Les microservices sont immortels : explication détaillée de la mise en œuvre des variables partagées dans le projet de moteur de politique
Others
2024-04-17 01:12:07
views: null
arrière-plan
1. Proposition de variables partagées
Il y a quelque temps, une étude de cas de l’équipe Amazon Prime Video a provoqué un tollé au sein de la communauté des développeurs. Fondamentalement, en tant que plate-forme de streaming, Prime Video propose chaque jour des milliers de flux en direct aux clients. Pour garantir que les clients reçoivent du contenu de manière transparente, Prime Video avait besoin de créer un outil de surveillance pour identifier les problèmes de qualité dans chaque flux consulté par les clients, ce qui imposait des exigences d'évolutivité extrêmement élevées.
À cet égard, l’équipe Prime Video a donné la priorité à l’architecture des microservices. Étant donné que les microservices peuvent décomposer une seule application en plusieurs modules, cela résout non seulement le problème du développement et du déploiement indépendants des outils, mais offre également une disponibilité, une fiabilité et une diversité technique plus élevées pour les applications. En fin de compte, le service de Prime Video se compose de trois parties : le convertisseur multimédia envoie les flux audio et vidéo au tampon audio et vidéo du détecteur ; le détecteur de défauts exécute l'algorithme et envoie des notifications en temps réel lorsque des défauts sont détectés et le troisième composant assure le contrôle ; l’orchestration des processus de service.
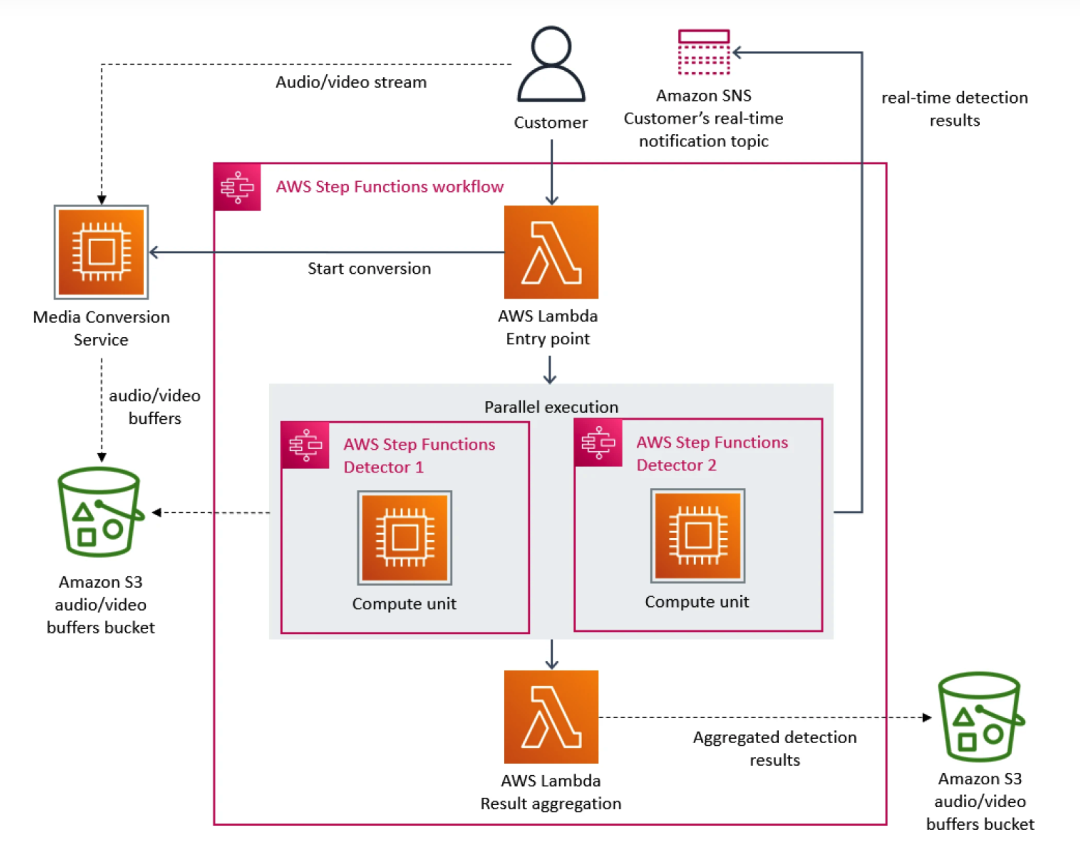 À mesure que de nouveaux flux s’ajoutent au service, le problème du coût excessif commence à apparaître. Étant donné qu'AWS Step facture les utilisateurs en fonction des transitions d'état des fonctions, lorsqu'un grand nombre de flux doivent être traités, les frais généraux liés à l'exécution de l'infrastructure à grande échelle deviennent très coûteux. Le coût total de tous les éléments de base est trop élevé, ce qui empêche Prime Video. l’équipe d’accepter la solution initiale à grande échelle. Au final, l'équipe Prime Video a restructuré l'infrastructure et a migré des microservices vers une architecture monolithique. Selon leurs données, les coûts d'infrastructure ont été réduits de 90 %.
Cet incident nous a également fait prendre conscience que l'architecture distribuée présente également des défauts par rapport à l'architecture à service unique. Par exemple, l'équipe Prime Video a rencontré un problème : l'architecture distribuée ne peut pas partager des variables comme l'architecture monolithique, ce qui oblige le service sous-jacent à traiter davantage de requêtes identiques, ce qui entraîne une flambée des coûts. Ce dilemme existe également dans l’architecture étrangère d’iQiyi, notamment dans la relation d’appel du moteur stratégique.
À mesure que de nouveaux flux s’ajoutent au service, le problème du coût excessif commence à apparaître. Étant donné qu'AWS Step facture les utilisateurs en fonction des transitions d'état des fonctions, lorsqu'un grand nombre de flux doivent être traités, les frais généraux liés à l'exécution de l'infrastructure à grande échelle deviennent très coûteux. Le coût total de tous les éléments de base est trop élevé, ce qui empêche Prime Video. l’équipe d’accepter la solution initiale à grande échelle. Au final, l'équipe Prime Video a restructuré l'infrastructure et a migré des microservices vers une architecture monolithique. Selon leurs données, les coûts d'infrastructure ont été réduits de 90 %.
