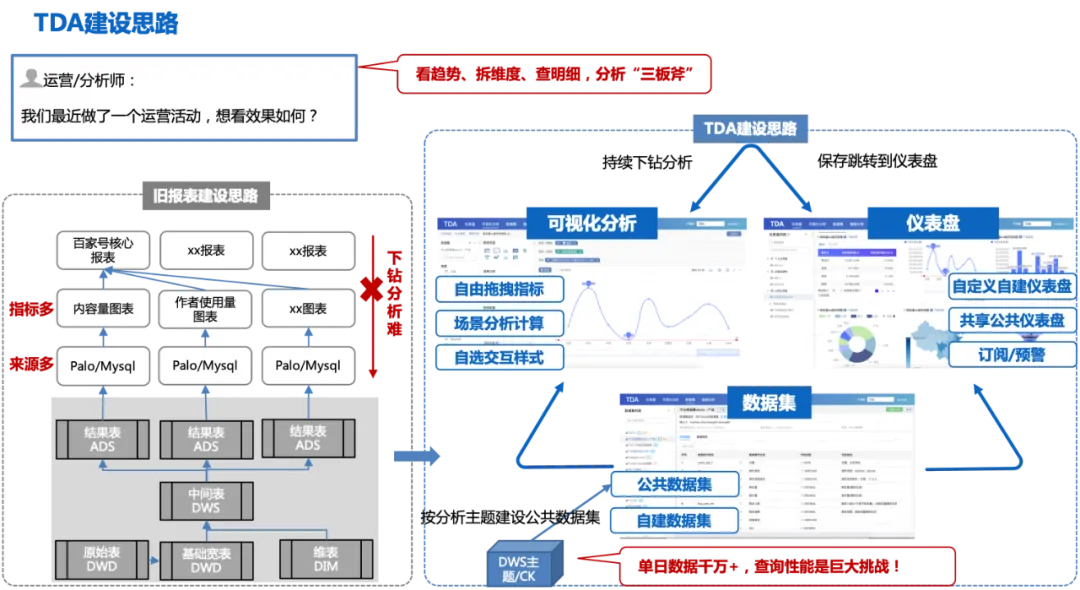
Cette idée de construction sera également confrontée à certains défis :
1. Les indicateurs de la dimension d'analyse doivent être complets, sinon plusieurs ensembles de données devront être construits, ce qui entraînera des ensembles de données nombreux et dispersés, le même problème que la construction du rapport précédent ;
2. Le calibre des données doit être précis et faisant autorité ;
3. Avec des dizaines de millions de données traitées en une seule journée, les performances des requêtes constituent un défi de taille.
En réponse aux défis ci-dessus, nous avons également formulé des objectifs correspondants pour répondre aux besoins d'une analyse commerciale efficace :
1. Complet (les indicateurs de la dimension d'analyse doivent être complets, couvrant plus de 80 % des besoins de l'entreprise) ;
2. Précis (calibre uniforme, données précises) ;
3. Rapidité (la rapidité de sortie des données est T+10h) ;
4. Rapide (requête de données de niveau 1 milliard en 10 secondes).
La plate-forme TDA garantira une construction d'ensembles de données complète, précise et efficace du point de vue de la construction des mécanismes de processus et des fonctions, se combinera avec le moteur de données MPP pour garantir les performances des requêtes et améliorera l'efficacité de l'analyse des utilisateurs grâce au glisser-déposer visuel, à l'analyse de scène, modélisation en libre-service et autres fonctionnalités.
02 Solution technique
Sur la base de l'analyse ci-dessus, le positionnement du produit de TDA est une plate-forme de BI qui permet aux utilisateurs d'effectuer des requêtes en libre-service à guichet unique. Les utilisateurs peuvent librement glisser et déposer des ensembles de données, effectuer une analyse visuelle des données et créer des tableaux de bord de base. Aidez les utilisateurs à bénéficier d’une expérience unique d’analyse des requêtes dans les perspectives suivantes :
Itération Business Kanban et amélioration de l'efficacité (libre-service) : le mode d'itération du rapport de données a changé, du mode de planification RD de demande PM à une conversion progressive en fonctionnement libre-service PM/opération (création de Kanban/analyse des données).
Amélioration de l'efficacité de l'analyse des données (extrêmement rapide) : une seule requête de données est réduite de quelques minutes à quelques secondes, l'efficacité de l'analyse des fluctuations des indicateurs est augmentée de 20 fois et l'analyse de bout en bout de l'attribution des fluctuations d'un seul indicateur se fait en 2 heures. -> 5 minutes.
