
Auteur|Cheng Wei, ingénieur R&D Big Data MetaAPP
ByConity est l'entrepôt de données cloud natif open source de ByteDance. Il répond aux besoins des utilisateurs d'entrepôts de données en matière d'expansion et de contraction élastiques des ressources, de séparation lecture-écriture, d'isolation des ressources, de forte cohérence des données, etc., tout en offrant également d'excellentes performances de requête et d'écriture.
MetaApp est l'un des principaux développeurs et opérateurs de jeux en Chine, qui se concentre sur la distribution efficace des informations mobiles et s'engage à construire un monde virtuel pour tous les âges. En 2023, MetaApp compte plus de 200 millions d'utilisateurs enregistrés, a collaboré sur 200 000 jeux et a un volume de distribution cumulé de plus d'un milliard.
MetaApp a prêté attention à ByConity dès les débuts de l'open source et a été l'un des premiers utilisateurs à le tester et à le lancer dans l'environnement de production. Dans l’idée de comprendre les capacités des projets d’entrepôt de données open source, l’équipe R&D big data de MetaApp a mené un test préliminaire sur ByConity. Son architecture de séparation stockage-calcul et ses excellentes performances, en particulier dans les scénarios d'analyse de journaux, sa prise en charge de requêtes complexes sur des données à grande échelle, ont incité MetaApp à effectuer des tests approfondis de ByConity et ont finalement remplacé complètement ClickHouse dans l'environnement de production, réduisant ainsi les coûts des ressources. de plus de 50 %.
Cet article présentera principalement les fonctions de la plateforme d'analyse de données MetaApp, les problèmes et solutions rencontrés dans les scénarios commerciaux, et l'aide à l'introduction de ByConity dans son activité.
Architecture et fonctions de la plateforme d'analyse de données MetaApp OLAP
Avec la croissance de l'activité et l'introduction d'opérations raffinées, les produits ont imposé des exigences plus élevées au service des données, notamment la nécessité d'interroger et d'analyser les données en temps réel et d'ajuster rapidement les stratégies opérationnelles pour mener des expériences AB sur un petit groupe de personnes ; vérifier l'efficacité des nouvelles fonctions. Il réduit le temps et la difficulté d'interrogation des données, permettant aux non-professionnels d'analyser et d'explorer les données de manière indépendante. Afin de répondre aux besoins de l'entreprise, MateApp a mis en œuvre une plateforme d'analyse de données OLAP qui intègre l'analyse des événements, l'analyse des conversions, la rétention personnalisée, le regroupement d'utilisateurs, l'analyse des flux de comportement et d'autres fonctions .
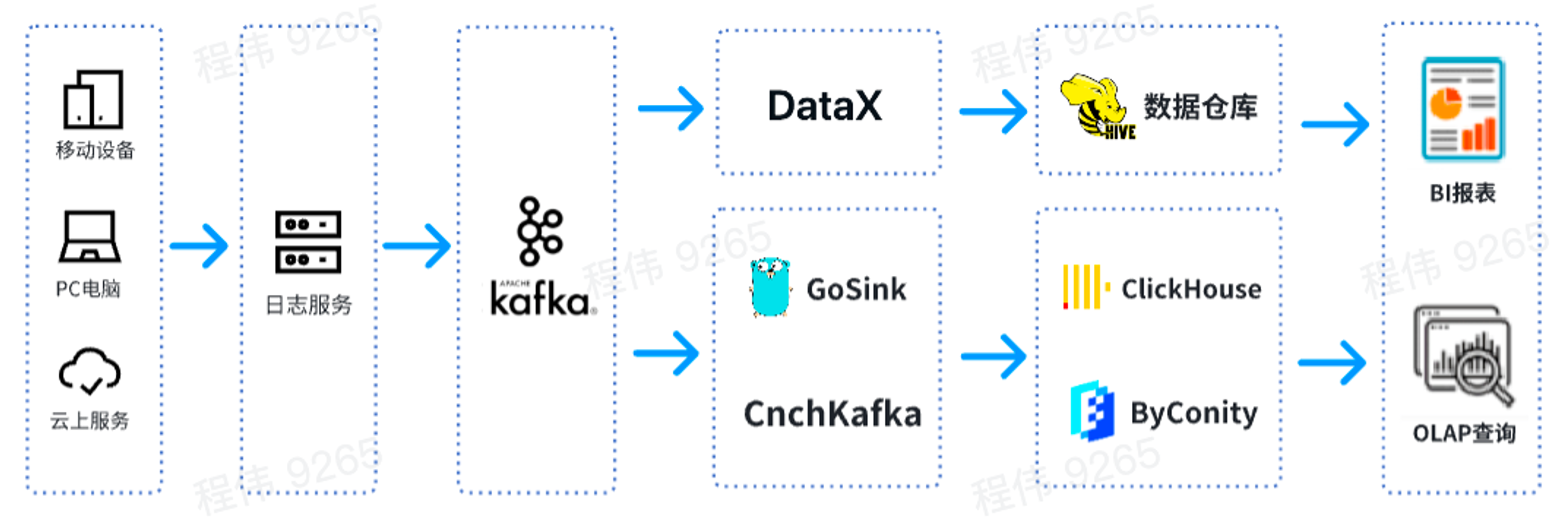
Il s'agit d'une architecture OLAP typique, divisée en deux parties, l'une hors ligne et l'autre en temps réel.
Dans le scénario hors ligne , nous utilisons DataX pour intégrer les données Kafka dans l'entrepôt de données Hive, puis générons des rapports BI. Les rapports BI utilisent le composant Superset pour afficher les résultats ;
Dans un scénario en temps réel , une ligne utilise GoSink pour l'intégration des données et intègre les données GoSink dans ClickHouse, et l'autre ligne utilise CnchKafka pour intégrer les données dans ByConity. Enfin, les données sont obtenues via la plateforme de requête OLAP pour les requêtes.
Comparaison des fonctions entre ByConity et ClickHouse
ByConity est un entrepôt de données cloud natif open source développé sur la base du noyau ClickHouse et adopte une architecture de séparation stockage-calcul. Tous deux présentent les caractéristiques suivantes :
- La vitesse d'écriture est très rapide, adaptée à l'écriture de grandes quantités de données, et la quantité de données écrites peut atteindre 50 Mo à 200 Mo/s.
- La vitesse de requête est très rapide. Sous des données massives, la vitesse de requête peut atteindre 2 à 30 Go/s.