Cet incident nous a également fait prendre conscience que l'architecture distribuée présente également des défauts par rapport à l'architecture à service unique. Par exemple, l'équipe Prime Video a rencontré un problème : l'architecture distribuée ne peut pas partager des variables comme l'architecture monolithique, ce qui oblige le service sous-jacent à traiter davantage de requêtes identiques, ce qui entraîne une flambée des coûts. Ce dilemme existe également dans l’architecture étrangère d’iQiyi, notamment dans la relation d’appel du moteur stratégique.
2. Relation d'appel du moteur de stratégie à l'étranger iQiyi
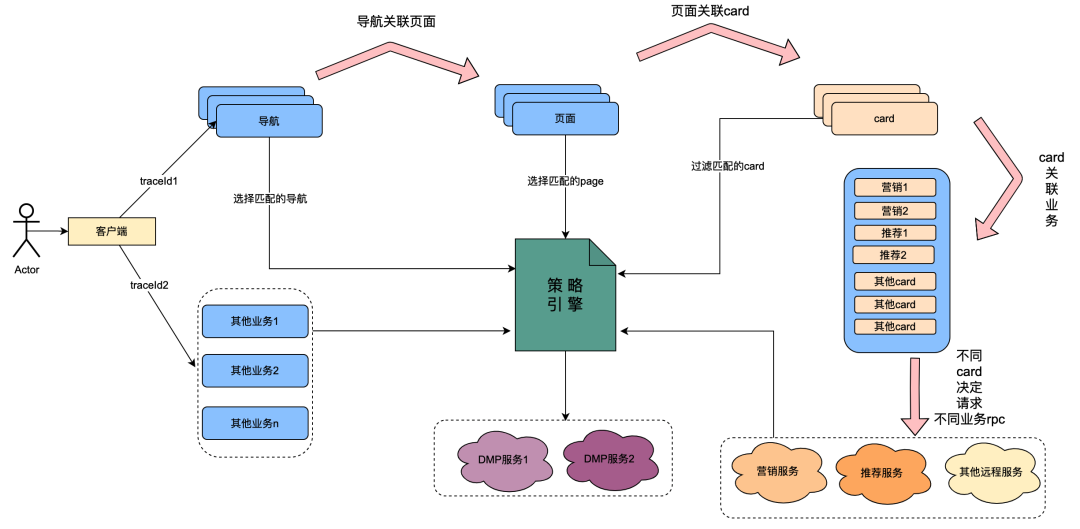
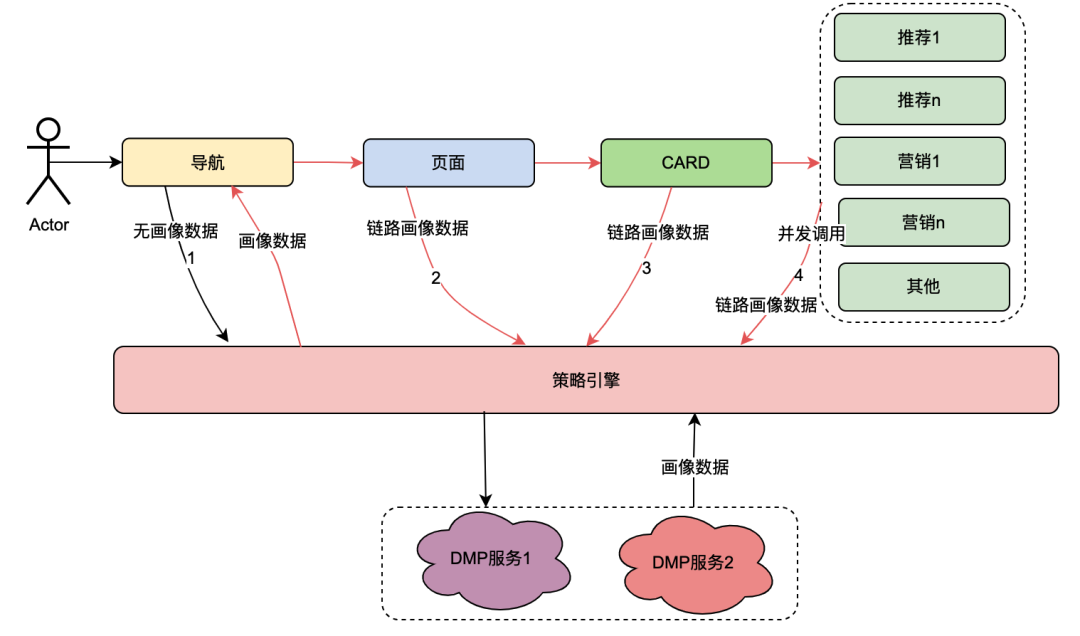
2.1 Introduction à la relation d'appel du moteur de politique
Parmi eux, la carte est le module de subdivision de chaque colonne de la page. Habituellement, les colonnes telles que les séries télévisées et les films constituent une seule carte. Les sources de données de chaque carte sont différentes, telles que les données marketing obtenues grâce au marketing, le contenu obtenu à partir des recommandations, le contenu du programme obtenu à partir de Chip, etc. Il existe une relation d'association. Par exemple, la page est associée sous la navigation, la carte est associée sous la page et les données professionnelles spécifiques de la carte sont associées sous la carte.
Le moteur de stratégie est un service de correspondance permettant d'identifier des groupes de personnes. Par exemple, une stratégie de groupe est actuellement configurée, qui contient des membres Gold japonais, des hommes, des jours d'expiration d'adhésion inférieurs à 7 jours et une préférence pour les anime japonais. Le service de moteur de stratégie peut identifier si un utilisateur appartient aux stratégies de groupe ci-dessus.
Après la transformation technologique du « tout est permis », la possibilité de personnaliser les dimensions du profil utilisateur en matière de navigation, de pages, de cartes et de données contenues dans les cartes a été obtenue. L'implémentation générale est la suivante : lorsque le client initie une requête, il demande d'abord l'API de navigation. En arrière-plan de configuration des données de navigation, les étudiants en opérations ont configuré différentes données de navigation, et chaque élément de données de navigation était associé à une stratégie. L'API de navigation obtient en interne toutes les données de navigation, puis utilise la stratégie associée à la navigation ainsi que l'ID utilisateur et l'ID de l'appareil comme paramètres d'entrée pour demander au moteur de stratégie. Le moteur de stratégie correspondra et renverra la stratégie correspondante. la navigation avec la politique qui répond aux exigences. Les données sont renvoyées, permettant ainsi à différents portraits d'utilisateurs de voir différentes données de navigation. Les pages, les cartes et les données contenues dans les cartes sont implémentées à peu près de la même manière.
