
L'utilisation de bases de données de séries chronologiques (TSDB) est courante dans diverses industries depuis des décennies, en particulier dans les systèmes de contrôle financier et industriel. Cependant, l'émergence de l'Internet des objets (IoT) a entraîné une augmentation de la quantité de données de séries chronologiques (données de séries chronologiques en abrégé), ce qui a imposé des exigences plus élevées en matière de performances des bases de données et de coûts de stockage, favorisant ainsi le besoin de solutions dédiées. bases de données de séries chronologiques.
Face aux problèmes d'architecture obsolète et d'évolutivité limitée des solutions de séries chronologiques existantes, une nouvelle génération de bases de données de séries chronologiques a émergé. Elles adoptent des architectures modernes qui permettent un traitement distribué et une expansion horizontale, ainsi qu'un déploiement flexible dans le cloud ou sur site.
Fin 2022, un autre produit à succès a rejoint le segment des bases de données de séries chronologiques open source et a été testé et produit par plus de 60 entreprises en seulement un an, attirant plus de 70 contributeurs d'universités et d'entreprises clés du pays et de l'étranger : openGemini, La base de données de séries chronologiques distribuées open source de Huawei se concentre principalement sur le stockage et l'analyse de données de séries chronologiques massives. Grâce à l'innovation technologique, elle simplifie l'architecture du système d'entreprise, réduit le coût de stockage des données de séries chronologiques massives et améliore l'efficacité du stockage et de l'analyse des données. Données de séries chronologiques.
Aujourd'hui, nous avons invité Xiang Yu, le leader de la communauté openGemini, à parler de leur histoire open source~
01 Né de besoins internes et évoluant progressivement vers une auto-recherche
La recherche et le développement d'openGemini sont nés à l'origine des propres besoins de Huawei.
En 2019, avec la création de Huawei Cloud, des centres de données ont été construits à Guangzhou, Shanghai, Pékin, Guizhou et Hong Kong, et plus de 260 services cloud ont été lancés. En moyenne, plusieurs To de données d'indicateurs de surveillance sont collectées chaque jour. . La solution Big Data originale est progressivement dépassée. Plus la quantité de données est importante, plus l'efficacité des requêtes est faible et le coût du stockage des données continue d'augmenter. Il existe un besoin urgent d'une base de données de séries temporelles dédiée à hautes performances et à haute évolutivité.
À cette époque, il n’existait aucun produit de base de données de séries chronologiques utile, capable de suivre l’évolution de la demande. InfluxDB est toujours une version autonome, et Apache IoTDB et TDengine nationaux sont loin de répondre aux exigences de production. Par conséquent, Huawei est déterminé à créer sa propre base de données, à optimiser le traitement des données et à résoudre les problèmes commerciaux très importants du moment. C’est dans ce contexte qu’openGemini est né.
Selon Xiang Yu, en termes de sélection technologique, ils ont initialement effectué une transformation de cluster basée sur l'open source InfluxDB. Cependant, avec l’augmentation du nombre d’indicateurs et l’augmentation de la fréquence de collecte, l’augmentation quotidienne du volume de données a atteint des dizaines de téraoctets. À cette époque, les failles de l'architecture d'InfluxDB ont commencé à devenir apparentes, affectant les performances et la stabilité du système. Ils ont donc choisi de reconstruire l’architecture et ont commencé l’auto-développement du noyau openGemini.
02 Personnalité unique, performances de pointe
Depuis sa création, openGemini a été étroitement lié aux besoins commerciaux de Huawei, de sorte que chaque conception est pleine de considérations pratiques. Plus précisément, openGemini se distingue des autres bases de données de séries chronologiques par neuf « personnalités » majeures :
Avantage en termes de performances : parmi la compétitivité différenciée d'openGemini, la haute performance est la plus importante. Dans les scénarios de données massives, openGemini améliore les scénarios de requêtes simples de plus de 2 fois, les scénarios de requêtes moyens de plus de 5 fois et les scénarios de requêtes complexes de plus de 10 fois par rapport à InfluxDB open source. Par rapport à d'autres produits open source similaires, openGemini présente également des avantages évidents en termes de performances.