Analyse commerciale en libre-service à guichet unique (one-stop) : réalise l'observation des tendances des données, l'analyse dimensionnelle approfondie, l'exportation détaillée et d'autres fonctions, réalisant une expérience intégrée de surveillance et d'analyse des données.
La matrice fonctionnelle de ce produit est la suivante :
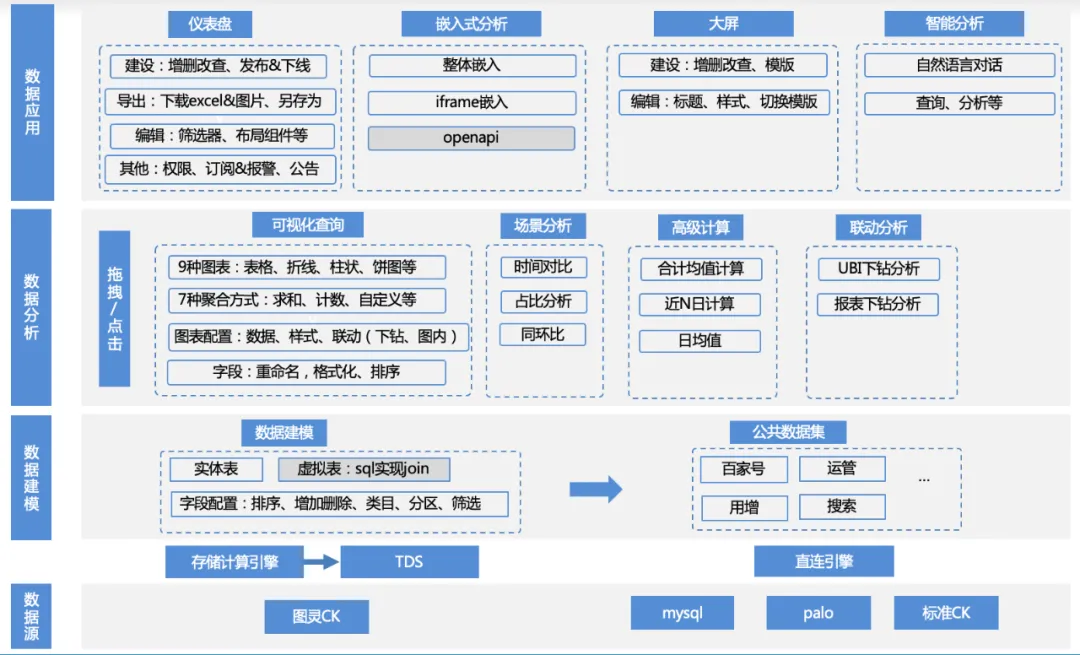
1. Accès à la source de données : l'entreprise utilise TDS pour calculer les données de la table de Turing en amont via le moteur de calcul, puis écrit les données dans des moteurs tels que clickhouse/mysql/palo et y accède via une connexion directe ; ou l'entreprise fournit son propre palo / Accès aux sources de données MySQL.
A. Gestion des sources de données : ajout, suppression, modification et requête de sources de données, clickhouse/mysql/palo et autres adaptations de pilotes de moteur
2. Modélisation des données : Après connexion à la source de données, les données peuvent être chargées dans le produit en écrivant du SQL et directement depuis la table d'origine. Mais ces tableaux nécessitent généralement un simple traitement secondaire pour les transformer en ensembles de données pouvant être analysés.
a. Gestion des ensembles de données : fonctions telles que l'ajout, la suppression, la modification, l'aperçu des données, la visualisation de schémas, l'analyse visuelle en un clic, etc.
b. Gestion des champs des ensembles de données : ajout, suppression, modification, tri des champs, champs personnalisés, etc.
c. Gestion des catégories de jeux de données : ajout, suppression, modification et tri personnalisé des catégories auxquelles appartiennent les champs, etc.
d. Gestion du répertoire des ensembles de données : ajout, suppression, modification et tri personnalisé du répertoire des ensembles de données, etc.
3. Analyse des données : sur la base de l'ensemble de données, les utilisateurs peuvent librement glisser-déposer des indicateurs, des dimensions, des filtres, sélectionner les types de graphiques et les méthodes d'analyse de scénarios appropriés, et effectuer des analyses et des calculs.
a. Configuration des données : changer d'ensemble de données, ajouter des champs personnalisés
b. Configuration du graphique : tableau, graphique linéaire, graphique à barres, diagramme circulaire et autres configurations de type de graphique, paramètres de couleur de légende, paramètres de format de données, etc.
C. Analyse de scénario : prise en charge de plusieurs capacités d'analyse de scénario telles que la valeur moyenne quotidienne, la comparaison d'une année sur l'autre, la proportion, le total, etc.
d. Analyse d'attribution : capacités d'analyse d'attribution en libre-service
e. Analyse interactive : analyse approfondie, etc.