À partir du contenu ci-dessus, on peut résumer que le lien appelant du moteur de politique présente les caractéristiques suivantes :
(1) Une opération d'un utilisateur ouvrant une page appellera plusieurs services de moteur de politique en série.
(2) Les performances de l’interface du moteur de politiques affectent directement l’expérience utilisateur : elle associe les requêtes de nombreux services métiers de pages.
(3) Les données du moteur de stratégie nécessitent une forte nature en temps réel : après qu'un utilisateur achète un abonnement, elles doivent être immédiatement associées aux stratégies liées aux membres.
2.2 Dilemmes rencontrés
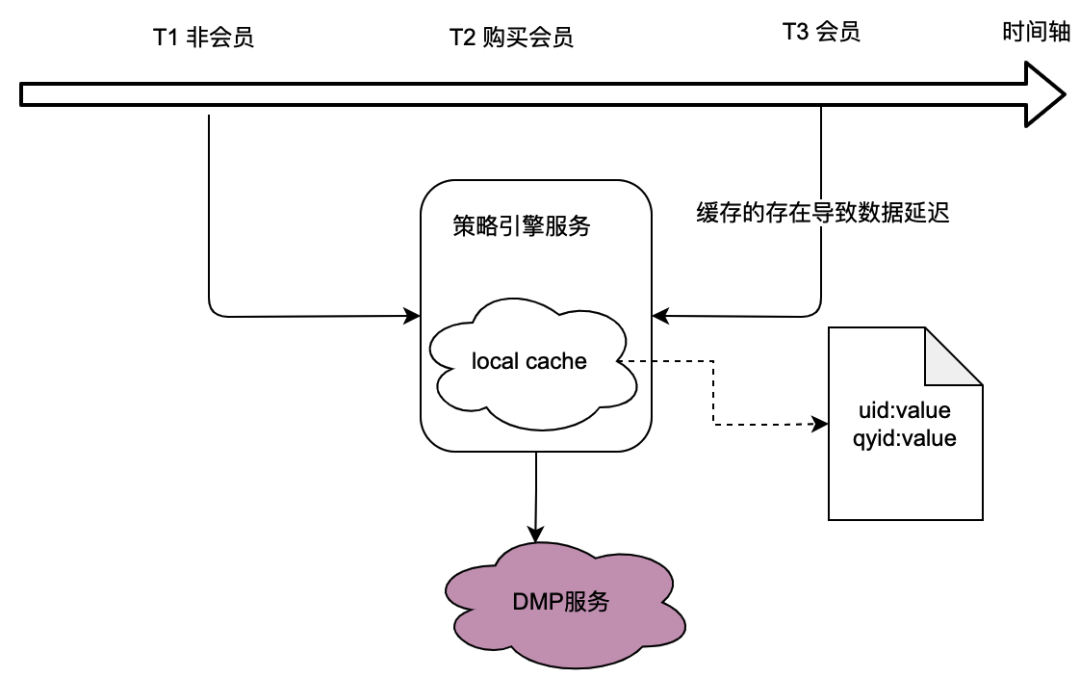
Comme le montre la relation d'appel de la section précédente, le moteur de politique, en tant que service sous-jacent, prend en charge le trafic de nombreuses parties commerciales, et le moteur de politique doit obtenir des données sur le portrait de l'utilisateur pour déterminer si la politique de foule correspond, ce qui dans à son tour, il s'appuie fortement sur le service DMP (Data Management Platforms). Afin de réduire le trafic vers le service DMP, nous avons envisagé une solution de mise en cache locale.
Cependant, le problème est évident, c'est-à-dire qu'il ne peut pas répondre aux exigences en matière de données en temps réel . Lorsqu'un utilisateur achète un abonnement et que les données portrait renvoyées par le service DMP changent, l'utilisateur ne peut pas voir les dernières données liées à la politique en raison du retard de la mise en cache locale, ce qui est évidemment intolérable.
Nous avons également envisagé des solutions de mise en cache distribuée. Si l'ID utilisateur est utilisé comme clé, le problème est le même que celui du cache local, qui ne peut pas répondre aux exigences en temps réel.
Par conséquent, comment optimiser le trafic vers les services DMP tout en répondant aux exigences de données en temps réel constitue un défi pour l’optimisation de l’ensemble du projet de moteur de politique.
L’aube des variables partagées
1. Vue d'ensemble
Le nœud du dilemme réside dans le fait que les services distribués ne peuvent pas partager de variables. Le comportement d'ouverture de page d'un utilisateur s'accompagne de plusieurs requêtes backend, et les données de profil utilisateur associées à ces multiples requêtes backend en sont en fait une, c'est-à-dire que les données de profil obtenues à partir du service DMP doivent être les mêmes. Ensuite, nous effectuons une analyse abstraite du lien d’appel du moteur de politique pour voir quelles sont ses fonctionnalités.
2. Analyse des liens d'appel du moteur de politique
La relation d'appel du moteur de politique a été introduite dans le chapitre 1.2.1 Introduction à la relation d'appel du moteur de politique. Cette fois, nous classons principalement de manière abstraite ses liens d'appel.