- Taux de compression de données élevé, faible coût de stockage, le taux de compression peut atteindre 0,2 ~ 0,3
ByConity présente les avantages de ClickHouse, maintient une bonne compatibilité avec ClickHouse et a été amélioré en termes de séparation lecture-écriture, d'expansion et de contraction élastiques et de forte cohérence des données . Les deux sont applicables aux scénarios OLAP suivants :
- Les ensembles de données peuvent être volumineux : des milliards ou des milliards de lignes
- Le tableau de données contient de nombreuses colonnes
- Interroger uniquement des colonnes spécifiques
- Les résultats doivent être renvoyés en millisecondes ou secondes
Lors de partages précédents, la communauté ByConity a comparé les deux [d'un point de vue utilisation]
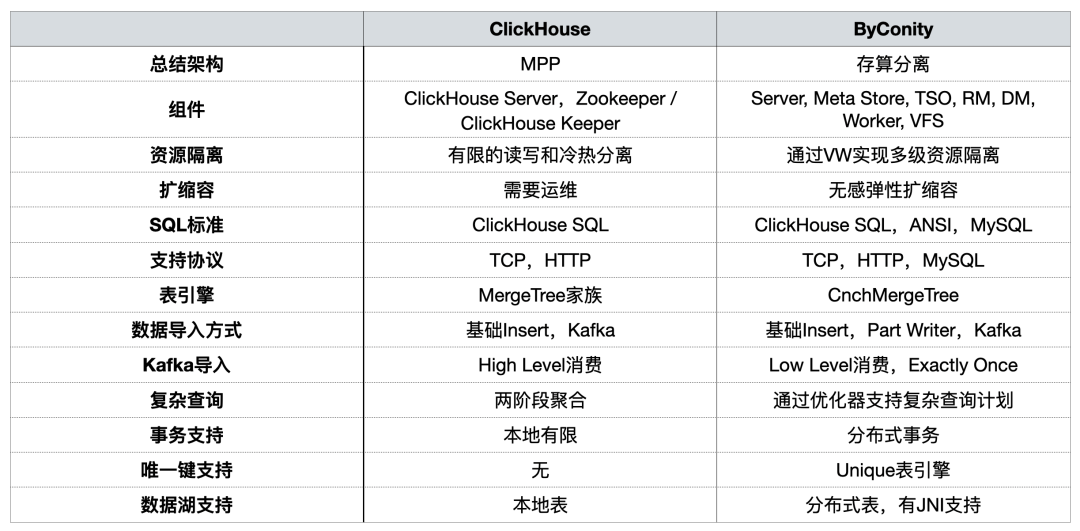
Lors de la construction de la plate-forme OLAP, nous nous sommes principalement concentrés sur l'isolation des ressources, l'expansion et la contraction de la capacité , les requêtes complexes et la prise en charge des transactions distribuées .
Problèmes rencontrés lors de l'utilisation de ClickHouse
Problème 1 : la lecture et l'écriture intégrées peuvent facilement accaparer les ressources et ne peuvent pas garantir une lecture/écriture stable.
Pendant les périodes de pointe, l'écriture de données occupera une grande quantité de ressources d'E/S et de CPU, ce qui affectera les requêtes (les temps de requête deviendront plus longs). Il en va de même pour les requêtes de données.
Problème 2 : L'expansion/réduction est gênante et prend beaucoup de temps
- Temps d'expansion/réduction long : étant donné que la machine est dans un IDC et appartient à un cloud privé, l'un des problèmes est que le cycle d'ajout de nœuds est extrêmement long. Il faut une à deux semaines entre le moment où la demande de nœuds est émise et l'ajout réel de bons nœuds, ce qui affecte l'activité ;
- Impossible d'augmenter et de réduire rapidement : les données doivent être redistribuées après la mise à l'échelle, sinon la pression sur les nœuds sera très élevée.
Troisième problème : l'exploitation et la maintenance sont fastidieuses et le SLA ne peut pas être garanti pendant les périodes de pointe.
- Souvent, en raison de pannes de nœuds métier, les requêtes de données sont lentes et l'écriture des données est retardée (de quelques heures à quelques jours) ;
- Il existe une grave pénurie de ressources pendant les périodes de pointe et il est impossible d'augmenter les ressources à court terme. Le seul moyen est de supprimer les données de certains services afin de fournir des services hautement prioritaires.
- Pendant les périodes de faible activité, un grand nombre de ressources sont inutilisées et les coûts sont gonflés. Bien que nous soyons en IDC, l'achat de machines IDC est également soumis au contrôle des coûts, et l'expansion des nœuds ne peut pas être illimitée. De plus, il existe une certaine consommation de coûts lors d'une utilisation normale ;
- Impossible d'interagir avec les ressources cloud.
Améliorations après l'introduction de ByConity
Tout d’abord, la séparation par ByConity des ressources informatiques de lecture et d’écriture peut garantir que les tâches de lecture et d’écriture sont relativement stables. Si les tâches de lecture ne suffisent pas, les ressources correspondantes peuvent être étendues pour compenser la pénurie, notamment en utilisant les ressources cloud pour l'expansion.
Deuxièmement, la mise à l’échelle vers le haut et vers le bas est relativement simple et peut être effectuée à un niveau infime. Étant donné que le stockage distribué HDFS/S3 est utilisé et que le calcul et le stockage sont séparés, la redistribution des données n'est pas requise après l'expansion et peut être utilisée directement après l'expansion.
De plus, le déploiement, l’exploitation et la maintenance cloud natifs sont relativement simples.
- Les composants de HDFS/S3 sont relativement matures et stables, avec une expansion et une contraction de la capacité, des solutions de reprise après sinistre matures et les problèmes peuvent être résolus rapidement ;
- Pendant les périodes de pointe, le SLA peut être garanti grâce à une expansion rapide des ressources ;
- Pendant les périodes de faible activité, les coûts peuvent être réduits en réduisant les ressources de stockage/informatique.
L’utilisation et le fonctionnement de ByConity
Utilisation du cluster ByConity
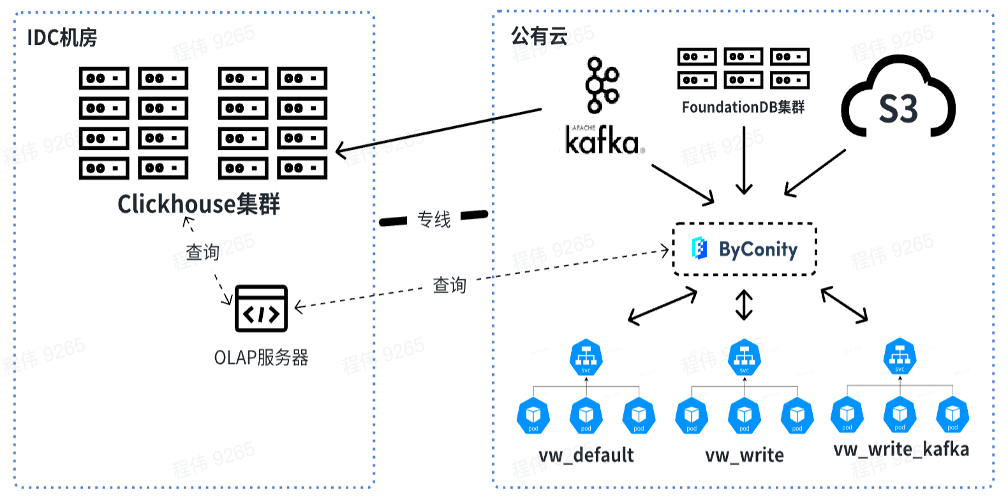
Actuellement, notre plateforme utilise ByConity de manière stable dans des scénarios commerciaux. Grâce à des migrations successives, ByConity a entièrement repris les données du cluster ClickHouse et a commencé à fournir des services de manière stable. Nous avons construit le cluster ByConity en utilisant S3 plus K8 sur le cloud. Nous avons également utilisé une solution d'expansion et de contraction planifiée, qui peut être étendue à 10 heures et réduite à 20 heures en semaine. jour. . Selon les calculs, cette méthode réduit les ressources d'environ 40 à 50 % par rapport à l'utilisation directe d'abonnements annuels et mensuels. En outre, nous promouvons également la combinaison de cloud privé et de cloud public pour atteindre l'objectif de réduction des coûts et d'amélioration de la stabilité des services.