Les performances d'écriture autonome officiellement annoncées sont les suivantes (l'outil de test est TSBS, veuillez vous référer à la documentation du site officiel d'openGemini pour les détails des tests pertinents) :

Comparaison des performances des requêtes sur une seule machine annoncée officiellement dans les scénarios DevOps (latence moyenne, ms) :

Comparaison des performances des requêtes sur une seule machine annoncée officiellement dans les scénarios IoT (délai moyen, ms) :
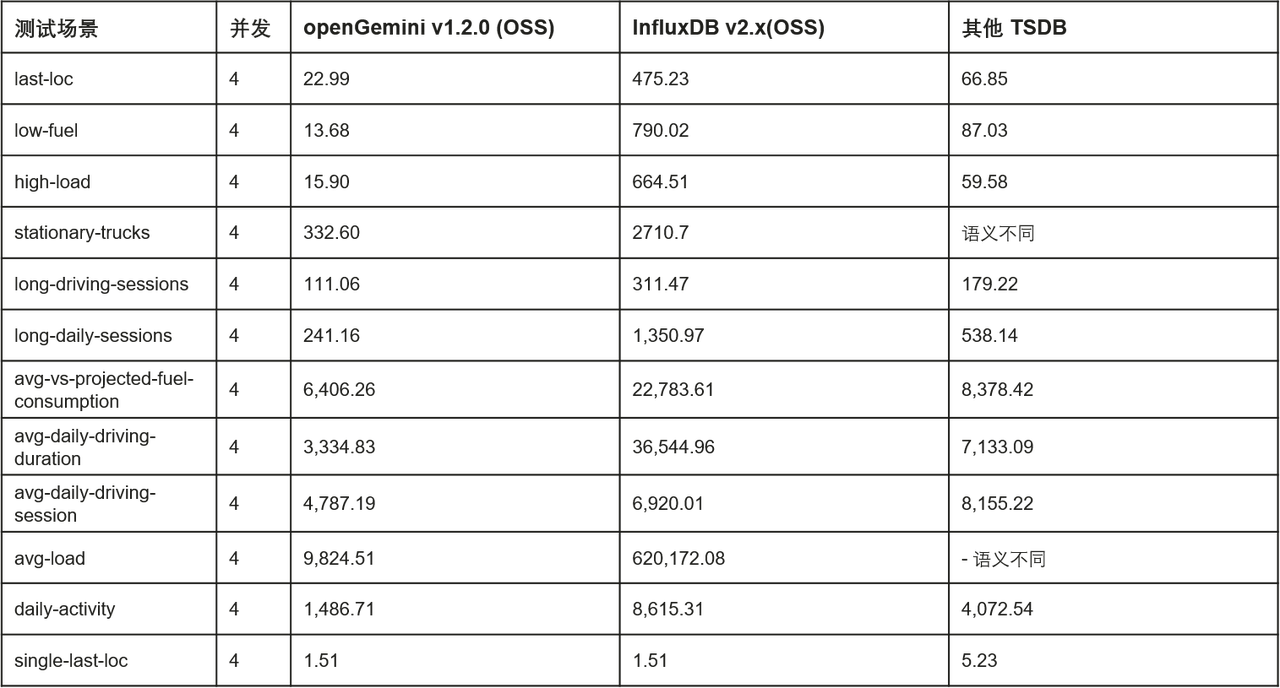
De plus, openGemini a lancé une série de fonctions pratiques de stockage et d'analyse de données pour construire une compétitivité plus différenciée :
Architecture distribuée unique : openGemini propose deux versions : cluster autonome et distribué. Le cluster distribué adopte l'architecture en couches de traitement parallèle massif MPP, qui divise le moteur de calcul, le moteur de stockage et la gestion des métadonnées en composants indépendants. -store et ts-meta respectivement. Différents composants prennent en charge une expansion horizontale indépendante, permettant de répondre avec flexibilité à des scénarios d'application complexes.
Moteur à cardinalité élevée : le problème de cardinalité élevée (également connu sous le nom de désastre de dimensionnalité) entraînera une expansion de l'index inversé, entraînant une consommation excessive de ressources mémoire et une réduction des performances de lecture et d'écriture. Il a longtemps entravé le développement de bases de données de séries chronologiques. Le moteur openGemini à base élevée résout complètement ce problème en créant un index clairsemé spécifique aux séries chronologiques, qui est très approprié pour une utilisation dans la surveillance des réseaux, le contrôle des risques financiers, l'Internet des objets, les transports et d'autres domaines.
Récupération de texte : les données texte sont un type de données courant. openGemini prend en charge la création d'index sur les données texte, adopte une méthode de segmentation de mots d'apprentissage dynamique, prend en charge la correspondance précise, d'expression et floue, et présente une faible utilisation des ressources mémoire et un avantage de récupération élevé.