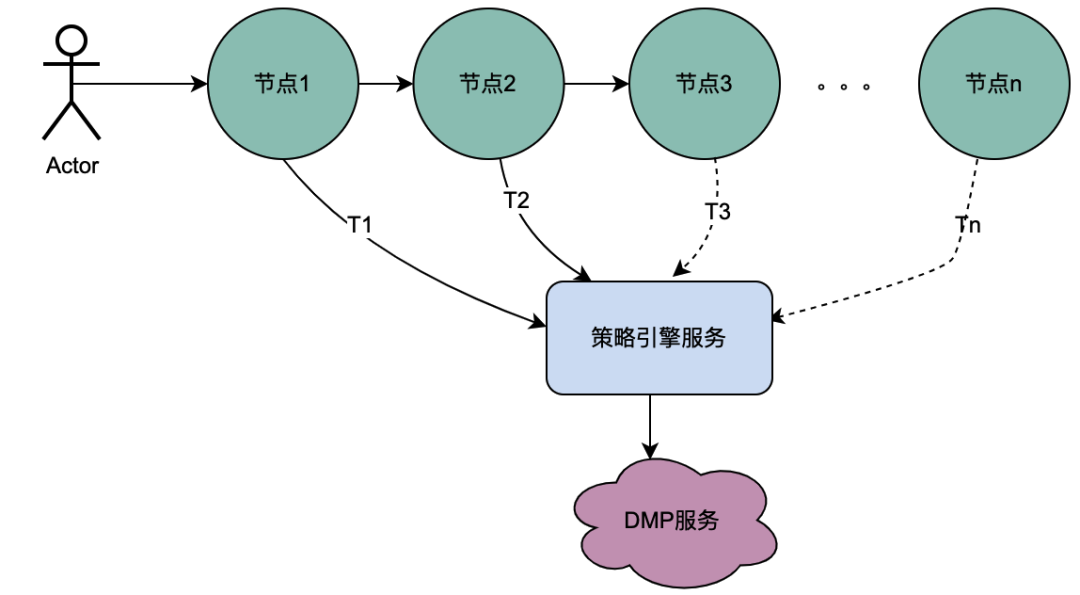
2.1 Scénario d'appel en série
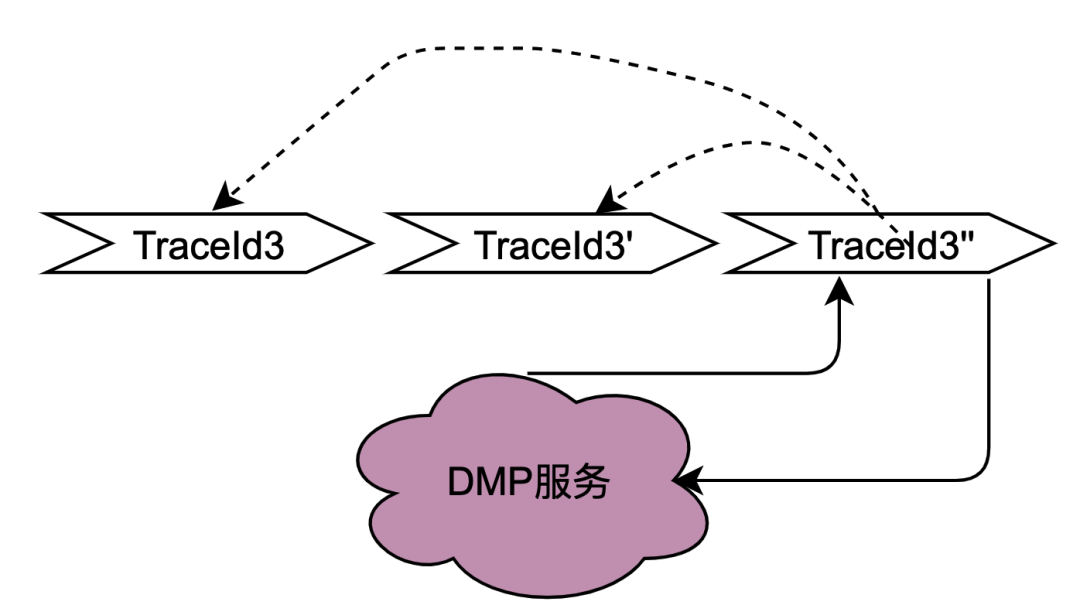
Comme vous pouvez le voir sur la figure ci-dessus, un utilisateur lance une requête et passe par plusieurs services de nœuds. Les services de nœuds sont dans une relation en série, et chaque nœud s'appuie sur le service de moteur de politique. Le service de moteur de politique doit obtenir le portrait de l'utilisateur. data. et évidemment, les requêtes de T1 à Tn proviennent toutes du même utilisateur, et les données obtenues par le service DMP doivent être les mêmes. Ensuite, si l'idée de variables partagées est utilisée, les requêtes au DMP. le service de T1 à Tn peut être optimisé à 1 demande. Nous nommons ici les données de portrait obtenues à partir du service DMP variables partagées distribuées .
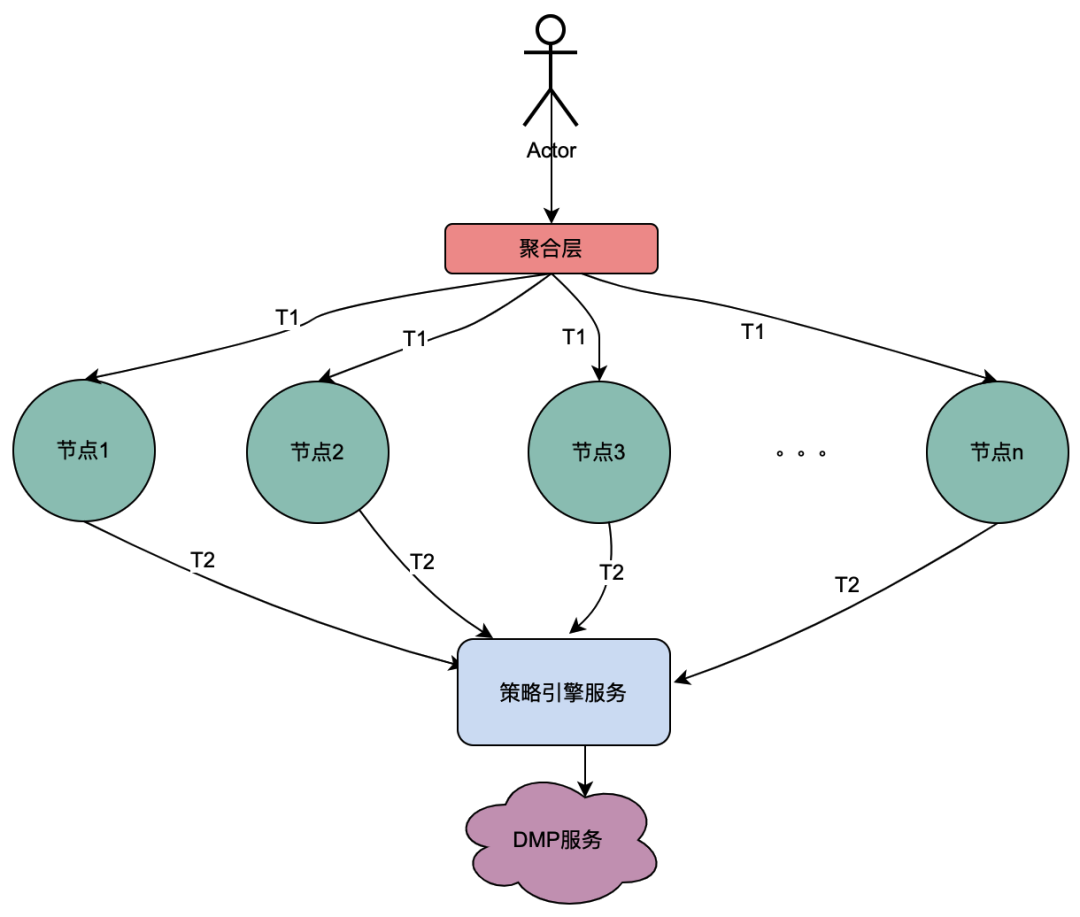
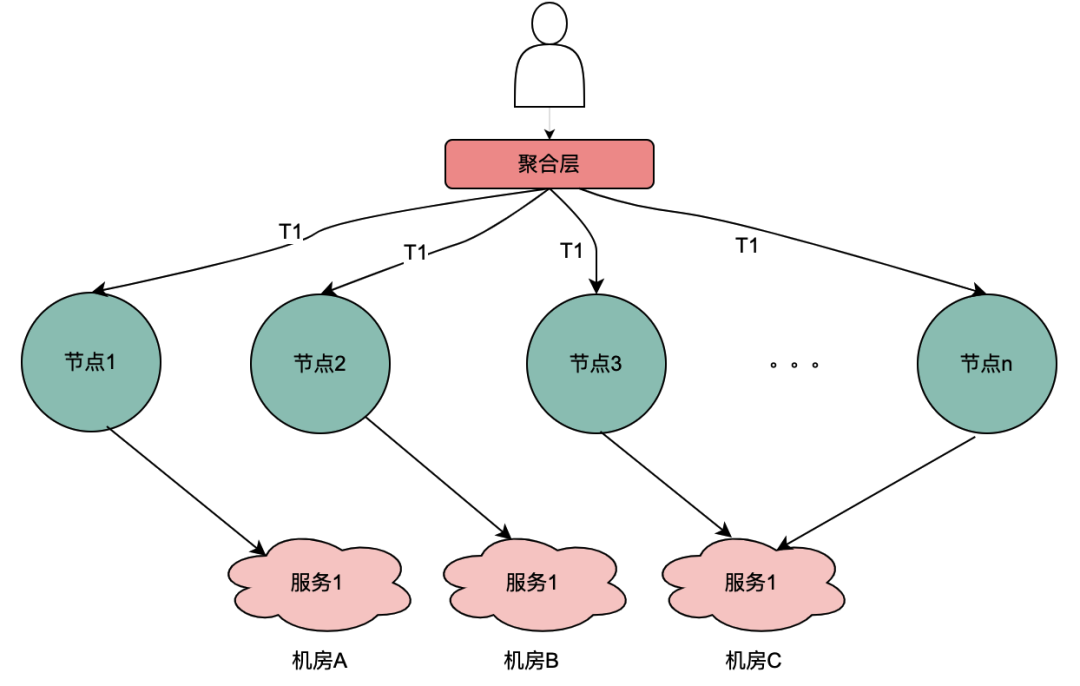
2.2 Scénario d'appel parallèle
À la différence de la chaîne d'appels série ci-dessus, les appels série T1 à Tn sont séquentiels dans le temps et l'appel T1 doit être antérieur à l'appel T2. Il n'y a pas de séquence temporelle pour les appels parallèles, c'est-à-dire que le même utilisateur peut lancer une demande et que l'entreprise de la couche d'agrégation peut lancer une demande au service dépendant en même temps, et le service dépendant dépend donc du moteur de politique. une requête initiée par le même utilisateur sera exécutée en même temps. Effectuez plusieurs requêtes au moteur de politique. Ensuite, si plusieurs requêtes sont placées dans une file d'attente, la première requête demande réellement le service DMP et les requêtes restantes attendent dans la file d'attente les données de la première requête, n requêtes peuvent être optimisées en 1 requête. Nous appelons ici les données de portrait obtenues à partir du service DMP variables locales partagées .