La figure ci-dessous montre notre utilisation actuelle, utilisant le serveur OLAP pour effectuer des requêtes conjointes sur le cluster ClickHouse et ByConity dans la salle informatique IDC hors ligne. À court terme, le cluster ClickHouse servira encore de transition pour les entreprises qui dépendent en partie de ClickHouse.
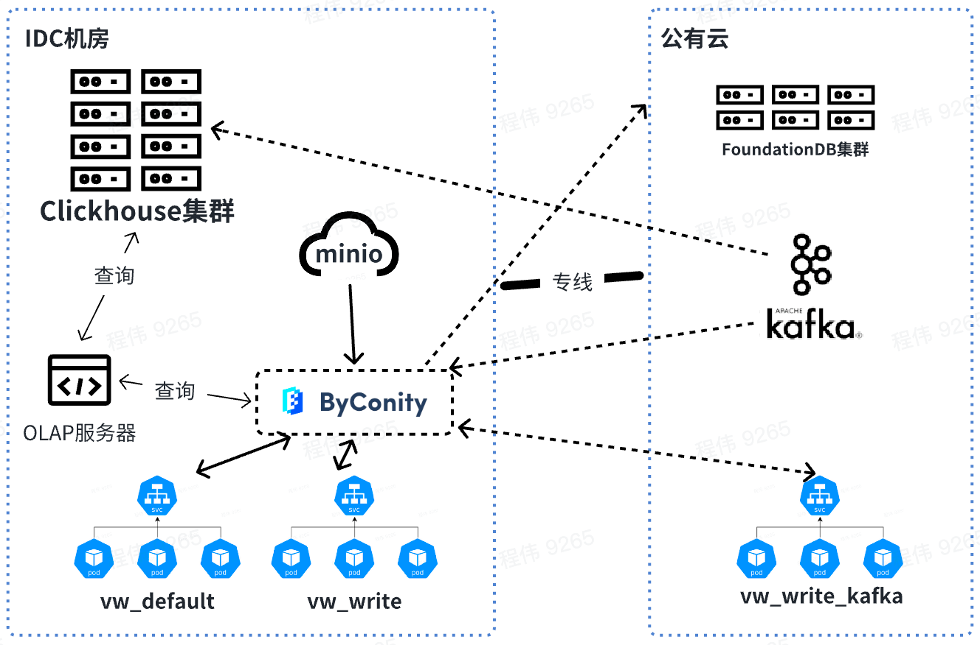
À l'avenir, nous interrogerons et fusionnerons les données hors ligne, tandis que les ressources consommées par Kafka seront utilisées en ligne. Lors de l'extension des ressources, vous pouvez étendre les ressources de vw_default et vw_write en ligne et utiliser rationnellement les ressources du cloud public pour résoudre le problème des ressources insuffisantes. Dans le même temps, la capacité est réduite lors des faibles pics d’activité afin de réduire la consommation du cloud public.
Comparaison des requêtes ByConity et ClickHouse dans les données d'entreprise
Ensemble de données de test et configuration des ressources
- Nombre d'éléments de données : partitionnés par date, 4 milliards d'éléments en une seule journée, 40 milliards au total en 10 jours
- Données tabulaires : 2 800 colonnes
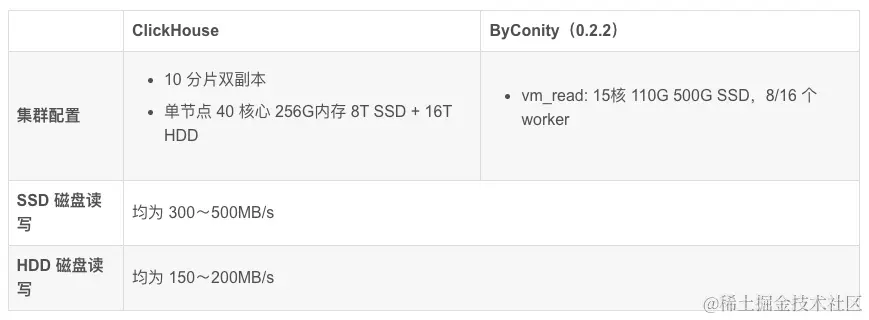
Comme le montre le tableau ci-dessus :
Les ressources utilisées par la requête de cluster ClickHouse sont : 400 cœurs et 2560 Go de mémoire
Les ressources utilisées par la requête du cluster de travail ByConity 8 sont : 120 cœurs et 880 Go de mémoire.
Les ressources utilisées par la requête du cluster de travail ByConity 16 sont : 240 cœurs et 1 760 Go de mémoire.