Agrégation de streaming : l'agrégation de streaming est une méthode de pré-agrégation qui sous-échantillonne les données lors de l'écriture des données. Son objectif est de résoudre le problème des méthodes de sous-échantillonnage traditionnelles qui lisent une grande quantité de données historiques à partir du disque à des fins de calcul, ce qui entraîne une amplification importante des E/S. Le problème.
Sous-échantillonnage à plusieurs niveaux : pour les données historiques existantes, les méthodes de sous-échantillonnage traditionnelles conserveront les détails des données historiques. Dans certains scénarios, les détails des données historiques ne sont pas importants et seules les caractéristiques des données doivent être conservées. La fonction de sous-échantillonnage à plusieurs niveaux peut extraire les caractéristiques des détails des données historiques et remplacer les détails des données historiques en place, ce qui peut réduire davantage. le coût de 50 %.
Détection et prédiction des anomalies : la détection et la prédiction des anomalies sont actuellement l'une des applications les plus matures de l'analyse de données de séries chronologiques et sont largement utilisées dans des scénarios tels que les transactions quantitatives, la détection de la sécurité des réseaux et la maintenance quotidienne des centres de données, des équipements industriels et de l'informatique. Infrastructure. openGemini fournit une bibliothèque de détection d'anomalies - openGemini-castor, qui encapsule des algorithmes de détection pour 13 scénarios d'anomalies courants. Elle présente les avantages d'une vitesse de détection rapide, d'une grande précision et de l'intégration du flux et du lot, aidant les applications à améliorer l'efficacité de l'analyse des données.
Stockage hiérarchisé des données chaudes et froides : prend en charge le transfert de données historiques vers le stockage objet, permettant ainsi une méthode peu coûteuse de conservation permanente des données historiques, et prend également en charge l'analyse hors ligne du Big Data. [Cette fonctionnalité devrait être publiée au deuxième semestre]
Fiabilité des données : prend en charge plusieurs copies informatiques pour améliorer encore la fiabilité des données. [Cette fonctionnalité devrait être publiée au deuxième semestre]

03 Focus sur l'expérience utilisateur, facilitant le démarrage
openGemini a non seulement de solides performances, mais sa conception unique peut également apporter beaucoup d'expérience confortable dans les applications réelles :
En termes de démarrage , openGemini est entièrement compatible avec InfluxDB v1. Dans le même temps, openGemini utilise le même protocole de ligne qu'InfluxDB. La modélisation des données est simple et facile à comprendre, et elle est également conviviale pour les développeurs de bases de données relationnelles. Enfin, openGemini utilise un langage de requête de type SQL, qui ne nécessite aucun apprentissage supplémentaire et est facile à démarrer. Pour le déploiement de cluster, la communauté fournit également l'outil de déploiement en un clic Gemix, qui permet d'économiser beaucoup de travail de configuration.
En termes de systèmes d'exploitation , openGemini prend actuellement en charge les systèmes Linux grand public (y compris openEuler), Windows et MacOS, ce qui rend le développement et le débogage d'applications plus pratiques. Le processeur prend en charge les architectures X86 et ARM64.
En termes de natif du cloud , openGemini fournit des images Dockerfile et Docker, prenant en charge le déploiement de Docker, K8s, KubeEdge et d'autres plates-formes. Étant donné que l'adresse IP change après le redémarrage du conteneur, openGemini a ajouté une fonction de nom de domaine pour garantir que les nœuds du cluster peuvent toujours maintenir la connectivité après le redémarrage du conteneur. La communauté a également créé le projet openGemini-operator pour faciliter le déploiement de conteneurs en un clic par les utilisateurs. openGemini prend en charge la lecture et l'écriture à distance de Prometheus et peut être utilisé comme stockage principal pour Prometheus afin de résoudre son problème de capacité de stockage insuffisante. [d'ailleurs : openGemini prendra également directement en charge PromQL, qui est actuellement en cours de développement]
En termes d'observabilité , la communauté a développé le composant ts-monitor, spécialisé dans la collecte d'indicateurs de nœuds et de noyau. Il est divisé en 19 sous-catégories et plus de 260 éléments. Il peut être utilisé avec Grafana pour réaliser une surveillance complète de l'état de fonctionnement. d'openGemini. Par exemple, des indicateurs tels que l'utilisation du processeur et de la mémoire, la bande passante en écriture, la latence en écriture, la simultanéité d'écriture et le QPS peuvent être visualisés d'un seul coup d'œil via l'interface visuelle, ce qui facilite la visualisation de l'état de fonctionnement, du réglage des performances de la base de données et de l'emplacement précis des problèmes. à tout moment.