Introduction aux variables partagées distribuées
1. Aperçu des principes
Lorsque l'utilisateur ouvre la page, le client demandera la navigation, puis obtiendra successivement la page de fonctionnalités, la carte spécifique et les données de la carte de fonctionnalités. Chaque lien implique le service du moteur de politique. Dans des circonstances normales, une demande client déclenchera plusieurs appels au moteur de stratégie, provoquant ainsi plusieurs appels au service DMP. Mais évidemment, il s'agit d'une demande du même utilisateur, et les données du portrait de l'utilisateur obtenues par ces demandes au service DMP doivent être les mêmes.
Sur la base de l'analyse ci-dessus, une description simple du principe des variables partagées distribuées est que lorsque [Navigation] obtient les données du portrait pour la première fois, il place son contenu dans le lien de requête et le transmet de la même manière que le TraceId du fichier complet. lien. De cette façon, lorsque l'aval tel que [Page] demande à nouveau le moteur de stratégie, il peut directement obtenir les données de lien dans le contexte de lien TraceContext sans demander le service DMP. Pour CARD, il en va de même pour le secteur des pages.
Il convient de mentionner que TraceContext ne peut être transmis que via une demande. De cette manière, lorsque les données de lien sont stockées, les données de portrait ne peuvent être placées dans le contexte de lien TraceContext qu'après que [Navigation] ait obtenu les données du moteur de stratégie.