Résumé des résultats des requêtes SQL métier
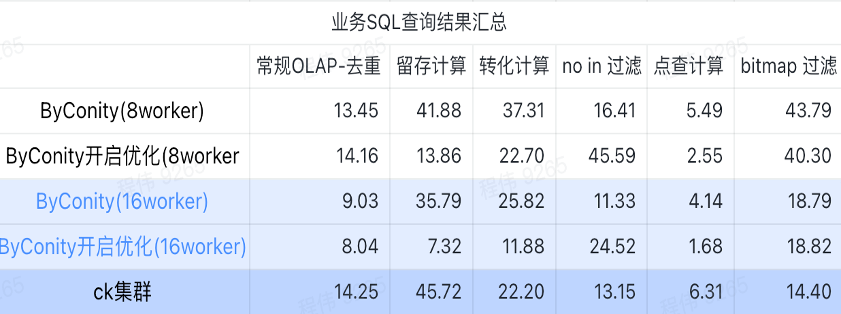
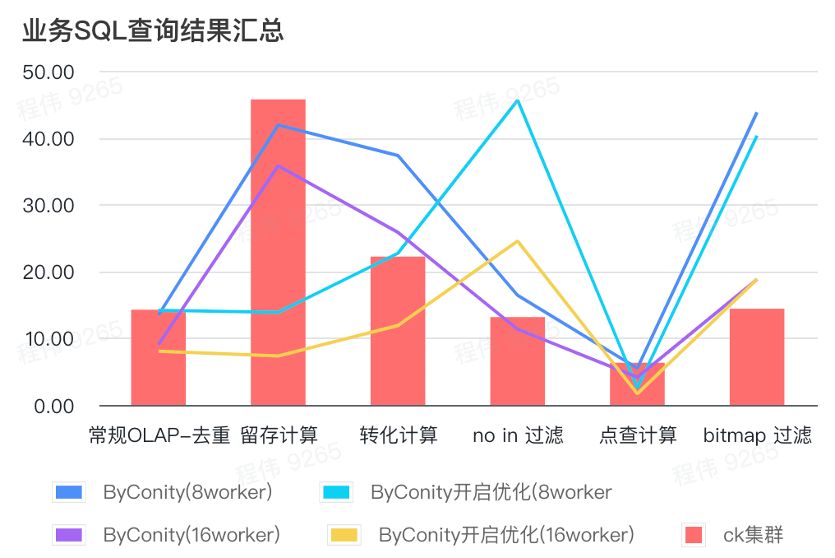
Le résumé ici utilise la valeur moyenne, comme vous pouvez le voir :
- OLAP conventionnel : la déduplication, la rétention, la conversion et l'énumération peuvent obtenir le même effet de requête que le cluster ClickHouse (400C, 2560G) avec un coût de ressources relativement faible (120C, 880G) et peuvent être doublés en augmentant les ressources (240C, 1760G). ) pour obtenir l'effet de doubler la vitesse des requêtes. Si une vitesse de requête plus élevée est requise, davantage de ressources peuvent être étendues ;
- L'absence de filtrage peut nécessiter un coût de ressource modéré (240C, 1760G) pour obtenir des effets similaires à ceux du cluster ClickHouse (400C, 2560G) ;
- Bitmap peut nécessiter des coûts de ressources plus élevés pour obtenir des effets similaires à ceux des clusters ClickHouse.
Requête générale/requête d'analyse d'événements
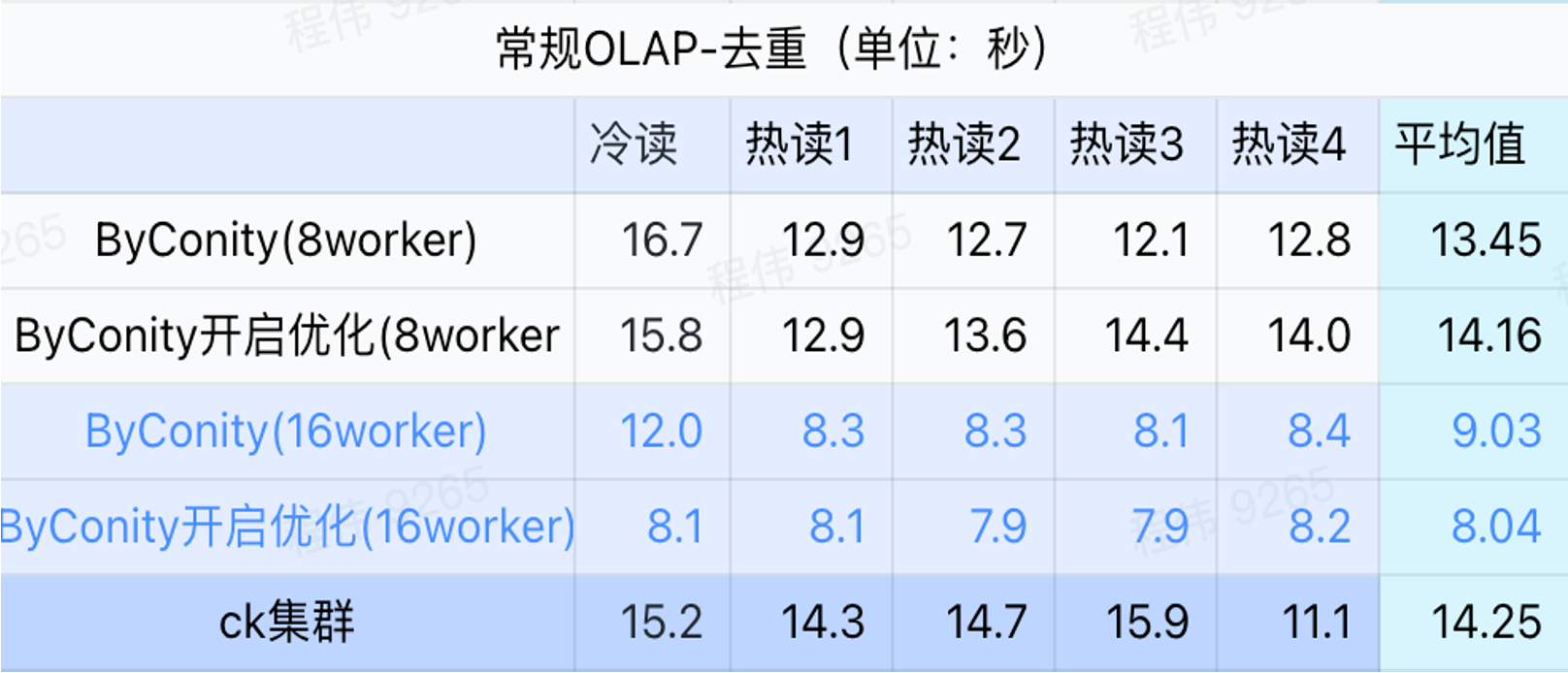
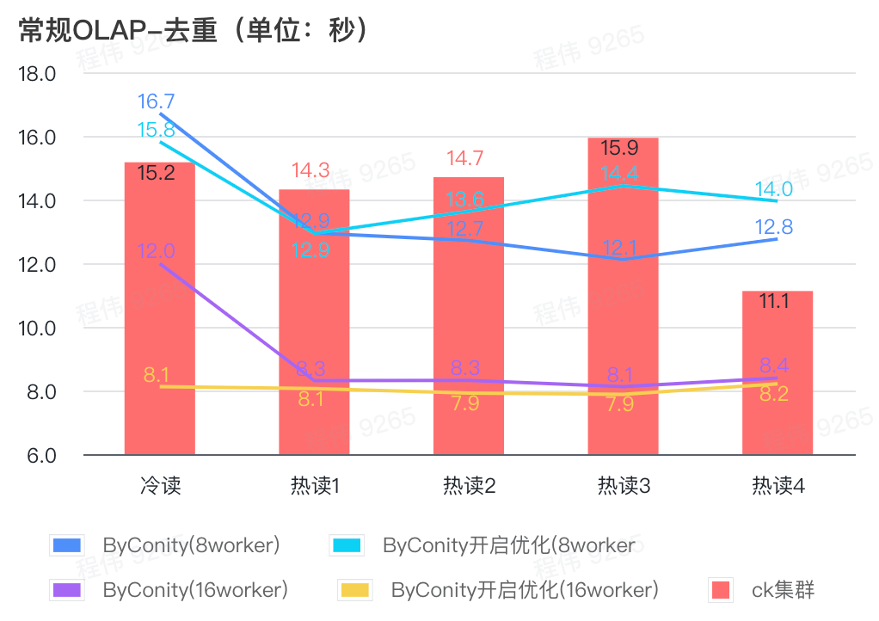
Comme le montre la figure ci-dessus :
- Dans le scénario de requête de déduplication, il n’y a pas beaucoup de différence entre activer l’optimisation ByConity et ne pas activer l’optimisation ;
- 8 travailleurs (120C 880G) atteignent essentiellement un temps de requête proche de ClickHouse ;
- Dans les scénarios de déduplication, la vitesse des requêtes peut être accélérée en augmentant les ressources informatiques.