4. Application de données : les utilisateurs peuvent enregistrer les résultats de l'analyse sur le tableau de bord, les intégrer dans une plateforme tierce, les enregistrer sur grand écran ou les utiliser directement pour une analyse intelligente, etc.
a. Gestion des tableaux de bord : ajout, suppression, modification de tableaux de bord, tri personnalisé, publication et hors ligne, export de données, alertes d'abonnement, etc.
b. Analyse intégrée : ifame intégré, sdk intégré et autres modes intégrés
c. Grand écran : grand écran en temps réel
d. Analyse intelligente : analyse conversationnelle LUI
2.1 Conception globale
L'architecture globale de TDA est présentée dans la figure ci-dessous :
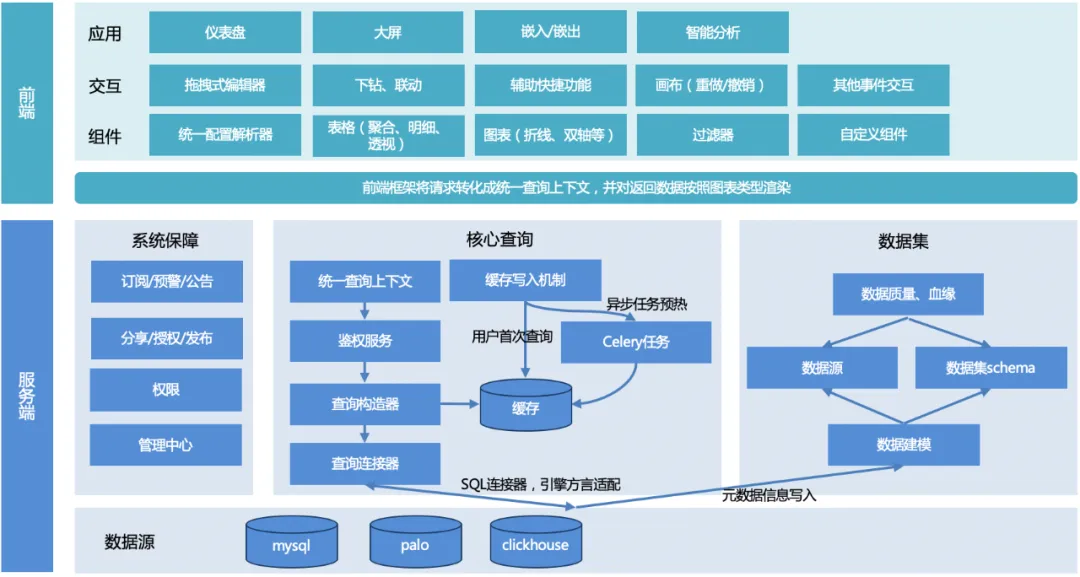
Le processus global : l'utilisateur lance une requête, le serveur unifie le contexte de la requête, construit l'objet de requête, adapte le dialecte du moteur sous-jacent, renvoie un format de données unifié, puis le cadre de rendu frontal s'adapte et restitue en fonction du type de graphique. .
Serveur:
1. Contexte de requête unifié : Afin de faciliter la réutilisation de fonctions communes lors du développement ultérieur d'autres fonctions de graphique, un contexte de requête unifié est conçu.
2. Constructeur de requête : Construisez un objet de requête (peut être multiple, par exemple, pour paginer une table, vous devez construire deux objets de requête, l'un est un objet de requête de pagination et l'autre est un objet de requête de comptage) en fonction de la requête paramètres transmis depuis le front-end.
3. Connecteur de requête :
a. Actuellement, il n'existe qu'un connecteur SQL, qui est utilisé pour satisfaire le moteur de requête SQL (mysql, palo, clickhouse, etc.). Différents moteurs, la syntaxe ou certaines fonctions peuvent être différents, et doivent être adaptés via différents moteurs. configurations de règles ;
b. D'autres connecteurs peuvent être étendus pour répondre aux requêtes non SQL à l'avenir.
4. Écriture du cache : Pour garantir les performances des requêtes, il existe deux méthodes d'écriture : l'écriture lorsque l'utilisateur accède pour la première fois, ou le préchauffage du cache via des tâches planifiées au céleri.
5. Module d'ensemble de données : Fournir un support aux données, établir des liens avec les sources de données sous-jacentes et garantir la qualité des données.
6. Module de garantie du système : l'abonnement, l'alerte précoce et l'annonce réalisent des capacités d'alerte précoce des données. Le partage, la publication et l'autorisation améliorent l'efficacité de la circulation des données. Le centre de gestion et les autorisations fournissent une gestion sous-jacente et une prise en charge des autorisations pour les données.
l'extrémité avant:
1. Bibliothèque de composants : fournit une analyse de configuration, différents composants de rendu de graphiques, des composants de filtre et des fonctionnalités de composants personnalisés.