如果导航没有关联策略数据,无需请求策略引擎,但是后面的页面、CARD等又关联了策略引擎,那该怎么处理呢?我们参考了TraceId的处理方式,在每个调用策略引擎服务的节点(不同业务如页面、CARD等)进行判断是否有链路数据,如果没有,则获取策略引擎数据后放置进去,如果有则忽略。这样就保证最前置的节点拿到画像数据后,进行向后传递,减少后续节点对于DMP服务的流量。很明显,这些逻辑有一些业务侵入性,所以我们将调用策略引擎的方式优化为SDK调用,在SDK内部做了一些统一的逻辑处理,让业务调用方无感知。
2、全链路追踪 — 基于SkyWalking
skywalking 是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器化技术(docker、K8s、Mesos)架构而设计,它是一款优秀的 APM(Application Performance Management)工具。skywalking 是观察性分析平台和应用性能管理系统。提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。对于为什么选择skywalking,除去skywalking本身的优势以外,业务上的理由是爱奇艺海外项目目前已经接入SkyWalking,开发成本最低,维护更加便利。所以,使用skywalking传递分布式共享变量只需要引入一个Maven依赖,调用其特有的方法,就可以将数据进行链路传递。
分布式共享变量的方案会增加网络传递数据的大小,增加网络开销;当链路数据足够大的时候甚至会影响服务响应性能。因此控制链路数据大小、链路数据的控制和评估链路数据对网络性能造成影响是尤为重要的。下面将详细介绍。
3、链路传输优化 — 压缩解压缩
3.1 压缩基本原理
目前用处最为广泛的压缩算法包括Gzip等大多是基于DEFLATE,而DEFLATE 是同时使用了 LZ77 算法与哈夫曼编码(Huffman Coding)的一种无损数据压缩算法。其中 LZ77 算法是先通过前向缓冲区预读取数据,然后再向滑动窗口移入(滑动窗口有一定的长度), 不断寻找能与字典中短语匹配的最长短语,然后通过标记符标记,依次来缩短字符串的长度。哈夫曼编码主要是用较短的编码代替较常用的字母,用较长的编码代替较少用的字母,从而减少了文本的总长度,其较少的编码通常使用构造二叉树来实现。
3.2 压缩选型
由于BI获取的用户画像TAG固定且个数较少,因此这里选择DMP数据作为实验对比数据。以下是不同场景下压缩大小对比数据

方案3得到的数据最小,因此选择方案3作为分布式共享变量的压缩方案。
4、数据大小导致的网络消耗分析和极端情况控制
4.1 背景概述
这种方案也存在一些弊端,即需要把用户画像数据通过网络传递,显然这增加了网络开销。理论上,网络数据量与传输速度成正比,但是在工程实践中,带宽肯定是有上限的,因此,对于DMP画像数据存入大小进行压测试验,以确定分布式共享变量对于网络性能的影响。
4.2 压测方案
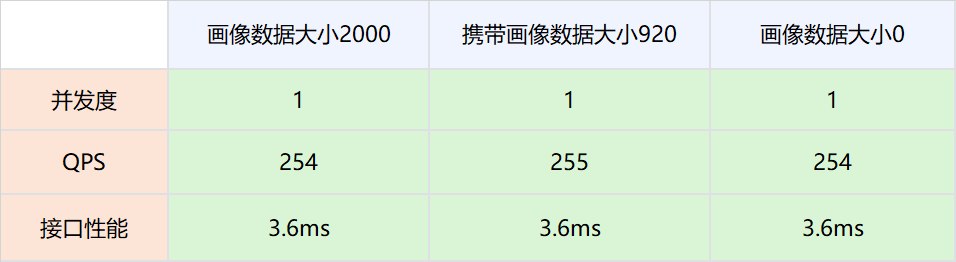
1.测试网络,画像数据不被策略引擎使用,策略引擎依然请求DMP服务。
实验组是请求策略引擎服务的时候带入压缩后的画像数据,对照组是请求策略引擎服务的时候不带入压缩后的画像数据。调整并发值,比较在不同QPS场景下两者的接口性能。