Calcul de rétention
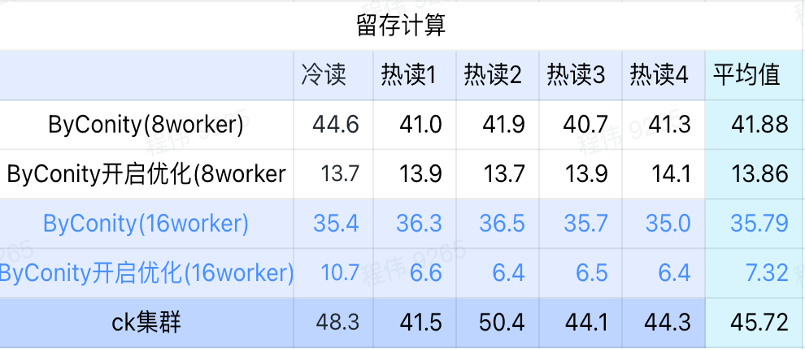
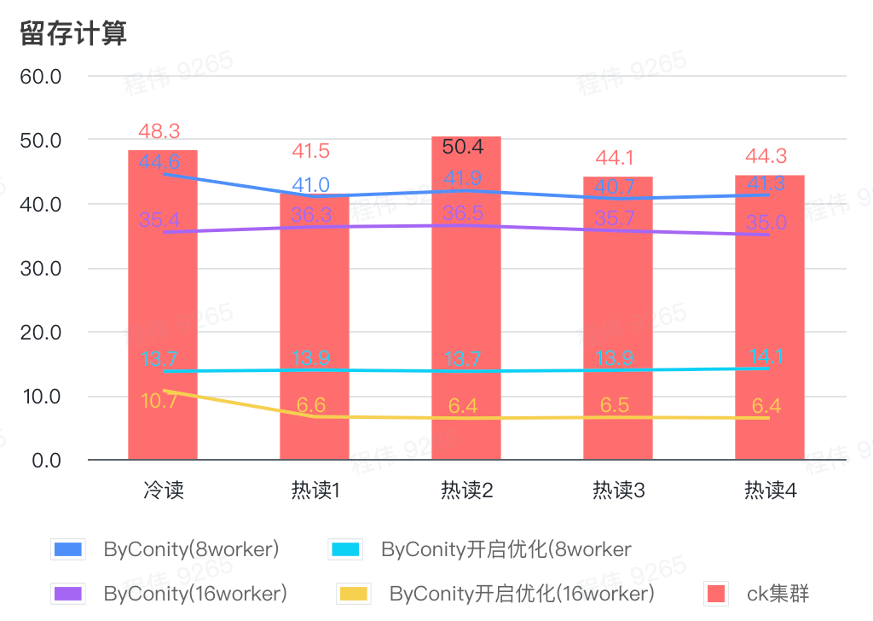
Comme le montre la figure ci-dessus :
- Dans le scénario informatique retenu, le temps de requête après que ByConity a activé l'optimisation est 33 % du temps de requête sans activation de l'optimisation ;
- 8 travailleurs (120C 880G) Le temps de requête avec l'optimisation activée est de 30 % du temps de requête ;
- Dans le scénario informatique retenu, la vitesse de requête peut être accélérée jusqu'à 16 % du temps de requête CK en augmentant les ressources informatiques + optimisation.
Calcul de conversion
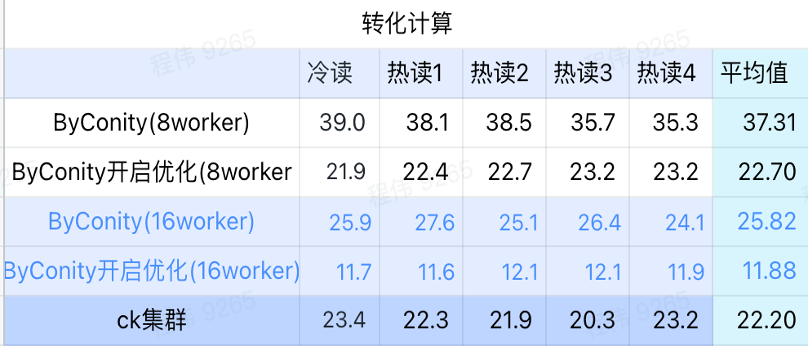
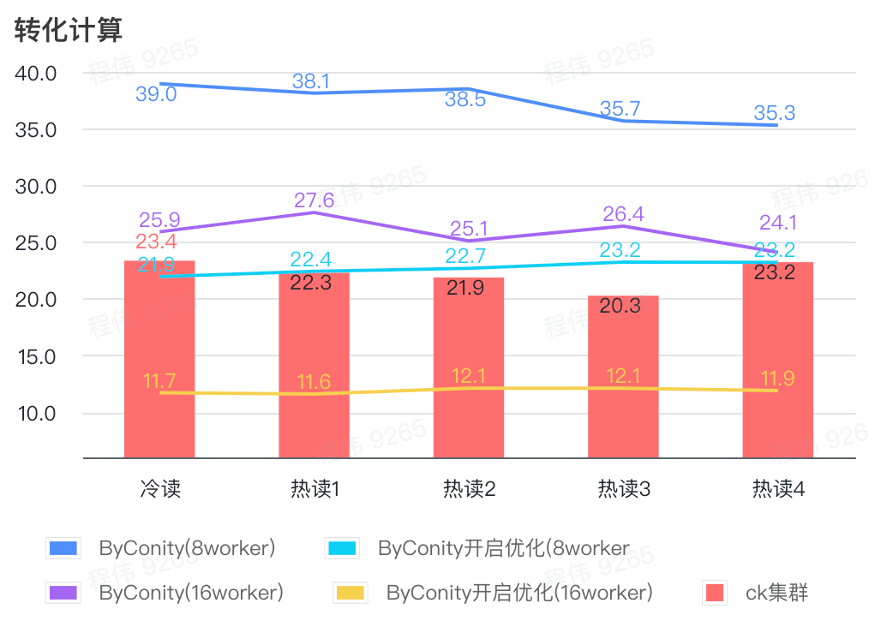
Comme le montre la figure ci-dessus :
- Dans le scénario de calcul de conversion, le temps de requête après l'activation de ByConity pour l'optimisation est de 60 % du temps de requête sans optimisation ;
- Le temps de requête de 8 travailleurs (120C 880G) avec l'optimisation activée est proche du temps de requête ClickHouse ;
- En transformant les scénarios informatiques, la vitesse des requêtes peut être accélérée jusqu'à 53 % du temps de requête ClickHouse en augmentant les ressources informatiques + l'optimisation.
pas dans le filtre
Le filtrage Not in est principalement utilisé dans les scénarios de regroupement d'utilisateurs et les scénarios de marquage d'utilisateurs.