04 Après les tests de combat réels internes, redonnez à l'open source
En tant que base de données de séries chronologiques, openGemini est actuellement le plus couramment utilisé dans l'Internet des objets et dans la surveillance de l'exploitation et de la maintenance. En termes de traitement de données massives, il présente des avantages que les bases de données ordinaires ne peuvent égaler. Dans le même temps, openGemini, en tant que projet interne de Huawei, a passé le test de « son propre peuple » :
Huawei Cloud SRE utilise openGemini comme base de stockage des données de surveillance. Au total, 25 clusters sont déployés sur l'ensemble du réseau, avec une taille de cluster maximale de 70 nœuds. Il a résisté avec succès au test réel de 40 millions d'écritures de données par seconde et 50 000 simultanées. requêtes. Par rapport à la solution originale, pour la même activité, le délai de bout en bout du système d'origine est réduit de 50 %, les ressources CPU peuvent être économisées de 68 %, les ressources mémoire peuvent être économisées de 50 % et le disque dur les ressources peuvent être économisées de plus de 90 %.
La plate-forme IoT industrielle de Huawei Cloud utilisait auparavant la version autonome d'InfluxDB. Depuis le passage à openGemini, elle n'a plus à se soucier du débit. Les performances de bout en bout et des requêtes ont augmenté de 3 fois, et le nombre de requêtes. les accès aux appareils ont augmenté jusqu'au niveau du million.
Xiang Yu a présenté qu'openGemini est originaire de l'open source et a beaucoup bénéficié du projet open source InfluxDB. Par conséquent, adhérant à l'esprit de l'open source, tous les codes openGemini sont open source. Il espère que davantage d'entreprises et de développeurs du monde entier en bénéficieront. il, et espère également qu'à travers la communauté ouverte, la plateforme, en collaboration avec les développeurs, promeut conjointement l'innovation technologique et partage les résultats open source.
À l'heure actuelle, openGemini ne propose qu'une version open source et un service cloud. Il n'envisage pas de s'impliquer dans des versions commerciales hors ligne et est prêt à faire un don à la fondation. À l'heure actuelle, la communauté présente encore de nombreuses imperfections.Ensuite, la communauté enrichira davantage les outils écologiques d'openGemini (tels que les outils de migration de données, SDK, intégration écologique du big data, etc.), les interfaces de gestion visuelle, les documents, etc.
« À l'heure actuelle, la planification technique de la communauté se concentrera généralement sur les trois scénarios d'application importants de l'Internet des objets, la surveillance et l'observabilité de l'exploitation et de la maintenance, et renforcera la compatibilité écologique et le renforcement des capacités du noyau des technologies associées. architecture logicielle de génération d'openGemini", a déclaré Xiang Yu.
"À court terme, openGemini n'envisagera pas de scénarios liés à l'industrie, car les scénarios commerciaux dans le domaine industriel sont très complexes, les exigences en temps réel sont extrêmement élevées, les fossés des fabricants de logiciels industriels sont très profonds et les choses qui Les bases de données de séries chronologiques peuvent faire sont limitées.De plus, la communauté manque d'expérience industrielle, nous n'en savons pas assez sur ce scénario, nous envisagerons ensuite de rechercher des partenaires dans le domaine industriel, tels que des fournisseurs de logiciels industriels, des solutions. fournisseurs, etc., pour coopérer et s'améliorer ensemble », a déclaré Xiang Yu.
Page d'accueil du site officiel d'openGemini : https://www.openGemini.org/
Adresse open source openGemini : https://github.com/openGemini
Un camarade de poulet "open source" deepin-IDE et a finalement réalisé l'amorçage ! Bon gars, Tencent a vraiment transformé Switch en une « machine d'apprentissage pensante » Examen des échecs de Tencent Cloud le 8 avril et explication de la situation Reconstruction du démarrage du bureau à distance RustDesk Client Web La base de données de terminal open source de WeChat basée sur SQLite WCDB a inauguré une mise à niveau majeure Liste d'avril TIOBE : PHP est tombé à un plus bas historique, Fabrice Bellard, le père de FFmpeg, a sorti l'outil de compression audio TSAC , Google a sorti un gros modèle de code, CodeGemma , est-ce que ça va vous tuer ? C'est tellement bon qu'il est open source - outil d'édition d'images et d'affiches open source