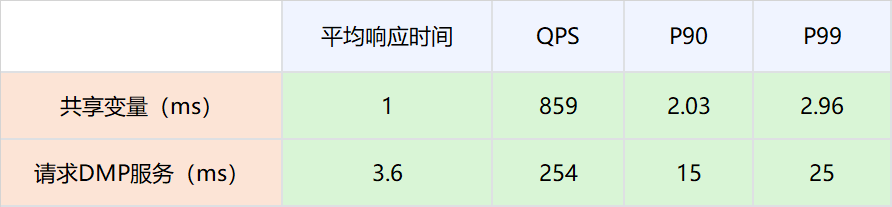
2.分布式共享变量的画像数据被策略引擎使用,策略引擎在有分布式共享变量画像数据的时候,不再请求DMP服务。
4.3结论
-
网络链路上存放数据大小在2000以下,对网络性能的影响可以忽略不计。
-
因为分布式共享变量的存在而减少对DMP服务的请求,接口性能可以有比较大的提升。具体数值为P99从25ms提升到2.96ms。
4.4 极端情况控制
因为DMP数据与用户行为相关,比如一个用户在海外站点所有站点都有购买会员的行为,那么其DMP画像数据就会很大。为了防止这种极端情况所以在判断压缩后的用户画像数据足够大的时候,将自动舍弃,而不是放入网络当中,防止大数据对整个网路数据的性能损耗。
5、线上运行情况
5.1 性能优化
|
|
|
|
|
|
|
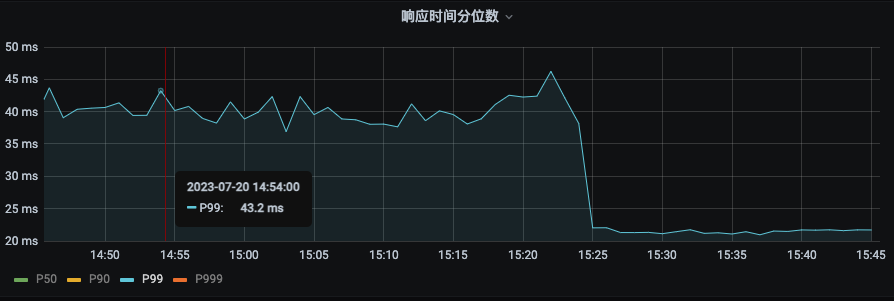
P99 由之前的43ms下降到22ms。下降幅度 48.8%
|
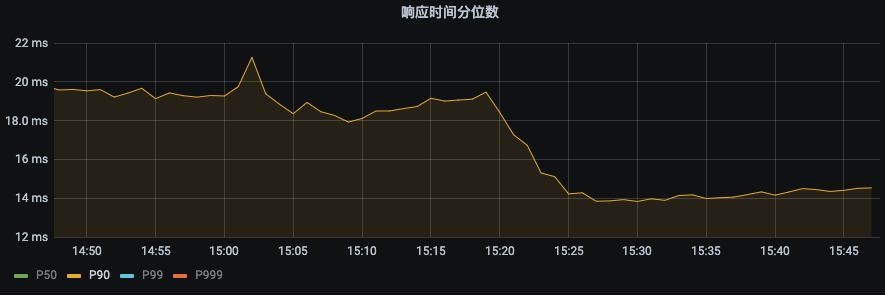
P90由之前19ms下降到14ms,下降幅度26.3%
|
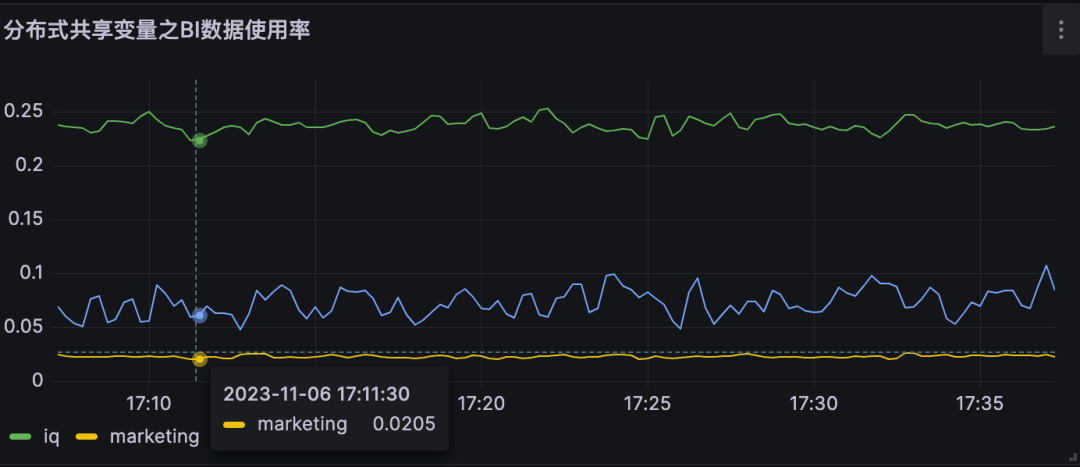
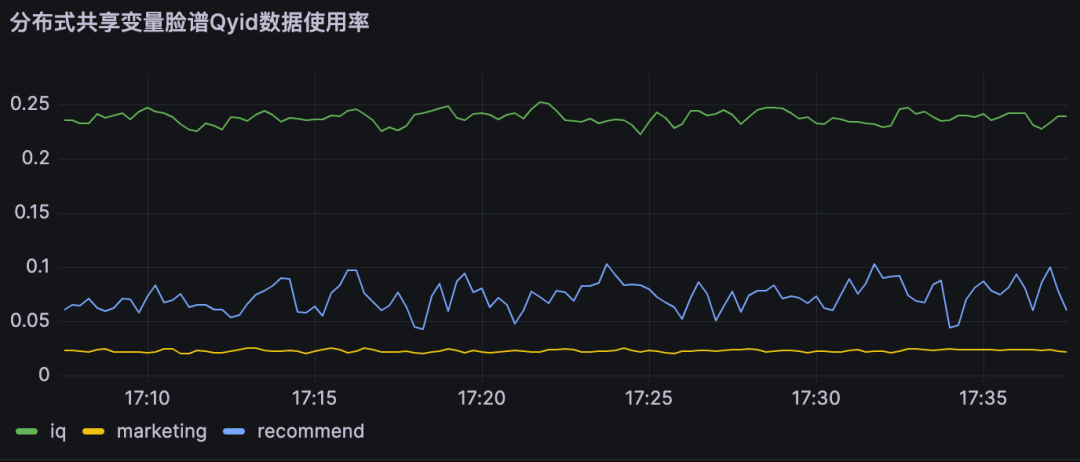
5.2 对DMP服务的流量优化
|
|
|
|
|
分布式共享变量使用率即为对不同DMP服务优化流量。
A业务节约大约25%的流量,B业务节约约10% 的流量,
|
|
|
|
|
6、结论
分布式共享变量在满足数据实时性要求的前提下,减少了对DMP服务的流量,同时提高了策略引擎服务的接口性能,具体优化指标见上节。
本地共享变量介绍
1、原理概述
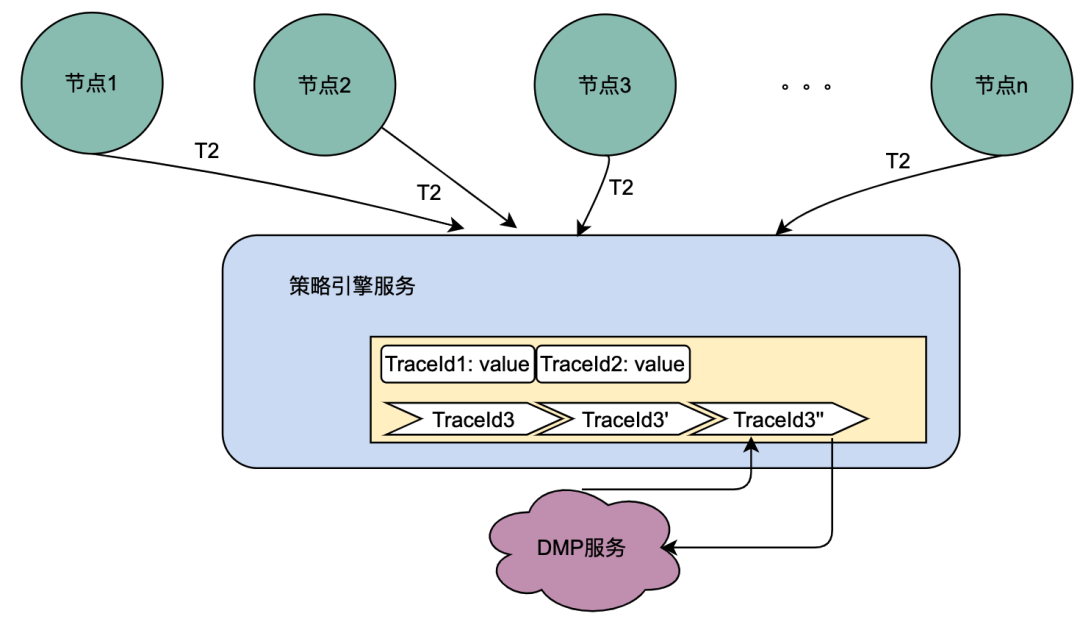
在2.2.2 并行调用场景章节对本地共享变量解决的调用场景进行了阐述,主要解决的是同一个用户并发请求策略引擎带来的多次请求DMP服务问题。如何区分是同一个用户的同一次请求呢?答案是TraceId。在一个请求下,TraceId一定是相同的,如果TraceId相同,那么策略引擎则可以认为是同一个用户的一次请求。
如上图,如果同时多个TraceId3的请求到达策略引擎,将这些请求放入队列,只要其中一个去获取用户画像数据(此处为TraceId3''),其余的请求TraceId3和TraceId3'在队列中等待TraceId3''的结果拿来用即可。
这种思路可以很好的优化并发请求的数据,符合策略引擎调用特性。实现起来有点类似AQS,开发落地有一些难点,比如Trace3''什么时候去请求DMP服务,当拿到数据后,后面仍然有其他trace3进来该如何处理,等待多少时间?这么一思考,这个组件的实现将会耗费我们很多的开发时长,那么有没有现成的中间件可以用呢?答案是本地缓存框架。
无论是本地缓存Caffeine 还是Guava Cache,有相同key的多个请求,只有一个key会请求下游服务,而其他请求会等待拿现成的结果。另外存放的时间可以通过配置缓存的失效时间来确定,至于失效时间的计算方法,将在下面章节会介绍。
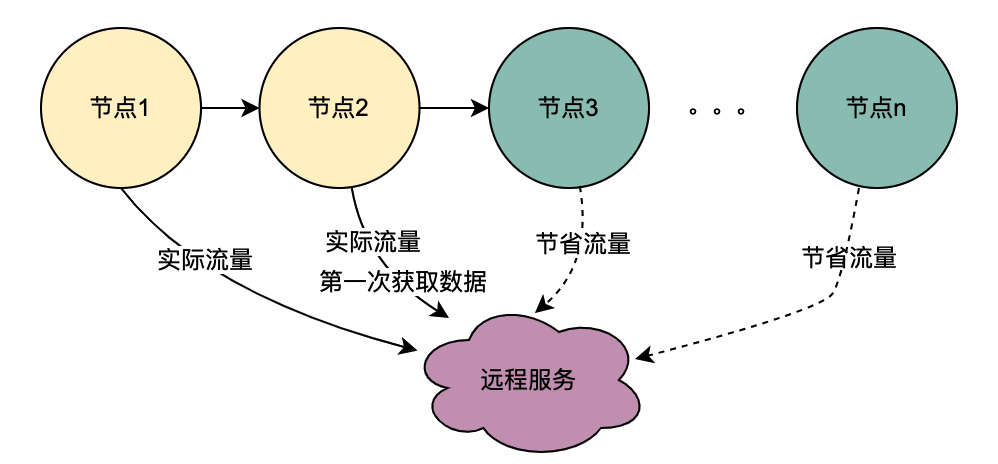