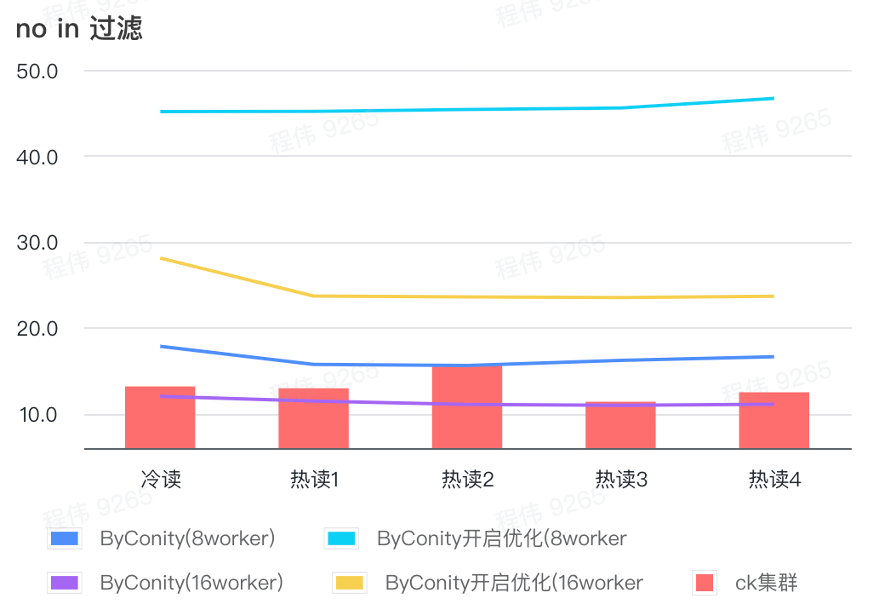
Comme le montre la figure ci-dessus :
- Dans le scénario sans filtrage, ByConity avec l'optimisation activée est pire que ByConity avec l'optimisation non activée, donc dans ce scénario, nous utilisons directement la méthode de non-activation de l'optimisation ;
- Le temps de requête de 8 travailleurs (120C 880G) sans optimisation est plus lent que le temps de requête de ClickHouse, mais pas beaucoup ;
- Dans les scénarios sans filtrage, la vitesse des requêtes peut être accélérée jusqu'à 86 % du temps de requête ClickHouse en augmentant les ressources informatiques.
Cliquez sur calcul 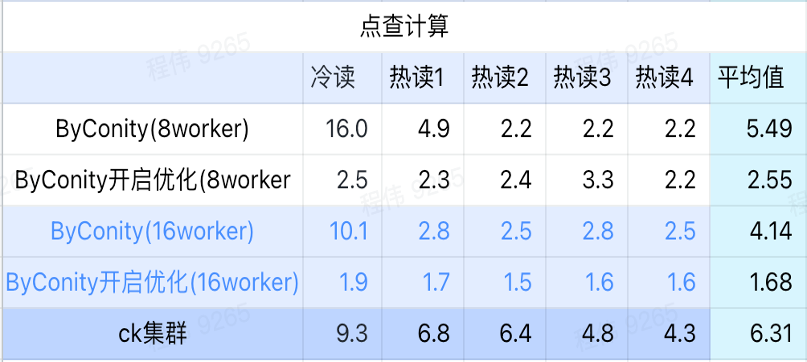
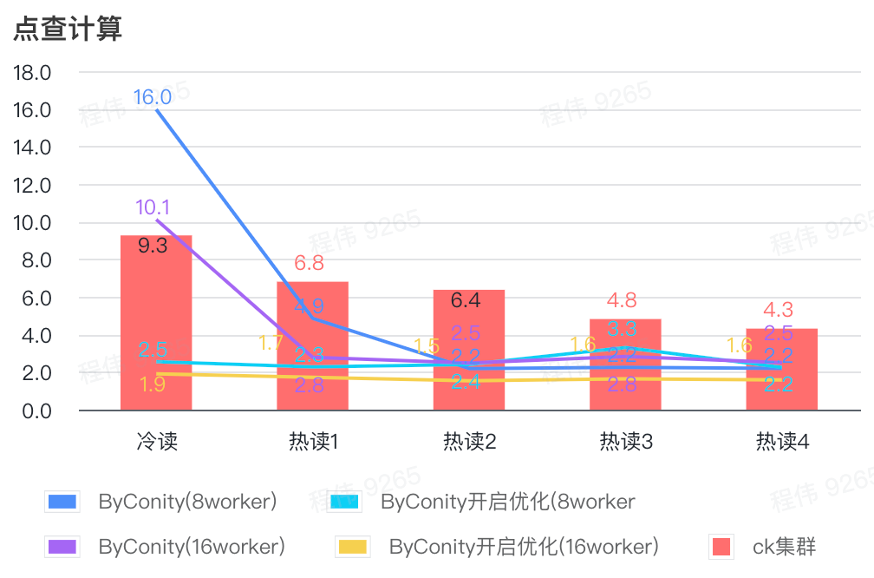
Comme le montre la figure ci-dessus :
- Après avoir vérifié la scène, il est préférable d'activer et d'optimiser ByConity plutôt que de ne pas activer l'optimisation ;
- Le temps de requête de 8 Workers (120C 880G) sans optimisation est proche du temps de requête ClickHouse ;
- Dans le scénario de clic, la vitesse de requête peut être accélérée jusqu'à 26 % du temps de requête ClickHouse en augmentant les ressources informatiques et en activant l'optimisation.