2. Interaction : encapsule les capacités d'interaction de la page, notamment l'éditeur glisser-déposer, les liens d'exploration, les fonctions de raccourci auxiliaires, les capacités de canevas et d'autres interactions d'événements.
3. Application : Implémentez différentes applications visuelles pour différents utilisateurs et scénarios d'utilisation, tels que des tableaux de bord, de grands écrans, etc.
2.2 Conception détaillée
2.2.1 Requête principale
La BI en libre-service à guichet unique, grâce à des idées de modélisation d'ensembles de données publiques, réalise l'idée d'analyse en trois points des « tendances, dimensions et détails », qui sera confrontée à de nombreux défis, notamment :
-
Données multi-sources, présentation multi-graphiques et analyses et calculs de scénarios multiples : il existe plusieurs moteurs de sources de données sous-jacents dans le système BI afin d'étendre de manière flexible les sources de données, le style de présentation nécessite également une prise en charge riche des graphiques, et au-delà. en même temps, afin de répondre à l'analyse dans différents scénarios, le calcul doit prendre en charge des capacités d'analyse communes telles que les valeurs moyennes mensuelles et quotidiennes.
-
Interroger des dizaines de millions de données en quelques secondes : L'idée de construire des ensembles de données publiques facilite l'analyse mais introduit également de nouveaux défis. La quantité de dizaines de millions de données en une seule journée pose un énorme défi en termes de performances des requêtes.
En réponse aux problèmes ci-dessus, des solutions correspondantes ont été formulées :
-
Requête unifiée : unifiez le contexte de la requête, construisez l'objet de requête, adaptez le dialecte du moteur sous-jacent, renvoyez un format de données unifié et le framework de rendu frontal adapte le rendu en fonction du type de graphique.
-
Optimisation des requêtes : Ⅰ> Mise en cache + roulement automatique, couvrant 70 % des requêtes de tableaux de bord publics ; Ⅱ> Optimisation de la construction des requêtes SQL et utilisation complète des capacités d'agrégation côté moteur III> Requêtes simultanées de noms de domaine multiples et traitement des réponses multi-coroutines ; .
Requête unifiée :
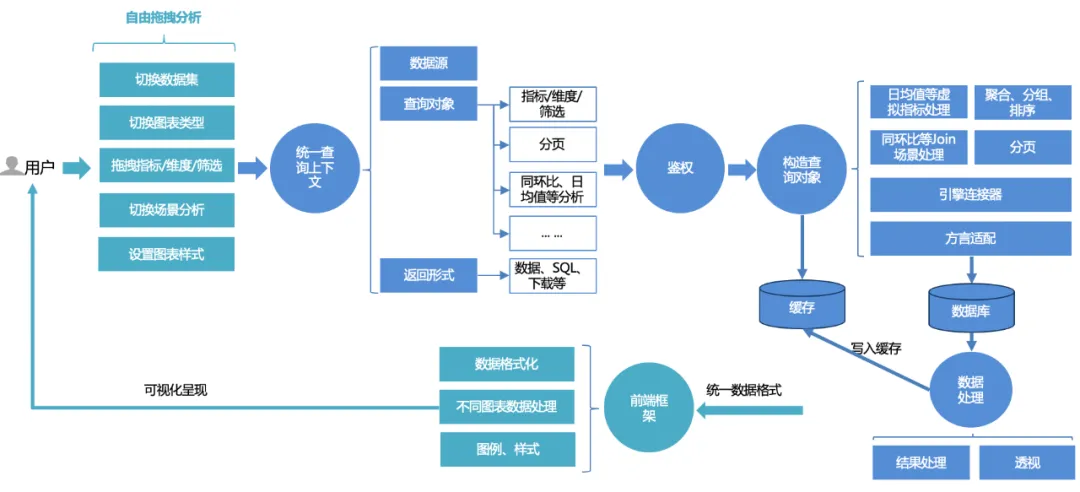
Le processus de requête unifié pour les utilisateurs de la plateforme est le suivant :
1. Les utilisateurs peuvent librement glisser-déposer l'analyse sur la page : changer d'ensemble de données, basculer entre différents types de graphiques, glisser-déposer des indicateurs, des dimensions, des filtres et des requêtes ; ou s'ils souhaitent utiliser certaines fonctionnalités avancées d'analyse de scène, ils peuvent basculer configurations en un seul clic.