2、网关层Hash路由方式的支持
目前,主流的服务一般都是多机房多机器部署,这样有水平扩展能力可以应对业务增长带来的流量增加的问题。但同一个用户的同一个请求,很可能到不同的服务实例,这样上一次获取到的本地缓存数据在下一次请求当中就无法获取。
如上图,同一个用户的同一次请求,被聚合层并发请求到不同业务节点1到节点n。由于策略引擎服务是多实例部署,那么不同节点的请求可能到不同实例,那么本地共享变量的命中率就会大大降低,对DMP服务的流量节约数据就会小很多。因此,需要一个方案使得用户的多次请求能到同一个机房的同一个实例。
最终落地的方案是网关支持按照业务自定义字段Hash路由。策略引擎使用qyid进行hash路由,即同一个设备的所有请求到策略引擎服务,那么路由到的机器实例一定是同一个。这样可以很好的提升本地共享变量的命中率。这里提一下,相比轮询请求,字段Hash方式存在如流量偏移的问题,需要配合服务实例流量的监控和报警,避免某些实例流量过多而导致不可用。由于和本次主题无关,实例流量的监控和报警在这里就不做介绍。
3、本地共享变量个数和有效时间设计
和本地缓存不同,本地共享变量的最大个数和过期时间与命中率不成正比,这和具体业务指标相关。
假设策略引擎服务QPS10000,服务实例有50台,那么每台实例的QPS是200,即一台服务实例每秒的请求是200个。只需要保证,同一个TraceId的一批请求,在个数区间内不被淘汰,在时间区间内不被过期即可。我们通过网关日志查找历史上同一个traceId的请求时间戳,几乎都在100ms内。
那么过期时间设置为1s,最大个数设置为200个就可以保证绝大多数同一个TraceId的批次请求,只有一个请求下游服务,其余从缓存获取数据。我们为此也进行了实验,设置不同的过期时间和缓存最大个数,结论和以上分析完全一致。
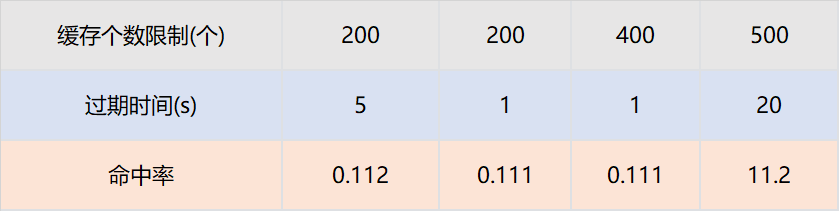
本地共享变量命中率与接口QPS和相同TraceId并发时间相关。
4、结论
-
对于DMP服务1,优化流量15.8%。对于DMP服务2,优化流量 16.7%。对于DMP服务3,优化流量16.2%。
-
与分布式共享变量一样,本地共享变量同样可以满足数据实时性要求,即不会存在1.2.2 遇到的困境 所遇到的缓存导致的数据实时性不够的问题。
总结和展望
本次优化是比较典型的技术创新项目。是先从社区看到一篇技术博客,然后想到爱奇艺海外遇到相同痛点问题的的项目,从而提出优化因为微服务导致的策略引擎对于DMP服务流量压力的目标。
在落地过程中,遇到使用本地缓存进行优化而无法克服数据实效性问题的挑战。最终沉下心分析策略引擎的调用链路,将调用链路一分为二:串行调用和并行调用,最终提出了共享变量的解决方案。因为串行调用和并行调用的特点迥异,依次针对两者进行分期优化,其中第一期通过分布式共享变量优化了串行调用DMP服务的流量,在第二期通过本地共享变量优化了并行调用DMP服务的流量。
参考文章:

也许你还想看
低代码、中台化:爱奇艺号微服务工作流实践
揭秘内存暴涨:解决大模型分布式训练OOM纪实
分布式系统日志打印优化方案的探索与实践
本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Origine my.oschina.net/u/4484233/blog/10924140