requête bitmap
La requête bitmap est un scénario davantage utilisé dans les tests AB.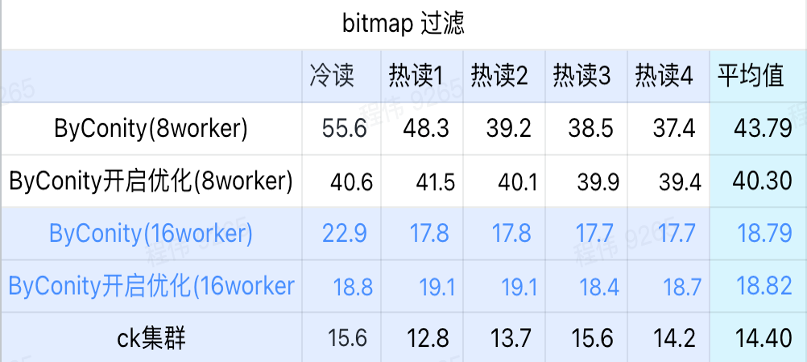
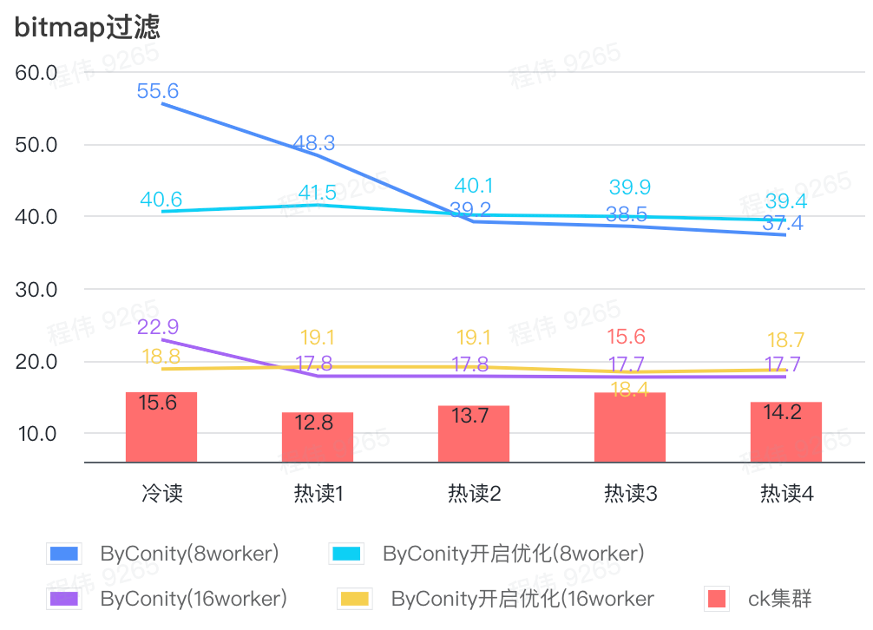
Comme le montre la figure ci-dessus :
- Dans la scène de filtrage bitmap, il est préférable d'activer l'optimisation ByConity plutôt que sans l'optimisation ByConity ;
- Le temps de requête de 8 travailleurs (120C 880G) sans optimisation est beaucoup plus lent que le temps de requête de ClickHouse ;
- La scène de filtrage bitmap, l'extension des ressources à 16 travailleurs (240C 1769G) est plus lente que la requête ClickHouse.
Gains après migration complète de ByConity
Ressources réduites
Ce qui suit ne compte pas les différences de CPU, les données sont uniquement à titre de référence.
Après la migration complète à l'aide de ByConity
- La comparaison de la consommation des ressources de requête et de fusion montre que la consommation du processeur est réduite d'environ 75 % par rapport à avant ;
- En comparant les ressources d'écriture de données, la consommation du processeur est réduite d'environ 35 % par rapport à avant ;
- Seule la moitié des ressources fixes doit être achetée, et la moitié restante dépend de la flexibilité des jours de travail (10h-20h). Le coût est réduit d'environ 25 % par rapport à l'achat de la totalité des ressources ;
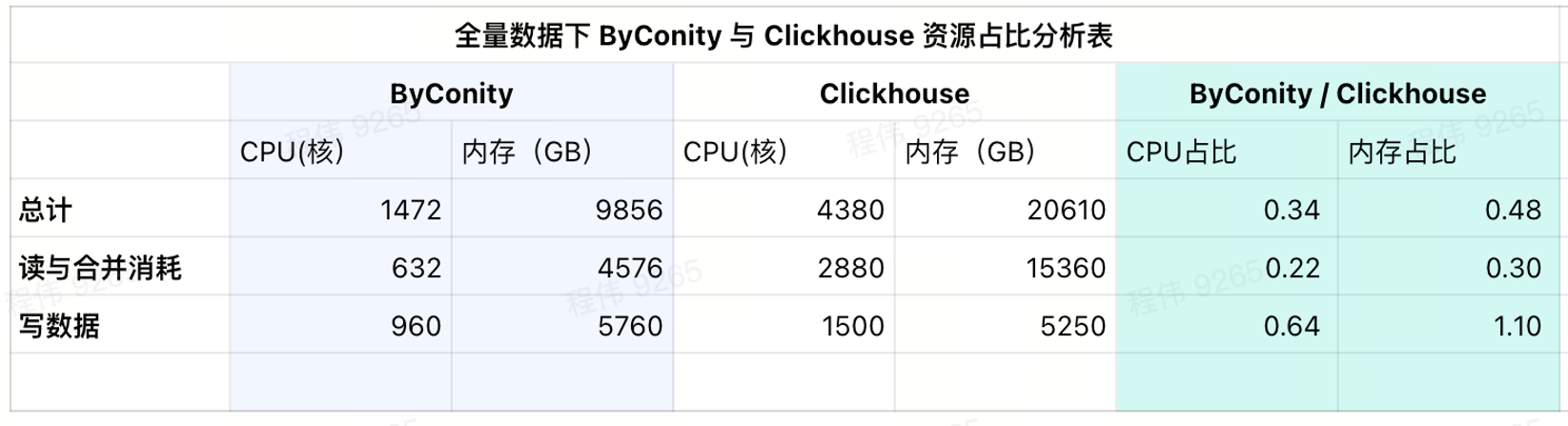
Consommation d'utilisation actuelle
Comme le montre le tableau des résultats actuel, les ratios CPU et mémoire de ByConity sont respectivement de 34 % et 48 % de ceux de ClickHouse.