2. La demande frontale sera traitée dans un contexte de requête unifié : comprenant une source de données, un objet de requête et un formulaire de retour. L'objet de requête encapsule des indicateurs de base, des dimensions, des informations de filtrage et des configurations d'analyse avancées telles que d'une année sur l'autre. comparaison et valeur moyenne quotidienne.
3. Service d'authentification unifié : basé sur la double authentification du tableau de bord et de l'ensemble de données, il prend également en charge un contrôle plus précis des autorisations de ligne et de ligne.
4. Construisez l'objet de requête : complétez d'abord la construction SQL de base (agrégation, regroupement, filtrage) basée sur des indicateurs, des dimensions et des triplets de filtrage, puis assemblez la logique de tri selon les règles de tri et ajoutez des options d'analyse avancées (telles que mois par mois, moyenne quotidienne, etc.) Une logique d'assemblage supplémentaire, puis un traitement de pagination doivent être combinés avec une adaptation du dialecte. Lors de l'interrogation de données, interrogez différentes bases de données (telles que mysql, palo, clickhouse, etc.) en fonction de différents moteurs. liants.
5. Interroger et traiter les données : Après avoir interrogé les données via l'éditeur de liens, traitez les données (traitement du format de date, perspective des graphiques linéaires, etc.).
6. Cache : Les données traitées sont écrites dans le cache ; ou si le cache est directement atteint pendant la requête, les données mises en cache sont directement lues et renvoyées.
7. Rendu unifié du cadre de rendu frontal : renvoie un format de données unifié et le front-end complète le rendu adaptatif des graphiques, des styles, etc.
Optimisation des requêtes : Ⅰ>Cache + roll-up automatique, couvrant 70 % des requêtes de tableaux de bord publics.
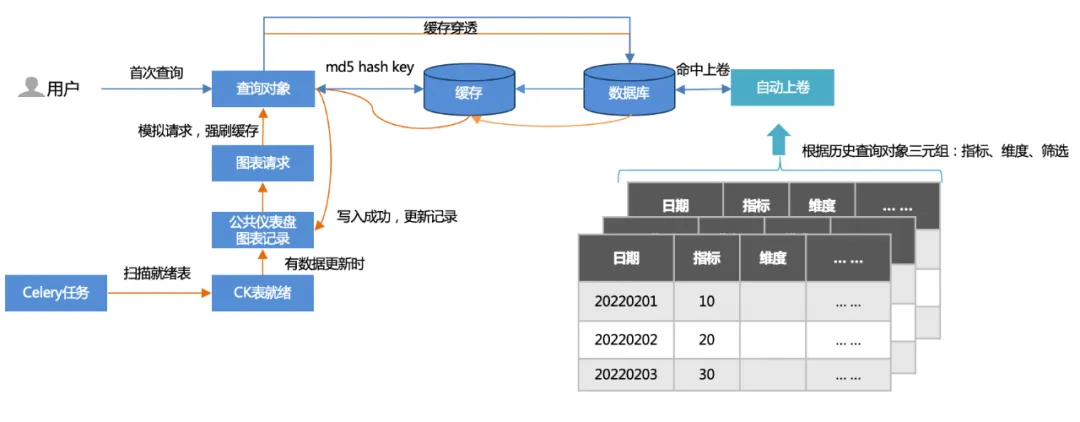
1. Deux méthodes de mise en cache :
Première requête : l'utilisateur accède d'abord (pénétration du cache), interroge la base de données, puis écrit dans le cache.
Préchauffage des tâches hors ligne : analysez les enregistrements de graphiques du tableau de bord public et simulez les demandes de graphiques (plus de 500 par mise à jour) pour forcer le vidage du cache.
2. Remontage automatique :
Sur la base des triples (indicateurs, dimensions, filtrage) des requêtes historiques, une table de cumul est établie et la requête atteint la table de cumul. La quantité de données interrogées est considérablement réduite et les performances sont accélérées.
Optimisation des requêtes : Ⅱ> Optimiser la construction des requêtes SQL et exploiter pleinement les capacités d'agrégation des moteurs d'architecture MPP (tels que clickhouse/palo, etc.).

Dans le scénario d'analyse de l'ensemble de données publiques, après avoir interrogé les données, il est presque impossible de les agréger et de les calculer dans la mémoire (par exemple, (a + b) / c doit être agrégé et calculé sur la base des données détaillées a, b , c), et vous devez utiliser le MPP côté moteur. La capacité de requête de l'architecture affine le calcul d'agrégation côté moteur pour l'exécution, tout comme l'agrégation mensuelle, le volume de données implique des dizaines de milliards, les données le volume après le calcul de l'agrégation côté moteur est réduit des dizaines de fois et les performances sont également améliorées plusieurs fois.
Optimisation des requêtes : III>Requêtes simultanées de noms de domaines multiples, traitement des réponses multi-coroutines.
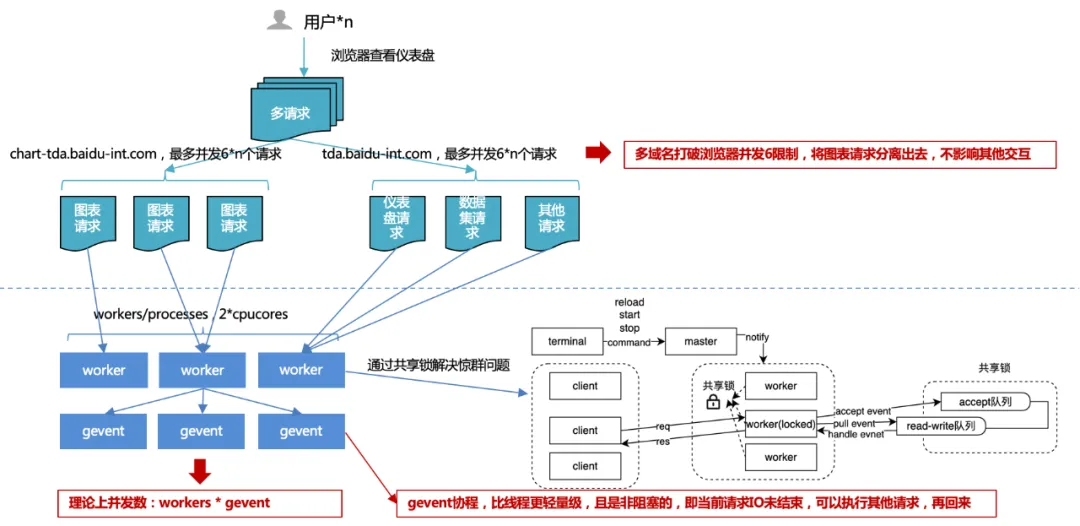
1. Limite de concurrence du navigateur de 6 : en utilisant plusieurs noms de domaine, les demandes de graphiques sont déchargées des autres demandes pour garantir une interaction fluide avec la plateforme et une simultanéité accrue des demandes de graphiques, améliorant ainsi les performances globales.
Considérez les ressources de ports du système d'exploitation : le nombre total de ports PC est de 65 536, donc un lien TCP (http est également TCP) occupe un port. Le système d'exploitation ouvre généralement la moitié du total des ports aux requêtes externes pour éviter que le nombre de ports ne soit épuisé rapidement.
Une concurrence excessive entraîne des problèmes de commutation et de performances fréquents : un thread gère une requête http, donc si le nombre de concurrences est énorme, des changements de thread fréquents se produiront. Et le changement de contexte de thread n’est parfois pas une ressource légère. Cela entraîne plus de pertes que de gains, donc un pool de connexions sera généré dans le contrôleur de requêtes pour réutiliser les connexions précédentes. On peut donc penser que le nombre maximum de pools de connexions sous un même nom de domaine est de 4 à 8. Si tous les pools de connexions sont utilisés, les tâches de requêtes suivantes seront bloquées et les tâches suivantes seront exécutées lorsqu'il y aura des liens libres.
Empêcher un grand nombre de requêtes simultanées du même client de dépasser le seuil de concurrence du serveur : le serveur définit généralement un seuil de concurrence pour la même source client afin d'éviter les attaques malveillantes. Si le navigateur ne définit pas de limites de concurrence pour le même nom de domaine, il le fait. peut entraîner le dépassement du seuil de concurrence du serveur. A été banni.
Mécanisme de conscience du client : Afin d'éviter que deux applications ne s'emparent des ressources, la partie la plus forte obtiendra des ressources sans restriction, provoquant le blocage permanent de la partie la plus faible.
2. Concurrence multi-processus + multi-coroutine côté serveur :
Lors du développement avec plusieurs processus, vous pouvez rencontrer le « problème du troupeau tonitruant », où plusieurs processus attendent le même événement. Lorsqu'un événement se produit, tous les processus seront réveillés par le noyau, mais après le réveil, un seul processus obtient l'événement et le traite. Les autres processus continuent d'entrer dans l'état d'attente après avoir découvert que l'acquisition du temps a échoué. écoutez le même événement, plus il y a de processus, plus le conflit pour le CPU est grave, ce qui entraîne des coûts de contexte importants.
Par conséquent, en réponse à cette situation, le service uwsgi a conçu et implémenté un mécanisme de verrouillage partagé pour garantir qu'un seul processus surveille les événements en même temps, résolvant ainsi le problème du troupeau tonitruant.