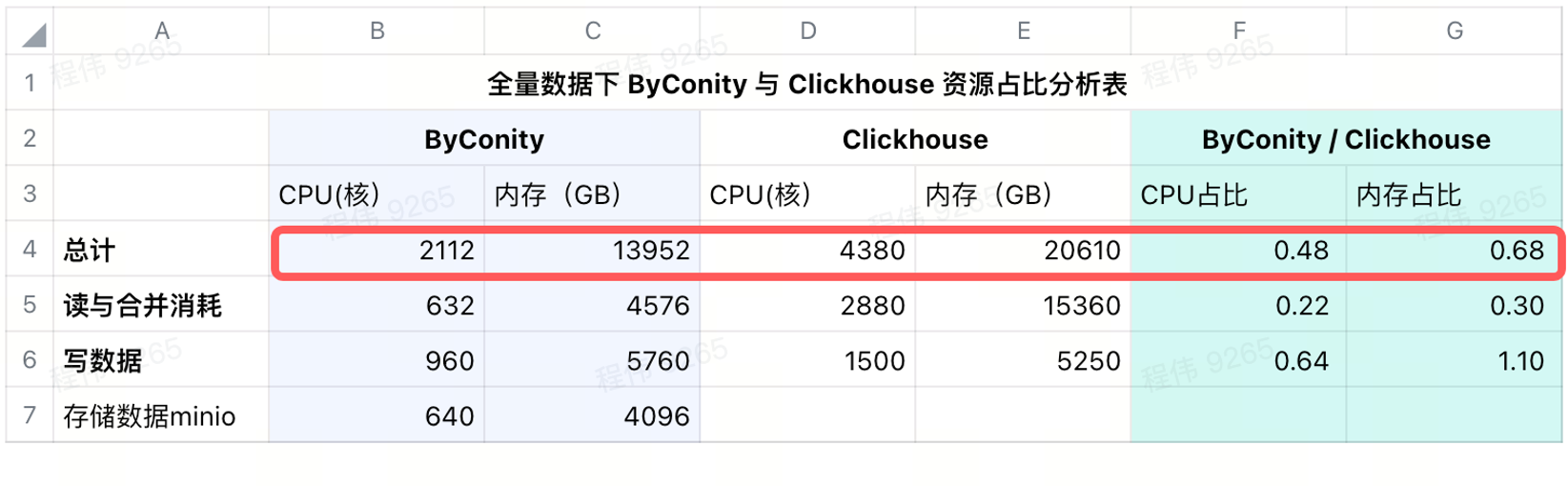
Consommation après ajout du stockage distant
Nous utilisons minio pour le stockage de données dans IDC, en utilisant un processeur de 640 cœurs, 4096 Go de mémoire, 16 nœuds, un seul nœud avec 40 cœurs, 256 Go et un disque de 36 To. Après avoir ajouté ces coûts à ByConity, le ratio CPU et mémoire de ByConity est toujours. inférieur à ClickHouse, respectivement 48% et 68% de ClickHouse. On peut dire qu'en termes d'utilisation des ressources, s'il est calculé sur une base annuelle et mensuelle, ByConity sera au moins environ 50 % inférieur à ce qu'il était auparavant, s'il est démarré et arrêté à la demande, le coût sera réduit d'environ 25 % ; par rapport à l’achat complet des ressources .
Coûts d’exploitation et de maintenance réduits
- Un moyen plus simple d’écrire des données de configuration. Dans le passé, le service d'écriture que nous avions spécialement configuré rencontrait souvent des problèmes tels que Trop de pièces.
- L'expansion maximale des requêtes est plus facile. Ajoutez simplement le nombre de pods et vous pouvez rapidement augmenter la capacité. Personne ne demandera « Pourquoi les données ne sont-elles pas sorties après une demi-heure de vérification ? »
Suggestions pour remplacer ClickHouse par ByConity
- Testez si votre SQL peut fonctionner normalement sur la plateforme ByConity de votre entreprise. S'il est compatible, il fonctionnera essentiellement. S'il y a des problèmes mineurs dans des cas individuels, vous pouvez les signaler dans la communauté pour obtenir un retour rapide ;
- Contrôlez les ressources du cluster de test, testez la taille de l'ensemble de données et comparez les résultats des requêtes du cluster ByConity et du cluster ClickHouse pour voir s'ils répondent aux attentes. Si prévu, un remplacement peut être planifié. Pour les tâches plus axées sur le calcul, ByConity peut être plus performant ;
- En fonction de la taille de l'ensemble de données de test, de l'espace S3 et HDF consommé, de la bande passante et de l'utilisation des ressources informatiques QPS, les ressources requises pour le stockage et le calcul de la quantité totale de données sont évaluées ;
- Entrez les données dans le cluster ByConity ou ClickHouse en même temps et démarrez la double exécution pendant un certain temps pour résoudre les problèmes qui surviennent lors de la double exécution. Par exemple, lorsque notre entreprise ne dispose pas de ressources suffisantes, nous les utilisons en fonction de l'activité. Nous pouvons d'abord créer un cluster ByConity sur le cloud, nous déplacer dans une certaine partie de l'entreprise, puis le remplacer progressivement en fonction de l'activité. Ressources IDC, nous pouvons les déplacer. Une partie des données est migrée hors ligne ;
- Vous pouvez vous désabonner du cluster ClickHouse une fois qu'il n'y a aucun problème de double exécution.
Il y a quelques considérations au cours de ce processus :
- La bande passante de lecture et le QPS du stockage distant S3 et HDFS peuvent être plus élevés et certaines préparations sont nécessaires. Par exemple, notre bande passante maximale en lecture et en écriture par seconde est : écriture 2,5 Go/lecture 6 Go, et le QPS maximal par seconde est : 2 ~ 6 000 ;
- Lorsque la bande passante du nœud Worker est pleine, cela provoquera également un goulot d'étranglement dans les requêtes ;
- Le disque de cache du nœud par défaut (c'est-à-dire le nœud de calcul de lecture) peut être configuré pour être plus grand de manière appropriée, ce qui peut réduire la pression de la bande passante de S3 pendant la requête et accélérer la requête.
- Si vous rencontrez des données non mises en cache, vous pourriez rencontrer des problèmes de démarrage à froid. ByConity propose également quelques suggestions opérationnelles à cet effet, qui doivent être davantage intégrées à sa propre activité. Par exemple, nous utilisons la vérification préalable le matin pour atténuer cette partie du problème de démarrage à froid.
plan d'avenir
À l’avenir, nous favoriserons le test et la mise en œuvre de la solution de lac de données ByConity. De plus, nous combinerons la gestion des indicateurs de données avec la théorie de l'entrepôt de données, afin que 80 % des requêtes tombent sur l'entrepôt de données. Tout le monde est invité à participer à l’expérience.
GitHub |https://github.com/ByConity/ByConity

Scannez le code QR pour ajouter ByConity Assistant
Un camarade de poulet "open source" deepin-IDE et a finalement réalisé l'amorçage ! Bon gars, Tencent a vraiment transformé Switch en une « machine d'apprentissage pensante » Examen des échecs de Tencent Cloud le 8 avril et explication de la situation Reconstruction du démarrage du bureau à distance RustDesk Client Web La base de données de terminal open source de WeChat basée sur SQLite WCDB a inauguré une mise à niveau majeure Liste d'avril TIOBE : PHP est tombé à un plus bas historique, Fabrice Bellard, le père de FFmpeg, a sorti l'outil de compression audio TSAC , Google a sorti un gros modèle de code, CodeGemma , est-ce que ça va vous tuer ? C'est tellement bon qu'il est open source - outil d'édition d'images et d'affiches open source