Mais même ainsi, le nombre de processus ne peut pas être étendu sans limite : il est généralement recommandé d'être égal à 2 fois le nombre de cœurs de processeur.
Alors puisque le nombre de processus est limité, comment améliorer le débit ? Dans des circonstances normales, IO est bloqué lorsque vous lisez une base de données ou un fichier, le processus ou le thread en cours attendra que l'opération IO renvoie le résultat avant de continuer à exécuter le code suivant. Si nous augmentons le débit grâce au multithreading et rencontrons un blocage des E/S, le thread restera bloqué et les autres requêtes simultanées ne seront pas traitées par le thread. Les E/S asynchrones sont implémentées via des coroutines, c'est-à-dire pour chaque thread, lorsqu'il s'agit d'E/S à la place. Au lieu d'attendre le résultat de l'IO, nous traitons d'abord la nouvelle demande, attendons que l'IO soit terminée, puis revenons au code qui doit attendre l'IO. De cette façon, nous utilisons pleinement chaque thread du programme et avons toujours quelque chose à faire. Cette méthode améliore le débit global et réduit le temps global, sans affecter le temps individuel.
2.2.2 Garantie du système
Abonnez-vous aux alertes :
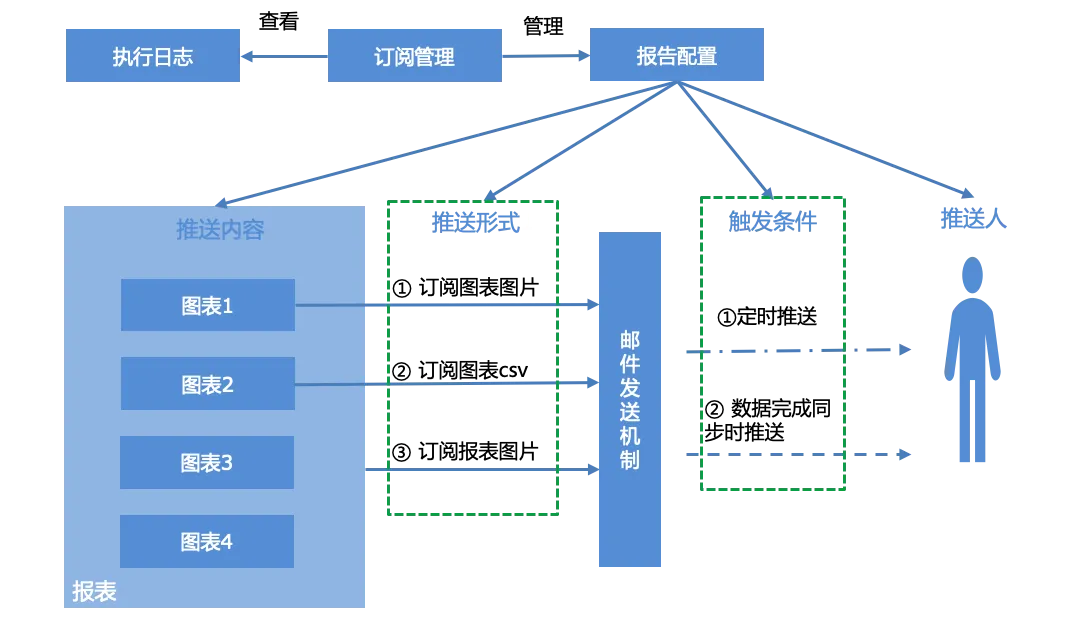
Les utilisateurs peuvent configurer les rapports pour les rapports, gérer les rapports d'abonnement générés en fonction de l'interface de gestion des abonnements et afficher le journal d'exécution du système, c'est-à-dire l'état de diffusion des rapports.
La configuration du rapport comprend principalement quatre parties, le contenu push, le formulaire push, les conditions de déclenchement et le pusher :
Contenu push : graphique unique, rapport complet
Forme push : trois formes de push
Capture d'écran du graphique
Graphique en pièce jointe à un e-mail de données CSV
Capture d'écran du rapport
Conditions de déclenchement :
Push planifié, push planifié basé sur l'expression cron.
Envoyé lorsque la synchronisation des données est terminée. Lorsque les ensembles de données associés à tous les graphiques du rapport terminent la synchronisation des données, les conditions d'envoi sont déclenchées et les notifications par e-mail sont terminées.
Pusher : Compte email, séparé par "," s'il y en a plusieurs.
Autorisations :

Gestion et contrôle hiérarchiques des autorisations de données : basé sur le noyau d'authentification à double couche de l'ensemble de données et du tableau de bord, il prend en charge les autorisations de ligne et de colonne pour demander une autorisation en fonction de la granularité des règles et contrôle de manière flexible les autorisations des utilisateurs.
Collaboration efficace : ouvrez le service d'autorité unifié MPS (système de gestion unifié des autorités), réalisez l'approbation des autorités, la récupération des expirations, le gel des démissions et d'autres capacités, ouvrez un bureau fluide, accélérez la circulation à grande vitesse de l'approbation des autorités.
03 Résumé et planification
3.1 Résumé
Après une itération continue, TDA a essentiellement développé des capacités d'analyse en libre-service à guichet unique et a atteint les indicateurs suivants :
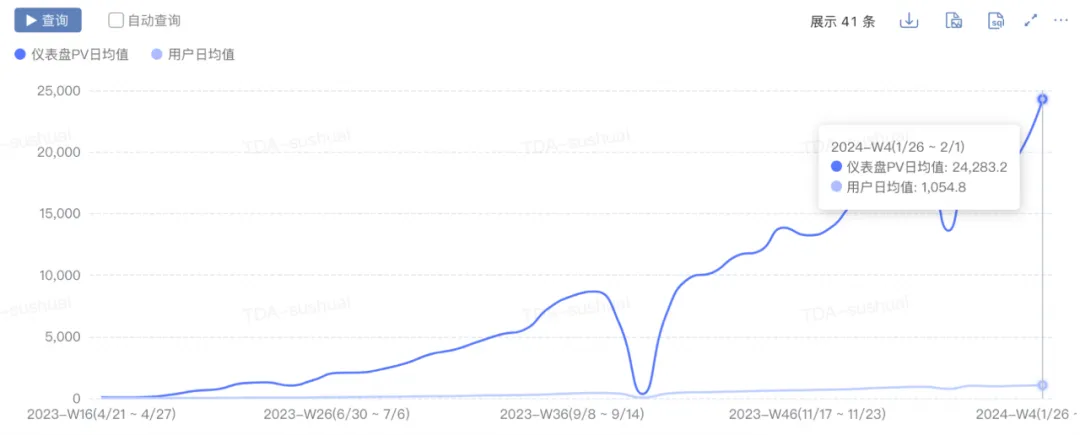
- Croissance de l'échelle : pv est passé de 0 à 2w+, uv a augmenté de 0 à 1000+ et les nouveaux graphiques quotidiens ont augmenté de 0 à 300+.
-
Amélioration des performances : le temps nécessaire pour atteindre le 90e percentile du premier écran du tableau de bord est passé de 10 s+ à 5 s.
-
Amélioration de l'efficacité commerciale : favorisez un taux de libre-service de plus de 80 % pour votre activité principale, multipliez par 20 l'efficacité de l'analyse des fluctuations et analysez l'attribution de bout en bout des fluctuations d'un seul indicateur de 2 heures à 5 minutes.
3.2 Planification
Avec la pénétration de la technologie native de l'IA dans divers domaines, TDA combinera également la technologie de l'IA à l'avenir pour améliorer l'expérience d'analyse intelligente de la plateforme.Les principaux points sont les suivants :
-
Accès aux données en libre-service : l'accès aux données sera libéralisé, les types de sources de données seront élargis, etc.
-
AI+BI : les fonctionnalités de BI telles que l'analyse d'attribution, l'analyse intégrée et les rapports d'analyse sont combinées à l'IA à grand modèle pour améliorer les produits d'analyse intelligents.
-
Cockpit de gestion (Explorer) : tableau de bord des objectifs OKR.
------FIN------
Lecture recommandée
Une brève analyse sur la manière d'accélérer les services commerciaux en temps réel
Évolution du système de connexion, conception et mise en œuvre de connexion pratiques
Cet article vous donnera une compréhension complète de la bibliothèque de base du langage Go IO
Réconciliation du système du Baidu Trading Center
Révéler le secret du moteur informatique de fusion de l'entrepôt de données Baidu
La première mise à jour majeure de JetBrains 2024 (2024.1) est open source. Même Microsoft prévoit de la payer. Pourquoi est-elle encore critiquée pour son open source ? [Récupéré] Le backend de Tencent Cloud s'est écrasé : un grand nombre d'erreurs de service et aucune donnée après la connexion à la console. L'Allemagne doit également être "contrôlable de manière indépendante". Le gouvernement de l'État a migré 30 000 PC de Windows vers Linux deepin-IDE et a finalement réussi démarrage ! Visual Studio Code 1.88 est sorti. Bon gars, Tencent a vraiment transformé Switch en une "machine d'apprentissage pensante". Le bureau à distance RustDesk démarre et reconstruit le client Web. La base de données de terminaux open source de WeChat basée sur SQLite, WCDB, a reçu une mise à niveau majeure.